一种预编码为非规则码的Raptor码优化编码方法与流程
本发明涉及数字信息传输技术领域,具体涉及一种预编码为非规则码的raptor码优化编码方法。
背景技术:
信道编码领域经历了一个不断发展的过程,从简单的线性分组码到turbo码,再到现在的ldpc码、极化码和喷泉码。数字喷泉码是一种无码率的纠错码,其主要思想为:在发送端将原始数据分为任意数量k的编码分组,而接收方只要收到其中任意n个编码分组(n略大于k)就可以高概率恢复原始数据,而无需知道所接收到的分组具体是哪些,我们定义译码开销ε=n/k-1。
lt(lubytransform)码在2002年被提出,lt码编译码复杂度不高且编码采用随机编码方式,从而能够满足不同用户的需求和变化的信道条件。但lt码存在译码成功恢复原始数据所需的运算量与原始数据长度k无法满足线性关系等局限性。为了改善lt码的局限性,shakrollahi提出了一种性能更佳的数字喷泉码——raptor码。raptor码是一种级联码,从而有较高的译码效率。raptor码编码时首先进行预编码,一般情况下为ldpc编码,再对于预编码生成的中间码进行lt编码。译码时预编码的纠错能力可以辅助lt码译码,从而提高了译码性能,同时引入预编码也使得raptor码的编译码运算量与原始编码长度保持线性关系。
lt码的生成矩阵与ldpc码的校验矩阵都是稀疏矩阵,即矩阵中的“1”的数量远小于“0”的数目。lt码的生成矩阵中的每一列的“1”的数量表示输出一个码字所需要的输入数据包的数目,其数目称为输出节点的度(degree),度所服从的概率函数称为度分布函数(常用的有理想孤波分布、鲁棒孤波分布和泊松度分布等等),生成矩阵中“1”的位置表示选取哪些输入数据包进行异或操作。lt码编码过程就是根据度分布函数产生一个度数d,然后完全随机地从长度为k的输入数据包中选出其中d个进行异或运算产生一个输出码字,如此循环。故lt码的生成矩阵的结构直接影响lt码的性能,从而现有诸多研究都是针对lt码的度分布函数进行优化,包括lt码的输入节点度分布和输出节点度分布。如awgn信道下无速率码编译码算法研究(哈尔滨工业大学硕士论文于晓杰)针对度小的输入节点连接较少的输出节点,在译码过程中度小的输入节点获得来自输出节点的信息少,译码恢复概率降低。度小的输入节点是影响误码平层高的一个重要原因,针对这原因该文章提出了输入节点均匀化连接的编码优化算法。
然而,raptor码作为一种级联码,当预编码采用非规则的ldpc码时校验矩阵h列重是不同的,列重较大的中间码字连接的校验节点多,译码恢复概率大,而列重较小的中间码字连接的校验节点少,译码恢复概率小
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种预编码为非规则码的raptor码优化编码方法。
该方法针对raptor码预编码为非规则ldpc码时中间码字列重的不同,对不同列重的中间码字进行不同概率的选择进行lt编码,适当降低列重大的中间码字的选择概率。通过对不同码字的实验仿真表明,该改进的编码算法相比于原编码方法(lt编码随机选定中间码字)提升了0.3~1.5db的编码增益。
本发明采用如下技术方案:
一种预编码为非规则码的raptor码优化编码方法,包括如下步骤:
s1进行raptor码的预编码,所述预编码为非规则的ldpc编码,生成长度为k的中间码字;
s2对长度为k的中间码字进行lt编码,然后根据度函数分布产生一个度数d;
s3随机地从长度为k的中间码字中选出一个中间码字;
s4如果选取的中间码字所在比特位对应的ldpc校验矩阵h中列重大于或等于设定阈值α,则进入s5;否则,进入s6;
s5生成一个0-99的随机数,如果随机数大于或等于设定阈值β,则重新随机地从长度为k的中间码字中选出其中一个中间码字,进入s6;否则,直接进入s6;
s6:将目前所选取的中间码字作为当前输出码字的一个成员,若选取的中间码字数量达到d个,则将d个中间码字进行异或操作生成当前输出码字,返回s2,直到生成至少大于k的输出码字;若选取的中间码字数量小于d个,则返回s3。
所述阈值α大于等于10,且小于等于20;
阈值β大于等于40,且小于等于60。
所述s3及s5中选取的中间码字均是未被选取过的。
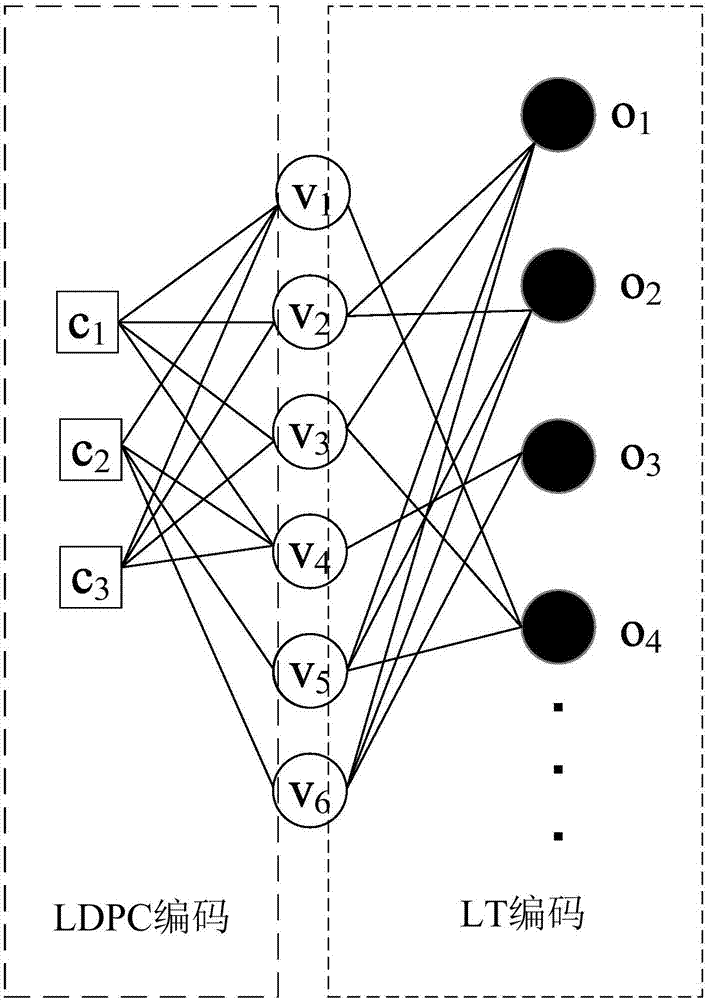
