电力安全作业及运维智能监管系统及方法与流程
本发明属于智能监管技术,具体涉及一种电力安全作业及运维智能监管系统及方法。
背景技术:
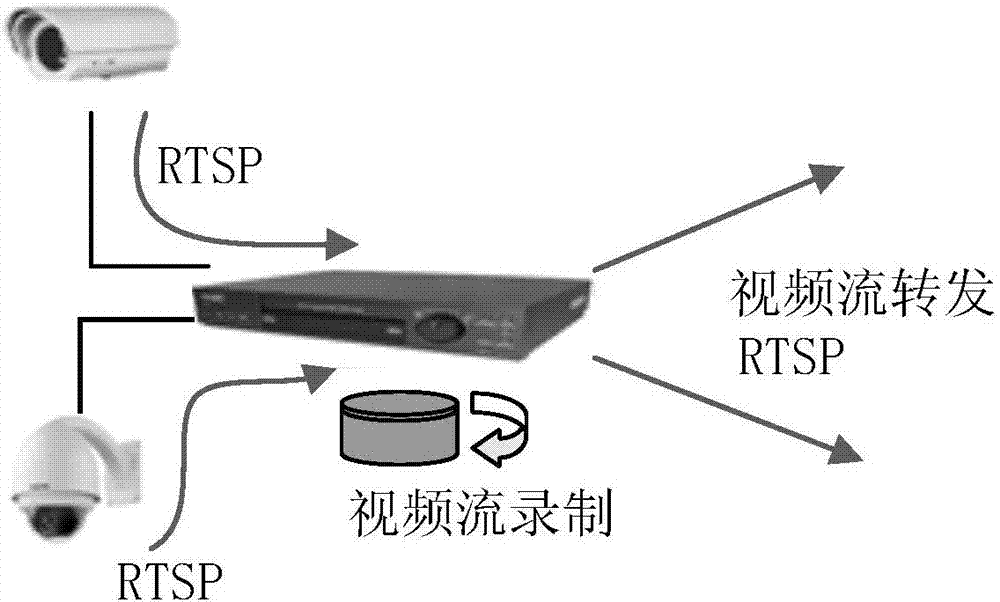
:我国经济飞速发展,电力体制改革不断深入,“互联网+”技术使电力客户的消费方式、使用习惯都发生了巨大变化,同时也大大提升了传统行业的竞争能力,近年来,随着我国国民经济的迅猛发展,电力负荷逐年增加,配电网络的结构也日趋复杂。同时随着近2年来电力施工中发生的众多电力事故,大部分原因是由于监管不到位,电力施工人员自身对安全的不重视,国家也加大了对电力行业安全监管的力度,特别是变电站和和输电线路是电力系统的重要设施,作为整个电网运行的核心组成部分,其建设前期人员安全、运转的安全性和可靠性直接关系整个电力系统的稳固。随着变电站“无人值守”的进一步落实,电力系统对智能化的需求与日俱增;目前变电站和输电线路采用的还是传统的监控方式,运维人员必须随时监控视频画面,以防漏掉故障与违反安全生产要求的图像。安全检查时更得通盘检索,浪费大量人力、物力与时间,无法充分发挥监控系统的功效。国家电网公司以往对变电站、主配网线路的安全作业由传统的纯人工监控监管向着科技化、智能化的新模式发展。现需要一套拥有人员安全行为鉴别、智能运维、智能化安防报警、智能化监管系统及方法。技术实现要素:本发明的目的是提供一种电力安全作业及运维智能监管系统及方法,能实现人员安全行为鉴别,智能运维、智能化安防报警以及智能化监管。本发明所述的电力安全作业及运维智能监管系统,包括前端采集单元、智能处理单元和分布式流媒体平台;所述前端采集单元包括:多个摄像装置,安装在不同的监控点,用于采集监控点的视频信息;以及一个或一个以上的网络视频录像机,用于记录摄像装置所采集的视频信息,该网络视频录像机通过监控网络与摄像装置连接;所述智能处理单元包括:模型训练机,用于构建卷积神经网络,并利用样本图像训练卷积神经网络;智能分析器,利用训练好的卷积神经网络对前端采集单元所采集的实时视频流进行识别,若识别出作业现场出现未授权的非作业人员,和/或设备出现异常,和/或作业现场人员有安全违规行为,则发出报警提示和/或记录;数据库服务器,用于存储匹配的图像视频文件,该数据库服务器与监控网络连接;所述分布式流媒体平台包括:流媒体服务器,用于转发前端采集单元的直播视频流以及将前端采集单元所采集的视频信息转发给智能分析器,该流媒体服务器与监控网络连接;监控管理平台,用于对系统内的各设备进行监控和管理,该监控管理平台与监控网络连接。所述分布式流媒体平台还包括:监控终端,该监控终端与监控网络连接,或该监控终端通过云端接入监控网络。本发明所述的电力安全作业及运维智能监管方法,采用本发明所述的电力安全作业及运维智能监管系统,其方法包括:构建卷积神经网络,利用样本图像训练卷积神经网络;利用训练好的卷积神经网络对前端采集单元所采集的实时视频流进行识别,若识别出作业现场出现未授权的非作业人员,和/或设备出现异常,和/或作业现场人员有安全违规行为,则发出报警提示和/或记录。还包括:利用火焰识别算法判别图像是否为火焰,若判为火焰,则发出报警提示。所述构建卷积神经网络,利用样本图像训练卷积神经网络包括:训练采用迁移学习技术进行训练,分为样本采集、样本预处理和训练建模;样本为视频时,采用相等时间间隔进行视频图像帧采样,将视频转化为图片格式文件;再对图像进行预处理,预处理包括图像降噪、图像色彩和饱和度调节;完成样本预处理后启动模型训练进程,模型训练分为开发阶段模型原型训练和现场部署后在线迁移学习训练两种模式;模型在训练过程中,在训练集上完成一个批次的训练,均在验证集上进行一次模型精度验证,检查模型泛化能力;模型经多轮迭代收敛后再进行上线部署,后期结合现场增量数据定期进行性能调优。所述利用训练好的卷积神经网络对前端采集单元所采集的实时视频流进行识别包括:获取前端采集单元所采集的实时视频流,经过视频抽帧后得到单帧图像,再进行降噪、色彩和旋转处理,并以图像矩阵的形式输入卷积神经网络;然后启动卷积神经网络向前传播计算模式,输入的图像矩阵经卷积进行图像特征重构后,由图像判别层生成预测标注框和故障种类代码的结构化数据。所述卷积神经网络分为安全行为判别神经网络、设备运行状态判别神经网络和人脸识别神经网络,利用人脸识别神经网络来识别作业现场是否出现未授权的非作业人员;利用设备运行状态判别神经网络来识别设备是否有异常;利用安全行为判别神经网络来识别作业现场人员是否有安全违规行为。