一种云存储数据安全审计方法与流程
本发明涉及云计算数据安全技术领域,更具体地,涉及一种云存储数据安全审计方法。
背景技术:
随着云计算的快速发展,越来越多的用户将数据存储在云端。用户在享受高性能和低成本云存储服务的同时,也面临着由于失去对数据的绝对控制权所带来的安全问题。尽管云服务提供商(Cloud Server Provider,CSP)承诺为用户提供一个安全可靠的存储环境,但由于云服务器是半可信的,当存储在云端的用户数据出现丢失、泄漏等情况时,云服务提供商很可能会为了自己的利益和声誉对用户隐瞒这一事实。因此,对存储在云端数据进行安全审计显得尤为重要。为了使审计结果公平可信,并降低成员在审计过程中计算和通信的开销,通常引入第三方审计者(third party auditor,TPA)来替代用户进行审计工作,但数据在公开审计时,不可避免地要提供部分与数据有关的信息,这可能威胁到数据本身的安全性和隐私性,导致成员数据内容可能被第三方审计者获取等问题。
针对这些问题,考虑数据单一所有者情况下,研究者从数据隐私保护,批量审计,动态数据审计等方面进行了研究。为了保护数据隐私:Ateniese等(Ateniese G,Burns R,Curtmola R,et al.Provable data possession at untrusted stores[C]//Proc of ACM Conference on Computer and Communications Security.Alexandria,Va,USA:ACM,2007:598-609.)提出基于RSA同态标签技术的可证明数据所有权模型,用户计算数据块标签,并与数据一起上传至服务器。挑战验证时,TPA向服务器发出挑战集,服务器根据挑战集产生证据再发送回TPA,TPA对证据进行验证。该方案降低了CSP和TPA的通信开销,但用户和CSP的通信开销和存储开销较大。Wang等(Wang C,Chow S S M,Wang Q,et al.Privacy-Preserving Public Auditing for Secure Cloud Storage[J].IEEE Transactions on Computers,2013,62(2):362-375.)提出基于BLS签名的云数据安全审计方案。在同等安全强度下,该方案的签名长度比RSA签名要短,降低了通信和存储开销,提高审计效率;同时,在将随机掩码引入数据块聚合值中,保护数据隐私。为了实现数据的动态审计,Erway等(Erway C C,Alptekin,Papamanthou C,et al.Dynamic Provable Data Possession[C]//ACM,2015:1-29.)提出了基于Skip list的支持全动态可证明数据所有权方案,支持数据全动态操作。Wang等(Wang Q,Wang C,Ren K,et al.Enabling Public Auditability and Data Dynamics for Storage Security in Cloud Computing[J].IEEE Transactions on Parallel and Distributed Systems,2011,22(5):847-859.)提出了基于Merkle Hash树的动态审计方案.该方案中叶结点使用的是数据块,用户每次执行更新操作或审计者每次执行审计操作时,云服务器为了构造MHT,不得不读取所有数据块;为减小用户动态操作和审计者执行审计过程的通信开销而选择长度较小的数据块时,MHT的高度将会变得非常高。为了实现批量审计,Wang等(Wang C,Wang Q,Ren K,et al.Privacy-Preserving Public Auditing for Data Storage Security in Cloud Computing[J].2010,62(2):525-533.)提出利用聚合标签的方法将数据标签组合实现批量审计,该方法能降低运算的次数。
