个人财产状态评估方法及装置与流程
本发明涉及信息处理技术领域,尤其涉及一种个人财产状态评估方法及装置。
背景技术:
在金融机构给客户提供家庭消费管理、理财规划管理、资产配置管理和和投资管理等业务时,需全面评估客户的个人财产状态,并对个人财产状态进行整理和分析,及时发现客户的财务隐患,纠正不良理财习惯,提高抵抗金融风险的能力。现有金融机构主要利用客户的资产状况和消费流水等金融数据评估个人财产状态,评估数据来源单一,导致个人财产状态评估结果准确率较低。金融机构基于准确率较低的个人财产状态评估结果给客户提供服务时,提供与其个人财产状态不匹配的业务,可能导致金融风险。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术中个人财产状态评估时,评估数据来源单一且个人财产状态评估结果准确率较低的不足,提供一种个人财产状态评估方法及装置。
本发明解决其技术问题所采用的技术方案是:一种个人财产状态评估方法,包括:
获取目标区域的地理位置围栏信息,所述地理位置围栏信息包括房屋信息和对应的目标用户;
获取与所述目标用户相关联的用户画像数据;
将所有目标用户划分成种子数据集和候选数据集;所述种子数据集包括至少一个种子用户,所述候选数据集包括至少一个候选用户;
利用所述种子用户的用户画像数据训练所述财产评估模型;
根据所述候选用户的用户画像数据,利用所述财产评估模型对所述候选用户的个人财产状态进行评估,以输出个人财产状态评估结果。
优选地,所述利用所述种子用户的用户画像数据训练所述财产评估模型,包括:
采用look-alike算法对所有种子用户的用户画像数据进行分类,获取若干所述子集群及每一所述子集群对应的共有画像数据;
获取每一所述种子用户的个人财产状态,并计算每一所述子集群中所有种子用户的个人财产均值;
将每一所述子集群中所述共有画像数据与所述个人财产均值进行逻辑回归处理,以获取所述财产评估模型。
优选地,所述根据所述候选用户的用户画像数据,利用所述财产评估模型对所述候选用户的个人财产状态进行评估,以输出个人财产状态评估结果,包括:
采用相似度算法计算所述候选用户的用户画像数据与每一所述子集群的所述共有画像数据的相似度;
判断所述相似度是否大于预设的相似阈值;
若是,则将子集群对应的个人财产均值作为所述个人财产状态评估结果输出。
优选地,所述用户画像数据包括基于位置服务的地理位置信息,所述地理位置信息包括与时间相关联的poi信息。
优选地,所述获取目标区域的地理位置围栏信息,包括:
采用网络爬虫爬取房产中介平台和/或房产登记平台,以获取目标区域的地理位置围栏信息。
本发明还提供一种个人财产状态评估装置,包括:
围栏信息获取模块,用于获取目标区域的地理位置围栏信息,所述地理位置围栏信息包括房屋信息和对应的目标用户;
画像数据获取模块,用于获取与所述目标用户相关联的用户画像数据;
数据集划分模块,用于将所有目标用户划分成种子数据集和候选数据集;所述种子数据集包括至少一个种子用户,所述候选数据集包括至少一个候选用户;
评估模型训练模块,用于利用所述种子用户的用户画像数据训练所述财产评估模型;
财产状态评估模块,用于根据所述候选用户的用户画像数据,利用所述财产评估模型对所述候选用户的个人财产状态进行评估,以输出个人财产状态评估结果。
优选地,所述评估模型训练模块包括:
画像数据分类单元,用于采用look-alike算法对所有种子用户的用户画像数据进行分类,获取若干所述子集群及每一所述子集群对应的共有画像数据;
财产均值计算单元,用于获取每一所述种子用户的个人财产状态,并计算每一所述子集群中所有种子用户的个人财产均值;
评估模型处理单元,用于将每一所述子集群中所述共有画像数据与所述个人财产均值进行逻辑回归处理,以获取所述财产评估模型。
优选地,所述财产状态评估模块包括:
