发声装置及其驱动方法、显示面板及显示装置与流程
本发明属于发声技术领域,具体涉及一种发声装置及其驱动方法、显示面板及显示装置。
背景技术:
发声装置应用在各个领域之中,例如在智能显示装置之中,会设置发声装置。智能显示装置能够根据压力、纹理触觉等实现人机交互,但现有的发声装置却只具有单一的发出声音的功能,发声方向和模式单一,使得接收发声装置所发声音的人物无法获得良好的收听体验。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题之一,提供一种发声装置,其能够实现根据人物来调整声波,使发声装置的发声智能化。
解决本发明技术问题所采用的技术方案是一种发声装置,包括:识别单元、定向发声单元和控制单元;其中,
所述识别单元与所述控制单元相连,其用于获取预设范围内的人物的相关信息,并将所述相关信息发送给所述控制单元;
所述控制单元与所述定向发声单元相连,其根据所述人物的相关信息,获取对应的音频信号,并控制所述定向发声单元按照所述音频信号发出声波。
本发明提供的发声装置,通过识别单元识别人物的相关信息,再通过控制单元根据相关信息获取对应人物的音频信号,之后控制定向发声单元按照音频信号发声,从而能够实现根据人物来调整声波,使发声装置的发声智能化。
优选的,所述识别单元包括:
人数识别模块,其用于获取所述预设范围内的人数信息;
位置识别模块,其用于获取各人物相对于所述发声装置的位置信息。
优选的,所述定向发声单元包括发声传感器阵列和音频处理模块,所述音频处理模块用于将所述音频信号转换为驱动信号,并驱动所述发声传感器阵列进行发声。
优选的,所述发声传感器阵列包括压电换能器阵列。
优选的,所述压电换能器阵列包括多个压电传感器;
所述压电换能器阵列包括第一基底、位于所述第一基底一侧的弹性膜层、位于所述弹性膜层背离所述第一基底一侧的第一电极、位于所述第一电极背离所述第一基底一侧的压电薄膜、位于所述压电薄膜背离第一基底一侧的第二电极;其中,
所述第一电极包括多个子电极,所述子电极呈阵列分布在所述弹性膜层背离所述第一基底一侧,每个所述子电极对应一压电传感器;
所述第一基底上具有多个开孔,所述开孔与所述子电极一一对应,所述子电极在所述第一基底上的正投影,位于与之对应的所述开孔在所述第一基底上的正投影内。
优选的,所述弹性膜层包括聚酰亚胺薄膜。
优选的,所述发声传感器阵列包括多个发声传感器,多个所述发声传感器均分为多个传感器组,每个所述传感器组对应接收一驱动信号。
优选的,多个所述发声传感器呈阵列分布,位于同一列或同一行的多个所述发声传感器相串联形成一所述传感器组;
或,
将多个所述发声传感器分为多个子阵列,每个子阵列中的所述发声传感器互相串联形成一所述传感器组。
优选的,所述定向发声单元还包括:
功率放大器,与所述音频处理模块相连,用于放大所述驱动信号;
阻抗匹配模块,连接在所述功率放大器与所述发声传感器阵列之间,用于匹配二者的阻抗以优化所述驱动信号。
优选的,所述控制单元包括:
数据记录模块,与所述识别单元相连,用于记录所述识别单元传输的所述相关信息;
音频信号计算模块,连接在所述数据记录模块与所述定向发声单元之间,其用于根据所述相关信息,计算所述相关信息对应的音频信号。
优选的,所述识别单元包括压电换能传感器、光脉冲传感器、结构光传感器、摄像头中的任一种。
相应地,本发明还提供一种发声装置的驱动方法,包括:
所述识别单元获取预设范围内的所述人物的相关信息,并将所述相关信息发送给所述控制单元;
所述控制单元根据所述人物的相关信息,获取对应的音频信号;
控制所述定向发声单元按照所述音频信号发出声波。
相应地,本发明还提供一种显示面板,所述上述的发声装置。
优选的,所述发声装置包括定向发声单元,所述定向发声单元包括发声传感器阵列,所述发声传感器阵列包括第一基底,和设置在所述第一基底一侧的多个发声传感器;
所述显示面板包括面板,所述面板包括第二基底,和设置在所述第二基底一侧的多个像素单元;其中,
所述发声传感器阵列和所述面板共用基底,且多个所述像素单元设置在多个所述发声传感器背离所共用的基底的一侧。
优选的,所述显示面板还包括面板和粘接层;
所述发声装置通过所述粘接层与所述面板相贴合。
优选的,所述显示面板为有机电激光显示面板或迷你发光二极管显示面板中的一种。
相应地,本发明还提供一种显示装置,包括上述显示面板。
附图说明
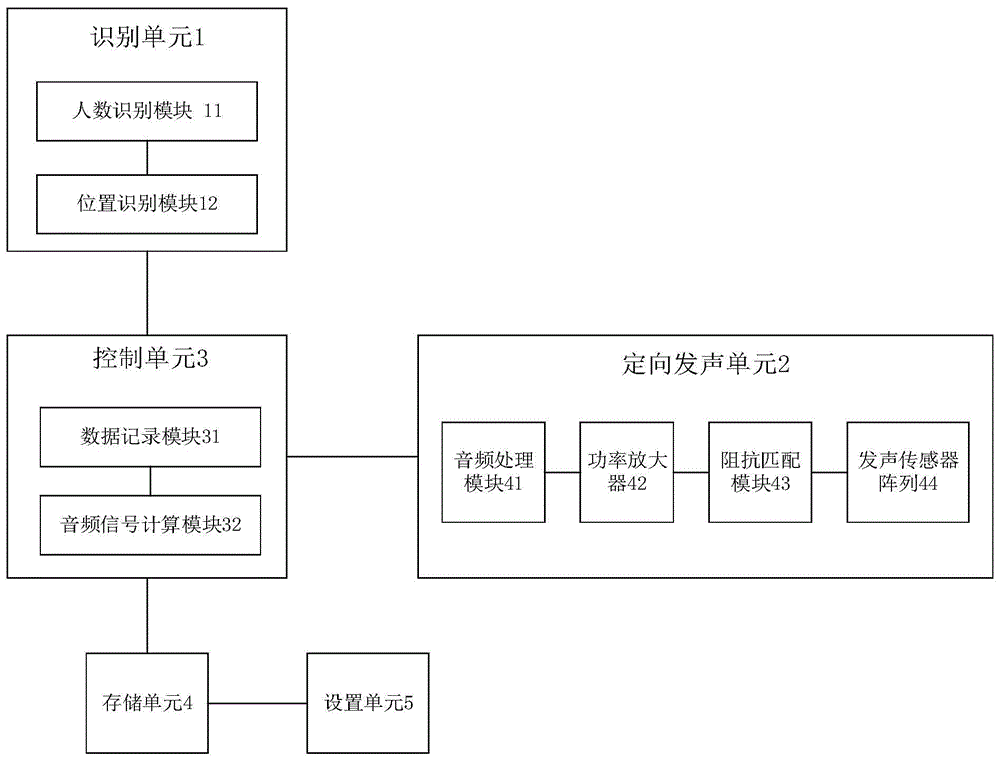
图1为本实施例提供的发声装置的一种实施例的架构图;
图2为本实施例提供的发声装置中发声传感器阵列的一种实施例的结构示意图;
图3为本实施例提供的发声装置中发声传感器的分组方式的一种实施例;
图4为本实施例提供的发声装置中发声传感器的分组方式的另一种实施例;
图5为本实施例提供的发声装置的驱动方法的流程图;
图6本实施例提供的驱动方法中声参量阵法的工作示意图;
图7为本实施例提供的驱动方法中声参量阵法的声波覆盖面积示意图;
图8为本实施例提供的驱动方法中声相控阵法中声波聚焦的原理示意图;
图9为本实施例提供的驱动方法中声相控阵法中声波偏转的原理示意图;
图10为本实施例提供的驱动方法中声相控阵法与声参量阵法结合的原理示意图;
图11为本实施例提供的显示面板中面板的结构示意图;
图12为本实施例提供的显示面板的一种实施例的结构示意图(面板与发声装置集成为一体)。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅是本发明的部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
附图中各部件的形状和大小不反映真实比例,目的只是为了便于对本发明实施例的内容的理解。
除非另外定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。同样,“一个”、“一”或者“该”等类似词语也不表示数量限制,而是表示存在至少一个。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
如图1所示,本实施例提供一种发声装置,包括:识别单元1、定向发声单元2和控制单元3。
具体地,识别单元1与控制单元3相连,定向发声单元2与控制单元3相连。识别单元1用于获取预设范围内的人物的相关信息,并将相关信息发送给控制单元3。预设范围可以根据需要以及识别单元1的识别范围来设定,例如预设范围可以为距离所述识别单元1的识别区域2米以内的范围。也即识别单元1检测预设范围内所包括的所有人物的相关信息,若预设范围内包括多个人物,则识别单元1分别识别每个人物的相关信息,并将各个人物的相关信息发送给控制单元3。控制单元3接收到人物的相关信息后,根据人物的相关信息获取对应的音频信息,并控制定向发声单元2按照控制单元3获取到的音频信号发出声波,该声波对应各个人物的相关信息。通过识别单元1识别人物的相关信息,再通过控制单元3根据相关信息获取对应人物的音频信号,之后控制定向发声单元2按照音频信号发声,从而能够实现根据人物来调整声波,使发声装置的发声智能化。
