一种音频分组采样传输再重组的方法与流程
本发明属于数据传输技术领域,尤其是在有交互应用的场景中进行的对音频传输有较高需求的系统。
背景技术:
在当今互联网+社会,人们通过互联网来观看视频,直播等等已经变得非常频繁和平常了。互联网上的音频传输对实时性和流畅度要求很高,尤其是在交互式应用场景(如视频通话、视频会议等),音频的卡顿会让人很敏感的察觉到。传统的实现方式为采集到pcm单元数据后,进行压缩编码及传输,播放端再进行解码播放。当有一帧数据阻塞或者丢失后,会有明显的卡顿,表现出较差的用户体验。
鉴于此,迫切的需要有一种音频分组采样传输再重组的方法来解决现有技术存在的问题和风险。本发明就是用来解决此类问题的,本专利提出的这种分组方式可以在只收到一帧分组后的音频数据后,还原出大部分原始语音效果,从而减少阻塞或丢失的几率。而在收到完整分组数据后,也可以完整的还原音质,最大程度的保障了客户体验。
技术实现要素:
本发明的目的就是提供一种音频分组采样传输再重组的方法,来解决现有技术中存在的诸多问题。
为了实现本发明的目的,本发明提供了一种音频分组采样传输再重组的方法,所述方法包括如下步骤:
步 骤1:将采集端采集到的数据缓存到CaptureBuffer中。
步 骤 2: 将单位采样CaptureBuffer进行拆分,奇数位采样数据存到CaptureBuffer1中,偶数位采样数据存到CaptureBuffer2中。这两个拆分Buffer均包含相同个数的采样点。
步 骤 3: 准备两个编码器,对这两个CaptureBuffer1和CaptureBuffer2音频数据进行分开压缩编码成EncoderBuffer1和EncoderBuffer2,再进行分开传输。
步 骤 4: 接收端准备两个解码器,将接收到的EncoderBuffer1或EncoderBuffer2分别解码成DecoderBuffer1或DecoderBuffer2。
1. 若EncoderBuffer1和EncoderBuffer2均收到,则将这两个解码buffer重组成PlayBuffer,奇数位用DecoderBuffer1填充,偶数位用DecoderBuffer2填充。
2.若EncoderBuffer1或EncoderBuffer2只收到一个,则将这一个解码后的buffer数据做扩充,并保存到PlayBuffer中。假如收到的是EncoderBuffer1,则将DecoderBuffer1相邻两个采样点数据做平均,再将这个数据作为新的采样点插入到相邻的两个采样点中间,最后一个采样点直接作拷贝;假如收到的是EncoderBuffer2,最前面的一个采样点直接作拷贝,再将DecoderBuffer2相邻两个采样点数据做平均,把这个数据作为新的采样点插入到相邻的两个采样点中间。重组后的PlayBuffer包含原始的相同数量的采样点。
步 骤 5: 将生成的PlayBuffer送到播放器中播放。
本发明,与现有技术相比,通过使用多条链路传输音频数据,在不通的应用场景中可以提供更快的传输速率或者更稳定的传输质量。比起现有技术,能更好的避免因数据阻塞等造成的音频卡顿问题,从而能更好的提高用户体验。
附图说明
图1是本发明的方法流程图。
图2是本发明的实例1示意图。
具体实例方式
为了使本发明的目的,技术方案及有益效果更加清楚明白,以下结合实例,对本发明进行进一步详细说明。应当理解为此处所描述的具体实例仅仅用以解释本发明,并不用于限制本发明的保护范围。
如图1 所示,本发明提供了一种音频分组采样传输再重组的方法,所述方法包括如下步骤:
步骤S101,将采集端采集到的数据缓存到CaptureBuffer中。假设每次采集包含256个采样点。
步骤S102,将单位采样CaptureBuffer进行拆分,奇数位采样数据存到CaptureBuffer1中,偶数位采样数据存到CaptureBuffer2中。这两个拆分Buffer均包含128个采样点。
