获得级联码结构的装置和方法以及计算机程序产品与流程
本公开整体上涉及数据编码和译码技术,尤其涉及一种用于获得在数据编码和译码技术中使用的级联码结构的装置和方法,以及相应的计算机程序产品。
背景技术:
极化码以其用显式构造和计算高效的连续消除(successivecancellation,sc)、sc列表(sclist,scl)或循环冗余校验(cyclicredundancycheck,crc)辅助的scl译码算法的能力实现对称离散无记忆信道的容量而闻名。极化码的基本思想是将物理通信信道呈现为多个极化比特信道,并仅在几乎无噪声的那些比特信道上发送信息比特,即,随着码长的增加,那些比特信道的信道容量趋于1,而冻结比特则在信道容量随着码长增加而趋于0的其余(有噪声的)比特信道上发送。鉴于此,极化码的构造涉及基于信道容量找到这种无噪声信道。
然而,极化码存在一个问题,与极化码的长度有关,极化码的长度限于值p=2n,其中n是正整数。对于某些需要其他长度的极化码的实际应用,需要克服该限制。另一问题是,由于通常在译码操作中使用的极化译码器的连续特性,sc/scl/crc辅助的scl译码延迟仍然高。
已经提出了解决上述问题的不同方法,其中一种方法是将极化码与其他码级联。通过这种级联,将极化码用作内码,而所述其他码则充当外码。外码本身通常实现为极化码所属的线性块码。换言之,一种情况是可行的,甚至是实际的,其中内极化码与外极化码级联,从而提供级联码或多段码。尽管由于可以并行对内极化码进行译码,这种级联码可以减少译码延迟,但是外极化码的长度仍然受到限制,该长度仍然等于2的幂,因而限制了整个级联码的长度。此外,用于构造级联码的现有技术具有高复杂性,这使得它们不太实用甚至不切实际。
因此,需要一种解决方案,与现有技术相比,提供更好的长度适配性和减少的译码延迟以及更低的级联码构造复杂度。
技术实现要素:
提供本发明内容以通过简化的形式介绍一系列概念,这些概念将在下面的具体实施方式中进一步描述。本发明内容既不旨在标识本公开的关键特征或必要特征,也不旨在用于限制本公开的范围。
本公开的目的是提供一种用于获得用于构造任意长度的级联码的级联码结构的解决方案,具有减少译码延迟、低构造复杂度和更好的纠错性能的特征。
上述目的通过所附权利要求中的独立权利要求的特征来实现。根据从属权利要求、具体实施方式和附图,其他实施例和示例是显而易见的。
根据第一方面,提供了一种用于获得级联码结构的装置。所述装置包括至少一个处理器,以及与所述至少一个处理器耦合的存储器。所述存储器存储处理器可执行指令,所述处理器可执行指令由所述至少一个处理器执行时使所述至少一个处理器接收输入数据,所述输入数据包括:由外码和内极化码组成的级联码的期望长度m、表示信息比特的数量的级联码维度k和预定义的比特索引序列。此后,所述至少一个处理器被指示基于所述期望长度m,计算外码长度t和级联母码的长度n=t·2n,使得m≤n≤nmax,其中nmax是所述级联母码的最大长度,2n是极化码长度,n是正整数。接下来,所述至少一个处理器被指示基于所述长度t、n和m以及所述级联码维度k定义打孔或缩短模式,并根据所述预定义的比特索引序列和所述打孔或缩短模式,计算外码维度的向量。所述外码维度的向量的每个向量分量表示旨在用于每个外码的信息比特的部分ki,使得
在第一方面的一实施方式中,所述外码包括线性块码。在这种情况下,所述至少一个处理器还被配置为基于所述长度t、所述外码维度的向量和所述打孔或缩短模式确定所述外码的生成矩阵。此后,所述至少一个处理器基于所述长度t、n和m,所述外码维度的向量,所述打孔或缩短模式,所述外码的生成矩阵以及所述内极化码的生成矩阵,获得所述级联码结构。这在根据第一方面的装置的使用中提供了更多的灵活性,因为它允许使用不同类型的外码。
在第一方面的另一实施方式中,通过使用循环冗余校验(crc)比特设置所述级联码维度k。这在由根据第一方面的装置获得的级联码结构的使用中提供了更好的纠错性能和更多的灵活性。
在第一方面的另一实施方式中,所述输入数据还包括用于选择所述打孔或缩短模式的选择参数rpsthr,并且所述至少一个处理器被配置为当k/m≤rpsthr时,定义所述打孔模式,当k/m>rpsthr时,定义所述缩短模式。这允许通过针对低码率应用所述打孔模式和针对高码率应用所述缩短模式来提高根据第一方面的装置的使用效率。
在第一方面的另一实施方式中,所述至少一个处理器被配置为通过以下方式定义所述打孔或缩短模式:以大小为n/t×t的比特索引矩阵的形式,逐行写入所述级联母码的比特索引1至n;将所述比特索引矩阵划分为比特索引束集合,每个比特索引束包括所述比特索引矩阵的至少一行;根据束优先级对所述比特索引束集合进行排列;以所得向量的形式逐行重写所述比特索引矩阵;和使用所述所得向量的前(n-m)个向量分量作为所述打孔模式的比特索引,并使用所述所得向量的后(n-m)个向量分量作为所述缩短模式的比特索引。这样定义的打孔或缩短模式允许为级联码提供改进的速率匹配方案。
在第一方面的另一实施方式中,所述预定义的比特索引序列的长度
这允许快速有效地将信息比特分配给级联码的外码。
在第一方面的另一实施方式中,所述预定义的比特索引序列的长度
在第一方面的另一实施方式中,通过以下方式生成所述预定义的比特索引序列:将(1,2,…,nsequence)范围内的所有可能值k作为所述信息比特的数量,通过使用每个k计算所述外码维度的向量,更改所述外码维度的向量,以使得对于每对相邻值k和k-1,所述外码维度的向量彼此仅相差一个向量分量,和通过使用这种向量分量的索引,生成所述预定义的比特索引序列。这允许减少获得级联码结构所需的时间和系统资源。
在第一方面的另一实施方式中,通过以下方式计算每个k的外码维度的向量:估计由每个内极化码提供的极化比特信道的容量ci;如下计算旨在用于每个外码的所述信息比特的部分ki:
在第一方面的另一实施方式中,所述存储器还存储所述生成矩阵的数据库,所述生成矩阵的每一个与所述外码维度的相应部分ki和所述外码长度t相关联。在这种情况下,所述至少一个处理器还被配置为:通过访问所述数据库并选择与构成所述外码维度的向量的部分ki和所述外码长度t相关联的所述生成矩阵,确定所述外码的生成矩阵。这允许减少获得级联码结构所需的时间。
