一种自适应缓冲块替换方法与流程
本发明涉及计算机系统结构领域,涉及一种自适应缓冲块替换方法。
背景技术:
缓存替换算法的核心在于充分局部性原理提高缓存命中率,各种替换算法的主要不同在于如何量化局部性。常见的两种缓存替换策略包括:基于访问时间的lru(leastrecentlyused)策略和基于访问频率的lfu(leastfrequentlyused)策略。lru策略仅维护了缓存块的访问时间信息,没有考虑被访问频率等因素,在某些访问模式下无法获得理想命中率。与lru策略的缺点类似,lfu策略仅维护各项的被访问频率信息,对于某缓存项,如果该项在过去有着极高的访问频率而最近访问频率较低,当缓存空间已满时该项很难被从缓存中替换出来,进而导致命中率下降。
spark是ucberkeleyamplab(加州大学伯克利分校的amp实验室)所开源的类hadoopmapreduce的通用并行框架,主要特点是提供了一个集群的分布式内存抽象—弹性分布式数据集rdd,以支持需要工作集的应用。在hadoopmapreduce框架中,shuffle过程是连接map和reduce之间的桥梁,shuffle过程会产生大量的中间文件,内存需求巨大,涉及到了磁盘的读写和网络的传输,它的性能高低直接影响到了整个程序的运行效率。随着大数据时代应用的规模不断增加,内存资源的需求量也随之增加,当内存大小无法满足应用的工作集的需求时,必然导致频繁的缓存块替换。若采用普通的lru策略,驱逐被访问最少的数据块,那么很可能出现当某一个不在内存中的数据块需要被访问时,由于内存资源不够,必须先驱逐另一个之后很可能被访问的相邻数据块,再把该块读入内存,会导致不必要的开销。因此,需要一种全面的、效率高的缓冲块替换策略。
技术实现要素:
有鉴于此,本发明提供一种解决或部分解决上述问题的一种自适应缓冲块替换方法。
为达到上述技术方案的效果,本发明的技术方案为:一种自适应缓冲块替换方法,在通用并行框架spark提供的弹性分布式数据集rdd上运行,弹性分布式数据集rdd为集群的分布式内存抽象,步骤如下:
1)结合弹性分布式数据集rdd的变换序列关系判断并得到属于弹性分布式数据集rdd的所有数据块的重计算开销,初始化记录数据块的重计算开销的数据结构,为其分配内存空间,并将内存空间的内部所有位初始化为0;
2)根据分配方案为弹性分布式数据集rdd的动作分配权重,分配方案为:
首先,将弹性分布式数据集rdd的动作分为transformations动作类型和actions动作类型,transformations动作类型为一种惰性操作,定义了一个新的弹性分布式数据集rdd,没有立即对其进行计算,actions动作类型则是对弹性分布式数据集rdd立即计算,并返回结果或者将结果写入到外部存储中;
将transformations动作类型分为map动作、flatmap动作、filter动作、distinct动作、union动作、intersection动作、subtract动作、cartesian动作;map动作表示对弹性分布式数据集rdd中的每一个元素进行一个操作,map动作的权重为t1;flatmap动作表示弹性分布式数据集rdd中的当前元素,并生成新的元素集合,flatmap动作的权重为t2;filter动作表示过滤弹性分布式数据集rdd中的一些元素,filter动作的权重为t3;distinct动作表示对弹性分布式数据集rdd中元素去重,distinct动作的权重为t4;union表示返回弹性分布式数据集rdd1、弹性分布式数据集rdd2的合并结果,在这其中对合并结果不去重,union动作的权重为t5;intersection动作表示返回弹性分布式数据集rdd1、弹性分布式数据集rdd2的合并结果,在这其中对合并结果去重,intersection动作的权重为t6;subtract动作表示对弹性分布式数据集rdd1、弹性分布式数据集rdd2的合并,合并后只保留在一个弹性分布式数据集rdd1中出现的元素而在另一个弹性分布式数据集rdd2不出现的元素,subtract动作的权重为t7;cartesian动作表示对对弹性分布式数据集rdd1、弹性分布式数据集rdd2进行笛卡尔积计算,cartesian动作的权重为t8;
