计算机自适应测验方法与流程
本发明涉及一种检测方法,特别是涉及一种计算机自适应测验方法。
背景技术:
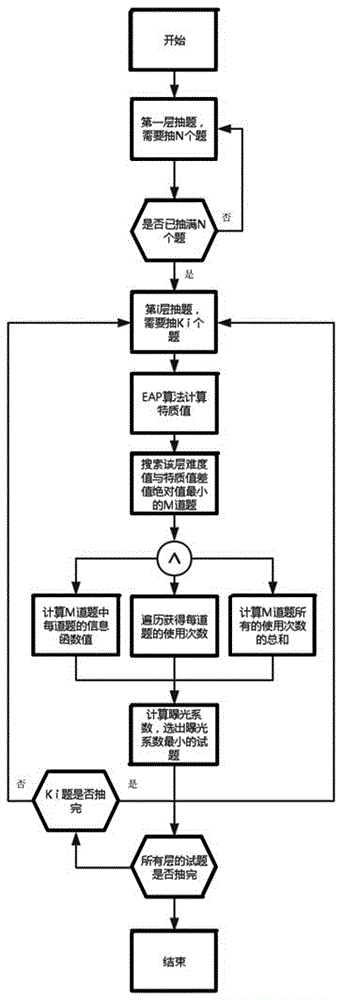
:当前最普遍的自适应测验方法是最大信息法、a分层法、影子题库等等。最大信息法即根据被试作答结果计算出来的特质值,计算题库里每一道试题的信息函数值,然后选择信息函数值最大的试题。a分层法是一种克服最大信息法抽不到低区分度试题的算法,a分层法依据试题的区分度对试题进行分层,然后对每一层或每几层进行最大信息法或难度值与特质值的最小绝对差值法进行抽题。影子题库是为每个被试从题库中抽出最符合当前要求的题库,然后用当前题库进行自适应测验的方法。现有流行的自适应测验方法均有一定的缺陷。最大信息法的测验效率最高,测验精度也最高,但是测验均匀性比较差,同时,遍历题库每一道试题计算信息函数也会导致系统的性能比较差。a分层虽然改善了最大信息法的测验均匀性,但是改善的幅度不大,同时遍历每一层试题计算信息函数的CPU开销也很大。影子题库提前排除了不适合被试的试题,形成了一个题库,极大改善了测验的均匀性,同时测验精度也测验效率也比较高,但是影子题库的目标函数和约束条件均比较复杂,在实际环境中应用会造成系统性能低下。本发明涉及计算机自适应测验的参数估计算法、抽题算法,本发明想要达到的目的是高效率高性能的进行自适应测验,为每个被试每次答题的结果进行计算并为他(她)抽出最适合他(她)的下一道题。技术实现要素:本发明所要解决的技术问题是提供一种计算机自适应测验方法,其能够提高检测均匀性,同时兼顾检测效率和检测精度,性能高。本发明是通过下述技术方案来解决上述技术问题的:一种计算机自适应测验方法,其特征在于,所述计算机自适应测验方法包括以下步骤:步骤一,用户开始做题;步骤二,第一层抽题,需要抽N个题,将第一层次的所有试题依据难度值从小到大的分成N堆,然后从每一堆抽出一道题,形成第一层所抽试题,N为自然数;步骤三,判断是否已做完第一层次的N道题,是则转步骤四,不是则转步骤二;步骤四,当第一层试题作答结束,转到第i层抽题,需要抽Ki个试题,Ki的值需要预先设置好,i为自然数;步骤五,根据之前的作答得分记录,通过得分、试题参数,利用EAP算法计算被试特质值;步骤六,搜索第i层难度值与特质值差值的绝对值最小的M道题,M为自然数;步骤七,计算这M道题的信息函数值,形成一个信息函数值的向量;步骤八,计算这M道题的曝光次数,以及这M道题曝光次数总和;步骤九,计算M道题的曝光系数向量,曝光系数是试题的曝光次数与试题的信息函数值与M道题曝光次数总和之积的比值,然后从曝光系数向量中选出最小元素;步骤九,判断所有层的试题是否抽完,是则转步骤十一,不是则转步骤十;步骤十,判断Ki题是否抽完,是则i=i+1然后转步骤四,不是则直接转步骤四;步骤十一,结束。优选地,所述步骤七包括以下步骤:计算M道题中每道题的信息函数值;遍历获得每道题的使用次数;计算M道题所有的使用次数的总和。优选地,所述计算机自适应测验方法采用异步非阻塞的解决方案,所谓非阻塞是指当线程遇到I/O操作时,不会以阻塞的方式等待I/O操作的完成或数据的返回,而只是将I/O请求发送给操作系统,继续执行下一条语句;当操作系统完成I/O操作时,以事件的形式通知执行I/O操作的线程,线程会在特定时候处理这个事件,所谓异步是指应用程序不需要进行轮询,进而处理每一个任务,只需在I/O完成后通过信号或是回调将数据传递给应用程序即可异步非阻塞的最大好处就是可以响应大规模的IO请求,非常适合大规模计算机自适应测验的应用。优选地,所述计算机自适应测验方法采用EAP算法,EAP算法是IRT模型后验概率函数值的平均数,其优点有不需要迭代,不会出现异常情况,并且运算量小,特别适合大规模的计算机自适应测验应用。本发明的积极进步效果在于:本发明能够提高检测均匀性,同时兼顾检测效率和检测精度,性能高,不用遍历计算每道试题的信息函数值,大大节省了中央处理器的资源,1000人1秒同时作答返回平均时间600毫秒。附图说明图1为本发明的算法流程图。