基于图卷积神经网络的webshell检测方法及装置
本发明涉及网络空间安全领域,具体涉及一种基于图卷积神经网络的webshell检测方法及装置。
技术背景
webshell本质上是一个采用php、jsp或asp等编写的脚本文件,常被攻击者用作操作网站服务器的后门工具。攻击者在从网站入侵进入到内网渗透时,一般通过上传webshell获得web服务器的权限。攻击者利用漏洞将webshell植入web服务器,通过webshell在服务器上执行系统命令、文件读写、数据库读取与写入、内网主机探测、流量监控等操作,为后续信息窃取、商业勒索、组建僵尸网络等活动提供便利。
目前常用的用于连接webshell的网站后门管理软件有蚁剑、冰蝎和哥斯拉等。
大部分公司都在网关接口处部署waf、ids,能够抵御外部攻击,但是内部的防护却很薄弱,攻击者一旦进入了内部网络之后,就能够发起各种攻击,如果能够及时发现攻击者的内网入侵行为就能够有效地止损。攻击者从网站入侵转变为内网入侵的关键点就是webshell,所以检测内网入侵行为的关键点就是webshell的检测。攻击者在利用webshell的过程中自然会产生相应的流量通信数据,留下webshell的流量痕迹,因此可通过检测网站流量发现webshell。
传统的检测方法是利用统计学手段以及静态特征匹配,但是检测性能一般,容易产生误报,并且不能识别未知的webshell,无法应对变形多样的webshell样本;现有的基于机器学习模型的webshell检测方式,主要依赖训练样本及特征工程的质量,若特征维度过高会导致检测速度下降,误报率升高,并且在训练样本不足的情况下检测效果不佳,此外也无法利用通信流量之间存在的关联关系进行分析检测。
为更好的说明本发明,先说明本发明用到的相关术语的定义:
1、图卷积的实现公式:
其中,h(k)为输入,a为邻接矩阵,
2、tf-idf(termfrequency/inversedocumentfrequency,词频-逆文本频率)是一种用于数据挖掘的常用加权技术,tf是指词频,idf是逆文本频率,计算公式如下:
其中,nω是某一文本中词条ω出现的次数,n是该文本总的词条数。
其中,y是语料库的文档总数,yω是包含词条ω的文档数。
tf-idfω=tfω*idfω
tf-idf即为tf和idf的乘积。
技术实现要素:
为了解决现有技术的不足,本发明提供了一种基于图卷积神经网络的webshell检测方法及装置,用以解决现有的webshell检测手段在样本量覆盖不足的情况下检测能力不足的问题,利用流量之间的关联关系和流量内容识别进行检测,提高检测速度的同时降低检测误报率。本发明用到了自然语言处理技术和图卷积技术,通过分析网站流量之间的链接关系构建流量关联图,然后应用图卷积模型训练图节点分类器,实现对网站流量数据的检测和分类。图卷积神经网络在文本分类上具有较好的鲁棒性,即使用较小的训练数据便可实现良好的分类效果,适用于检测webshell这种训练样本量不足的分类问题。
为了实现上述目的,本发明提供了如下的技术方案:
一种基于图卷积神经网络的webshell检测方法,其步骤包括:
1)解析流量数据包,提取流量文本数据与reference信息,并根据流量文本数据获取请求的网站资源文件与流量通信所属的资源文件关系,通过reference信息得到流量之间的链接跳转关系;
2)将每条流量数据与请求的网站资源文件作为节点,根据流量之间的链接跳转关系及流量通信所属的资源文件关系获取节点依赖关系,以构建流量关联图,并依据流量关联图,得到该流量数据包的邻接矩阵;
3)对该流量文本数据进行特征提取,得到流量关联图中每一节点的特征向量;