构建安全行为判别神经网络,利用样本图像训练安全行为判别神经网络的方法包括:步骤11、构建原始图像数据集:对实际作业环境下工作人员的行为进行拍摄并录制视频,采取视频抽帧的方式获取包含工作人员行为的图片文件,构建原始图像数据集;步骤12、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注分为3个ROI进行,ROI为感兴趣区域;其中,第1个ROI包含人体头部至小腿中部区域;第2个ROI包含颈部和头部区域;第3个ROI包含小腿中部以下及足部;图像依据下述分类规则进行标注:第1个ROI的标注:①规范的长袖长裤着装、②穿短袖上衣、③穿短裤、④长袖上衣挽袖口、⑤长裤挽裤脚、⑥未佩戴安全帽;第2个ROI的标注:①穿安全鞋、②穿拖鞋和凉鞋;第3个ROI标注:①未抽烟及打电话、②打电话、③抽烟;标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml文件;全部图片完成标注后,即构成训练数据集;步骤13、设计神经网络判别模型:神经网络判别模型包括输入层、卷积层、池化层和判别输出层;输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出;步骤14、模型训练:模型训练在DarkNet上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法;将训练数据集按预设的比例分为训练集与验证集;训练集图片数据集随机组合,每k1张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD算法进行,设置初始学习率;每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低,继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值时,结束模型训练迭代,使用验证集对模型的性能进行评估;步骤15、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并对图像标注的结果进行检查和筛选,形成增量图像数据集;将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤14重新训练模型,实现判别模型在增量数据上的持续优化。构建设备运行状态判别神经网络,利用样本图像训练设备运行状态判别神经网络的方法包括:步骤21、构建原始图像数据集:对实际设备运行状态进行拍摄并录制视频,采取视频抽帧的方式获取包含设备运行状态的图片文件,构建原始图像数据集;步骤22、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注1个ROI,分类标注规则为:①设备正常运行、②设备故障;标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml文件;全部图片完成标注后,即构成训练数据集;步骤23、设计神经网络判别模型:判别模型包括输入层、卷积层、池化层和判别输出层;输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出;步骤24、模型训练:模型训练在DarkNet上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法;将训练数据集按预设的比例分为训练集与验证集;训练集图片数据集随机组合,每k2张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD算法进行,设置初始学习率;每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低,继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值时,结束模型训练迭代,使用验证集对模型的性能进行评估;步骤25、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并对图像标注的结果进行检查和筛选,形成增量图像数据集;将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤24重新训练模型,实现判别模型在增量数据上的持续优化。构建人脸识别神经网络,利用样本图像训练人脸识别神经网络的方法包括:步骤31、构建原始图像数据集:对人脸进行拍照,构建人脸数据集;步骤32、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注1个ROI,即人物的面部特征,分类标注规则为:①根据人员身份ID进行标注;标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml文件;全部图片完成标注后,即构成训练数据集;步骤33、设计神经网络判别模型:判别模型包括输入层、卷积层、池化层和判别输出层组成,输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出;步骤34、模型训练:模型训练在DarkNet上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法;将训练数据集按预设的比例分为训练集与验证集;训练集图片数据集随机组合,每k3张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD算法进行,设置初始学习率;每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低,继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值时,结束模型训练迭代,使用验证集对模型的性能进行评估;步骤35、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并由专业人员对图像标注的结果进行检查和筛选,形成增量图像数据集;将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤34重新训练模型,实现判别模型在增量数据上的持续优化。本发明的有益效果:(1)监督工作人员在运维检修作业过程中对安全规范准则的遵守情况,实时的检测并识别违反规定的行为;违规行为主要包括未佩戴安全帽、未穿工作服、穿拖鞋或凉鞋、作业场内抽烟、作业现场火灾、检修作业接打电话等;(2)对现场工作人员进行管理,当监测到有人员进入设定检测区域时,摄像机会检测人脸并抓拍人脸图像,把人脸抓拍照片发送到后台进行人脸比对、检索等智能业务处理。通过人脸识别检测,能够达到人员监管的目的;(3)通过对重点区域、重点设备运行状态的24小时实时监测,将运维巡视人员从繁重的巡视任务中解放出来,同时也提升了设备安全动作的可靠性;综上所述,本发明相对于现有纯人工视频监管模式,减少了纯人工监管过程中因监管人员疏漏、疲劳、风险报警不及时等情况带来的作业安全风险及电力事故的发生,以更科学的方式实现电力现代化、智能化方向提供了更有力的基础保障。附图说明图1为本发明的原理框图;图2为本发明中前端采集设备交互流程图;图3为本发明中智能分析流程图;图中:1、前端采集单元,11、摄像装置,12、网络视频录像机,2、监控网络,3、智能处理单元,31、智能分析器,32、数据库服务器,33、模型训练机,4、分布式流媒体平台,41、流媒体服务器,42、监控管理平台,43、监控终端。具体实施方式以下结合附图对本发明作进一步说明。如图1所示的电力安全作业及运维智能监管系统,包括前端采集单元1、智能处理单元3和分布式流媒体平台4。如1所示,所述前端采集单元1包括多个摄像装置11和一个或一个以上的网络视频录像机12。本实施例中,摄像装置11的数量根据实际情况确定,分别安装在预设的各监控点处,利用摄像装置11采集各监控点的视频信息。摄像装置11包括摄像机、云台和固定座;摄像机安装在所述云台上,所述云台用于控制所述摄像机转动;云台安装在所述固定座上。如图1所示,网络视频录像机12用于记录摄像装置11所采集的视频信息,网络视频录像机12通过监控网络3与摄像装置11连接。如图1所示,所述智能处理单元3包括通过交换机接入到监控网络3的智能分析器31、数据库服务器32和模型训练机33。模型训练机33用于构建卷积神经网络,并利用样本图像训练卷积神经网络。智能分析器31利用训练好的卷积神经网络对前端采集单元1所采集的实时视频流进行识别,若识别出作业现场出现未授权的非作业人员,和/或设备出现异常,和/或作业现场人员有安全违规行为,则发出报警提示和/或记录。数据库服务器32采用NoSql数据库,用于存储匹配的图像视频文件,供监控管理平台42查询检索,该数据库服务器32与监控网络2连接。如图1所示,所述分布式流媒体平台4包括流媒体服务器41、监控管理平台和监控终端43。如图1所示,流媒体服务器41进行两类转发,一类是根据客户端请求进行直播流转发,支持标准的RTP(实时传输协议)/RTSP(实时流传输协议)推送直播,可根据前端接入规模采用分布式、多点部署;另一类是将前端的高清网络摄像机采集的视频影像不间断的转发给智能分析器31,本实施例中,视频流亦可通过前端采集单元直接发送给智能分析器31。流媒体服务器41是负责前端的高清网络摄像机和网络视频录像机12的多路接入及转发,需要高配置的PC服务器或已集成嵌入式的NVR。每台流媒体服务器41需要具备32路1080p高清视频接入能力,在多余32个监控点的作业现场,本系统能够分布式接入多个流媒体服务器41,实现负载均衡,分摊转发压力。如图1所示,监控管理平台42用于对系统内的各设备进行监控和管理。该监控管理平台42与监控网络3连接。本发明所述的电力安全作业及运维智能监管方法,采用本发明所述的电力安全作业及运维智能监管系统,其方法包括:构建卷积神经网络,利用样本图像训练卷积神经网络;利用训练好的卷积神经网络对前端采集单元1所采集的实时视频流进行识别,若识别出作业现场出现未授权的非作业人员,和/或设备出现异常,和/或作业现场人员有安全违规行为,则发出报警提示和/或记录。由于电力生产现场环境较复杂,实施生产现场的人员面部识别,存在待测目标多佩戴安全帽,面部存在阴影或者面部特征不全;待测目标姿态多变,需要对待测目标侧脸进行识别的情况。传统的基于面部几何特征匹配进行人脸识别的技术目前仅能对人脸正面面部特征进行识别,且要求待测目标脱帽且面部无遮挡,其技术应用无法满足生产现场环境要求。