金瑜等(金瑜等.基于MapReduce的云存储数据审计方法研究[J].计算机科学,2017,44(2):195-201.)针对以上数据安全审计方案审计效率较低,用户计算量较大等问题,提出了基于MapReduce云存储数据审计方案,将数据签名计算代理出去,减少了用户计算量,并行化数据签名和批量审计过程,提高了审计效率,由于Mapreduce自身的实现机制限制,不能有效处理频繁迭代计算和基于非内存计算,每次Mapper操作需要将计算结果写入磁盘,在效率上存在瓶颈。同时,MapReduce适合处理离线数据,无法满足大规模数据实时性处理的要求。已有的基于MapReduce的并行云存储数据安全审计方法,所处理的是存储在HDFS的离线数据,当用户发送数据到代理签名方请求签名时,并不会得到实时的响应,代理签名方需要将该请求的待签名数据存储在HDFS中,并等待签名请求达到一定的数量时,代理签名方才从HDFS中获取用户数据并进行签名,签名和审计的延迟性,无法满足一些用户对签名和审计实时性的要求,实用性不高。
技术实现要素:
本发明的首要目的是提出一种云存储数据安全审计方法,基于spark streaming,针对在大规模用户及云计算环境下,传统云存储数据安全审计方法的审计效率低、用户计算量大的问题,以及常见的基于MapReduce的云存储数据安全审计方法的审计效率不高、不支持实时处理数据签名和审计等缺点,实现了实时处理用户数据块签名和批量审计的高效的云存储数据安全审计。
为解决上述技术问题,本发明的技术方案如下:
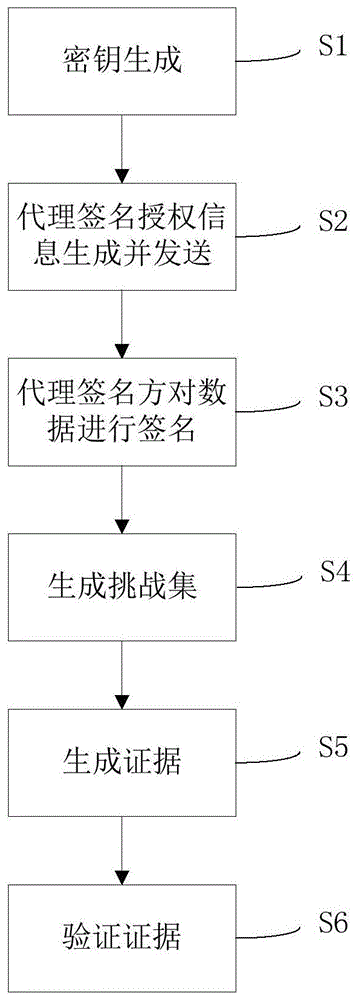
一种云存储数据安全审计方法,包括以下步骤:
S1:密钥生成:随机选取x←Zp,u←G1,计算v←gx∈G2,其中Zp表示为整数模数p剩余类集合,G1,G2,GT是阶为素数p的乘法循环群,g是乘法循环群G2的生成元,G1,G2满足双线性对映射e:G1×G2→GT,定义私钥sk=(x),公钥pk=(u,g,v);
S2:代理签名授权信息生成并发送:随机选取y←Zp,产生用户身份信息mw,计算Q=gy∈G2,P=h(mw,Q)·x+y,P∈Zp,其中h为单向哈希函数,将待签名数据F和代理授权信息(P,Q,mw),即{F,P,Q,mw}发送给代理签名方;
S3:代理签名方对数据进行签名:代理签名方利用Kafka作为消息队列服务器,在微批处理时间区间内持续接收用户传递来的{F,P,Q,mw},使用Spark Streaming将接收到的{F,P,Q,mw},分成数据块存放在Spark Streaming的数据块队列中,Spark通过任务调度器对Spark Streaming的数据块队列数据进行计算,将计算结果发送至云服务提供商中进行存储和维护;
S4:生成挑战集:第三方审计者从集合[1,n]之间选取c个元素,组成集合I,对于每一个i∈I,随机生成νi∈ZP,挑战集chal={(i,νi)i∈I},将挑战集chal发送给云服务器;
S5:生成证据:云服务提供商收到来自第三方审计者的挑战集chal时,云服务器提供证据proof={μ,σ,R,H(mi)i∈I}返回第三方审计者,其中R是随机掩码,R=(ω)d=(uPSK)d,其中d为第三方审计者为每次审计任务而随机产生的;
S6:验证证据:第三方审计者利用Kafka作为消息队列服务器,不断接收云服务提供商传递来的proof信息,并对proof信息进行验证后把验证结果发送到每个用户。
