一种无线传感器网络参数自适应调节方法与流程
本发明涉及无线传感器网络的mac层接入技术和q学习算法,基于ieee802.15.4通信协议中基本的mac接入机制csma/ca技术,通过q学习算法对该接入机制的重要参数进行调节,从而优化无线传感器网络的服务质量。具体是一种无线传感器网络中基于分布式q学习的参数自适应调节方法。
背景技术:
在低时延确定性的无线传感器网络中,基于csma/ca接入机制的802.15.4协议得到了广泛应用。但由于csma/ca是竞争型的mac协议,各个节点在接入信道和发送数据的时候可能会发生碰撞,因此需要进行空闲信道检测、退避和重传。在标准的csma/ca机制中,退避和重传次数一般设为默认值,并且无法针对不同的网络进行动态设置,这就造成了在某些信道状况不佳、服务质量要求较高的通信环境中无法满足要求的问题。由于应用的需要,目前对mac层接入协议的研究中,也提出了一些调节网络参数以适应通信指标要求的调节方法。这些调节方法多数需要由传感器节点根据通信质量向协调器节点发送配置请求帧,请求分配相应的通信资源,而协调器根据各个节点发送的请求帧为节点分配优先级或时隙。这种优化方法的优点是协调器可以根据节点信息的重要性提供差异化服务,并且分配专用时隙可以有效地避免因为碰撞造成的丢包等问题。但由于增加了配置请求帧和配置帧的,导致网络整体的能耗以及通信的复杂度大大上升,对于使用电池供电的传感器节点来说,会导致网络的寿命缩短。因此,一个可以对网络参数进行自适应调节的接入机制优化方法是迫切的现实需求。
在现在的自适应调节方法中,各种学习算法是研究的热点。其中q学习算法由于是无模型的学习算法,可以有多个代理,学习机制是分布式的,并且算法复杂度较低,因此得到了广泛的应用。使用q学习算法的应用由于无需和环境中的其他智能体进行信息交换,而是通过自身获得的奖励对每个“状态-动作”对的q值进行更新。
考虑到无线传感器网络是一种能量有限并且低时延确定性的网络,结合q学习算法来优化网络的有效传输率和时延显得十分有应用价值。
技术实现要素:
本发明提出一种无线传感器网络中基于q学习的参数自适应调节方法,该方法结合csma/ca接入机制的特点来满足网络有效传输率和时延的要求,采用q学习算法,可以有效地提高算法的收敛速率,减少计算的复杂度,是一种开销较小的参数设置方法。
一种无线传感器网络中基于q学习的参数自适应调节方法,以网络通信时延d以及网络有效传输率r作为目标函数,以传感器节点作为智能体,以无线传感器网络的环境状态作为q学习的环境状态集合s,每次通信中各个节点的通信参数的设置动作作为智能体代理的动作集合a,以传感器网络节点所采用的通信参数与其的通信时延以及有效传输率之间的对应关系作为各个传感器节点的瞬时反馈奖励函数,采用分布式q学习迭代算法对网络中各个节点的通信参数进行设置,在迭代过程中设置探索策略函数。
由于假设环境状态不发生改变,因此转移概率公式和q值函数的迭代公式属于已知公式。
在一次发送过程中,子节点需要进行两次空闲信道检测,在两次信道检测结果均为空闲的情况下才可以进行发送。一般将第一次和第二次空闲信道检测失败的概率之和设为x。如果信道检测失败,则会进入退避周期,随机退避一段时间,在退避结束之后,又会重新进行空闲信道检测。退避的次数是有限制的,其必须小于最大退避次数m,在退避次数到达m时,则本次发送失败。而如果成功接入信道并发送了数据帧,但没有收到协调器返回的ack时,则传感器节点会进行重传,重传的步骤与正常发送的步骤相同。若重传次数达到最大重传次数n时,则本次发送失败。这里将在每一次发送(包括正常的发送和重传)中成功接入信道但因为数据帧传输失败而进入下一次重传或发送失败的概率设为y。
在第t次数据传输中,单个无线传感器节点的有效传输率r(t)和时延d(t)的计算方式如下所示:
其中
其中ts为数据帧成功发送的时间,tc为数据帧传输中发生碰撞的时间,而
其中sb指的是时间单元aunitbackoffperiod(20个符号)。γ=max(α,(1-α)β),α和β分别指的是第一次和第二次空闲信道检测失败的概率,m为最大退避次数,w0指的是第一次退避中的最小退避时间。