将actions动作类型分为collect动作、count动作、take动作、top动作、takeordered动作、fold动作、foreach动作;collect动作表示将弹性分布式数据集rdd转换为数组,collect动作的权重为a1;count动作返回弹性分布式数据集rdd中的元素数量,count动作的权重为a2;take动作表示获取弹性分布式数据集rdd中从0到指定标号的元素,指定标号用常量num表示,take动作的权重为a3;top动作表示从弹性分布式数据集rdd中,按照默认或给定的排序规则,返回其中的从0到指定标号的元素,top动作的权重为a4;takeordered动作表示按照与top动作的排序规则相反的顺序返回从0到指定标号的元素,takeordered动作的权重为a5;fold动作表示将弹性分布式数据集rdd中的每个元素累积求和,fold动作的权重为a6;foreach动作表示遍历弹性分布式数据集rdd中的每个元素,foreach动作的权重为a7;
3)弹性分布式数据集rdd执行第2)步所分类的动作时,数据块的重计算开销的数据结构中对应的弹性分布式数据集rdd的记录位增加相应动作的权重;弹性分布式数据集rdd分为父弹性分布式数据集以及子弹性分布式数据集,数据块的重计算开销与弹性分布式数据集rdd的动作以及父弹性分布式数据集和子弹性分布式数据集的依赖关系有关,其中,父弹性分布式数据集和子弹性分布式数据集的依赖关系分为窄依赖、宽依赖两种;窄依赖表示子弹性分布式数据集中的每个数据块只依赖于父弹性分布式数据集中的有限个固定数据块,宽依赖表示子弹性分布式数据集可以依赖于父弹性分布式数据集中的所有数据块;
4)判断弹性分布式数据集rdd的缓存块替换开销,并调整其的阈值,并定义缓冲块替换策略,缓冲块替换策略分为lru策略、lcc策略两种,lrc策略为驱逐最少访问的数据块策略,lcc策略为驱逐最小重计算开销的数据块策略,初始时默认缓存块替换策略为lru策略,并设置其替换阈值为threshold-lru,其后根据替换条件判断是否将缓冲块替换策略修改为lcc策略,并设置其替换阈值为threshold-lcc;lcc策略的初始替换阈值threshold-lcc=0;lru策略的初始替换阈值threshold-lcc=3;
5)动态地选择缓冲块替换策略;
初始时默认缓存块替换策略为lru策略,并设置其替换阈值为threshold-lru,设置初始缓冲块替换策略的数据块读取开销c=0,当其的内存块在时间段t内,被驱逐后又重新被读入时,缓冲块替换策略的数据块读取开销c=c+1,当连续三个缓冲块替换策略的数据块在时间段t内被驱逐并被重新读入时,缓冲块替换策略的数据块读取开销c的值超过threshold-lru,修改缓存块替换策略为lcc策略;选取权重最低的弹性分布式数据集rdd所对应的数据块,将根据lcc策略将其修改为驱逐重计算开销最小的数据块;当缓冲块替换策略为lcc策略时,驱逐完属于权重最低的弹性分布式数据集rdd的所有数据块之后,权重最低的弹性分布式数据集rdd的重计算开销设置为无效,根据弹性分布式数据集rdd的重计算开销对弹性分布式数据集rdd重新进行排序,选择重计算开销最小的弹性分布式数据集rdd作为新的驱逐对象,当缓冲块替换策略的数据块读取时间小于threshold-lru,lcc策略替换开销过大,将缓存块替换策略修改为lru策略;
6)通过弹性分布式数据集rdd的容错特点恢复其的数据块;