近年来,基于深度学习技术的人脸识别技术取得了长足进度,在复杂场景下进行图像分类识别的效果大大优于基于几何特征匹配的图像分类技术,因此,本发明采用多层卷积神经网络技术进行人脸识别。多层卷积神经网络模型是实现基于深度学习实现人脸识别的基本组件,技术核心为图像卷积算法和基于多层神经网络结构的权值网络。图像卷积算法用于实现图像特征的构建,再结合多层神经网络结构对已构建特征进行组合,模型可以实现图像像素级特征到高阶图像语义特征的自动构建,从而避免了传统几何特征匹配算法需要人工定义图像特征的缺陷,而且大大增加了图像特征组合的容量,使面部特征构建更加灵活多变,对待测目标面部正面、侧面均可进行识别。正是由于模型可以实现特征自动构建,模型具有图像语义分割的能力,从而实现人脸自动侦测,无需前端部署人脸侦测组件,并可实现依赖部分人脸特征,实现被遮挡情况下的人脸识别。同时,模型依赖自身权值网络结构实现人脸判别,无需进行人脸比对,因为无需在后端部署人脸数据库,简化了系统设计的复杂程度。(一)神经网络模型神经网络模型由输入层、卷积层、池化层和softmax输出层组成。输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取,每个卷积层均采取批正则化措施;池化层接于卷积层后,用于降低参数规模和防止过拟合;输出层采用softmax函数进行分类判别值的输出。神经网络判别模型的结构如下:(二)火焰识别算法图像暗通道算法基本原理是在图像上设置一定大小的滑动窗口,计算滑动窗口内各像素点各通道亮度的最小值,获得图像的暗通道图。经统计,在绝大多数非天空局部区域内,非烟雾图像(背景)的暗通道值低于火焰产生的烟雾(前景)的暗通道值,因此,通过计算图像暗通道图,可以增强火焰产生的烟雾效果。暗通道图计算公式为:Jdark=(miny∈Ω(x)(minc∈r,g,b(Jc(y))));其中:Jdark为暗通道值,Jc为RGB各通道亮度值,Ω为滑动窗口,r,g,b是代表红、绿、蓝三个颜色通道。在进行视频火焰识别时,各帧图像均转化为暗通道图,然后采用混合高斯模型减除暗通道图中的背景图像,实现火焰烟雾的识别和起火点的定位。(三)非结构化数据存储及管理生产作业现场在整个智能监管系统的覆盖下,会实时的产生大量的非结构化数据,如图像、视频、日志文件等。非结构化数据是数据结构不规则或不完整,不同于传统的结构化数据,不方便用传统的关系型数据库来表现和存储。(1)非关系型数据库系统采用一种非关系型数据库(NoSql)MongoDB来存储上述非结构化数据,方便供后台管理平台查询和检索。MongoDB是一个基于分布式文件存储的高性能数据库系统,且易于动态扩展,在高负载的情况下,可添加更多的节点,可以保证服务器性能。(2)图形化(GUI)管理工具为了便于管理人员监管日常的安全作业情况,基于MongoDB的GUI插件,开发定制话的GUI显示工具,支持针对特定日期时间、关键字的视频图像的增删改查操作。基于非关系型数据库及定制化的GUI插件,运维管理人员可通过友好易用的操作界面按照时间、违规类型、违规级别定期检索和查询图片和视频片段等安全管理记录。(三)电力安全作业及运维智能监管系统的建设方案(1)前端采集单元本实施例中,摄像机采用普通高清网络摄像机。高清网络摄像机将摄像头采集到的模拟视频信号编码压缩成数字信号,从而可以直接接入本地局域网及路由设备。网络用户可以通过多种方式查看高清网络摄像机捕获到的视频图像,经过授权的用户还可以控制云台转动或对系统配置进行操作。高清网络摄像机支持WIFI无线接入、POE供电(网络供电)和光纤接入。本实施例中高清网络摄像机的配置要求如下:·像素:200万;·镜头焦距:3.8mm~12mm;·多码流输出:主码流:1080p,子码流:640p;·码率:128kbps~5Mbps连续可调;·编码格式:H.264/H.265/MJPEG;·接入标准:Onvif,RTSP;·网络接口:RJ4510M/100M自适应,WIFI802.11b/g/n(选配);·红外距离:30~40米可视距离。如图2所示,网络视频录像机12可以实时更新需要录像的视频监控点信息;汇报视频监控点的录像状态;视频录像功能;对视频监控点进行录像策略配置;从流媒体服务器41提取码流进行录像;支持第三方录像指令控制。本实施例中,网络视频录像机12主要用于记录视频信息。本实施例中,网络视频录像机12的配置要求如下:·网络视频输入:16路1080p;·接入带宽:160Mbps;·视频解码:H.264/H.265;·音频解码:G.711;·输出接口:HDMI,VGA;·盘位数:2盘位,每盘位最大支持8TB容量硬盘;·接入标准:Onvif,RTSP;·网络接口:RJ451000M,WIFI802.11b/g/n(选配)。如图2所示,网络视频录像机12与高清网络摄像机之间通过TCP/IP协议进行数据交互。(2)智能处理单元(2.1)智能处理单元的功能智能处理单元主要由模型训练机、智能分析器、数据库服务器等设备构成。模型训练机用于人脸及行为的样本训练及模型建立,智能分析器则负责识别比对,数据库服务器采用NoSql数据库,存储匹配的图像视频文件,供监控管理平台42查询检索。