一种基于用户彩铃信息识别用户挂机状态的方法与流程
本发明属于通信技术领域,具体涉及一种基于用户彩铃信息识别用户挂机状态的方法。
背景技术:
在现有的呼叫中分为2个部分,一部分为信令,另一部分为媒体;信令用来控制呼叫流程,包含起呼,媒体协商,接通和挂机等步骤;媒体用来建立媒体传输通道,进行媒体传输,媒体又包含2种类型,彩铃和通话,在正常的通话中,电话用户可以根据彩铃来判断被叫用户的状态是在忙或关机或其他。在呼叫中心中一般用信令中的挂机码进行被叫用户的挂机状态的判断。
现存的问题是信令中的挂机码往往和真实的挂机原因不一致,即挂机码不准确,导致这个问题的原因主要是在运营商的核心网络中存在多家厂商提供的设备,但是厂商直接对错误码的定义没有统一的标准。最终导致信令中的错误码和真实的挂机原因不一致。
挂机码不准确带来的直接问题就是呼叫中心无法获取到被叫用户的真实状态,在ai外呼和自动外呼的场景中会严重的影响后期的统计和分析结果。
技术实现要素:
(一)解决的技术问题
本发明提供一种基于用户彩铃信息识别用户挂机状态的方法,以解决背景技术中提到的实际问题。
(二)技术方案
为实现上述目的,本发明提供如下技术方案:一种基于用户彩铃信息识别用户挂机状态的方法,包括如下步骤:
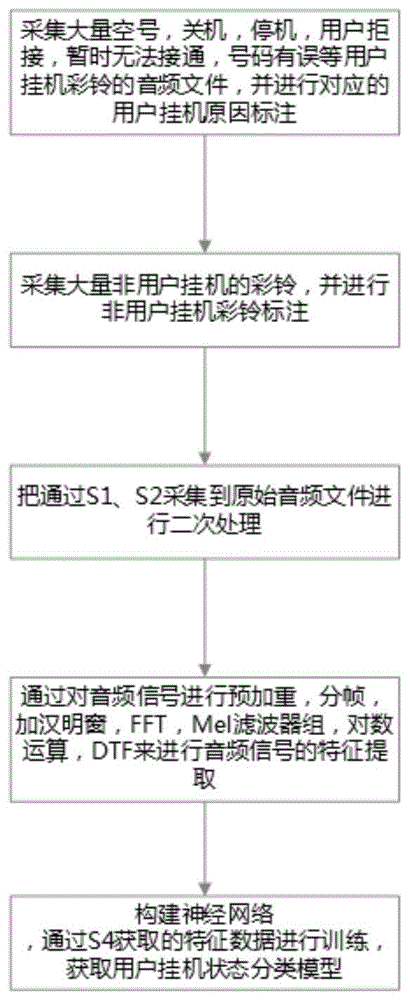
s1:采集大量空号,关机,停机,用户拒接,暂时无法接通,号码有误等用户挂机彩铃的音频文件,并进行对应的用户挂机原因标注;
s2:采集大量非用户挂机的彩铃,并进行非用户挂机彩铃标注;
s3:把通过s1、s2采集到原始音频文件进行二次处理;
s4:通过对音频信号进行预加重,分帧,加汉明窗,fft,mel滤波器组,对数运算,dtf来进行音频信号的特征提取;
s5:构建一个包含3个full-connect层,1个包含4层lstm的双向rnn,2个full-connect层,一个softmax层组成的神经网络;
s6:通过s4获取的特征数据输入到s5构建的神经网络进行训练,获取用户挂机状态分类模型,用于彩铃信息分类;
s7:在呼叫中心发起自动外呼,接受到180/183带有sdp的媒体信息时,进行媒体协商,建立语音通道,把语音信息进行整理后发送给用户挂机状态分类模型进行处理;
s8:用户挂机状态分类模型识别出用户挂机状态后,通知呼叫中心进行对应的操作;
s9:呼叫中心接收到200应答信息后,通知用户挂机状态分类模型,终止识别;
s10:呼叫中心接受到bye信令后,通知用户挂机状态分类模型,终止识别。
进一步的,所述步骤s1具体包括:通过呼叫中心批量外呼空号,关机,停机,用户拒接,暂时无法接通,号码有误的电话号码,然后通过呼叫中心把用户呼叫彩铃音频进行保存,并进行自动标注。
进一步的,步骤s2具体包括:通话呼叫中心批量外呼,记录所有用户彩铃,把所有接收到200应答消息的彩铃保存下来,并进行标注为非挂机,其他彩铃进行舍弃。
进一步的,步骤s3具体包括:收尾端的静音进行切除;对音频文件进行安装时间切割,时间长度7秒,向前重叠2秒,并继承原始文件标签。
进一步的,所述步骤s7具体包括以下步骤:
步骤(1):把语音信息实时解码为s16格式;
步骤(2):对解码后端音频进行实时音频信号特征提取;
步骤(3):把提取后一帧完整音频特征后发送到用户挂机状态分类模型。
进一步的,所述步骤s8具体包括当用户挂机状态分类模型识别出用户挂机状态为非挂机状态后,继续进行下一轮识别,不通知呼叫中心;用户挂机状态分类模型出用户挂机状态为挂机状态后,把对应的挂机原因发送给呼叫中心,呼叫中心进行对应的挂机操作,本记录挂机原因。
(三)与现有技术相比具有以下有益效果
(1)相对于通过信令判断用户挂机原因,通过用户彩铃信息识别挂机状态可以大幅提高准确率。
(2)用户彩铃信息识别挂机状态方法相对于目前市面上已有的彩铃识别技术,具有识别速度快,处理性能强的特点,系统稳定、性价比高。
(3)用户彩铃信息识别挂机状态方法可以结合预测外呼系统,系统可以快速的识别出用户挂机状态,当用户挂机后,自动跳到下一个号码继续外呼。这样一来,在预测外呼中,不仅可以快速并且有准确识别出用户挂机状态,还可以大幅提高了客服的有效接通率。
(4)本方法与呼叫中心使用同一套底层代码,具有电信级别的系统稳定性,同时,无需大量硬件设备,具有良好的适用性及可扩展性,性价比极高。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明的流程结构图;
图2是本发明的实施步骤图;
图3是本发明的神经网络图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种基于用户彩铃信息识别用户挂机状态的方法,具体步骤如下:
s1、采集大量空号,关机,停机,用户拒接,暂时无法接通,号码有误等用户挂机彩铃的音频文件,并进行对应的用户挂机原因标注;