相似度计算单元,用于采用相似度算法计算所述候选用户的用户画像数据与每一所述子集群的所述共有画像数据的相似度;
相似度比较单元,用于判断所述相似度是否大于预设的相似阈值;
评估结果输出单元,用于若是,则将子集群对应的个人财产均值作为所述个人财产状态评估结果输出。
优选地,所述用户画像数据包括基于位置服务的地理位置信息,所述地理位置信息包括与时间相关联的poi信息。
优选地,所述围栏信息获取模块,用于采用网络爬虫爬取房产中介平台和/或房产登记平台,以获取目标区域的地理位置围栏信息。
本发明与现有技术相比具有如下优点:本发明所提供的个人财产评估方法及装置中,先获取目标区域的地理位置围栏信息(包括目标用户),并获取与目标用户相关联的用户画像数据;将目标用户划分成种子用户和候选用户;采用种子用户的用户画像数据训练财产评估模型,并利用训练好的财产评估模型对候选用户的用户画像数据进行处理,输出候选用户的个人财产评估结果。采用目标区域的种子用户的用户画像数据训练财产评估模型,利用训练好的财产评估模型对目标区域的候选用户进行个人财产评估,使得个人财产状态评估结果具有较高的准确性、客观性和可靠性。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例1中个人财产状态评估方法的一流程图;
图2是本发明实施例2中个人财产状态评估装置的一原理框图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
实施例1
图1示出本实施例中个人财产状态评估方法的一流程图。该个人财产状态评估方法可在银行、保险等金融机构的终端上应用,用于评估任一用户的个人财产状态。如图1所示,该个人财产状态评估方法包括如下步骤:
s10:获取目标区域的地理位置围栏信息,地理位置围栏信息包括房屋信息和对应的目标用户。
其中,目标区域可以是任一住宅小区。房屋信息可以是目标区域(住宅小区)内任一房屋的房屋位置、房屋房号、房屋大小、房屋销售均价、房屋租金均价等信息。目标用户可以是该房屋信息对应的房屋所有权人。本实施例中,获取目标区域的地理位置围栏信息,以获取任一住宅小区中每一房屋的房屋信息和对应的目标用户,由于目标用户居住在同一住宅小区内,其个人财产状态具有一定的相似性,以便于基于地理位置围栏信息确定的目标用户进行个人财产状态评估。该目标区域对应的住宅小区优选为房屋销售均价较高的住宅小区,房屋销售均价超高,其对应的房屋户主(即目标用户)应当具有相应的个人财产状态。
具体地,步骤s10具体包括:采用网络爬虫爬取房产中介平台和/或房产登记平台,以获取目标区域的地理位置围栏信息。
具体地,网络爬虫按预设规则自动抓取房产中介平台和/或房产登记平台中的房屋信息,并获取与房屋信息相关联的目标用户,将房屋信息和目标用户作为目标区域的地理位置信息输出。可以理解地,房产中介平台和/或房产登记平台中存储有目标区域任一房屋的房屋信息和目标用户,采用网络爬虫从房产中介平台和/或房产登记平台爬取目标区域的地理位置围栏信息,爬取数据内容明确,处理速度较快。
本实施例中,目标用户是与目标区域的任一房屋信息对应的房屋所有权人,同一目标区域的目标用户的个人财产状态具有一定的相似度。可以理解地,与目标区域的房屋销售均价相同或相似的其他区域也可以作为同一目标区域,以扩大目标区域的目标用户范围。基于目标区域的目标用户进行个人财产评估,在一定程度上可提高个人财产状态评估结果的准确性和可靠性。
s20:获取与目标用户相关联的用户画像数据。
用户画像数据(即persona数据)是真实用户的虚拟代表,是建立在一系统真实数据(marketingdata/usabilitydata)之上的目标用户模型。当前银行、保险等金融机构存储的目标用户的用户画像数据包括但不限于用户姓名、身份识别特征、照片、联系方式、家庭住址、办公场所、职业和收入等。本实施例中,获取与目标用户相关联的用户画像数据中,每一用户画像数据对应的用户与地理信息围栏信息中的房屋信息和目标用户相关联,以使每一目标用户的用户画像数据均包含目标区域的房屋信息,以便基于与房屋信息相关的目标用户的用户画像数据进行处理,