(2.1.1)人脸识别前端采集单元捕获人脸图像,基于训练好的作业现场人员人脸库进行识别比对,若发现未授权的非作业人员则自动保存图像并生产告警记录。(2.1.2)设备运行状态判定对设备运行视频图像进行分类判定。通过对视频图像的判读,对断路器及隔离刀闸分合状态,待测目标与带电体距离、变电设备锈蚀及破损、变压器漏油等场景进行识别和报警。(2.1.3)行为识别识别并判定作业现场的安全违规行为。通过对视频图像的判读,对抽烟、打手机、为佩戴安全帽、穿拖鞋等多种违规行为进行判定识别。(2.1.4)记录存档图像比对结果达到阈值,将触发后续处理流程,生成结构化数据,将图像和结构化数据一起存储到数据库,供监控管理平台查询,并生产日志记录。日志记录要求包含时间信息,能关联到对应的视频录像片段。(2.2)智能处理单元的架构(2.2.1)模型训练流程模型训练采用迁移学习技术进行训练,分为样本采集、样本预处理和训练建模3个阶段。样本为视频时,采用相等时间间隔进行视频图像帧采样,将视频转化为图片格式文件。再对图像进行图像降噪、图像色彩和饱和度调节等预处理工作。完成上述准备工作后,启动模型训练进程。模型训练分为开发阶段模型原型训练和现场部署后在线迁移学习训练2种模式。模型在训练过程中,在训练集上完成一个批次的训练,均在验证集上进行一次模型精度验证,检查模型泛化能力。模型经多轮迭代收敛后便可进行上线部署,后期结合现场增量数据定期进行性能调优。(2.2.2)智能分析流程图像判别基于训练好的算法模型,算法模型完成训练后便具备图像判别的能力。如图3所示,视频采集模块获取前端高清网络摄像机的实时视频流,经过视频抽帧后得到单帧图像,再进行降噪、色彩、旋转等一些列预处理,接着传输至判别算法模块。图像以图像矩阵的形式进行输入。然后启动神经网络模型向前传播计算模式,输入的图像矩阵经卷积进行图像特征重构后,由图像判别层生成预测标注框和行为类别代码的结构化数据。最后,结构化的数据与图像存入非结构化数据库,供监控平台管理查询。(2.3)智能处理单元的实施方案(2.3.1)样本采集(2.3.1.1)行为及设备图片采集图像采集分为实际场景下故障隐患图像采集和实验室模拟拍摄故障隐患图像2种形式。实际场景下故障隐患图像采集,可以直接利用用户已有的拍摄到故障隐患图像资料。实验室模拟拍摄,则是由技术人员结合现场实际情况布置实验拍摄环境,对故障设备、装置、部件实物进行拍摄。(2.3.1.2)人像采集人像采集时,人像采集时,分为佩戴安全帽和未佩戴安全帽2种情形进行,采集时围绕人员头部360°拍照采样。获取人员人像后,采用图像增强技术,对单张图像进行色彩、光照的调节和一定程度图像几何形变处理,提升样本数量构建人像训练集,构建训练集时,每张人像图片均对应一个人员ID编号,人像图片作为模型训练样本输入值,人员ID编号为样本标签值。(2.3.2)标签样本集制作标签样本集的制作使用图像标注工具labelImg进行,采用图框标注的形式对故障隐患位置进行标注,标注框以xml文件格式保存,并与样本图像一一对应。标注信息包括标注框的区域信息和图像语义信息(即故障隐患分类值)。标注好的图像样本训练样本数量:验证样本数量=4:1进行样本划分,分别构建训练样本集和验证样本集。(2.3.3)模型训练现场部署阶段采取定期在线迁移学习的形式的进行,模型上线部署后,由现场工作人员对现场施工人员头像进行图像采集,构建训练样本集,模型训练时,关闭模型卷积层权重网络,只对模型全连接层进行训练,以适应现场特定施工人员和人员变动时身份识别的场景。采用现场在线迁移学习技术,可以实现在现场小样本增量数据上的模型快速部署,达到识别模型在线学习和在线迭代的目的。(2.3.4)模型部署系统采用DarkNet框架进行模型部署。DarkNet是一款基于CUDA的专门用于搭建神经网络模型的轻量级深度学习框架,支持CUDA运算,支持CPU(即中央处理器)和GPU(即图形处理器)两种计算模式。框架名称:DarkNet;框架类型:卷积神经网络计算框架;支持语言:C/C++;支持操作系统:Linux、windows;计算模式:CPU/GPU。(3)分布式流媒体平台本实施例中,整套解决方案包括有:监控管理平台、流媒体服务器、流媒体播放器和监控终端43(即客户端)等,以及周边众多工具库,包括编码、转码、推流等。各个功能单元既可以独立使用于项目,又可以整体使用,形成一个完整、简单、易用、高效的流媒体解决方案。(3.1)分布式流媒体平台的功能(3.1.1)实时视频流转发流媒体服务器负责接入并转发前端设备的直播视频流,支持标准的RTP/RTSP推送直播,可根据前端接入规模采用分布式、多点部署。系统中流媒体服务器进行两类转发,一类是根据客户端请求进行直播流转发;另一类是将前端高清网络摄像机采集的视频影像不间断的转发给智能分析器;(3.1.2)设备管理维护监控管理平台42是总控中心,实现前端设备的访问及管理。负责接入来自前端设备的注册请求、其他设备节点的连接(如流媒体服务器41等)、客户端的连接请求等。