一种具有语音交互功能的健康服务智能机器人的制作方法
本发明涉及机器人技术领域,具体涉及一种具有语音交互功能的健康服务智能机器人。
背景技术:
随着我国国民经济的快速发展,人民生活水平的提高,我国人口老龄化逐步加深,同时社会的发展导致当今社会竞争的加剧,亚健康人群也快速增加,老龄人口增长、平均寿命延长也促使了亚健康人群、慢性病人群的增长,随着我国人口老龄化的进一步加深,空巢老人和独居老人人口也呈上升趋势,健康服务日益成为人们眼中的关键焦点。
为了应对我国以上社会形势,迫切需要针对亚健康、慢性病和中老年人群,能够提供健康、医疗和服务等方面的服务。
技术实现要素:
针对上述问题,本发明提供一种具有语音交互功能的健康服务智能机器人。
本发明的目的采用以下技术方案来实现:
一种具有语音交互功能的健康服务智能机器人,该健康服务智能机器人包括:机器人本体和设置在机器人本体上的人工智能模块和健康服务模块;所述人工智能模块,用于与用户进行语音交互,以获取用户的健康服务需求,并将用户的健康服务需求发送至所述健康服务模块;所述健康服务模块,用于根据接收到的用户的健康服务需求提供相应的健康服务;所述健康服务需求包括:血压检测、心率检测、血氧检测、体温检测、胎心监测、ces治疗、雾化治疗和健康氧疗中的一种或者多种。
优选地,该健康服务智能机器人还包括与所述人工智能模块连接的身份识别装置,所述身份识别装置用于采集用户人脸图像并确定用户身份,当识别结果显示用户具有操作所述健康服务智能机器人的权限时,则发送控制信息至所述人工智能模块,控制所述人工智能模块启动;所述身份识别装置包括感应器、视觉传感器和识别模块;所述感应器,用于感应是否有用户接近;所述视觉传感器,用于当所述感应器感应到用户接近时,采集用户人脸图像;所述识别模块,用于对采集的用户人脸图像进行识别以确认用户身份,当识别结果显示用户具有操作所述健康服务智能机器人的权限时,则发送控制信息至所述人工智能模块,控制所述人工智能模块启动。
优选地,所述身份识别装置还包括数据库,所述数据库与所述识别模块连接,所述数据库中用于存储有操作健康服务智能机器人权限的人员的人脸特征信息。
优选地,所述人工智能模块包括语音采集子模块、语音理解子模块和语音输出子模块;所述语音采集子模块,用于采集用户的语音信息;所述语音理解子模块,用于对所述用户语音信息进行语句识别和语义理解,以获取用户的健康服务需求;所述语音输出子模块,用于将用户的健康服务需求发送至所述健康服务模块。
优选地,所述健康服务模块包括健康处理单元、检测单元和治疗单元;所述健康处理单元,用于根据接收到的用户的健康服务需求,控制所述检测单元对用户进行心率检测、血氧检测、胎心检测、血压检测和体温检测;或控制所述治疗单元对用户进行ces治疗、雾化治疗和健康氧疗。
优选地,所述检测单元包括心率检测仪、血氧仪、胎心监测仪、血压计和体温计。
优选地,所述治疗单元包括ces治疗仪、雾化器和氧疗仪。
本发明的有益效果为:本发明的健康服务智能机器人通过与用户进行语音交互,以获取用户的健康服务需求,进而通过健康服务模块为用户提供主动式的健康服务。该健康服务智能机器人本体上收纳有多种健康服务设备,可实现用户的多且全面的健康服务需求。
附图说明
利用附图对本发明作进一步说明,但附图中的实施例不构成对本发明的任何限制,对于本领域的普通技术人员,在不付出创造性劳动的前提下,还可以根据以下附图获得其它的附图。
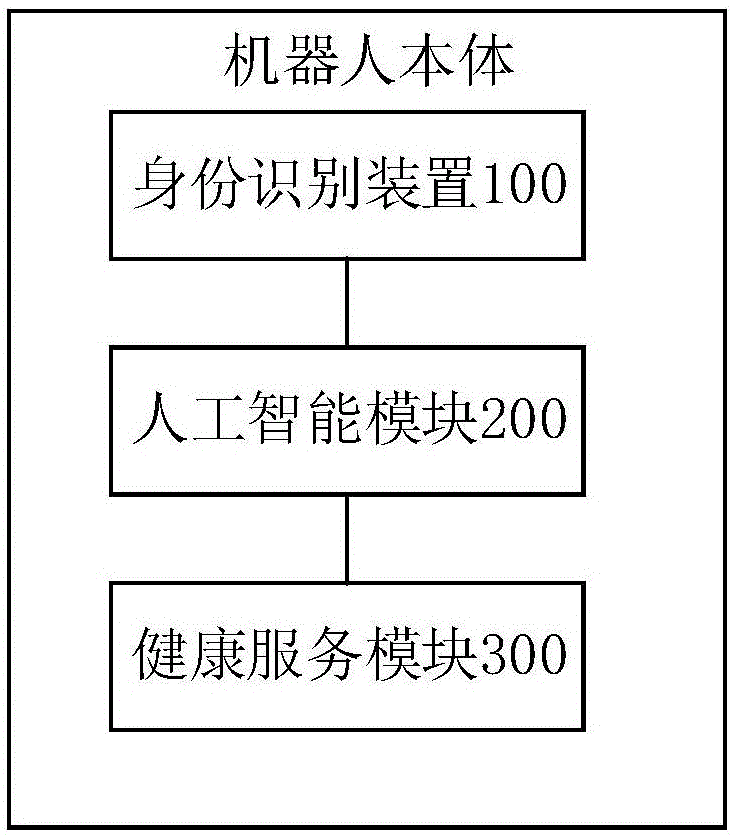
图1是本发明的健康服务智能机器人结构示意图;
图2是本发明的健康服务智能机器人的身份识别装置的结构示意图;
图3是本发明的健康服务智能机器人的人工智能模块的结构示意图;
图4是本发明的健康服务智能机器人的健康服务模块的结构示意图;
图5是本发明的健康服务智能机器人的检测单元的结构示意图;
图6是本发明的健康服务智能机器人的治疗单元的结构示意图;
图7是本发明的健康服务智能机器人的语音理解子模块的结构示意图。
