再现方法、装置及介质、信息处理方法及装置与流程
技术领域
本技术涉及再现装置、再现方法、信息处理装置、信息处理方法以及程序,并且特别地,涉及能够实现高度灵活的声音数据的再现同时反映内容创建者的意图的再现装置、再现方法、信息处理装置、信息处理方法以及程序。
背景技术
在乐器表演的教学视频等中包括的图像通常是由内容创建者预先通过剪辑等获得的图像。此外,声音是由内容创建者针对2声道、5.1声道等通过将诸如解说语音和乐器的表演声音的多个声源适当地混合而获得的声音。因此,用户可以观看仅具有内容创建者所期望的视点中的图像和声音的内容。
顺便地,近年来基于对象的音频技术已经引起关注。基于对象的声音数据由对象的音频波形信号和元数据构成,该元数据指示由距离参考视点的相对位置表示的定位信息。
再现基于对象的声音数据,以基于元数据将波形信号渲染成与再现侧的系统兼容的期望声道数的信号。渲染技术的示例包括基于矢量的幅度平移(VBAP)(例如,非专利文献1和2)。
引用列表
非专利文献
非专利文献1:ISO/IEC 23008-3 Information technology-High efficiency coding and media delivery in heterogeneous environments-第3部分:3D audio
非专利文献2:Ville Pulkki,“Virtual Sound Source Positioning Using Vector Base Amplitude Panning”,AES期刊,第45卷,第6期,第456至466页,1997年
技术实现要素:
本发明要解决的问题
即使在基于对象的声音数据中,声音定位也是由每个对象的元数据确定的。因此,用户可以观看仅具有根据元数据预先准备的渲染结果的声音的内容,换句话说,观看仅具有在确定的视点(假定的收听位置)和其定位位置处的声音的内容。
因此,可以考虑使得能够选择任何假定的收听位置,根据由用户选择的假定收听位置来校正元数据,并且执行其中通过使用校正后的元数据来修改定位位置的渲染再现。
然而,在这种情况下,再现声音变为机械地反映每个对象的相对位置关系的变化的声音,并且并不总是成为令人满意的声音,即内容创建者期望表达的声音。
本技术是鉴于这样的情况而做出的,并且可以实现高度灵活的声音数据的再现,同时反映内容创建者的意图。
解决问题的方法
根据本技术的一方面的再现装置包括获取单元和渲染单元,获取单元获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的声音数据的渲染参数的内容,并且渲染单元基于针对所选择的预定的假定收听位置的渲染参数来渲染所述声音数据并输出声音信号。
内容还可以包括关于预先设置的假定收听位置的信息。在这种情况下,还可以提供显示控制单元,该显示控制单元基于关于假定收听位置的信息来使得用于选择假定收听位置的画面被显示。
针对假定收听位置中的每一个的渲染参数可以包括表示音频对象被定位的位置的定位信息以及作为用于声音数据的增益调整的参数的增益信息。
渲染单元可以基于与针对所选择的假定收听位置的渲染参数不同的渲染参数,对被选择作为无论所选择的假定收听位置如何其声源位置固定的音频对象的音频对象的声音数据进行渲染。
渲染单元能够不对构成内容的声音的多个音频对象中的预定音频对象的声音数据进行渲染。
还可以提供生成单元,该生成单元基于针对假定收听位置的渲染参数,针对为其未准备渲染参数的假定收听位置生成音频对象中的每一个的渲染参数。在这种情况下,渲染单元可以通过使用由生成单元生成的渲染参数来渲染音频对象中的每一个的声音数据。
生成单元可以基于针对为其准备了渲染参数的多个附近的假定收听位置的渲染参数,针对为其未准备渲染参数的假定收听位置生成渲染参数。
生成单元可以基于在过去获取的内容中包括的渲染参数,针对为其未准备渲染参数的假定收听位置生成渲染参数。
生成单元可以通过使用估计器来针对为其未准备渲染参数的假定收听位置生成渲染参数。
获取单元可以获取与记录内容的场所相对应的估计器,并且生成单元可以通过使用由获取单元获取的估计器来生成渲染参数。
可以通过至少使用包括在过去获取的内容中的渲染参数进行学习来构成估计器。
该内容还可以包括用于显示来自作为视点位置的假定收听位置的图像的视频数据。在这种情况下,还可以提供视频再现单元,其再现视频数据并使得来自作为视点位置的所选择的预定的假定收听位置的图像被显示。
根据本技术的一方面,获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的声音数据的渲染参数的内容,基于针对所选择的预定的假定收听位置的渲染参数来渲染声音数据,并输出声音信号。其中,基于与针对所选择的假定收听位置的渲染参数不同的渲染参数,对被选择作为无论所选择的假定收听位置如何其声源位置均固定的音频对象的音频对象的声音数据进行渲染。根据本技术的一方面,公开了一种在其上包含程序的非暂态计算机可读介质,所述程序使计算机执行处理,所述处理包括以下步骤:获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的所述声音数据的渲染参数的内容;以及基于针对所选择的预定的假定收听位置的渲染参数来渲染所述声音数据,并输出声音信号,其中,基于与针对所选择的假定收听位置的渲染参数不同的渲染参数,对被选择作为无论所选择的假定收听位置如何其声源位置均固定的音频对象的音频对象的声音数据进行渲染。根据本技术的一方面,公开了一种信息处理装置,包括:参数生成单元,其针对多个假定收听位置中的每一个生成音频对象中的每一个的声音数据的渲染参数;以及内容生成单元,其生成包括所述音频对象中的每一个的声音数据和所生成的渲染参数的内容,其中,被选择作为无论所选择的假定收听位置如何其声源位置均固定的音频对象的音频对象的声音数据的渲染参数与针对所选择的假定收听位置的渲染参数不同。根据本技术的一方面,公开了一种信息处理方法,包括以下步骤:针对多个假定收听位置中的每一个生成音频对象中的每一个的声音数据的渲染参数;以及生成包括所述音频对象中的每一个的声音数据和所生成的渲染参数的内容,其中,被选择作为无论所选择的假定收听位置如何其声源位置均固定的音频对象的音频对象的声音数据的渲染参数与针对所选择的假定收听位置的渲染参数不同。
发明的效果
根据本技术,可以实现高度灵活的声音数据的再现,同时反映内容创建者的意图。
注意,本文描述的效果不一定是限制性的,并且可以是本公开内容中描述的效果中的任何一种效果。
附图说明
图1是示出一个内容场景的视图。
图2是示出音频对象和视点的示例的图。
图3是示出针对视点#1的渲染参数的示例的图。
图4是示出每个音频对象的说明性定位的视图。
图5是示出每个音频对象的增益分配的示例的图。
图6是示出针对视点#2至#5的渲染参数的示例的图。
图7是示出再现装置的配置示例的框图。
图8是示出再现装置的功能配置示例的框图。
图9是示出图8中的音频再现单元的配置示例的框图。
图10是用于说明再现装置的音频再现处理的流程图。
图11是示出音频再现单元的另一配置示例的框图。
图12是示出音频再现单元的又一配置示例的框图。
图13是示出渲染参数的其他示例的图。
图14是示出音频再现单元的配置示例的框图。
图15是示出针对视点#6和视点#7的渲染参数的示例的图。
图16是示出针对视点#6的每个音频对象的说明性定位的视图。
图17是示出针对视点#7的每个音频对象的说明性定位的视图。
图18是示出针对任意视点#X的伪渲染参数的示例的图。
