用于语义值数据压缩和解压缩的方法、设备和系统与流程
相关申请的交叉引用
本申请要求于2015年5月21日提交的、名称为“用于数据压缩和解压缩的方法、设备和系统”的瑞典专利申请号1550644-7的优先权,其内容通过引用整体并入本文。
本专利申请的公开通常涉及例如在高速缓存/存储器子系统中和/或在计算机系统的数据传输子系统中,或者在数据通信系统中的数据压缩和解压缩的领域。
背景技术:
数据压缩是用于减小数据大小的一种行之有效的技术。其应用到保存在计算机系统的存储器子系统中的数据以增加存储器容量。当数据在计算机系统内的不同子系统之间传输时,或者通常当在包括通信网络的数据通信系统中的两点之间进行传输时,数据压缩也被使用。
数据压缩需要两个基本操作:1)压缩(也称为编码),其将未压缩的数据作为输入,并通过由各自的码字(在文献中也称为编码、译码或代码)代替数据值而将其转换成压缩的数据;以及2)解压缩(也称为解码),其将压缩的数据作为输入,并通过由各自的数据值代替码字将其转换成未压缩的。数据压缩可以是无损的,也可以是有损的,取决于解压缩后的实际数据值是否与被压缩前的原始数据值完全相同(无损),或者解压缩后的数据值是否与原始数据值不同且原始值不能被恢复(有损)。压缩和解压缩可以用软件或硬件来实施,或者用软件和硬件的结合来实现各自的方法、装置和系统。
在图1中示出了计算机系统100的示例。计算机系统100包括使用通信装置(例如互连网络)连接至存储器分级结构110的一个或多个处理单元p1...pn。每个处理单元包括处理器(或核心),并且可以是cpu(中央处理单元)、gpu(图形处理单元)或者通常是执行计算的块。另一方面,存储器分级结构110构成计算机系统100的存储子系统,并且包括可以以一个或多个级l1-l3组织的高速缓冲存储器120,以及存储器130(又名主存储器)。存储器130也可以连接至次级存储器(例如硬盘驱动器、固态驱动器或闪存)。存储器130可以以多个级组织,例如快速主存储器(例如ddr)和闪存。当前示例中的高速缓冲存储器120包括三个级,其中l1和l2是专用高速缓存,因为每个处理单元p1-pn连接至专用的l1/l2高速缓存,而l3在所有处理单元p1-pn之间共享。替代的示例可以实现具有更多、更少或甚至没有高速缓存级的不同的高速缓存分级结构;以及具有或不具有专用高速缓存以被私有或共享的高速缓存分级结构;各种存储器分级结构;具有不同数量的处理单元和在处理单元与存储器子系统之间的通常不同的组合,所有这些都是由技术人员容易实现的。
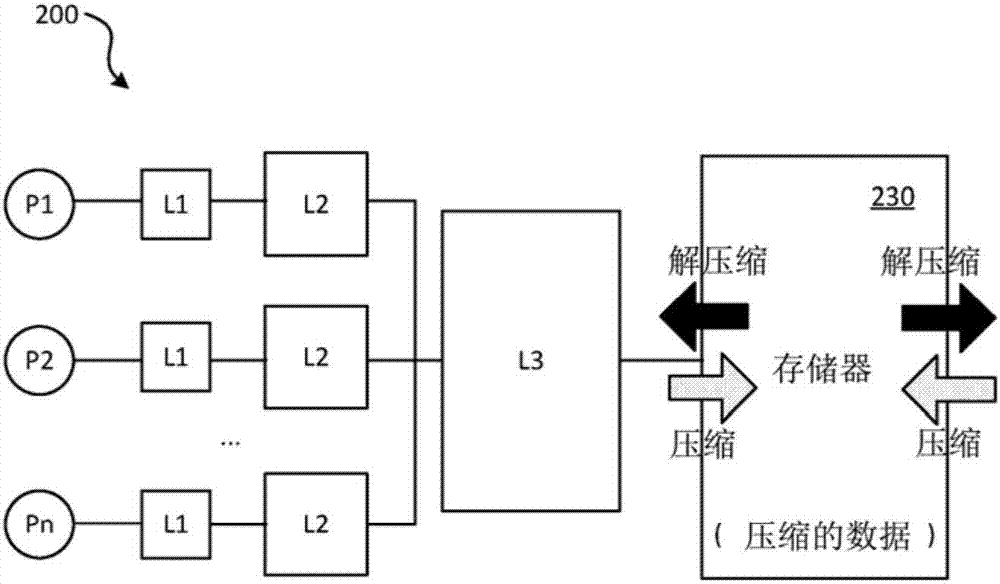
数据压缩可以以不同的方式应用到计算机系统。图2描绘了例如像图1的系统100的计算机系统的示例200,其中数据在存储器中(例如在这种计算机系统的主存储器中)被压缩。这意味着数据在通过如上所述的相应压缩操作而被保存在存储器中之前被压缩,并且数据在离开存储器时被解压缩。
如图3所示,在计算机系统的替代的示例300中,可以将数据压缩应用到高速缓存系统的l3高速缓存。类似于前面的示例,数据在被保存在高速缓存中之前需要被压缩,并且在数据离开高速缓存(例如,到其他高速缓存级(l2)或到数据未压缩的存储器330)之前需要被解压缩。在替代的示例中,数据可以压缩保存在高速缓存分级结构的任何级中。
数据也可以仅在被计算机系统中的不同子系统之间传输时才被压缩。如图4所示,在计算机系统的可替代的示例400中,当使用相应的通信装置在l3高速缓存与存储器430之间传输数据时,数据被压缩。类似于前面的示例,在通信装置的端部需要存在压缩和解压缩,使得数据在传输之前被压缩,而在另一端被接收时被解压缩。
在计算机系统的替代的示例500中,可以将数据压缩应用到如图5所示的子系统的组合中。在该示例中,当数据被保存在存储器530中并且当它们被在存储器530与高速缓存分级结构520之间传输时,数据被压缩。这样,当数据被从高速缓存分级结构520移动到存储器530时,它们可以仅需要在被从l3高速缓存传输之前被压缩。可替代地,离开存储器530到高速缓存分级结构520的被压缩的数据,可以仅需要在它们被接收到将存储器530连接至高速缓存分级结构520的通信装置的另一端时被解压缩。关于将压缩应用到计算机系统中的不同子系统的组合,任何示例都是可能的,并且可以由本领域技术人员实现。
数据的传输也可以在通信网络内的两个任意点之间进行。图6示出了数据通信系统600的示例,该数据通信系统包括两点之间的通信网络605,其中数据由发射机610传输并由接收机620接收。在这种示例中,这些点可以是网络中的两个中间节点,或通信链路的源节点和目的节点,或这些情况的组合。数据压缩可以应用到如图7中的示例系统700所示的这种数据通信系统。在由发射机710将数据传送到通信网络705上之前需要应用压缩,而在由接收机720接收到之后需要应用解压缩。
存在各种不同的算法来实现数据压缩。数据压缩算法中的一个家族是统计压缩算法,其是数据相关的,并能提供接近熵的压缩效率,因为它们基于数据值的统计特性分配可变长度(也称为可变宽度)的代码:使用短码字对经常出现的数据值进行编码,使用长码字对不经常出现的数据值进行编码。哈夫曼编码是已知的统计压缩算法。
用于加速解压缩的哈夫曼编码的已知变型是范式哈夫曼编码。在此基础上,码字具有数字序列特性,意味着相同长度的码字是连续的整数。
现有技术中提出了基于范式哈夫曼的压缩和解压缩机构的示例。这种压缩和解压缩机构可以用于前述的示例中,以实现基于哈夫曼的压缩和解压缩。
在图9中示出了来自现有技术的实现哈夫曼编码(例如范式哈夫曼编码)的压缩器900的示例。其将未压缩的块作为输入,该未压缩的块是数据值的流,并且包括在贯穿本公开中通常表示为v1、v2、...、vn的一个或多个数据值。单元910可以是从未压缩的块输出的数据值的存储单元或提取器,其向可变长度编码单元920提供数据值。可变长度编码单元920包括代码表(ct)922和码字(cw)选择器928。ct922是一个表格,其可以被实施作为查找表(lut)或计算机高速缓冲存储器(任意关联性的),并且包含一个或多个条目,每个条目包括可以使用码字、cw925和码字长度(cl)927来压缩的值923。由于统计压缩算法使用的各种码字的集是可变长度的,所以当它们被保存在每个条目具有固定大小的宽度(码字925)的ct922中时,它们必须用零填充。码字长度927保持可变长度编码的实际长度(例如,以位为单位)。cw选择器928使用cl来识别实际的cw并丢弃填充的零。然后将编码的值级联到压缩值的其余部分,这些值完全形成压缩的块。在图11中示出了如前所述的压缩步骤之后的压缩方法的示例性流程图。
