一种中医医案数据挖掘的方法与流程
本发明涉及中医学领域,尤其涉及一种中医医案数据挖掘的方法。
背景技术:
中医医案也即是病案,是医生治疗疾病时辩证、立法、处方用药的连续记录。医案记录了中医临床大夫试试辩证论治的过程,反映了医家的思维活动、学术观点以及丰富的临床经验,为中医药理论的创新与发展提供了宝贵的研究素材。对医案进行研究,并从医案中学习相关知识,不仅能丰富和深化理论知识,而且可以提高临床诊疗水平,开阔视野,启迪思路。因此,医案对于从事中医临床、教学和科研工作者来说,在中医临床研究和实践方面具有重大的指导意义。
但中医医案中存在着一些术语表达模糊、称谓繁以及含义不明确,使得中医医案的数据挖掘存在着效率低、应用不广泛等情况。因此,建立高效、科学的中医医案数据库并使用对海量医案数据进行挖掘,是目前待解决的问题。
技术实现要素:
针对上述存在的问题,本发明旨在提供一种中医医案数据挖掘的方法,能够拓宽数据挖掘技术在中医药领域的应用,为相关产业的发展提供支持。
为了实现上述目的,本发明所采用的技术方案如下:
一种中医医案数据挖掘的方法,其特征在于,包括以下步骤:
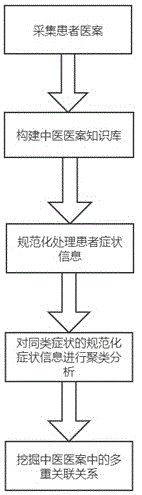
s1:采集海量患者医案;
s2:构建基于粒计算的中医医案知识库;
s3:采用信息抽取算法对所述中医医案知识库文档中记载的患者症状信息进行规范化处理;
s4:通过文本聚类算法对同一类症状的规范化患者症状信息进行聚类分析;
s5:通过关联规则挖掘算法挖掘中医医案中的症状与方药,症状与证型,证型与方药之间以及中药配伍之间的多重关联关系。
进一步地,步骤s2中所述的构建基于粒计算的中医医案知识库的具体步骤包括:
s21:构建中医医案的概念集;
s22:结合所述概念集,使用汉语词法分析系统ictclas分词系统对中医医案进行分词;
s23:对中医医案数据进行合适的粒化,并对粒子进行合成和分解;
s24:通过基于粒计算的概念获取算法及关系抽取算法对本体概念及关系的提取;
s25:将提取后的本体概念组成知识库。
进一步地,步骤s21中构建中医医案的概念集的具体步骤包括:
s211:将由概念产生的相关概念定为概念集、概念、术语集、术语,且它们之间的关系如公式(1)所示,用于表示同一术语对于不同概念的集合:
其中,
s212:采用公式(2)设定其阈值,并通过优化所述阈值,构建中医医案的概念集,公式(2)表示为:
其中,dmdt,k为术语tt,k对于dk的领域隶属度,cft,k为dk的领域特征词,0≤α≤1,其中α为控制
进一步地,步骤s3中所述的信息抽取算法采用的是基于语义特征分析进行处理,其具体步骤包括:
s31:结合语义词典和中医医案知识库进行语义消歧和同义词合并;
s32:采用消除冗余模块对中医医案中的句子进行冗余消除。
进一步地,所述消除冗余模块是基于句子相似度进行的,所述句子相似度进行迭代更新的计算公式(2)为:
其中,r(a,b)为a,b为两个比较的对象的相似度,c是个阻尼系数,为常数,c∈[0,1];如果a≠b,并且a或b没有邻居,则r(a,b)=0。
进一步地,步骤s4中的文本聚类算法采用文本聚类技术,基于语义的文本相似度量,结合本体的中医医案知识库,根据文本相似度公式对同一症状患者信息进行分析,其具体步骤包括:
s41:将中医医案知识库中医案文档集合划分成簇;
s42:将相似症状的规范化的患者症状信息分为一簇;
s43:采用向量空间模型表示每个患者的症状信息;
s44:构建基于症状信息的特征矩阵;
s45:使用余弦距离度量文本之间的相似度,通过改进的k-means算法修正聚类中心,减少迭代次数,输出最优聚类结果。
