基于多维网络的癌症细胞系治疗药物预测方法与流程
本发明属于生物信息学
技术领域:
,特别涉及一种癌症细胞系治疗药物预测方法,可用于癌症对药物的反应预测实验。
背景技术:
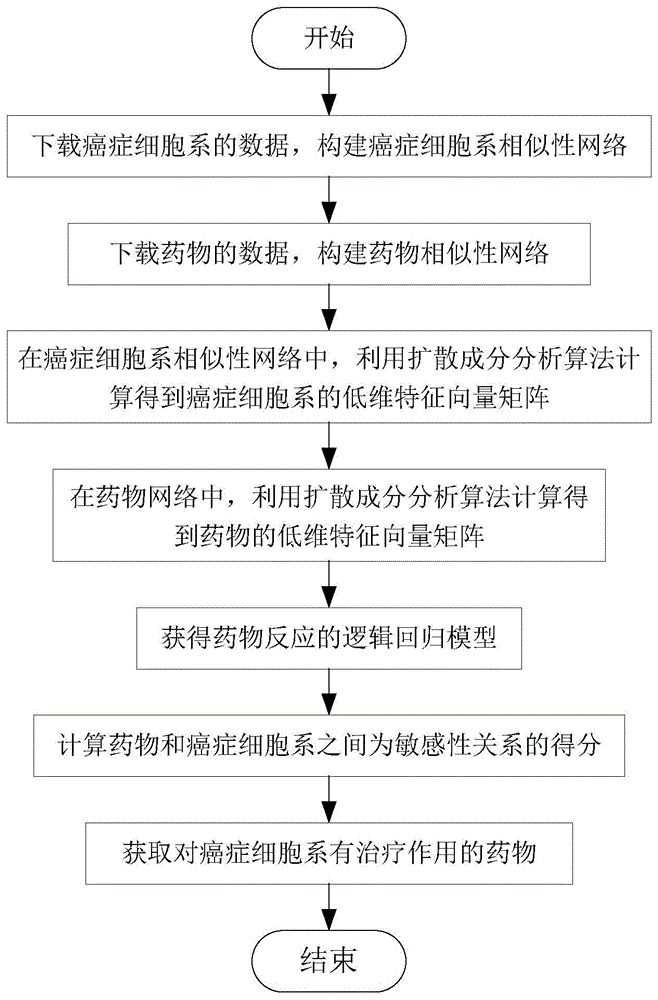
:癌症是一类复杂的异质性疾病,忽略癌症患者体内生物分子特征,仅仅依据癌症患者临床症状的传统治疗方式无法满足现代医疗治疗癌症的要求。目前,治疗癌症的主要手段是使用分子靶向药物抑制癌症的发展。精准医疗提倡的就是靶向疗法,根据癌症患者的体内分子特性选择具体的治疗方案是提高癌症治疗效果的有效途径。在动物体内移植肿瘤,然后把化合物作用于动物体内,观察动物体内肿瘤的生长变化,以此确定化合物对肿瘤的作用效果,这种研究治疗肿瘤药物的方法费用高、耗时长而且成功率低。面对这些挑战,人类癌症细胞系为预测药物反应提供了新的载体,有利于筛选治疗癌症的候选药物。原发性肿瘤细胞系的培养时间相对较短,研究人员可以快速测试药物对某种癌症的治疗是否有效,缩小治疗癌症的候选药物范围。目前用细胞系培养技术培养出的癌症细胞系能够近似的模拟癌症细胞在癌症病人体内的生长环境,癌症细胞系和癌症病人体内癌症细胞的基因表达、染色体增益或缺失以及甲基化水平具有极大的相似性,癌症细胞系能够更加准确的模拟癌症病人对药物的反应情况。通过分析癌症细胞系分子数据预测药物反应,能够提高预测药物反应的准确率。根据不同的数据和理论,目前的药物反应预测方法主要分为以下两类:一.基于机器学习的药物反应预测方法。随着机器学习理论的不断发展,使用机器学习预测药物反应的方法取得了较好的结果。此类方法的主要流程是:首先,提取癌症细胞系的基因表达谱作为特征。然后,利用药物的已知反应数据训练预测模型。最后,预测模型计算出新的药物反应。此类方法的优点是从癌症细胞系的基因表达水平进行药物反应研究,缺点是没有考虑到癌症细胞系之间的关系,没有考虑到药物之间的关系,其预测的准确率有待提高。二.基于网络的药物反应预测方法。网络能够反映节点之间的关系。已有研究发现相似的癌症细胞系对相似的药物具有相似的反应。癌症细胞系相似性网络描述了癌症细胞系之间的相似性,药物相似性网络描述了药物之间的相似性,在相似性网络中使用信息传播方法来预测药物的反应。此类方法的主要流程是:首先,基于基因表达谱构建癌症细胞系相似性网络,以及基于化学结构构建药物相似性网络,然后,将癌症细胞系和药物的已知反应映射到癌症细胞系相似性网络和药物相似性网络之间,建立癌症细胞系节点和药物节点的连边,形成异构网络,最后在异构网络中通过信息传播预测药物反应。此类方法的优点是从癌症细胞系之间以及药物之间的相似性关系进行药物反应预测研究,缺点是仅从单一层面计算癌症细胞系相似性和药物相似性,预测结果准确率有待提升。技术实现要素:本发明的目的在于针对上述现有技术存在的缺陷,提出一种基于多维网络的癌症细胞系药物反应预测方法,以提高药物反应预测结果的准确率。本发明的技术方案是:根据癌症细胞系的基因表达、基因突变及拷贝数变异数据构建癌症细胞系三维相似性网络;根据药物的靶标及化学结构特征构建药物二维相似性网络;通过在癌症细胞系三维相似网络和药物二维相似性网络中应用扩散成分分析算法,得到癌症细胞系和药物的低维特征向量;将癌症细胞系和药物的低维特征向量作为训练数据集的特征,用已知的药物反应关系作为训练数据集的标签,训练得到预测药物反应的逻辑回归模型,根据此模型来预测对药物反应敏感的癌症细胞系。