具体地,用户画像数据包括基于位置服务的地理位置信息,地理位置信息包括与时间相关联的poi信息。
以目标用户一天的地理位置信息为例,该地理位置信息中包括0:00—24:00的poi信息,每一poi信息用于指示电子地图中的一点,包括poi点名称、经度和纬度等信息。通过对该目标用户在一段时间内每天的地理位置信息进行处理,可确定该目标用户的家庭住址、办公场所、上下班时间、常去的娱乐、消费、健身等等。可以理解地,用户画像数据还可以包括消费特征、投资特征或其他影响个人财产评估因素特征。可以理解地,若目标用户经常性出入高档消费场所,或者在金融机构有大额投资记录等信息,则该目标用户的个人财产较低,其获取的个人财产评估结果较高,以保证个人财产评估的准确性。基于位置服务的地理位置信息是目标用户的日常生活轨迹,具有客观性,基于地理位置信息进行个人财产状态评估,可有利于提高个人财产状态评估结果的客观性和准确性,避免仅依据目标用户自主提供的信息进行个人财产评估所导致的主观性强,评估结果准确性低的问题出现。
其中,基于位置服务(locationbasedservice,简称lbs)是通过电信移动运营商的无线电通讯网络(如gsm网、cdma网)或外部定位方式(如gps)获取移动终端(即目标用户)的位置信息(地理坐标,或大地坐标),在地理信息系统(geographicinformationsystem,简称gis)平台的支持下,为目标用户提供相应服务的一种增值业务。总体来看,lbs由移动通信网络和计算机网络结合而成,两个网络之间通过网关实现交互。移动终端通过移动通信网络发出请求,经过网关传递给lbs服务平台;lbs服务平台根据目标用户请求和目标用户当前位置进行处理,并将结果通过网关返回给目标用户。poi(pointofinterest,即兴趣点或信息点),包括名称、类型、经度、纬度等资料,以使poi可在电子地图上呈现,以标示电子地图上的某个地标、景点等地点信息。
本实施例中,基于位置服务的移动终端为智能手机,通过开启智能手机上的定位功能,以使lbs服务平台实时获取智能手机的地理位置信息,从而了解携带该智能手机的目标用户的地理位置信息。地理位置信息包括与时间相关联的poi信息中的时间包括日期和时刻,通过该地理位置信息可了解目标用户在任一时刻所处的poi信息。可以理解地,地理位置信息与目标用户的用户id相关联,用户id用于识别唯一识别用户,可以是身份证号或手机号。
s30:将所有目标用户划分成种子数据集和候选数据集;种子数据集包括至少一个种子用户,候选数据集包括至少一个候选用户。
本实施例中,对目标区域所有目标用户,依据是否进行过个人财产评估且具有评估的个人财产状态作为划分条件,将目标区域所有目标用户划分成种子数据集和候选数据集。其中,种子数据集中每一种子用户具有评估后的个人财产状态。候选数据集中每一候选用户不具有评估后的个人财产状态。
s40:利用种子用户的用户画像数据训练财产评估模型。
由于种子数据集中所有种子用户均具有评估后的个人财产状态,而每一种子用户均具有相应的用户画像数据,该用户画像数据包括但不限于用户姓名、身份识别特征、照片、联系方式、家庭住址、办公场所、职业和收入等,还包括体现目标用户日常生活轨迹的基于位置服务的地理位置数据。对所有种子用户的用户画像数据进行共性分析,获取种子用户的画像数据与个人财产状态之间的关联关系,以训练财产评估模型。
