视频生成方法、存储介质和装置与流程
本发明涉及计算机领域,特别涉及一种视频生成方法、存储介质和装置。
背景技术:
相比文字、语音和图片,视频是一种更好的呈现方式,但视频制作依赖人力,成本较高。现存的大量的静态图片,例如绘本,都需要更佳的视频呈现方法。如何将静态图片自动生成视频,是目前急需解决的技术问题。
技术实现要素:
有鉴于此,本发明提供一种视频生成方法、存储介质和装置,以解决如何基于图片自动生成视频的问题。
本发明提供一种视频生成方法,该方法包括:
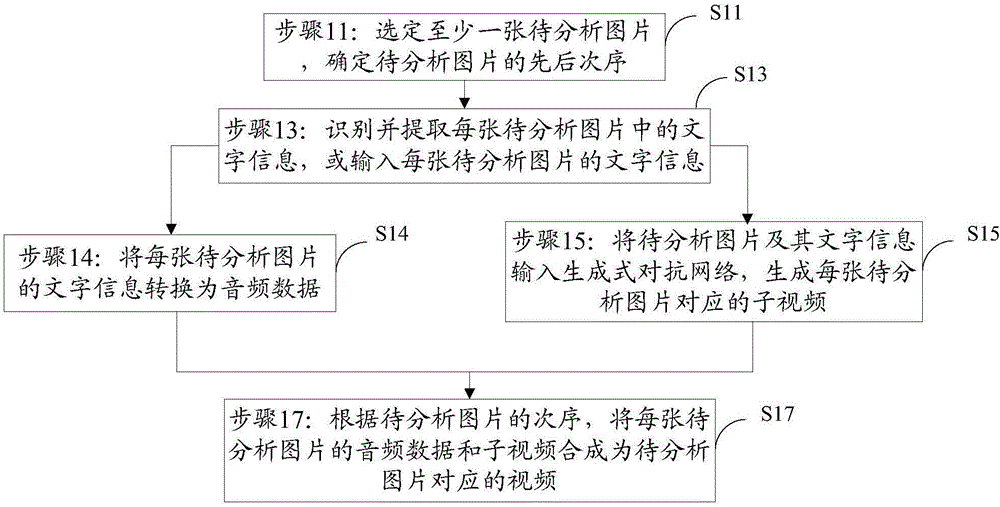
步骤11:选定至少一张待分析图片,确定待分析图片的先后次序;
步骤13:识别并提取每张待分析图片中的文字信息,或输入每张待分析图片的文字信息,分别执行步骤14和步骤15;
步骤14:将每张待分析图片的文字信息转换为音频数据;
步骤15:将待分析图片及其文字信息输入生成式对抗网络,生成每张待分析图片对应的子视频;
步骤17:根据待分析图片的次序,将每张待分析图片的音频数据和子视频合成为所有待分析图片对应的视频。
本发明还提供一种非瞬时计算机可读存储介质,非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行本发明上述的视频生成方法中的步骤。
本发明还提供一种视频生成装置,包括处理器和上述的非瞬时计算机可读存储介质。
本发明使用对抗式生成网络将静态图片生成连续性的视频,本发明设计生成式对抗网络的输入不仅包括图片,还包括该图片相关的文字信息,使生成式对抗网络可以更好地输出该图片相关的子视频,进而确保本发明的视频生成方法可以产生真正的视频。
附图说明
图1为本发明视频生成方法的流程图;
图2为本发明视频生成装置的结构图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
如图1所示,本发明的视频生成方法包括:
步骤11:选定至少一张待分析图片,确定待分析图片的先后次序。
其中,确定待分析图片的先后次序可以自动依据图片的生成时间确定,如果图片是绘本,还可以自动依据页码确定先后次序,或用户人工确定图片的先后次序。
步骤13:识别并提取每张待分析图片中的文字信息,或输入每张待分析图片的文字信息,分别执行步骤14和步骤15。
识别文字信息可以利用光学字符识别技术,例如利用现有的cnn+blstm+ctc组合模型识别并提取每张待分析图片中的文字信息,其中cnn为卷积神经网络,blstm为双向长短时记忆循环神经网络,ctc为时序分类算法。绘本的图片上一般都会附带相关的文字信息。
当图片上没有附带文字信息时,例如照片,则用户可以输入相关的文字作为该图片的文字信息。
步骤14:将每张待分析图片的文字信息转换为音频数据。
步骤15:将待分析图片及其文字信息输入生成式对抗网络,生成每张待分析图片对应的子视频。
现有的生成式对抗网络的输入一般为图片,本发明设计生成式对抗网络的输入不仅包括图片,还包括该图片相关的文字信息,使生成式对抗网络可以更好地输出该图片相关的子视频。
如果待分析图片包含多张图片,可以每次将一张图片及其文字信息输入生成式对抗网络,生成式对抗网络输出该图片相关的子视频,或者一次将所有图片及其文字信息输入生成式对抗网络,生成式对抗网络输出每张图片相关的子视频。一次将所有图片输入生成式对抗网络,有利于生成式对抗网络更好地理解所有图片综合表达的内容。
本发明生成式对抗网络训练方法包括:
步骤201:样本数据准备,从互联网下载视频,将同一场景的视频分割成独立的n个子部分,每个子部分的时长为3-4秒,为每个子部分添加的描述文字;
步骤202:取每个子视频的第一帧备用,通过2d卷积获取该第一帧的特征图向量;将子视频的描述文字转换成向量;并和图像特征向量融合,作为生成式对抗网络的生成器的输入;
步骤203:由生成器预测第一帧后续的数十帧,产生3~4秒的短视频(标准动画的帧率为24fps);
步骤204:生成器产生的短视频作为生成式对抗网络判别器的输入,判别器通过比较子视频(真视频)与短视频(假视频)的偏差来校对生成式对抗网络内的参数。
步骤17:根据待分析图片的次序,将每张待分析图片的音频数据和子视频合成为所有待分析图片对应的视频。
可选地,在步骤14和步骤15之后,以及步骤17之前还包括:
步骤16:比较每张待分析图片的音频数据的时长与其子视频的时长是否相同,如果不同,通过调整待分析图片的子视频的时长和/或调整其音频数据的时长使两者的时长相同。
当每张待分析图片的音频数据的时长与其子视频的时长不同时,可使用ffmpeg调节子视频的播放速度以调整视频时长,或调节音频的比特率来调节音频的时长。考虑到调节比特率会影响音频的播放效果,因此一般采用调节视频时长来匹配音频时长。