附图标记:身份识别装置100;人工智能模块200;健康服务模块300;感应器110;视觉传感器120;识别模块130;数据库140;语音采集子模块210;语音理解子模块220;语音输出子模块230;健康处理单元310;检测单元320;治疗单元330;心率检测仪321;血氧仪322;胎心监测仪323;血压计324;体温计325;ces治疗仪331;雾化器332;氧疗仪333;语音检测单元221;语音降噪单元222;语音理解单元223。
具体实施方式
结合以下实施例对本发明作进一步描述。
图1示出了一种具有语音交互功能的健康服务智能机器人,该健康服务智能机器人包括:机器人本体和设置在机器人本体上的人工智能模块200和健康服务模块300;所述人工智能模块100,用于与用户进行语音交互,以获取用户的健康服务需求,并将用户的健康服务需求发送至所述健康服务模块300;所述健康服务模块300,用于根据接收到的用户的健康服务需求提供相应的健康服务;所述健康服务需求包括:血压检测、心率检测、血氧检测、体温检测、胎心监测、ces治疗、雾化治疗和健康氧疗中的一种或者多种。
优选地,该健康服务智能机器人还包括与所述人工智能模块200连接的身份识别装置100,所述身份识别装置100用于采集用户人脸图像并确定用户身份,当识别结果显示用户具有操作所述健康服务智能机器人的权限时,则发送控制信息至所述人工智能模块100,控制所述人工智能模块200启动。参见图2,所述身份识别装置100包括感应器110、视觉传感器120和识别模块130;所述感应器110,用于感应是否有用户接近;所述视觉传感器120,用于当所述感应器110感应到用户接近时,采集用户人脸图像;所述识别模块130,用于对采集的用户人脸图像进行识别以确认用户身份,当识别结果显示用户具有操作所述健康服务智能机器人的权限时,则发送控制信息至所述人工智能模块200,控制所述人工智能模块200启动。
优选地,所述身份识别装置还100包括数据库140,所述数据库140与所述识别模块130连接,所述数据库140中用于存储有操作健康服务智能机器人权限的人员的人脸特征信息。具体地,所述识别模块130对采集的用户人脸图像进行处理,提取用户人脸特征信息,并与数据库140预存的具有操作所述健康服务智能机器人的权限的人员的人脸特征信息进行匹配,若匹配度大于设定的阈值,则匹配成功,然后发送控制信息至所述人工智能模块100,人工智能模块100接收到控制信息,然后与用户进行语音交互。
优选地,参见图3,所述人工智能模块200包括语音采集子模块210、语音理解子模块220和语音输出子模块230;所述语音采集子模块210,用于采集用户的语音信息;所述语音理解子模块220,用于对所述用户语音信息进行语句识别和语义理解,以获取用户的健康服务需求;所述语音输出子模块230,用于将用户的健康服务需求发送至所述健康服务模块300。
优选地,参见图4,所述健康服务模块300包括健康处理单元310、检测单元320和治疗单元330;所述健康处理单元310,用于根据接收到的用户的健康服务需求,控制所述检测单元320对用户进行心率检测、血氧检测、胎心检测、血压检测和体温检测;或控制所述治疗单元330对用户进行ces治疗、雾化治疗和健康氧疗。
优选地,参见图5,所述检测单元320包括心率检测仪321、血氧仪322、胎心监测仪323、血压计324和体温计325。
优选地,参见图6,所述治疗单元330包括ces治疗仪331、雾化器332和氧疗仪333。
本发明的有益效果为:本发明的健康服务智能机器人通过与用户进行语音交互,以获取用户的健康服务需求,进而通过健康服务模块为用户提供主动式的健康服务。该健康服务智能机器人本体上收纳有多种健康服务设备,可实现用户的多且全面的健康服务需求。
优选地,参见图7,所述语音理解子模块220包括语音检测单元221、语音降噪单元222和语音理解单元223;
所述语音检测单元221,用于对用户的语音信息进行检测,以获取语音帧片段;
所述语音降噪单元222,用于对所述语音帧片段进行降噪处理;
所述语音理解单元223,用于对降噪后的语音帧进行语句识别和语义理解,以获取用户的健康服务需求。
优选地,所述对用户的语音信息进行检测,以获取语音帧片段,其实现过程是:
(1)对用户的语音信息进行分帧、加窗操作;