其实现步骤包括如下:(1)下载癌症细胞系的数据,构建癌症细胞系相似性网络:(1a)从与癌症细胞系基因表达相关的任意一个数据库下载n个癌症细胞系和这n个癌症细胞系所对应的t个基因的表达数据,得到基因表达矩阵构建癌症细胞系基因表达相似性网络(1b)从与癌症细胞系突变相关的任意一个数据库下载n个癌症细胞系和这n个癌症细胞系所对应的p个基因的突变数据,得到突变矩阵构建癌症细胞系突变相似性网络(1c)从与癌症细胞系拷贝数变异相关的任意一个数据库下载n个癌症细胞系和这n个癌症细胞系所对应的q个基因的拷贝数变异数据,得到拷贝数变异矩阵构建癌症细胞系拷贝数变异相似性网络(2)下载药物的数据,构建药物相似性网络:(2a)从与药物化学结构相关的任意一个数据库下载m个药物的化学结构表达式数据chm,构建药物化学结构相似性网络(2b)从与药物靶标相关的任意一个数据库下载m个药物的靶标数据tam,构建药物靶标相似性网络(3)在癌症细胞系基因表达相似性网络癌症细胞系突变相似性网络和癌症细胞系拷贝数变异相似性网络中,利用扩散成分分析算法计算得到n个癌症细胞系的低维特征向量矩阵其中dc表示癌症细胞系特征向量的维度数量;(4)在药物化学结构相似性网络和药物靶标相似性网络中,利用扩散成分分析算法计算得到m个药物的低维特征向量矩阵其中dd表示药物特征向量的维度数量;(5)获得药物反应的逻辑回归模型:(5a)从癌症细胞系低维特征向量矩阵中的第i行得到第i个癌症细胞系的低维特征向量:其中,i=1,2,3,...,n;(5b)从药物低维特征向量矩阵中的第x行得到第x个药物的低维特征向量:(5c)将第i个癌症细胞系的低维特征向量和第x个药物的低维特征向量组合为联合特征向量:(5d)从与药物反应相关的任意一个数据库下载已知药物与癌症细胞系的反应关系数据;(5e)基于已知药物与癌症细胞系的反应关系数据和其对应的联合特征向量,对逻辑回归模型进行训练,得到药物反应预测模型;(6)将未知反应关系的药物与癌症细胞系所对应的联合特征向量作为药物反应预测模型的输入,计算药物和癌症细胞系之间的敏感性关系的得分;(7)判断敏感性关系得分是否大于0.5,如果是,则对应的药物对癌症细胞系有治疗作用,否则,对应的药物对癌症细胞系没有治疗效果。本发明与现有技术相比,具有以下优点:1、本发明在获取癌症细胞系特征向量时,综合了癌症细胞系的基因表达谱,基因突变和拷贝数变异分子特征,以及癌症细胞系之间的相似性关系,相对于目前方法中采用的癌症细胞系的基因表达谱,全面的考虑到癌症细胞系基因组特性对药物反应的影响,有效地提高了药物重定位的准确率。2、本发明在获取癌症细胞系特征向量时,通过使用扩散成分分析算法,不仅代表节点在网络中的拓扑结构特征,而且降低了网络带来的噪音影响,相对于目前方法中直接根据癌症细胞系相似性网络预测药物反应,进一步提高了药物反应预测的准确率。附图说明图1是本发明的实现总流程图;具体实施方式以下结合附图和具体实施例,对本发明作进一步详细描述。参照图1、本实例的实现步骤如下:步骤1,下载癌症细胞系的数据,构建癌症细胞系相似性网络:1a)构建癌症细胞系基因表达相似性网络1a1)本实例从gdsc数据库中下载955个癌症细胞系的基因表达值数据,得到基因表达矩阵mexp,基因表达矩阵mexp有955行和17738列,其中行表示癌症细胞系,列表示基因;1a2)从基因表达矩阵mexp中的第i行得到第i个癌症细胞系的基因表达特征向量:其中,i=1,2,3,...,955;1a3)从基因表达矩阵mexp中的第j行得到第j个癌症细胞系的基因表达特征向量:其中,j=1,2,3,...,955;1a4)计算上述ciexp与cjexp之间的皮尔森相关性,得到第i个癌症细胞系和第j个癌症细胞系的基因表达相似性,作为癌症细胞系基因表达相似性网络中的元素的值,得到癌症细胞系基因表达相似性网络1b)构建癌症细胞系突变相似性网络1b