在图10中示出了来自现有技术的解压缩器1000的示例。范式哈夫曼解压缩可以分为两个步骤:码字检测和值恢复。每个步骤都是由一个单元来实现的:(1)码字检测单元(cdu)1020和(2)值恢复单元(vru)1030。cdu1020的目的是在压缩序列内找到有效码字(即压缩数据值的码字序列)。cdu1020包括一组比较器1022和优先级编码器1024。各个比较器1022a、b、c将各个潜在的位序列与已知的码字进行比较,该已知的码字在本示例中是首先分配的(在代码生成时)用于特定长度的范式哈夫曼码字(fcw)。在另一实施中,也可以使用最后分配的范式哈夫曼码字,但是在这种情况下,所进行的精确比较将是不同的。要比较的前述位序列的最大的大小可以保存在存储单元1010(例如实现为fifo或触发器)中,并且该最大的大小取决于在代码生成时决定的有效哈夫曼码字的最大长度(mcl)来确定比较器的数量和其最宽的最大宽度。然而,取决于这种解压缩器所选择的实现(例如,以软件或硬件),该最大长度可以在设计、编译、配置或运行时间上被限制为特定值。比较器1022的输出被插入类似结构1024的优先级编码器,该结构1024输出匹配码字长度(在图10中称为“匹配长度”)。在此基础上,从保存在存储单元1010中的位序列中提取检测到的有效码字(匹配码字);位序列被移位与“匹配长度”所定义的位置一样多的位置,并且空白部分被加载压缩序列的下一位,使得cdu1020可以确定下一个有效码字。
另一方面,值恢复单元(vru)1030包括偏移量表1034、减法器单元1036和解压缩查找表(delut)1038。来自先前步骤的“匹配长度”用于确定偏移值(保存在偏移表1034中),该偏移值必须减去(1036)在先前的步骤中确定的匹配码字的算术值,以得到delut1038的地址,在该地址中,对应于检测到的码字的原始数据值可以被从其中恢复并附加到保存在解压缩的块1040中的解压缩值的其余部分。重复解压缩器的操作,直到在输入压缩序列(在图10中被称为压缩的块)中被压缩存储的所有值被恢复为未压缩的数据值v1、v2、...、vn。
在图12中示出了如前所述的解压缩步骤之后的解压缩方法的示例性流程图。
前述压缩器和解压缩器可以使用可变长度的哈夫曼编码来快速有效地压缩数据块,并且可以使用可变长度的哈夫曼编码来解压缩数据块。也可以使用包括实现其他压缩和解压缩算法的压缩器和解压缩器的其他压缩方案,诸如基于增量、基于模式等等。所述方案的共同特征是它们对值局部性进行设计时间的假设以减少压缩或/和解压等待时间。一个常见的假设是,固定大小的数据类型(例如,32位整数)最好利用值局部性。然而,当要压缩的值包括语义上有意义的数据字段时,所述方案不能有效地压缩。本发明人已经认识到在数据压缩和解压缩技术领域存在改进的空间。
技术实现要素:
本发明的目的是提供数据压缩和解压缩技术领域的改进。
本公开大体上公开了用于当将压缩应用到例如计算机系统和/或数据通信系统中的高速缓存子系统和/或存储器子系统和/或数据传输子系统时,用于压缩数据值的数据集和解压缩数据值的数据集的方法、设备和系统。存在使用例如基于熵的可变长度编码——并且一个这种方式是使用哈夫曼编码的——在所述子系统中有效地压缩数据的各种方法、设备和系统。然而,当所述数据集的数据值包括多个语义上有意义的数据字段时,所述方法、设备和系统不能有效地压缩。因此,根据本发明公开的第一概念,不是将压缩作为整体应用到每个数据值,而代替的是应用到每个数据值的语义上有意义的至少一个数据字段,并且独立于所述数据值的其他语义上有意义的数据字段,以便生成压缩数据字段;然后压缩数据字段被包括在结果聚合压缩数据集中。根据第二个概念,共享相同语义含义的数据字段被分组在一起。由于可以并行使用多个压缩器和解压缩器,因此这可以加速压缩和解压缩,并且由于各种压缩算法用于压缩不同的组,因此提高了压缩效率。本发明的第三个概念是一种系统,其中在考虑首先将至少一个所述字段(例如尾数)进一步划分为两个或多个子字段以增加值局部性和提高可压缩性之后,方法和设备执行浮点数字的语义上有意义的数据字段的压缩和解压缩。所述浮点特定的压缩和解压缩方法和设备被定制为有效地压缩浮点值的子字段并进一步减少压缩和解压缩等待时间,这对于在计算机系统和/或通信网络中的高速缓存子系统和/或存储器子系统和/或数据传输子系统的性能是很关键的,同时避免了由于元数据而增加的区域开销。
本发明的第一方面是一种用于将未压缩数据集压缩成压缩数据集的数据压缩设备,所述未压缩数据集包括多个数据值。数据压缩设备包括分离器,该分离器被配置为将数据集中的各个数据值划分为多个语义上有意义的数据字段。数据压缩设备还包括压缩器,该压缩器包括一个或多个压缩单元,其中所述压缩单元中的第一压缩单元被配置为对于每个数据值的语义上有意义的数据字段中的至少一个数据字段,将第一数据压缩方案独立于该数据值的其他语义上有意义的数据字段而应用到该数据字段以生成压缩数据字段。数据压缩设备还包括聚合器,该聚合器被配置为将压缩数据字段包括在结果聚合压缩数据集中以生成压缩数据集。数据压缩设备通过允许在数据字段级而不是数据值级利用值局部性来提供改进的数据压缩。
本发明的第二方面是一种用于将未压缩数据集压缩成压缩数据集的数据压缩方法,所述未压缩数据集包括多个数据值。数据压缩方法包括:对于数据集中的每个数据值,将数据值划分为多个语义上有意义的数据字段;对于每个数据值的至少一个语义上有意义的数据字段,将第一数据压缩方案独立于该数据值的其他语义上有意义的数据字段而应用到该数据字段以生成压缩数据字段;并且将压缩数据字段包括在结果聚合压缩数据集中,以生成压缩数据集。数据压缩方法通过允许在数据字段级而不是数据值级利用值局部性来提供改进的数据压缩。
本发明的第三方面是一种包括代码指令的计算机程序产品,所述代码指令在由处理设备加载和执行时引起执行根据上述第二方面的方法。
本发明的第四方面是一种包括被配置为执行根据上述第二方面的方法的逻辑电路的设备。
本发明的第五方面是一种用于将压缩数据集解压缩为解压缩数据集的数据解压缩设备,所述压缩数据集表示数据值,每个该数据值具有多个语义上有意义的数据字段,该数据字段中的至少一个字段已独立于其他语义上有意义的数据字段而被压缩。数据解压缩设备包括解压缩器,该解压缩器包括一个或多个解压缩单元,其中,所述解压缩单元中的第一解压缩单元被配置为将用于每个数据值的所述至少一个压缩数据字段的第一数据解压缩方案应用到该压缩数据字段以生成解压缩数据字段。数据解压缩设备包括被配置为通过将包括解压缩数据集的结果数据值中的每个解压缩数据字段来生成解压缩数据集的机构。
本发明的第六方面是一种用于将压缩数据集解压缩为解压缩数据集的数据解压缩方法,所述压缩数据集表示每个具有多个语义上有意义数据字段的每一个的数据值,该数据字段中的至少一个已独立于其他语义上有意义的数据字段而被压缩。数据解压缩方法包括:对于每个数据值的所述至少一个压缩数据字段,将第一数据解压缩方案应用到该压缩数据字段以生成解压缩数据字段;以及通过包括解压缩数据集的结果数据值中的每个解压缩数据字段来生成解压缩数据集。
本发明的第七方面是一种包括代码指令的计算机程序产品,所述代码指令在由处理设备加载和执行时引起执行根据上述第六方面的方法。
本发明的第八方面是一种包括被配置为执行根据上述第六方面的方法的逻辑电路的设备。
本发明的第九方面是包括根据上述第一方面的一个或多个存储器、数据压缩设备和根据上述第五方面的数据解压缩设备的系统。
