外科患者术后恢复状态预测模型构建方法
本发明涉及医疗技术领域,具体涉及一种外科患者术后恢复状态预测模型构建方法。
背景技术:
现有技术中没有一种针对术后患者的恢复状态的有效评估方法,不便于对患者的恢复状态进行预测。
技术实现要素:
为了解决上述现有技术中存在的技术问题,本发明公开了一种外科患者术后恢复状态预测模型构建方法,以便于对术后患者的恢复状态进行预测。
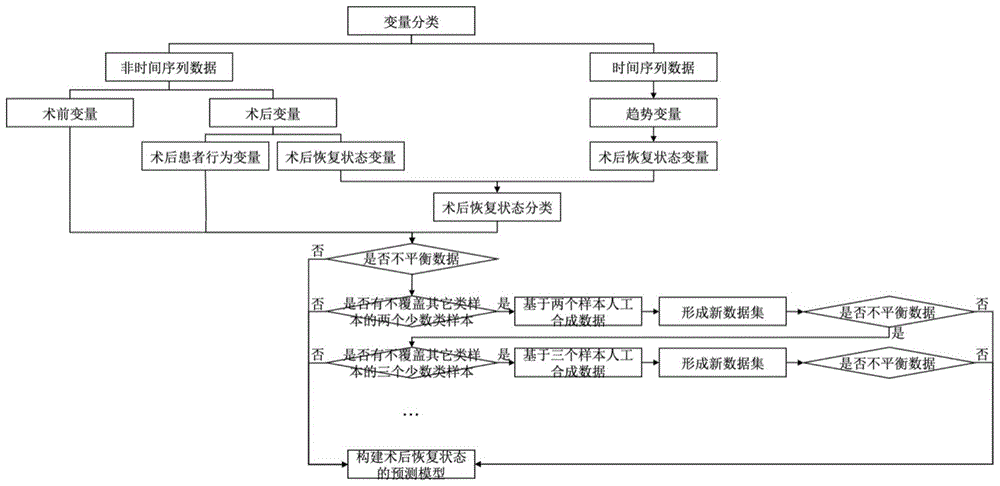
本发明外科患者术后恢复状态预测模型构建方法,包括以下步骤:
步骤一:采集时间序列变量以及非时间序列变量,将时间序列变量转化为趋势变量,步骤具体如下:
(1)计算在相邻数据采集时间(t-1和t)之间每一类时间序列变量xi=(xi,t1,xi,t2,...,xi,tj,...)的变化量,i表示时间序列变量类型,
(2)确定每一个时间序列变量在各时间的趋势变量tri,t取值,如果变化量为负值,则相应的趋势变量取值-1;如果变化量为非负值,则相应的趋势变量取值1,
步骤二:利用趋势变量和指标的正常范围确定每个指标的术后恢复状态变量,具体如下:
(1)判断在每一个数据采集时刻,每一个趋势变量的取值是否在相应的指标正常范围之间,如果在正常范围之间,则指标变量取值1;反之,则指标变量取值0,
(2)根据临床诊疗标准、趋势变量是否在指标正常范围内,确定每位患者在各个指标的术后恢复状态变量ii取值;如果趋势变量均为-1或者趋势变量先升高再下降,并且最后一个数据采集时刻趋势变量的取值在指标正常范围内,则该患者指标术后恢复较好,术后恢复状态变量记为1;如果最后两个数据采集时刻趋势变量的取值都在指标正常范围内,那么这位患者指标术后恢复较好,术后恢复状态变量记为1;如果3个趋势变量皆为-1,但最后一个数据采集时刻趋势变量的取值不在指标正常范围内,那么这位患者的指标术后恢复一般,术后恢复状态变量记为0;其他情况,例如趋势变量出现波动和反复、数值升高,说明这位患者的术后恢复差,术后恢复状态变量记为-1。
步骤三:
利用支持向量机(svm)算法,根据所有时间序列变量转化的术后恢复状态变量和非时间序列变量中除下床活动次数、下床活动时长截止术后3天外的其他变量,对患者的术后恢复状态变量进行分类:
步骤四:以术后恢复状态分类为因变量,以所有非时间序列中的术前变量、(术后患者行为变量)术后下床活动次数和术后下床活动时长截止术后3天为自变量,利用随机森林算法,构建预测模型,如果观测值出现某种或某几种术后恢复状态分类占全部观测值比例小于理论占比的20%的情形,数据视为不平衡数据,其中每种分类的理论占比等于
其中,时间序列变量包括vas评分、bi评分、主动咳嗽及咳痰次数、深呼吸次数;非时间序列变量包括术前变量、术后变量,所述术前变量包括术后住院时长、性别、切口类型、切口长度、bmi、ca、肿瘤直径、肿瘤数目、手术时间、切除范围、出血量、有无输血、输血浆量、输悬红量、ishak评分、组织分化等级、有无侵犯包膜、切除范围、有无癌栓、有无卫星结节、术前pt;所述术后变量包括术后1月生命质量评分、有无并发症、手术并发症clavien分级、有无再入院、下床活动次数、下床活动时长截止术后3天、术后出现肠鸣音(小时)、术后肛门排气或排便(小时)、术后1月生命质量评分。
进一步地,所述步骤四具体为:术后恢复状态共有n类,那么每种分类的理论占比为1/n,如果在数据集中,属于某一类型的患者人数与患者总数的比例小于1/n的20%,则此类型观测值为少数类,对于数据集中的少数类,用以下方法人工合成数据,进行数据集的补充,再利用补充后的新数据集,构建预测模型:
(1)如果数据集中只有一个少数类
①对于少数类
yo≠ya+βy(yb-ya),βy∈(0,1)
或
xo1≠xa1+βx1(xb1-xa1),βx1∈(0,1)
或
xo2≠xa2+βx2(xb2-xa2),βx2∈(0,1)
…
且
②在这两个样本间的连线上,随机选择一个点,生成一个人工合成数据
yab=ya+βy(yb-ya),βy∈(0,1)
xab1=xa1+βx1(xb1-xa1),βx1∈(0,1)
xab2=xa2+βx2(xb2-xa2),βx2∈(0,1)
…
③将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入④。
④利用新数据集,寻找少数类
yo=c1ya+c2yb+c3yc
xo1=c1xa1+c2xb1+c3xc1
