声场再现设备、方法和程序与流程
本技术涉及一种声场再现设备、声场再现方法和程序。特别是,本技术涉及一种声场再现设备、声场再现方法和配置为能够进一步准确地再现特定声场的程序。
背景技术:
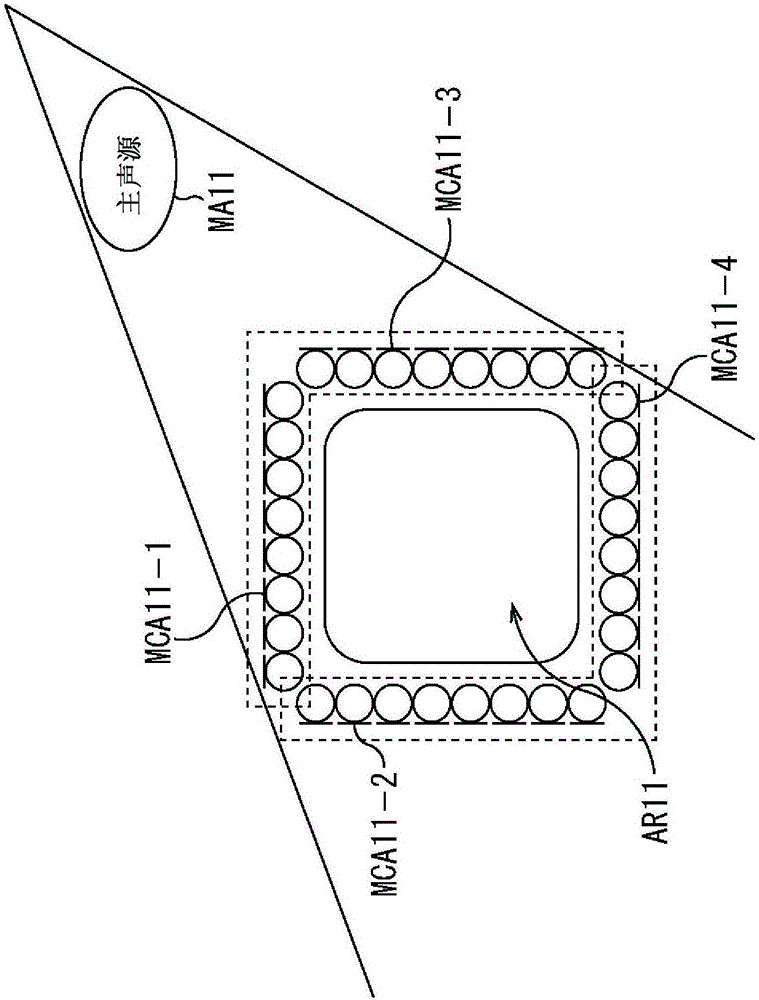
:在过去,波场合成技术已经是公知的,其中在波场合成技术中使用多个麦克风在声场中声音的波面上拾取所述声音,从而基于已获得的声音拾取信号再现声场。例如,在封闭空间内的声场需要准确地再现的情况下,可以根据Kirchhoff-Helmholtz理论再现声场。在Kirchhoff-Helmholtz理论中,在封闭空间的边界表面的声压和在封闭空间内的所有坐标上的声压梯度都被记录,然后使用具有偶极性质的发声体和具有单极性质的发声体在相应的坐标回放声音。在真实的环境中,麦克风和扬声器用来记录和回放声场。通常,由于物理限制,使用一对简单声压麦克风和单极扬声器。在这种情况下,由于缺少声压梯度,回放的声场和实际的声场之间产生差异。作为产生这样的差异的典型示例,给出一种情况,其中由于在封闭空间外面的通过穿过封闭空间的内部的另外的声源,使得从在封闭空间外面的声源到达的信号和从封闭空间内到达的信号在录音时被混合。结果,在该示例中,在回放中从意想不到的位置,听到两个声源。换言之,通过听到声场的用户而感知的声源的位置设置在与声源应该位于的原来的位置不同。这种现象是由在与封闭空间对应的收听区域中最初就已经用物理方式去除的信号由于缺少获取声压梯度而被保持住所引起的。因此,例如,提出了一种技术,其中麦克风设置在刚性体的表面,使声压梯度为零,从而解决上述现象的发生(例如,参考非专利文献1)。此外,还提出了另一种技术,其中封闭空间的边界表面被限制到平坦表面或直线上,以排除从边界表面内部到达的信号的影响,从而防止上述现象的发生(例如,参考非专利文献2)。引用列表非专利文件非专利文献1:ZhiyunLi,RamaniDuraiswami,NailA.Gumerov,"CaptureandRecreationofHigherOrder3DSoundFieldsviaReciprocity",inProceedingsofICAD04-TenthMeetingoftheInternationalConferenceonAuditoryDisplay,Sydney,Australia,July6-9,2004。非专利文献2:ShoichiKoyamaetal.,"DesignofTransformFilterforSoundFieldReproductionusingMicorphoneArrayandLoudspeakerArray",IEEEWorkshoponApplicationsofSignalProcessingtoAudioandAcoustics2011技术实现要素:本发明要解决的问题然而,在上面描述的技术中,已经难以准确地再现特定声场。例如,由于所需要的声音拾取所针对的声场范围是与刚性体的立方体积成比例的,在非专利文献1中公开的技术不适合用于对宽范围声场进行记录。同时,在非专利文献2中公开的技术中,用于声场中的声音拾取的麦克风阵列的安装被限制在不经常发生声音转向的地方(例如,靠近墙)。本技术已作考虑到这样的情况,并且从而其目的是能够进一步准确地再现特定声场。解决问题的方法根据本技术的一个方面的声场再现设备包括:加强单元,基于从通过使用声音拾取单元从主声源提取声音获取的信号提取的特征量,加强通过用放置在主声源前面的第一麦克风阵列拾取声音而获得的第一声音拾取信号的主声源分量。可以进一步为声场再现设备提供减弱单元,基于特征量,减弱通过利用设置在辅助声源前面的第二麦克风阵列拾取声音获取的第二声音拾取信号的主声源分量。加强单元能够基于特征量,将第一声音拾取信号分离为主声源分量和辅助声源分量,并加强分离的主声源分量。减弱单元能够基于特征量将第二声音拾取信号分离成主声源分量和辅助声源分量,并加强分离的辅助声源分量以减弱第二声音拾取信号的主声源分量。加强单元能够使用非负张量分解,将第一声音拾取信号分离成主声源分量和辅助声源分量。减弱单元能够使用非负张量分解,将第二声音拾取信号分离成主声源分量和辅助声源分量。该声场再现设备可以具有多个加强单元,每个加强单元对应于多个第一麦克风阵列中的每一个。该声场再现设备可以具有多个减弱单元,每个减弱单元对应于多个第二麦克风阵列中的每一个。第一麦克风阵列可以设置在连接由第一麦克风阵列和第二麦克风阵列和主声源包围的空间的直线上。声音拾取单元可以设置在主声源的附近。根据本技术的另外的方面的声场再现方法或程序,包括基于从通过从主声源使用声音拾取单元提取声音获得的信号提取的特征量,加强通过使用放置在主声源前面的第一麦克风阵列拾取声音获得的第一声音拾取信号的主声源分量的步骤。根据本技术的一个方面,基于从通过使用声音拾取单元从主声源拾取声音的信号提取的特征量,通过使用放置在主声源前面的第一麦克风阵列拾取声音获得的第一声音拾取信号的主声源分量被放大。本技术的效果根据本技术的一个方面,特定声场可以进一步准确地再现。注意,这里所描述的效果不必被限定,并且本公开描述的任何效果可能会被应用。附图说明图1是描述本技术的示意图。图2是描述主声源线型麦克风阵列和辅助声源线型麦克风阵列的示意图。图3是说明主声源加强声场再现单元的示例性配置的示意图。图4是描述张量分解的示意图。图5是描述声场再现处理的流程图。图6是说明主声源加强声场再现单元的另外的示例性配置的示意图。图7是说明计算机的示例性配置的示意图。执行本发明的模式在下文中,将参考附图描述应用本技术的实施例。<第一实施例><关于本技术>本技术被配置使用多个线型麦克风阵列在真实空间(声音拾取空间)中对声场录音,每个线型麦克风阵列由顺序放置在一条直线上的多个麦克风构成,并且基于由此获得的声音拾取信号,使用多个线型扬声器阵列再现声场,每个线型扬声器阵列由放置在一条直线上的多个扬声器构成。此时,基于声音拾取信号的声音被回放,使得在再现声场的再现空间(收听区域)和声音拾取空间之间获得等效声场。在下文中,假设作为主要需要声音拾取的对象的声源被称做主声源,而其它声源被称为辅助声源。注意,可以使用多个主声源。根据本技术,例如,三种类型的声音拾取单元用于在声音拾取空间中拾取声音,如图1所示。图1所示的示例代表一个系统,其中线型麦克风阵列和线型扬声器阵列都被布置在四条边上,以形成正方形,由此从出现在由线型麦克风阵列围成的封闭空间之外的声源产生的声场在由线型扬声器阵列围成的封闭空间(收听区域)之内被再现。具体而言,如图1的左侧所示,作为将被主要拾取的声音的声源的主声源MA11和作为将不被主要拾取的声音的声源的辅助声源SA11出现在声音拾取空间。在这种情况下,使用麦克风MMC11和线型麦克风阵列MCA11-1至线型麦克风阵列MCA11-4拾取来自该主声源MA11的声音和来自该辅助声源SA11的声音。此时,来自辅助声源的声音从不同于来自主声源的声音的方向到达线型麦克风阵列中的每一个。麦克风MMC11由单个麦克风或多个麦克风构成,作为另外的选择,由设置在接近主声源MA11的位置上的麦克风阵列构成,并拾取来自主声源MA11的声音。麦克风MMC11设置在声音拾取单元中的靠近主声源MA11的位置上,其中所述声音拾取单元设置在声音拾取空间内。特别是,麦克风MMC11设置在主声源MA11附近,从而使得当在声场中拾取声音的时候,从主声源MA11拾取的声音的音量足够大到可以忽略来自辅助声源SA11的声音。注意,下面的描述将通过假设麦克风MMC11由单个麦克风构成来继续。同时,线型麦克风阵列MCA11-1到线型麦克风阵列MCA11-4设置在声音拾取空间的四条边上,以形成正方形。由线型麦克风阵列MCA11-1至线型麦克风阵列MCA11-4围成的正方形区域AR11作为对应于如图1右侧所示的再现空间中的收听区域HA11的区域。收听区域HA11是听众听到再现声场的区域。在该示例中,线型麦克风阵列MCA11-1设置在主声源MA11的前方(前面),而线型麦克风阵列MCA11-4设置在辅助声源SA11的前方(前面)。注意,当不需要特别彼此区分这些线型麦克风阵列的时候,在下文中假设线型麦克风阵列MCA11-1至线型麦克风阵列MCA11-4也简称为线型麦克风阵列MCA11。在声音拾取空间中,线型麦克风阵列MCA11中的一些被设定为主要从主声源MA11拾取声音的主声源线型麦克风阵列,而其它线型麦克风阵列声源被设定为主要从辅助声源SA11拾取声音的辅助声源线型麦克风阵列。