所公开的实施例的其他方面、目标、特征和优点将从以下详细公开内容、所附的从属权利要求以及附图中显现。一般而言,除非在本文中另有明确定义,否则权利要求中所使用的所有术语根据其在本技术领域中的普通含义进行解释。
除非另有明确说明,否则所有对“元件、设备、部件、装置、步骤等”的引用将被公开地解释为指代元件、设备、部件、装置、步骤等中的至少一个实例。除非明确说明,否则本文公开的任何方法的步骤不必按照所公开的确切顺序来执行。
附图说明
参考以下附图来描述背景技术的示例以及发明方面的实施例:
图1示出了包括n个处理核心的计算机系统的框图,每个处理核心连接至三级高速缓存分级结构和主存储器。
图2示出了图1的框图,其中主存储器以压缩形式保存数据。
图3示出了图1的框图,其中l3高速缓存以压缩形式保存数据。其他缓存级也可以以压缩形式保存数据。
图4示出了图1的框图,其中数据在通信装置中被压缩(例如当在存储器与高速缓存分级结构之间被传输时)。
图5示出了图1的框图,其中可以将压缩应用到主存储器以及应用到连接存储器与高速缓存分级结构的链路。通常,可以将压缩应用到像高速缓存分级结构、传输装置(例如连接存储器与高速缓存子系统的链路)和主存储器的部件的任何组合。
图6示出了连接通信网络中的两点的数据传送链路的框图。这些点可以是网络中的两个中间节点或者通信链路的源节点和目标节点或这些情况的组合。
图7示出了图6的数据传送链路的框图。其中传输的数据是压缩形式的,因此它们可能需要在发射机中压缩并在接收机中解压缩。
图8在左侧示出了未压缩的数据值块,并且在右侧示出了压缩形式的相同的块,该块使用利用哈夫曼编码已经生成的可变长度的编码。所有的未压缩的块的数据值被相应的哈夫曼码字替换。
图9示出了用于压缩(或编码)如图8所示的使用哈夫曼编码的块的压缩器。
图10示出了用于解码(或解压缩)使用范式哈夫曼编码压缩的块的解压缩器。
图11示出了用于压缩使用可变长度编码(例如哈夫曼)的块的方法的示例性流程图。
图12示出了用于解压缩使用可变长度编码(例如范式哈夫曼)压缩的压缩的块的解压缩方法的示例性流程图。
图13示出了包括多个64位双精度浮点值的数据集,其中根据ieee-754标准每个值还包括三个语义位字段(符号、指数和尾数)。
图14示出了包括某个数据类型的多个值的数据集,其中根据数据结构格式每个值还包括3个已知类型的3个语义位字段。
图15示出了首先将所述位字段划分为三组,然后压缩图14的数据集的所有值的三个语义位字段的示例数据压缩设备的框图。
图16示出了可以由图15中的数据压缩设备的实施例使用的语义位字段分类器方法的示例性流程图。
图17示出了解压缩图14的数据集的所有值的压缩语义位字段,然后重建初始数据集的示例数据解压缩设备的框图。
图18示出了可以由17中的数据压缩设备的实施例使用的初始数据集重构方法的示例性流程图。
图19示出了包括各种数据类型的多个值的数据值的块。
图20示出了将数据集的浮点值分为四个子字段的示例数据压缩设备的框图,其中三个子字段基于根据ieee-754标准的语义位字段;由于揭示了更高的值局部性,因此其中一个子字段(即尾数)进一步分为两个更多的子字段:尾数高和尾数低。该数据压缩设备压缩指数、尾数高和尾数低。
图21示出了以加速解压缩的方式解压缩四个压缩子字段组中的三个子字段组的示例数据解压缩设备的框图。
图22a示出了根据本发明的总体数据压缩设备。
图22b示出了图22中的总体数据压缩设备的变体。
图23示出了根据本发明的总体数据压缩方法。
图24示出了根据本发明的总体数据解压缩设备。
图25示出了根据本发明的总体数据解压缩方法。
图26示出了根据本发明的包括数据压缩设备和数据解压缩设备的总体系统。
具体实施方式
本申请公开了用于当将压缩应用到计算机系统和/或数据通信系统中的高速缓存子系统和/或存储器子系统和/或数据传输时,压缩一个或多个数据值的数据集和解压缩一个或多个数据值的数据集的方法、设备和系统。每个所述数据集包含一个或多个确定数据类型的数据值,并且数据集可以是任意大小。对于数据集中的每个数据值,数据值包括多个语义上有意义的数据字段。在这些公开的方法、设备和系统中,不是将压缩作为整体应用到数据值,而代替的是应用到每个数据值的语义上有意义的数据字段中的至少一个数据字段,并且独立于数据值的其他语义上有意义的数据字段中的数据字段以便生成压缩数据字段;然后将压缩数据字段包括在结果聚合压缩数据集中。所应用的压缩可以是无损或有损的,而各种压缩方法、设备和系统可以用来压缩各种语义上有意义的数据字段。
不是所有的语义上有意义的数据字段都必须经受数据压缩。有利地,考虑语义上有意义的数据字段的值局部性,并且在表现出高度值局部性的语义上有意义的数据字段中的一个(或多个)字段,经受适于基于值局部性而产生良好可压缩性的数据压缩。
数据类型可以是整型、浮点型、字符型、字符串型等,也可以是代码指令,但是它还可以是诸如数据结构类型、对象类型等的抽象数据类型。一些数据类型的数据可以遵循特定格式(例如视频格式、音频格式),或特定标准(例如遵循ascii格式的字符、遵循ieee-754标准的浮点数据等)。图13的示例数据集包括4个遵循根据ieee-754标准格式的双精度浮点值。根据所述标准,浮点数据值包括三个数据字段:符号、指数和尾数(有效数)。所述位字段的宽度基于所选的精度而变化。在图13的示例实施例中,所选择的精度是双精度(64位),符号位字段是1位,指数位字段是11位,尾数位字段是52位。可以决定将压缩应用在例如数据集的值的符号和指数位字段中,这是因为与尾数位字段相比,它们通常表现出较高的值局部性。也可以考虑遵循其他标准的浮点值的替代数据集。然而包括遵循某个标准的某些类型的值的又一个替代数据集是由unicode标准(例如utf-8、utf-16)限定的文本类型。
图14中示出了另一个替代数据集并且包括8个值。这些值中的每一个都是数据结构(即抽象数据类型),并且包括三个字段:短整型位字段(16位)、字符型位字段(8位)和布尔型位字段。类似于前面的实施例,基于表现出的值局部性,可以选择将压缩应用到所有字段或它们的子集。
通过将共享来自不同数据值的相同语义含义的压缩数据字段分组在一起可以有利地得到结果聚合压缩数据集,使得压缩数据字段在聚合压缩数据集中呈现彼此相邻。因为不同的数据字段可以用不同的方法、设备和系统来压缩,因此可以使用不同的编码,从而需要不同的压缩器和解压缩器,这可以提高压缩效率、加速压缩,特别是解压缩,以及显著减少元数据和整体复杂度。特别地,如果相同数据字段的压缩数据呈现彼此相邻,则它们将全部使用相同的解压缩器而不需要在各种解压缩器之间切换,或者不需要使一个解压缩器的设计复杂化以便能够解压缩多个位字段。此外,可以并行使用不同压缩字段的解压缩器来增加解压缩吞吐量。
现在将接着描述本申请中的数据压缩设备和数据解压缩设备的某些实施例,所述数据压缩设备被配置为根据上文操作。该描述将参考图15-图21来进行。然后,本申请将呈现总体发明方面,其概括在图15-图21所示的特定实施例中,将参考图22-26来描述这些总体发明方面。