进一步地,步骤s5的中所述的关联规则挖掘算法,基于本体的中医医案知识库来挖掘中医医案中症状、方药之间、证型之间的多重关联关系。
本发明的有益效果是:
1、粒计算是信息处理的一种新的概念和计算范式,本发明中考虑到中医医案概念术语存在着表述模糊、称谓繁杂以及含义不明确等中医医案数据特点,通过基于粒计算的概念获取算法以及概念间多层关联关系抽取构建中医医案知识库,进而为后续的数据挖掘奠定了基础;
2、本发明中在患者症状信息进行规范化处理时提出了信息抽取的概念。传统信息抽取采用基于浅层特征分析和语义特征分析的句子抽取算法抽取文摘句,而由于中医医案的数据特点,采用这种传统方式易使结果产生歧义,因此本发明中采用基于语义特征分析进行处理,结合中医医案知识库,提出语义消歧和同义词合并策略,有效提高了患者症状信息处理的规范化和准确率;
3、由于海量中医医案数据结构的复杂性,本发明通过研究关联规则的最新动态,将群智优化算法以及粒计算用于中医用药规律的数据挖掘,建立群智能优化算法与关联规则挖掘的对应关系,并为解决群智能算法易陷入局部最优的问题,提出了一种带有小概率的规范知识引导的扰动策略,增强算法跳出局部最优的能力,提高算法的运行效率,从而使用本发明中的挖掘算法能够有效减少冗余,提高算法完成的时效性;
综上所述,本发明在收集大量医案的基础上构建基于粒计算的中医医案知识库,研究通过关联规则挖掘算法、聚类分析,对中医医案进行高效的数据挖掘,解决由于海量中医医案中存在的属于表述模糊、繁杂以及因之带来数据挖掘算法效率低及应用不广泛等问题。拓宽数据挖掘技术在中医药领域的应用,为促进相关产业的发展提供理论和技术支持。
附图说明
图1为本发明提供的一种中医医案数据挖掘的方法的流程图。
具体实施方式
为了使本领域的普通技术人员能更好的理解本发明的技术方案,下面结合实施例对本发明的技术方案做进一步的描述。
参考附图1可以看出,一种中医医案数据挖掘的方法,包括以下步骤:
s1:以心血管医案为例,通过人工整理、网络平台等方式,收集心血管患者医案1万份,同时建立中医医案术语词典、中药同义词典、症状同义词词典、证型同义词词典、停用词词典、中药性味归经词典;
s2:构建基于粒计算的中医医案知识库;
s3:采用信息抽取算法对所述中医医案知识库文档中记载的患者症状信息进行规范化处理,用于在提高规范化的准确率的基础上提高效率;
s4:通过文本聚类算法对同一类症状患者进行分析,用于实现症状与证型之间辩证规律的研究;
s5:通过关联规则挖掘算法挖掘中医医案中的症状与方药,症状与证型,证型与方药之间以及中药配伍之间的多重关联关系。
进一步地,步骤s2中所述的构建基于粒计算的中医医案知识库的具体步骤包括:
s21:构建中医医案的概念集,概念集是构建知识库的基础,决定着构建完成后的本体能否完整地描述该中医医案的概念模型;
s22:结合所述概念集,使用汉语词法分析系统ictclas分词系统对中医医案进行分词;
s23:对中医医案数据进行合适的粒化,并对粒子进行合成和分解;
s24:通过基于粒计算的概念获取算法及关系抽取算法对本体概念及关系的提取;
s25:将提取后的本体概念组成知识库。
进一步地,步骤s21中构建中医医案的概念集的具体步骤包括:
s211:将由概念产生的相关概念定为概念集、概念、术语集、术语,且它们之间的关系如公式(1)所示,用于表示同一术语对于不同概念的集合:
其中,
s212:采用公式(2)设定其阈值,并通过优化所述阈值,构建中医医案的概念集,其中,阈值的设定是构建概念集合的关键,所述公式(2)表示为:
其中,dmdt,k为术语tt,k对于dk的领域隶属度,cft,k为dk的领域特征词,0≤α≤1,其中α为控制