例如,主声源线型麦克风阵列和辅助声源线型麦克风阵列是如图2所示明确确定的。注意,在图2中,与图1的情况下的构成部件对应的构成部件是用相同的参考数字表示的,并且其描述将适当的省略。然而,为了描述的目的,主声源MA11的相对于图2中各个线型麦克风阵列MCA11的位置设置在与图1的情况不同的位置。在图2的示例中,位于主声源MA11和对应于收听区域HA11的区域AR11之间的线型麦克风阵列MCA11设定为主声源线型麦克风阵列。因此,设置在连接主声源MA11与区域AR11中任意位置的直线上的线型麦克风阵列MCA11被设定为主声源线型麦克风阵列。此外,在线型麦克风阵列MCA11中,除了主声源线型麦克风阵列之外的线型麦克风阵列MCA11设定为辅助声源线型麦克风阵列。换句话说,当把主声源MA11比作光源时,被主声源MA11发出的光照射的线型麦克风阵列MCA11被设定为主声源线型麦克风阵列。同时,位于主声源线型麦克风阵列后面并且没有被主声源MA11发出的光照射的线型麦克风阵列MCA11,即被主声源线型麦克风阵列遮挡并且当从主声源MA11观察时看不到的线型麦克风阵列MCA11,被设定为辅助声源线型麦克风阵列。因此,在图2中,线型麦克风阵列MCA11-1和线型麦克风阵列MCA11-3设定为主声源线型麦克风阵列,而线型麦克风阵列MCA11-2和线型麦克风阵列MCA11-4设定为辅助声源线型麦克风阵列。回到图1的描述,在声音拾取空间中,当在声场中拾取声音的时候,每个线型麦克风阵列MCA11都用作主声源线型麦克风阵列或辅助声源线型麦克风阵列。在该示例中,设置在主声源MA11前面的线型麦克风阵列MCA11-1设定为主声源线型麦克风阵列。同时,当从主声源MA11观查时,设置在线型麦克风阵列MCA11-1后面的线型麦克风阵列MCA11-2至线型麦克风阵列MCA11-4设定辅助声源线型麦克风阵列。作为如上面所描述的从主声源MA11和辅助声源SA11拾取声音的实例,例如,考虑表演中演奏的乐器作为主声源MA11而表演的鼓掌的观众作为辅助声源SA11的使用实例。在这样使用实例中,采用了例如表演主要由主声源线型麦克风阵列录音而掌声由辅助声源线型麦克风阵列录音的系统。注意,为了使下面的描述更简单,将通过假设线型麦克风阵列MCA11-1作为主声源线型麦克风阵列、线型麦克风阵列MCA11-4作为辅助声源线型麦克风阵列并且不使用剩余的线型麦克风阵列(即线型麦克风阵列MCA11-2和线型麦克风阵列MCA11-3)来继续描述。如上所述的在声音拾取空间中拾取声音所针对的声场在如图1的右侧所示的再现空间中使用线型扬声器阵列SPA11-1至线型扬声器阵列SPA11-4再现,其中线型扬声器阵列SPA11-1至线型扬声器阵列SPA11-4分别对应于线型麦克风阵列MCA11-1至线型麦克风阵列MCA11-4。在再现空间中,线型扬声器阵列SPA11-1至线型扬声器阵列SPA11-4设置为正方形的形状,以包围收听区域HA11。注意,在下文中,当不需要特别彼此区分这些线型扬声器阵列的时候,线型扬声器阵列SPA11-1至线型扬声器阵列SPA11-4被简称为线型扬声器阵列SPA11。在这里,在声音拾取空间中的声场不能仅通过使用与线型麦克风阵列MCA11-1对应的线型扬声器阵列SPA11-1回放用线型麦克风阵列MCA11-1拾取的声音,以及使用与线型麦克风阵列MCA11-4对应的线型扬声器阵列SPA11-4回放用线型麦克风阵列MCA11-4拾取的声音来准确地再现。例如,如图1中左侧的箭头所指示的,在通过线型麦克风阵列MCA11-1拾取时,作为从主声源MA11到达的信号(声音)的表演的声音,以及作为从辅助声源SA11穿过区域AR11到达的信号的掌声发生混合。因此,当使用了线型扬声器阵列SPA11-1,回放用线型麦克风阵列MCA11-1拾取的声音时,其中混合了主声源MA11的声音和辅助声源SA11的声音的混合信号向收听区域HA11的方向传播。因此,在收听区域HA11听到声音的听众获得仿佛辅助声源SA11位于与辅助声源SA11应位于的原始位置正相反的位置的印象。具体而言,在原始的环境,来自辅助声源SA11的声音从图1的下侧到达收听区域HA11。然而,听众听到的仿佛是来自辅助声源SA11的声音从图1的上侧到达收听区域HA11。同样,如图1中左侧的箭头所指示的,当被线型麦克风阵列MCA11-4拾取时,作为从辅助声源SA11到达的信号的掌声与作为从主声源MA11穿过区域AR11到达的信号的表演的声音被混合。因此,当使用了线型扬声器阵列SPA11-4,回放用线型麦克风阵列MCA11-4拾取的声音,其中混合了辅助声源SA11的声音和主声源MA11的声音的混合信号向收听区域HA11的方向传播。因此,在收听区域HA11听到声音的听众获得仿佛主声源MA11位于与主声源MA11应位于的原始位置正相反的位置的印象。具体而言,在原始的环境,来自主声源MA11的声音从图1的上侧到达收听区域HA11。然而,听众听到的仿佛是来自主声源MA11的声音从图1的下侧到达收听区域HA11。如上所述,因为从彼此不同的方向到达的来自主声源MA11(在演出中演奏的乐器的声音)和来自辅助声源SA11(鼓掌)的声音被互相混合,声场不能仅通过回放用线型麦克风阵列MCA11拾取的声音而准确地再现。作为针对此的技术方案,为了减少由于从不同于主要采集声音的声源的方向到达的声音的混合造成的影响,本技术使用用麦克风MMC11从主声源MA11拾取的声音来执行主声源加强处理和主声源减弱处理。具体地说,用麦克风MMC11拾取的声音是来自辅助声源SA11的声音以比来自主声源MA11的声音的音量足够小的音量录音的声音,并且从而代表来自主声源MA11的声音的特征的特征量(在下文中也称为主声源特征量)可以从麦克风MMC11拾取的声音轻松地提取。本技术使用主声源特征量从而在用线型麦克风阵列MCA11-1拾取声音获得的声音拾取信号上执行主声源加强处理。在主声源加强处理中,主声源MA11的声音分量(具体而言,表演的声音分量)被专门加强。此后,基于经过主声源加强处理的声音拾取信号,声音在线型扬声器阵列SPA11-1被回放。同时,主声源特征量用于在用线型麦克风阵列MCA11-4拾取声音而获得的声音拾取信号上执行主声源减弱处理。在主声源减弱处理中,辅助声源SA11的声音分量(具体而言,掌声成分)被加强从而相对专门减弱主声源MA11的声音分量。此后,基于经过主声源减弱处理的声音拾取信号,声音在线型扬声器阵列SPA11-4被回放。由于上述处理,在收听区域HA11中的听众能够听到来自主声源MA11的表演的声音和来自辅助声源SA11的掌声,表演的声音从图1的上侧到达,掌声从图1下侧到达。因此,可以进一步在再现空间中准确地再现在声音拾取空间中的特定声场。换句话说,因为本技术不需要任何为对应于收听区域HA11的区域AR11的大小和形状、线型麦克风阵列MCA11的设置等等提供的限制,所以在声音拾取空间中的任何声场都可以进一步精确地再现。注意,在图1中,描述了其中将构成正方形类型的麦克风阵列的各个线型麦克风阵列MCA11设定为主声源线型麦克风阵列或辅助声源线型麦克风阵列的示例。然而,构成球形麦克风阵列或环形麦克风阵列一些麦克风阵列可以设定为主要用于拾取来自主声源的声音且对应于主声源线型麦克风阵列的麦克风阵列和主要用于拾取来自辅助声源的声音且对应于辅助声源线型麦克风阵列的麦克风阵列。<主声源加强声场再现单元的示例性配置>接下来,将使用(例如)本技术应用于主声源加强声场再现单元的情况,对应用本技术的具体实施例进行描述。图3是说明根据实施例应用本技术的主声源加强声场再现单元的示例性配置的示意图。主声源加强声场再现单元11由麦克风21、主声源获取单元22、麦克风阵列23-1、麦克风阵列23-2、主声源驱动信号产生器24、辅助声源驱动信号产生器25、扬声器阵列26-1、和扬声器阵列26-2构成。例如,麦克风21由单个的麦克风或多个麦克风构成,作为另外的选择,由麦克风阵列构成,并且设置在声音拾取空间中的主声源附近。该麦克风21对应于图1所示的麦克风MMC11。麦克风21拾取从主声源发出的声音,并将由此获得的声音拾取信号提供给主声源获取单元22。基于由麦克风21提供的声音拾取信号,主声源获取单元22从声音拾取信号中提取主声源特征量,以提供给主声源驱动信号产生器24和辅助声源驱动信号产生器25。因此,主声源的特征量是在主声源获取单元22中获取的。