图15中示出了数据压缩设备1500的实施例的框图,该数据压缩设备通过将共享相同语义含义的未压缩数据集1510的数据字段分组在一起,然后将不同组中的各个分组单独压缩,来压缩图14的示例数据集。数据压缩设备1500包括语义位字段分类器1510形式的分离器;不同组的存储单元1525;一个或多个数据压缩单元1530(在本申请中也称为压缩器或压缩器引擎)以及以连结单元1540的形式的聚合器。首先将初始数据集插入到语义位字段分类器1520中。分类器1520还将数据集的值包含的语义位字段的数量,以及不同语义位字段的大小作为输入1522、1523。分类器1520的工作在图16的示例方法中进一步描述。分类器1520的输出是保存在存储单元1525中的多个未压缩位字段组。在该特定实施例中,有三组位字段:1)(整)短字段组(存储在存储单元1525a中);2)字符型字段组(存储在存储单元1525b中);和3)布尔型字段组(存储在存储单元1525c中)。不同的位字段组将被多个压缩器1530压缩。这些压缩器中的每一个对特定组进行编码,并且可以实现适合于所述组的特定压缩算法(即方案):因此,压缩器s1530a压缩短整型位字段组;压缩器c1530b压缩字符型字段组;压缩器b1530c压缩布尔型字段组。通过猜测类型或通过提供关于如稍后将描述的类型的信息,所述压缩器运行无损或有损压缩算法(方案),或者可以基于所述位字段的目标明确类型而在各种压缩算法中相应地配置所述压缩器。
在一些实施例中,如果语义上有意义的数据字段的值局部性被认为对于该组位字段或其他原因不适合于产生有效压缩,则压缩器1530a、1530b、1530c可以被配置为通过相应地设置输入参数1532a、1532b、1532c(在图15中被示为“cmp?”)而完全不压缩所有特定组。最后,压缩的位字段组由连结单元1540级联,该连结单元1540形成如图15底部所示的压缩数据集1590。因此,压缩数据集1590包括数据类型短整型的数据字段的压缩组1542a;随后是数据类型字符型的数据字段的压缩组1542b;并且最后是数据类型布尔型的数据字段的压缩组1542c,其由各自的压缩单元(压缩器)1530a、1530b、1530c应用的压缩方案产生。
图16中示出了语义位字段分类器方法的示例性流程图,该分类器方法由图15的数据压缩设备1500的实施例的分类器单元1520实现。该方法以包括b值的数据集、语义位字段的大小(以位为单位)以及每个值包含的语义位字段的数目(即a)作为输入。该方法的输出是将语义位字段组组织为尺寸为axb的二维数组。对于数据集中的每个值i,从所述值中迭代地提取每个位字段j。由于语义位字段的大小是预先已知的,因此每个值的位字段提取可以是顺序的,或者可以是并行的。类似地,数据集的多个值的位字段提取可以是顺序的,或者也可以是并行的。假设所述分类器方法用于图14的分组图1的数据集的值的语义位字段,则语义位字段a的数量为3(短整型、字符型和布尔型),数据集值b的数量为8。根据目标实现,本领域技术人员可以以软件或逻辑电路来实现所述分类器方法。本领域技术人员也可以实现所述方法的替代实施例。
可以在包括语义位字段的数据集是数据结构的示例实施例中,从应用二进制或编程语言中提取包括语义位字段的数量和大小(例如图15中的1522、1523)并且被提取分类器(例如图15中的1520)所需要的信息。然后,如果所述示例实施例是应用到计算机系统中的高速缓存子系统和/或存储器子系统和/或数据传输子系统的压缩器,则所述提取的信息经由(但不限于)系统软件到强调的硬件的专用命令被提供给分类器。在替代实施例中,在将压缩器应用到对应于媒体数据的数据(例如遵循示例视频格式的数据)的情况下,所述信息可由媒体中心提供。在又一个替代实施例中,在将所述压缩器应用到遵循特定标准或格式(例如根据ieee-754标准的浮点数据)的数据的情况下,可以基于所述使用的标准来生成所述信息。对于其中所述压缩器引擎可以配置有多个压缩算法中的一个算法的实施例,可以以类似于对语义位字段的数字和大小所做的方式,将关于所述语义位字段的数据类型的信息提供给压缩器,来为不同组的位字段相应地配置压缩器引擎(例如图15中的1530)。本领域技术人员可以实现替代的方式来为其他实施例提供或生成这种信息。
图17中示出了解压缩示例压缩数据集1710的数据解压缩设备1700的实施例的框图。可以由图15的数据压缩设备1500已产生的压缩数据集1710,包括数据类型短整型的数据字段的压缩组1712a,随后是数据类型字符型的数据字段的压缩组1712b,最后是数据类型布尔型的数据字段的压缩组1712c。数据解压缩设备1700包括多个解压缩单元1730(在本申请中也被称为解压缩器或解压缩器引擎);解压缩的位字段组的存储单元1735,以及被配置为生成解压缩数据集1790的重构器单元1740的形式的机构。首先,压缩数据字段的各个组1712a、1712b、1712c中的每一个组由各自的解压缩单元1730a、1730b、1730c解压缩,其中每一个压缩单元被配置为解压缩组1712a、1712b、1712c中相应的一个组。不同组的解压缩可以顺序或并行地进行。然而,并行解压缩要求已知不同压缩字段组的边界:或者保存为元数据,或者因为编码大小是固定的。之后,如图17的底部所示,将每组解压缩字段保存在存储单元1735中,并且然后由生成数据值的解压缩数据集1790的重构器单元1740处理所有的组。
图18中示出了初始数据集重构方法的示例性流程图,该初始数据集重构方法由图17的数据解压缩设备1700的重构单元1740实现。该方法将由图17的解压缩器1710解压缩的、被组织为大小为a×b的二维数组语义位字段组,以及每个值所包含的语义位字段的数量(即a)作为输入。方法的输出是一个包含b值的数据集。从每个位字段组的第一个条目开始,迭代到所有位字段组的第二、第三个条目等,通过将各个组的语义位字段放置在由位字段的聚合大小所指示的值的形式的各自的位的位置,而将各个组的语义位字段组合在一起,从而形成各个值。例如,假设重构方法用于恢复图14的数据集,通过将位字段“短整型”、“字符型”和“布尔型”分别放置在0-15、16-23以及24-31位的位置,其中假定位置0对应于该值的开始(左侧),并且31对应于该值的结束(右侧),以从左到右将它们组合在一起,从而形成数据集的每个数据值。每个值连结到数据集中其余的重构值。由于语义位字段的大小是预先已知的,因此每个值的位字段的组合可以是顺序的,或者可以是并行的。类似地,数据集的多个值的值重构可以是顺序的,也可以是并行的。根据目标实现,本领域技术人员可以以软件或逻辑电路来实现所述分类器方法。本领域技术人员也可以实现所述方法的替代实施例。
图15的压缩器和图17的解压缩器的前述实施例分别具有三个压缩器单元1530和三个解压缩器单元1710。因此,它们可以支持多达三个不同的字段组的压缩,然而,本领域技术人员可以实现替代实施例,以具有可以配置的更多数量的可用压缩器/解压缩器。除非目标系统是包括可重新配置的逻辑的系统(例如fpga),否则压缩器的所述数量必须限制为由所述压缩器和解压缩器支持的位字段的最大数量;因此,可以在运行时配置可变数量的压缩器/解压缩器。