可以理解地,每一种子用户是目标区域的目标用户,利用种子用户的用户画像数据训练财产评估模型,在一定程度上可提高个人财产状态评估结果的准确性和可靠性。而且,用户画像数据包括用于体现种子用户日常生活轨迹的地理位置数据,具有客观性,基于地理位置信息训练财产评估模型,可有利于提高个人财产状态评估结果的客观性和准确性。
进一步地,步骤s40包括如下步骤:
s41:采用look-alike算法对所有种子用户的用户画像数据进行分类,获取若干子集群及每一所述子集群对应的共有画像数据。
其中,look-alike,即相似人群扩展,是一种基于现有用户/设备id,通过一定的算法评估模型,找到更多拥有潜在关联性的相似人群的技术。本实施例所采用look-alike算法中采用种子用户的用户画像数据为正样本,训练分类模型以获取共有画像数据,以便于采用候选用户的用户画像数据为负样本,通过分类模型进行筛选。
具体地,采用look-alike算法对所有种子用户的用户画像数据进行分类过程中采用到基于pu-learning(learningfrompositiveandunlabledexample,即正例和无标记样本学习)的分类方法进行分类,分类过程简单方便,可有效降低人工分类的预备工作量,提高分类精度。可以理解地,采用look-alike算法对所有种子用户的用户画像数据进行分类,获得的每一子集群具有相同的共有画像数据,是可用于评估个人财产状态的关联特征。
由于每一种子用户的用户画像数据包括体现目标用户日常生活轨迹的基于位置服务的地理位置数据,采用look-alike算法对所有种子用户的用户画像数据进行分类获取的每一子集群中的共有画像数据与基于位置服务的地理位置数据相关联,具有客观性和可靠性。
s42:获取每一种子用户的个人财产状态,并计算每一子集群中所有种子用户的个人财产均值。
由于种子数据集中每一种子用户具有评估后的个人财产状态,则采用look-alike算法对所有种子用户的用户画像数据进行分类而获取到的每一子集群中的种子用户也具有评估后的个人财产状态。本实施例中,计算每一子集群中所有种子用户的个人财产均值,采用个人财产均值构建财产评估模型。
s43:将每一子集群中的共有画像数据与个人财产均值进行逻辑回归处理,以获取财产评估模型。
本实施例中,将每一子集群的共有画像数据与该子集群的个人财产均值采用逻辑回归算法进行逻辑回归处理,以获取财产评估模型。该财产评估模型中,子集群中的共有画像数据与个人财产均值建立映射关系。其中,共有画像数据与基于位置服务的地理位置数据相关联,具有客观性和可靠性,使其形成的财产评估模型具有客观性和可靠性。
其中,逻辑回归(logisticregression)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。逻辑回归(logisticregression)是一个被logistic方程归一化后的线性回归。在逻辑回归(logisticregression)中,若设样本是{x,y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
其中,θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
s50:根据候选用户的用户画像数据,利用财产评估模型对候选用户的个人财产状态进行评估,以输出个人财产状态评估结果。
在练好的财产评估模型中,使用户画像数据与个人财产状态建立映射关系。对于任一不具有评估的个人财产状态的候选用户,只需将候选用户的用户画像数据输入训练好的财产评估模型进行个人财产状态评估,即可输出个人财产状态评估结果,评估过程简单方便,且输出的个人财产状态评估结果具有客观性和准确性,并且评估过程操作简单方便。
进一步地,步骤s50包括如下步骤:
s51:采用相似度算法计算候选用户的用户画像数据与每一子集群的共有画像数据的相似度。
