无线资源调度一体智能化控制系统及方法、无线通信系统与流程
本发明属于无线通信技术领域,尤其涉及一种无线资源调度一体智能化控制系统及方法、无线通信系统。
背景技术:
目前,业内常用的现有技术是这样的:第五代移动通信系统提供并支持三种类型的场景,包括增强移动宽带(enhancedmobilebroadband,embb),超可靠低延迟通信(ultra-reliableandlowlatencycommunications,urllc),以及大规模机器通信(massivemachinetypecommunications,mmtc),新兴场景对吞吐量、可靠性、时延等提出了更高的需求。同时,随着智能终端的发展,业务呈现多样性和异构性,如在线阅读,在线游戏,虚拟现实/增强现实等多样业务提出更严格的qos需求以保障用户体验。因此,如何灵活调度无线资源以保障和提升用户体验,是目前相关工程和科研领域的热点问题之一。每个基站执行无线资源调度的主体是资源调度模块,它的主要功能是为用户分配共享信道的rb以保障用户qos需求和提升资源利用率。无线资源调度过程主要包括用户调度和资源分配。用户调度根据相关参数,如信道质量信息(channelqualityinformation,cqi)和qos,确定待调度用户和它们的优先级。目前常用的用户调度规则有最大载干比(maxchannel/interference,maxc/i),轮询(roundrobin,rr),比例公平(proportionalfairness,pf),以及增强型比例公平(enhancedproportionalfairness,epf)等。资源分配根据相关参数,如待传输包的大小、用户优先级等,确定分配给用户的rb数量和rb位置。然而,目前的不同资源调度规则无法应对第五代移动通信系统中更多样和复杂的通信需求,这些需求可能体现在时延、吞吐量、可靠性、甚至是它们的结合。现有资源调度规则侧重不同的需求,如maxc/i侧重吞吐量,rr侧重公平性,pf实现吞吐量和公平性的折中,epf考虑了qos需求,缺乏灵活性和融合性,无法适应第五代移动通信系统中丰富的网络场景。此外。现有提高灵活性的方法主要是在每个tti内选择最佳的调度规则,然后执行该规则从而产生最合适的调度策略,但在不同调度规则间切换需要较长时间,造成了高的切换时延且降低了决策时效性。同时,资源调度通常被考虑成高复杂大规模的优化问题,在第五代移动通信系统超密集网络中,由于用户和基站数量的增加,问题建模和求解变得更复杂。因此,如何针对第五代移动通信系统的丰富场景和多样需求,建模资源调度问题,实现灵活高效的无线资源调度是拟解决的问题之一。
传统的性能优化通常侧重于优化单个模块,然而,由于更加复杂和动态的网络,单模块优化思路面临优化模型不精确以及模块之间策略失配等挑战。模块一体化已经成为一种发展趋势,目的是实现全局最优代替子模块最优,从而减少增益损失,提升算法泛化性,提高决策实时性。因此,如何实现模块一体化的无线资源调度是拟解决的问题之一。随着智能化浪潮的发展及各大产业规模的稳步增长,智能化被认为是当前无线通信低迷和徘徊不前的爆发点、拐点和超级引擎,也是第五代移动通信网络的关键的特征之一。因此,如何实现一体智能化无线资源调度是迫在眉睫的拟解决问题之一。现有技术一公开了一种基站、小基站和通信链路资源的调度方法。其中,基站指宏基站,小基站指微基站。该方法的具体步骤是:首先,微基站向宏基站上报负载信息和信道状态信息。其次,宏基站在毫米波频段向微基站发送无线资源占用信息,指示微基站的无线资源被无线回程链路占用的情况。