图19中示出了数据值的块,其与图13和图14的数据集相反,包括一个或多个具有各种类型的数据值,并且每个数据值不一定包括多个语义上有意义的数据字段或共享相同语义的多个数据字段。图19中示出的所述块的示例包括6个值:三个是整型;一个值是类似图14的实施例中的数据结构;而另外两个值是双精度浮点值(64位),所述每个值都包括根据ieee-754标准的三个语义位字段(符号、指数和尾数)。可以或者通过将数据值块视为数据值的特定数据集;或者通过在每个数据集中包括包含相同语义位字段的那些数据值而通过在所述数据值块内形成一个或多个数据值的数据集,来通过本公开的方法、设备和系统来压缩所述数据值块。可以保持未压缩或使用传统的压缩方法、设备和系统来压缩其余的数据值。
在图1中所示的计算机系统的实施例中,当数据块被保存在高速缓存分级结构中时,数据值块可以代替地被称为1)高速缓存行、高速缓存集、高速缓存扇区或类似物,当数据块被保存在存储器中或被传输到这种计算机系统内的通信装置中时,数据值块可以代替地被称为2)高速缓存行、高速缓存集、高速缓存扇区或类似物。另一方面,在图6所示的数据通信系统内的传输链路的实施例中,数据块也可以被称为分组、报文(flit),有效载荷,数据头等。
如果数据集的值的特定数据类型根据任何可用的标准有利地是浮点数字,其中语义上有意义的数据字段可以包括这种浮点数字的符号、指数和尾数,则数据字段的一个或多个可以被进一步细分,例如通过将尾数划分为两个子字段:尾数高和尾数低。压缩尾数是具有挑战性的;其最低有效位表现出很高的不规则性(即,尾数的最低有效位中的位为1(或0)的概率为50%),如在图13中可观察到的,这是因为它们即使在所表示的实数变化微小时也会快速变化。另一方面,由于尾数是浮点数字的主要部分,因此压缩尾数将最终显著提高浮点压缩率。由于这个原因,将尾数划分为两个或多个子字段可以揭示一些子字段表现出值局部性,因此尾数可以是部分可压缩的。例如,在图13的数据集实施例中,尾数的20个最高有效位(即,x4d86e)对于所述数据集的4个尾数位字段中的3个是相同的;类似地,尾数的16个最高有效位(即,x4d86)对于所述数据集的所有尾数位字段是相同的。因此,通过将尾数划分为例如两个子字段而从尾数中提取出这16或20位,可以提高尾数的整体可压缩性。
图20和图21中分别示出了示例系统的数据压缩设备2000和数据解压缩设备2100的实施例,其执行浮点数字的语义上有意义的数据字段的压缩和解压缩,并且考虑将尾数进一步划分为两个或多个子字段。所述示例系统被称为fp-h。
图20中示出了fp-h的数据压缩设备2000的一个实施例的框图。数据压缩设备2000包括存储单元和/或提取单元2015;语义位字段分类器2020形式的分离器;用于语义位字段组的存储单元2025;压缩单元(压缩器)2030,其被配置为压缩所述各种语义上有意义的数据字段;以及连结单元2040形式的聚合器。存储/提取单元2015用于将未压缩数据集2010的浮点值保存和/或提取到分类器2020,该分类器2020以与图16的示例分类器类似的方式构建。在该示例压缩器中的数据集包括多个根据ieee-754标准格式化的8个双精度浮点值。替代的压缩器实施例可以支持其他浮点精度、其他浮点表示法(例如十进制)或其他标准,而数据集可以具有任意大小。
按以下步骤进行压缩:
(步骤-1)输入未压缩数据集2010的每个浮点值被分类器2020划分为四个子字段,然后将它们组织在一起并存储在存储单元2025中。这四个子字段是:符号(s)、指数(被称为e或exp)、尾数高(mh)和尾数低(ml);可以基于分离尾数时显示的值局部性程度,来静态或动态地确定尾数字段被划分的mh和ml子字段的大小。
(步骤-2)通过相应的压缩器2030,将每个子字段独立地并且与其余的子字段并行地压缩。尽管可以使用其他无损或有损压缩算法,但是示例fp-h系统采用诸如哈夫曼编码的可变长度的统计压缩,因为其可以积极利用其所表现出的高值局部性。因此,图9的示例压缩器可以用于实现每个压缩器2030。
(步骤-3)fp-h数据压缩设备2000选择试图压缩除符号之外的所有数据子字段,因为其构成了浮点值的一小部分。然而,替代实施例也可以针对符号压缩。如图20的底部所示,由连结单元2040以一定顺序(即,符号、压缩ml、压缩exp、压缩mh)将组织在组中的压缩子字段连结在一起,以形成压缩数据集2090。字段分组不是必要的,但是是有益的;当使用各种可变长度的编码时,这种重构压缩数据集2090的数据的方式可以显著地加速解压,而不需要保持元数据来限定各种压缩子字段的边界。由于采用可变长度的统计压缩来压缩尾数子字段和指数,所以在采样(或训练)阶段期间使用示例值频率表(vft)结构(或值表)来监视每个子字段的值频率统计:e-vft2034a、mh-vft2034b、ml-vft2034c。共同拥有的专利申请us13/897,385描述了所述vt和所述训练阶段的示例实施例。
图21中示出了fp-h的数据解压缩设备2100的实施例的框图。数据解压缩设备2100包括存储单元2105,该存储单元保留输入压缩数据集2110;多个解压缩单元,该解压缩单元包括尾数子字段解压缩器2130a和2130b与指数解压缩器2130c;以及存储单元2145,该存储单元保留解压缩和重构数据集2190。压缩数据集的边界是已知的:如图21所示,开始由“x”表示,而结束由“y”表示。如之前在压缩器实施例中所述,不存在用于保留关于可变长度的压缩mh和指数(e)子字段的边界和确切偏移/大小的信息的元数据,因为元数据增加了区域开销,因此他们减少了压缩的收益。因此,对这些子字段中的每一个进行解压缩必须等待前一个子字段的解压缩完成:首先解压缩ml,然后解压缩e,最后解压缩mh。当未压缩符号位组被放置在压缩数据集(即x)的开始处时,压缩ml子字段组被放置在压缩数据组2110的第8位的位置。由于可变长度的哈夫曼编码的解压缩本质上是连续的,因此这可以显著增加解压缩等待时间。
图21的fp-h数据解压缩设备2100替换为使用两阶段的解压缩过程:在阶段i中,压缩mh和ml子字段组被并行地解压缩,然后在阶段ii中,压缩指数组被解压缩。通过将压缩mh子字段组以相反的顺序保存在压缩数据集的末尾(‘y’指向压缩mh组的第一位),来允许mh和ml的并行解压缩。在解压缩器2130a和2130b各自解压缩8个值之后,mh和ml的解压缩完成。此时,压缩指数子字段的边界变为已知,因此通过解压缩器2130c(阶段ii)可以立即开始解压缩。图10的基于范式哈夫曼的解压缩器可以用于实现解压缩器2130a、2130b和2130c中的每一个。图21的数据解压缩设备2100可以将解压缩子字段(ml、mh)和解压缩数据字段(e)直接放置在保存在存储单元2145中的完全解压缩数据集的相应位的位置中,使得当最后的指数字段被解压缩时,解压缩数据集2190已准备好。因此,解压缩器2130a、2130b和2130c实现生成解压缩数据集2190的机构,而没有任何针对此的单独机构。替代实施例可以替代地被设计成与图17中的一个类似,如本领域技术人员所容易实现的,使用单独的重构器单元来实现生成解压缩数据集2190的机构。