本实施例中,采用文本相似度算法计算候选用户的用户画像数据与每一子集群的共有画像数据的相似度。采用文本相似度算法计算相似度包括如下过程:首先,对候选用户的用户画像数据进行分词、去停用词等预处理。然后,基于tf-idf或者其他权重进行文本特征提取与加权。最后,采用向量空间模型vsm进行余弦值计算,以计算得到候选用户的用户画像数据与每一子集群的共有画像数据的相似度。其中,tf(termfrequency,即关键词词频),是指一篇文章中关键词出现的频率;idf(inversedocumentfrequency,即逆向文本频率),是用于衡量关键词权重的指数。采用文本相似度算法计算相近度,具有计算过程简单,计算速度较快的优点。可以理解地,还可以采用基于语义相似度的文本相似度算法、基于拼音相似度的汉语模糊搜索算法等相似度算法进行处理。
s52:判断相似度是否大于预设的相似阈值。
其中,相似阈值是预先设置的,用于判断候选用户归属于任一子集群的数值,可自主设置。本实施例中,相似阈值设为70%。即候选用户的用户画像数据与一子集群的共有画像数据的相似度大于相似阈值(70%)时,则认为候选用户可归属于该子集群。
s53:若是,则将子集群对应的个人财产均值作为个人财产状态评估结果输出。
可以理解地,若候选用户的用户画像数据与一子集群的共有画像数据的相似度大于相似阈值时,认为候选用户可归属于该子集群,将该子集群对应的个人财产均值作为该候选用户的个人财产状态评估结果输出。本实施例中,任一候选用户的个人财产状态评估结果与其用户画像数据相关联,而用户画像数据包括基于位置服务的地理位置信息相关联,具有客观性和可靠性。
本实施例所提供的个人财产评估方法中,先获取目标区域的地理位置围栏信息(包括目标用户),并获取与目标用户相关联的用户画像数据;将目标用户划分成种子用户和候选用户;采用种子用户的用户画像数据训练财产评估模型,并利用训练好的财产评估模型对候选用户的用户画像数据进行处理,输出候选用户的个人财产评估结果。采用目标区域的种子用户的用户画像数据训练财产评估模型,利用训练好的财产评估模型对目标区域的候选用户进行个人财产评估,评估过程简单方便,且输出的个人财产状态评估结果具有较高的准确性、客观性和可靠性。
实施例2
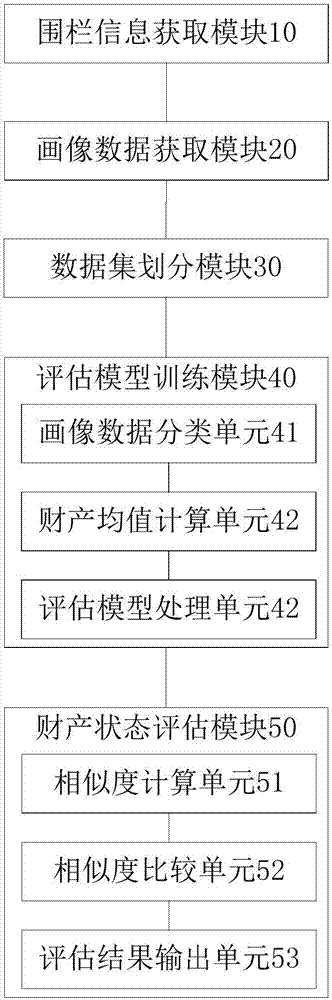
图2示出本实施例中个人财产状态评估装置的一流程图。该个人财产状态评估装置可在银行、保险等金融机构中应用,用于评估任一用户的个人财产状态。如图2所示,该个人财产状态评估装置包括围栏信息获取模块10、画像数据获取模块20、数据集划分模块30、评估模型训练模块40和财产状态评估模块50。
围栏信息获取模块10,用于获取目标区域的地理位置围栏信息,地理位置围栏信息包括房屋信息和对应的目标用户。
其中,目标区域可以是任一住宅小区。房屋信息可以是目标区域(住宅小区)内任一房屋的房屋位置、房屋房号、房屋大小、房屋销售均价、房屋租金均价等信息。目标用户可以是该房屋信息对应的房屋所有权人。本实施例中,获取目标区域的地理位置围栏信息,以获取任一住宅小区中每一房屋的房屋信息和对应的目标用户,由于目标用户居住在同一住宅小区内,其个人财产状态具有一定的相似性,以便于基于地理位置围栏信息确定的目标用户进行个人财产状态评估。该目标区域对应的住宅小区优选为房屋销售均价较高的住宅小区,房屋销售均价超高,其对应的房屋户主(即目标用户)应当具有相应的个人财产状态。
具体地,围栏信息获取模块10,用于采用网络爬虫爬取房产中介平台和/或房产登记平台,以获取目标区域的地理位置围栏信息。
具体地,网络爬虫按预设规则自动抓取房产中介平台和/或房产登记平台中的房屋信息,并获取与房屋信息相关联的目标用户,将房屋信息和目标用户作为目标区域的地理位置信息输出。可以理解地,房产中介平台和/或房产登记平台中存储有目标区域任一房屋的房屋信息和目标用户,采用网络爬虫从房产中介平台和/或房产登记平台爬取目标区域的地理位置围栏信息,爬取数据内容明确,处理速度较快。