具体实施方式下面结合附图给出本发明较佳实施例,以详细说明本发明的技术方案。如图1所示,本发明计算机自适应测验方法主要包括以下步骤:步骤一,用户开始做题;步骤二,第一层抽题,需要抽N个题,将第一层次的所有试题依据难度值从小到大的分成N堆,然后从每一堆抽出一道题,形成第一层所抽试题,N为自然数;步骤三,判断是否已做完第一层次的N道题,是则转步骤四,不是则转步骤二;步骤四,当第一层试题作答结束,转到第i层抽题,需要抽Ki个试题,Ki的值需要预先设置好,i为自然数;步骤五,根据之前的作答得分记录,通过得分、试题参数,利用EAP算法计算被试特质值;步骤六,搜索第i层难度值与特质值差值的绝对值最小的M道题,M为自然数;步骤七,计算这M道题的信息函数值,形成一个信息函数值的向量;步骤八,计算这M道题的曝光次数,以及这M道题曝光次数总和;步骤九,计算M道题的曝光系数向量,曝光系数是试题的曝光次数与试题的信息函数值与M道题曝光次数总和之积的比值,然后从曝光系数向量中选出最小元素;步骤九,判断所有层的试题是否抽完,是则转步骤十一,不是则转步骤十;步骤十,判断Ki题是否抽完,是则i=i+1然后转步骤四,不是则直接转步骤四;步骤十一,结束。步骤七包括以下步骤:计算M道题中每道题的信息函数值;遍历获得每道题的使用次数;计算M道题所有的使用次数的总和。依据试题使用次数与a分层、最大信息函数和影子题库结合,通过建立目标函数和约束条件求解最小曝光系数,将试题使用次数与信息函数值置于同一量纲。所述计算机自适应测验方法采用异步非阻塞的解决方案,所谓非阻塞是指当线程遇到I/O操作时,不会以阻塞的方式等待I/O操作的完成或数据的返回,而只是将I/O请求发送给操作系统,继续执行下一条语句;当操作系统完成I/O操作时,以事件的形式通知执行I/O操作的线程,线程会在特定时候处理这个事件,所谓异步是指应用程序不需要进行轮询,进而处理每一个任务,只需在I/O完成后通过信号或是回调将数据传递给应用程序即可异步非阻塞的最大好处就是可以响应大规模的IO请求,非常适合大规模计算机自适应测验的应用。本发明将试题库提前载入缓存,保证IO的畅通无阻。所述计算机自适应测验方法采用EAP算法,EAP算法是IRT模型后验概率函数值的平均数,其优点有不需要迭代,不会出现异常情况,并且运算量小,特别适合大规模的计算机自适应测验应用。EAP算法的速度是极大似然法的两倍。本发明的工作原理如下:以a分层为基础,结合试题使用次数、影子题库和极大信息法进行抽题。第1层为随机抽取难度均匀的试题,例如第一层试题难度分布为-3到3,需要随机抽3题,则本发明随机抽取难度为[-3,-1],[-1,1],[1,3]这三个层次的试题(对应步骤二)。其他层根据被试的特质值进行抽题,首先根据被试的特质值抽取与难度值最小绝对差值的若干道题(缺省默认是30道题)组成题库,然后计算题库里的试题的使用次数总和,接着把使用次数总和与每道试题的使用次数以及每道试题的信息函数带入约束条件计算(该条件是试题的曝光次数与试题的信息函数值与M道题曝光次数总和之积的比值),目标函数最小的曝光系数,然后抽取最小曝光系数的试题(对应步骤七、步骤八、步骤九)。结束规则是定长,比如第一层抽3题,第二层抽3题,第三层抽3题,第四层抽3题,则作答试题达到12题后结束。综上所述,本发明能够提高检测均匀性,同时兼顾检测效率和检测精度,性能高,不用遍历计算每道试题的信息函数值,大大节省了中央处理器的资源,1000人1秒同时作答返回平均时间600毫秒。应用蒙特卡洛方法,在区分度为unif(1,3)和难度为norm(0,1)的300道随机题库下,该算法的各项测验指标如表1所示。表1基于蒙特卡洛方法的计算机自适应测验方法的各项检验指标检测指标指标值检测均匀性0.99检测效率9.7检测重叠率0.02由表1结果得知,试验符合理论分析,计算机自适应测验方法检测均匀性高,同时兼顾检测效率和检测精度。以上所述的具体实施例,对本发明的解决的技术问题、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1