在fp-h系统的一个替代实施例中,可以选择使ml组不被压缩,因为由于尾数的最低有效位的不规则性而导致局部性的期望值较低。这可以通过仅需要阶段i(mh和指数的并行解压缩)来加速解压缩。
观察到数据集的值的指数字段表现出较高的值局部性:时间(即经常出现相同的值),以及空间局部性(即值在空间上接近,意味着它们彼此相比具有较小的值差异)。因此,可以实现fp-h系统的替代实施例,该实施例尝试使用更轻量级的压缩算法(例如增量编码)来压缩指数。与fp-h系统的上述实施例相比,这可以在压缩效率方面具有小的不利影响;然而,相比于在第二阶段基于哈夫曼的压缩指数固有的顺序解压缩,解压缩可以显著加速。
在fp-h系统的替代实施例中,当数据集的值的指数字段可以是典型的集群时,可以使用基于增量的压缩器来压缩指数(尾数子字段如前所述被压缩和解压缩)。有趣的是,基于增量的解压缩仅需要很少的周期;这可以减少在替代的fp-h解压缩器实施例中的第二解压阶段的等待时间。该替代实施例系统被称为fp-h-增量。特别是当数据集是示例计算机系统和/或数据通信系统中的示例高速缓存子系统和/或示例存储器子系统和/或示例数据传输子系统中的块时,各个所述数据集经常出现两个指数簇。因此需要两个底数以便能够表示两个指数簇。因此,压缩指数组包括三个部分:两个底数(每个11位,类似于双精度浮点值的未压缩指数的宽度)、8个增量(宽度为2位)和一个掩码(8×1位)。掩码限定在解压期间要使用哪个底数,而增量宽度可以是任意大小,取决于指数簇所要覆盖的范围目标。图20的fp-h数据压缩设备2000的压缩器2030a和图21的fp-h数据解压缩设备2100的解压缩器2130a,可以由本领域技术人员通过协调如在第21届国际并行架构和编译技术会议论文集(pact'12)中发表的论文gennadypekhimenko,vivekseshadri,onurmutlu,phillipb.gibbons,michaela.kozch和toddc.mowry,2012,《基于增量即时压缩:用于片上高速缓存的实际数据压缩》中所公开的相应的压缩器和解压缩器来实现。
本文公开的数据压缩和解压缩设备的压缩和解压缩单元(即压缩器和解压缩器)可以被本领域技术人员流水线化和/或并行化,以增加处理吞吐量和/或减少压缩和解压缩等待时间。
所公开的发明及其实施例的方法和框图可以优选地在运行时由包括在处理器设备/处理器芯片或存储器设备/存储器芯片中或与其相关联的任何逻辑电路来执行。因此,其它发明方面包括被配置为执行上述方法和框图的逻辑电路、处理器设备/处理器芯片和存储器设备/存储器芯片。
应当注意的是,除了明确公开的实施例以外的其他实施例,在相应的发明范围内同样是可能的。
对于在本公开中参考的任何实体(例如数据集、数据类型、数据值、数据字段、数据块,高速缓存块、高速缓存行、数据组块等)的数据大小通常没有特别的限制。
现在参考图22-图26,现在将描述在图15-图21中示出的具体实施例所概括的总体发明方面。将使用相同的附图标记;在图22a-图26的附图之一中具有格式xxnn的附图标记一般表示在图22-图26或图15-图21的任何其他附图中相同或至少对应的元件yynn。
图22a公开了用于将未压缩数据集2210压缩成压缩数据集2290的数据压缩设备2200。未压缩数据集2210包括多个数据值2212a-m。数据压缩设备2200包括分离器2220,其被配置为将数据集中的每个数据值划分为多个语义上有意义的数据字段2214a-n。分离器2220例如可以是上述分类器单元1520、2020中的任何一种。
数据压缩设备2200还包括压缩器2230,该压缩器2230包括一个或多个压缩单元2230a、2230b,其中压缩单元中的第一压缩单元2230a被配置为对于每个数据值的语义上有意义的字段中的至少一个2214a,将第一数据压缩方案独立于语义上有意义的数据字段中的其他语义上有意义的数据字段2214b、2214n而应用到该数据字段2214a,以生成压缩数据字段2232a。数据压缩单元2230例如可以是前述数据压缩单元或压缩器1530、2030中的任何一个。
此外数据压缩设备2200还包括聚合器2240,该聚合器2240被配置为包括在结果聚合压缩数据集中的压缩数据字段以生成压缩数据集2290。聚合器2240可以例如是任何前述的连结单元1540、2040。
数据压缩设备2200通过允许在数据字段级而不是数据值级利用值局部性来提供改进的数据压缩。
有利地,数据压缩设备2200的压缩器2230包括第二压缩单元2230b,该第二压缩单元2230b被配置为应用与第一压缩单元2230a的第一数据压缩方案不同的第二数据压缩方案(压缩器2230还可以很好地包括被配置为应用第三数据压缩方案等的第三压缩单元2230c)。
有利地,从图15-图21中的上述实施例的描述中清楚的是,第一和第二数据压缩方案中的至少一个是无损数据压缩方案,诸如例如以下任何无损数据压缩方案:统计压缩(诸如例如哈夫曼压缩、范式哈夫曼压缩、算术编码)、增量编码、基于字典(dictionary)的压缩、基于模式的压缩、基于有效性的压缩、空数据集压缩。
然而,在替代实施例中,第一和第二数据压缩方案中的至少一个而是有损数据压缩方案。
第一压缩单元2230a的第一数据压缩方案可以适于利用语义上有意义的数据字段2214a-n中的至少一个2214a的值局部性,以产生比如果已将第一数据压缩方案整体应用到整个数据值2212a时更好的压缩性。
在数据压缩设备2200的一些实施例中,语义上有意义的数据字段2214a-n中的至少一个不被压缩单元2230a、2230b中的任何压缩单元压缩,而是未被压缩并且被聚合器2240以未压缩形式包括在所产生的压缩数据集2290中。这例如是图20的实施例中的符号(s)数据字段的情况。
在数据压缩设备2200的一些实施例中,聚合器2240被配置为保持来自所产生的压缩数据集2290中的未压缩数据集2210的数据字段2214a-n的原始顺序。
然而,优选地,例如对于如图15的实施例那样,数据压缩设备2200的分离器2220被配置为将来自数据值2212a-m的各自的第一语义上有意义的数据字段2214a组成第一数据字段组(例如图15中的组1525a),并且将第一数据字段组提供给第一压缩单元2230a(例如压缩器s1530a),而分离器2220被配置为将来自数据值2212a-m的各自的第二语义上有意义的数据字段2214b组成第二数据字段组(例如组1525b),并且将第二数据字段组提供给第二压缩单元2230b(例如压缩器c1530b)。聚合器2240(例如连结单元1540)被配置为形成来自第一压缩单元的压缩数据字段2232a的第一组(例如1542a),形成来自第二压缩单元的压缩数据字段2232b的第二组(例如1542b),并且在所产生的压缩数据集2290中将第一组与第二组连结。第一数据字段组(例如1525a)中的各自的第一语义上有意义的数据字段2214a可以共享相同的语义含义,并且第二数据字段组(例如1525b)中的第二语义上有意义的数据字段2214b可以共享相同的语义含义。这种相同的语义含义可以例如是第一或第二数据字段组中的相应的第一或第二语义上有意义的数据字段2214a、2214b(例如1525a、1525b)具有相同的数据类型,或具有相同数据类型的相同子字段。