在图1中,步骤14的一种实现方式为:
步骤141:通过语音合成tts(texttospeech)技术将每张待分析图片的文字信息转换为相应的音频数据。
在图1中,步骤14的另一种实现方式为:
步骤141-1:将每张待分析图片及其文字信息输入cnn+lstm模型,或将每张待分析图片及其文字信息的关键字输入cnn+lstm模型,输出每张待分析图片的文字增强描述;
步骤141-2:通过语音合成tts技术将每张待分析图片的文字增强描述转换为相应的音频数据。
上述cnn+lstm模型中cnn用于特征提取可采用现有模型。
其中lstm的训练方法如下:
步骤301:将样本图片输入已经训练好的开源物体检测模型(ssd,yolo等),开源物体检测模型输出样本图片的多标签属性表;
根据使用场景不同,比如针对动画绘本,可以采集对应的数据集,通过迁移学习微调网络,使得识别效果更出色。
步骤302:识别样本图片所包含的文字信息,并对其进行分词后,匹配上述多标签属性表,如果多标签属性表中的任一标签出现在文字信息中,则增加该标签在多标签属性表中的属性值;比如:文字信息中包含了“鸟”,则将属性表中的“鸟”对应的属性(或称为概率)从0修改为1.0;
步骤303:将多标签属性表输入长短期记忆网络lstm,lstm输出该标签属性表的文字增强描述;
步骤304:通过比较文字增强描述和样本图片对应的样本描述之间的差异来训练lstm。
进一步地,步骤17还包括:将每张图片的文字增强描述以字幕的形式添加到所有待分析图片对应的视频中。
用户在观看合成视频的时候,可以选择是否显示字幕。
本发明的方法可用于儿童绘本,基于绘本图片,将绘本故事转换为视频,用于儿童辅助教育。
本发明的方法还可以用于动画行业,基于少量的画面例如动漫,生成动画,减少动画制作的人力成本。
本发明的方法还用于手机相册的“故事模块”,由用户自己选择,或者根据用户拍摄的时间、地点以及场景的关联性,手动或自动从用户的相册中选取多张图片,然后基于选择的图片生成真实的视频,让“故事模块”可以真正的讲故事,更具趣味性。
本发明的方法还可用于制作社交网站或新闻行业的短视频素材,基于拍摄的原始照片素材,快速生成一段新闻视频。
本发明旨在提供一种新颖的视频生成方式,通过现有的单张或多张静态图片生成其对应的视频,有效提高了信息呈现的可读性,提升用户体验,并减少人力制作视频的成本。
本发明还提供一种非瞬时计算机可读存储介质,非瞬时计算机可读存储介质存储指令,指令在由处理器执行时使得处理器执行本发明上述的视频生成方法中的步骤。
本发明还提供一种视频生成装置,包括处理器和上述的非瞬时计算机可读存储介质。
如图2所示,本发明的视频生成装置包括:
图片输入模块:选定至少一张待分析图片,确定待分析图片的先后次序;
文字信息模块:识别并提取每张待分析图片中的文字信息,或输入每张待分析图片的文字信息,分别执行音频生成模块和音频生成模块;
音频生成模块:将每张待分析图片的文字信息转换为音频数据;
视频生成模块:将待分析图片及其文字信息输入生成式对抗网络,生成每张待分析图片对应的子视频;
音视频合成模块:根据待分析图片的次序,将每张待分析图片的音频数据和子视频合成为待分析图片对应的视频。
可选地,在音频生成模块和视频生成模块之后,以及音视频合成模块之前还包括:
匹配调整模块:比较每张待分析图片的音频数据的时长与其子视频的时长是否相同,如果不同,通过调整待分析图片的子视频的时长和/或调整其音频数据的时长使两者的时长相同。
可选地,在文字信息模块中,识别并提取每张待分析图片中的文字信息包括:基于cnn+blstm+ctc模型识别并提取每张待分析图片中的文字信息。
可选地,音频生成模块包括:通过语音合成tts技术将每张待分析图片的文字信息转换为相应的音频数据。
进一步地,音频生成模块包括:
文字增强模块:将每张待分析图片及其文字信息输入cnn+lstm模型,或将每张待分析图片及其文字信息的关键字输入cnn+lstm模型,输出每张待分析图片的文字增强描述;
音频转换模块:通过语音合成tts技术将每张待分析图片的文字增强描述转换为相应的音频数据。
可选地,音视频合成模块还包括:将每张图片的文字增强描述以字幕的形式添加到待分析图片对应的视频中。
需要说明的是,本发明的视频生成装置的实施例,与视频生成方法的实施例原理相同,相关之处可以互相参照。
以上所述仅为本发明的较佳实施例而已,并不用以限定本发明的包含范围,凡在本发明技术方案的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!