本实施例中,目标用户是与目标区域的任一房屋信息对应的房屋所有权人,同一目标区域的目标用户的个人财产状态具有一定的相似度。可以理解地,与目标区域的房屋销售均价相同或相似的其他区域也可以作为同一目标区域,以扩大目标区域的目标用户范围。基于目标区域的目标用户进行个人财产评估,在一定程度上可提高个人财产状态评估结果的准确性和可靠性。
画像数据获取模块20,用于获取与目标用户相关联的用户画像数据。
用户画像数据(即persona数据)是真实用户的虚拟代表,是建立在一系统真实数据(marketingdata/usabilitydata)之上的目标用户模型。当前银行、保险等金融机构存储的目标用户的用户画像数据包括但不限于用户姓名、身份识别特征、照片、联系方式、家庭住址、办公场所、职业和收入等。本实施例中,获取与目标用户相关联的用户画像数据中,每一用户画像数据对应的用户与地理信息围栏信息中的房屋信息和目标用户相关联,以使每一目标用户的用户画像数据均包含目标区域的房屋信息,以便基于与房屋信息相关的目标用户的用户画像数据进行处理,
具体地,用户画像数据包括基于位置服务的地理位置信息,地理位置信息包括与时间相关联的poi信息。
以目标用户一天的地理位置信息为例,该地理位置信息中包括0:00—24:00的poi信息,每一poi信息用于指示电子地图中的一点,包括poi点名称、经度和纬度等信息。通过对该目标用户在一段时间内每天的地理位置信息进行处理,可确定该目标用户的家庭住址、办公场所、上下班时间、常去的娱乐、消费、健身等等。可以理解地,用户画像数据还可以包括消费特征、投资特征或其他影响个人财产评估因素特征。可以理解地,若目标用户经常性出入高档消费场所,或者在金融机构有大额投资记录等信息,则该目标用户的个人财产较低,其获取的个人财产评估结果较高,以保证个人财产评估的准确性。基于位置服务的地理位置信息是目标用户的日常生活轨迹,具有客观性,基于地理位置信息进行个人财产状态评估,可有利于提高个人财产状态评估结果的客观性和准确性,避免仅依据目标用户自主提供的信息进行个人财产评估所导致的主观性强,评估结果准确性低的问题出现。
其中,基于位置服务(locationbasedservice,简称lbs)是通过电信移动运营商的无线电通讯网络(如gsm网、cdma网)或外部定位方式(如gps)获取移动终端(即目标用户)的位置信息(地理坐标,或大地坐标),在地理信息系统(geographicinformationsystem,简称gis)平台的支持下,为目标用户提供相应服务的一种增值业务。总体来看,lbs由移动通信网络和计算机网络结合而成,两个网络之间通过网关实现交互。移动终端通过移动通信网络发出请求,经过网关传递给lbs服务平台;lbs服务平台根据目标用户请求和目标用户当前位置进行处理,并将结果通过网关返回给目标用户。poi(pointofinterest,即兴趣点或信息点),包括名称、类型、经度、纬度等资料,以使poi可在电子地图上呈现,以标示电子地图上的某个地标、景点等地点信息。
本实施例中,基于位置服务的移动终端为智能手机,通过开启智能手机上的定位功能,以使lbs服务平台实时获取智能手机的地理位置信息,从而了解携带该智能手机的目标用户的地理位置信息。地理位置信息包括与时间相关联的poi信息中的时间包括日期和时刻,通过该地理位置信息可了解目标用户在任一时刻所处的poi信息。可以理解地,地理位置信息与目标用户的用户id相关联,用户id用于识别唯一识别用户,可以是身份证号或手机号。
数据集划分模块30,用于将所有目标用户划分成种子数据集和候选数据集;种子数据集包括至少一个种子用户,候选数据集包括至少一个候选用户。