1)本实例从gdsc数据库中下载955个癌症细胞系的突变数据,得到突变矩阵mmut,突变矩阵mmut有955行和19015列,其中行表示癌症细胞系,列表示突变基因;1b2)从突变矩阵mmut中的第i行得到第i个癌症细胞系的突变特征向量:其中,i=1,2,3,...,955;1b3)从突变矩阵mmut的第j行得到第j个癌症细胞系的突变特征向量:其中,j=1,2,3,...,955;1b4)计算上述与之间的余弦相似性,得到第i个癌症细胞系和第j个癌症细胞系的突变相似性,作为癌症细胞系突变相似性网络中元素的值,得到癌症细胞系突变相似性网络1c)构建癌症细胞系拷贝数变异相似性网络1c1)本实例从gdsc数据库中下载955个癌症细胞系的拷贝数变异数据,得到拷贝数变异矩阵mcnv,拷贝数变异矩阵mcnv矩阵有955行和798列,其中行表示癌症细胞系,列表示基因片段;1c2)从拷贝数变异矩阵mcnv中的第i行得到第i个癌症细胞系的拷贝数变异特征向量:其中,i=1,2,3,...,955;1c3)从拷贝数变异矩阵mcnv中的第j行得到第j个癌症细胞系的拷贝数变异特征向量:其中,j=1,2,3,...,955;1c4)计算上述cicnv与cjcnv之间的斯皮尔曼相关性得到第i个癌症细胞系和第j个癌症细胞系的拷贝数变异相似性,作为癌症细胞系拷贝数变异相似性网络中元素的值,得到癌症细胞系拷贝数变异相似性网络步骤2,下载药物的数据,构建药物相似性网络。2a)构建药物化学结构相似性网络2a1)本实例从pubchem下载219个药物的化学结构表达式数据ch219;2a2)使用padel工具将药物的化学结构表达式数据ch219转换为化学结构分子特征,得到化学结构矩阵mchem,化学结构矩阵mchem有219行和1024列,行表示药物,列表示化学结构分子特征;2a3)从化学结构矩阵mchem中的第x行得到第x个药物的化学结构分子特征向量:其中,x=1,2,3,...219;2a4)从化学结构矩阵mchem中的第y行得到第y个药物的化学结构分子特征向量:其中,y=1,2,3,...219;2a5)计算上述与之间的皮尔森相关性得到第x个药物和第y个药物的相似性,作为药物化学结构相似性网络中元素的值,得到药物化学结构相似性网络2b)构建药物靶标相似性网络2b1)本实例从gdsc数据库下载219个药物的靶标数据ta219;2b2)从药物的靶标数据ta219中,得到第x个药物的靶标集合:sx=(g1,g2,...gk),其中k表示第x个药物的靶标数量,其中,x=1,2,3,...219;2b3)从药物的靶标数据ta219中,得到第y个药物药物的靶标集合:sy=(g1,g2,...gh),其中h表示第y个药物的靶标数量,其中,y=1,2,3,...219;2b4)通过smith-waterman算法计算第x个药物的靶标集合sx和第y个药物的靶标集合sy中的元素对之间的序列相似性,得到k×h个序列相似性值,其中最大的序列相似性值是第x个药物和第y个药物的相似性,作为药物靶标相似性网络中元素的值,得到药物靶标相似性网络步骤3,获得955个癌症细胞系的低维特征向量矩阵3a)在癌症细胞系各网络中,以第i个癌症细胞系节点为种子进行游走,得到第i个癌症细胞系扩散状态其中l=1,2,3分别表示癌症细胞系表达相似性网络癌症细胞系突变相似性网络和癌症细胞系拷贝数变异相似性网络3b)基于癌症细胞系扩散状态计算癌症细胞系低维特征向量矩阵即通过如下公式求解得到:其中,ficell是癌症细胞系低维特征向量矩阵的第i行,表示第i个癌症细胞系节点的特征向量,由955个癌症细胞系节点的特征向量组成癌症细胞系低维特征向量矩阵表示第i个癌症细胞系在第l个癌症细胞系网络中的上下文特征向量,dkl表示kl散度函数。