在第一方面的另一实施方式中,在缩短模式的情况下,所述至少一个处理器还被配置为:在每个所述生成矩阵中,将具有与缩短模式相对应的索引的所有列设置为零。大小减小的所述生成矩阵可以减少构造所述外码所需的时间和系统资源。
根据第二方面,提供了一种信息编码装置。该信息编码装置包括至少一个处理器,以及与所述至少一个处理器耦合的存储器。所述存储器存储处理器可执行指令,所述处理器可执行指令在由所述至少一个处理器执行时使所述至少一个处理器:接收k个信息比特的向量;接收根据第一方面的装置获得的所述级联码结构;以及利用所述级联码结构对k个信息比特的向量进行编码。这允许使编码过程更有效且资源占用更少,并提供更好的纠错性能。
根据第三方面,提供了一种信息译码装置。该信息译码装置包括至少一个处理器,以及与所述至少一个处理器耦合的存储器。所述存储器存储处理器可执行指令,所述处理器可执行指令由所述至少一个处理器执行时使所述至少一个处理器接收信道输出,所述信道输出包括使用根据第一方面的装置获得的所述级联码结构进行编码的信息比特;接收所述级联码结构本身;以及使用所述级联码结构从接收到的通道输出中检索信息比特。这允许使译码过程更有效且资源占用更少,并提供更好的纠错性能。
在第三方面的一实施方式中,所述至少一个处理器还被配置为通过并行译码内极化码来检索信息比特。这允许显著减少译码延迟。
根据第四方面,提供了一种用于获得级联码结构的方法。该方法从接收输入数据的步骤开始,所述输入数据包括:由外码和内极化码组成的级联码的期望长度m,表示信息比特的数量的级联码维度k和预定义的比特索引序列。该方法还包括以下步骤:基于期望的长度m,计算外码长度t和级联母码的长度n=t·2n,使得m≤n≤nmax,其中nmax是所述级联母码的最大长度,2n是极化码长度,n是正整数。该方法的后续步骤包括基于长度t、n和m以及级联码维度k定义打孔或缩短模式,并根据预定义的比特索引序列和所述打孔或缩短模式,计算外码维度的向量。所述外码维度的向量的每个向量分量表示旨在用于每个外码的信息比特的部分ki,使得
在第四方面的一实施方式中,所述外码包括线性块码。在这种情况下,该方法还包括以下步骤:基于所述长度t、所述外码维度的向量以及所述打孔或缩短模式来确定所述外码的生成矩阵。在这种情况下,获得所述级联码结构的步骤包括:基于所述长度t、n和m,所述外码维度的向量,所述打孔或缩短模式,所述外码的生成矩阵和所述内极化码的生成矩阵,获得所述级联码结构。这在根据第二方面的方法使用时提供了更多的灵活性,因为它允许使用不同类型的外码。
在第四方面的另一实施方式中,通过使用循环冗余校验(crc)比特设置所述级联码维度k。这在由根据第四方面的方法获得的所述级联码结构中提供了更好的纠错性能和更多的灵活性。
在第四方面的另一实施方式中,所述输入数据还包括用于选择打孔或缩短模式的选择参数rpsthr,并且所述方法还包括在k/m≤rpsthr时定义所述打孔模式,并且在k/m>rpsthr时定义所述缩短模式。这允许通过针对低码率应用所述打孔模式和针对高码率应用所述缩短模式来提高根据第四方面的方法的使用效率。
在第四方面的另一种实施方式中,该方法还包括以下步骤:通过以大小为n/t×t的比特索引矩阵的形式,逐行写入所述级联母码的比特索引1至n来定义打孔或缩短模式;将所述比特索引矩阵划分为比特索引束集合,每个比特索引束包括所述比特索引矩阵的至少一行;根据束优先级排列比特索引束集合;以所得向量的形式逐行重写所述比特索引矩阵;和将所述所得向量的前(n-m)个向量分量作为所述打孔模式的比特索引,并将所述所得向量的后(n-m)个向量分量作为所述缩短模式的比特索引。这样定义的打孔或缩短模式允许为级联码提供改进的速率匹配方案。
在第四方面的另一实施方式中,所述预定义的比特索引序列的长度
这允许快速有效地将信息比特分配给级联码的外码。
在第四方面的另一实施方式中,所述预定义的比特索引序列的长度
在第四方面的另一实施方式中,通过以下方式生成所述预定义的比特索引序列:将(1,2,…,nsequence)范围内的所有可能值k作为所述信息比特的数量,通过使用每个k计算所述外码维度的向量,更改所述外码维度的向量,以使得对于每对相邻值k和k-1,所述外码维度的向量彼此仅相差一个向量分量,和通过使用这种向量分量的索引生成所述预定义的比特索引序列。这允许减少获得级联码结构所需的时间和系统资源。
在第四方面的另一实施方式中,通过以下方法计算每个k的所述外码维度的向量:估计由每个内极化码提供的极化比特信道的容量ci;如下计算旨在用于所述每个外码的信息比特的部分ki:
在第四方面的另一实施方式中,该方法进一步包括存储生成矩阵的数据库,所述生成矩阵的每一个与外码维度的相应部分ki和所述外码长度t相关联。在这种情况下,该方法还包括:通过访问所述数据库并选择与构成所述外码维度的向量和外码长度t的部分ki相关联的生成矩阵,确定外码的生成矩阵。这允许减少获得级联码结构所需的时间。
在第四方面的另一实施方式中,该方法还包括,在缩短模式的情况下,在每个所述外码的生成矩阵中,将具有与该缩短模式相对应的索引的所有列设置为零。大小减小的生成矩阵允许减少构造外码所需的时间和系统资源。
根据第五方面,提供了一种信息编码方法。该信息编码方法包括以下步骤:接收k个信息比特的向量;接收通过根据第四方面的方法获得的所述级联码结构;以及通过使用所述级联码结构对k个信息比特的向量进行编码。这允许使编码过程更有效且资源占用更少,并提供更好的纠错性能。
根据第六方面,提供了一种信息译码方法。该信息译码方法包括以下步骤:接收包括通过使用根据第四方面的方法获得的所述级联码结构编码的信息比特的信道输出;接收所述级联码结构本身;以及通过使用所述级联码结构从接收到的通道输出中检索信息比特。这允许使译码过程更有效且资源占用更少,并提供更好的纠错性能。
在第六方面的一实施方式中,检索步骤包括并行地译码内极化码。这允许显着减少译码延迟。
根据第七方面,提供了一种计算机程序产品。该计算机程序产品包括存储计算机可执行指令的计算机可读存储介质,所述计算机可执行指令在由所述至少一个处理器执行时使所述至少一个处理器执行根据第四方面的方法的步骤。因此,根据第四方面的方法可以以计算机指令或码的形式体现,从而在其使用中提供灵活性。
通过阅读以下详细描述并查看附图,本公开的其他特征和优点对于本领域技术人员将是显而易见的。
附图说明
在下文中,将参考附图更详细地描述示例,其中:
图1示出了常规打孔操作的示意图;
图2示出了常规缩短操作的示意图;
图3示出了根据本公开的一个方面的用于获得级联码结构的装置的框图;
图4示出了根据本公开另一方面的用于获得级联码结构的方法的流程图;
图5展示了如何定义图4所示方法中使用的打孔或缩短模式;
图6a-6c展示了如何构造比特索引矩阵(图6a)并将比特索引矩阵划分为比特索引束(图6b和6c);
图7a-7b示出了束置换的示例;
图8示出了涉及在图4所示的方法中使用类型i的预定义比特索引序列的一个实施例;
图9示出了涉及在图4所示的方法中使用类型ii的预定义比特索引序列的另一实施例;
图10示出了用于计算类型i或类型ii的预定义比特索引序列的方法的流程图;
图11示出了用于计算级联码维度的所有可能值的外码维度的向量的方法的流程图;
图12示出了包括用于线性外码的生成矩阵示例性数据库;
图13示出了根据本发明的另一方面的信息编码方法的流程图;
图14示出了根据本发明的另一方面的信息译码方法的流程图;
图15表示在通信系统中使用图3所示的装置的一个示例;
图16-19展示了在基于通过使用图4所示的方法获得的级联码结构构造的级联码和通过使用现有技术的速率匹配方案所构造的常规极化码之间的码性能比较的结果。
具体实施方式
参考附图进一步详细地描述本公开的各种实施例。然而,本公开可以以许多其他形式实施,并且不应被解释为限于以下描述中公开的任何特定结构或功能。相反,提供这些实施例是为了使本公开的描述详细和完整。
根据本公开,对于本领域技术人员而言显而易见的是,本公开的范围涵盖本文公开披露的任何实施例,而不管该实施例是独立实现还是与本公开的任何其他实施例共同实施。例如,可以通过使用本文提供的任何数量的实施例来实现本文公开的装置和方法。此外,应当理解,可以使用所附权利要求中提出的一个或多个元件或步骤来实现本公开的任何实施例。
如本公开所使用的,术语“级联码”是指纠错码,其通过级联或组合两个或多个更简单的码而获得,以便以合理的复杂度实现良好的性能。更具体地说,级联码由内码和外码组成。此外,本公开意味着内码仅由极化码表示,而外码由任何类型的线性块纠错码(或简称为线性外码)或非线性外码(例如goethals、kerdock和preparata非线性码,带有明确定义的码字列表的非线性码等)表示。
极化码本身是线性外码的一种,它允许人们“重新分配”在表示感兴趣的物理通信信道的极化比特信道之间的错误概率。部分比特信道比其他比特信道具有较低的错误概率。具有较低错误概率的比特信道也被称为无噪声比特信道,然后被用于发送信息比特。其他比特信道仅用于传输冻结的比特,在某种意义上说,它们是“冻结的”。由于发送侧和接收侧都知道哪些比特信道被冻结,因此可以将任意值(例如二进制零)分配给每个冻结的比特信道。因此,极化码允许人们通过使用高可靠的比特信道来传递期望的信息比特,从而使错误的发生最小化。同时,极化码允许使用任何通过更改f表示为r=k/p的码率(其中p=k+f是极化码的长度,k是信息比特的数量,f是冻结比特的数量),它们的主要缺点是p总是等于2的幂,即,p=2n,其中n是正整数。换言之,通过使用极化码生成的比特信道被限制为2n的数量。为了克服该限制,已经提出了不同的方法,包括涉及使用所谓的打孔和缩短操作的方法。
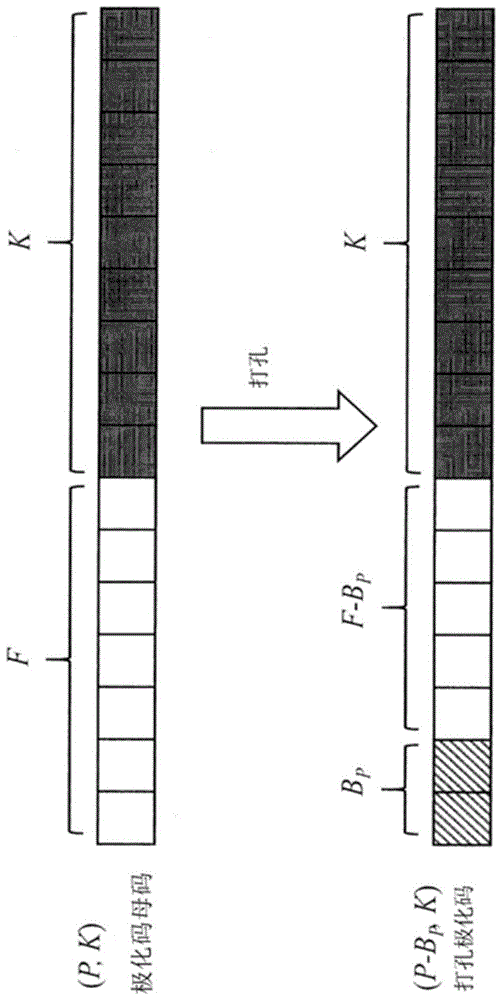
本文中的术语“打孔”以其在本领域中通常被接受的含义使用,并在图1中进行了示意性说明。根据定义,打孔操作是指从中通过擦除或丢弃一些冻结的比特来减小极化码的长度的技术。在这种情况下,要减小长度的极化码称为极化码母码(motherpolarcode)。相应地,上述长度p被认为是极化码母码的长度。换言之,极化码母码是长度为p=2n且维度为k(其表示跨无噪声极化信道分配的信息比特的总数)的(p,k)码。参考图1,信息比特k显示为灰色框,而冻结比特f(即,用于冻结或噪声极化信道的那些比特)显示为白框。此外,要擦除的比特被称为“打孔比特”(参见图1中的纹理框),并且用于所述擦除的方案被称为“打孔模式”。打孔模式定义了应该对哪一个或多个冻结比特f进行打孔,从而得出打孔比特的数量bp<p-k。打孔的比特没有从编码器侧发送到译码器侧,并且译码器在对极化码进行译码时仅将打孔的比特作为擦除比特来处理。
本文中术语“缩短”也以其在本领域中通常被接受的含义使用,并在图2中示意性地示出。根据定义,缩短操作是指切割极化码母码的长度的技术,但是现在通过将某些信息比特k限制为一个固定值,例如零。这样的信息比特被称为“缩短比特”(参见图2中的纹理框),并且用于所述限制的方案被称为“缩短模式”。因此,缩短模式定义了应该缩短信息比特k中的一个或多个,从而得到缩短比特的数量bs<k。类似地,缩短的比特没有从编码器侧发送到译码器侧,但是向译码器通知了缩短的比特的位置和值,并在对极化码进行译码时考虑它们。
因此,可以通过对极化码母码进行打孔或缩短操作来获得期望长度的极化码。这使得能够构造具有宽范围的长度减小(与极化码母码的长度p相比)的极化码,从而提高了码率(因为它与长度p成反比)。
同时,即使不是全部,现有技术解决方案也几乎不建议针对级联码使用打孔和缩短操作,以使其长度适合于不同的应用。此外,关于级联码的现有技术解决方案主要依赖于具有与p相似的外码长度的线性外码。换言之,现有技术解决方案使用的外码长度也等于2的幂。但是,如果外码长度不必等于2的幂,则级联码的长度n的可用范围要宽得多。例如,假设级联码的最大长度n限制为1024,那么在2的幂和任意情况下,外码长度的数量将不同,即:
n∈{64,128,256,512,1024}时,n=2t2n,其中2t是现有技术解决方案中使用的线性外码的有限长度,t是正整数,并且,
n∈{64,80,96,112,128,160,192,224,256,320,384,448,512,640,768,896,1024}时,n=t2n,t∈{5,6,7,8}是线性外码的任意长度。
因此,即使人们试图将对应于2的幂的情况的现有技术解决方案与现有的打孔或缩短模式相结合以提供码长适配,与任意情况相比,这种码长适配需要对更大数量的比特进行打孔或缩短,进而降低了纠错性能。而且,现有技术的解决方案还遭受高码构造复杂性的困扰,这需要采用许多系统资源。