可选地,如图1所示,识别单元1识别的相关信息可以包括多种类型的信息,例如,识别单元1可以识别预设范围内所包括的人物的人数,还可识别各个人物相对于发声装置的位置。相应地,识别单元1可以包括人数识别模块11和位置识别模块12,其中人数识别模块11用于获取预设范围内的人数信息,位置识别模块12用于获取预设范围内各人物相对于发声装置的位置信息,也即识别单元1发送给控制单元3的相关信息包括人数信息和各人物的位置信息。从而控制单元3可以根据各人物相对于发声装置的位置信息,计算发送给各人物的声波的角度,并生成对应的音频信号控制定向发声单元2发声,使各人物可以更好地接受声音,并且控制单元3可以根据人数和各人物的位置信息,计算声波的覆盖面积,使定向发声单元2发出的声波可以覆盖预设范围内的所有人物,进一步提升人物的收听体验。
可选地,识别单元1可以包括多种类型的识别器件,例如可以采用体感识别,也可以采用图像识别。例如,识别单元1可以包括压电换能传感器、光脉冲传感器、结构光传感器、摄像头中的任一种。
具体地,若识别单元1为压电换能传感器,压电换能传感器能够发射超声波,超声波遇到人物时会反射,压电换能传感器通过探测反射回来的超声波,也即探测回波信号,可以识别出预设范围内的人数信息,和各人物的位置信息。若识别单元1可以采用光脉冲传感器,通过飞行时间(timeofflight,tof)技术进行识别,光脉冲传感器可以向预设范围内发射光脉冲,若预设范围内存在人物,则人物会反射光脉冲,通过探测光脉冲的飞行(往返)时间来得到人物的位置信息和人数信息。若识别单元1采用结构光传感器,结构光传感器可以包括相机和投射器,通过投射器投射到人物的主动结构信息,如激光条纹、格雷码、正弦条纹等,再通过单个或多个相机拍摄被测表面获取结构光图像,之后可以基于三角测量原理获得人物的三维图像,即可识别到人物的位置信息和人数信息。识别单元1还可以采用摄像头进行识别,例如通过双摄像头采用双目识别技术,可以通过摄像头采集到的图像识别出预设范围内的人数信息和各人物的位置信息。当然,识别单元1还可以采用其他方式进行识别,具体的可以根据需要设计,在此不做限定。
可选地,如图1所示,定向发声单元2可以包括发声传感器阵列44和音频处理模块41,音频处理模块41用于将控制单元3传输的音频信号转换为驱动信号,并将驱动信号发声传感器阵列44,以驱动发声传感器阵列44进行发声。驱动信号可以包括声波传播的角度,具体地,例如驱动信号可以包括发声传感器阵列44中各个发声传感器发射声波的时序,通过各个传感器的发射声波的相位延迟,可以调整发声传感器阵列44的发声方向。
可选地,发声传感器阵列44可以包括多种类型的传感器,例如发声传感器阵列44为压电换能器阵列,也即发声传感器阵列44包括多个压电换能器。当然,发声传感器阵列44也可以为其他类型的传感器阵列,具体的根据需要设置,在此不做限定。
进一步地,如图2所示,若发声传感器阵列44为压电换能器阵列,压电换能器阵列包括多个压电传感器。具体地,压电换能器阵列包括第一基底1、位于第一基底1一侧的弹性膜层2、位于弹性膜层2背离第一基底1一侧的第一电极3、位于第一电极3背离第一基底1一侧的压电薄膜4、位于压电薄膜4背离第一基底1一侧的第二电极5。