图19是示出使用伪渲染参数的每个音频对象的说明性定位的视图。
图20是示出音频再现单元的配置示例的框图。
图21是用于说明再现装置的另一音频再现处理的流程图。
图22是示出内容生成装置的功能配置示例的框图。
图23是用于说明内容生成装置的内容生成处理的流程图。
图24是示出分发系统的配置示例的图。
图25是示出再现装置和内容生成装置的配置示例的框图。
图26是示出元数据解码器的配置示例的框图。
图27是示出参数估计器的输入和输出的示例的图。
图28是示出每个对象的布置示例的视图。
图29是从倾斜方向看的场所的视图。
图30是示出针对视点1至视点5的渲染参数的图。
图31是示出从图30继续的针对视点1至视点5的渲染参数的图。
图32是示出视点6的位置的视图。
图33是示出视点2A和视点3A的位置的视图。
图34是示出针对视点2A和视点3A的渲染参数的图。
图35是示出针对视点6的渲染参数的图。
图36是示出分发系统的另一配置示例的图。
图37是示出再现装置和内容生成装置的配置示例的框图。
图38是示出图37中的参数估计器学习单元的配置示例的框图。
图39是示出分发系统的又一配置示例的框图。
具体实施方式
在下文中,将描述用于执行本技术的模式。将按以下顺序给出描述。
-第一实施方式
1.关于内容
2.再现装置的配置和操作
3.再现装置的另一配置示例
4.渲染参数的示例
5.自由视点的示例
6.内容生成装置的配置和操作
7.修改示例
-第二实施方式
1.分发系统的配置示例
2.生成渲染参数的示例
3.分发系统的另一配置示例
<<第一实施方式>>
<1.关于内容>
图1是示出通过根据本技术的一个实施方式的再现装置再现的内容的一个场景的视图。
由再现装置再现的内容的图像是其视点可以切换的图像。内容包括用于显示来自多个视点的图像的视频数据。
此外,由再现装置再现的内容的声音是其视点(假定的收听位置)可以切换的声音,使得例如将图像的视点的位置设置为收听位置。在视点被切换的情况下,声音的定位位置切换。
将内容的声音准备为基于对象的音频。包括在内容中的声音数据包括每个音频对象的波形数据和用于定位每个音频对象的声源的元数据。
由这样的视频数据和声音数据构成的内容以通过预定方法例如MPEG-H复用的形式提供给再现装置。
给出以下描述,其中再现目标内容是乐器表演的教学视频,但是本技术可以应用于包括基于对象的声音数据的各种内容。例如,其中台词、背景声音、声音效果、BGM等由音频对象构成的包括多视点图像和声音等的多视点戏剧被认为是这样的内容。
图1示出的水平长矩形区域(画面)被显示在再现装置的显示器上。图1中的示例示出了从左按顺序包括弹奏贝斯的人H1、打鼓的人H2、弹奏主吉他的人H3以及弹奏侧吉他的人H4的乐队的表演。图1所示的图像是其视点在从前方看见整个乐队的位置处的图像。
如图2的A中示出的,每个独立的波形数据被记录在内容中作为贝斯、鼓、主吉他和侧吉他的表演以及教师的解说语音的每个音频对象。
给出以下描述,其中指令目标是主吉他的表演。侧吉他、贝斯和鼓的表演是伴奏。图2的B示出了指令目标是主吉他的表演的教学视频的视点的示例。
如图2的B中示出的,视点#1是在从前方看到整个乐队的位置处的视点(图1)。视点#2是在从前方仅看到弹奏主吉他的人H3的位置处的视点。
视点#3是在看到弹奏主吉他的人H3的左手附近的特写的位置处的视点。视点#4是在看到弹奏主吉他的人H3的右手附近的特写的位置处的视点。视点#5是在弹奏主吉他的人H3的位置处的视点。用于显示来自每个视点的图像的视频数据被记录在内容中。
图3是示出针对视点#1的每个音频对象的渲染参数的示例的图。
图3中的示例示出定位信息和增益信息作为每个音频对象的渲染参数。定位信息包括指示方位角的信息和指示仰角的信息。对于正中面和水平面,方位角和仰角被分别表示为0°。
图3示出的渲染参数指示主吉他的声音被定位成向右10°,侧吉他的声音被定位成向右30°,贝斯的声音被定位成向左30°,鼓的声音被定位成向左15°,并且解说语音被定位成0°,并且所有增益都设置成1.0。
图4是示出针对视点#1的每个音频对象的说明性定位的图,其通过使用图3中示出的参数来实现。
在图4中圈出的位置P1至P5分别指示贝斯表演、鼓表演、解说语音、主吉他表演和侧吉他表演所处的位置。
通过使用图3中示出的参数来渲染每个音频对象的波形数据,用户收听如图4所示定位的每个表演和解说语音。图5是示出针对视点#1的每个音频对象的L/R增益分配的示例的图。在该示例中,用于输出声音的扬声器是2声道扬声器系统。
如图6所示,还针对视点#2至#5中的每一个准备了每个音频对象的这样的渲染参数。
针对视点#2的渲染参数是用于主要再现主吉他的声音与聚焦在主吉他上的视点图像的参数。至于每个音频对象的增益信息,与主吉他和解说语音的增益相比,侧吉他、贝斯和鼓的增益被抑制。
针对视点#3和视点#4的渲染参数是用于再现比视点#2的情况更集中在主吉他上的声音以及集中在吉他指法上的图像的参数。
至于视点#5,参数用于再现定位在演奏者的视点处的声音以及视点图像,使得用户可以假装是人H3,即主吉他演奏者。
因此,在由再现装置再现的内容的声音数据中,针对每个视点准备每个音频对象的渲染参数。针对每个视点的渲染参数由内容创建者预先确定,并作为元数据与音频对象的波形数据一起被发送或保存。
<2.再现装置的配置和操作>
图7是示出再现装置的配置示例的框图。
图7中的再现装置1是用于对包括基于对象的声音数据的多视点内容进行再现的装置,对于基于对象的声音数据,准备了针对每个视点的渲染参数。再现装置1例如是个人计算机并由内容观看者操纵。
如图7示出的,中央处理单元(CPU)11、只读存储器(ROM)12和随机存取存储器(RAM)13通过总线14相互连接。总线14还连接至输入/输出接口15。输入单元16、显示器17、扬声器18、存储单元19、通信单元20和驱动器21连接至输入/输出接口15。
输入单元16由键盘、鼠标等构成。输入单元16输出表示用户的操纵的内容的信号。
显示器17是诸如液晶显示器(LCD)或有机EL显示器的显示器。显示器17显示各种信息,例如用于选择视点的选择画面和再现内容的图像。显示器17可以是与再现装置1集成的显示器或连接至再现装置1的外部显示器。
扬声器18输出再现内容的声音。扬声器18例如是连接至再现装置1的扬声器。
存储单元19由硬盘、非易失性存储器等构成。存储单元19存储各种数据,例如由CPU 11执行的程序和再现目标内容。
通信单元20由网络接口等构成,并经由网络例如因特网与外部装置通信。经由网络分发的内容可以由通信单元20接收并再现。
驱动器21将数据写入附加的可移除介质22中并读出记录在可移除介质22上的数据。在再现装置1中,适当地再现由驱动器21从可移除介质22读出的内容。
图8是示出再现装置1的功能配置示例的框图。
通过利用图7中的CPU 11执行预定程序来实现图8示出的配置的至少一部分。在再现装置1中,实现内容获取单元31、分离单元32、音频再现单元33和视频再现单元34。
内容获取单元31获取诸如上述包括视频数据和声音数据的教学视频的内容。
在经由可移除介质22将内容提供给再现装置1的情况下,内容获取单元31控制驱动器21读出并获取记录在可移除介质22上的内容。此外,在经由网络将内容提供给再现装置1的情况下,内容获取单元31获取从外部装置发送并由通信单元20接收的内容。内容获取单元31将获取的内容输出至分离单元32。