主声源获取单元22由设置在声音拾取空间中的发射器31和设置在再现空间中的接收器32构成。发射器31具有时间频率分析器41、特征量提取单元42和通信单元43。时间频率分析器41对由麦克风21提供的声音拾取信号进行时间频率变换,并将由此获得的时间频率谱提供给特征量提取单元42。特征量提取单元42从由时间频率分析器41提供的时间频率谱提取主声源特征量,并提供给通信单元43。通信单元43通过有线或无线的方式向接收器32发送由特征量提取单元42提供的主声源特征量。接收器32包括通信单元44。通信单元44接收从通信单元43发送的主声源特征量,以提供给主声源驱动信号产生器24和辅助声源驱动信号产生器25。麦克风阵列23-1包括线型麦克风阵列并用作主声源线型麦克风阵列。即麦克风阵列23-1对应于图1所示的线型麦克风阵列MCA11-1。麦克风阵列23-1在声音拾取空间中的声场中拾取声音并将由此获得的声音拾取信号提供给主声源驱动信号产生器24。麦克风阵列23-2包括线型麦克风阵列并用作辅助声源线型麦克风阵列。即麦克风阵列23-2对应于图1所示的线型麦克风阵列MCA11-4。麦克风阵列23-2在声音拾取空间中的声场中拾取声音并将由此获得的声音拾取信号提供给辅助声源驱动信号产生器25。注意,在下文中假设,当不需要特别彼此区分这些麦克风阵列的时候,麦克风阵列23-1和麦克风阵列23-2也简称为麦克风阵列23。基于由主声源获取单元22提供的主声源特征量,主声源驱动信号产生器24从由麦克风阵列23-1提供的声音拾取信号提取主声源分量,并且作为主声源的扬声器驱动信号,也产生其中提取的主声源分量被加强的信号,以提供给扬声器阵列26-1。由主声源驱动信号产生器24执行的处理对应于已参考图1进行描述的主声源加强处理。主声源驱动信号产生器24由设置在声音拾取器空间中的发射器51和设置在再现空间中的接收器52构成。发射器51具有时间频率分析器61、空间频率分析器62和通信单元63。时间频率分析器61对由麦克风阵列23-1提供的声音拾取信号执行时间频率变换,并将由此获得的时间频率谱提供给空间频率分析器62。空间频率分析器62对由时间频率分析器61提供的时间频率谱执行空间频率变换,并将由此获得的空间频率谱提供给通信单元63。通信单元63通过有线或无线的方式向接收器52发送由空间频率分析器62提供的空间频率谱。接收器52具有通信单元64、空间频率合成器65、主声源分离单元66、主声源加强单元67和时间频率合成器68。通信单元64接收从通信单元63发送的空间频率谱,以提供给空间频率合成器65。在由通信单元64提供的空间频率谱的空间区域内找到扬声器阵列26-1的驱动信号之后,空间频率合成器65执行逆空间频率变换并向主声源分离单元66提供由此获得的时间频率谱。基于由通信单元44提供的主声源特征量,主声源分离单元66将由空间频率合成器65提供的时间频率谱分离成作为主声源分量的主声源时间频率谱和作为辅助声源分量的辅助声源时间频率谱,以提供给主声源加强单元67。基于由主声源分离单元66提供的主声源时间频率谱和辅助声源时间频率谱,主声源加强单元67产生其中主声源分量被加强的主声源加强时间频率谱,以提供给时间频率合成器68。时间频率合成器68执行由主加强单元67提供的主声源加强时间频率谱的时间频率合成,并将由此获得的扬声器驱动信号提供给扬声器阵列26-1。基于由主声源获取单元22提供的主声源特征量,辅助声源驱动信号产生器25从由麦克风阵列23-2提供的声音拾取信号提取主声源分量,并且,还产生其中提取的主声源分量被减弱的信号(作为辅助声源的扬声器驱动信号),以提供给扬声器阵列26-2。由辅助声源驱动信号产生器25执行的处理对应于参考图1进行描述的主声源减弱处理。辅助声源驱动信号产生器25由设置在声音拾取器空间中的发射器71和设置在再现空间中的接收器72构成。发射器71具有时间频率分析器81、空间频率分析器82和通信单元83。时间频率分析器81对由麦克风阵列23-2提供的声音拾取信号执行时间频率变换,并将由此获得的时间频率谱提供给空间频率分析器82。空间频率分析器82对由时间频率分析器81提供的时间频率谱执行空间频率变换,并将由此获得的空间频率谱提供给通信单元83。通信单元83通过有线或无线的方式向接收器72发送由空间频率分析器82提供的空间频率谱。接收器72具有通信单元84、空间频率合成器85、主声源分离单元86、主声源减弱单元87和时间频率合成器88。通信单元84接收从通信单元83发送的空间频率谱,以提供给空间频率合成器85。在由通信单元84提供的空间频率谱的空间区域内找到扬声器阵列26-2的驱动信号之后,空间频率合成器85执行逆空间频率变换并向主声源分离单元86提供由此获得的时间频率谱。基于由通信单元44提供的主声源特征量,主声源分离单元86将由空间频率合成器85提供的时间频率谱分离成主声源时间频率谱和辅助声源时间频率谱,以提供给主声源减弱单元87。基于由主声源分离单元86提供的主声源时间频率谱和辅助声源时间频率谱,主声源减弱单元87产生主声源分量被减弱(即辅助声源分量被加强)的主声源减弱时间频率谱,以提供给时间时间频率合成器88。时间频率合成器88执行由主声源减弱单元87提供的主声源减弱时间频率谱的时间频率合成,并将由此获得的扬声器驱动信号提供给扬声器阵列26-2。扬声器阵列26-1例如包括线型扬声器阵列,并对应于图1的线型扬声器阵列SPA11-1。扬声器阵列26-1基于由时间频率合成器68提供的扬声器驱动信号回放声音。因此,再现了来自声音拾取空间中的主声源的声音。扬声器阵列26-2例如包括线型扬声器阵列,并对应于图1的线型扬声器阵列SPA11-4。扬声器阵列26-2基于由时间频率合成器88提供的扬声器驱动信号回放声音。因此,再现了来自声音拾取空间中的辅助声源的声音。注意,在下文中,当不需要特别彼此区分这些扬声器阵列的时候,假设扬声器阵列26-1和扬声器阵列26-2也简称为扬声器阵列26。在这里,构成主声源加强声场再现单元11的各个成员将被更详细地描述。(时间频率分析器)首先,将描述时间频率分析器41、时间频率分析器61和时间频率分析器81。描述将通过使用时间频率分析器61作为这里的示例来继续。时间频率分析器61分析在构成麦克风阵列23-1的每个麦克风(麦克风传感器)获得的声音拾取信号s(nmic,t)的时间频率信息。注意,声音拾取信号中的nmic代表指示构成麦克风阵列23-1的麦克风的麦克风指数,其中麦克风指数表示为nmic=0,…,Nmic-1。此外,Nmic代表构成的麦克风阵列23-1的麦克风的数量,并且t代表时间。时间频率分析器61从声音拾取信号s(nmic,t)获得经历了分割成固定大小的时间帧分割的输入帧信号sfr(nmic,nfr,l)。随后,时间频率分析器61将输入帧信号sfr(nmic,nfr,l)与由下面的公式(1)表示的窗函数wT(nfr)相乘,以获得窗函数-应用信号sw(nmic,nfr,l)。具体而言,计算下面的公式(2)并算出窗函数-应用信号sw(nmic,nfr,l)了。[数学公式1]wT(nfr)=(0.5-0.5cos(2πnfrNfr))0.5...(1)]]>[数学公式2]sw(nmic,mfr,l)=wT(nfr)sfr(nmic,nfr,l)…(2)在这里,在公式(1)和公式(2)中nfr表示时间指数,其中时间指数表示为nfr=0,…,Nfr-1。同时,l代表时间帧指数,其中时间帧指数表示为l=0,…,L-1。此外,Nfr代表帧大小(在时间帧中的样本数),而L是帧的总数。此外,帧大小Nfr代表样本的数量等于在采样频率fsT[Hz](=R(fsT×Tfr)下的一帧的时间Tfr[s],其中R()是任何取整函数。在该实施例中,例如,一个帧的时间设置为Tfr=1.0[s],其中四舍五入被用作取整函数R()。然而,也可以采用另外的取整函数。类似的,虽然帧的偏移量设置为帧大小Nfr的50%,也可以采用另外的偏移量。进一步,Hanning窗的平方根在这里用作窗函数。然而,另外的窗,例如可以采用Hanning窗或BlackmanHarris窗用于其中。一旦如上所述获得窗函数-应用信号sw(nmic,nfr,l),时间频率分析器61计算下面的公式(3)和公式(4),从而对窗函数-应用信号sw(nmic,nfr,l)执行时间频率变换,从而算出时间频率谱的S(nmic,nT,l)。[数学公式3]sw,(nmic,mT,l)=sw(nmic,mT,l)mT=0,...,Nfr-10mT=Nfr,...,MT-1...