一种可配置的并行BCH纠错编码方法与流程
本发明属于数据纠错领域,具体是一种参数可配置的并行化bch纠错编码方法及硬件实现。
背景技术:
bch码是一种能够有效纠正数据错误的编解码算法,通过编码计算将校验位附加在原有信息位上进行数据传输,接收者对获取的数据进行解码并在必要时纠正错误信息,该算法常用于纠正通信系统中的数据发送与接收的信道传输的误码,或者数据存储器进行数据写入和读回的过程中的数据纠错。bch码属于线性分组码,对随机发生的多个错误比特纠错能力强,特别是在短或中等码长下性能接近于理论值,并且构造方便、编码相对简单,适合硬件电路实现。
具体操作中,bch编码算法是对k位信息位m(x)经过生成多项式g(x)的变换产生r位校验位s(x),然后将信息位与校验位组合在一起形成n位码字c(x)的过程,其中n=k+r。为了便于描述和计算,在分组码中,每一个码字通常都表示为其关联的多项式形式。想要得到bch编码的码字多项式,关键就是求出校验多项式,其基本的计算过程为:首先将原始信息多项式:
m(x)=mk-1xk-1+mk-2xk-2+…+m2x2+m1x+m0mi∈{0,1}
乘以xn-k次幂变为xn-k×m(x);而后,xn-k×m(x)除以生成多项式
g(x)=grxr+gr-1xr-1+…+g2x2+g1x+g0gi∈{0,1}
得到商q(x)和余数多项式s(x),即
xn-k×m(x)=q(x)×g(x)+s(x),
最终得到码字多项式为:
c(x)=xn-k×m(x)+s(x)=c0+c1x+c2x2+…+cn-1xn-1。
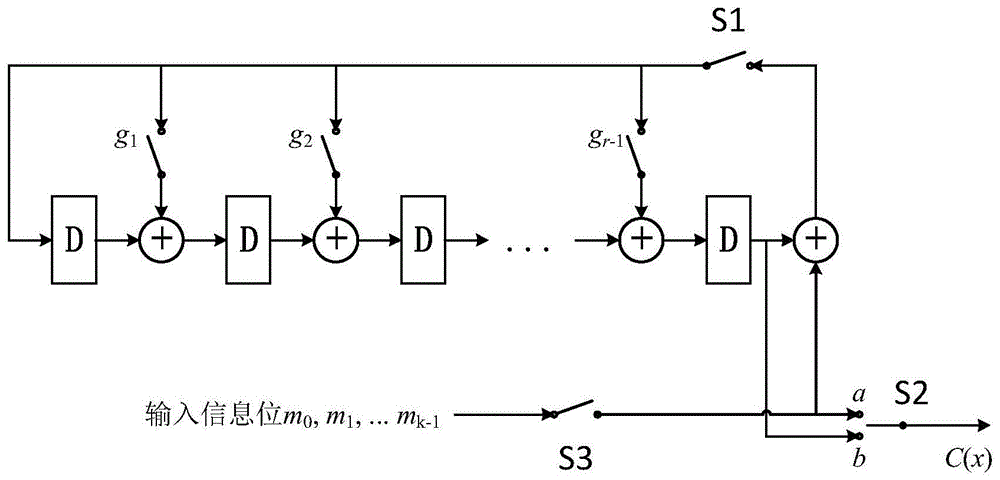
图1所示为根据现有技术实现的线性反馈移位寄存器示意图,如图1所示,现有的基于生成多项式计算编码校验位,是采用如图1所示的线性反馈移位寄存器(lfsr)的方式。令s1和s3闭合,s2打到a处,将原始数据m(x)逐一输入计算,同时输出给c(x);然后断开s1和s3,s2打到b处,再次输出给c(x)的n-k个数据即为编码校验位。
上述方法简单可行,但是只能逐位计算,因此计算效率很低,不能满足高速数据处理的要求。
技术实现要素:
本发明个的目的在于提供一种可配置的并行bch纠错编码方法,用于解决上述现有技术的问题。
本发明一种可配置的并行bch纠错编码方法,其中,包括:以p作为并行计算数据位宽,设定信息位k能够被p整除,即kmodp=0;二是p小于校验位长度r;
将原始信息多项式m(x)用以下方式分为p组,得到:
m(x)=m0(x)+m1(x)+...+mp-1(x),
其中
进一步计算:
其中
g(x)=grxr+gr-1xr-1+…+g2x2+g1x+g0gi∈{0,1}
编码校验位s(x)表示为:
整体计算通道分为p路输入,分别对应于m′i(x),i=0~p,对于每一路输入m′i(x),与对应系数gn和上一次的寄存器存储的结d进行模加运算,并将结果暂存在对应的寄存器中。
本编码方法实现了数据的并行化输入与输出,等比例的减少了处理流程的时间消耗,显著提高了编码处理效率。
附图说明
图1所示为根据现有技术实现的线性反馈移位寄存器示意图;
图2所示为s(x)的计算操作的实现示意图;
图3所示为计算框图变化后的结构图;
图4所示为本发明本方法的一流程图;
图5为本发明方法实现的具体实例的结构图。
具体实施方式
为使本发明的目的、内容、和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