即就是以中医医案文本集为前景语料集,以非中医医医案文本集为背景语料集,通过优化阈值公式(2)的阈值,构建中医医案的概念集。
进一步地,传统信息抽取采用基于浅层特征分析和语义特征分析的句子抽取算法抽取文摘句,易出现歧义,而本发明步骤s3中所述的信息抽取算法采用的是基于语义特征分析进行处理,其具体步骤包括:
s31:结合语义词典和中医医案知识库对中医医案进行语义消歧和同义词合并;
s32:采用消除冗余模块对中医医案中的句子进行冗余消除。
进一步地,所述消除冗余模块是基于句子相似度进行的,所述句子相似度进行迭代更新的计算公式(2)为:
其中,r(a,b)为a,b为两个比较的对象的相似度,c是个阻尼系数,为常数,c∈[0,1];如果a≠b,并且a或b没有邻居,则r(a,b)=0。
文本聚类技术是指将文档集合划分成簇,使同一簇内的文档尽可能相似,而簇与簇之间的相似性尽可能小。对规范化的患者症状信息进行聚类分析,把相似的患者症状信息分为一簇,分析其症状与证型之间辩证规律。
通过文本聚类技术研究症状与证型之间辩证规律时,对文本相似度量方法的设计是本环节的关键技术。传统的文本相似度量方法大多采用tf-idf方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度,这些方法忽略了文本中词项的语义信息,本研究采用基于语义的文本相似度量方法,借助于基于本体的中医医案知识库,在传统词频向量中扩充了语义相似的词项,进一步增加了症状文本表示向量的维度,最后利用文本相似度对症状信息进行聚类分析。
进一步地,步骤s4中的文本聚类算法采用文本聚类技术,基于语义的文本相似度量,结合本体的中医医案知识库,根据文本相似度公式对同一症状患者信息进行分析,其具体步骤包括:
s41:将中医医案知识库中医案文档集合划分成簇;
s42:将相似症状的规范化的患者症状信息分为一簇;
s43:采用向量空间模型(vectorspacemodel,vsm)表示每个患者的症状信息;
s44:构建基于症状信息的特征矩阵;
s45:使用余弦距离度量文本之间的相似度,通过改进的k-means算法修正聚类中心,减少迭代次数,输出最优聚类结果。
进一步地,步骤s5的中所述的关联规则挖掘算法,基于本体的中医医案知识库来挖掘中医医案中症状、方药之间、证型之间的多重关联关系。
通过关联规则挖掘算法对患者医案中的症状、证型、方药之间的相互关系挖掘时,提高时间效率及空间效率,减少冗余现象是本发明中的关键解决问题。通过研究关联规则的最新动态,把群智优化算法及粒计算用于中医药规律的数据挖掘;
实施例:
首先,从门诊医案系统中收集、整理名老中医医案里心血管患者医案1万份;
其次,利用收集到的心血管患者医案来构建基于粒计算的中医医案知识库,然后采用信息抽取算法对中医医案知识库中的医案进行规范化处理,得到规范化的患者医案信息;
再次,通过文本聚类算法对同心血管症状的规范化后的患者信息进行聚类分析,剖析了名老中医用药规律和经验;
最后,通过关联规则挖掘算法挖掘其症状与方药,症状与证型,证型与方药之间以及中药配伍之间的多重关联关系,通过得出的关联关系获取有效方剂,用于治疗患者以及为中成药的组方提供指导。
综上所述,本发明通过中医医案数据挖掘算法,从名老中医医案收集、整理、规范化处理到数据挖掘、经验规则挖掘整个流程中,充分利用规范化门诊医案文本资料的基础上,深度剖析了名老中医用药规律和经验,获取有效经验方剂,为中成药的组方提供指导,开发中成药及院内制剂,创造经济效益。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!