本实施例中,对目标区域所有目标用户,依据是否进行过个人财产评估且具有评估的个人财产状态作为划分条件,将目标区域所有目标用户划分成种子数据集和候选数据集。其中,种子数据集中每一种子用户具有评估后的个人财产状态。候选数据集中每一候选用户不具有评估后的个人财产状态。
评估模型训练模块40,用于利用种子用户的用户画像数据训练财产评估模型。
由于种子数据集中所有种子用户均具有评估后的个人财产状态,而每一种子用户均具有相应的用户画像数据,该用户画像数据包括但不限于用户姓名、身份识别特征、照片、联系方式、家庭住址、办公场所、职业和收入等,还包括体现目标用户日常生活轨迹的基于位置服务的地理位置数据。对所有种子用户的用户画像数据进行共性分析,获取种子用户的画像数据与个人财产状态之间的关联关系,以训练财产评估模型。
可以理解地,每一种子用户是目标区域的目标用户,利用种子用户的用户画像数据训练财产评估模型,在一定程度上可提高个人财产状态评估结果的准确性和可靠性。而且,用户画像数据包括用于体现种子用户日常生活轨迹的地理位置数据,具有客观性,基于地理位置信息训练财产评估模型,可有利于提高个人财产状态评估结果的客观性和准确性。
进一步地,评估模型训练模块40具体包括画像数据分类单元41、财产均值计算单元42和评估模型处理单元43。
画像数据分类单元41,用于采用look-alike算法对所有种子用户的用户画像数据进行分类,获取若干子集群及每一所述子集群对应的共有画像数据。
其中,look-alike,即相似人群扩展,是一种基于现有用户/设备id,通过一定的算法评估模型,找到更多拥有潜在关联性的相似人群的技术。本实施例所采用look-alike算法中采用种子用户的用户画像数据为正样本,训练分类模型以获取共有画像数据,以便于采用候选用户的用户画像数据为负样本,通过分类模型进行筛选。
具体地,采用look-alike算法对所有种子用户的用户画像数据进行分类过程中采用到基于pu-learning(learningfrompositiveandunlabledexample,正例和无标记样本学习)的分类方法进行分类,分类过程简单方便,可有效降低人工分类的预备工作量,提高分类精度。可以理解地,采用look-alike算法对所有种子用户的用户画像数据进行分类,获得的每一子集群具有相同的共有画像数据,是可用于评估个人财产状态的关联特征。
由于每一种子用户的用户画像数据包括体现目标用户日常生活轨迹的基于位置服务的地理位置数据,采用look-alike算法对所有种子用户的用户画像数据进行分类获取的每一子集群中的共有画像数据与基于位置服务的地理位置数据相关联,具有客观性和可靠性。
财产均值计算单元42,用于获取每一种子用户的个人财产状态,并计算每一子集群中所有种子用户的个人财产均值。
由于种子数据集中每一种子用户具有评估后的个人财产状态,则采用look-alike算法对所有种子用户的用户画像数据进行分类而获取到的每一子集群中的种子用户也具有评估后的个人财产状态。本实施例中,计算每一子集群中所有种子用户的个人财产均值,采用个人财产均值构建财产评估模型。
评估模型处理单元43,用于将每一子集群中的共有画像数据与个人财产均值进行逻辑回归处理,以获取财产评估模型。
本实施例中,将每一子集群的共有画像数据与该子集群的个人财产均值采用逻辑回归算法进行逻辑回归处理,以获取财产评估模型。该财产评估模型中,子集群中的共有画像数据与个人财产均值建立映射关系。其中,共有画像数据与基于位置服务的地理位置数据相关联,具有客观性和可靠性,使其形成的财产评估模型具有客观性和可靠性。