(3)]]>[数学公式4]S(nmic,nT,l)=ΣmT=0MT-1Sw,(nmic,mT,l)exp(-i2πmTnTMT)...(4)]]>具体而言,零填充信号sw’(nmic,mT,l)通过公式(3)的计算得到,并且然后,基于获得的零填充信号sw’(nmic,mT,l)计算公式(4),由此算出时间频率谱S(nmic,nT,l)。注意,在公式(3)和公式(4)中MT代表时间频率变换中使用的点的数量。同时,nT代表时间频率谱指数。在这里,假设NT=MT/2+1并且nT=0,...,NT-1。此外,在公式(4)中i代表纯虚数。此外,在该实施例中,时间频率变换根据短时傅里叶变换(STFT)执行。然而,可以使用其它时间频率变换,例如离散余弦变换(DCT)和修正离散余弦变换(MDCT)。此外,STFT的点MT的数量设置为等于或大于Nfr并接近Nfr的二次幂的值。然而,点MT的数量可以设置为除此之外的值。时间频率分析器61向空间频率分析器62提供通过上述的处理获得的时间频率谱S(nmic,nT,l)。通过执行与时间频率分析器61类似的处理,时间频率分析器41也从由麦克风21提供的声音拾取信号中计算出时间频率谱,以提供给特征量提取单元42。此外,时间频率分析器81也从由麦克风阵列23-2提供的声音拾取信号计算出时间频率谱,以提供给空间频率分析器82。(特征量提取单元)特征量提取单元42从由时间频率分析器41提供的时间频率谱S(nmic,nT,l)提取主声源特征量。作为主声源特征量的提取方法,将在这里描述作为示例的基于使用非负张量分解(NTF)的主声源而获取频率的方法。然而,主声源特征量可以配置为使用另外的方法被提取。注意,例如,在"DerryFitzGeraldetal.,"Non-NegativeTensorFactorisationforSoundSourceSeparation",ISSC2005,Dublin,Sept.1-2."中详细描述了NTF。特征量提取单元42首先计算下面的公式(5),作为将时间频率谱S(nmic,nT,l)转换为非负谱V(j,k,l)的预处理。[数学公式5]V(j,k,l)=(S(j,k,l)×conj(S(j,k,l)))ρ…(5)在这里,时间频率谱S(nmic,nT,l)中的麦克风指数由信道指数j代替,而其中的时间频率谱指数nT用频率指数k代替。因此,麦克风指数nmic记为j并且时间频率谱指数nT记为k。此外,假设Nmic=J并且NT=K。在这种情况下,一个由麦克风指数nmic确定的麦克风将被当做一个信道。此外,在公式(5)中,conj(S(j,k,l))代表时间频率谱S(j,k,l)的复共轭,并且ρ代表用于变换为非负值的控制值。用于变换为非负值的控制值ρ可以设置为任何类型的值,只是例如,在这里用于变换为非负值的控制值被设置为ρ=1。通过计算公式(5)获得的非负谱V(j,k,l)在时间方向上被耦合,从而将被表示为非负谱V,并且在NTF期间作为输入。例如,当非负谱V解释为三维张量J×K×L时,非负谱V可以分为P个三维张量Vp’(在下文中,也被称为基谱)。在这里,p代表表示基谱的基指数,并表示为p=0,…,P-1,其中P代表基数。在下文中,假设由基指数p表征的基也称为基p。此外,P个三维张量的Vp’的每一个可以表示为三个向量的直积,并从而分解成三个向量。由于为三个类型向量的每一个收集P个向量,新获得三个矩阵(即信道矩阵Q、频率矩阵W和时间矩阵H);因此,所以认为非负谱V可以分解成三个矩阵。注意,信道矩阵Q的大小被表示为J×P,频率矩阵W的大小表示为K×P,并且时间矩阵H的大小表示为L×P。注意,在下文中,当表示三维张量或者矩阵的各个元素的时候,将使用小写字母标记。例如,非负谱V中的各个元素表示为vjkl,而信道矩阵Q各个元素表示为qjkl。此外,例如,假设vjkl也记为[V]jkl。假设其它矩阵用与此类似的方式标记,并且,例如,qjkl也记为[Q]jkl。在执行张量分解时,特征量提取单元42通过采用非负张量分解(NTF)最大限度地减少误差张量E。通过张量分解获得的每个信道矩阵Q、频率矩阵W和时间矩阵H具有特征属性。在这里,将描述信道矩阵Q、频率矩阵W和时间矩阵H。例如,如图4所示,假设作为将三维张量(该三维张量通过从由箭头R11表示的非负谱V中排出误差张量E而获得)分解为P个三维张量的结果(其中P代表基数),获得由箭头R12-1至箭头R12-P分别表示的基谱V0’至基谱VP-1’。这些基谱Vp’(wherep=0,...,P-1)中的每一个,即上述三维张量Vp’可以表示为三个向量的直积。例如,基谱V0’可以表示为三个向量的直积,即由箭头R13-1表示的向量[Q]j,0,,由箭头R14-1表示的向量[H]l,0和由箭头R15-1表示的向量[W]k,0。向量[Q]j,0是由J个元素构成的列向量,其中J表示的信道的总数,并且向量[Q]j,0中的J个元素中的每一个是对应于由信道指数j表示的每个信道(麦克风)的分量。同时,向量[H]l,0是由L个元素构成的行向量,其中L代表时间帧的总数,并且向量[H]l,0中的L个元素的每一个是对应于由时间帧指数l表示的每个时间帧的分量。此外,向量[W]k,0是由K个元素构成的列向量,其中K代表频率(时间频率)数,并且向量[W]k,0中的K数个元素的每一个是对应于由频率指数k表示的频率的分量。上面描述的向量[Q]j,0、向量[H]l,0和向量[W]k,0分别代表基谱V0’信道方向的属性、时间方向的属性和频率方向的属性。同样,基谱V1’可以表示为三个向量(即由箭头R13-2表示的向量[Q]j,1、由箭头R14-2表示的向量[H]l,1和由箭头R15-2表示的向量[W]k,1)的直积。此外,基谱VP-1’可以表示为三个向量(即由箭头R13-P表示的向量[Q]j,P-1、由箭头R14-P表示的向量[H]l,P-1和由箭头R15-P表示的向量[W]k,P-1)的直积。此后,针对每个维度,收集了对应于P数个基谱Vp’的每一个的各自三个维度的各个三个类型的向量,以形成作为信道矩阵Q、频率矩阵W和时间矩阵H而获得的矩阵。具体而言,如在图4下侧的箭头R16所示,由代表各个基谱Vp’的频率方向属性的向量构成的矩阵(即向量[W]k,0至向量[W]k,P-1)被设置为频率矩阵W。同样,如箭头R17所示,由代表各个基谱Vp’的时间方向属性的向量构成的矩阵(即向量[H]l,0至向量[H]l,P-1)被设置为时间矩阵H。此外,如箭头R18所示,由代表各个基谱Vp’的信道方向属性的向量构成的矩阵(即向量[Q]j,0至向量[Q]j,P-1)被设置为信道矩阵Q。由于非负张量分解(NTF)的属性,使得分离成P个份的基谱Vp’的每一个去获取,以便分别代表声源中的特定属性。在NTF中,所有元素限制为非负值,并且因此,只允许基谱Vp’的相加组合。结果是,减少了组合的模式的数目,从而启动根据专属于声源的属性的更容易的分离。结果,通过选择任意的基指数p,各个点声源被提取,从而可以实现声学处理。在这里,将进一步描述各个矩阵的属性,特别是,信道矩阵Q、频率矩阵W和时间矩阵H。信道矩阵Q代表非负谱V的信道方向的属性。因此认为信道矩阵Q代表在P数个基谱Vp’的每一个中,对J个信道j的每个的总共的贡献程度。频率矩阵W代表非负谱V的频率方向的属性。更具体的,频率矩阵W代表在总共P个基谱Vp’中,对于K个频率区间(frequencybin)中的每一个的贡献程度,即每个基谱Vp’的频率特性。此外,矩阵H代表非负谱V的时间方向的属性。更具体的是,时间矩阵H代表在总共P个基谱Vp’中,对于L个时间帧的每一个的贡献程度,即每个基谱Vp’的时间特性。回到由特征量提取单元42计算出主声源特征量的描述,NTF(非负张量分解)通过下面的公式(6)的计算,使成本函数C相对于信道矩阵Q、频率矩阵W和矩阵时间H最小化,从而建立了优化的信道矩阵Q、优化的频率矩阵W和优化的时间矩阵H。[数学公式6]minQ,W,HC(V|V,)=defΣjkldβ(vjkl|vjkl,)subjecttoQ,W,H≥0...(6)]]>注意,在公式(6)中,vjkl代表非负谱V的元素,而vjkl作为元素vjkl’的预测值。该元素vjkl’是使用下面的公式(7)获得的。注意,在公式(7)中,qjp代表构成的信道矩阵Q的元素,并由信道指数j和基指数p确定,即矩阵元素[Q]j,p。同样,wkp代表矩阵元素[W]k,p并且hlp代表矩阵元素[H]l,p。