分离单元32对从内容获取单元31提供的内容中包括的视频数据和声音数据进行分离。分离单元32将内容的视频数据输出至视频再现单元34,并将声音数据输出至音频再现单元33。
音频再现单元33基于元数据对构成从分离单元32提供的声音数据的波形数据进行渲染,并使扬声器18输出内容的声音。
视频再现单元34对从分离单元32提供的视频数据进行解码,并使显示器17显示来自预定视点的内容的图像。
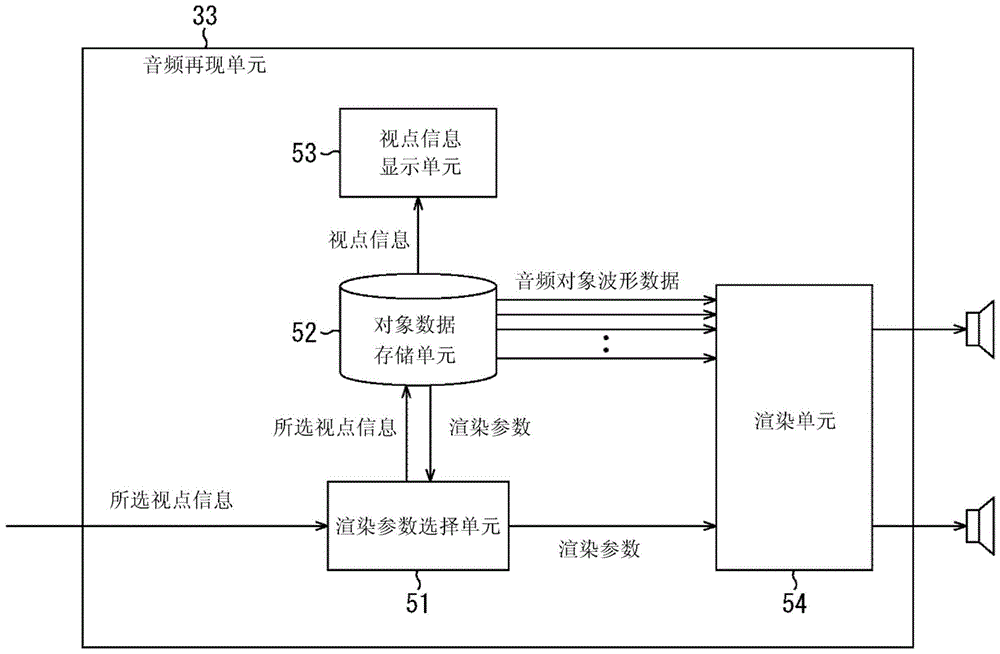
图9是示出图8中的音频再现单元33的配置示例的框图。
音频再现单元33由渲染参数选择单元51、对象数据存储单元52、视点信息显示单元53和渲染单元54构成。
渲染参数选择单元51根据输入的所选视点信息,从对象数据存储单元52中选择针对用户选择的视点的渲染参数,并将渲染参数输出至渲染单元54。在由用户从视点#1至视点#5中选择预定视点的情况下,将表示所选视点的所选视点信息输入至渲染参数选择单元51中。
对象数据存储单元52针对视点#1至视点#5中的每个视点存储每个音频对象的波形数据、视点信息和每个音频对象的渲染参数。
由渲染参数选择单元51读出存储在对象数据存储单元52中的渲染参数,并且由渲染单元54读出每个音频对象的波形数据。由视点信息显示单元53读出视点信息。要注意的是,视点信息是表示视点#1至#5被准备为内容的视点的信息。
视点信息显示单元53使显示器17根据从对象数据存储单元52读出的视点信息来显示视点选择画面,该视点选择画面是用于选择再现视点的画面。视点选择画面示出预先准备的多个视点,即视点#1至#5。
在视点选择画面中,多个视点的存在可以由图标或字符指示,或者可以由表示每个视点的缩略图指示。用户操纵输入单元16以从多个视点中选择预定视点。将表示由用户使用视点选择画面选择的视点的所选视点信息输入至渲染参数选择单元51中。
渲染单元54从对象数据存储单元52读出并获取每个音频对象的波形数据。渲染单元54还获取从渲染参数选择单元51提供的针对由用户选择的视点的渲染参数。
渲染单元54根据从渲染参数选择单元51获取的渲染参数渲染每个音频对象的波形数据,并将每个声道的声音信号输出至扬声器18。
例如,扬声器18是2声道扬声器系统,其分别向左打开30°和向右打开30°,并且视点#1被选择。在这种情况下,渲染单元54基于图3中的渲染参数获得图5中示出的增益分配,并且根据获得的增益分配执行再现,以将每个音频对象的声音信号分配给LR声道中的每一个。在扬声器18处,基于从渲染单元54提供的声音信号输出内容的声音。因此,实现了如图4示出的定位再现。
在扬声器18由诸如5.1声道或22.2声道的三维扬声器系统构成的情况下,渲染单元54使用诸如VBAP的渲染技术来针对每个扬声器系统生成每个声道的声音信号。
这里,参考图10中的流程图,将描述具有上述配置的再现装置1的音频再现处理。
当选择再现目标内容并由用户使用视点选择画面选择观看视点时,开始图10中的处理。将表示由用户选择的视点的所选视点信息输入至渲染参数选择单元51中。要注意的是,至于视频的再现,由视频再现单元34执行用于显示来自由用户选择的视点的图像的处理。
在步骤S1中,渲染参数选择单元51根据输入的所选视点信息,从对象数据存储单元52中选择针对所选视点的渲染参数。渲染参数选择单元51将所选渲染参数输出至渲染单元54。
在步骤S2中,渲染单元54从对象数据存储单元52中读出并获取每个音频对象的波形数据。
在步骤S3中,渲染单元54根据从渲染参数选择单元51提供的渲染参数渲染每个音频对象的波形数据。
在步骤S4中,渲染单元54将通过渲染获得的每个声道的声音信号输出至扬声器18,并使扬声器18输出每个音频对象的声音。
在内容被再现时,重复执行上述处理。例如,在内容的再现期间视点被用户切换的情况下,用于渲染的渲染参数也被切换至针对新选择的视点的渲染参数。
如上面描述的,由于针对每个视点准备了每个音频对象的渲染参数并且使用渲染参数执行再现,因此用户可以从多个视点中选择期望的视点并且观看具有与所选择视点匹配的声音的内容。通过使用针对由用户选择的视点准备的渲染参数来再现的声音堪称由内容创建者用心制作的具有高音乐性的声音。
假定准备了对所有视点都共同的一个渲染参数并且选择了视点的情况。在校正渲染参数以机械地反映所选视点的位置关系的变化并用于再现时,该声音有可能变成内容创建者不想要的声音。然而,这样的情况可以被避免。
换句话说,通过其中可以选择视点的上述处理可以实现高度灵活的声音数据的再现,同时反映内容创建者的意图。
<3.再现装置的另一个配置示例>
图11是示出音频再现单元33的另一配置示例的框图。
图11中示出的音频再现单元33具有与图9中的配置类似的配置。将适当地省略冗余的描述。
在具有图11示出的配置的音频再现单元33中,可以指定不希望其定位位置根据视点来变化的音频对象。在上述音频对象中,例如,在某些情况下,无论视点的位置如何,解说语音的定位位置优选地被固定。
表示固定对象——固定对象是其定位位置被固定的音频对象——的信息作为固定对象信息被输入至渲染参数选择单元51中。固定对象可以由用户指定或者可以由内容创建者指定。
图11中的渲染参数选择单元51从对象数据存储单元52中读出默认渲染参数作为由固定对象信息指定的固定对象的渲染参数,并将默认渲染参数输出至渲染单元54。
对于默认渲染参数,例如,可以使用针对视点#1的渲染参数,或者可以准备专用渲染参数。
此外,对于除固定对象之外的音频对象,渲染参数选择单元51从对象数据存储单元52读出针对由用户选择的视点的渲染参数,并将渲染参数输出至渲染单元54。
渲染单元54基于从渲染参数选择单元51提供的默认渲染参数和针对由用户选择的视点的渲染参数来渲染每个音频对象。渲染单元54将通过渲染获得的每个声道的声音信号输出至扬声器18。
对于所有音频对象,可以使用默认渲染参数而不是针对所选视点的渲染参数来执行渲染。
图12是示出音频再现单元33的又一配置示例的框图。
图12示出的音频再现单元33的配置与图9中的配置的不同之处在于,在对象数据存储单元52与渲染单元54之间提供开关61。
在具有图12示出的配置的音频再现单元33中,可以指定要再现的音频对象或不再现的音频对象。将表示需要再现的音频对象的信息作为再现对象信息输入至开关61中。需要再现的对象可以由用户指定或者可以由内容创建者指定。
图12中的开关61将由再现对象信息指定的音频对象的波形数据输出至渲染单元54。
渲染单元54基于从渲染参数选择单元51提供的针对由用户选择的视点的渲染参数来渲染需要再现的音频对象的波形数据。换句话说,渲染单元54不对不需要再现的音频对象进行渲染。
渲染单元54将通过渲染获得的每个声道的声音信号输出至扬声器18。
因此,例如,通过将主吉他指定为不需要再现的音频对象,作为模型,用户可以使主吉他的声音静音,并在观看教学视频时叠加她/他的表演。在这种情况下,从对象数据存储单元52向渲染单元54仅提供除主吉他之外的音频对象的波形数据。
可以通过控制增益,而不是控制向渲染单元54输出波形数据来实现静音。在这种情况下,再现对象信息被输入至渲染单元54。例如,渲染单元54根据再现对象信息将主吉他的增益调整为0并且根据从渲染参数选择单元51提供的渲染参数调整其他音频对象的增益,并执行渲染。
通过不论所选择的视点如何均固定定位位置并且以这种方式仅再现必要的声音,用户可以根据他/她的偏好来再现内容。
<4.渲染参数的示例>
特别地,在音乐内容的创建中,除了调整定位位置和增益之外,通过例如均衡器调整声音质量并添加具有混响的混响成分来执行每个乐器的声音再现。用于声音再现的这样的参数也可以作为元数据与定位信息和增益信息一起添加至声音数据中并用于渲染。