所有关于设备连接的维护与管理、控制命令的下发、设备信息上报解析,客户端请求控制,负载均衡等。本实施例中,监控管理平台42同时也是监控服务器,配置PC服务器和一台显示设备,监控图像画面可以实现1/2/4/6/8/9/12/16多画面分屏显示,支持实时监控图像抓拍。监控管理平台42为系统提供运行环境,负责实时流媒体播放、录像检索回放、分析结果查询以及根据告警记录关联并调取对应的录像等多项功能。每项任务均要消耗资源,需要稍高的配置。(3.1.3)客户端远程接入监控终端43分为现场监控和远程终端两类。现场监控处于系统局域网段内,监控端会预置流媒体播放器,供运维人员查看各监控点的实时情况,它的接入通常不需要特别的权限;远程终端是从外网通过流媒体服务器接入,要考虑安全性,监控管理平台42需要对远程接入的终端认证鉴权。监控终端43接入后,用户可以查看和检索网络视频录像机12上的视频录像,以及操控前端设备(比如:控制云台转动等)。(3.1.4)录像回放检索客户端接入平台后,用户可以查看和检索网络硬盘录像机上的视频录像,以及操控前端设备。视频录像需要通过流媒体服务器进行提取和转发。(3.1.5)系统日志系统日志功能可以记录系统的操作、违规事件等信息,可记录用户的登陆信息,安全违规事件记录等。系统日志可导出、打印等,方便查询和备份。(3.2)分布式流媒体平台的架构(3.2.1)信令交互流程:高清网络摄像机接入后,会在监控管理平台42进行注册,并定期发送心跳,维持与监控管理平台42的连接;而监控管理平台42则会对高清网络摄像机进行验证鉴权,并记录高清网络摄像机的设备信息。客户端的实时视频播放请求会发送给监控管理平台42,监控管理平台42收到后向对应的高清网络摄像机发送启动直播流推送的信令,信令中包含流媒体服务器的IP及端口(高清网络摄像机接下来会向该IP和端口推送视频流),最后监控管理平台42给客户端返回请求响应。(3.2.2)数据交互流程:客户端的播放请求被监控管理平台42接受并响应后,高清网络摄像机开始向流媒体服务器推送RTSP直播流。而此时流媒体服务器同时充当RTSP客户端和服务器,一方面作为RTSP客户端向源高清网络摄像机获取视频数据,另一方面作为服务器,将获取的视频数据分发给正在请求的客户端。(3.3)分布式流媒体平台的实施方案流媒体平台中各节点设备的系统环境均为搭载linux系统的PC服务器或集成设备,通过千兆以太网卡连接到局域网内,设备间互联互通。所有监控点进行不间断录像,录像文件保存15天,录像文件能被监控端及远程客户端随时调取查看。(3.3.1)流媒体服务器流媒体服务器是流媒体服务平台的核心设备,负责前端高清网络摄像机/网络视频录像机12的多路接入及转发,需要高配置的PC服务器。每台流媒体服务器需要具备32路1080p高清视频接入能力,在多余32个监控点的作业现场,本系统能够分布式接入多个流媒体服务器,实现负载均衡,分摊转发压力。流媒体服务器要求兼容海康、大华、宇视等主流设备厂商的高清网络摄像机/网络视频录像机12。(3.3.2)监控管理平台监控管理平台42同时也是监控服务器,配置PC服务器和一台显示设备,监控图像画面可以实现1/2/4/6/8/9/12/16多画面分屏显示,支持实时监控图像抓拍。监控管理平台42为管理系统提供运行环境,负责实时流媒体播放、录像检索回放以及分析结果查询等多项功能。每项任务均要消耗资源,需要稍高的配置。(3.3.3)分布式部署监控管理平台42与流媒体服务器能够分布式、平行部署,动态扩容,各设备节点都能将信息写到共享的redis(是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。)中进行数据共享,监控管理平台42将在线设备相关信息写入到redis,流媒体服务器将负载信息和流媒体直播相关信息写入redis,这样在多个监控管理平台42、流媒体服务器之间就可以进行直播级联,会话共享。(3.3.4)QoS(服务质量)要求基于IP网络(指基于IP协议簇的网络)开展视频监控业务,网络本身必须对端到端的通信服务质量QoS提供保障。网络视频监控业务的QoS实现要求承载IP网络的音视频码流时,做到延迟小、抖动低、丢包率低。需要达到下表要求:协议丢包率网络延时延时抖动TCP<1/100<200ms<50msUDP<1/1000<500ms<100ms(四)电力安全作业及运维智能监管系统的应用场景(1)电力安全生产行为监管主要监督工作人员在运维检修作业过程中对安全规范准则的遵守情况,实时的检测并识别违反规定的行为。纳入监管范围的违规行为主要包括:未佩戴安全帽;未穿工作服、或上下颜色不统一;穿凉鞋、拖鞋等;工作服挽袖口、挽裤腿;作业场内抽烟;检修作业接打电话;作业时未佩戴安全带、高处防坠用品或装置作业人员擅自穿、跨越规定安全围栏或超越安全警戒线防外力破坏(防外破),针对电力线路设定警戒范围,当有外物闯入与线路或设定目标距离小于安全距离时,系统根据外物类型自动侦测并报警。当出现上述违规行为后,系统会自动分析判断,抓取违规人员的人脸图像,记录存档并提示预警。