其中,弹性膜层2作为发声传感器阵列44(压电换能器阵列)的弹性辅助膜,用于增强压电薄膜4的振动幅度。第二电极5可以为片状电极,其覆盖整个第一基底1的区域,第一电极1包括多个子电极31,多个子电极31呈阵列分布在弹性膜层2背离第一基底1一侧,每个子电极31对应一压电传感器001,也就说,子电极31及子电极31背离第一基底1一侧的各个膜层对应子电极31的区域形成一个压电传感器001,发声传感器阵列44具有扬声器功能,子电极31、压电薄膜4和弹性膜层2共同构成发声传感器阵列44(扬声器)的振膜,用于发出声波。第一基底1上具有多个开孔11,开孔11作为发声传感器阵列44(扬声器)的腔室,开孔11与子电极31一一对应,子电极31在第一基底1上的正投影,位于与之对应的开孔11在第一基底1上的正投影内,以使声波能够透过作为腔室的开孔11传播出去。并且,在第一基底1上制作开孔11,可以使第一基底1、弹性膜层2和压电薄膜4形成悬空膜结构。
可选地,在第一基底1上可以采用激光打孔、氢氟酸刻蚀打孔等多种方式形成开孔11。
可选地,第一基底1可以包括多种类型的基底,例如第一基底1可以为玻璃基底1。弹性膜层2可以包括多种类型的弹性膜层,例如弹性膜层可以为聚酰亚胺薄膜(polyimide,pi),当然,弹性膜层2也可以采用其他材料制成,在此不做限定。
可选地,压电换能器阵列可以为微机电系统(micro-electro-mechanicalsystem,mems)的压电换能器阵列。
可选地,如图3、图4所示,发声传感器阵列44包括多个发声传感器,图中以发声传感器为压电传感器001为例,多个压电传感器001呈阵列分布在第一基底1,为了便于描述,图3、图4中省略压电传感器001的具体结构,用圆形代替压电传感器001。多个压电传感器001均分为多个传感器组,每个传感器组对应接收一音频处理模块41发送的驱动信号,也即采用分组驱动的方式控制发声传感器阵列44中的发声传感器,从而可以减少引起传感器组的驱动线的数量,简化发声传感器阵列44的结构,并且,可以采用整个传感器组传播一方向的声波,相较于只采用一个传感器传播一方向的声波,传感器组的方式将得到更大的声波覆盖面积。并且,可以方便地根据人物相较于发声装置的距离调节声波,例如,若人物距离发声传感器阵列44的中线上的传感器较近时,可以采用中线上的传感器组进行发声,以增大声波的覆盖面积。
具体地,可以采用多种方式对多个发声传感器进行分组。以下以方式一和方式二为例进行说明。
方式一、
参见图3,以发声传感器为压电传感器001为例,多个压电传感器001呈阵列分布,位于同一列(图3)或同一行的多个压电传感器001形成一传感器组a,每个传感器组a中的压电传感器001互相串联,一传感器组a对应一驱动信号(如图3中驱动信号p1……pn)。
方式二、
参见图4,以发声传感器为压电传感器001为例,多个压电传感器001呈阵列分布,将多个压电传感器001分为多个子阵列,每个子阵列中的压电传感器001形成一传感器组a,每个传感器组a中的压电传感器001互相串联,一传感器组a对应一驱动信号(如图4中驱动信号p1……p4)。
当然,还可以采用其他方式对发声传感器阵列44中的多个发声传感器进行分组,以上仅为举例说明,在此不做限定。