还针对每个视点准备添加至定位信息和增益信息的其他参数。
图13是示出渲染参数的其他示例的图。
在图13的示例中,除了定位信息和增益信息之外,还包括均衡器信息、压缩器信息和混响信息作为渲染参数。
均衡器信息由关于用于由均衡器进行声学调整的滤波器的类型、滤波器的中心频率、锐度、增益和预增益的每条信息构成。压缩器信息由关于用于由压缩器进行声学调整的频率带宽、阈值、比率、增益、启动时间和释放时间的每条信息构成。混响信息由关于用于通过混响进行声学调整的初始反射时间、初始反射增益、混响时间、混响增益、倾泻(dumping)以及干/湿系数的每条信息构成。
包括在渲染参数中的参数可以是除了图13中示出的信息之外的信息。
图14是示出与包括图13中示出的信息的渲染参数的处理兼容的音频再现单元33的配置示例的框图。
图14示出的音频再现单元33的配置与图9中的配置的不同之处在于,渲染单元54由均衡器单元71、混响成分添加单元72、压缩单元73及增益调整单元74构成。
渲染参数选择单元51根据输入的所选视点信息,从对象数据存储单元52中读出针对由用户选择的视点的渲染参数,并将渲染参数输出至渲染单元54。
将从渲染参数选择单元51输出的渲染参数中包括的均衡器信息、混响信息和压缩器信息分别提供给均衡器单元71、混响成分添加单元72和压缩单元73。此外,将渲染参数中包括的定位信息和增益信息提供给增益调整单元74。
对象数据存储单元52将针对每个视点的每个音频对象的渲染参数与每个音频对象的波形数据和视点信息一起存储。存储在对象数据存储单元52中的渲染参数包括图13中示出的每条信息。将存储在对象数据存储单元52中的每个音频对象的波形数据提供给渲染单元54。
渲染单元54根据从渲染参数选择单元51提供的每个渲染参数对每个音频对象的波形数据执行单独的声音质量调整处理。渲染单元54对通过执行声音质量调整处理获得的波形数据执行增益调整,并将声音信号输出至扬声器18。
换句话说,渲染单元54的均衡器单元71基于均衡器信息对每个音频对象的波形数据执行均衡处理,并且将通过均衡处理获得的波形数据输出至混响成分添加单元72。
混响成分添加单元72基于混响信息执行混响成分添加处理,并将添加了混响成分的波形数据输出至压缩单元73。
压缩单元73基于压缩器信息对从混响成分添加单元72提供的波形数据执行压缩处理,并将通过压缩处理获得的波形数据输出至增益调整单元74。
增益调整单元74基于定位信息和增益信息,执行对从压缩单元73提供的波形数据的增益的增益调整,并将通过执行增益调整获得的每个声道的声音信号输出至扬声器18。
通过使用如上文描述的渲染参数,内容创建者可以在针对每个视点的音频对象的渲染再现中更多地反映他/她自己的声音再现。例如,可以通过这些参数对由于声音的方向性而使声音的音调针对每个视点如何变化进行再现。此外,还可以由内容创建者控制声音的有意混合组成,使得针对某一视点有意地抑制吉他的声音。
<5.自由视点的示例>
在上文中,可以从针对其准备了渲染参数的多个视点中选择视点,但是还可以自由地选择任意视点。此处的任意视点是针对其未准备渲染参数的视点。
在这种情况下,通过利用针对邻近任意视点的两个视点的渲染参数来生成针对所选择的任意视点的伪渲染参数。通过应用所生成的渲染参数作为针对任意视点的渲染参数,可以针对任意视点执行声音的渲染再现。
其渲染参数用于生成伪渲染参数的视点的数量不限于两个,并且可以通过使用针对三个或更多个视点的渲染参数来生成针对任意视点的渲染参数。此外,除了针对邻近视点的渲染参数之外,还可以通过使用针对任何视点的渲染参数来生成伪渲染参数,只要渲染参数是针对任意视点附近的多个视点即可。
图15是示出针对两个视点即视点#6和视点#7的渲染参数的示例的图。
在图15的示例中,包括定位信息和增益信息作为主吉他、侧吉他、贝斯、鼓和解说语音的音频对象中的每个音频对象的渲染参数。包括图13中示出的信息的渲染参数也可以用作图15中示出的渲染参数。
此外,在图15的示例中,针对视点#6的渲染参数表示主吉他的声音被定位成向右10°、侧吉他的声音被定位成向右30°、贝斯的声音被定位成向左30°、鼓的声音被定位成向左15°,并且解说语音被定位成0°。
同时,针对视点#7的渲染参数表示主吉他的声音被定位成向右5°、侧吉他的声音被定位成向右10°、贝斯的声音被定位成向左10°、鼓的声音被定位成向左8°,并且解说语音被定位成0°。
图16和图17示出了针对相应视点即视点#6和视点#7的每个音频对象的说明性定位。如图16所示,来自前方的视点被假定成视点#6,并且来自右手的视点被假定成视点#7。
此处,选择视点#6与视点#7之间的中间点,换言之选择来自前方稍微向右的视点作为任意视点#X。关于任意视点#X,视点#6和视点#7是邻近视点。任意视点#X是针对其未准备渲染参数的视点。
在这种情况下,在音频再现单元33中,通过使用上述针对视点#6和视点#7的渲染参数来生成针对任意视点#X的伪渲染参数。例如,基于针对视点#6和视点#7的渲染参数通过插值处理例如线性插值来生成伪渲染参数。
图18是示出针对任意视点#X的伪渲染参数的示例的图。
在图18的示例中,针对任意视点#X的渲染参数表示主吉他的声音被定位成向右7.5°、侧吉他的声音被定位成向右20°、贝斯的声音被定位成向左20°、鼓的声音被定位成向左11.5°,并且解说语音被定位成0°。图18中示出的每个值是在图15中示出的针对视点#6和视点#7的渲染参数的各个值之间的中间值,并且是通过线性插值处理获得的。
图19示出了使用图18中示出的伪渲染参数的每个音频对象的说明性定位。如图19所示,任意视点#X是从相对于图16示出的视点#6稍微向右看到的视点。
图20是示出具有如上所描述的生成伪渲染参数的功能的音频再现单元33的配置示例的框图。
图20中示出的音频再现单元33的配置与图9中的配置的不同之处在于,在渲染参数选择单元51与渲染单元54之间设置渲染参数生成单元81。将选择的表示任意视点#X的视点信息输入至渲染参数选择单元51和渲染参数生成单元81中。
渲染参数选择单元51根据输入的所选视点信息,从对象数据存储单元52读出针对与用户选择的任意视点#X邻近的多个视点的渲染参数。渲染参数选择单元51将针对多个邻近视点的渲染参数输出至渲染参数生成单元81。
例如,渲染参数生成单元81基于所选择的视点信息,识别任意视点#X与针对其准备了渲染参数的多个邻近视点之间的相对位置关系。通过根据所识别的位置关系执行插值处理,渲染参数生成单元81基于从渲染参数选择单元51提供的渲染参数来生成伪渲染参数。渲染参数生成单元81将生成的伪渲染参数作为针对任意视点#X的渲染参数输出至渲染单元54。
渲染单元54根据从渲染参数生成单元81提供的伪渲染参数渲染每个音频对象的波形数据。渲染单元54将通过渲染获得的每个声道的声音信号输出至扬声器18并使得扬声器18输出声音信号作为针对任意视点#X的声音。
此处,将参考图21中的流程图对具有图20中的配置的音频再现单元33的音频再现处理进行描述。
例如,当用户使用由视点信息显示单元53显示的视点选择画面选择任意视点#X时,开始图21中的处理。将表示任意视点#X的所选视点信息输入至渲染参数选择单元51和渲染参数生成单元81中。
在步骤S11中,渲染参数选择单元51根据所选择的视点信息,从对象数据存储单元52中选择针对与任意视点#X邻近的多个视点的渲染参数。渲染参数选择单元51将所选择的渲染参数输出至渲染参数生成单元81。
