视频编码中帧内编码的码率估计方法与流程
本发明属于视频编码技术领域,涉及帧内(I帧)预测编码技术,尤其涉及一种视频编码中帧内(I帧)的码率估计方法,可用于快速高效地选择出帧内预测的最佳模式,减少帧内编码所需的时间。
背景技术:
视频编码技术是指对视频进行压缩的技术。日常生活中的视频数据包括信息和冗余数据两部分内容,视频编码旨在去除视频数据的冗余部分,以减少视频数据在存储和传输过程中的压力。当前主流的视频编码平台都采用基于图像块的混合编码框架,图像块需要经过预测、变换、量化、熵编码等方法,最大限度地消除视频数据中的统计冗余。
率失真优化技术(Rate-Distortion Optimization,简称RDO)是保证在一定的视频质量条件下尽量减少编码比特数的方法,或在一定码率限制条件下尽量减少编码的失真。率失真过程会通过率失真优化函数来评估每种预测方式的优劣,主要通过考察每种预测模式的失真和编码比特数。在相同失真的情况下,编码比特数越小的预测模式将会在RDO过程中被选择。由此,在RDO过程中需要得到每种预测模式的失真以及编码比特数。然而,要求得到某种预测模式的编码比特数,需要对该预测块的变换量化后的结果做熵编码,这却是一个非常耗时的过程。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种视频编码中帧内(I帧)的码率估计方法,主要通过预测块的信息建模,并在相应模型下利用信息熵理论估计出预测块编码比特数,从而跳过了熵编码的过程;本发明方法可用于快速高效地选择出帧内预测的最佳模式,减少帧内编码所需的时间。在视频质量损失较少(0.64%BD-rate损失)的情况下节约了较多的编码时间(37.7%的RDO模块时间)。
率失真优化RDO过程首先选出每一种块划分下的最优预测模式;再从各种块划分的最优模式中选出最佳的块划分模式。本发明的关键创新点在于:本发明使用了广义高斯分布和均匀分布相结合的新模型,新模型对视频编码中的残差分布的拟合与实际结果更为接近,同时由于模型尾部是均匀分布,使得在整个码率估计过程中,更新查找表环节的计算复杂度能够大大降低。本发明方法增加了对估计编码比特数修正的环节,相当于对上述混合模型的决策结果进行了一次修正,使得修正结果更加接近真实熵编码的结果。
本发明提供的技术方案是:
一种视频编码中帧内编码的码率估计方法,通过对预测块的残差信息进行建模,并在相应模型下根据信息熵理论估计出预测块的编码比特数,从而可以在RDO(率失真优化,Rate-Distortion Optimization)过程中跳过熵编码过程,有效地减少编码时间;所述码率估计方法主要包括:统计预测块分布信息并建模过程、根据模型估计预测模式的编码比特数的过程,和对估计的编码比特数做出修正的过程;具体步骤如下:
1)统计预测块分布信息并建模的流程如下:
11)以一帧为单位,统计不同的预测块大小(RDO过程会将预测块划分为不同的大小,从4x4~64x64)中每个位置的残差分布,并对预测块中每个位置的残差用广义高斯分布模型和均匀分布模型的混合模型进行拟合,得到的概率密度函数作为用于预测块中每个位置的概率分布情况的混合模型。(注:混合模型的更新频率原则上每一帧更新一次,也就是说当前帧的统计结果会用到下一帧的预测当中。但如果在一帧结束以后没有达到一定的样本数量,则不会更新模型,统计样本与下一帧样本一同更新。)
12)用步骤11)得到的模型,计算出预测块在每个位置上、量化结果为特定值的概率(即对某一预测块上的某一位置,若经过量化后这个位置的量化值为x,求出这种情况发生的概率),再根据概率求出信息熵。以算出的信息熵作为预测块在这个位置这个量化值的估计编码比特数。将估计得到的编码比特数存放到一个数据表中,这样在下一帧编码的RDO过程中只需要查询该数据表即可获得相应的编码比特数。
2)根据模型估计RDO过程的每种预测模式的编码比特数:
在上述的建模过程在我们得到了预测块在每个位置的每个量化值的估计编码比特数,我们在RDO的过程中,经过预测、变换、量化步骤后,根据每个位置量化的结果从相应数据表中查询得到该位置的估计比特数,并将这个预测块的所有位置的编码比特数相加即可得到该预测块的估计编码比特数,从而跳过了熵编码的过程。
3)估计的编码比特数做出修正:
利用步骤2)的结果,我们可以跳过熵编码的过程,选出每种块大小(4x4~64x64)中的最佳预测模式(这在RDO过程中已经实现;我们的发明是利用步骤2)替代了RDO过程中计算复杂度较高的熵编码过程)。RDO过程会紧接着在不同块划分的最优模式中选出一个最佳模式作为最终的划分结果。本发明中,当我们得出每个块大小的最优模式后,对这些最优模式做一个简易的熵编码,并用这个简易的熵编码结果作为最优模式的预估编码比特数,用于我们在不同的块大小之间选择出最优的划分方式。
与现有技术相比,本发明的有益效果是:
本发明提供一种视频编码中帧内(I帧)的码率估计方法,主要通过预测块的信息建模,并在相应模型下利用信息熵理论估计出预测块编码比特数,从而跳过了熵编码的过程;本发明方法可用于快速高效地选择出帧内预测的最佳模式,减少帧内编码所需的时间。本发明具有以下优点:
(一)广义高斯分布和均匀分布的混合模型比较符合真实情况的残差分布,在同一种块大小中能够很好地甄别出最优的预测模式。
(二)对每一种块大小中的最优模式做了重新的熵编码(简易熵编码),该过程与真实的熵编码相比复杂度较低,但足够用来决策出最好的块划分方式。视频质量损失较少(0.64%BD-rate损失)。
(三)一帧更新一次统计模型,而在RDO过程中只需要做简单的查询操作,时间复杂度较低。节约了较多的编码时间(节省了37.7%的RDO模块时间)
附图说明
图1是本发明提供的码率估计方法的流程框图。
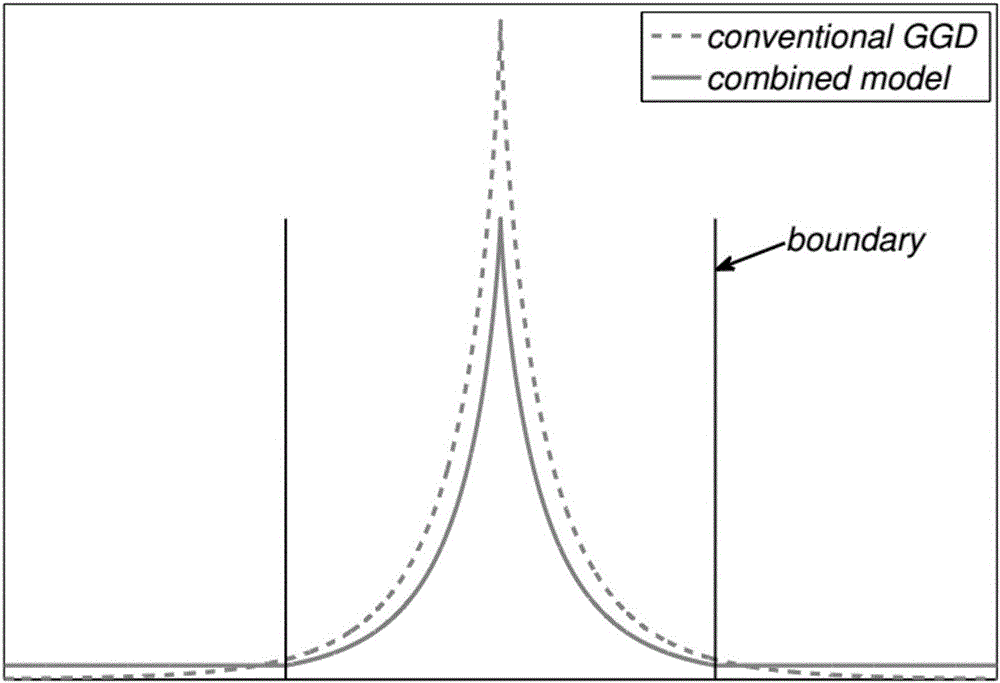
图2是现有的广义高斯分布模型和本发明所提出的混合模型的概率密度函数图;
其中,虚线形表示传统的广义高斯分布模型;实线形表示广义高斯分布和均匀分布的混合模型;两条竖线与横轴的交点表示在混合模型中广义高斯分布和均匀分布的分界点。
图3是本发明计算预测块中某一位置被量化为特定值的概率示意图;
其中,曲线是针对预测块中某一个位置的残差分布;横轴表示该位置量化前的值,纵轴表示该位置量化前取特定值的概率密度;对于该位置而言,当量化后的结果时,从量化公式其中f为量化偏移,Qstep为量化步长,int(x)表示取整函数,sgn(x)表示符号函数)可知,对应的量化前的值可能处于的区间是从而在这个区间对曲线求积分,即可得到该位置的值被量化为的概率,也就是图3中黑色阴影部分的面积;对于量化后结果为可得量化前区间可能处于(-(1-f)·Qstep,(1-f)·Qstep),该区间即量化死区deadzone,图3中部白色阴影部分的面积表示该位置量化后结果为的概率。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供了一种在视频编码领域的I帧编码中率失真优化(Rate Distortion Optimization)模块的快速码率估计方法,用以估算RDO过程中每种预测模式的编码码率,以替代真实熵编码过程的巨大的时间复杂度,在视频质量损失较少(0.64%BD-rate损失)的情况下节约了较多的编码时间(37.7%的RDO模块时间)。本发明适用于视频编码中I帧的码率估计。
本发明通过对预测块的残差信息进行建模,并在相应模型下根据信息熵理论估计出预测块的编码比特数,从而可以在RDO过程中跳过熵编码过程,有效地减少编码时间;图1是本发明提供的码率估计方法的流程框图,主要包括三个部分:统计预测块分布信息并建模、根据模型估计预测模式的编码比特数、并对估计的编码比特数做出修正;具体包括如下步骤:
1)统计预测块分布信息并建模,流程如下:
11)以一帧为单位,统计不同的预测块大小(4x4~64x64)中每个位置的残差分布,并对预测块中每个位置的残差用广义高斯分布模型和均匀分布模型的混合模型进行拟合,得到预测块中每个位置的概率分布情况。