然后,微基站根据信道状态信息和无线资源占用信息,将微基站的无线回程链路所需的无线资源分配给该微基站。最后,微基站将剩余无线资源分配给接入链路,用于传输用户数据。该方法中宏基站根据各个微基站的负载信息动态的调整回程链路资源,提升了网络资源利用率和系统容量。但该方法侧重宏基站到微基站的无线资源分配,没有实现微基站到用户的无线资源分配,即接入链路无线资源的分配情况。而且,该方法仅提供了用于实现无线资源调度的微基站和宏基站的功能模块,但没有提供具体的资源调度数学模型。现有技术二基于频谱衬垫的认知ofdm系统比例公平资源分配方法。该方法采用启发式算法分配无线资源,可提高资源利用率和系统吞吐量。该方法的具体步骤是:第一步,认知基站获取资源分配所需的信道状态信息;第二步,认知基站基于萤火虫方法分配频率和功率资源;第三步,认知基站通过广播方式将资源分配结果通知认知用户。该方法限定比例公平规则分配无线资源,缺乏灵活性和融合性,无法适应和满足第五代移动通信系统中丰富的网络场景以及用户在吞吐量、可靠性、时延等性能的多样化需求。
综上所述,现有技术存在的问题是:
(1)现有技术侧重宏基站到微基站的无线资源分配,没有实现微基站到用户的无线资源分配,即接入链路无线资源的分配情况。而且,现有技术一仅提供了用于实现无线资源调度的微基站和宏基站的功能模块,没有提供具体的资源调度数学模型。
(2)现有技术限定比例公平规则分配无线资源,缺乏灵活性和融合性,无法适应和满足第五代移动通信系统中丰富的网络场景以及用户在吞吐量、可靠性、时延等性能的多样化需求。
解决上述技术问题的难度:如何智能建模第五代移动通信系统超密集网络中的无线资源调度问题,以适应多种类型的场景和丰富异构的业务;如何针对用户的不同的qos需求,灵活地分配无线资源,以满足用户对吞吐量、可靠性、时延等性能的需求。
解决上述技术问题的意义:解决难点对用户的体验、网络的演进、以及智能化应用于无线通信的推动具有重要意义。解决难点使所提方法在在第五代移动通信系统中发挥更优性能具有重要意义。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种无线资源调度一体智能化控制系统及方法、无线通信系统。
本发明是这样实现的,一种无线资源调度一体智能化控制方法,所述无线资源调度一体智能化控制方法包括:基站获取待调度用户列表;基站收集用户无线资源调度相关参数,并构建状态空间;基站根据深度神经网络为所有用户决策资源调度动作;基站利用深度神经网络计算当前状态动作对应的累积奖励;基站执行资源分配动作并获得环境反馈的期望累积奖励;基站在线更新深度神经网络。
进一步,所述基站获取待调度用户列表如下:
listj=[1,2,...,i,...mj];
其中,listj表示第j个基站服务的用户列表,mj表示第j个基站服务的用户数量,i表示第i个用户。
进一步,所述基站构建当前环境状态如下:
sj={s1,...,si,...,smj},
其中,sj表示第j个基站的状态,由mj个元组组成,si表示第i个用户的状态,
进一步,所述基站根据深度神经网络为所有用户决策资源调度动作,其动作空间如下:
aj={a1,...,ai,...,amj};
其中,aj表示第j个基站的动作空间,由mj个元素组成,ai表示第i个用户被分配的资源块rb数量。
进一步,基站利用深度神经网络计算当前状态sj动作aj下输出的累积奖励值为qj,mainnet(sj,aj|θj),其中mainnet是权重参数为θj的深度神经网络,深度神经网络的输入为(sj,aj),输出为第j个基站在状态sj动作aj下计算得到累积奖励值qj,mainnet(sj,aj|θj)。