在步骤S12中,渲染参数生成单元81通过根据任意视点#X与针对其准备了渲染参数的多个邻近视点之间的位置关系执行插值处理来生成伪渲染参数。
在步骤S13中,渲染单元54从对象数据存储单元52中读出并获取每个音频对象的波形数据。
在步骤S14中,渲染单元54根据由渲染参数生成单元81生成的伪渲染参数来渲染每个音频对象的波形数据。
在步骤S15中,渲染单元54将通过渲染获得的每个声道的声音信号输出至扬声器18,并使扬声器18输出每个音频对象的声音。
通过以上处理,再现装置1可以对相对于针对其未准备渲染参数的任意视点#X而定位的音频进行再现。用户可以自由选择任意视点并观看内容。
<6.内容生成装置的配置和操作>
图22是示出生成诸如如上面描述的教学视频的内容的内容生成装置101的功能配置示例的框图。
内容生成装置101例如是由内容创建者操纵的信息处理装置。内容生成装置101基本具有与图7中示出的再现装置1的硬件配置类似的硬件配置。
将给出以下描述,其中适当引用图7中示出的配置以用于内容生成装置101的配置。图22示出的每个组成部分通过用内容生成装置101的CPU11(图7)执行预定程序来实现。
如图22示出的,内容生成装置101由视频生成单元111、元数据生成单元112、音频生成单元113、复用单元114、记录控制单元115和发送控制单元116构成。
视频生成单元111获取从外部输入的图像信号,并通过用预定编码方法对多视点图像信号进行编码来生成视频数据。视频生成单元111将生成的视频数据输出至复用单元114。
元数据生成单元112根据内容创建者的操纵针对每个视点生成每个音频对象的渲染参数。元数据生成单元112将生成的渲染参数输出至音频生成单元113。
此外,元数据生成单元112根据内容创建者的操纵生成视点信息,该视点信息是关于内容的视点的信息,并且将该视点信息输出至音频生成单元113。
音频生成单元113获取从外部输入的声音信号,并生成每个音频对象的波形数据。音频生成单元113通过将每个音频对象的波形数据与由元数据生成单元112生成的渲染参数相关联来生成基于对象的声音数据。
音频生成单元113将所生成的基于对象的声音数据与视点信息一起输出至复用单元114。
复用单元114通过预定方法例如MPEG-H对从视频生成单元111提供的视频数据和从音频生成单元113提供的声音数据进行复用,并且生成内容。构成内容的声音数据还包括视点信息。复用单元114用作生成包括基于对象的声音数据的内容的生成单元。
在经由记录介质提供内容的情况下,复用单元114将所生成的内容输出至记录控制单元115。在经由网络提供内容的情况下,复用单元114将所生成的内容输出至发送控制单元116。
记录控制单元115控制驱动器21并将从复用单元114提供的内容记录在可移除介质22上。将由记录控制单元115在其上记录内容的可移除介质22提供给再现装置1。
发送控制单元116控制通信单元20,并将从复用单元114提供的内容发送至再现装置1。
此处,将参考图23中的流程图描述具有以上配置的内容生成装置101的内容生成处理。
在步骤S101中,视频生成单元111获取从外部输入的图像信号,并生成包括多视点图像信号的视频数据。
在步骤S102中,元数据生成单元112根据内容创建者的操纵,针对每个视点生成每个音频对象的渲染参数。
在步骤S103中,音频生成单元113获取从外部输入的声音信号,并生成每个音频对象的波形数据。音频生成单元113还通过将每个音频对象的波形数据与由元数据生成单元112生成的渲染参数相关联来生成基于对象的声音数据。
在步骤S104中,复用单元114对由视频生成单元111生成的视频数据和由音频生成单元113生成的声音数据进行复用,并生成内容。
通过以上处理生成的内容经由预定路径提供给再现装置1,并在再现装置1中再现。
<7.修改示例>
由再现装置1再现的内容包括视频数据和基于对象的声音数据,但是内容可以由基于对象的声音数据构成,而不包括视频数据。在从针对其准备了渲染参数的收听位置中选择预定收听位置的情况下,通过使用针对所选择的收听位置的渲染参数来再现每个音频对象。
在上文中渲染参数由内容创建者确定,但是也可以由观看内容的用户她自己/他自己确定。此外,由用户他自己/她自己确定的针对每个视点的渲染参数可以经由因特网等提供给其他用户。
通过使用以这种方式提供的渲染参数的渲染再现,再现了由不同用户预期的声音。要注意的是,内容创建者可以对可以由用户设置的参数的类型和值进行限制。
在上述实施方式中的每一个中,可以适当地组合实施方式中的两个或更多个实施方式来使用。例如,在如参照图11所描述的可以指定其定位位置不希望改变的音频对象的情况下,可以如参照图12所描述的能够指定需要再现的音频对象。
<<第二实施方式>>
<1.分发系统的配置示例>
图24是示出分发系统的配置示例的图,该分发系统对包括如上所描述的对象音频的内容进行分发,对于该对象音频,针对每个视点准备了渲染参数。
在图24的分发系统中,由内容创建者管理的内容生成装置101被放置在正在举行音乐现场演出的场所#1处。同时,再现装置1放置在用户家中。再现装置1和内容生成装置101经由因特网201连接。
内容生成装置101生成由包括多视点图像的视频数据和包括针对多个相应视点的渲染参数的对象音频构成的内容。由内容生成装置101生成的内容被发送至例如服务器(未示出)并经由服务器提供给再现装置1。
再现装置1接收从内容生成装置101发送的内容,并再现针对用户选择的视点的视频数据。此外,再现装置1通过使用针对由用户选择的视点的渲染参数来渲染对象音频,并输出音乐现场演出的声音。
例如,内容生成装置101跟随音乐现场演出的进展实时地生成内容并发送内容。再现装置1的用户可以基本实时地远程观看音乐现场演出。
在图24的示例中,仅再现装置1被示为接收分发的内容的再现装置,但是实际上许多再现装置被连接至因特网201。
再现装置1的用户可以自由地选择任意视点并听到对象音频。在没有从内容生成装置101发送针对由用户选择的视点的渲染参数的情况下,再现装置1生成针对所选视点的渲染参数并渲染对象音频。
在前述示例中通过线性插值生成渲染参数,但是渲染参数也可以通过使用由神经网络构成的参数估计器来在图24中的再现装置1中生成。再现装置1具有通过使用在场所#1处举办的音乐现场演出的声音数据进行学习而生成的参数估计器。稍后将描述通过使用参数估计器来生成渲染参数。
图25是示出再现装置1和内容生成装置101的配置示例的框图。
图25仅示出了再现装置1和内容生成装置101的部分配置,但是再现装置1具有图8示出的配置。此外,内容生成装置101具有图22示出的配置。
内容生成装置101具有音频编码器211和元数据编码器212。音频编码器211对应于音频生成单元113(图22),并且元数据编码器212对应于元数据生成单元112。
音频编码器211在音乐现场演出期间获取声音信号,并生成每个音频对象的波形数据。
元数据编码器212根据内容创建者的操纵针对每个视点生成每个音频对象的渲染参数。
音频生成单元113将由音频编码器211生成的波形数据与由元数据编码器212生成的渲染参数相关联,从而生成基于对象的声音数据。在复用单元114中对基于对象的声音数据与视频数据进行复用,并且然后由发送控制单元116发送至再现装置1。
再现装置1具有音频解码器221、元数据解码器222和再现单元223。音频解码器221、元数据解码器222和再现单元223构成音频再现单元33(图8)。在再现装置1的内容获取单元31中获取从内容生成装置101发送的内容,并且通过分离单元32分离基于对象的声音数据和视频数据。