由于可以并行使用多个压缩器(和解压缩器)并且通过使用不同的压缩算法来压缩不同的组来提高压缩效率,这种实施例是特别有利的,因为它可以加速压缩(和解压缩)。因此,第一和第二压缩单元2230a-b(例如1530a、1530b)可以被配置为当分别压缩第一和第二数据字段组(例如1525a、1525b)中的数据字段时并行操作。
在数据压缩设备2200的实施例中,未压缩数据集2210的数据值2212a-m是标准数据类型的,诸如例如以下任何标准数据类型:整型、浮点型、字符型、字符串型。其也可以是遵循特定标准的代码指令或数据。
可替代地,在数据压缩设备2200的实施例中,未压缩数据集2210的数据值2212a-m是抽象数据类型的,诸如例如数据结构类型或对象类型,或者遵循诸如视频格式、音频格式等的特定格式的数据。当抽象数据类型是数据结构类型时,其可以例如包括上述一个或多个标准数据类型的组合,以及布尔型和指针。
如图22b中的2230a-b所示,数据压缩设备2200的第一和第二压缩单元2230a-b可以是可控制的,以确定以下中的至少一个:各自的压缩单元是否要通过应用其相应的数据压缩方案来执行数据压缩;以及用于各自的数据压缩方案的数据压缩算法,该数据压缩算法可从多个数据压缩算法中选择。这种控制的示例在图15中的1532a-1532c处可见。第一和第二压缩单元2230a-b的控制可以基于语义上有意义的数据字段2214a-n的相应数据类型。
如图22b中的2222处所示,数据压缩设备2200的分离器2220可以被配置为接收关于语义上有意义的数据字段2214a-n的数量和大小的结构化数据字段信息。例如,这种结构化数据字段信息可以是图15中的实施例的信息1522、1523的形式。
在一些有利的实施例中,数据压缩设备2200被用于压缩浮点数。例如在图20的实施例中就是这种情况。因此,未压缩数据集2210(例如2010)的数据值2212a-m是浮点数,并且语义上有意义的数据字段2214a-n可以是符号(s)、指数(e)和尾数(mh、ml)。指数(e)和尾数(mh、ml)数据字段可以由压缩器2230(例如2030)的各自的压缩单元2230a-c(例如2030a-c)来压缩。在一些可替代的(实施例)中,类似在图20中,符号(s)数据字段未被压缩,并且不被压缩器2230(例如2030)的任何压缩单元2230a-c(例如2030a-c)压缩。
为了进一步利用数据局部性,数据压缩设备2200的分离器2220可以被配置为进一步将语义上有意义的数据字段2214a-n中的至少一个划分为两个或更多个子字段,其中压缩器单元中的至少一个被配置为对于子字段中的至少一个,将数据压缩方案独立于其他子字段而应用到该子字段,以生成压缩子字段,其中聚合器2240被配置为包括在结果聚合压缩数据集中地压缩子字段,以生成压缩数据集2290。
同样,例如在图20的实施例中就是这种情况。子字段可以是尾数高(mh)和尾数低(ml),其中尾数高(mh)和尾数低(ml)子字段中的至少一个独立于尾数高和尾数低子字段中的另一个而被压缩。有利地,通过统计压缩来压缩尾数数据字段的至少尾数高(mh)子字段,其中通过统计压缩、增量编码或另一压缩方案中的一个来压缩指数(e)数据字段。
在诸如例如图20的有益的实施例中,尾数数据字段的尾数高(mh)和尾数低(ml)子字段与指数(e)数据字段全部通过压缩器2230(2030)各自的压缩单元(2030c、2030b、2030)来压缩,并且聚合器2240(例如2040)被配置为通过在其中保存按以下顺序生成压缩数据集2290(2090):
i.包括符号(s)数据字段的第一组(2042-1),
ii.然后是包括尾数数据字段的压缩尾数低(ml)子字段的第二组(2042-2);
iii.然后是包括压缩指数(e)数据字段的第三组(2042-3);以及
iv.然后是包括与未压缩数据集(2010)相比顺序相反的尾数数据字段的压缩尾数高(mh)子字段的第四组(2042-4)。
该布置将允许有效的解压缩。
图23中示出了总体发明的数据压缩方法。除了和/或作为图23中的2310-2330所公开的功能的细化之外,该总体发明的数据压缩方法可以具有如上所述的数据压缩设备2200的各种实施例的任何或全部功能特征。
图24公开了用于将压缩数据集2410解压缩成解压缩数据集2490的数据解压缩设备2400。压缩数据集2410表示数据值2482,每个数据值具有多个语义上有意义的数据字段2484,该数据字段2432a中的至少一个已被压缩,独立于其他语义上有意义的数据字段。例如,解压缩数据集2490可以由上述的任何数据压缩设备2200、1500、2000生成。数据解压缩设备2400包括解压缩器2430,该解压缩器2430包括一个或多个解压缩单元2430a、2430b。解压缩单元中的第一解压缩单元2430a被配置为对于每个数据值的至少一个压缩数据字段2432a,将第一数据解压缩方案应用到该压缩数据字段2432a,以生成解压缩数据字段(2484a)。数据解压缩单元2430例如可以是前述数据解压缩单元或解压缩器1730、2130a-2130c中的任一个。
数据解压缩设备2400包括机构2440,该机构2440被配置为通过包括在解压缩数据集2490的结果数据值(2482a)中的每个解压缩数据字段2484a,来生成解压缩数据集2490。
有利地,数据解压缩设备2400的解压缩器2430包括第二压缩单元2430b,该第二压缩单元2430b被配置为应用与第一解压缩单元2430a的第一数据解压缩方案不同的第二数据解压缩方案(解压缩器2430可以很好地包括第三压缩单元2430c,该第三压缩单元被配置为应用第三数据解压缩方案等)。
有利地,从以上描述中清楚的是,所述第一和第二数据解压缩方案中的至少一个是无损数据解压缩方案。然而,在替代实施例中,所述第一和第二数据解压缩方案中的至少一个是有损数据解压缩方案。
在数据解压缩设备2400的一些实施例中,压缩数据集2410的数据字段2484中的至少一个不被压缩,并且通过被配置为生成解压缩数据集的机构2440而以未压缩形式被包括在解压缩数据集2490的结果数据值2482中。
在数据解压缩设备2400的一些实施例中,机构2440被配置为保持来自所生成的解压缩数据集2490中的压缩数据集2410的压缩数据字段2432a、2432b的顺序。
有利地,例如对于图17的实施例的情况,解压缩器2430(例如1730)的解压缩单元2430a(例如1730a-1730c)被配置为从压缩数据集2410(例如1710)接收压缩数据字段的各自的组(例如1712a-1712c),解压缩相应组的压缩数据字段,并向机构2440(例如1740)提供解压缩数据字段的相应组(例如1735a-1735c)。机构2440(例如1740)被配置为对于如由各自的解压缩单元2430a、2430b(例如1730a-1730c)解压缩的解压缩数据字段的组(例如1735a-1735c),在所产生的解压缩数据集2490中重构压缩之前的原始数据集的数据值中数据字段的原始顺序。