进一步,所述基站执行资源分配动作并获得环境反馈的期望累积奖励,输出的期望累积奖励值为:
其中,yj表示第j个基站在状态sj下执行动作aj获得的期望累计奖励值,rj(sj,aj)表示第j个基站在状态sj下执行动作aj获得的网络反馈的立即奖励值,当第j个基站在状态sj下执行动作aj后,该基站进入新状态sj′,qj,targetnet(sj′,aj′|θj)表示第j个基站在状态sj′和最优动作aj′下通过权重参数为θj的深度神经网络targetnet计算得到的未来累计奖励值,γ表示折扣因子。
进一步,所述深度神经网络targetnet和深度神经网络mainnet具有相同的结构,初始时刻,targetnet和mainnet具有相同的权重参数θj;mainnet被用于更新权重参数θj,targetnet被用于估测未来累计奖励值,计算期望累积奖励值;每隔一定周期,mainnet将更新的权重参数赋值给targetnet。
进一步,所述基站在线更新深度神经网络,更新方法如下:
lj(θj)=(yj-qj,mainnet(sj,aj|θj))2;
其中,lj(θj)是第j个基站用于更新深度神经网络mainnet的损失函数,对θj执行梯度下降从而最小化损失函数。
本发明的另一目的在于提供一种实现所述无线资源调度一体智能化控制方法的无线资源调度一体智能化控制系统,所述无线资源调度一体智能化控制系统采用智能工具,深度强化学习,聚合用户调度和资源分配功能,基于无线资源调度的相关参数,为所有用户同时决策资源分配结果。
本发明的另一目的在于提供一种应用所述无线资源调度一体智能化控制方法的移动通信系统。
综上所述,本发明的优点及积极效果为:本发明实现了联合用户调度和资源分配的智能无线资源调度,推进了智能化在实时通信的发展。本发明基于现有无线资源调度流程,采用深度强化学习方法智能建模超密集网络中的无线资源调度问题,克服了现有技术中无线资源调度问题难建模或模型不准确的不足,使得本发明有效实现自动的无线资源管理。
本发明考虑了用户多样业务和异构qos需求,优化目标是最大化用户在不同qos指标的满意度,实现了用户体验的提升。本发明可灵活适应用户在可靠性、吞吐量、时延等性能的变化的需求,克服了现有技术中不同调度规则适用不用需求和不同场景的不足,使得本发明有效提升场景应用的泛化能力。
本发明采用智能化的无线资源调度架构,聚合了用户调度和资源分配模块,提升了实时通信的决策时效性。本发明避免了性能侧重不同的调度规则的选择,克服了现有技术中在不同调度规则间选择和切换造成时延高的不足,使得本发明有效应用时延敏感的实时通信场景。
附图说明
图1是本发明实施例提供的无线资源调度一体智能化控制系统结构示意图。
图2是本发明实施例提供的无线资源调度一体智能化控制方法流程图。
图3是本发明实施例提供的无线资源调度一体智能化控制方法实现流程图。
图4是本发明实施例提供的超密集网络场景示意图。
图5是本发明实施例提供的无线资源调度算法图。
图6是本发明实施例提供的无线资源调度仿真图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
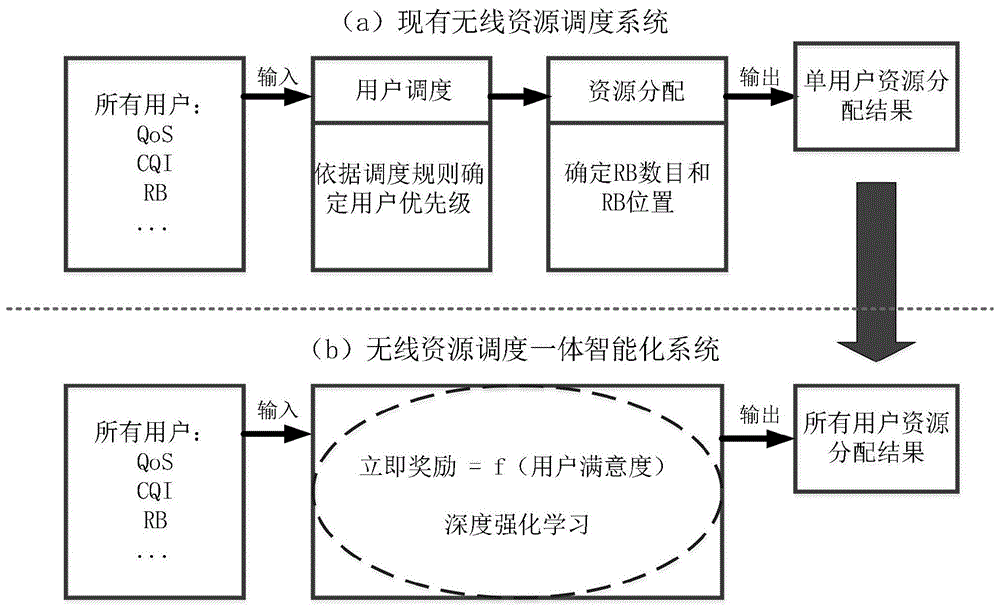
如图1所示,本发明实施例提供的无线资源调度一体智能化控制系统基于深度强化学习联合实现用户调度和资源分配,在这种架构下,基站可实现智能化自动化无线资源管理。