步骤S103,准备两个编码器(采样率为8K、采样位数16、单声道),对这两个CaptureBuffer1和CaptureBuffer2音频数据进行分开压缩编码成EncoderBuffer1和EncoderBuffer2,再进行分开传输。
步骤S104,接收端准备两个解码器(采样率为8K、采样位数16、单声道),将接收到的EncoderBuffer1或EncoderBuffer2分别解码成DecoderBuffer1或DecoderBuffer2,各包含128个采样点。
1. 若EncoderBuffer1和EncoderBuffer2均收到,则将这两个解码buffer重组成PlayBuffer,奇数位用DecoderBuffer1填充,偶数位用DecoderBuffer2填充。
2.若EncoderBuffer1或EncoderBuffer2只收到一个,则将这一个解码后的buffer数据做扩充,并保存到PlayBuffer中。假如收到的是EncoderBuffer1,则将DecoderBuffer1相邻两个采样点数据做平均,再将这个数据作为新的采样点插入到相邻的两个采样点中间,最后一个采样点直接作拷贝;假如收到的是EncoderBuffer2,最前面的一个采样点直接作拷贝,再将DecoderBuffer2相邻两个采样点数据做平均,把这个数据作为新的采样点插入到相邻的两个采样点中间。重组后的PlayBuffer包含原始的256个采样点。
步骤S105,将生成的PlayBuffer送到播放器中播放(16K采样率、采样位数16、单声道)。
以上所述仅是本发明的优选方式,应当指出,不局限于将采样点分两组传输,只要是采用分组传输的策略都是本发明的保护范围。还应当指出对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
如图2所示,具体实例。
以下介绍本发明的一种音频分组采样传输再重组的方法。
实例1
如图2所示,假设应用场景为一个对实时传输要求很高的网络会议,按着步骤S101的要求,将采集端采集到的数据缓存到CaptureBuffer中。假设每次采集包含256个采样点。
根据步骤S102,将单位采样CaptureBuffer进行拆分,奇数位采样数据存到CaptureBuffer1中,偶数位采样数据存到CaptureBuffer2中。这两个拆分Buffer均包含128个采样点。
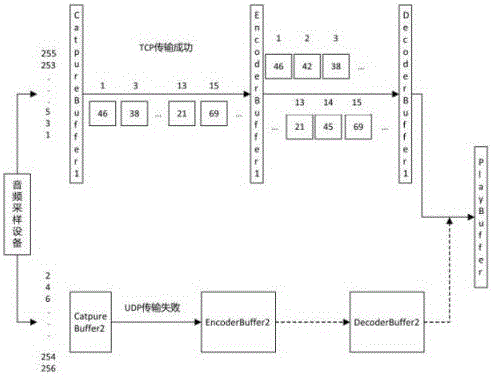
按着步骤S103,准备两个编码器(采样率为8K、采样位数16、单声道),对这两个CaptureBuffer1和CaptureBuffer2音频数据进行分开压缩编码成EncoderBuffer1和EncoderBuffer2,其中一路采用TCP的方式传输,另外一路采用UDP的方式传输。
按着步骤S104,接收端准备两个解码器(采样率为8K、采样位数16、单声道),分别从TCP 和UDP的线路接收数据。将接收到的EncoderBuffer1或EncoderBuffer2分别解码成DecoderBuffer1或DecoderBuffer2,各包含128个采样点。本例中假设通过TCP线路传输的数据全部收到了EncoderBuffer1中,UDP传输的数据丢失未到达EncoderBuffer2。本例以奇数位1、3、13、15作为例子,假设他们对应的采样数值为46、38、21、69。将EncoderBuffer1中的数据解码后放入DecodeBuffer1中,取相邻两个点的平均值座位新的采样点插入到这两个相邻采样点的中间,最后一个采样点直接拷贝。此例中如图2所示,将奇数位1和奇数位3的采样数值做平均,得出了(46+38)/2=42作为偶数位2的填充数值,同样的,奇数位13和奇数15的采样值做平均,得出(21+69)/2=45做完偶数位14的填充数。通过此方法,将TCP这一路传过来的128个奇数位采样点,补充为本来的256个采样点并放入PlayBuffer中。
按着步骤S105,将生成的PlayBuffer送到播放器中播放(16K采样率、采样位数16、单声道)。
- 还没有人留言评论。精彩留言会获得点赞!