其中,逻辑回归(logisticregression)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。逻辑回归(logisticregression)是一个被logistic方程归一化后的线性回归。在逻辑回归(logisticregression)中,若设样本是{x,y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
其中,θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
财产状态评估模块50,用于根据候选用户的用户画像数据,利用财产评估模型对候选用户的个人财产状态进行评估,以输出个人财产状态评估结果。
在练好的财产评估模型中,使用户画像数据与个人财产状态建立映射关系。对于任一不具有评估的个人财产状态的候选用户,只需将候选用户的用户画像数据输入训练好的财产评估模型进行个人财产状态评估,即可输出个人财产状态评估结果,评估过程简单方便,且输出的个人财产状态评估结果具有客观性和准确性,并且评估过程操作简单方便。
进一步地,财产状态评估模块50具体包括相似度计算单元51、相似度比较单元52和评估结果输出单元53。
相似度计算单元51,用于采用相似度算法计算候选用户的用户画像数据与每一子集群的共有画像数据的相似度。
本实施例中,采用文本相似度算法计算候选用户的用户画像数据与每一子集群的共有画像数据的相似度。采用文本相似度算法计算相似度包括如下过程:首先,对候选用户的用户画像数据进行分词、去停用词等预处理。然后,基于tf-idf或者其他权重进行文本特征提取与加权。最后,采用向量空间模型vsm进行余弦值计算,以计算得到候选用户的用户画像数据与每一子集群的共有画像数据的相似度。其中,tf(termfrequency,即关键词词频),是指一篇文章中关键词出现的频率;idf(inversedocumentfrequency,即逆向文本频率),是用于衡量关键词权重的指数。采用文本相似度算法计算相近度,具有计算过程简单,计算速度较快的优点。可以理解地,还可以采用基于语义相似度的文本相似度算法、基于拼音相似度的汉语模糊搜索算法等相似度算法进行处理。
相似度比较单元52,用于判断相似度是否大于预设的相似阈值。
其中,相似阈值是预先设置的,用于判断候选用户归属于任一子集群的数值,可自主设置。本实施例中,相似阈值设为70%。即候选用户的用户画像数据与一子集群的共有画像数据的相似度大于相似阈值(70%)时,则认为候选用户可归属于该子集群。
评估结果输出单元53,用于若是,则将子集群对应的个人财产均值作为个人财产状态评估结果输出。
可以理解地,若候选用户的用户画像数据与一子集群的共有画像数据的相似度大于相似阈值时,认为候选用户可归属于该子集群,将该子集群对应的个人财产均值作为该候选用户的个人财产状态评估结果输出。本实施例中,任一候选用户的个人财产状态评估结果与其用户画像数据相关联,而用户画像数据包括基于位置服务的地理位置信息相关联,具有客观性和可靠性。
本实施例所提供的个人财产评估装置中,先获取目标区域的地理位置围栏信息(包括目标用户),并获取与目标用户相关联的用户画像数据;将目标用户划分成种子用户和候选用户;采用种子用户的用户画像数据训练财产评估模型,并利用训练好的财产评估模型对候选用户的用户画像数据进行处理,输出候选用户的个人财产评估结果。采用目标区域的种子用户的用户画像数据训练财产评估模型,利用训练好的财产评估模型对目标区域的候选用户进行个人财产评估,评估过程简单方便,且输出的个人财产状态评估结果具有较高的准确性、客观性和可靠性。
本发明是通过几个具体实施例进行说明的,本领域技术人员应当明白,在不脱离本发明范围的情况下,还可以对本发明进行各种变换和等同替代。另外,针对特定情形或具体情况,可以对本发明做各种修改,而不脱离本发明的范围。因此,本发明不局限于所公开的具体实施例,而应当包括落入本发明权利要求范围内的全部实施方式。
- 还没有人留言评论。精彩留言会获得点赞!