从公式(1)、(2)和(3)可以看出,由于假设环境状态不发生改变,因此cca检测失败概率x、传输失败概率(即传感器节点成功接入信道并发送数据给协调器,但未接收到协调器返回的ack的概率)y、最小退避时间w0,以及数据帧成功发送的时间ts和数据帧传输中发生碰撞的时间tc均为常数不发生改变,有效传输率和时延只与最大退避次数m和最大重传次数n有关。
以网络通信时延d以及网络有效传输率r作为目标函数,具体计算公式如下:
所述探索策略是最简单的ε-greedy作为动作选择策略,它使用随机接收准则进动作作选择,每次除选择估计价值最优的动作外,还以一个较小的概率有限度地接收估计价值次优的动作,这使得搜索算法有可能跳出搜索空间中局部最优子空间的陷阱,寻找到最优的动作选择策略。其探索策略公式为:
“探索”即随机策略,是为了对“状态-动作”空间实现遍历,从而避免算法收敛于一个局部最优解,其概率为ε;而“利用”即贪婪策略,即智能体以概率1-ε选择该策略,并从查找表中选择对应q值最大的动作作为下一个学习周期中智能体所采用的动作。其可以防止学习过程过于震荡而不收敛。
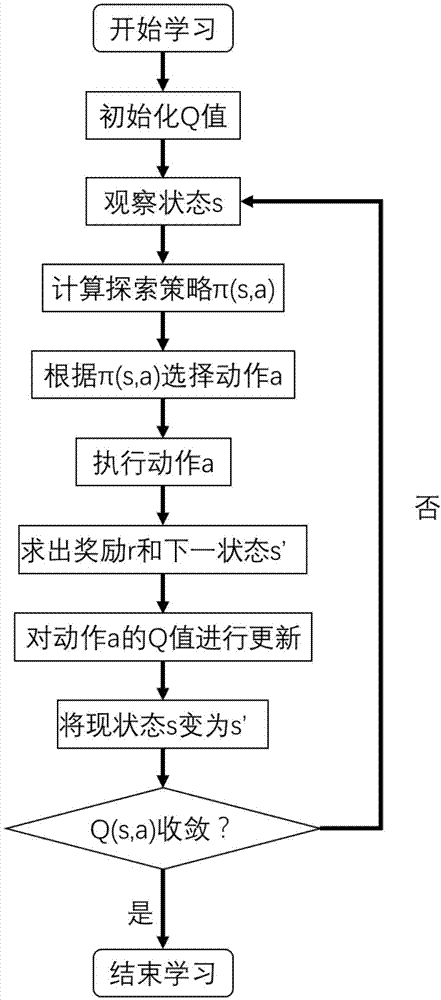
所述在无线传感器网络中采用分布式q学习算法对各个传感器节点的通信参数进行优化的具体过程如下:
步骤1:初始化各个动作的q值,一般情况下将它们都初始化为0;
步骤2:观察现状态s;
步骤3:通过q(s,a)求出策略π(s,a),从而对探索新动作和利用现在动作的概率进行平衡;
步骤4:根据代理策略π(s,a)选择一个动作a;
步骤5:执行动作a并观察所得到的奖励r和下一个状态s′;
步骤6:使用公式qt(a)=qt-1(a)+αt[rt-qt-1(a)]对q(s,a)的值进行更新;
步骤7:将现状态s变为s′;
步骤8:重复4—8的步骤:,直到q(s,a)的值收敛
q值的更新公式为qt(a)=qt-1(a)+αt[rt-qt-1(a)],其中其中αt为学习速率,rt为奖励。
学习速率αt决定了q学习算法的收敛速率,αt越大,“状态-动作”对的收敛速率也越快。但收敛速率过快会导致学习算法出现局部最优解的问题。因此,一般情况下令学习速率αt=0.1,以保证学习算法能够正常地工作。
根据通信的实际要求,我们将网络有效传输率r所允许的最小值rmin设置为99%,即在100个数据帧中只允许1个丢帧存在。
根据q学习的机制,q值是瞬时更新的,因此每一成功收包或者丢包都会给予动作相应的奖励与惩罚。由于有效传输率的阈值rmin=99%,则我们要保证q值在有效传输率低于为99%的情况下为负值,而在99%的情况下为正值。这样才能够保证满足要求的动作即(m,n)的q值可以收敛到1,而不满足要求的动作的q值则会收到惩罚收敛为负值或0。
若有限传输率的阈值为rmin=99%,则对于收包的奖励和丢包的惩罚应该满足:成功接收99个数据帧而丢失一个数据帧时,该动作的q值大于0;而成功98个数据帧而丢失2个数据帧时,该动作的q值小于0;
根据有效传输率和q值的关系,可以计算处动作在收包时获得的奖励和丢包时受到的惩罚之间的关系。本专利将收包获得的奖励设为1,则丢包所受到的惩罚rp需要满足
可以求出惩罚rp的取值范围为[5,8]。
根据惩罚rp的取值范围,可知rp共有4中取值。但由于在rp=5的情况下,成功接收99个数据帧而丢失一个数据帧时的q值最大,便于算法收敛,因此将惩罚rp的值设为5。
根据传感器节点采用不同的通信参数设置动作a所产生的不同结果,奖励函数rt的值设定如下。
本发明提出了一种基于分布式q学习算法的无线传感器网络参数自适应调节方法,以规定的传感器节点的通信时延和有效传输率的阈值为目标,无线传感器网络中各个节点依据每种参数设置所获得的通信质量参数进行学习并最终适应,将该过程映射成分布式多智能体q学习过程,并通过使用ε-greedy贪婪算法的分布式q学习算法来逼近到最佳最佳参数设置。本发明可以有效地提高算法的收敛速率,减少计算的复杂度,是一种开销较小的无线传感器网络通信参数设置方法。
附图说明
图1是本发明实施方法中基于q-learning算法的q值更新机制示意图。