[数学公式7]vjkl,=Σp=0P-1qjpwkphlp...(7)]]>由用公式(7)计算出的元素vjkl’构成的谱用作作为非负谱V的预测值的近似谱V’。换句话说,近似谱V’是非负谱V的近似值,其可以从P个基谱Vp’中获得,其中P代表基数。此外,在公式(6)中,β偏差(β-divergence)dβ用作测量非负谱V和近似谱V’之间的距离的标记。例如,该β偏差由下面的公式(8)表示,其中x和y代表任意的变量[数学公式8]具体而言,当β不是1或0时,用由公式(8)的最上侧示出的公式计算出β偏差。同时,在β=1的情况下,用公式(8)中间示出的公式计算出β偏差。此外,在β=0(板仓齐藤距离)的情况下,用在公式(8)最下侧示出的公式计算出该β偏差。具体而言,在β=0的情况下,要进行在下面的公式(9)中示出的运算。[数学公式9]dβ=0(x|y)=xy-logxy-1...(9)]]>进一步,在β=0的情况下,在β偏差dβ=0(x|y)中对y的偏微分在下面的公式(10)中说明。[数学公式10]d,β=0(x|y)=1y-xy2...(10)]]>因此,在公式(6)的示例,β偏差D0(V|V’)在下面的公式(11)中说明。同时,对β偏差D0(V|V’)中的信道矩阵Q、频率矩阵W和时间矩阵H的偏微分分别在下面的公式(12)至公式(14)中说明。注意,公式(11)到公式(14)中的所有的减法、除法和对数运算是对每个元素进行计算。[数学公式11]D0(V|V,)=Σjkldβ=0(vjkl|vjkl,)=Σjkl(vjklvjkl,-logvjklvjkl,-1)...(11)]]>[数学公式12]▿qjpD0(V|V,)=Σklwkphlpd,β=0(vjkl|vjkl,)...(12)]]>[数学公式13]▿wkpD0(V|V,)=Σjlqjphlpd,β=0(vjkl|vjkl,)...(13)]]>[数学公式14]▿hlpD0(V|V,)=Σjkqjpwkpd,β=0(vjkl|vjkl,)...(14)]]>随后,当使用同时表示信道矩阵Q、频率矩阵W和时间矩阵H的参数θ表示的时候,NTF中的更新的公式在下面的公式(15)中说明。注意,在公式(15)中,符号“·”代表每个元素的乘法并且除法是对每个元素计算的。[数学公式15]θ←θ·[▿θD0(V|V,)]-[▿θD0(V|V,)]+where▿θD0(V|V,)=[▿θD0(V|V,)]+-[▿θD0(V|V,)]-...(15)]]>注意,在公式(15)中,[σθD0(V|V’)]+和[σθD0(V|V’)]-分别代表函数σθD0(V|V’)的正的部分和负的部分。因此,在公式(6)的情况下(即在不考虑约束函数的情况下),NTF中关于各个矩阵的更新的公式表示为如下面的公式(16)至公式(18)所示的公式。注意,公式(16)至公式(18)中的所有阶乘和除法是对每个元素计算的。[数学公式16][数学公式17][数学公式18]注意,公式(16)至公式(18)中的符号“o”代表矩阵的直积。具体而言,当A是矩阵iA×P并且B是矩阵iB×P的时候,“AoB”代表iA×iB×P的三维张量。此外,<A,B>{C},{D}被称为张量的收缩积(contractionproduct),并通过以下公式(19)表示。然而,对于公式(19),假设其中的各个字母与代表矩阵的符号或迄今为止所描述的类似物不相关。[数学公式19]<A,B>{1,...,M},{1,...,M}=Σi1=1l1...ΣiM=1lMai1...iM,j1...jMbi1...iM,k1...kP...(19)]]>在使用公式(16)至公式(18)更新信道矩阵Q、频率矩阵W和时间矩阵H时,特征量提取单元42使公式(6)中的成本函数C最小化,从而找到优化的信道矩阵Q、优化的频率矩阵W和优化的时间矩阵H。随后,特征量提取单元42将所获得的频率矩阵W提供给通信单元43作为在频率方面代表主声源的特征的主声源特征量。注意,在下文中假设作为主声源特征量的频率矩阵W也特别称为主声源频率矩阵WS。(空间频率分析器)随后,将描述空间频率分析器62和空间频率分析器82。这里,将主要描述空间频率分析器62。空间频率分析器62对由时间频率分析器61提供的时间频率谱S(nmic,nT,l)计算下面的公式(20),以执行空间频率变换,从而计算出空间频率谱SSP(nS,nT,l)。[数学公式20]SSP(nS,nT,l)=1MSΣms=0MS-1S,(mS,nT,l)exp(i2πmSnSMS)...(20)]]>注意,在公式(20)中MS表示在空间频率变换中使用的点的数量,并且表示为mS=0,…,MS-1。同时,S’(mS,nT,l)代表通过向空间频率谱S(nmic,nT,l)补零获得的零填充信号,并且i是纯虚数。此外,nS表示空间频率谱指数。在该实施例中,空间频率变换是根据逆离散傅里叶变换(IDFT)通过公式(20)的计算执行的。此外,当需要时,零补充可根据用于IDFT的点的数量MS正确地执行。在该实施例中,在麦克风阵列23-1获得的信号的空间采样频率设为fsS[Hz]。该空间采样频率fsS[Hz]是基于构成麦克风阵列23-1的麦克风之间的间隔确定的。例如,在公式(20)中,点的数量MS是基于空间采样频率fsS[Hz]确定的。此外,对于适用0≤mS≤Nmic-1的点mS,设置零填充信号S’(mS,nT,l)=时间频率谱S(nmic,nT,l),而适用Nmic≤mS≤MS-1的点mS,设置零填充信号S’(mS,nT,l)=0。通过上面描述的处理获得的空间频率谱SSP(nS,nT,l)表明通过包含在时间帧l中的时间频率nT的信号在空间形成了什么波形。空间频率分析器62向通信单元63提供空间频率谱SSP(nS,nT,l)。此外,通过执行与空间频率分析器62类似的处理,空间频率分析器82也基于由时间频率分析器81提供的时间频率谱,计算出空间频率谱,以提供给通信单元83。(空间频率合成器)同时,基于由空间频率分析器62通过通信单元64和通信单元63提供的空间频率谱SSP(nS,nT,l),空间频率合成器65计算下面的公式(21),以在用扬声器阵列26-1再现声场(波面)的空间区域中找到驱动信号DSP(mS,nT,l)。具体而言,驱动信号DSP(mS,nT,l)采用谱分割方法(SDM)计算出来。[数学公式21]DSP(mS,nT,l)=4iexp(-ikpwyref)H0(2)(kpwyref)SSP(nS,nT,l)...(21)]]>在这里,在公式(21)中kpw使用下面的公式(22)获得。[数学公式22]kpw=(ωc)2-kx2...(22)]]>注意,在公式(21)中,yref代表SDM中的参考距离,并且参考距离yref作为精确再现波面的位置。该参考距离yref是在与麦克风阵列23-1中的麦克风所顺序放置的方向垂直的方向上的距离。例如,这里的参考距离设置为yref=1[m]。然而,可以采用另外的值。此外,在公式(21)中,H0(2)代表一个Hankel函数,并且i代表纯虚数。同时,mS代表空间频率谱指数。进一步,在公式(22)中,c代表声音的速度,并且ω代表时间角频率。注意,虽然使用SDM计算出驱动信号DSP(mS,nT,l)的方法已经在这里作为示例描述了,驱动信号可以用另外的方法计算出来。此外,特别在“JensAdrens,SaschaSpors,"ApplyingtheAmbisonicsApproachonPlanarandLinearArraysofLoudspeakers",in2ndInternationalSymposiumonAmbisonicsandSphericalAcoustics”里详细的描述了SDM。随后,空间频率合成器65计算下面的公式(23),以在空间区域中对驱动信号DSP(mS,nT,l)执行逆空间频率变换,从而计算出时间频率谱D(nspk,nT,l)。在公式(23)中,离散傅里叶变换(DFT)作为逆空间频率变换执行。[数学公式23]D(nspk,nT,l)=ΣmS=0MS-1DSP(mS,nT,l)exp(-i2πmSnspkMS)...(23)]]>注意,在公式(23)中,nspk表示确定构成扬声器阵列26-1的扬声器的扬声器指数。同时,MS表示用于DFT的点的数量,并且i表示纯虚数。在公式(23)中,将作为空间频率谱的驱动信号DSP(mS,nT,l)被变换为时间频率谱,并且同时也执行了驱动信号的重采样。