本发明一种可配置的并行bch纠错编码方法包括:为了提升计算效率,实现并行计算,下面的算法以p作为并行计算数据位宽。首先给出2个设定:一是信息位k能够被p整除,即kmodp=0;二是p小于校验位长度r。
首先将原始信息多项式m(x)用以下方式分为p组,得到:
m(x)=m0(x)+m1(x)+...+mp-1(x),
其中
进一步计算:
其中
于是,编码校验位s(x)可以表示为:
图2所示为s(x)的计算操作的实现示意图,如2所示,整体计算通道分为p路输入,分别对应于m′i(x),i=0~p。对于每一路输入m′i(x)来说,与对应系数gn和上一次的寄存器存储的结果d进行模加运算,并将结果暂存在对应的寄存器d中。由于在每个有效的输入数据之间存在(p-1)个数据0的输入,进一步考虑把(p-1)个数据0整体处理,以减少计算次数。可以用图2方式实现s(x)的计算操作。
可以得到,当输入为数据0时,电路中的寄存器的下一状态d(t+1)和当前状态d(t)之间存在如下矩阵运算关系:
当输入为一组有效数据i(t)和连续(p-1)组数据0时,可以得到:
其中
图3所示为计算框图变化后的结构图,如图3所示,这样,上述计算流程中的gn系数阵列可以用
图4所示为本发明本方法的一流程图,如图4所示,本方法的流程具体包括:预处理和编码计算;
预处理包括:确定编码配置包括:信息位数k,校验位数r,码字长度n,纠错位数t以及本原多项式f(x);
计算参数:生成多项式g(x);生成多项式矩阵tg,校验计算矩阵tg(p-1);生成计算处理电路;
进行编码计算,包括:信息位数据并行输入;
计算校验位数据;
判断是否输入完毕,如果是,则输出信息位数据m(x),否则输出校验位数据s(x)。
图5为本发明方法实现的具体实例的结构图,如图5所示,本发明确定的编码方案配置为:以32byte数据作为输入信息,实际信息位为k=256bit=32x8bit,对其进行bch码编码处理,选择gf(29)作为有限域计算空间。设定纠错能力为t=4bit,可以得到校验位数为r=36bit,总码字长度为n=292bit,因此实现基于二进制bch(292,256,4)分组码。选择本原多项式为f(x)=1+x4+x9,实现p=8位并行处理。
计算相关参数得到生成多项式
g(x)=g36x36+g35x35+g34x34+g31x31+g30x30+g25x25+g23x23+g21x21+g20x20+g19x19+g16x16+g15x15+g11x11+g8x8+g7x7+g5x5+g0
,其中gn为有限域gf(29)中的对应元素。从而得到矩阵tg,进一步计算校验位计算矩阵得到:
基于上述预处理结果,编码计算的硬件电路实现的结构如图5,原始数据的256bit信息位以8位数据位宽并行逐次进入编码器模块,每个时钟周期计算矩阵对信息位进行处理,将结果存储在寄存器中,原始数据信息位同时也作为当前电路的输出。当所有信息位输入后,停止模除功能单元的计算,使用选择信号切换mux通道,将当前寄存器中的数据以8位并行方式逐次输出,即得到校验位数据。
与已有技术相比,本发明的有益效果在于:
本方法的结构简单,易于硬件实现,可以支持fpga或芯片化设计等不同实现方式。本结构实现架构化效果明显,可以通过参数的不同配置快速形成对应方案。本编码方法实现了数据的并行化输入与输出,等比例的减少了处理流程的时间消耗,显著提高了编码处理效率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!