基于对象的声音数据被输入到音频解码器221。此外,针对每个视点的渲染参数被输入至元数据解码器222中。
音频解码器221对声音数据进行解码,并将每个音频对象的波形数据输出至再现单元223。
元数据解码器222将针对由用户选择的视点的渲染参数输出至再现单元223。
再现单元223根据从元数据解码器222提供的渲染参数渲染每个音频对象的波形数据,并使扬声器输出与每个声道的声音信号对应的声音。
如图25所示,在省略并且未示出插入的构成部分的情况下,将由音频编码器211生成的每个音频对象的波形数据提供给音频解码器221。此外,将由元数据编码器212生成的渲染参数提供给元数据解码器222。
图26是示出元数据解码器222的配置示例的框图。
如图26所示,元数据解码器222由元数据获取单元231、渲染参数选择单元232、渲染参数生成单元233和累积单元234构成。
元数据获取单元231接收并获取以被包括在声音数据中的形式发送的针对每个视点的渲染参数。将由元数据获取单元231获取的渲染参数提供给渲染参数选择单元232、渲染参数生成单元233和累积单元234。
渲染参数选择单元232基于输入的所选视点信息识别由用户选择的视点。在从元数据获取单元231提供的渲染参数中存在针对用户选择的视点的渲染参数的情况下,渲染参数选择单元232输出针对由用户选择的视点的渲染参数。
此外,在不存在针对由用户选择的视点的渲染参数的情况下,渲染参数选择单元232将所选择的视点信息输出至渲染参数生成单元233,并使渲染参数生成单元233生成渲染参数。
渲染参数生成单元233具有参数估计器。渲染参数生成单元233使用参数估计器来生成针对由用户选择的视点的渲染参数。为了生成渲染参数,从元数据获取单元231提供的当前渲染参数和从累积单元234读出的过去的渲染参数被用作至参数估计器的输入。渲染参数生成单元233输出生成的渲染参数。由渲染参数生成单元233生成的渲染参数对应于前述伪渲染参数。
因此,渲染参数由渲染参数生成单元233通过还使用过去从内容生成装置101发送的渲染参数来生成。例如,在每天在场所#1处举行音乐现场演出并且每天分发其内容的情况下,每天从内容生成装置101(元数据编码器212)发送渲染参数。
图27是示出渲染参数生成单元233所具有的参数估计器的输入和输出的示例的图。
如箭头A1至A3所指示的,除了关于由用户选择的视点的信息之外,将从元数据编码器212发送的当前(最新)渲染参数和过去的渲染参数输入至参数估计器233A中。
此处,渲染参数包括参数信息和渲染信息。参数信息是包括指示音频对象的类型的信息、音频对象的位置信息、视点位置信息以及关于日期和时间的信息的信息。同时,渲染信息是关于波形数据的特性例如增益的信息。稍后将描述构成渲染参数的信息的细节。
在输入这样的每条信息的情况下,如箭头A4指示的,参数估计器233A输出由用户选择的视点的渲染信息。
渲染参数生成单元233通过使用从元数据编码器212发送的渲染参数适当地执行参数估计器233A的学习。在预定的定时例如当发送新的渲染参数时执行参数估计器233A的学习。
累积单元234存储从元数据获取单元231提供的渲染参数。累积单元234累积从元数据编码器212发送的渲染参数。
<2.生成渲染参数的示例>
此处,将描述通过渲染参数生成单元233生成渲染参数。
(1)假设存在多个音频对象。
对象的声音数据如下定义。
x(n,i)i=0,1,2,...,L-1
n是时间索引。此外,i表示对象的类型。此处,对象的数量是L。
(2)假设存在多个视点。
针对每个视点的对象的渲染信息如下定义。
r(i,j)j=0,1,2,...,M-1
j表示视点的类型。视点的数量是M。
(3)针对每个视点的声音数据y(n,j)由以下表达式(1)表示。
[数学式1]
此处,假设渲染信息r是增益(增益信息)。在这种情况下,渲染信息r的值的范围从0至1。通过将每个对象的声音数据乘以增益并将所有对象的声音数据相加来表示针对每个视点的声音数据。表达式(1)中所示出的计算由再现单元223执行。
(4)在用户指定的视点不是视点j=0,1,2,...,M-1中的任何视点的情况下,通过使用过去的渲染参数和当前的渲染参数来生成针对用户指定的视点的渲染参数。
(5)下面利用对象的类型、对象的位置、视点的位置和时间来定义针对每个视点的对象的渲染信息。
r(obj_type,obj_loc_x,obj_loc_y,obj_loc_z,lis_loc_x,lis_loc_y,lis_loc_z,date_time)
obj_type是指示对象类型的信息,并且指示例如乐器的类型。
obj_loc_x、obj_loc_y和obj_loc_z是指示对象在三维空间中的位置的信息。
lis_loc_x、lis_loc_y和lis_loc_z是指示视点在三维空间中的位置的信息。
date_time是表示执行表演的日期和时间的信息。
从元数据编码器212将由obj_type、obj_loc_x、obj_loc_y、obj_loc_z、lis_loc_x、lis_loc_y、lis_loc_z和date_time构成的这样的参数信息与渲染信息r一起发送。
这将在下文中具体描述。
(6)例如,如图28示出的布置贝斯、鼓、吉他和声乐的每个对象。图28是从正上方看到的场所#1中的舞台#11的视图。
(7)对于场所#1,如图29所示设置XYZ的各个轴。图29是从倾斜方向看到的包括舞台#11和观众席的整个场所#1的视图。原点O是舞台#11的中心位置。视点1至5设置在观众席处。
每个对象的坐标如下表示。单位是米。
贝斯的坐标:x=-20,y=0,z=0
鼓的坐标:x=0,y=-10,z=0
吉他的坐标:x=20,y=0,z=0
声乐的坐标:x=0,y=10,z=0
(8)每个视点的坐标如下表示。
视点1:x=0,y=50,z=-1
视点2:x=-20,y=30,z=-1
视点3:x=20,y=30,z=-1
视点4:x=-20,y=70,z=-1
视点5:x=20,y=70,z=-1
(9)此时,例如,针对视点1的每个对象的渲染信息如下表示。
贝斯的渲染信息:
r(0,-20,0,0,0,50,-1,2014.11.5.18.34.50)
鼓的渲染信息:
r(1,0,-10,0,0,50,-1,2014.11.5.18.34.50)
吉他的渲染信息:
r(2,20,0,0,0,50,-1,2014.11.5.18.34.50)
声乐的渲染信息:
r(3,0,10,0,0,50,-1,2014.11.5.18.34.50)
举行音乐现场演出的日期和时间是2014年11月5日18:34:50。此外,每个对象的obj_type具有以下值。
贝斯:obj_type=0
鼓:obj_type=1
吉他:obj_type=2
声乐:obj_type=3
针对视点1至视点5的每个视点,元数据编码器212发送包括如上所述被表示的参数信息和渲染信息的渲染参数。在图30和图31中示出针对视点1至视点5的每个视点的渲染参数。
(10)此时,根据上述表达式(1),在选择视点1的情况下的声音数据由以下表达式(2)表示。
[数学式2]
y(n,1)=x(n,0)*r(0,-20,0,0,0,50,-1,2014.11.5.18.34.50)+x(n,1)*r(1,0,-10,0,0,50,-1,2014.11.5.18.34.50)+x(n,2)*r(2,20,0,0,0,50,-1,2014.11.5.18.34.50)+x(n,3)*r(3,0,10,0,0,50,-1,2014.11.5.18.34.50)···(2)