可选的,如图1所示,定向发声单元2还包括功率放大器42和阻抗匹配模块43。功率放大器42与音频处理模块41相连,功率放大器用于放大音频处理模块41传入的驱动信号。阻抗匹配模块43连接在功率放大器42与发声传感器阵列44之间,阻抗匹配模块43用于匹配功率放大器42和发声传感器阵列44的阻抗,通过调节功率放大器42和/或发声传感器阵列44的阻抗大小,使二者的阻抗相匹配达到最大的驱动信号放大作用,以优化驱动信号。功率放大器42和阻抗匹配模块43相配合,以优化驱动信号,使驱动信号最大化后传输至发声传感器阵列44。
可选地,如图1所示,控制单元3包括数据记录模块31和音频信号计算模块32。数据记录模块31与识别单元1相连,数据记录模块31用于记录识别单元1传输的人物的相关信息,并将记录好的相关信息传输给音频信号计算模块32。音频信号计算模块32连接在数据记录模块31与定向发声单元2之间,音频信号计算模块32用于根据相关信息,计算人物相关信息对应的音频信号。本实施例提供的发声装置的发声传感器阵列44可以通过各种方式驱动发声传感器发声,音频信号计算模块32按照预设的算法计算音频信号,以实现根据人物的位置信息调整对应该人物角度的声波,根据人数信息和各人物的位置信息,计算所需的声波覆盖面积。
可选地,本实施例提供的发声装置还包括存储单元4和设置单元5。存储单元4连接控制单元3,设置单元5连接存储单元4。本发明提供的发声装置可以包括多种发声模式,例如单人物模式和多人物模式,可以通过设置单元5对发声模式进行设置,并将设置存储在存储单元4中。设置单元5还可以对发声装置进行初始化设置,并将初始化设置存入存储单元4中,控制单元3可以从存储单元4中读取设置信息,并对发声装置进行对应的设置。
相应地,如图5所示,本实施例还提供一种发声装置的驱动方法,包括:
s1、识别单元1获取预设范围内的人物的相关信息,并将相关信息发送给控制单元3。
具体地,识别单元1识别的相关信息包括预设范围内所包括的人物的数量,即人数信息,以及预设范围内各人物的相对于发声装置的位置信息,例如与发生装置的中线的角度,并将相关信息传输给控制单元3。
s2、控制单元3根据人物的相关信息,获取对应的音频信号。
具体地,控制单元3包括数据记录模块31和音频信号计算模块32,音频信号计算模块32按照预设的算法计算音频信号,预设的算法根据发声装置采用的发声模式来设置。以下以发声装置采用声相控阵法和声参量阵法来控制发声传感器阵列44中的各个发声传感器为例进行说明。
具体地,参见图6、图7,由于可听声的传播指向性较低,因此,发声装置还可以采用声参量阵法驱动发声传感器阵列44中的各个发声传感器,以增加声波的指向性。参见图6,发声传感器阵列44中的多个发声传感器可以中线的两侧各为一组的方式分为传感器阵列组c1和传感器阵列组c2,控制单元3控制音频处理模块41产生两个驱动信号,第一个驱动信号经功率放大器42和阻抗匹配模块43的优化后传输给传感器阵列组c1,驱动传感器阵列组c1发出频率为f1的超声波,第二个驱动信号经功率放大器42和阻抗匹配模块43传输给传感器阵列组c2,驱动传感器阵列组c2发出频率为f2的超声波,f1与f2的频率不同,从而两个频率不同的超声波在空气中发生非线性交互作用后,可以调制出人耳可听见的声波(简称“可听声”)。由于超声波的声波相较于可听声的声波更加尖锐,因此超声波具有更强的指向性,采用声参量阵法驱动发声传感器阵列44发声可增强可听声的指向性。