xo2=c1xa2+c2xb2+c3xc2
…
且满足c1+c2+c3≠1或c1,c2,c3至少有一个不在[0,1]。
⑤在着三个样本形成的三角形中,随机选择一个点,生成一个人工合成数据
yabc=c1ya+c2yb+c3yc
xabc1=c1xa1+c2xb1+c3xc1
xabc2=c1xa2+c2xb2+c3xc2
…
c1+c2+c3=1
⑥将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入⑦。
⑦按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本人工合成数据,直到新数据集中少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
(2)如果数据集包含两个以上(包含两个)少数类
①对于每一个少数类
②将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
③对于每一个少数类
④将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
⑤按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本对每一个少数类人工合成数据,直到新数据集中所有少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
综上可见,本发明提供了一种手术后恢复状态评价方法,有助于对外科患者术后恢复状态进行有效评估,对患者的术后恢复状态进行预测。
以下结合附图以及具体实施方式对本发明作进一步说明。凡基于本发明上述内容所实现的技术均属于本发明的范围。显然,根据本发明的上述内容,按照本领域的普通技术知识和惯用手段,在不脱离本发明上述基本技术思想前提下,还可以做出其它多种形式的修改、替换或变更。
以下通过实施例形式的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。
下面结合附图和具体实施方式对本发明做进一步的说明。本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
构成本发明的一部分的附图用来辅助对本发明的理解,附图中所提供的内容及其在本发明中有关的说明可用于解释本发明,但不构成对本发明的不当限定。在附图中:
图1本发明外科患者术后恢复状态预测模型构建方法的流程示意图。
图2本发明中不平衡数据中基于两个样本人工合成数据示意图
图3本发明中不平衡数据中基于三个样本人工合成数据示意图
具体实施方式
下面结合附图对本发明进行清楚、完整的说明。本领域普通技术人员基于这些说明的情况下将能够实现本发明。在结合附图对本发明
进行说明前,需要特别指出的是:
本发明中在包括下述说明在内的各部分中所提供的技术方案、技术特征,在不冲突的情况下,这些技术方案、技术特征可以相互组合。
下述说明中涉及到的本发明的优选实施方式、实施例通常仅是本发明一分部的实施方式和实施例。因此,基于本发明中的优选实施方式、实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施方式、实施例,都应当属于本发明保护的范围。
本发明的说明书和权利要求书及有关的部分中的术语“包括”、“具有”以及它们的任何变形,意图在于覆盖不排他的包含。
本发明中的其他相关术语和单位,均可基于本发明相关内容得到合理的解释。
本发明外科患者术后恢复状态预测模型构建方法,包括以下步骤:
步骤一:采集时间序列变量以及非时间序列变量,将时间序列变量转化为趋势变量,步骤具体如下:
(1)计算在相邻数据采集时间(t-1和t)之间每一类时间序列变量xi=(xi,t1,xi,t2,...,xi,tj,...)的变化量,i表示时间序列变量类型,
(2)确定每一个时间序列变量在各时间的趋势变量tri,t取值,如果变化量为负值,则相应的趋势变量取值-1;如果变化量为非负值,则相应的趋势变量取值1,
步骤二:利用趋势变量和指标的正常范围确定每个指标的术后恢复状态变量,具体如下:
(1)判断在每一个数据采集时刻,每一个趋势变量的取值是否在相应的指标正常范围之间,如果在正常范围之间,则指标变量取值1;反之,则指标变量取值0,