现有无线资源调度系统采用人为逻辑建模的方式,如图1(a)所示,主要包含四个步骤:第一步,基站收集所有待调度用户的无线资源调度相关参数,如cqi,qos等;第二步,基站依据调度规则,如pf,rr等,确定待调度用户的优先级;第三步,基站确定分配给最高优先级用户的rb数量和rb位置;第四步,基站通过下行物理控制信道通知用户资源分配结果。现有无线资源调度系统一次输出一个用户的资源分配结果。
本发明的无线资源调度一体智能化控制系统采用智能化建模的方式,如图1(b)所示,主要包含三个步骤:第一步,基站收集所有待调度用户的无线资源调度相关参数,如cqi,qos等;第二步,基站确定分配给所有待调度用户的rb数量和rb位置;第三步,基站通过下行物理控制信道通知用户资源分配结果。无线资源调度一体智能化控制系统的输出是所有用户的资源分配结果。
本发明的无线资源调度一体智能化控制系统基于深度强化学习可建立用户无线资源调度相关参数和无线资源分配结果间的隐含数学关系。为提升用户体验,本发明将立即奖励设计为用户相对于不用qos指标,如时延、吞吐量等,的用户满意度函数。本发明的目标是针对用户不用qos需求,通过有效的资源分配最大化用户满意度。所提基于深度强化学习的架构是智能化的学习架构,具备以下优势:克服现有技术中通过选择和切换调度规则面临决策时效性低的挑战,实现用户体验的提升,以及克服现有技术中基于人为逻辑建模面临建模困难或模型不准确的挑战,实现自动智能无线资源管理。
如图2所示,本发明实施例提供的无线资源调度一体智能化控制方法包括以下步骤:
s101:基站获取待调度用户列表:基站将处于活跃态且在媒体访问控制层有包待传输的用户组成待调度用户列表;
s102:基站收集用户无线资源调度相关参数,并构建状态空间:基站获取用户反馈的物理层cqi等信息,获取用户的高层qos等信息,构建深度强化学习的状态空间;
s103:基站根据深度神经网络为所有用户决策资源调度动作:在当前状态下,基站采用targetnet深度神经网络在动作空间中选择最优资源调度动作;
s104:基站利用深度神经网络计算当前状态动作对应的累积奖励:在当前状态动作对下,基站采用mainnet深度神经网络计算累积奖励值;
s105:基站执行资源分配动作并获得环境反馈的期望累积奖励:基站执行选择的最优资源调度动作,获得环境反馈的立即奖励,并依据targetnet深度神经网络获得期望累积奖励值;
s106:基站在线更新深度神经网络:基站基于累积奖励值和期望累积奖励值最小化损失函数,更新mainnet深度神经网络。
下面结合附图对本发明的应用原理作进一步的描述。
如图3所示,本发明实施例提供的无线资源调度一体智能化控制方法具体包括以下步骤:
本发明的应用场景为超密集蜂窝网络,实施例基于超密集小基站(smallbasestation,sbs)网络场景说明。超密集小基站网络场景示意图参照图4。图4包含多个sbss和多个用户设备(userequipment,ue),具有不同qos需求的ues随机分布在sbss周围。在每个tti,每个sbs为它服务的ues执行无线资源调度。本实施例考虑的前提是上层控制器为每个小基站分配部分子带,该分配的目标是最小化sbss间干扰造成的性能损失。基于此前提,本发明可以将sbss间的干扰当做噪声。为了方便呈现,本发明考虑相邻sbss使用正交子带,不相邻sbss可复用子带,如图4所示,具有相同颜色的sbss意思是子带复用,具有不同颜色的sbss意思是子带正交。例如,sbs1、sbs2、sbs3、sbs4、sbs5、sbs6、sbs8、sbs9是子带正交,而sbs1和sbs7是子带复用。ue1被sbs1服务,可以接收到来自sbs1的有用信号和来自sbs7的干扰信号。需要说明的是本发明不局限于当前示意图中的超密集小基站网络场景、sbs数量以及ue数量。