4)将所述邻接矩阵与所述特征向量输入由训练集训练得到的双层gcn模型,得到webshell检测结果;
其中,通过以下步骤得到训练好的双层gcn模型:
a)解析训练集中的样本流量数据包,提取各样本流量数据包中的文本数据与样本reference信息,并根据文本数据获取请求的样本网站资源文件与样本流量通信所属的资源文件关系,通过样本reference信息得到样本流量之间的链接跳转关系;
b)针对每一样本流量数据包,将每条样本流量数据与请求的样本网站资源文件作为节点,根据样本流量之间的链接跳转关系及样本流量通信所属的资源文件关系获取节点依赖关系,以构建该样本流量数据包的样本流量关联图,并依据样本流量关联图,得到相应的样本邻接矩阵及节点标签;
c)对每一文本数据进行特征提取,得到相应样本流量关联图中每一节点的样本特征向量;
d)将各样本流量数据包的样本邻接矩阵、样本特征向量及节点标签输入一双层gcn模型进行迭代训练,得到训练好的双层gcn模型。
进一步地,通过以下步骤得到流量文本数据:
1)从流量数据包中提取http数据;
2)从http数据中筛选出对网站脚本文件请求所产生的http请求,并将该些http请求划分为请求资源与请求参数;
3)对请求资源进行处理,得到标准化后的请求资源;
4)对请求参数进行url解码、base64解码及格式化操作,得到标准化后的请求参数数据;
5)依据标准化后的请求资源与标准化后的请求参数数据,得到流量文本数据。
进一步地,通过以下步骤获取节点依赖关系:
1)根据流量节点所访问的文件节点,对流量节点进行分组,并将组内所有的流量节点连接到共同访问的文件节点,其中依据流量数据得到的节点为流量节点,依据请求的网站资源文件得到的节点为文件节点;
2)组内的流量节点之间彼此根据reference信息进行链接,得到组内流量节点链接关系;
3)根据reference信息链接各组之间的流量节点,得到组外流量节点链接关系;
4)根据文件节点下的流量节点之间是否存在链接关系链接文件节点,得到文件节点链接关系;
5)依据组内流量节点链接关系、组外流量节点链接关系及文件节点链接关系,得到节点依赖关系。
进一步地,将邻接矩阵输入训练好的双层gcn模型之前,对邻接矩阵引入自环,得到引入自环后的邻接矩阵。
进一步地,通过以下步骤得到流量关联图中每一节点的特征向量:
1)基于符号和空格对流量文本数据进行分词操作,并依据分词结果,建立词汇表;
2)根据常见的停用词和无意词表对词汇表进行过滤,得到过滤后的词汇表;
3)以过滤后的词汇表为基准,统计每条流量数据中出现各词汇的词频及各文件节点下的所有流量数据的词频;
4)使用信息增益方法对过滤后的词汇表中所有词汇进行计算,并依据设定阈值,选择特征词;
5)对特征词进行特征计算,得到流量关联图中每个节点对应的特征向量。
进一步地,对特征词进行特征计算的方法包括:tf-idf方法。
进一步地,通过以下步骤得到webshell检测结果:
1)对特征向量和邻接矩阵经过第一层图卷积运算,并将第一层图卷积运算结果通过激活函数进行非线性变换,得到第一层图输出结果;
2)将第一层图输出结果经过第二层图卷积运算,并将第二层图卷积运算结果经sigmoid函数输出,得到webshell检测结果。
进一步地,训练双层gcn模型的损失函数包括:每个节点的预测label和真实label的交叉熵。
进一步地,训练双层gcn模型的方法包括:mini-batchsgd。
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述所述的方法。
一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机以执行上述所述的方法。
与现有技术相比,本发明具有以下优势:
本发明利用采集到的网站流量数据,提取网站流量中的特征,常规的流量特征提取主要关注内容特征以及协议字段特征,而很少关注流量间存在的关联关系。本发明在特征提取阶段除了对常规的流量特征进行提取外,还根据流量间的跳转关系,建立图模型,提取流量间的关联特征。同时,本发明还引入了深度学习领域的图卷积技术提高检测准确率。
附图说明
图1为本发明的整体框架流程图。
图2为本发明的数据预处理流程示意图。
图3为本发明的数据文本向量化流程图。
图4为本发明的图卷积模型检测流程图。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的目的、特征和优点能够更加明显易懂,下面结合附图和事例对本发明中技术核心作进一步详细的说明。
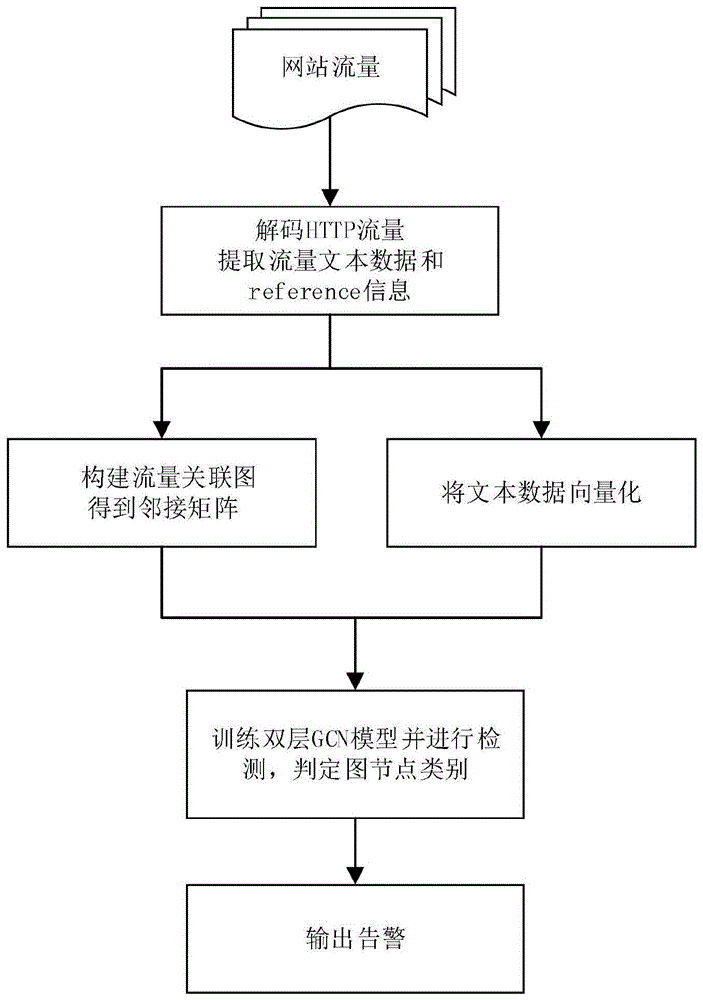
本发明的webshell检测方法,参照图1的整体框架图。共分为五个步骤:
步骤一,流量数据预处理。如图2所示,对网站流量数据进行解析,提取流量中的http流量数据,然后提取文本数据并处理,具体步骤如下:
1)从网站流量中提取http数据;
2)从http流量中提取文本数据。先筛选出http流量中对网站脚本文件请求所产生的通信流量,然后将这些http请求划分为请求资源和请求参数两部分,从中提取关键数据
(例如在请求链接
192.168.1.9/php/big/up/webshell.php?a=selfremove&c=%2fwww%2fadmin%2flocalhost_80%2fwwwroot%2fphp%2fbig%2fup%2f&p1=&p2=&p3=&charset=windows-1251中,请求资源为192.168.1.9/php/big/up/webshell.php,请求参数为a=selfremove&c=%2fwww%2fadmin%2flocalhost_80%2fwwwroot%2fphp%2fbig%2fup%2f&p1=&p2=&p3=&charset=windows-1251),其中http请求通常分为get和post两种资源请求方式,分别进行处理分类,并对请求参数数据进行url解码、base64解码以及格式化操作,最后得到标准化后的请求参数数据;
3)获取http流量请求头中的的reference字段并记录,得到reference信息。reference信息中记录了当前流量来源于哪一条流量的跳转。
步骤二,构建流量关联图。
1)建立图节点。图节点有两种,分别是流量节点和网站文件节点。将每一条流量数据看作是一个图节点,作为流量节点。从步骤一筛选出的对网站脚本文件请求所产生的通信流量中,选择这些网站脚本文件作为图模型中的网站文件节点。即将每条流量数据和请求的网站资源文件均看作是图中的一个节点。
2)构建节点依赖关系。需要链接的节点关系有流量节点—文件节点,流量节点—流量节点,文件节点—文件节点。根据流量之间的链接跳转关系以及流量通信所属的资源文件关系进行建立。具体的步骤如下:
先根据流量节点所访问的文件节点进行分组,将访问同一文件节点的流量节点分为一组,并将组内所有的流量节点链接到文件节点,组内的流量节点之间彼此根据reference关系进行链接,若存在reference关联则连接,否则不建立连接;组外的流量节点之间根据是否存在reference关系进行连接;文件节点之间根据文件节点下的流量节点间是否存在链接关系进行连接。最后根据建立好的节点依赖关系,形成邻接矩阵,并引入自环。
步骤三,文本特征向量化。如图3所示,对预处理阶段得到的文本数据进行特征提取,转变为特征向量,具体流程如下:
1)对文本数据进行分词。基于符号和空格对所有流量数据的文本进行分词操作,建立词汇表;