步骤s1具体包括:通过呼叫中心批量外呼空号,关机,停机,用户拒接,暂时无法接通,号码有误的电话号码,然后通过呼叫中心把用户呼叫彩铃音的频保存下,并进行自动标注。
s2、采集大量非用户挂机的彩铃,并进行非用户挂机彩铃标注;
步骤s2具体包括:
s2-1、通话呼叫中心批量外呼,记录所有用户彩铃,把所有接收到200应答消息的彩铃保存下来,并进行标注为非挂机,其他彩铃进行舍弃。
s3、把通过s1、s2采集到原始音频文件进行二次处理;
步骤s3具体包括:
s3-1、首尾端的静音进行切除,通过
s3-2、对音频文件进行安装时间切割,时间长度7秒,向前重叠2秒,并继承原始文件标签。
s4、通过对音频信号进行预加重,分帧,加汉明窗,fft,mel滤波器组,对数运算,dtf来进行音频信号的特征提取。
s4-1、将语音信号通过传递函数为h(z)=1-μz-1的一阶高通滤波器进行预加重,其中μ=0.95;
s4-2、音频信号为8khz,以256个采样点进行分帧,即每帧的时间为32ms,公式为t=n/f,n为采样点个数;
s4-3、将每一帧乘以汉明窗,增加帧的连续性;结果为
s4-4、通过
s4-5、通过mel频率滤波器组对频谱进行平滑化,并消除谐波,突显原先语音的共振峰,频率响应定义为:
其中m为滤波器数量,f(m)=floor((nfft+1)*h(i)/samplerate,nfft为fft数量,h(i)是最小和最大频率的melscale值的m+2均分,samplerate为采样率;
s4-6、为每个滤波器组的输出计算对数能量
s4-7、进行dct获取系数:
s5、构建一个包含3个full-connect层,1个包含4层lstm的双向rnn,2个full-connect层,一个softmax层组成的神经网络;长短期记忆网络(lstm,longshort-termmemory)是一种时间循环神经网络;
s5-1、建立3个1024节点的full-connect层,每个full-connect层后面进行batchnormalization操作,加速训练并提高准确率,参考图3的全连接层;
s5-2、然后是建立一个包含4层lstm的双向rnn,cells数量为1024,参考图3的rnn层;
s5-3、建立2个1024节点的full-connect层,每个full-connect层后面进行batchnormalization操作,加速训练并提高准确率;
s5-4、最后加入softmax层,并且定义损失函数为
s6、通过s4获取的特征数据输入到s5构建的神经网络进行训练,获取用户挂机状态分类模型,用于彩铃信息分类;
s7、在呼叫中心发起自动外呼,接受到180/183带有sdp的媒体信息时,进行媒体协商,建立语音通道,把语音信息进行整理后发送给用户挂机状态分类模型进行处理;
步骤s7具体包括:
s7-1、把语音信息实时解码为s16格式;
s7-2、对解码后端音频进行实时音频信号特征提取;
s7-3、把提取后一帧完整音频特征后发送到用户挂机状态分类模型。
s8、用户挂机状态分类模型识别出用户挂机状态后,通知呼叫中心进行对应的操作;
步骤s8具体包括:
s8-1、用户挂机状态分类模型识别出用户挂机状态为非挂机状态后,继续进行下一轮识别,不通知呼叫中心;
s8-2、用户挂机状态分类模型出用户挂机状态为挂机状态后,把对应的挂机原因发送给呼叫中心,呼叫中心进行对应的挂机操作,记录挂机原因。
s9、呼叫中心接收到200应答信息后,通知用户挂机状态分类模型,终止识别。
s10、呼叫中心接受到bye信令后,通知用户挂机状态分类模型,终止识别。
本发明通过采集大量空号,关机,停机,用户拒接,暂时无法接通,号码有误等用户挂机彩铃的音频文件,并进行对应的用户挂机原因标注,采集大量非用户挂机的彩铃,并进行非用户挂机彩铃标注;通过对音频信号进行预加重,分帧,加汉明窗,fft,mel滤波器组,对数运算,dtf来进行音频信号的特征提取。
本发明在呼叫中心发起自动外呼,接受到180/183带有sdp的媒体信息时,进行媒体协商,建立语音通道,把语音信息进行整理后发送给用户挂机状态分类模型进行处理;用户挂机状态分类模型识别出用户挂机状态后,通知呼叫中心进行对应的操作;呼叫中心接收到200应答信息后,通知用户挂机状态分类模型,终止识别;呼叫中心接受到bye信令后,通知用户挂机状态分类模型,终止识别。
本实施例通过用基于用户彩铃信息识别用户挂机状态的方法识别对10000个测试号码进行测试,识别准确率达到99%;在预测外呼中使用基于用户彩铃信息识别用户挂机状态的方法,并结合国内业务多变和数据不确定性因素多的特点,自动计算恰当的预测外呼规则,最大化的实现外呼速度、座席工作量和客户体验度的平衡。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!