步骤4,获得219个药物的低维特征向量矩阵4a)在药物各网络中,以第x个药物节点为种子进行游走,得到第x个药物扩散状态其中r=1,2分别表示药物化学结构相似性网络和药物靶标相似性网络4b)基于药物扩散状态计算药物低维特征向量矩阵即通过如下公式求解得到:其中,是药物低维特征向量矩阵的第x行,表示第x个药物节点的特征向量,由219个药物节点的特征向量组成药物低维特征向量矩阵表示第x个药物在第r个网络中的上下文特征向量,dkl表示kl散度函数。步骤5,获得药物反应的逻辑回归模型。5a)从癌症细胞系低维特征向量矩阵中的第i行得到第i个癌症细胞系的低维特征向量:其中,i=1,2,3,...,955;5b)从药物低维特征向量矩阵中的第x行得到第x个药物的低维特征向量:其中,x=1,2,3,...,219;5c)将第i个癌症细胞系的低维特征向量和第x个药物的低维特征向量组合为联合特征向量:5d)本实例以gdsc数据库为例,从gdsc数据库下载21346个已知药物与癌症细胞系的敏感性关系数据;5e)通过逻辑回归模型进行训练,得到药物反应预测模型:5e1)将已知药物与癌症细胞系的治疗关系作为正样本数据集sp;5e2)将未知药物与癌症细胞系的反应关系作为负样本数据集sn;5e3)基于正样本数据sp、负样本数据sn和联合特征向量f,通过如下公式求解逻辑回归模型中的参数向量z:其中,cadb表示正样本数据元素,表示正样本数据元素cadb的联合特征向量,ca'db'表示负样本数据元素,表示负样本数据元素ca'db'的联合特征向量;5e4)基于训练得到的参数向量z,得到药物反应预测模型:其中,i表示第i个癌症细胞系,x表示第x个药物,表示第i个癌症细胞系和第x个药物的联合特征向量,logit(i,x)表示第i个癌症细胞系和第x个药物之间的敏感性关系得分。步骤6,将未知反应关系的药物与癌症细胞系所对应的联合特征向量作为药物反应预测模型的输入,得到药物和癌症细胞系之间的敏感性关系得分。步骤7,判断敏感性关系得分是否大于0.5,如果是,则对应的药物对癌症细胞系有治疗作用,否则,对应的药物对癌症细胞系没有治疗效果。以下结合仿真实验,对本发明的技术效果作进一步说明:1.仿真条件仿真实验在intel(r)core(tm)i7-8700kcpu、主频3.70ghz,内存48g,ubuntu平台上的matlabr2018a上进行。2.仿真内容与结果为了证明本发明能够预测治疗癌症的候选药物,以gdsc数据库和pubchem数据库作为实施例对治疗癌症的候选药物结果进行仿真实验,对药物和癌症细胞系之间的敏感性关系得分按照从大到小排名后,并对敏感性得分排名前5的预测结果进行验证,其结果如表1所示。表1药物名称癌症细胞系名称癌症细胞系类型敏感性关系得分排名文献pmidrefametinibgakmelanoma119706763sorafenibhl-60acute_myeloid_leukaemia229983847sunitinib1nomo-1acute_myeloid_leukaemia323969938fedratinibem-2leukemia426833125crizotinibme-1acute_myeloid_leukaemia527494825表1中的文献pmid表示pubmed数据库中的文献索引号。从表1可以看出,仿真实验预测结果排名前5的敏感性关系已经被现有的文献所验证,说明了本发明方法的准确率高。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1