(2)根据临床诊疗标准、趋势变量是否在指标正常范围内,确定每位患者在各个指标的术后恢复状态变量ii取值;如果趋势变量均为-1或者趋势变量先升高再下降,并且最后一个数据采集时刻趋势变量的取值在指标正常范围内,则该患者指标术后恢复较好,术后恢复状态变量记为1;如果最后两个数据采集时刻趋势变量的取值都在指标正常范围内,那么这位患者指标术后恢复较好,术后恢复状态变量记为1;如果3个趋势变量皆为-1,但最后一个数据采集时刻趋势变量的取值不在指标正常范围内,那么这位患者的指标术后恢复一般,术后恢复状态变量记为0;其他情况,例如趋势变量出现波动和反复、数值升高,说明这位患者的术后恢复差,术后恢复状态变量记为-1。
步骤三:
利用支持向量机(svm)算法,根据所有时间序列变量转化的术后恢复状态变量和非时间序列变量中除下床活动次数、下床活动时长截止术后3天外的其他变量,对患者的术后恢复状态变量进行分类:
步骤四:以术后恢复状态分类为因变量,以所有非时间序列中的术前变量、(术后患者行为变量)术后下床活动次数和术后下床活动时长截止术后3天为自变量,利用随机森林算法,构建预测模型,如果观测值出现某种或某几种术后恢复状态分类占全部观测值比例小于理论占比的20%的情形,数据视为不平衡数据,其中每种分类的理论占比等于
其中,时间序列变量包括vas评分、bi评分、主动咳嗽及咳痰次数、深呼吸次数;非时间序列变量包括术前变量、术后变量,所述术前变量包括术后住院时长、性别、切口类型、切口长度、bmi、ca、肿瘤直径、肿瘤数目、手术时间、切除范围、出血量、有无输血、输血浆量、输悬红量、ishak评分、组织分化等级、有无侵犯包膜、切除范围、有无癌栓、有无卫星结节、术前pt;所述术后变量包括术后1月生命质量评分、有无并发症、手术并发症clavien分级、有无再入院、下床活动次数、下床活动时长截止术后3天、术后出现肠鸣音(小时)、术后肛门排气或排便(小时)、术后1月生命质量评分。
所述步骤四具体为:术后恢复状态共有n类,那么每种分类的理论占比为1/n,如果在数据集中,属于某一类型的患者人数与患者总数的比例小于1/n的20%,则此类型观测值为少数类,对于数据集中的少数类,用以下方法人工合成数据,进行数据集的补充,再利用补充后的新数据集,构建预测模型:
(1)如果数据集中只有一个少数类
①对于少数类
yo≠ya+βy(yb-ya),βy∈(0,1)
或
xo1≠xa1+βx1(xb1-xa1),βx1∈(0,1)
或
xo2≠xa2+βx2(xb2-xa2),βx2∈(0,1)
…
且
②如图2所示,在这两个样本间的连线上,随机选择一个点,生成一个人工合成数据
yab=ya+βy(yb-ya),βy∈(0,1)
xab1=xa1+βx1(xb1-xa1),βx1∈(0,1)
xab2=xa2+βx2(xb2-xa2),βx2∈(0,1)
…
③将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入④。
④利用新数据集,寻找少数类
且以三个样本为顶点形成的三角形中没有其他类的样本
yo=c1ya+c2yb+c3yc
xo1=c1xa1+c2xb1+c3xc1
xo2=c1xa2+c2xb2+c3xc2
…
且满足c1+c2+c3≠1或c1,c2,c3至少有一个不在[0,1]。
⑤如图3所示,在着三个样本形成的三角形中,随机选择一个点,生成一个人工合成数据
yabc=c1ya+c2yb+c3yc
xabc1=c1xa1+c2xb1+c3xc1
xabc2=c1xa2+c2xb2+c3xc2
…
c1+c2+c3=1
c1,c2,c3∈[0,1]
⑥将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入⑦。
⑦按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本人工合成数据,直到新数据集中少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
(2)如果数据集包含两个以上(包含两个)少数类
①对于每一个少数类
②将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
③对于每一个少数类
④将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