具体而言,空间频率合成器65以根据扬声器阵列26-1中的扬声器间隔的空间采样频率执行驱动信号的重采样(逆空间频率变换),以便获得用于扬声器阵列26-1的驱动信号(其使得能够再现声音拾取空间中的声场)。空间频率合成器65向主声源分离单元66提供如上所述获得的时间频率谱D(nspk,nT,l)。此外,通过执行与空间频率合成器65类似的处理,空间频率合成器85也计算出作为扬声器阵列26-2的驱动信号的时间频率谱,以提供给主声源分离单元86。(主声源分离单元)在主声源分离设备66中,由特征量提取单元42通过通信单元44和通信单元43提供的用作主声源特征量的主声源频率矩阵WS,被用于从由空间频率合成器65提供的时间频率谱D(nspk,nT,l)提取主声源信号。如在特征量提取单元42的情况下,该NTF在这里被用来提取主声源信号(主声源分量)。具体而言,主声源分离单元66计算下面的公式(24),以将时间频率谱D(nspk,nT,l)变换为非负谱VSP(j,k,l)。[数学公式24]VSP(j,k,l)=(D(j,k,l)×conj(D(j,k,l)))ρ…(24)在这里,在时间频率谱D(nspk,nT,l)中的扬声器指数nspk被信道指数j取代,而时间频率谱指数nT在此处被频率指数k取代。此外,在公式(24)中,conj(D(j,k,l))表示时间频率谱D(j,k,l)的复数共轭,并且ρ表示用于变换为非负值的控制值。用于变换为非负值的控制值ρ可以设置为任何类型的值,例如,用于变换为非负值的控制值在这里设置为ρ=1。通过计算公式(24)获得的非负谱VSP(j,k,l)在被表示为非负谱VSP的时间方向上被耦合,并且在NTF期间用作输入。此外,对如上所述获得的非负谱VSP,在使用在下面的公式(25)至公式(27)中所示的更新公式更新信道矩阵Q、频率矩阵W和时间矩阵H时,主声源分离单元66将成本函数最小化,从而找到优化的信道矩阵Q、优化的频率矩阵W和优化的时间矩阵H。[数学公式25][数学公式26][数学公式27]注意,这里的计算是在频率矩阵W包括作为其中一部分的主声源频率矩阵WS的前提下执行的,并且因此,在在公式(26)中示出的频率矩阵W的更新期间,除了主声源频率矩阵WS的元素被专门更新。因此,在频率矩阵W被更新时,对应于包括在频率矩阵W中作为元素的主声源频率矩阵WS的部分没有更新。一旦,优化的信道矩阵Q、优化的频率矩阵W和优化的时间矩阵H通过上面所述的计算被获得,主声源分离单元66从这些矩阵中提取对应于主声源的元素和对应于辅助声源的元素,以将拾取的声音分离成主声源分量和辅助声源分量。具体而言,主声源分离单元66将优化的频率矩阵W中除了主声源频率矩阵WS的元素设置为辅助声源频率矩阵WN。在将优化的信道矩阵Q中除了主声源信道矩阵QS的元素设置为辅助声源信道矩阵QN时,主声源分离单元66还从优化的信道矩阵Q提取对应于主声源频率矩阵WS的元素作为主声源信道矩阵QS。辅助声源信道矩阵QN是辅助声源的分量。同样,在将优化的时间矩阵H中除了主声源时间矩阵HS元素设置为辅助声源时间矩阵HN时,主声源分离单元66还从优化的时间矩阵H提取对应于主声源频率矩阵WS的元素作为主声源时间矩阵HS。辅助声源时间矩阵HN是辅助声源的分量。在这里,在信道矩阵Q和时间矩阵H中对应于主声源频率矩阵WS的元素表示在图4的示例中示出的基谱Vp’中的,包括主声源频率矩阵WS的元素的基谱Vp’的元素。主声源分离单元66进一步使用Wiener滤波器从通过上面描述的处理获取的矩阵组中提取主声源。具体而言,主声源分离单元66计算下面的公式(28),以基于主声源信道矩阵QS、主声源频率矩阵WS和主声源时间矩阵HS的各自元素,找到主声源的基谱VS’的各个元素。[数学公式28]vS{jkl},=ΣpqS{jp}wS{kp}hS{lp}...(28)]]>同样,主声源分离单元66计算下面的公式(29),以基于辅助声源信道矩阵QN、辅助声源频率矩阵WN和辅助声源时间矩阵HN的各自元素,找到辅助声源的基谱VN’的各个元素。[数学公式29]vN{jkl},=ΣpqN{jp}wN{kp}hN{lp}...(29)]]>基于已经获得的主声源的基谱VS’和辅助声源的基谱VN’,主声源分离单元66进一步计算下面的公式(30)和公式(31),来计算出主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l)。注意,在公式(30)和公式(31)中,符号“·”表示帧对每个元素的乘法,并且对每个元素做除法计算。[数学公式30]DS(j,k,l)=VS,VS,+VN,·D(j,k,l)...(30)]]>[数学公式31]DN(j,k,l)=VN,VS,+VN,·D(j,k,l)...(31)]]>在公式(30)中,时间频率谱D(nspk,nT,l)中的主声源分量(即时间频率谱D(j,k,l))被单独提取以设置为主声源时间频率谱DS(j,k,l)。随后,主声源时间频率谱DS(j,k,l)中的信道指数j和频率指数k分别被原始扬声器指数nspk和原始时间频率谱指数nT替换,从而被设置为主声源时间频率谱DS(nspk,nT,l)。同样,在公式(31)中,时间频率谱D(j,k,l)中的辅助声源分量被单独提取以设置为辅助声源时间频率谱DN(j,k,l)。随后,辅助声源时间频率谱DN(j,k,l)中的信道指数j和频率指数k分别被原始扬声器指数nspk和原始时间频率谱指数nT取代,从而被设置为辅助声源时间频率谱DN(nspk,nT,l)。主声源分离单元66将通过上面描述的计算获得的主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l)提供给主声源加强单元67。此外,主声源分离单元86也执行与主声源分离单元66类似的处理,以将所获的主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l)提供给主声源减弱单元87。(主声源加强单元)主声源加强单元67使用由主声源分离单元66提供的主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l),从而生成主声源加强时间频率谱DES(nspk,nT,l)。具体而言,主声源加强单元67计算下面的公式(32),以计算出主声源加强时间频率谱DES(nspk,nT,l),其中时间频率谱D(nspk,nT,l)中的主声源时间频率谱DS(nspk,nT,l)的分量被加强。[数学公式32]DES(nspk,nT,l)=αDS(nspk,nT,l)+DN(nspk,nT,l)…(32)注意,在公式(32)中,α代表表示主声源时间频率谱DS(nspk,nT,l)的加强程度的权重系数,其中权重系数α设置为大于1.0的系数。因此,在公式(32)中,对主声源时间频率谱用权重系数α进行加权,并且然后加上辅助声源时间频率谱,从而获得主声源加强时间频率谱。即执行加权加法。主声源加强单元67向时间频率合成器68提供通过计算公式(32)获得的主声源加强时间频率谱DES(nspk,nT,l)。(主声源减弱单元)主声源减弱单元87使用由主声源分离单元86提供的主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l),从而生成主声源减弱时间频率谱DEN(nspk,nT,l)。具体而言,主声源减弱单元87计算下面的公式(33),以计算出主声源减弱时间频率谱谱DEN(nspk,nT,l),其中加强了时间频率谱D(nspk,nT,l)中的辅助声源时间频率谱DN(nspk,nT,l)的分量。[数学公式33]DEN(nspk,nT,l)=DS(nspk,nT,l)+αDN(nspk,nT,l)…(33)注意,在公式(33)中,α代表表示辅助声源时间频率谱DN(nspk,nT,l)的加强程度的权重系数,其中权重系数α设置为大于1.0的系数。注意,公式(33)中的权重系数α可以是与公式(32)中的权重系数α相同的值,或者作为另一个选择,也可以是与其不同的值。在公式(33)中,对辅助声源时间频率谱用权重系数α进行加权,并且然后加上主声源时间频率谱,从而获得主声源减弱时间频率谱。即执行加权加法来加强辅助声源时间频率谱,并因此,主声源时间频率谱被相对减弱。主声音减弱单元87将通过计算公式(33)获得的主声源减弱时间频率谱DEN(nspk,nT,l)提供给时间频率合成器88。