进一步地,控制单元3可以由发声传感器阵列44的排布,按照以下阵列指向性函数d(α,θ)来确定声参量阵法模式下,发声传感器阵列44发出的声波的指向性:
其中,k=2π/λ,发声传感器阵列44包括n列m行,每行发声传感器的行间距为d2,每列发声传感器的列间距为d1,α和θ为声波指向的方向在球面坐标中的角度。
以下发声传感器阵列44为101×101的阵列为例,101为一行/列发声传感器的数量,即m=n=101,行间距和列间距相等,即d1=d2=2.8mm,发声传感器的尺寸半径r=0.9mm,相邻的两个发声传感器之间的间隙为1mm,代入上式可得传感器阵列44发出的声波的指向性图示(如图7所示)。其中指向性角η为10°,指向性覆盖面积为以声波的正方向为中线,往两侧偏转10°的覆盖范围,在距离声源(发声传感器阵列44的中心)为l1处声源在中线两侧传播的最大距离为d1,在距离声源为l2处声源在中线两侧传播的最大距离为d2,图7中l2=2×l1,相应地,d2=2×d1。取l1为1m,d1=0.176m,则本实施例中声波在1m处距离中线两侧传播的最大距离为2×d1=0.352m。若人物在距离声源1m处的区域,且距离中线超过0.176m以内即可收听到发声传感器阵列44发出的声音。
进一步地,如图8、图9所示,若采用声相控阵法来控制发声传感器阵列44中的各个发声传感器,以发声传感器为压电传感器001为例,控制单元3中的音频信号计算模块32可以通过计算多个压电传感器001中各个压电传感器001的激发延迟时间,得到具有延迟时间序列的音频信号,再将该音频信号传输给音频处理模块41,音频处理模块41根据音频信号中的延迟时间序列,以相应时序的激励脉冲序列驱动各个压电传感器(或传感器组),于是各压电传感器001发射的声波产生了相位差,从而影响干涉结果,即可实现声波的聚焦(图8)和偏转方向(图9),从而能够实现根据人物来调整声波,使发声装置的发声智能化。在识别单元1识别到预设范围后的人物的相关信息后,根据某人物的位置信息,控制单元3计算出使声波的传播方向对应该人物的位置的音频信号,并传输给音频处理模块41,音频处理模块41将音频信号转换成对应的驱动信号,驱动信号经过功率放大器42和阻抗匹配模块43的优化后传输给发声传感器阵列44,驱动发声传感器阵列44发出传播方向对应该人物的位置的声波。
进一步地,基于上述,在采用声参量阵法驱动发声传感器阵列44时,声波由于加强了指向性,因此覆盖面积较小,若人物没有正对发声传感器阵列44的中线,偏离中线的距离较远,则可能收听不到声音。因此可以结合声参量阵法和声相控阵法,以声参量阵法加强声波的指向性,再通过声相控法调整各个发声传感器发声的延时,从而增大声波的覆盖面积。
具体地,参见图10,以发声传感器阵列44包括一行发声传感器为例,发声传感器数量为101个(图10中s1……s101),位于中心的发声传感器为第五十个发声传感器s50,相邻的两个发声传感器的间距为1mm。因为人耳的视觉暂留效应,人耳不能分辨时间差小于0.1s的两个声音,会认为时间差小于0.1s的两个声音为一个声音。所以,可以使控制单元3采用相控聚焦扫描的方式获得大的收听面积。控制单元3控制发声传感器阵列44以声参量阵法,沿发声传感器阵列44的中线(即s50正对的方向)传播声波,其指向性角度η为10°。