步骤一,基站获取待调度用户列表。
基站将处于活跃态且在媒体访问控制层有包待传输的用户组成待调度用户列表,待调度用户列表表示如下:
listj=[1,2,...,i,...mj];
其中,listj表示第j个基站服务的用户列表,mj表示第j个基站服务的用户数量,i表示第i个用户。
步骤二,基站收集用户无线资源调度相关参数,并构建状态空间。
基站获取用户反馈的物理层cqi等信息,获取用户的高层qos等信息,状态表示如下:
sj={s1,...,si,...,smj};
其中,sj表示第j个基站的状态,由mj个元组组成,si表示第i个用户的状态,表示如下:
其中,
f={f1,f2,...,ff}表示qos指标集合,其中qos指标包括保证比特率(guaranteebiteratio,gbr)、时延等,f表示qos指标的数量,
其中,xi表示第i个用户的qos提供,表示如下:
xi={xi,f1,xi,f2,...,xi,ff};
f={f1,f2,...,ff}表示qos指标集合,xi,ff表示基站通过无线资源调度提供给第i个用户在qos指标ff的性能。qos提供取决于无线资源调度的效率。
其中,
e={e1,e2,...,ee}表示环境参数的集合,其中环境参数包括cqi、业务到达率等,e表示环境参数的数量,
步骤三,基站根据深度神经网络为所有用户决策资源调度动作。
第j个基站的动作空间表示如下:
aj={a1,...,ai,...,amj};
其中,aj表示第j个基站的动作空间,由mj个元素组成,ai表示第i个用户被分配的rb数量。在当前状态下,基站采用targetnet深度神经网络在动作空间中选择最优资源调度动作,表示如下:
其中,aj*表示第j个基站最优资源调度动作,
步骤四,基站利用深度神经网络计算当前状态动作对应的累积奖励。
在当前状态sj动作aj对下,基站采用mainnet深度神经网络计算累积奖励值qj,mainnet(sj,aj|θj),其中,θj表示mainnet深度神经网络的权重。mainnet深度神经网络的输入为(sj,aj),输出为第j个基站在状态sj动作aj下计算得到累积奖励值qj,mainnet(sj,aj|θj)。
步骤五,基站执行资源分配动作并获得环境反馈的期望累积奖励。
基站在状态sj执行选择的最优资源调度动作aj*,获得环境反馈的立即奖励,表示如下:
其中,rj(sj,aj)表示第j个基站在状态sj执行选择的最优资源调度动作aj*获得的立即奖励,mj表示第j个基站服务的用户数量,f表示qos指标的数量,si,fff表示第i个用户在qos指标fff的用户满意度,与qos需求和qos提供有关。
基站依据targetnet深度神经网络获得期望累积奖励值,表示如下:
其中,yj表示第j个基站在状态sj下执行动作aj获得的期望累计奖励值,rj(sj,aj)表示第j个基站在状态sj下执行动作aj获得的网络反馈的立即奖励值,当第j个基站在状态sj下执行动作aj后,该基站进入新状态sj′,qj,targetnet(sj′,aj′|θj)表示第j个基站在状态sj′和最优动作aj′下通过权重参数为θj的深度神经网络targetnet计算得到的未来累计奖励值,γ表示折扣因子。
步骤六,基站在线更新深度神经网络。