(时间频率合成器)时间频率合成器68计算下面的公式(34),从而对由主声源加强单元67提供的主声源加强时间频率谱DES(nspk,nT,l)执行时间频率合成,以获得输出帧信号dfr(nspk,nfr,l)。虽然逆短时傅里叶变换(ISTFT)此处作为时间频率合成,但是可以采用在时间频率分析器61执行的任何相当于时间频率变换(正变换)的逆变换的变换。数学公式[34]dfr(nspk,nfr,l)=1MTΣmT=0MT-1D,(nspk,mT,l)exp(i2πnfrmTMT)...(34)]]>注意,公式(34)中的D’(nspk,mT,l)是使用下面的公式(35)获得的。数学公式[35]D,(nspk,mT,l)=DES(nspk,mT,l)mT=0,...,NT-1conj(DES(nspk,MT-mT,l))mT=NT,...,MT-1...(35)]]>在公式(34)中,i代表纯虚数并且nfr代表时间指数。此外,在公式(34)和公式(35)中,MT代表用于ISTFT的点的数量,并且nspk代表扬声器指数。进一步,时间频率合成器68用窗函数wT(nfr)乘以获得的输出帧信号dfr(nspk,nfr,l)并执行重叠相加,以执行帧合成。例如,帧合成通过计算下面的公式(36)执行,从而找到输出信号d(nspk,t)。数学公式[36]dcurr(nspk,nfr+|Nfr)=dfr(nspk,nfr,|)wT(nfr)+dprev(nspk,nfr+|Nfr)…(36)注意,与帧时间频率分析器61使用的窗函数相同的窗函数在此处用作窗函数wT(nfr),其中将输出帧信号dfr(nspk,nfr,l)乘以窗函数wT(nfr)。然而,在其他的窗(例如Hamming窗)的情况下,可以采用矩形窗口。此外,在公式(36)中,dprev(nspk,nfr+lNfr)和dcurr(nspk,nfr+lNfr)都代表输出信号d(nspk,t),其中dprev(nspk,nfr+lNfr)代表更新前的值,而dcurr(nspk,nfr+lNfr)代表更新后的值。时间频率合成器68将如上面所述获得的输出信号d(nspk,t)提供给扬声器阵列26-1作为扬声器驱动信号。此外,通过执行与时间频率合成器68点类似的处理,时间频率合成器88还基于由主声源减弱单元87提供的主声源减弱时间频率谱DEN(nspk,nT,l)产生扬声器驱动信号,以提供给88扬声器阵列26-2。<声场再现处理的描述>下一步,将描述上面描述的由主声源加强声场再现单元11执行的处理的流程。一旦被用来在波面相对于声音拾取空间中的声音拾取声音,主声源加强声场再现单元11执行声场再现处理,其中波面的声音被拾取并且声场被再现。在下文中,参考图5的流程图,将描述主声源加强声场在线处理单元11进行的声场再现处理。在步骤S11,麦克风21从主声源拾取声音,即在声音拾取空间中获取主声源的声音,并将由此获得的声音拾取信号提供给时间频率分析器41。在步骤S12,麦克风阵列23-1从声音拾取空间中的主声源拾取声音,并将由此获得的声音拾取信号提供给时间频率分析器61。在步骤S13,麦克风阵列23-2从声音拾取空间中的辅助声源拾取声音,并将由此获得的声音拾取信号提供给时间频率分析器81。注意,在更多的细节中,步骤S11至步骤S13的处理是同时进行的。在步骤S14,时间频率分析器41分析由麦克风21提供的声音拾取信号中的时间频率信息,即主声源上的时间频率信息。具体而言,时间频率分析器41对声音拾取信号执行时间帧分割,并用窗函数乘以由此获得的输入帧信号,以计算出窗函数应用信号。时间频率分析器41还对窗函数应用信号执行时间频率变换,并将由此获得的时间频率谱提供给特征量提取单元42。具体而言,计算公式(4)并计算出时间频率谱S(nmic,nT,l)。在步骤S15,基于由时间频率分析器41提供的时间频率谱,特征量提取单元42提取主声源特征量。具体而言,通过计算公式(5),并在同一时间计算公式(16)至公式(18),特征量提取单元42优化信道矩阵Q、频率矩阵W和时间矩阵H,并向通信单元43提供通过优化获得的主声源频率矩阵WS作为主声源特征量。在步骤S16,通信单元43发送由特征量提取单元42提供的主声源特征量。在步骤S17,时间频率分析器61分析由麦克风阵列23-1提供的声音拾取信号中的时间频率信息,即主声源上的时间频率信息,并将由此获得的时间频率谱提供给空间频率分析器62。在步骤S17,执行与步骤S14类似的处理。在步骤S18,空间频率分析器62对由时间频率分析器61提供的时间频率谱执行空间频率变换,并向通信单元63提供由此获得的空间频率谱。具体而言,在步骤S18计算公式(20)。在步骤S19,通信单元63发送由空间频率分析器62提供的空间频率谱。在步骤S20,时间频率分析器81分析由麦克风阵列23-2提供的声音拾取信号中的时间频率信息(即辅助声源信号上的时间频率信息),并将由此获得的时间频率谱提供给空间频率分析器82。在步骤S20,执行与步骤S14类似的处理。在步骤S21,空间频率分析器82对由时间频率分析器81提供的时间频率谱执行空间频率变换,并将由此获得的空间频率谱提供给通信单元83。具体而言,在步骤S21计算公式(20)。在步骤S22,通信单元83发送由空间频率分析器82提供的空间频率谱。在步骤S23,通信单元44接收由通信单元43传送的主声源特征量,以提供给主声源分离单元66和主声源分离单元86。在步骤S24,通信单元64接收由通信单元63传送的主声源的空间频率谱,以提供给空间频率合成器65。在步骤S25,空间频率合成器65基于由通信单元64提供的空间频率谱在空间区域中找到驱动信号,并且然后对该驱动信号执行逆空间频率变换,从而将由此获得的时间频率谱提供给主声源分离单元66。具体而言,空间频率合成器65计算上述公式(21),从而在空间区域中找到驱动信号,并另外计算公式(23)以计算出时间频率谱D(nspk,nT,l)。在步骤26,基于由通信单元44提供的主声源特征量,主声源分离单元66将由空间频率合成器65提供的时间频率谱分解为主声源分量和辅助声源分量,以提供给主声源加强单元67。具体而言,主声源分离单元66计算公式(24)至公式(31),并且然后计算出主声源时间频率谱DS(nspk,nT,l)和辅助声源时间频率谱DN(nspk,nT,l),以提供给主声源加强单元67。在步骤S27,主声源加强单元67基于由主声源分离单元66提供的主声源时间频率谱和辅助声源谱计算公式(32),以加强主声源分量并将由此获得的主声源加强时间频率谱提供给时间频率合成器68。在步骤S28,时间频率合成器68执行由主声源加强单元67提供的主声源加强时间频率谱的时间频率合成。具体来说,时间频率合成器68计算公式(34)以从主声源加强时间频率谱计算出输出帧信号。此外,时间频率合成器68用窗函数乘以输出帧信号,以计算公式(36)并通过帧合成计算出输出信号。时间频率合成器68将如上面所述获得的输出信号提供给扬声器阵列26-1作为扬声器驱动信号。在步骤S29,通信单元84从通信单元83接收辅助声源的空间频率谱,来提供给空间频率合成器85。在步骤S30,空间频率合成器85基于由通信单元84提供的空间频率谱在空间区域中找到驱动信号,并且然后对该驱动信号执行逆空间频率变换,以将由此获得的时间频率谱提供给主声源分离单元86。具体而言,在步骤S30中执行与步骤S25中的类似的处理。在步骤S31,基于由通信单元44提供的主声源特征量,主声源分离设备86将由空间频率合成器85提供的时间频率谱分离为主声源分量和辅助声源分量,以便提供给主声源减弱单元87。在步骤S31,执行与步骤S26类似的处理。在步骤S32,主声源减弱单元87基于由主声源分离单元86提供的主声源时间频率谱和辅助声源谱计算公式(33),以减弱主声源分量,并将由此获得的主声源减弱时间频率谱提供给获得时间频率合成器88。在步骤S33,时间频率合成器88对由主声源减弱单元87提供的主声源减弱时间频率谱执行频率合成,并将由此获得的输出信号提供给扬声器阵列26-2作为扬声器驱动信号。在步骤S33,执行与步骤S28的类似的处理。在步骤S34,扬声器阵列26回放声音。具体而言,扬声器阵列26-1基于由时间频率合成器68提供的驱动信号回放声音。因此,主声源的声音从扬声器阵列26-1输出。此外,扬声器阵列26-2基于由时间频率合成器88提供的驱动信号回放声音。因此,辅助声源的声音从扬声器阵列26-2输出。