以人物处于位置o2为例,即人物在偏离中线角度β为60°、距离发声传感器阵列44为1m处要听到声波,则通过脉冲序列控制多个发声传感器,从第一个发声传感器s1开始,各个发声传感器(s1到s101)依次间隔固定的延迟时间(例如1us)发射声波,该声波频率与声参量法产生的可听声的声波频率相同,各个发声传感器发射的声波具有固定的相位差,互相干涉即可使声波的覆盖范围增大。最终在本实施例中声波可以得到20mm~2.8m的覆盖面积。综上所述,通过声参量阵法驱动发声传感器阵列44增加声波的指向性,再通过声相控阵法调节声波的传播角度以及覆盖面积,即可实现根据人物来调整声波,使发声装置的发声智能化。
s3、控制定向发声单元2按照音频信号发出声波。
具体地,控制单元3根据人物的相关信息计算音频信号,再将音频信号传输给定向发声单元2,音频信号中包括定向发声单元2中各发声传感器的发声频率或延迟序列,即可根据人物来调整声波的传播方向和覆盖面积。
相应地,本实施例还提供一种显示面板,上述的发声装置。
发声装置可以和面板集成为一体,也可以与显示面板的面板相贴合,外置于面板外。
具体地,参见图2、图11和图12,若发声装置与显示面板集成为一体,如图2所示,发声装置包括定向发声单元2,定向发声单元2包括发声传感器阵列44,发声传感器阵列44包括第一基底1和设置在第一基底1一侧的多个发声传感器(例如压电传感器001)。如图11所示,显示面板包括面板,面板包括第二基底01,和设置在第二基底01一侧的多个像素单元6。每个像素单元6包括像素电极61和像素62,像素62包括多个子像素,例如红色子像素623、绿色子像素622和蓝色子像素621。其中,参见图12,发声传感器阵列44和面板共用基底,将发声装置与面板集合为一体形成具有屏幕发声功能的显示面板,多个像素单元6设置在多个发声传感器(压电传感器001)背离所共用的基底(图12中1(01)所示)的一侧,从而可以使显示面板具有屏幕发声功能,且可以减少显示面板的厚度。
可选地,发声装置还可以外置在面板上,具体的,显示面板包括面板,在面板的出光侧,发声装置通过粘接层与面板相贴合,外置在面板的出光侧,且发声装置为透明的发声装置,不影响面板的出光率。
可选地,发声装置可以应用在各种类型的显示面板中,例如显示面板可以为有机电激光(oled)显示面板,也可以为迷你发光二极管(miniled)显示面板,在此不做限定。
进一步地,发声装置中的控制单元可以与显示面板的背板上的控制芯片(cpu)共用,定向发声单元2中的发声传感器阵列44设置在面板的出光侧,定向发声单元2中的音频处理模块41、功率放大器42和阻抗匹配模块43可以设置在显示面板的周边区域,例如像素单元驱动电路所在区域。识别单元1可以设置在显示面板的其中一侧,例如设置在显示面板设置摄像头的一侧。若识别单元1为摄像头,识别单元1的摄像头可以与显示面板中的摄像头共用。
相应地,本实施例还提供一种显示装置,包括上述显示面板。
需要说明的是,本实施例提供的显示装置可以为:手机、平板电脑、电视机、显示器、笔记本电脑、数码相框、导航仪等任何具有显示功能的产品或部件。对于该显示装置的其它必不可少的组成部分均为本领域的普通技术人员应该理解具有的,在此不做赘述,也不应作为对本发明的限制。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!