(2)对分帧、加窗得到的每一帧数据进行傅里叶变换,以获取对应的振幅频谱、相位谱和噪声频谱估计值;
(3)基于得到的每一帧数据的振幅频谱、噪声频谱估计值,计算每一帧数据的tae值,根据得到的tae值判断各个帧是否为语音帧,具体判断方法是:
若tae(m)<t,第m帧为噪声帧,若tae(m)≥t,第m帧为语音帧,t为设定的阈值;遍历所有帧,然后将属于语音帧的帧数据进行去窗、叠加和快速傅里叶逆变换,即可得到时域里的语音帧片段;
其中,tae值的计算公式为:
式中,tae(m)为第m帧的tae值,m=1,2,…m,m为帧个数;y(m,k)为第m帧的振幅频谱,d(m,k)为噪声频谱估计值,k表示第k个频点,其满足k=1,2,…,k。
有益效果:上述实施例中将用户的语音信息进行分帧、加窗和傅里叶变换后,根据得到的各个帧数据对应的振幅频谱、相位谱和噪声频谱估计值,求出各个帧的tae值,然后将得到的tae值与预设的阈值进行比较,进而完成对当前帧是否属于语音帧的判断,在求解tae值不仅考虑了当前帧的振幅频谱和噪声频谱估计值的影响,而且能够根据各个帧的振幅频谱和噪声频谱估计值实现对各个帧是否属于语音帧的自适应判断,提高了该语音检测单元221的鲁棒性,降低了后续语音降噪单元222和语音理解单元223的工作负担,并提高了语音降噪单元222和语音理解单元223的工作效率,即只需对检测出来的语音帧片段分析即可,进而提高了语音理解子模块220的工作效率。
在一个具体的实施例中,各个帧的噪声频谱估计值可通过下述过程进行估算:
(1)基于分帧、加窗、傅里叶变换后的用户的语音信息,根据前十帧数据获取噪声频谱的初始估计值;
(2)利用下方的分段函数对噪声频谱估计值进行更新:
式中,d(m,k)为第m帧的噪声频谱估计值,y(m,k)为第m帧的振幅频谱,d0为噪声频谱的初始估计值,d(m-1,k)为第(m-1)帧的噪声频谱估计值,α1为平滑因子,其取值范围是:
有益效果:通常一段语音信号的前十帧只包含噪声帧,利用前十帧数据得到噪声频谱的初始估计值,然后基于得到噪声频谱的初始估计值、当前帧以及其上一帧的振幅频谱对当前帧的噪声频谱估计值进行更新,得到更新后的各个帧的噪声频谱估计值,该算法能够自适应的实现对各个帧的噪声频谱估计值的更新,提高了后续对语音帧检测的鲁棒性,有利于对语音帧片段的准确检测。
优选地,所述的对所述语音帧片段进行降噪处理,具体是:
(1)对所述语音帧片段进行分帧、加窗和傅里叶逆变换,获取相应帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱;
(2)基于得到的每一帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱,计算每一帧的噪声抑制增益因子,其中第n帧噪声抑制增益因子的计算公式为:
式中,g(n)为第n帧的噪声抑制增益因子,y(n,k)为第n帧的振幅频谱,d(n,k)为第n帧的噪声频谱估计值,py(n,k)为第n帧的功率谱,pd(n,k)为第n帧的噪声功率谱,γ为权重系数,η为噪声衰减因子;
(3)基于得到所述语音帧片段的噪声抑制增益因子、振幅频谱和相位谱,通过去窗、叠加和快速傅里叶逆变换,即可得到降噪后的语音帧片段。
有益效果:在上述实施例中,将从语音检测单元221得到的时域里的语音帧片段经过分帧、加窗和傅里叶变换后,并获取各个帧的振幅频谱、功率谱、噪声频谱估计值和噪声功率谱,根据自定义的噪声抑制增益因子的计算公式计算各个帧的噪声抑制增益因子,将得到的各个帧的噪声抑制增益因子与相应的振幅频谱相乘,即可得到修正后的振幅频谱。将修正后的振幅频谱及其相应的相位谱进行去窗、叠加和快速傅里叶变换,即可得到降噪后的语音帧片段,该算法通过对各个帧的振幅频谱进行修正,能够有效抑制所述语音帧片段中的随机噪声,同时增强了非噪声部分。使去噪后的语音帧片段保留语音信号中的细节特征,有利于后续对用户的语音信息进行语句识别和语义理解,获取用户的健康服务需求,进而为用户提供相应的健康服务。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!