图2是本发明实施方式中基于q-learning算法的传感器网络参数调节方法示意图。
图3是本发明的摘要附图。
具体实施方式
下面结合具体实例对本发明的具体实施方式作进一步说明:
步骤s101:初始化网络拓扑与通信机制。本发明给定一个星型无线传感器网络,如图1所示,其由1个协调器节点和n个传感器子节点构成。所有传感器节点均采用csma/ca接入机制访问信道,csma/ca算法的流程图如图2所示。在传感器节点成功接入信道进行发送,但未能收到协调器返回的ack的时候,传感器节点会进行重传,重传机制如图3所示。
步骤s102:选择学习算法并设置学习算法的优化目标。各个传感器节点均使用q学习算法对自己与协调器之间通信的有线传输率和时延进行调节,学习速率为αt,并且在计算每个“状态-动作”对的q值时,不考虑之前具有最佳q值的“状态-动作”对的q值,因此令其折扣因子γ的值为0。探索策略采用的是ε-greedy贪婪策略,。所使用的网络模型如图1所示,各个传感器节点通过无线信道与协调器节点进行通信。
步骤s103:选择学习算法的策略更新机制并设置优化函数参数。在本发明中,学习速率αt=0.1,这是为了防止学习速率过快导致局部最优解的情况产生。其次ε-greedy探索策略所采用的探索概率的值ε=0.1,这是为了避免探索概率过高而导致q值无法收敛。
由于本调节机制的优化目标为无线传感器网络的有效传输率和时延,而有效传输率并不是一个瞬时值,而是在进行一定次数的通信之后求得的平均值。而在每次通信之后都需要求出奖励rt的值,并且要求的有效传输率必然十分接近于1。因此,传输失败所获的惩罚必然要大于成功传输所获得的奖励,这样才能使所有动作的q值得到收敛。
在我们所使用的q值更新函数qt(a)=qt-1(a)+αt[rt-qt-1(a)]中,按照上文的叙述,针对不同的通信情况需要设置不同的奖励和惩罚的参数rt,其具体的设置如下所示:
步骤s104:根据优化目标设置充分学习门限。由于本调节方法使用的是q学习算法,根据我们的q值更新公式,服务质量最佳的动作的q值在经过学习之后会收敛到1。但在实际上,该q值只是无限接近于1而无法达到1,并且随着q值更新次数的增长,q值的增长也更加缓慢。如果对收敛时q值的大小要求过高,会导致学习阶段过长影响通信的时延以及能耗。因此需要设置充分学习门限ξ用于确认q值是否已经收敛。其次ξ的值也不能设置的过低,导致探索新动作的概率过低,从而出现局部最优解的情况。。
步骤s105:使用学习算法对优化目标进行优化。本部分设计本发明一种基于分布式q学习的无线传感器网络参数自适应调节方法,具体步骤如下:
1、初始化:在t=0时刻,将无线传感器网络中所有的传感器节点的“状态-动作”对的q值函数qt(s,ai)=0,其中ai∈a(a),是动作集合a中的动作之一,在我们的调节机制中,其代表的是各个传感器节点在通信中采用的通信参数即最大退避次数m和最大重传次数n的组合,即a=(m,n)。由于0≤m≤5,0≤n≤7,因此ai共有48种组合。充分学习门限值设为ξ;
2、在整个学习过程中,对于所有的节点,重复下面第3~6步,直到有动作的q值满足qt(s,ai)>ξ;
3、使用ε-greedy贪婪策略,根据动作集合a中所有动作的q值qt(s,ai)求出策略π(s,a),从而对探索新动作和利用现在动作的概率进行平衡;
4、根据策略π(s,a)在动作集合a中选择一个动作at,用于确定在接下来的发送中采用的通信参数的设置。
5、执行动作at,即按照选择的m和n的组合进行发送,根据通信的服务质量即时延和丢包计算出奖励或惩罚rt的值,若传感器节点未收到协调器返回的ack帧,则惩罚rt的值为-5,若成功接收但时延超过了要求,则惩罚rt的值为-1,若成功接收,且时延满足要求,则奖励rt的值为1;
6、使用公式qt+1(a)=qt(a)+αt[rt-qt(a)]对qt(s,ai)的值进行更新。
步骤s106:结束学习并固定通信参数设置。依据充分学习门限结束学习算法。当q值达到充分学习门限之后,结束学习算法,之后按q值最大的通信参数进行通信。
- 还没有人留言评论。精彩留言会获得点赞!