基站基于累积奖励值和期望累积奖励值最小化损失函数,损失函数表示如下:
lj(θj)=(yj-qj,mainnet(sj,aj|θj))2;
其中,lj(θj)是第j个基站关于权重θj的损失函数,基站对θj执行梯度下降从而最小化损失函数,以更新mainnet深度神经网络。初始时刻,targetnet和mainnet具有相同的权重参数θj。mainnet被用于更新权重参数θj,targetnet被用于估测未来累计奖励值,从而计算期望累积奖励值。每隔一定周期,mainnet将更新的权重参数赋值给targetnet。
如图5所示,本发明具体实施过程如下:
第一步,初始tti,第j个基站初始化权重θj,折扣因子γ,赋值周期c,记录当前状态sj。
第二步,通过ε贪婪算法选择资源调度动作aj*,ε贪婪算法如下:
其中,ε∈(0,1)表示探索率,
第三步,通过mainnet深度神经网络计算累积奖励值qj,mainnet(sj,aj|θj),在当前状态sj动作aj对下,基站采用mainnet深度神经网络计算累积奖励值qj,mainnet(sj,aj|θj),其中,θj表示mainnet深度神经网络的权重。mainnet深度神经网络的输入为(sj,aj),输出为第j个基站在状态sj动作aj下计算得到累积奖励值qj,mainnet(sj,aj|θj)。
第四步,第j个基站执行aj*后,获取立即奖励rj(sj,aj),更新状态sj′。其中,rj(sj,aj)为第j个基站执行aj*后的用户满意度。
第五步,第j个基站在状态sj下执行动作aj依据targetnet深度神经网络获得期望累积奖励值,表示如下:
其中,rj(sj,aj)表示第j个基站在状态sj下执行动作aj获得的网络反馈的立即奖励值,当第j个基站在状态sj下执行动作aj后,该基站进入新状态sj′,qj,targetnet(sj′,aj′|θj)表示第j个基站在状态sj′和最优动作aj′下通过权重参数为θj的深度神经网络targetnet计算得到的未来累计奖励值,γ表示折扣因子。
第六步,计算损失函数lj(θj)=(yj-qj,mainnet(sj,aj|θj))2。基站对θj执行梯度下降从而最小化损失函数,以更新mainnet深度神经网络。
第七步,如果tti=c,将mainnet深度神经网络权重赋值给targetnet深度神经网络,即qj,targetnet=qj,mainnet。将tti计数置0。
如图6所示,对本发明的效果作进一步简化说明。仿真环境见表1。
表1仿真环境
本发明实施例考虑用户具有四种不同的业务类型,分别是恒定比特率(constantbitrates,cbr)、可变比特率(variablebitrates,vbr)、视频会话(conversationalvideo,cv)、非会话类视频(non-conversationalvideo,ncv)。qos指标包含两种,分别是gbr和时延。基于表1的仿真参数得到无线资源调度仿真结果如图6所示。横轴是仿真时间,纵轴是用户平均不满意度。为了更好的展现细节和趋势,本发明采用用户不满意度表征无线资源调度性能。从图中可以看出,折扣因子γ对收敛速率有影响,当γ为0.01时,算法在2000ms左右收敛,当γ为0.05时,算法在3000ms左右收敛,当γ为0.2时,算法在6000ms左右收敛。随着γ的增大,算法收敛速度变慢,这是因为无线资源调度属于实时通信,因此更注重立即回报。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!