一种云数据中心的数据处理方法与流程
本发明涉及数据处理技术领域,特别是一种云数据中心的数据处理方法。
背景技术:
云数据中心的数据处理问题是其需解决的主要问题之一。云数据中心的数据处理过程中,数据到达数据中心,首先进入任务队列,新到达的任务数据作为生产者不停的放入任务队列,处理任务的虚拟机作为消费者从任务队列中取出数据包进行处理。该过程可以看作一个生产者消费者问题。
生产者消费者问题描述了两个共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。但仍存在这样的问题:生产者会在缓冲区满时加入数据,消费者会在缓冲区中空时消耗数据。
目前的解决方法,在处理数据包的过程中,会出现消费者对数据包的重复处理,造成资源和能耗的浪费。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种云数据中心的数据处理方法,本发明能加快消费者对数据包的处理。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种云数据中心的数据处理方法,包括以下步骤:
步骤一、确定生产者消费者模型,该模型为环形队列;
步骤二、生产者按顺序从环形队列的初始位置逐个放入数据包,同时将数据包的信息赋值到数据单元packet_unit中,数据单元packet_unit是用来保存每个数据包的包号、长度和在环形内存队列中的位置信息;
步骤三、判断策略执行条件并执行相应的策略;具体如下:
若当前要处理的数据包的位置小于队列长度且当前队尾收到的数据包号已经大于当前需要处理的数据包号,此时处理从g_current+M 到queue_size-1的数据包;其中,共享元素g_current用来表示当前生产者生产数据包在队列中的位置,queue_size表示环形队列长度,M为数据处理的间隔步数;
若当前要处理的数据包的位置小于队列长度且当前收到的数据包号已经大于当前需要处理的数据包号,此时处理从0 到g_current的数据包;
若当前要处理的数据包的位置已经大于或等于队列长度,此时数据包的位置取(g_current+ M) % queue_size;若当前需要处理的数据包号已经大于当前已经处理的数据包号,所以此时处理从(g_current+ M) % queue_size 到g_current的数据包。
作为本发明所述的一种云数据中心的数据处理方法进一步优化方案,M=1。
作为本发明所述的一种云数据中心的数据处理方法进一步优化方案,M=1是表明生产者和消费的处理速度相同。
作为本发明所述的一种云数据中心的数据处理方法进一步优化方案,M=2。
作为本发明所述的一种云数据中心的数据处理方法进一步优化方案,M=3。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)根据消费者的三种处理策略,在单生产者和双消费者的实验环境下,消费者可以迅速找到当前没有处理过的数据包,进而加快数据包的处理速度;
(2)实际情况中,通过queue_size和M值的设定,可以尽可能的减少消费者对数据包的重复处理,用最小的消耗达到高速处理数据的目的;
(3)本发明的关键点是:多个消费者根据不同情况选择对应策略处理环形队列中的数据,以最小的重复处理消耗达到高速处理数据包的目的;
(4)本发明提出了基于环形队列的多消费者数据处理策略,分三种情况对多消费者的数据处理问题,进行了分析,并提出相应的数据处理策略;本发明所提出的数据处理方法能降低重复数据包的处理次数,提高多消费者数据处理的效率。
附图说明
图1为本发明环形队列示意图;
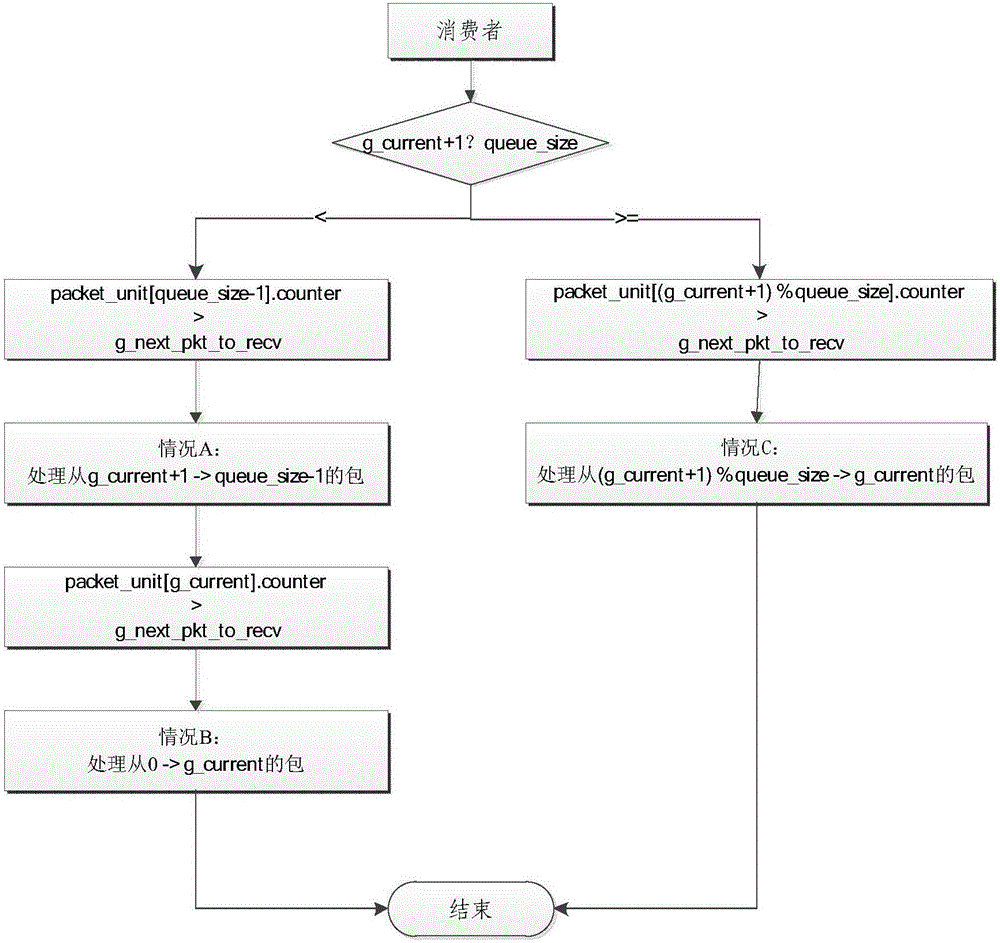
图2为本发明策略方法的消费者处理流程图;
图3为本发明策略方法的情况A示意图;
图4为本发明策略方法的情况B示意图;
图5为本发明策略方法的情况C示意图;
图6是本方法的流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