优选地,S3中Spark通过任务调度器对Spark Streaming的数据块队列数据进行计算,具体包括以下步骤:
S3.1:将Spark Streaming的数据块队列数据作为输入流分布式数据集userDStreamRDD,并使用partitionBy函数进行分区;
S3.2:在每个分区使用flatMap函数将userDStreamRDD每行字符串解析出验证用户授权信息和数据签名所需参数<T,(P,Q,mw)>,T为用户标签;
S3.3:使用filter函数筛选满足gP=vr·Q的授权信息正确的用户待签名数据和对应签名参数,其中r=h(mw,Q);
S3.4:选择私钥z←Zp,计算PSK=P+z·r,PPK=vr·gz·r·Q以及ω=uPSK,并将文件分块,即F=(m1,m2,···,mn),使用map函数计算数据块签名,:H(·)为将二进制字符串映射到G1的哈希函数;
S3.5:使用reduce函数将各个分区用户的数据块签名归并到master节点上;
S3.6:代理签名方将{F,Φ}发送至云服务提供商进行存储和维护,Φ为数据块签名集合。
优选地,步骤S6的验证数据的具体步骤包括:
S6.1:将proof信息作为输入流分布式数据集pfDStreamRDD,并使用partitionBy函数进行分区;
S6.2:在每个分区中使用flatMap函数将pfDStreamRDD每行字符串解析出验证证据所需的参数;
S6.3:对于每个用户的数据证据,使用map函数验证:
输出键值对<T,ture/false>;
S6.4:使用reduce函数将各个分区数据验证结果归并到master节点上;
S6.5:将每个用户数据的验证结果根据T发送到每个用户。
优选地,步骤S3.1中的数据块队列数据格式为文本文件格式,所述文本文件中每行一条记录,每一条记录代表一个用户数据块签名和验证代理授权信息所需所有参数,记录中的每个字段以“,”为分隔符分开。
优选地,步骤S3各个分区的用户签名输出为文本文件格式,所述文本文件中每行一条记录,每一条记录代表一个用户标识和数据块签名结果,记录中的每个字段以“,”为分隔符分开。
优选地,所述的proof信息为文本文件格式,每行一条记录,每一条记录代表服务器产生的一个证据,记录中的每个字段以“,”为分隔符分开。
优选地,步骤S6.5中的验证结果为文本文件格式,每行一条记录,每一条记录代表一个挑战标识和该挑战数据的验证结果,记录中的每个字段以“,”为分隔符分开。
与现有技术相比,本发明技术方案的有益效果是:
(1)用户计算量小。本发明利用代理签名技术将数据签名任务交予代理签名方,有效降低了用户的计算量。
(2)数据签名和批量审计的实时性。
(3)审计效率更高。与传统云存储数据审计方法相比,本发明并行化数据代理签名和批量审计过程,审计效率更高,方法可用性更好;与已有基于MapReduce的并行化云存储审计方法相比,由于弹性分布式数据集和基于内存计算等特点,使得审计效率进一步提高。
(4)批量审计数据证据时,失败响应处理更加高效。
附图说明
图1为一种云存储数据安全审计方法流程图。
图2为云存储数据安全审计方法模型图;
图中①到⑦分别表示不同的数据流信息。
图3为代理签名方并行化数据块签名过程流程图。
图4为第三方审计者验证流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
一种云存储数据安全审计方法,如图1,其具体模型如图2所示,包括以下步骤:
S1:密钥生成:随机选取x←Zp,u←G1,计算v←gx∈G2,其中Zp表示为整数模数p剩余类集合,G1,G2,GT是阶为素数p的乘法循环群,g是乘法循环群G2的生成元,G1,G2满足双线性对映射e:G1×G2→GT,定义私钥sk=(x),公钥pk=(u,g,v);