当主声源和辅助声源的声音如上所述的输出的时候,在声音拾取空间中的声场被再现在再现空间中。当声音拾取中间中的声场被再现的时候,完成了声场再现处理。用目前为止描述的方式,主声源加强声场再现单元11使用主声源特征量,来将通过拾取声音获得的时间频率谱分离为主声源分量和辅助声源分量。随后,主声源加强声场再现单元11加强通过主要从主声源拾取声音获得的时间频率谱的主声源分量,以产生扬声器驱动信号,并且同时减弱通过主要从辅助声源拾取声音获得的时间频率谱的主声源分量,以产生扬声器驱动信号。如目前为止的描述,主声源分量被适当地加强,同时当产生用于扬声器阵列26的扬声器驱动信号时主声源分量被适当地减弱,因此在声音拾取空间中的特定声场可以通过简单的处理进一步精确地再现。<第一实施例的第一变化><主声源加强声场再现单元的示例性配置>注意,上面的描述使用了一个示例,其中一个麦克风阵列23被用作主声源线型麦克风阵列和辅助声源线型麦克风阵列的每一个。然而,多个麦克风阵列可以作为主声源线型麦克风阵列或辅助声源线型麦克风阵列。在这种情况下,例如,主声源加强声场再现单元被配置为如图6所示。注意,在图6中,对应于图3的情况下的构成部件是用相同的参考数字表示的,并且其描述将适当的省略。如图6所示的主声源加强声场再现单元141由麦克风21、主声源获取单元22、麦克风阵列23-1至麦克风阵列23-4、主声源驱动信号产生器24、主声源驱动信号产生器151、辅助声源驱动信号产生器25、辅助声源驱动信号产生器152和扬声器阵列26-1至扬声器阵列26-4构成。在该示例中,四个麦克风阵列(即麦克风阵列23-1至麦克风阵列23-4)设置在声音拾取空间中的正方形形状中。此外,两个麦克风阵列,即麦克风阵列23-1和麦克风阵列23-3用作主声源线型麦克风阵列,而其余的两个麦克风阵列,即麦克风阵列23-2和麦克风阵列23-4用作辅助声源线型麦克风阵列。同时,分别对应于这些麦克风阵列23-1至23-4的扬声器阵列26-1至扬声器阵列26-4设置在再现空间中的正方形形状中。如在图3的情况下,通过采用由主声源获取单元22提供的主声源特征量,主声源驱动信号产生器24从由麦克风阵列23-1提供的声音拾取信号产生用于主要回放来自主声源的声音的扬声器驱动信号,以提供给扬声器阵列26-1。如图3所示的类似于主声源驱动信号产生器24的配置被设置用于主声源驱动信号产生器151。通过采用由主声源获取单元22提供的主声源特征量,主声源驱动信号产生器151从由麦克风阵列23-3提供的声音拾取信号产生用于主要回放来自主声源的声音的扬声器驱动信号,从而提供给扬声器阵列26-3。因此,基于扬声器驱动信号,在扬声器阵列26-3中再现来自主声源的声音。同时,如在图3的情况下,通过采用由主声源获取单元22提供的主声源特征量,辅助声源驱动信号产生器25从由麦克风阵列23-2提供的声音拾取信号产生,用于主要回放来自辅助声源的声音的扬声器驱动信号,以提供给扬声器阵列26-2。类似于图3所示的辅助声源驱动信号产生器25的配置被设置用于辅助声源驱动信号产生器152。通过采用由主声源获取单元22提供的主声源特征量,辅助声源驱动信号产生器152从由麦克风阵列23-4提供的声音拾取信号产生用于主要回放来自辅助声源的声音的扬声器驱动信号,来提供给扬声器阵列26-4。因此,基于扬声器驱动信号,来自辅助声源的声音在扬声器阵列26-4上再现。此外,一系列上面描述的处理也可以用硬件执行,也可以通过软件执行。当该系列的处理由软件执行时,构成软件的程序安装在计算机中。在这里,当安装各种类型的程序(例如,通用计算机)的时候,计算机包括内置专用硬件的计算机和能够执行各种类型功能的计算机。图7是表示用程序执行前述系列的处理掉计算机的示例性硬件配置的框图。在计算机中,中央处理单元(CPU)501、只读存储器(ROM)502和随机读取存储器(RAM)503通过总线504互连。此外,输入/输出接口505连接到总线504。输入单元506、输出单元507、记录单元508、通信单元509和驱动器510连接到输入/输出接口505。输入单元506包括键盘、鼠标、麦克风和图像拾取单元。输出单元507包括显示器和扬声器。记录单元508包括硬盘和非易失性存储器。通信单元509包括网络接口。驱动器510驱动可移动介质511,例如磁盘、光盘、磁光盘或半导体存储器。在如上所述配置的计算机中,例如,上述系列的处理用这样的方式进行,CPU501通过输入/输出接口505和总线504将记录在记录单元508中的程序加载到RAM503以执行。例如,由计算机(CPU501)执行的程序可以通过被记录在用作包介质或类似的可移动介质511中提供。此外,该程序可以通过有线或无线传输介质(例如局域网、互联网或数字卫星广播)来提供。在计算机中,该程序可以通过在驱动器510中安装可移动介质511经由输入/输出接口505安装到记录单元508。当被通信单元509接收时,该程序也可以通过有线或无线传输介质安装到记录单元508。作为另一种选择的方式,该程序可以提前安装到ROM502或记录单元508。请注意,由计算机执行的程序可以是其中处理是根据本说明书描述的顺序按时间顺序执行的程序,或者作为另一个选择,可以是其中处理是并行或在必要的时间(例如,当调用时)执行的程序。此外,根据本技术的实施例不限于上述实施例和可以不脱离本技术的范围的各种变形例。例如,本技术可以采用云计算的配置,其中在一个功能被划分和分配给多个设备,以通过网络中其中协调处理。此外,在上述流程图中所描述的各个步骤可以由多个设备的每个分担执行,以及由单一的设备进行。进一步,当一个步骤中包括多个处理时,包括在一个步骤中的多个处理可以通过多个设备的每个分担执行,以及由单一的设备进行。此外,本技术中描述的效果只是作为示例,并且限制而不被解释为限制。可能有另外的效果。此外,本技术可以如下面的描述配置。(1)一种语音的声场再现设备,包括:加强单元,所述加强单元基于从通过使用声音拾取单元从主声源拾取声音而获取的信号提取的特征量,加强通过使用放置在所述主声源前面的第一麦克风阵列拾取声音而获得的第一声音拾取信号的主声源分量。(2)根据(1)的声场再现设备,进一步包括:减弱单元,所述减弱单元基于所述特征量,减弱通过利用放置在辅助声源前面的第二麦克风阵列拾取声音而获取的第二声音拾取信号的所述主声源分量。(3)根据(2)的声场再现设备,其中,所述加强单元基于所述特征量,将所述第一声音拾取信号分离为所述主声源分量和辅助声源分量,并加强所分离的主声源分量。(4)根据(3)的声场再现设备,其中,所述减弱单元基于所述特征量,将所述第二声音拾取信号分离成所述主声源分量和所述辅助声源分量,并加强所分离的辅助声源分量以减弱所述第二声音拾取信号的所述主声源分量。(5)根据(3)或(4)的声场再现设备,其中,所述加强单元使用非负张量分解,将所述第一声音拾取信号分离成所述主声源分量和所述辅助声源分量。(6)根据(4)或(5)的声场再现设备,其中,所述减弱单元使用所述非负张量分解,将所述第二声音拾取信号分离成所述主声源分量和所述辅助声源分量。(7)根据任(1)到(6)中任何一个声场再现设备,其中在所述声场再现设备中,多个所述加强单元中的每一个对应于多个所述第一麦克风阵列中的每一个设置。(8)根据(2)到(6)中任何一个声场再现设备,其中在所述声场再现设备中,多个所述减弱单元中的每一个对应于多个所述第二麦克风阵列中的每一个设置。(9)根据(2)到(6)中任何一个声场再现设备,其中,所述第一麦克风阵列设置在连接由所述第一麦克风阵列和所述第二麦克风阵列包围的空间和所述主声源的直线上。(10)根据(1)到(9)中任何一个声场再现设备,其中,所述声音拾取单元设置在所述主声源的附近。(11)一种声场再现方法,包括:基于从通过使用声音拾取单元从主声源拾取声音而获得的信号提取的特征量,加强通过使用放置在所述主声源前面的第一麦克风阵列拾取声音而获得的第一声音拾取信号的主声源分量的步骤。(12)一种使计算机执行处理的程序,包括:基于从通过使用声音拾取单元从主声源拾取声音而获得的信号提取的特征量,加强通过使用放置在所述主声源前面的第一麦克风阵列拾取声音而获得的第一声音拾取信号的主声源分量的步骤。参考符号列表11主声源加强声场再现单元42特征量提取单元66主声源分离单元67主声源加强单元86主声源分离单元87主声源减弱单元当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1