然而,对于x(n,i),i代表以下对象。
i=0:贝斯对象
i=1:鼓对象
i=2:吉他对象
i=3:声乐对象
(11)用户指定由图32中的虚线指示的视点6作为观看位置。针对视点6的渲染参数不从元数据编码器212发送。视点6的坐标如下表示。
视点6:x=0,y=30,z=-1
在这种情况下,通过使用针对视点1至5的当前(2014.11.5.18.34.50)渲染参数和过去(在2014.11.5.18.34.50之前)发送的针对附近视点的渲染参数来生成针对当前视点6的渲染参数。从累积单元234读出过去的渲染参数。
(12)例如,图33示出的针对视点2A和视点3A的渲染参数是过去发送的。视点2A位于视点2与视点4之间,并且视点3A位于视点3与视点5之间。视点2A和视点3A的坐标如下表示。
视点2A:x=-20,y=40,z=-1
观点3A:x=20,y=40,z=-1
在图34中示出了针对视点2A和3A中的每个视点的渲染参数。在图34中,每个对象的obj_type同样具有以下值。
贝斯:obj_type=0
鼓:obj_type=1
吉他:obj_type=2
声乐:obj_type=3
因此,从元数据编码器212发送其渲染参数的视点的位置并不总是固定位置,而是在那时的不同位置。累积单元234存储针对在场所#1的各个位置处的视点的渲染参数。
要注意的是,希望在用于估计的当前渲染参数和过去的渲染参数中贝斯、鼓、吉他和声乐中的每个对象的配置和位置是相同的,但可以是不同的。
(13)用于针对视点6的渲染信息的估计方法
以下信息被输入到参数估计器233A中。
-针对视点1至视点5的参数信息和渲染信息(图30和图31)
-针对视点2A和视点3A的参数信息和渲染信息(图34)
-针对视点6的参数信息(图35)
在图35中,lis_loc_x、lis_loc_y和lis_loc_z表示由用户选择的视点6的位置。此外,使用表示当前日期和时间的2014.11.5.18.34.50作为data_time。
用作至参数估计器233A的输入的针对视点6的参数信息由渲染参数生成单元233例如基于针对视点1至视点5的参数信息和由用户选择的视点的位置来生成。
在输入这样的每条信息的情况下,参数估计器233A输出如图35中的右端列所示的针对视点6的每个对象的渲染信息。
贝斯的渲染信息(obj_type=0):
r(0,-20,0,0,0,30,-1,2014.11.5.18.34.50)
鼓的渲染信息(obj_type=1):
r(1,0,-10,0,0,30,-1,2014.11.5.18.34.50)
吉他的渲染信息(obj_type=2):
r(2,20,0,0,0,30,-1,2014.11.5.18.34.50)
声乐的渲染信息(obj_type=3):
r(3,0,10,0,0,30,-1,2014.11.5.18.34.50)
将从参数估计器233A输出的渲染信息与针对视点6的参数信息一起提供给再现单元223,并用于渲染。因此,参数生成单元233生成并输出由针对为其未准备渲染参数的视点的参数信息以及通过使用参数估计器233A估计的渲染信息构成的渲染参数。
(14)参数估计器233A的学习
渲染参数生成单元233通过使用渲染参数作为学习数据来执行参数估计器233A的学习,渲染参数从元数据编码器212发送并累积在累积单元234中。
在参数估计器233A的学习中,将从元数据编码器212发送的渲染信息r用作教学数据。例如,渲染参数生成单元233通过调整系数来执行参数估计器233A的学习使得渲染信息r与神经网络的输出r^之间的误差(r^-r)变小。
通过使用从内容生成装置101发送的渲染参数执行学习,参数估计器233A成为场所#1的估计器,其被用于在场所#1中的预定位置被设置为视点的情况下生成渲染参数。
在上文中渲染信息r是具有从0到1的值的增益,但是可以包括如参照图13描述的均衡器信息、压缩器信息和混响信息。换句话说,渲染信息r可以是表示增益、均衡器信息、压缩器信息或混响信息中的至少任何一个的信息。
此外,参数估计器233A输入图27中示出的每条信息,但是可以简单地被配置为当输入针对视点6的参数信息时输出渲染信息r的神经网络。
<3.分发系统的另一配置示例>
图36是示出分发系统的另一配置示例的图。与上述构成部分相同的构成部分用相同的附图标记表示。将省略冗余描述。这也适用于图37和随后的附图。
在图36的示例中,存在作为正在举行音乐现场演出的场所的场所#1-1至#1-3。内容生成装置101-1至101-3分别放置在场所#1-1至#1-3处。在不必区分内容生成装置101-1至101-3的情况下,将它们统称为内容生成装置101。
内容生成装置101-1至101-3中的每一个具有与图24中的内容生成装置101的功能类似的功能。换句话说,内容生成装置101-1至101-3经由因特网201对包含在各个场所举行的音乐现场演出的内容进行分发。
再现装置1接收由放置在正在举行由用户选择的音乐现场演出的场所处的内容生成装置101所分发的内容,如上面描述的再现基于对象的声音数据等。再现装置1的用户可以选择视点并观看正在预定场所举行的音乐现场演出。
在前述示例中,在再现装置1中生成用于生成渲染参数的参数估计器,但是在图36的示例中在内容生成装置101侧生成用于生成渲染参数的参数估计器。
换句话说,内容生成装置101-1至101-3如前面提到的通过使用过去的渲染参数作为学习数据等来单独生成参数估计器。
由内容生成装置101-1生成的参数估计器是与场所#1-1中的声学特性和每个观看位置兼容的针对场所#1-1的参数估计器。由内容生成装置101-2生成的参数估计器是针对场所#1-2的参数估计器,并且由内容生成装置101-3生成的参数估计器是针对场所#1-3的参数估计器。
例如,在再现由内容生成装置101-1生成的内容的情况下,再现装置1获取针对场所#1-1的参数估计器。在用户选择针对其未准备渲染参数的视点的情况下,再现装置1将当前的渲染参数和过去的渲染参数输入至针对场所#1-1的参数估计器中,并如前面提到的生成渲染参数。
因此,在图36的分发系统中,在内容生成装置101侧准备针对每个场所的参数估计器并将其提供给再现装置1。由于通过使用针对每个场所的参数估计器生成针对任意视点的渲染参数,因此再现装置1的用户可以选择任意视点并观看在每个场所处的音乐现场表演。
图37是示出再现装置1和内容生成装置101的配置示例的框图。
在图37示出的内容生成装置101的配置与图25示出的配置的不同之处在于提供了参数估计器学习单元213。图36示出的内容生成装置101-1至101-3中的每一个具有与图37示出的内容生成装置101的配置相同的配置。
参数估计器学习单元213通过使用由元数据编码器212生成的渲染参数作为学习数据来执行参数估计器的学习。参数估计器学习单元213在预定定时处例如在开始分发内容之前将参数估计器发送至再现装置1。
再现装置1的元数据解码器222的元数据获取单元231接收并获取从内容生成装置101发送的参数估计器。元数据获取单元231用作获取针对场所的参数估计器的获取单元。
由元数据获取单元231获取的参数估计器被设置在元数据解码器222的渲染参数生成单元233中,并且用于适当地生成渲染参数。
图38是示出图37中的参数估计器学习单元213的配置示例的框图。
参数估计器学习单元213由学习单元251、估计器DB 252和估计器提供单元253构成。