还应注意,考虑到内码仅由常规的极化码表示,因此级联码的构造基本上要比外码的构造低。反过来,外码的构造是基于码率的选择,或者换言之,是基于信息比特的分配。因为码率和信息比特数量是相互依赖的参数,所以对于本领域技术人员这是显而易见的。分配给每个外码的信息比特数量也称为外码维度,并且所有外码的外码维度被组合为外码维度的向量。
本公开提供了一种用于获得级联码结构的解决方案,该解决方案能够构造与传统的极化码相比具有任意长度、低译码延迟和更好的纠错性能的级联码,并且本身简化了码的构造过程。
如本文所用,术语“级联码结构”是指构造期望长度m的级联码所需的参数的组合。通常,本文所讨论的级联码结构包括长度t、n和m,外码维度的向量,打孔或缩短模式以及内极化码的生成矩阵。在线性外码的情况下,除了上面列出的参数之外,级联码结构还包括外码的生成矩阵。如此定义的级联码结构可以在编码和译码过程中使用,这将在后面讨论。
图3示出了根据本公开的一方面的用于获得级联码结构的装置300的框图。如图3所示,装置300包括存储302和耦合到存储302的至少一个处理器304。存储302存储处理器可执行指令306,该处理器可执行指令306将由至少一个处理器304执行以通过适当的方式获得级联码结构。
存储302可以被实现为现代电子计算机中使用的非易失性或易失性存储器。作为示例,非易失性存储器可以包括只读存储器(read-onlymemory,rom)、铁电随机存取存储器(random-accessmemory,ram)、可编程rom(programmablerom,prom)、电可擦除prom(electricallyerasableprom,eeprom)、固态驱动器(solidstatedrive,ssd)、闪存、磁性磁盘存储器(例如硬盘驱动器和磁带)、光盘存储(例如cd、dvd和蓝光光盘)等。对于易失性存储器,其示例包括动态ram、同步dram(synchronousdram,sdram)、双数据速率sdram(doubledataratesdram,ddrsdram)、静态ram等。
处理器304可以被实现为中央处理器(centralprocessingunit,cpu)、通用处理器、单用途处理器、微控制器、微处理器、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(fieldprogrammablegatearray,fpga)、数字信号处理器(digitalsignalprocessor,dsp)、复杂的可编程逻辑设备等。值得注意的是,处理器304可被实现为前述的任何组合。作为示例,处理器304可以是两个或更多个cpu、通用处理器等的组合。
存储在存储302中的处理器可执行指令306可以被配置为使得处理器304执行本公开的各方面的计算机可执行代码。可以通过诸如java、c、c++、python等的一种或多种编程语言的任何组合来写入用于执行本公开的各方面的操作或步骤的计算机可执行代码。在一些示例中,计算机可执行代码可以是高级语言的形式或者是预编译的形式,并且由解释器(也预存储在存储302中)动态地生成。
图4示出了根据本公开的另一方面的用于获得级联码结构的方法400的流程图。当使处理器304执行处理器可执行指令306时,方法400旨在由装置300的处理器304执行。
特别地,方法400开始于步骤s402,其中处理器304接收以下输入数据:
级联码的期望长度m;
级联码维度k,它只是表示信息比特数的参数;和
预定义的比特索引序列。
接下来,方法400进到步骤s404,其中处理器304基于期望的长度m来计算外码长度t和级联母码(motherconcatenatedcode)的长度m。更具体地,n=t·2n,并且m≤n≤nmax,其中nmax是级联母码的最大长度(例如,取决于旨在使用级联码的通信或存储系统)。之后,方法400进到步骤s406,其中处理器304基于长度t、n和m以及级联码维度k来定义打孔或缩短模式。进一步,在步骤s408中,指示处理器304根据与外码长度t对应的预定义的比特索引序列和打孔或缩短模式,计算外码维度的向量。外码维度的向量的每个向量分量表示旨在用于每个外码的信息比特的部分ki,从而
在涉及使用线性外码的一个实施例中,方法400包括一个附加步骤(未示出),其中处理器304还基于长度t、外码维度的向量以及打孔或缩短模式来确定外码的生成矩阵。可以在步骤s408之后直接或在步骤s410之后执行附加步骤。在这种情况下,在步骤s412中,处理器304基于长度t、n和m,外码维度的向量,打孔或缩短模式,外码的生成矩阵,以及内极化码的生成矩阵来获得级联码结构。
在一个实施例中,可以通过考虑循环冗余校验(crc)比特来设置在方法200的步骤s402中接收的级联码维度k。换言之,级联码维度k可以指示信息比特加上crc比特的数量。
在一个实施例中,处理器304可以根据选择参数rpsthr来确定方法400的步骤s406中的打孔或缩短模式,该选择参数rpsthr仅仅是用于码率r的预定阈值。特别地,处理器304可以在方法400的步骤s402中或者接收选择参数rpsthr作为附加输入,或者在方法400的步骤s406中从预先存储有选择参数rpsthr的存储302中检索选择参数rpsthr。此外,可以将码率r或者取为k/n的比值,而称其为级联母码率,或者取为k/m,而称其为期望的(速率匹配)级联码率。可替代地,处理器304可以考虑级联母码率和速率匹配级联码率两者来定义打孔或缩短模式。使用上述给出的可选方案中的哪一个取决于特定的应用,但是对于本公开,比率k/m是更优选的。鉴于此,当码率r低于或等于选择参数rpsthr,即,k/m≤rpsthr时,可以定义打孔模式,而当码率r高于选择参数rpsthr,即,k/m>rpsthr时,定义缩短模式。还应当注意,选择参数rpsthr可以在相对宽的数值范围内变化,例如,在1/4至1/2之间。