(2)现场工作人员管理当有监测到有人员进入设定检测区域时,摄像机会检测人脸并抓拍最佳识别度的人脸图像,把人脸抓拍照片发送到后台进行人脸比对、检索等智能业务处理。通过人脸识别检测,可以达到人员监管的目的,例如:人员合法性检测记录是否是备案作业人员(非工作人员作业时应触发告警);非法闯入检测当有嫌疑人进入设定禁区或警戒区域时,嫌疑人会被被标记上醒目警示色如上图红色提醒,并触发告警联动,及时提醒监控中心。(3)现场工作负责人检测在电力施工中有明确要求现场施工负责人需全天候在作业现场,当通过布置的多摄像头方案或进出入门口摄像检测方案确保能正确检测现场工作负责人是否在现场情况,如在工作时间内离岗,系统将自动检测并向主控中心报警。(4)变电站设备运维监测通过对重点区域、重点设备运行状态的24小时实时监测,将运维巡视人员从繁重的巡视任务中解放出来,同时也提升了设备安全动作的可靠性。(4.1)消防预警监测到烟雾及明火后,及时的触发消防报警,避免了以往因反应时间长,偶发性疏忽而造成的严重后果,提升消防安全管理水平。(4.2)设备运行状态辨识前期主要包括室断路器及隔离刀闸分合判定,临近带电体告警、变电设备锈蚀及破损预警等。随着大量的训练和辨认算法成熟度不断提升,将会有更多的设备运行状态纳入到监测范围内。(4.3)电气设备柜门状态辨别施工作业人员完成设备运检未按要求关闭合拢柜门,当发生柜门未关闭时系统会自动通知主要负责人。本实施例中,根据应用场景不同采用不同的神经网络模型,卷积神经网络分为安全行为判别神经网络、设备运行状态判别神经网络和人脸识别神经网络。其中:构建安全行为判别神经网络,利用样本图像训练安全行为判别神经网络,包括:步骤11、构建原始图像数据集:对实际作业环境下工作人员的行为进行拍摄并录制视频,采取视频抽帧的方式获取包含工作人员行为的图片文件,构建原始图像数据集。步骤12、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注分为3个ROI进行,ROI为感兴趣区域;其中,第1个ROI包含人体头部至小腿中部区域;第2个ROI包含颈部和头部区域;第3个ROI包含小腿中部以下及足部。图像依据下述分类规则进行标注:第1个ROI的标注:①规范的长袖长裤着装、②穿短袖上衣、③穿短裤、④长袖上衣挽袖口、⑤长裤挽裤脚、⑥未佩戴安全帽。第2个ROI的标注:①穿安全鞋、②穿拖鞋和凉鞋。第3个ROI标注:①未抽烟及打电话、②打电话、(3)抽烟。标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml(即指可扩展标记语言)文件;全部图片完成标注后,即构成训练数据集。步骤13、设计神经网络判别模型:神经网络判别模型包括输入层、卷积层、池化层和判别输出层;输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出。神经网络判别模型的结构如下:每个卷积层均采取批正则化措施。步骤14、模型训练:模型训练在DarkNet(即暗网)上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法;将训练数据集按预设(本实施例为4:1)的比例分为训练集与验证集;训练集图片数据集随机组合,每k1(本实施例k1=32)张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD(即随机梯度下降)算法进行,设置初始学习率(本实施例中,初始学习率为1e-3,即0.001);每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU(即交并比)值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低(本实施例中,将学习率降低至原学习率的1/2或1/10),继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值(本实施例中,预设阈值为0.01)时,结束模型训练迭代,使用验证集对模型的性能进行评估。步骤5、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并由专业人员对图像标注的结果进行检查和筛选,形成增量图像数据集;将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤14重新训练模型,实现判别模型在增量数据上的持续优化。本实施例中,构建设备运行状态判别神经网络,利用样本图像训练设备运行状态判别神经网络,包括:步骤21、构建原始图像数据集:对实际设备运行状态进行拍摄并录制视频,采取视频抽帧的方式获取包含设备运行状态的图片文件,构建原始图像数据集;步骤22、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注1个ROI,分类标注规则为:①设备正常运行、②设备故障;标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml文件。