S2:代理签名授权信息生成并发送:随机选取y←Zp,产生用户身份信息mw,计算Q=gy∈G2,P=h(mw,Q)·x+y,P∈Zp,其中h为单向哈希函数,将待签名数据F和代理授权信息(P,Q,mw),即{F,P,Q,mw}发送给代理签名方;
S3:代理签名方对数据进行签名:代理签名方利用Kafka作为消息队列服务器,在微批处理时间区间内持续接收用户传递来的{F,P,Q,mw},使用Spark Streaming将接收到的{F,P,Q,mw},分成数据块存放在Spark Streaming的数据块队列中,Spark通过任务调度器对Spark Streaming的数据块队列数据进行计算,将计算结果发送至云服务提供商中进行存储和维护,如图3所示,具体包括以下步骤:
S3.1:将Spark Streaming的数据块队列数据作为输入流分布式数据集userDStreamRDD,并使用partitionBy函数进行分区,数据块队列数据格式为文本文件格式,所述文本文件中每行一条记录,每一条记录代表一个用户数据块签名和验证代理授权信息所需所有参数,记录中的每个字段以“,”为分隔符分开。
S3.2:在每个分区使用flatMap函数将userDStreamRDD每行字符串解析出验证用户授权信息和数据签名所需参数<T,(P,Q,mw)>,T为用户标签;
S3.3:使用filter函数筛选满足gP=vr·Q的授权信息正确的用户待签名数据和对应签名参数,其中r=h(mw,Q);
S3.4:选择私钥z←Zp,计算PSK=P+z·r,PPK=vr·gz·r·Q以及ω=uPSK,并将文件分块,即F=(m1,m2,···,mn),使用map函数计算数据块签名,:H(·)为将二进制字符串映射到G1的哈希函数;
S3.5:使用reduce函数将各个分区用户的数据块签名归并到master节点上;
S3.6:代理签名方将{F,Φ}发送至云服务提供商进行存储和维护,Φ为数据块签名集合,各个分区的用户签名输出为文本文件格式,所述文本文件中每行一条记录,每一条记录代表一个用户标识和数据块签名结果,记录中的每个字段以“,”为分隔符分开;
S4:生成挑战集:第三方审计者从集合[1,n]之间选取c个元素,组成集合I,对于每一个i∈I,随机生成νi∈ZP,挑战集chal={(i,νi)i∈I},将挑战集chal发送给云服务器;
S5:生成证据:云服务提供商收到来自第三方审计者的挑战集chal时,云服务器提供证据proof={μ,σ,R,H(mi)i∈I}返回第三方审计者,其中R是随机掩码,R=(ω)d=(uPSK)d,其中d为第三方审计者为每次审计任务而随机产生的;
S6:验证证据:第三方审计者利用Kafka作为消息队列服务器,不断接收云服务提供商传递来的proof信息,并对proof信息进行验证后把验证结果发送到每个用户,如图4所示,具体包括以下步骤:
S6.1:将proof信息作为输入流分布式数据集pfDStreamRDD,并使用partitionBy函数进行分区,所述的proof信息为文本文件格式,每行一条记录,每一条记录代表服务器产生的一个证据,记录中的每个字段以“,”为分隔符分开。;
S6.2:在每个分区中使用flatMap函数将pfDStreamRDD每行字符串解析出验证证据所需的参数;
S6.3:对于每个用户的数据证据,使用map函数验证:
输出键值对<T,ture/false>;
S6.4:使用reduce函数将各个分区数据验证结果归并到master节点上;
S6.5:将每个用户数据的验证结果根据T发送到每个用户,验证结果为文本文件格式,每行一条记录,每一条记录代表一个挑战标识和该挑战数据的验证结果,记录中的每个字段以“,”为分隔符分开。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!