由于可以并行使用多个解压缩器并且通过使用不同的解压缩算法来解压缩不同的组来提高压缩效率,这种实施例是特别有利的,因为它可以加速解压缩。因此,解压缩器2430(例如1730)的解压缩单元2430a、2430b(例如1730a-1730c)可以被配置为并行操作。
在数据解压缩设备2400的实施例中,解压缩数据集2490的数据值2482是标准数据类型。可替代地,解压缩数据集2490的数据值2482可以是抽象数据类型的。
解压缩器2430(例如1730)的解压缩单元2430a、2430b(例如1730a-1730c)可以是可控制的,以确定以下中的至少一个:各自的解压缩单元是否要通过应用其相应的数据解压缩方案来执行数据解压缩;以及用于各自的数据解压缩方案的数据解压缩算法,该数据解压缩算法可从多个数据解压缩算法中选择。这种控制的示例在图17的1732a-1732c处可见。第一和第二解压缩单元2430a-b(例如1730a-1730c)的控制可以基于语义上有意义的数据字段2484的相应数据类型。
数据解压缩设备2400的机构2440可以被配置为接收关于语义上有意义的数据字段2484的数量和大小的结构化数据字段信息(例如,图17中的1742、1743)。
在一些有利的实施例中,数据解压缩设备2400被用于压缩浮点数。例如在图21的实施例中就是这种情况。因此,解压缩数据集2490的数据值2482是浮点数,并且语义上有意义的数据字段2484可以是符号(s)、指数(e)和尾数(mh、ml)。可以通过解压缩器2430的各自的解压缩单元2430a、2430b(例如2130a-2130c)来解压缩压缩数据集2410(例如2110)的压缩指数(e)和尾数(mh、ml)数据字段2432a、2432b。在一些可替代的(实施例)中,类似在图21中,压缩数据集2410(例如2110)的符号(s)数据字段未被压缩,并且不被解压缩器2430的任何解压缩单元2430a、2430b(例如2130a-2130c)解压缩。
如对于图20的数据压缩设备已描述的,压缩数据集2410可以包括语义上有意义的数据字段中的至少一个压缩子字段(mh、ml)。因此,如同图21的数据解压缩设备2100的情况,解压缩器单元2400(例如2130a、2130b)中的至少一个(例如2130a)可以被配置为将数据解压缩方案应用到所述至少一个子字段(ml)以生成解压缩子字段,并且机构2440(例如2130a)可以被配置为包括将在解压缩数据集2490的结果数据值中的解压缩子字段。
同样,例如在图21的实施例中就是这种情况。子字段可以是尾数高(mh)和尾数低(ml),其中尾数高(mh)和尾数低(ml)子字段中的至少一个独立于尾数高和尾数低子字段中的另一个而被解压缩。有利地,通过统计解压缩来解压缩尾数数据字段的至少尾数高(mh)子字段,并且其中通过统计解压缩、增量编码或另一解压缩方案中的一个来解压缩指数(e)数据字段。
在诸如例如图21的有益的实施例中,压缩数据集2210(例如2110)按以下顺序包括:
i.包括符号(s)数据字段的第一组,
ii.然后是包括尾数数据字段的压缩尾数低(ml)子字段的第二组,
iii.然后是包括压缩指数(e)数据字段的第三组;以及
iv.然后是包括与压缩前的原始数据集的数据值中的原始顺序相比顺序相反的尾数数据字段的压缩尾数高(mh)子字段的第四组。
对于该实施例,解压缩器2430可以具有两阶段的操作架构,其中:
·在第一阶段中,通过解压缩器2430的第一和第二解压缩单元(例如2130a、2130b)的统计解压缩来并行地解压缩尾数数据字段的尾数高(mh)和尾数低(ml)子字段,以及
·在第二阶段中,通过解压缩器2430的第三解压缩单元(例如2130c)的统计解压缩、增量解码或另一解压缩方案来解压缩指数(e)数据字段。
该布置将允许有效的解压缩。
有利地,第一、第二和第三解压缩单元(例如2130a、2130b、2130c)被配置为各自的解压缩尾数高(mh)和尾数低(ml)子字段与解压缩指数(e)数据字段直接放置在解压缩数据集2490(例如2190)中,从而实现所述机构2440并且消除了单独机构的需要(类似图17中的重构器单元1740)。
图25中示出了总体发明的数据解压缩方法。除了和/或作为对图25中的2510-2530所公开的功能的细化之外,该总体发明的数据解压缩方法可以具有如上所述的数据解压缩设备2400的各种实施例的任何或全部功能特征。
本文所公开的各个数据压缩设备可以例如以硬件来实现,例如为集成电路中的数字电路、专用设备(例如存储器控制器)、可编程处理设备(例如中央处理单元(cpu)或数字信号处理器(dsp))、现场可编程门阵列(fpga)或其他逻辑电路等。本文中所描述的各个数据压缩方法的功能性可以例如由被适当配置的相应数据压缩设备中的任一个来执行;或者通常由包括被配置为执行相应的数据压缩方法的逻辑电路(包括在例如处理器设备/处理器芯片或存储器设备/存储器芯片中或与其相关联)执行;或者可替代地通过包括在由通用处理设备(诸如cpu或dsp(例如图1-5的处理单元p1...pn中的任何一个)加载和执行时使得相应方法执行的代码指令的相应的计算机程序产品执行。
本文所公开的各个数据解压缩设备可以例如以硬件来实现,例如为集成电路中的数字电路、专用设备(例如存储器控制器)、可编程处理设备(例如中央处理单元(cpu)或数字信号处理器(dsp))、现场可编程门阵列(fpga)或其它逻辑电路等。本文中所描述的各个数据解压缩方法的功能性可以例如由被适当配置的相应数据解压缩设备中的任一个执行;或者通常由包括被配置为执行相应的数据解压缩方法的逻辑电路(包括在例如处理器设备/处理器芯片或存储器设备/存储器芯片中或与其相关联)执行;或者可替代地通过包括在由总体处理设备(诸如cpu或dsp(例如图1-5的处理单元p1...pn中的任何一个)加载和执行时使得相应方法执行的代码指令的相应的计算机程序产品执行。
图26示出了根据本发明的总体系统2600。该统包括一个或多个存储器2610、数据压缩设备2620(诸如例如数据压缩设备1500、2000、2200中的任何一个)和数据解压缩设备2630(诸如例如数据解压装置1700、2100、2400中的任一个)。有利地,系统2600是计算机系统(诸如图1-5的计算机系统100-500中的任何一个);并且所述一个或多个存储器2610是一个或多个高速缓冲存储器(诸如图1-5的高速缓冲存储器l1-l3中的任何一个)、一个或多个随机存取存储器(诸如图1-5的存储器130-530中的任一个)或者一个或多个次级存储器。可替代地,系统2600是数据通信系统(诸如图6-7的通信网络600、700),其中所述一个或多个存储器2610可以是与数据通信系统中的传送和接收节点相关联的数据缓冲器。(诸如图6-7的发射机610、710和接收机620、720)。
- 还没有人留言评论。精彩留言会获得点赞!