全部图片完成标注后,即构成训练数据集。步骤23、设计神经网络判别模型:判别模型包括输入层、卷积层、池化层和判别输出层;输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出。神经网络判别模型的结构如下:每个卷积层均采取批正则化措施。步骤24、模型训练:模型训练在DarkNet上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法。将训练数据集按预设(比如:4:1)的比例分为训练集与验证集;训练集图片数据集随机组合,每k2(比如:32)张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD算法进行,初始学习率为1e-3;每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低至原学习率的1/2或1/10,继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值(比如:0.01)时,结束模型训练迭代,使用验证集对模型的性能进行评估。步骤25、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并由专业人员对图像标注的结果进行检查和筛选,形成增量图像数据集。将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤24重新训练模型,实现判别模型在增量数据上的持续优化。本实施例中,构建人脸识别神经网络,利用样本图像训练人脸识别神经网络,包括:步骤31、构建原始图像数据集:对人脸进行拍照,构建人脸数据集。步骤32、构建训练数据集:原始图像数据集构建完成后,对图像进行标注,图像标注1个ROI,即人物的面部特征,分类标注规则为:①根据人员身份ID进行标注;标注后的ROI信息通过1个xml格式文件进行保存,每张图片对应1个xml文件;全部图片完成标注后,即构成训练数据集。步骤33、设计神经网络判别模型:判别模型包括输入层、卷积层、池化层和判别输出层组成,输入层用于图片的输入;卷积层采取多层叠加的形式布置,用于图像特征从低到高的提取;池化层接于卷积层后,用于降低参数规模和防止过拟合;判别输出层采用softmax函数进行分类判别值的输出;神经网络判别模型的结构如下:TypeFiltersSize/StrideOutputConv1-1323X3224X224Maxpool12X2/2112X112Conv2-1643X3112X112Maxpool22X2/256X56Conv3-11283X356X56Conv3-2641X156X56Conv3-31283X356X56Maxpool32X2/228X28Conv4-12563X328X28Conv4-21281X128X28Conv4-32563X328X28Maxpool42X2/214X14Conv5-15123X314X14Conv5-22561X114X14Conv5-35123X314X14Conv5-42561X114X14Conv5-55123X314X14maxpool52X2/27X7Conv6-110243X37X7Conv6-25121X17X7Conv6-310243X37X7Conv6-45121X17X7Conv6-510243X37X7Conv710001X17X7AvgpoolGlobal1000softmax每个卷积层均采取批正则化措施。步骤34、模型训练:模型训练在DarkNet上实现,由DarkNet框架提供神经网络判别模型计算所需要的卷积、池化等算子,以及模型训练和性能评估算法。将训练数据集按预设(比如:4:1)的比例分为训练集与验证集;训练集图片数据集随机组合,每k3(比如:32)张图片组成1个批次,经图像旋转、色彩调节和亮度调节后,逐批次输入模型进行训练,训练采用SGD算法进行,初始学习率为1e-3;每个批次训练完成后,计算模型的损失函数值、损失函数均方差、IOU值和召回率;统计并绘制损失函数变化曲线,根据损失函数值变化情况,对学习率进行调节,具体方法为:观察损失函数曲线,当每个批次模型训练迭代之后,损失函数值出现震荡,则将学习率降低至原学习率的1/2或1/10,继续模型迭代;当损失函数收敛至趋近于零,且损失函数均方差低于预设阈值(比如:0.01)时,结束模型训练迭代,使用验证集对模型的性能进行评估。步骤5、判别模型的持续优化:判别模型上线后,依靠判别模型对视频图像进行自动标注,并由专业人员对图像标注的结果进行检查和筛选,形成增量图像数据集。将增量图像数据集与图像训练数据集合并,形成新的训练数据集,然后按步骤34重新训练模型,实现判别模型在增量数据上的持续优化。本实施例中,k1、k2、k3、初始学习率以及预设阈值等可根据实际情况适当调整。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1