弹性分布式数据集rdd的容错机制采用记录更新的方式,只支持粗颗粒变换,粗颗粒变换只记录弹性分布式数据集rdd上的单个数据块上执行的单个操作,然后将创建弹性分布式数据集rdd的变换序列存储下来,弹性分布式数据集rdd的变换序列为弹性分布式数据集rdd由其他弹性分布式数据集rdd变换的信息以及重建其中的数据的信息;当需要恢复弹性分布式数据集rdd中的数据块时,根据弹性分布式数据集rdd记录的动作以及与父弹性分布式数据集的依赖关系选择不同的恢复方法;窄依赖可以直接通过计算父弹性分布式数据集的某块数据计算得到子弹性分布式数据集对应的某块数据;宽依赖需要将父弹性分布式数据集中的所有数据块全部重新计算来恢复,并根据其的重新计算时间,设置新的缓存块替换策略转换阈值threshold-lcc=t,其中t为ccb中权重最低的弹性分布式数据集rdd中数据块的重计算时间。
本发明的有益成果是:本发明结合弹性分布式数据集rdd自身特点,通过其的依赖关系恢复数据块,降低了内存的i/o需求;本发明采用低内存开销的重计算开销的数据结构记录弹性分布式数据集rdd的动作权重,属于同一rdd的所有数据块重计算开销相同,极大地降低了内存开销;本发明针对大数据应用的特点优化缓存替换策略,通过记录rdd的动作权重判断重计算开销,来驱逐重计算开销较小的数据块,避免了lru策略导致的数据块重复驱逐与读入,能够显著减少内存开销;本发明涉及的缓存策略能够动态识别负载特征,自动切换缓冲块替换策略,实现了性能最大化。
附图说明
图1是本发明的流程示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合实施例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,能实现同样功能的产品属于等同替换和改进,均包含在本发明的保护范围之内。具体方法如下:
实施例1:缓存替换算法的核心在于充分局部性原理提高缓存命中率,各种替换算法的主要不同在于如何量化局部性。常见的两种缓存策略包括:基于访问时间的lru(leastrecentlyused)策略和基于访问频率的lfu(leastfrequentlyused)策略。lru算法维护一个缓存项队列,队列中的缓存项按每项的最后被访问时间排序。当缓存空间已满时,将处于队尾,即删除最后一次被访问时间距现在最久的项,将新的区段放入队列首部。但lru算法仅维护了缓存块的访问时间信息,没有考虑被访问频率等因素,在某些访问模式下无法获得理想命中率。lfu算法按每个缓存块的被访问频率将缓存中的各块排序,当缓存空间已满时,替换掉缓存队列中访问频率最低的一项。与lru的缺点类似,lfu仅维护各项的被访问频率信息,对于某缓存项,如果该项在过去有着极高的访问频率而最近访问频率较低,当缓存空间已满时该项很难被从缓存中替换出来,进而导致命中率下降。
spark是ucberkeleyamplab(加州大学伯克利分校的amp实验室)所开源的类hadoopmapreduce的通用并行框架,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。这个抽象就是rdd(resilientdistributeddataset),也被称为弹性分布式数据集。rdd一种有容错机制的特殊集合,可以分布在集群的节点上,以函数式编操作集合的方式,进行各种并行操作。可以将rdd理解为一个具有容错机制的特殊集合,它提供了一种只读、只能有已存在的rdd变换而来的共享内存,然后将所有数据都加载到内存中,方便进行多次重用。spark的特点总结如下:a.rdd是分布式的,可以分布在多台机器上,进行计算。b.rdd是弹性的,计算过程中内存不够时它会和磁盘进行数据交换。c.这些限制可以极大的降低自动容错开销d.spark实质是一种更为通用的迭代并行计算框架,用户可以显示的控制计算的中间结果,然后将其自由运用于之后的计算。