学习单元251通过使用由元数据编码器212生成的渲染参数作为学习数据来执行对存储在估计器DB 252中的参数估计器的学习。
估计器提供单元253控制发送控制单元116(图22)以将存储在估计器DB 252中的参数估计器发送至再现装置1。估计器提供单元253用作向再现装置1提供参数估计器的提供单元。
因此,可以在内容生成装置101侧准备针对每个场所的参数估计器,并且在预定定时处例如在开始再现内容之前该将参数估计器提供给再现装置1。
针对每个场所的参数估计器在放置在图36的示例中的每个场所处的内容生成装置101中生成,但是也可以由连接至因特网201的服务器生成。
图39是示出分发系统的又一配置示例的框图。
图39中的管理服务器301接收从放置在场所#1-1至#1-3处的内容生成装置101-1至101-3发送的渲染参数,并学习用于各个场所的参数估计器。换句话说,管理服务器301具有图38中的参数估计器学习单元213。
在再现装置1再现在预定场所处的音乐现场演出的内容的情况下,管理服务器301将针对该场所的参数估计器发送至再现装置1。再现装置1适当地使用从管理服务器301发送的参数估计器来再现音频。
因此,可以经由连接至因特网201的管理服务器301来提供参数估计器。要注意的是,可以在内容生成装置101侧执行参数估计器的学习,并且可以将生成的参数估计器提供给管理服务器301。
要注意的是,本技术的实施方式不限于上述实施方式,并且可以在不脱离本技术的主旨的范围内进行各种改变。
例如,本技术可以采用云计算的配置,其中一个功能由多个装置经由网络来共享和协作处理。
此外,在上述流程图中描述的每个步骤可以由一个装置执行,或者也可以由多个装置共享并执行。
此外,在一个步骤中包括多个处理的情况下,一个步骤中包括的多个处理可以由一个装置执行,或者也可以由多个装置共享并执行。
说明书中描述的效果仅是示例,并不受限制,并且可以发挥其他效果。
-关于程序
上述一系列处理可以由硬件执行或者可以由软件执行。在由软件执行一系列处理的情况下,将构成软件的程序安装在并入专用硬件的计算机、通用个人计算机等中。
要安装的程序通过记录在图7示出的可移除介质22上来提供,该可移除介质22由光盘(只读致密盘存储器(CD-ROM)、数字通用盘(DVD等)、半导体存储器等构成。此外,程序可以经由有线或无线传输介质例如局域网、因特网或数字卫星广播来提供。程序也可以预先安装在ROM 12和存储单元19中。
要注意的是,由计算机执行的程序可以是其中根据说明书中描述的顺序以时间序列执行处理的程序,或者可以是其中并行执行处理或在必要的定时例如在进行调用时执行处理的程序。
-关于组合
本技术还可以采用以下配置。
(1)一种再现装置,包括:
获取单元,其获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的所述声音数据的渲染参数的内容;以及
渲染单元,其基于针对所选择的预定的假定收听位置的渲染参数来渲染所述声音数据,并输出声音信号。
(2)根据(1)所述的再现装置,其中,所述内容还包括关于预先设置的假定收听位置的信息,并且
所述再现装置还包括显示控制单元,所述显示控制单元基于关于假定收听位置的所述信息使得用于选择假定收听位置的画面被显示。
(3)根据(1)或(2)所述的再现装置,其中,针对假定收听位置中的每一个的渲染参数包括表示所述音频对象被定位的位置的定位信息和作为用于所述声音数据的增益调整的参数的增益信息。
(4)根据(1)至(3)中任一项所述的再现装置,其中,所述渲染单元基于与针对所选择的假定收听位置的渲染参数不同的渲染参数,对被选择作为其声源位置固定的音频对象的音频对象的声音数据进行渲染。
(5)根据(1)至(4)中任一项所述的再现装置,其中,所述渲染单元不对构成所述内容的声音的多个音频对象中的预定音频对象的声音数据进行渲染。
(6)根据(1)至(5)中任一项所述的再现装置,还包括生成单元,所述生成单元基于针对假定收听位置的渲染参数,针对为其未准备渲染参数的假定收听位置生成所述音频对象中的每一个的渲染参数,
其中,所述渲染单元通过使用由所述生成单元生成的渲染参数来渲染所述音频对象中的每一个的声音数据。
(7)根据(6)所述的再现装置,其中,所述生成单元基于针对为其准备了渲染参数的多个附近的假定收听位置的渲染参数,针对为其未准备所述渲染参数的假定收听位置生成所述渲染参数。
(8)根据(6)所述的再现装置,其中,所述生成单元基于在过去获取的所述内容中包括的渲染参数,针对为其未准备渲染参数的假定收听位置生成所述渲染参数。
(9)根据(6)所述的再现装置,其中,所述生成单元通过使用估计器来针对为其未准备渲染参数的假定收听位置生成所述渲染参数。
(10)根据(9)所述的再现装置,其中,所述获取单元获取与记录所述内容的场所相对应的所述估计器,以及
所述生成单元通过使用由所述获取单元获取的所述估计器来生成所述渲染参数。
(11)根据(9)或(10)所述的再现装置,其中,通过至少使用在过去获取的所述内容中包括的渲染参数进行学习来构成所述估计器。
(12)根据(1)至(11)中任一项所述的再现装置,其中,所述内容还包括用于显示来自作为视点位置的假定收听位置的图像的视频数据,并且
所述再现装置还包括视频再现单元,所述视频再现单元再现所述视频数据并使来自作为视点位置的所选择的预定的假定收听位置的图像被显示。
(13)一种再现方法,包括以下步骤:
获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的所述声音数据的渲染参数的内容;以及
基于针对所选择的预定的假定收听位置的渲染参数来渲染所述声音数据,并输出声音信号。
(14)一种使计算机执行处理的程序,所述处理包括以下步骤:
获取包括音频对象中的每一个的声音数据和针对多个假定收听位置中的每一个的所述声音数据的渲染参数的内容;以及
基于针对所选择的预定的假定收听位置的渲染参数来渲染所述声音数据,并输出声音信号。
(15)一种信息处理装置,包括:
参数生成单元,其针对多个假定收听位置中的每一个生成音频对象中的每一个的声音数据的渲染参数;以及
内容生成单元,其生成包括所述音频对象中的每一个的声音数据和所生成的渲染参数的内容。
(16)根据(15)所述的信息处理装置,其中,所述参数生成单元还生成关于预先设置的假定收听位置的信息,并且
所述内容生成单元生成还包括关于假定收听位置的所述信息的所述内容。
(17)根据(15)或(16)所述的信息处理装置,还包括视频生成单元,所述视频生成单元生成用于显示来自作为视点位置的假定收听位置的图像的视频数据,
其中,所述内容生成单元生成还包括所述视频数据的所述内容。
(18)根据(15)至(17)中任一项所述的信息处理装置,还包括生成估计器的学习单元,所述估计器用于在除了针对其生成所述渲染参数的所述多个假定收听位置以外的位置被设置为收听位置的情况下,生成所述渲染参数。
(19)根据(18)所述的信息处理装置,还包括提供单元,所述提供单元将所述估计器提供至再现所述内容的再现装置。
(20)一种信息处理方法,包括以下步骤:
针对多个假定收听位置中的每一个生成音频对象中的每一个的声音数据的渲染参数;以及
生成包括所述音频对象中的每一个的声音数据和所生成的渲染参数的内容。
附图标记列表
1 再现装置
33 音频再现单元
51 渲染参数选择单元
52 对象数据存储单元
53 视点信息显示单元
54 渲染单元
- 还没有人留言评论。精彩留言会获得点赞!