关于步骤s406,可以根据图5所示的流程图来执行。特别地,用于执行步骤s406的流程图从子步骤s502开始,在该步骤中,处理器304以大小为n/t×t的比特索引矩阵的形式,逐行地写入级联母码的比特索引1至n,如图6a所示。此外,在子步骤s504中,处理器304将比特索引矩阵划分为一组比特索引束,每个比特索引束包括比特索引矩阵的至少一行。图6b和6c涉及优选实施例,其中比特索引束的数量由nb=n/(nrt)定义,其中nr=2q是连续行的数量,并且q∈{0,1,…,n}是正整数。显然,所有三个参数nb、nr和q都是相互关联的,只要知道其中一个,就有可能找到其余两个。作为示例,图6b示出了具有单个比特索引束的一个极限情况,该单个比特索引束包括比特索引矩阵的所有行(即,q=n,nr=2n,nb=n/(nrt)=1),并且图6c示出了具有一组单行比特索引束的另一极限情况(即,q=0,nr=20=1,nb=n/t=2n)。值得注意的是,本公开不限于以上优选实施例,并且一些其他实施例是可行的,其中根据特定的应用,每个比特索引束可以包括不同数量的连续或不连续的行。
回到图5,下一个子步骤s506恰好是置换子步骤,其中处理器304根据束优先级对比特索引束的集合进行置换。可以通过使用不同的优先级或可靠性序列来执行所述置换,例如,如r1-167209(“极化码设计和速率匹配”,huawei,3gpptsgranwg1meeting#86,瑞典哥德堡,2016年8月22日至26日)中讨论的极化权重(polarweight,pw)序列,以及3gppts38.212v15.0.0(“多路复用和信道编码”,2017年)中讨论的极化序列(polarsequence,ps)。简而言之,将优先级序列的项视为比特索引束的序列号,并且优先级序列内的项的出现或布置指示比特索引束的优先级。应该注意的是,在使用上述优先级序列的情况下,它们的长度应该减小到nb=n/(nrt)的长度,从而可以将减小的优先级序列用于所述置换。因此,处理器304根据某个优先级序列重新排列比特索引束,从而修改比特索引矩阵,如图7a和7b和中的箭头示意性所示。
此后,处理器304在子步骤s508中以所得向量的形式逐行重写比特索引矩阵。然后,处理器304在子步骤s510中使用所得向量的前(n-m)个向量分量作为打孔模式的比特索引(参见图7a中的阴影单元),以及所得向量的后(n-m)个向量分量作为缩短模式的比特索引(参见图7b中的阴影单元)。
下面通过使用数字示例来更详细地解释上述用于执行图5所示的步骤s406的流程图。值得注意的是,给出数值示例仅出于说明性目的,并且不应被解释为对本公开的任何限制。特别地,在数值示例中使用的不同码的长度在实践中很少或几乎不出现,而只是为了避免繁琐的计算而选择。因此,数值示例的目的是向读者解释如何处理步骤s406。现在回到数值示例,让我们做以下假设:
级联母码的最大长度:
所要构造的级联码的期望长度:m=1,
级联码维度:k=10,
比特索引束的数量:nb=4,并且
优先级序列由以下pw序列给出:spriority=(1,2,3,4,5,6,7,8)(这种spriority意味着在比特索引矩阵中仅要进行一个置换,即,第四和第五比特索引束应在比特索引矩阵中切换它们的位置)。
根据m,处理器304可以容易地得到长度n=20(因为它是最接近19的值),并且长度t=5(其跟从n=t·2n=20)。此外,处理器304可以通过去除索引大于4的所有项,即,
接下来,在子步骤s504中,处理器304将比特索引矩阵划分为nb=4个比特索引束。应用上面计算长度n、t和初始给定的nb的值,可以容易地发现每个比特索引束仅包括比特索引矩阵的一行:nr=n/(nbt)=1。因此,子步骤s504的结果是四个比特索引束,每个比特索引束包括一行比特索引矩阵。此后,处理器304应在子步骤s506中根据
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]。
最后,在子步骤s510中,处理器304选择前(n-m)=20-19=1个向量分量作为构成打孔模式的比特索引,或者选择后(n-m)=20-19=1个向量分量作为构成缩短模式的比特索引。再次应当注意的是,在任何其他数值示例中,打孔或缩短模式可以包括多于一个的比特索引。然后,在子步骤s510中获得的比特索引被用于减少预定义的比特索引序列,这将在后面讨论。
为了使处理器304可以理解,可以将图5所示的用于执行步骤s406的流程图写为以下伪代码(应当注意,在上面的数字示例中,索引以1开头,在伪代码1中以0开头):
伪代码1:打孔或缩短模式的定义。
输入:
-所需级联码的长度m,m≤n;
-参数nb,nr,或q;
-优先级序列spriority(pw或ps);
-打孔或缩短操作(例如,基于选择参数rpsthr);
输出:
-打孔或缩短模式(或换言之,打孔或缩短的比特的集合y)。
执行:
现在将参考图8和图9更详细地描述方法400的步骤s408。具体地,图8和图9分别示出了用于根据类型i或类型ii的预定义的比特索引序列来计算外码维度的向量的流程图。
更具体地说,类型i的预定义的比特索引序列的长度为
下面,通过使用与应用于图5所示的流程图相同的数值示例,进一步详细地说明图8所示的上述流程图。换言之,在涉及使用类型i的预定义比特索引序列的实施例中,将考虑相同的假设。仅有增加的两处在于选择参数rpsthr=0.5,从而意味着应该使用缩短模式,因为k/m=10/19≈0.53>0.5,并且类型i的预定义比特索引序列如下排列所示:
si=(40,39,35,38,30,20,37,34,29,36,33,19,28,25,32,18,15,27,10,24,17,31,14,26,23,9,16,13,22,8,5,12,7,4,21,11,3,6,2,1)
在这样的假设下,ki的数量(或者换言之,要使用的外码的数量)等于n/t=20/5=4。这意味着处理器304需要找到四个在外码中的每一个的部分ki,即,以[k1,k2,k3,k4]的形式找到外码维度的向量,其中(k1+k2+k3+k4)=k=10。接下来,让我们在步骤s408中应用上述所有假设。根据子步骤s802,处理器304首先从预定义的比特索引序列(包括40个项)中删除大于20的比特索引,从而得到以下缩减的比特索引序列:
之后,相同的子步骤s802涉及进一步去除与缩短模式相对应的比特索引。在该数值示例中,缩短模式包括一个比特索引,即,20,并且处理器304需要将其从
接下来,在子步骤s804中,处理器304初始化信息比特屏蔽向量u=[uj],其中每个向量分量uj=0并且j=1,2,…,20。换言之,信息比特屏蔽向量表示如下:
u=[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。