在mapreduce框架中,shuffle是连接map和reduce之间的桥梁,当map的输出结果要被reduce使用时,输出结果需要按key哈希,并且分发到每一个reducer上去,这个过程就是shuffle。shuffle过程会产生大量的中间文件,内存需求巨大。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。随着大数据时代应用的规模不断增加,内存资源的需求量也随之增加,当内存大小无法满足应用的工作集的需求时,必然导致频繁的缓存块替换。若采用普通的lru策略,驱逐被访问最少的数据块,那么很可能出现当某一个不在内存中的数据块需要被访问时,由于内存资源不够,必须先驱逐另一个之后很可能被访问的相邻数据块,再把该块读入内存,导致不必要的开销。
实施例2:本实施例基于sparkrdd的一种自适应缓存块替换策略的实施步骤如下:
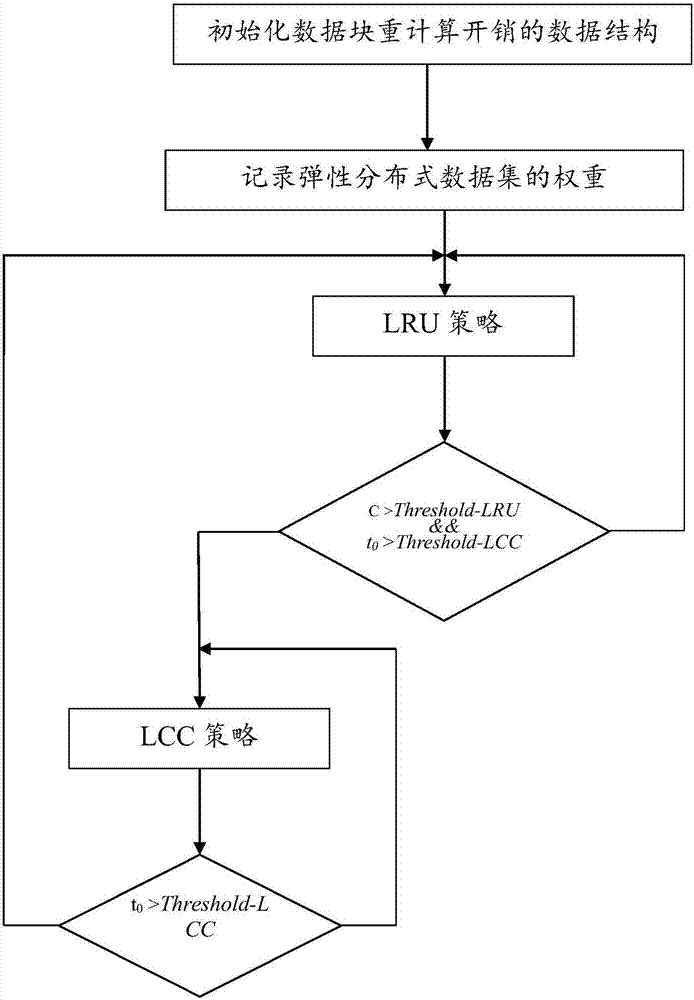
1)根据主机内存资源和弹性分布式数据集rdd的数量,初始化重计算开销的数据结构,为其分配相应内存空间,为每个rdd建立权重信息,所有位初始化为0。跳转执行步骤2);
2)根据弹性分布式数据集rdd经历的动作及其与父rdd的依赖关系,记录每个rdd的权重。跳转执行步骤3);
3)设置数据块的替换策略为lru策略,监控短时间内是否有内存块被驱逐后又重新读入内存,若有则c+1。跳转执行步骤4);
4)若c的值超过替换策略转换阈值threshold-lru,且数据块的读取开销t0大于重计算开销阈值threshold-lcc,则跳转执行步骤5),否则跳转执行步骤3);
5)数据块替换策略为lcc策略,驱逐重计算开销最小的数据块。当需要恢复数据块时,读取rdd血统关系,重新计算数据块,并根据重计算开销设置新的转换阈值threshold-lcc。跳转执行步骤6);
6)比较数据读取开销与重计算开销。若数据块的读取开销t0大于重计算开销阈值threshold-lcc,则跳转执行步骤5),否则跳转执行步骤3)。
本实施例设计一种基于sparkrdd的一种自适应缓存块替换策略,通过低内存开销的cbb记录rdd的重计算权重。为了结合应用特点优化数据块替换策略,本发明设计了一种动态缓存替换策略,结合rdd的血统关系判断属于某一rdd的所有数据块的重计算开销,动态识别当前缓存替换策略下数据块的读取延迟,当短时间内多个数据块被驱逐后又重新读入内存时,将数据块替换策略更改为lcc。之后在数据块恢复阶段,根据数据块的重计算开销设置新的阈值threshold-lcc,当重计算开销大于内存读取数据块的延迟后,将数据块的替换策略更改为lru。本实施例具有低内存开销、动态更改数据块替换策略,自适应负载特点等优点。
本发明的有益成果是:本发明结合弹性分布式数据集rdd自身特点,通过其的依赖关系恢复数据块,降低了内存的i/o需求;本发明采用低内存开销的重计算开销的数据结构记录弹性分布式数据集rdd的动作权重,属于同一rdd的所有数据块重计算开销相同,极大地降低了内存开销;本发明针对大数据应用的特点优化缓存替换策略,通过记录rdd的动作权重判断重计算开销,来驱逐重计算开销较小的数据块,避免了lru策略导致的数据块重复驱逐与读入,能够显著减少内存开销;本发明涉及的缓存策略能够动态识别负载特征,自动切换缓冲块替换策略,实现了性能最大化。
以上所述仅为本发明之较佳实施例,并非用以限定本发明的权利要求保护范围。同时以上说明,对于相关技术领域的技术人员应可以理解及实施,因此其他基于本发明所揭示内容所完成的等同改变,均应包含在本权利要求书的涵盖范围内。
- 还没有人留言评论。精彩留言会获得点赞!