其中:模型的更新频率原则上每一帧更新一次,也就是说,当前帧的统计结果会用到下一帧的预测当中。但如果在一帧结束以后没有达到一定的样本数量,则不会更新模型,统计样本与下一帧样本一同更新。
12)计算出预测块在每个位置上,当量化结果为特定值的概率,再利用信息熵公式(f(P)=-log(P))根据概率求出信息熵。以算出的信息熵作为预测块在这个位置这个量化值的估计编码比特数。将估计得到的编码比特数存放到一个数据表中,这样在下一帧编码的RDO过程中只需要查询该数据表即可获得相应的编码比特数。
2)根据模型估计预测模式的编码比特数
在上述的建模过程在我们得到了预测块在每个位置的每个量化值的估计编码比特数,我们在RDO的过程中,经过预测、变换、量化步骤后,根据每个位置量化的结果从相应数据表中查询得到该位置的估计比特数,并将结果相加即可得到该预测块的估计编码比特数,从而跳过了熵编码的过程。
3)估计的编码比特数做出修正
在每一个块大小(4x4~64x64)中我们用上述方式决策出当前块大小的最优预测模式。当我们得出每个块大小的最优模式后,对这些最优模式做一个简易的熵编码,并用这个简易的熵编码结果作为最优模式的预估编码比特数,用于我们在不同的块大小之间选择出最优的划分方式。
在统计预测块分布信息并建模过程中,具体地,我们以一帧为单位,统计不同的预测块大小中每个位置的残差分布(每个位置有一个独立的残差分布模型),并对预测块中每个位置的残差用广义高斯分布模型和均匀分布模型的混合模型进行拟合,得到预测块中每个位置的概率分布情况。广义高斯分布函数表达式如下:
其中,
表达式中,fuv(x)表示预测块中每个位置的概率密度分布(u,v为预测块中位置的坐标),σuv表示在该位置的标准差,ηuv控制着概率密度函数的形状(用表达式进行估算),Γ(·)表示伽马函数。本发明将广义高斯分布模型与均匀分布模型结合,混合模型表达式f′uv(x)如式3:
其中,θuv是一个调整因子,以保证概率密度函数在整个区间内积分为1。buv是广义高斯分布和均匀分布的边界,muv表征量化后x能够取的最大值,从而得到广义高斯分布和均匀分布混合模型的表达式,如图2所示。图2是现有的广义高斯分布模型和本发明所提出的混合模型的概率密度函数图。
在根据模型估计预测模式的编码比特数的过程中,具体地,我们首先根据混合模型的概率密度函数计算量化结果为某一特定值的概率图3是本发明计算预测块中某一位置被量化为特定值的概率示意图。如图3所示,对于模型中的广义高斯分布的那部分,计算表达式如式4:
其中,f表示量化偏移,Qstep表示量化步长。对于的情况,我们取作为计算的近似结果,而情况下的概率我们可以不必计算,正如下面所说的,我们会忽略当量化结果为0的时候所带来的编码比特数。
对于模型中均匀分布的那部分,计算表达式如式5所示:
我们得到概率以后,可以利用信息熵理论,通过式6估计编码比特数:
这样,通过式7我们就能够得到每个预测块的编码比特数:
rB=∑u∑vruv (式7)
需要注意的是,计算概率的公式具有比较高的计算复杂度,我们可以将计算结果存到一个查找表中,这样就只需要在更新概率模型的时候计算一次,并缓存结果,在之后的RDO模块中就可以直接查找结果,从而有效地提高RDO模块的时间效率。
上述方式可以快速的估计出同一个块大小中的最优预测模式,但这个估计的编码比特数在决策不同块大小的时候效果并不理想,需要对估计的码率做出修正。
在对估计的码率做出修正的过程中,具体地,当我们得出一个块大小的最优模式以后,我们可以对这个模式进行一次简易的熵编码,并用该结果用于不同块大小之间的RDO决策依据。简易熵编码的思想比较简单,我们只将完整的熵编码过程进行到二值化的步骤,并用二值化产生的比特数作为最后的估计编码比特数。
至此完成在RDO过程中的码率估计的所有步骤。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!