此外,在子步骤s806中,指示处理器304向每个向量分量uj赋一,该向量分量uj的索引出现在用(19,18,15、10,17,14,9,16,13,8)表示的缩减的比特索引序列的前k个比特索引中。即,信息比特屏蔽向量被转换为以下内容:
u=[0,0,0,0,0,0,0,1,1,1,1,0,1,1,1,1,1,1,1,0]。
最后,处理器304在子步骤s808中根据所述等式(1)计算外码的部分ki,从而以[0,3,3,4]的形式获得外码维度的向量。作为所述等式(1)的替代,处理器304可以首先被配置为将修改的向量u整形为大小为n/t×t的矩阵,并通过简单地通过计算矩阵的每一行中有多少个部分来计算部分ki,如下图所示:
为了使处理器304可以理解,可以将涉及在步骤s408中使用类型i的预定义比特索引序列的实施例写入为以下伪代码:
伪代码2:基于si计算外码维度的向量。
输入:
-长度n和t,已在伪代码1中获得的;
-级联码维度k;
-打孔或缩短模式(或伪代码1的输出);
-比特索引序列si。
输出:
-部分ki,i=1,…,n/t。
执行:
1.从码序列si中去除大于n的所有元素或比特索引,从而得到
2.从
3.初始化u=[uj],其中当
4.为所有向量分量uj赋一,其索引出现在
5.计算
对于类型ii的预定义比特索引序列,它具有相同的长度
其中,
之后,在子步骤s904中,处理器304使用n/t个零向量分量ki来初始化外码维度的向量,并且在子步骤s906中,处理器304每次当向量的索引出现在缩减的比特索引序列的前k个比特索引时,将每个向量分量ki增加一,如以下公式所示:
下面,通过使用与应用于图8所示的流程图相同的数值示例,来更详细地说明图9所示的上述流程图。换言之,在涉及使用类型ii的预定义比特索引序列的实施例中,将考虑相同的假设。唯一的区别在于,类型ii的预定义比特索引序列如下所示:
sii=(8,8,7,8,6,4,8,7,6,8,7,4,6,5,7,4,3,6,2,5,4,7,3,6,5,2,4,3,5,2,1,3,2,1,5,3,1,2,1,1)。
鉴于此,根据子步骤s902,处理器304首先去除大于n/t=4的比特索引,从而获得以下缩减的比特索引:
之后,在同一子步骤s902中,处理器304进一步去除与缩短模式相对应的比特索引。再次,使用缩短模式的原因是k/m=10/19≈0.53>0.5,并且缩短模式由一个比特索引20表示。值得注意的是,如果将等式(2)应用于
接下来,在子步骤s904中,处理器304使用n/t个零向量分量ki来初始化外码维度的向量,如下所示:
[k1,k2,k3,k4]=[0,0,0,0]。
然后,在子步骤s906中,指令处理器304在每次根据所述等式(3)在
[k1,k2,k3,k4]=[0,3,3,4]。
为了使处理器304可以理解,可以将涉及在步骤s408中使用类型ii的预定义比特索引序列的实施例写入为以下伪代码:
伪代码3:基于sii计算外码维度的向量。
输入:
-长度n和t,如在伪代码1中获得的;
-级联码维度k;
-打孔或缩短模式(或伪代码1的输出);
-比特索引序列sii。
输出:
-部分ki,i=1,…,n/t。
执行:
1.从码序列sii中删除所有大于n/t的元素或比特索引,得到
2.从
3.当
4.计算
在一个实施例中,类型i和类型ii的预定义比特索引序列都是预先计算的,即在开始方法400之前,是由装置300本身,即处理器304,或由远程设备计算的。在后一种情况下,装置300可以被配置为通过无线或有线连接,连接到远程设备,以便下载预定义的比特索引序列并将其存储在存储302中以供进一步使用。这允许在方法400的执行期间减少资源成本。然而,不管涉及装置300还是远程设备,预定义的比特索引序列的计算都可以参考如下讨论的图10被执行。
更具体地,图10示出了用于计算类型i或类型ii的预定义比特索引序列的方法1000。方法1000仅需要长度t和nmax作为输入数据,并且从步骤s1002开始,考虑到所有可能的值k=1,…,nmax,以进行进一步处理。在下一步骤s1004中,通过使用每个可能的值k来计算外码维度的向量。此后,在步骤s1006中,对所计算出的外码维度的向量进行更改,使得对于每对相邻值k和k-1,外码维度的向量彼此仅相差一个向量分量。在最后的步骤s1008中,通过使用这样的向量分量的索引来生成类型i或类型ii的预定义比特索引序列。
应当注意,方法1000是基于类型i和类型ii的预定义比特索引序列中的不同执行地计算。特别地,对于两种类型的比特索引序列,方法1000可以被写入为以下伪代码:
伪代码4:比特索引序列的构造。
输入:
-级联码的最大长度nmax,其中
-外码长度t。
输出:
-比特索引序列si或sii。
执行:
在一个实施例中,当需要保存存储302的存储器资源时,对于所有可能的值k=1,…nmax/2,可以通过使用伪代码4来构造长度为nmax/2的比特索引序列。可以在线计算比特索引序列的另一半,如下所示:
如果比特索引序列为si,则si(nmax-k+1)=nmax-si(k)+1,或者,
如果比特索引序列是sii,则sii(nmax-k+1)=nmax/t-sii(k)+1。
现在将参考图11说明在伪代码4的第6行中提到的所有k∈{1,…,nmax}的外码维度向量的计算。特别是,图11示出了方法1100的流程图,该方法1100针对每个可能的k计算外码维度的向量。首先,在步骤s1102中,处理器304通过使用以下之一来估计由每个内极化码提供的极化比特信道的容量ci:密度演化、近似公式或表格数据。所有这些技术从现有技术中是众所周知的(例如,参见s.tenbrink、g.kramer和a.ashikhmin的工作,在伪代码4中指出)。接下来,在步骤s1104中,处理器304计算用于每个外码的信息比特的部分ki,如下所示:
其中,
此后,在步骤s1106中,指示处理器304以获得用于外码的信息比特的所有部分ki的总和,并在步骤s1108中,确定该总和是否等于k。如果确定结果为“是”,则在步骤s1110中,处理器304通过使用部分ki来计算外码维度的向量。同时,如果确定结果为“否”,则处理器304继续进行部件ki的进一步处理。特别地,如果确定总和小于k,则处理器304在步骤s1112中找到索引i,以使得差
为了使处理器304可以理解,方法1100可以表示为以下伪代码:
伪代码5:基于信道容量计算外码维度的向量。
输入:
-级联码的长度n,其中n=t2n;
-外码长度t;
-级联码维度k。
输出:
-部分ki,其中i=1,…,n/t。
执行:
回到线性外码的情况,以下可以确定线性外码的生成矩阵。在一个实施例中,存储302还可以包括数据库,该数据库包括与外码长度t的值的宽度范围相对应的生成矩阵,并且处理器304可以进一步被配置为访问数据库并找到生成矩阵的那些矩阵,对应于给定值t和ki。在另一实施例中,这样的数据库可以被存储在诸如远程服务器的远程设备中,并且处理器304可以被配置为与远程设备通信以检索相应的生成矩阵。
图12中示出了用于线性外码的一些示例性生成矩阵。具体地,图12示出了数据库,该数据库包括用于t=5,6,7,8的线性外码的生成矩阵gt(ki)。可以看出,数据库的列由不同的生成矩阵gt(ki)表示,而数据库的行由不同的值ki表示。对于本领域技术人员以下应该显而易见的是,图12所示的数据库的结构是说明性的,并且可以基于特定的应用用任何其他结构代替。
现在让我们给出一个这样的例子,从图12所示的数据库中检索生成矩阵。假设长度n、t和部分ki是上面所计算的长度,当考虑类型i和类型ii的预定义比特序列的数值示例时,即n=20,t=5,并且[k1,k2,k3,k4]=[0,3,3,4]。然后,处理器304应访问数据库并搜索与部分k2,k3,k4和给定长度t相对应的生成矩阵。对于k1=0,这部分意味着第一外码的码率为零,并且总是生成全零码字,因此在这种情况下不需要生成矩阵。因此,处理器304最终应检索以下生成矩阵:
已知级联码的结构,即长度n、t和m,外码维度的向量、打孔或缩短模式、生成矩阵gt(ki)(在线性外码的情况下)以及用于内极化码,可以很容易地构造级联码本身。
在涉及使用缩短模式的一个实施例中,处理器304需要在从数据库中检索出每个外码i=1,…,n/t之后,对生成矩阵gt(ki)进行校正。特别地,该校正在于在每个生成矩阵gt(ki)中将所有具有与缩短模式相对应的索引的列设置为零。所述设置为零可以写为以下伪代码(其中索引从0开始):
伪代码6:使用缩短模式时,将gt(ki)中的所有列设置为零。
输入:
-在伪代码1中获得的长度n和t;
-级联码维度k;
-缩短模式y(或伪代码1的输出);
-检索gt(ki)。
输出:
-校正的gt(ki)。
执行:
1.if缩短,则:
2.对于y中的y,执行以下操作:
3.
4.j=mod(y,t);
5.对于从0到ki-1的k,执行以下操作;
6.gt(ki)(k,j)=0;
7.endfor
8.endfor
9.endif
伪代码6可以解释如下:“对于每个缩短的比特y∈y,确定其在表示级联码码字的所得矩阵中的位置(i,j)。然后,对于上面确定的每个(i,j),将与第i个外码相对应的生成矩阵gt(ki)中的第j列的所有元素设置为零。
图13示出了根据本公开的另一方面的信息编码方法1300的流程图。方法1300包括步骤s1302-s1306,并且旨在由级联的编码器执行。类似于装置300,级联编码器可以被实现为存储计算机可执行指令的存储器和执行计算机可执行指令以执行方法1300的至少一个处理器的的组合。方法1300从步骤s1302开始,包括:接收k个信息比特的向量。级联码维度k和k个信息比特的向量之间的差异在于,前者仅指示要编码的信息比特的数量,而后者则指示k个信息比特的特定排列。此外,方法1300前行到步骤s1304,包括:接收在方法400中获得的级联码结构。方法1300的最后步骤s1306包括:通过使用级联码结构对k个信息比特的向量进行编码。现在将更详细地描述方法1300的步骤s1306。
首先,将k个信息比特的向量表示为v(k)。如上所述,级联码结构包括以下参数:长度t、n和m,外码维度的向量,打孔或缩短模式,外码的生成矩阵gt(ki)(如果外码是线性的),以及内极化码的生成矩阵。一旦被接收,向量v(k)被分成n/t个子向量,每个子向量的长度等于对应的ki。每个子向量v(ki)旨在用于每个n/t外码。接下来,使用外码对子向量v(ki)进行编码,从而获得外码矩阵(ci,j),其中每一行都包含外码码字(ci,1,…,ci,t),其中1≤i≤n/t,1≤j≤t。在线性外码的情况下,通过分别将生成矩阵gt(ki)应用于子向量v(ki)来获得外码码字:
(ci,1,…,ci,t)=v(ki)gt(ki),其中i=1,…,n/t。
如果ki=0,如前所述,则相应的外码码字(ci,1,…,ci,t)是全零码字。此后,通过使用内极化码中的相应一个对外码矩阵(ci,j)的每个第j列进行编码,以得到结果矩阵(di,j)形式的级联码码字。极化编码本身是众所周知的过程,因此在此省略其细节。此外,将所得矩阵(di,j)以长度为n的向量的形式逐行重写,在该向量上,仅选择向量中不对应于打孔或缩短模式的那些m个比特进行传输。
图14示出了根据本公开的另一方面的信息译码方法1400的流程图。方法1400包括步骤s1402-s1406,并且旨在由级联的译码器执行。类似于装置300,级联译码器可以被实现为存储计算机可执行指令的存储器和执行计算机可执行指令以执行方法1400的至少一个处理器的组合。方法1400开始于步骤s1402,包括:通过使用方法1300,接收包括被编码为级联码码字的信息比特的信道输出。还应当注意,该信道输出表示级联译码器从外部(例如,从通信信道)接收到的信号,以及,除了编码的信息比特外,还包括不同的噪声。此外,方法1400进行到步骤s1404,其包括接收级联码结构本身。方法1400的最后步骤s1406包括通过使用级联码结构从接收的信道输出中检索信息比特。在这里应该注意,这种检索涉及将打孔的比特作为已擦除的比特,将缩短的比特作为已知的等于0的比特。这种检索的细节可以在例如以下论文中找到:h.saber和imarsland,“基于带有极短外码的极码的通用级联码的设计”,载于《ieee车载技术交易》(ieeetransationsonvehicletechnology),第66卷,第4号,第3103-3115页,2017年4月。特别是,该文章的作者建议将sc译码器与最大似然(maximum-likelihood,ml)译码器一起使用,以共同译码t个内极化码和n/t个外码。在一个实施例中,scl或crc辅助的scl译码器和ml译码器的组合可以实现级联码译码器。此外,另一实施例中,对t个内极化码进行并行译码是可能的。