本发明的工作原理:一种预编码为非规则ldpc码的raptor码优化编码方法的工作原理可结合图2中的raptor码tanner图进行分析。raptor编码分为ldpc编码和lt编码,从而raptor码的tanner图是由ldpc校验节点,ldpc变量节点(中间码字节点)和输出节点之间连接而成。在ldpc编码的tanner图中,变量节点的度越大,即其对应在ldpc校验矩阵中的列重越大,该变量节点能有更多的校验节点参与校验,译码成功率高;同理,在lt编码的tanner图中,变量节点的度越大,其连接的输出节点数量越大,译码成功率也会更高。所以在进行lt编码时如果使得每个变量节点在raptor码的tanner图中总的度数相对趋于均匀化,将会增大整个码字的译码成功率。如图2所示,变量节点即中间节点v1和v4在ldpc码tanner图中的度数为较大的3,所以在进行lt编码时将减少对v1和v4的选择概率以减低其在raptor码tanner图中总的度数,如图2中v1和v4在lt码的tanner图中的度数被降低为1,通过本发明的方法使得raptor码中中间节点v1-v6的总度数均为4,这将有利于整个码字译码成功率的提高。
本发明相对于现有技术具有如下的优点:
(1)该编码算法相比于原编码方法(lt编码随机选定中间码字)提升了0.3~1.5db的编码增益。
(2)该发明所提出的方法简单有效,基本不增加计算复杂度,硬件实现方便。
附图说明
图1为本发明的工作流程图。
图2为本发明中raptor码tanner图的优化算法原理分析图。
图3为本发明的仿真验证图:
图4为本发明的仿真验证图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例
如图1及图2所示,一种预编码为非规则码的raptor码优化编码方法,包括如下步骤:
s1进行raptor码的预编码,所述预编码为非规则的ldpc编码,生成长度为k的中间码字;
s2对长度为k的中间码字进行lt编码,然后根据度函数分布产生一个度数d;
s3随机地从长度为k的中间码字中选出一个中间码字;
s4如果选取的中间码字所在比特位对应的ldpc校验矩阵h中列重大于或等于设定阈值α,本实施例阈值为10,则进入s5;否则,进入s6;
s5生成一个0-99的随机数,如果随机数大于或等于设定阈值β,本实施例阈值为40,则重新随机地从长度为k的中间码字中选出其中一个中间码字,进入s6;否则,直接进入s6;
s6:将目前所选取的中间码字作为当前输出码字的一个成员,若选取的中间码字数量达到d个,则将d个中间码字进行异或操作生成当前输出码字,返回s2,直到生成至少大于k的输出码字;若选取的中间码字数量小于d个,则返回s3。
所述的从长度为k的中间码字中选出一个中间码字中的中间码字是在生成当前输出码字所选取的中间码字中未被选取过的。
在高斯白噪声(awgn)信道及bpsk调制的情况下,采用raptor码的bp全局迭代译码算法。以码率为90%的(1000,900)非规则ldpc码、码率为90%的(5000,4500)非规则ldpc码作为raptor码预编码为例,对比原编码方法与本发明提出的一种预编码为非规则ldpc码的raptor码优化编码方法的性能。
(1)如图3所示:对于以码率为90%的(1000,900)非规则ldpc码作为raptor码预编码,编码后raptor码的码率设置为2/3,采用码率高的预编码,随着信噪比的增加,误块率迅速下降。在误块率为10-3附近,优化编码方法相比原编码方法有1.5db增益,性能得到大幅度提升。
(2)如图4所示:对于以码率为90%的(5000,4500)非规则ldpc码作为raptor码预编码,编码后raptor码的码率设置为2/3,对于预编码采用非规则的长码来说,raptor码的性能良好。在误块率为10-3附近,优化编码方法相比原编码方法有0.3db增益,性能提升比较明显。
从仿真结果可以看出,当采用长度不同的非规则ldpc码进行预编码时,该编码算法相比于原编码方法即lt编码随机选定中间码字提升了0.3~1.5db的编码增益,当采用短码作为预编码时性能提升较为明显。
本发明所提出的优化编码方法是针对预编码为非规则ldpc码的raptor码,在进行raptor码的lt编码时,对中间码字的选择做出了一定的限定,根据中间码字所在比特位对应的ldpc校验矩阵h中列重的不同进行选择。对不同列重的中间码字进行不同概率的选择进行lt编码,适当降低列重大的中间码字的选择概率。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!