目前解决本发明背景技术中提出的问题,就必须让生产者在缓冲区满时休眠(要么干脆就放弃数据),等到下次消费者消耗缓冲区中的数据的时候,生产者才能被唤醒,开始往缓冲区添加数据。同样,也可以让消费者在缓冲区空时进入休眠,等到生产者往缓冲区添加数据之后,再唤醒消费者。通常采用进程间通信的方法解决该问题,常用的方法有信号灯法等。如果解决方法不够完善,则容易出现死锁的情况。出现死锁时,两个线程都会陷入休眠,等待对方唤醒自己。该问题也能被推广到多个生产者和消费者的情形。
图6是本方法的流程图,一种云数据中心的数据处理方法,所述方法包括如下步骤:
I、确定生产者消费者模型;
II、判断策略执行条件;
III、执行相应的策略;
IV、执行完毕;
优选的,所述步骤I包括采用了基于环形的队列。
首先介绍本发明中涉及的几个基础定义和问题。
1)定义环形数据队列,队列长度为queue_size。此数值由实际需要和系统性能决定。
2)定义共享元素g_current,用来表示当前生产者生产数据包在队列中的位置。
3)无锁性,即是为了保证生产者和消费者不同时处理同一块内存区域。所以消费者每次处理环形队列的g_current+M位置来实现无锁性。M值的大小受生产者和消费者的处理影响。本发明采取理想情况M=1,表明生产者和消费的处理速度相同。
4)定义数据单元packet_unit,用来保存每个数据包的包号counter、长度len和在环形内存队列中的位置信息x。
5)定义当前需处理数据包的编号为g_next_pkt
生产者按顺序从环形队列的初始位置逐个放入数据包,同时把数据包的信息赋值到数据单元packet_unit中,如下图1。
优选的,所述步骤II中的策略执行条件包括两种类型,三种情况;
本发明把消费者处理数据的模式分为两类,共三种情况,根据不同情况处理环形队列中不同位置的数据,以达到加速处理数据的目的。图2为消费者处理流程图。
一类:g_current+1 < queue_size
此类情况即当前要处理的数据包的位置小于队列长度。然后分别判断情况A和B进行数据处理。
情况A(packet_unit[queue_size-1].counter > g_next_pkt)
这表示当前队尾收到的数据包号已经大于当前需要处理的数据包号,此情况说明当前最小的包号(即当前需要处理的包号)在队列的后半段。所以此时处理从g_current+1 到queue_size-1的数据包,如下图3。
情况B(packet_unit[g_current].counter > g_next_pkt)
这表示当前收到的数据包号已经大于当前需要处理的数据包号,此情况说明当前最小的包号(即当前需要处理的包号)在队列的前半段。所以此时处理从0 到g_current的数据包,如下图4。
二类:g_current+1 >= queue_size
此类情况表明当前要处理的数据包的位置已经大于等于队列长度,此时包的位置取(g_current+1) % queue_size。
情况C(packet_unit[(g_current+1) % queue_size].counter > g_next_pkt)
这表示当前需要处理的数据包号已经大于当前已经处理的数据包号,此情况说明当前最小的包号(即当前需要处理的包号)在(g_current+1) % queue_size和g_current之间。所以此时处理从(g_current+1) % queue_size 到g_current的数据包。本文M=1,此情况即是处理整个环形队列,如下图5。
根据消费者的三种处理策略,在单生产者和双消费者的实验环境下,消费者可以迅速找到当前没有处理过的数据包,进而加快数据包的处理速度。
实际情况中,通过queue_size和M值的设定,可以尽可能的减少消费者对数据包的重复处理,用最小的消耗达到高速处理数据的目的。
本发明的关键点是:多个消费者根据不同情况选择对应策略处理环形队列中的数据,以最小的重复处理消耗达到高速处理数据包的目的。
本发明提出了基于环形队列的多消费者数据处理策略,分三种情况对多消费者的数据处理问题,进行了分析,并提出相应的数据处理策略。本发明所提出的数据处理方法能降低重复数据包的处理次数,提高多消费者数据处理的效率。
显然,以上所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!