图15示出了其中在通信系统1500中使用装置300的一个示例。如图所示,通信系统1500包括发送侧和接收侧。发送侧包括装置300和包括外部编码器1504、内部编码器1506的级联编码器1502。接收侧通过无线通信信道1508连接到发送侧,并且包括装置300和级联译码器1510,级联译码器1510包括内部译码器1512和外部译码器1514。下面描述通信系统1500的操作原理。
首先,级联编码器1502从装置300接收k个信息比特的向量,即v(k),以及级联码结构。通过使用级联码结构,关于向量v(k)的信息比特,级联编码器1502执行上述方法1300。特别地,构成矩阵(ci,j)的外码码字是由级联编码器1502的外部编码器1504生成的,而级联码码字是所得矩阵的形式(di,j)且由级联编码器1502的内部编码器1506生成。接着,级联编码器1502将级联码码字重写为长度为n的向量,并且仅向通信信道1508提供向量中与打孔或缩短模式不对应的那些m个比特。本领域技术人员将认识到,如此生成和修改(基于打孔或缩短模式)的级联码码字在进入通信信道1508之前应适当地调制到载波上。为了这个目的,可以使用任何合适的众所周知的调制方案,并且所有的这些都在本公开的范围之内。还应该注意的是,当已调制的载波在通信信道1508上传播时,其接受不同的噪声,因此,如前所述,信道输出包括已调制的载波和噪声的组合。
在接收侧,首先应该通过适当的解调方案对信道输出进行解调,这对于本领域技术人员来说也是显而易见的。之后,将解调的信道输出提供给级联译码器1510,级联译码器1510还从装置300接收相同的级联码结构。接下来,级联译码器1510针对解调后的信道输出执行上述方法1400。为此目的,内部译码器1512和外部译码器1514共同操作以从解调的信道输出中检索信息比特。这种联合操作在图15中用双向箭头示意性地示出。此外,信息比特的所述检索涉及将打孔的比特作为擦除比特,并且将缩短的比特作为已知等于0的比特。在一个实施例中,级联译码器1510可以被实现为作为内部译码器1512的sc/scl/crc辅助的scl译码器和作为外部译码器1514的ml译码器的任何组合。在一个其他实施例中,内部译码器1512对t个内极化码进行并行译码是可能的。
图16-19示出了在执行方法400时由装置300获得的级联码(以下简称为级联码)与通过使用在3gppts38.212,“复用和信道编码”版本15,2017年中公开的速率匹配方案构造的常规极化码之间码性能比较的结果。该结果已经通过使用加性高斯白噪声(additivewhitegaussiannoise,awgn)信道作为通信信道1508,正交相移键控(quadraturephaseshiftkeying,qpsk)调制方案以及crc辅助scl译码器和ml译码器的上述组合获得。特别地,已经使用了sca-scl译码器的以下参数:列表大小等于8,crc被设置为24。然而,这些参数的值不限制如何使用本公开的可能性,对本领域技术人员显而易见的是,基于特定应用,可以使用参数的任何其他值。
更具体地,图16示出了信噪比(signal-to-noiseratio,snr)对所期望的级联和极化码的长度m的依赖性,考虑了不同的k=44,64,84(参见指示方向的箭头,其中k会增加),误帧率(frameerrorrate,fer)等于0.00001。应当注意,在所讨论的仿真中,fer等于块错误率(blockerrorrate,bler)。应当注意,基于在方法400的步骤s406中获得的缩短或打孔模式(参见伪代码1)以及在方法400的步骤s408中获得的类型i或类型ii的比特索引序列(即,伪代码2或3),获得了对级联码的依赖性。。可以看出,级联码(见实线)的snr-on-m相关性比常规极化码(见虚线)的平滑。这意味着当改变m和k时,级联码会逐渐改变码性能,即snr。
图17示出了在考虑到k=44且fer等于0.00001的情况下,snr(上位)和增益(下位)对所希望的级联和极化码长度m的依赖性。通过使用常规极化码和每个m的级联码获得的snr之间的db差来计算增益。两个相关性右侧的示出的插入图显示了增益值在所有值m上的分布。类似地,很容易看出,级联码(见实线)的snr-on-m依赖性比常规极化码(见虚线)的平滑。在某些m处,曲线之间存在显着差异,例如在150至200的范围内,这会导致更大的增益值。
图18和19示出了snr和增益对级联和极化码的期望长度m的类似依赖性,但是现在分别考虑了k=64,84和相同的fer。可以再次看到,级联码的snr-on-m相关性(见实线)比常规极化码的(见虚线)平滑,并且在某些m下,曲线之间存在显着差异。因此,根据本公开的级联码在不同的m和k值下表现出更好的码性能。
本领域技术人员应该理解,本文公开的方法的每个框或步骤,或者框或步骤的任何组合,可以通过各种手段来实现,例如硬件、固件和/或软件。作为示例,可以通过计算机可执行指令、数据结构、程序模块和其他合适的数据表示来体现上述方框或步骤中的一个或多个。此外,体现上述方框或步骤的计算机可执行指令可以存储在相应的数据载体上,并由至少一个处理器(如装置300的处理器304)执行。该数据载体可以实现为任何计算机可读存储介质。所述介质被配置为可由所述至少一个处理器读取以执行计算机可执行指令。这样的计算机可读存储介质可以包括易失性和非易失性介质、可移动和不可移动介质。作为示例而非限制,计算机可读介质包括以适合于存储信息的任何方法或技术实现的介质。更详细地,计算机可读介质的实际示例包括但不限于信息传递介质、ram、rom、eeprom、闪存、其他存储器技术、cd-rom、数字多功能光盘(digitalversatilediscs,dvd)、全息照相介质或其他光盘存储、磁带、磁带盒、磁盘存储和其他磁性存储设备。
尽管在此描述了本公开的示例性实施例,但是应当注意,在不脱离由所附权利要求限定的法律保护范围的情况下,可以对本公开的实施例进行任何各种改变和修改。在所附权利要求中,词语“包括”不排除其他元件或步骤,并且不定冠词“一”或“一个”不排除多个。在互不相同的从属权利要求中记载某些措施的事实并不意味着不能有利地使用这些措施的组合。
- 还没有人留言评论。精彩留言会获得点赞!