2)停用词过滤。根据常见的停用词和无意词表对词汇表进行过滤,过滤掉其中的无意词;
3)词频统计。以词汇表为基准,统计每条流量数据中出现词汇的词频,并统计文件节点下的所有流量数据的词频;
4)特征词选择。使用信息增益对所有词汇进行计算,设定阈值,选择信息增益满足阈值范围的词汇作为特征词;
(信息增益是一种基于熵的评估方法,定义为某个词为分类能够提供的信息量,计算公式如下:
其中h(c)表示整体信息熵,h(c|t)表示条件熵,p(ci)为某个类别出现的概率,p(word)为某个词汇在所有类别中出现的概率,
5)特征计算。使用tf-idf对选择出的特征词进行特征计算,得到每个节点对应的特征向量,计算公式如下:
tf-idfω=tfω*idfω
步骤四,模型检测。图卷积在文本分类上非常好的分类效果,并且鲁棒性好,使用较小的训练数据便可达到很高的分类效果。本发明是对网络通信流量进行分类检测,实质是对通信流量中的文本数据进行分类,因此采用图节点分类方法,构建双层gcn模型,输入带有标签的数据集进行监督学习训练,然后利用训练得到的模型进行流量检测,如图4所示,具体流程如下:
1)构建双层gcn模型,该模型参考aaai会议在2019发布的论文《graphconvolutionalnetworksfortextclassification》。模型如下所示
输入的特征向量和邻接矩阵先经过第一层图卷积运算,然后通过激活函数relu进行非线性变换,再进入第二层图卷积层进行运算,最后通过sigmoid函数输出;
2)将流量数据的特征向量、邻接矩阵以及图节点标签输入构建好的模型中进行迭代训练,损失函数采用每个节点的预测label和真实label的交叉熵,训练方法采用mini-batchsgd,经过300次epoch,得到训练好的检测模型,并根据准确率和召回率设定webshell判定阈值;
3)将待检测流量的特征向量和邻接矩阵输入到训练好的双层gcn模型中进行检测,根据阈值判定节点标签,检测流量节点中存在的webshell,最终确定webshell文件,发出告警信息。
实验数据
本发明的实验数据包括良性流量数据和webshell流量数据两部分。正常网站通信流量中包含的webshell流量数据很少,覆盖范围并不全面,大规模的流量数据一般被安全企业和政府机构所掌控,因此为了得到全面的流量数据集,首先需要利用网络上公开的各类型webshell样本生成流量数据。针对http的流量生成,搭建沙箱测试环境,在内网环境下模拟webshell攻击行为,服务器环境选择apache、tomcat和nigix等;网页脚本语言选择常见的php;选择各类型的webshell后门文件(一句话木马、小马、大马以及包括菜刀、冰蝎、哥斯拉等在内的客户端类型后门)。webshell样本可以从github上公开的webshell项目中收集获得,良性样本数据使用常见的cms(wordpress、phpcms)生成良性样本流量。此外,由于webshell样本是从公开渠道获取,不同的后门样本质量参差不齐,并且存在适用场景的问题,即部分样本仅适用于特定的服务器环境和版本下,因此需要对收集到的数据样本进行筛选整理,当服务器环境部署完毕后,编写自动化脚本进行访问测试,选择可以正常访问的样本文件,同时对访问异常的样本文件根据实际状况进行修改或删除。根据最终获得的样本文件,依据样本类型分别生成流量数据。对于常规的服务端类型的后门文件(一句话、小马、大马),可以编写自动化爬虫脚本进行批量访问。对于良性样本流量,可以对常见的cms网站编写自动化爬虫脚本进行流量获取。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!