⑤按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本对每一个少数类人工合成数据,直到新数据集中所有少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
非时间序列变量指标如下表1;
表1
结合表1以及附图1,以下通过crp指标为例对本发明作进一步说明:
步骤一:采集时间序列变量以及非时间序列变量,将时间序列变量转化为趋势变量,步骤具体如下:
(1)计算在相邻数据采集时间(t-1和t)之间每一类时间序列变量xi=(xi,t1,xi,t2,...,xi,tj,...)的变化量,i表示时间序列变量类型,
(2)确定每一个时间序列变量在各时间的趋势变量tri,t取值,如果变化量为负值,则相应的趋势变量取值-1;如果变化量为非负值,则相应的趋势变量取值1,
术后1天vas评分的变化量为术后1天vas评分与术后8小时vas评分的差值,
术后3天hb的变化量为术后3天hb与术后1天hb的差值,
δhb,3=hb3-hb1
(2)确定每一个时间序列变量在各时间的趋势变量tri,t取值。如果变化量为负值,则相应的趋势变量取值-1;如果变化量为非负值,则相应的趋势变量取值1。
步骤二:利用趋势变量和指标的正常范围确定每个指标的术后恢复状态变量,具体如下:
(1)判断在每一个数据采集时刻,每一个趋势变量的取值是否在相应的指标正常范围之间,如果在正常范围之间,则指标变量取值1;反之,则指标变量取值0,
crp的正常参考值为800-8000μg/l,
(2)根据临床诊疗标准、趋势变量是否在指标正常范围内,确定每位患者在各个指标的术后恢复状态变量ii取值;如果趋势变量均为-1或者趋势变量先升高再下降,并且最后一个数据采集时刻趋势变量的取值在指标正常范围内,则该患者指标术后恢复较好,术后恢复状态变量记为1;如果最后两个数据采集时刻趋势变量的取值都在指标正常范围内,那么这位患者指标术后恢复较好,术后恢复状态变量记为1;如果3个趋势变量皆为-1,但最后一个数据采集时刻趋势变量的取值不在指标正常范围内,那么这位患者的指标术后恢复一般,术后恢复状态变量记为0;其他情况,例如趋势变量出现波动和反复、数值升高,说明这位患者的术后恢复差,术后恢复状态变量记为-1。
crp升高表明机体炎性反应亢进。手术前crp升高,术后5天crp水平应下降,如crp不降低或再次升高,提示可能并发感染或血栓栓塞。因此,对于crp,共有4个术后观测值,
crp指标术后恢复较好,crp术后恢复状态变量记为1,icrp=1;如果最后两个数据采集时刻变量值都在指标正常范围内,trcrp,2=trcrp,3=1,那么这位患者crp指标术后恢复较好,crp术后恢复状态变量记为1,icrp=1;如果3个趋势变量皆为-1,但最后一个数据采集时刻变量值不在指标正常范围内,ncrp,3=-1,那么这位患者的crp指标术后恢复一般,crp术后恢复状态变量记为0,icrp=0;
其他情况,例如趋势出现波动和反复、数值升高,说明这位患者的crp指标术后恢复差,crp术后恢复状态变量记为-1,icrp=-1。通过这一步骤,将每一类时间序列变量xi转化为一个术后恢复状态变量ii。
步骤三:
利用支持向量机(svm)算法,根据所有时间序列变量转化的术后恢复状态变量和非时间序列变量中除下床活动次数、下床活动时长截止术后3天外的其他变量,对患者的术后恢复状态变量进行分类:
步骤四:以术后恢复状态分类为因变量,以所有非时间序列中的术前变量、(术后患者行为变量)术后下床活动次数和术后下床活动时长截止术后3天为自变量,利用随机森林算法,构建预测模型,如果观测值出现某种或某几种术后恢复状态分类占全部观测值比例小于理论占比的20%的情形,数据视为不平衡数据,其中每种分类的理论占比等于
其中,时间序列变量包括vas评分、bi评分、主动咳嗽及咳痰次数、深呼吸次数;非时间序列变量包括术前变量、术后变量,所述术前变量包括术后住院时长、性别、切口类型、切口长度、bmi、ca、肿瘤直径、肿瘤数目、手术时间、切除范围、出血量、有无输血、输血浆量、输悬红量、ishak评分、组织分化等级、有无侵犯包膜、切除范围、有无癌栓、有无卫星结节、术前pt;所述术后变量包括术后1月生命质量评分、有无并发症、手术并发症clavien分级、有无再入院、下床活动次数、下床活动时长截止术后3天、术后出现肠鸣音(小时)、术后肛门排气或排便(小时)、术后1月生命质量评分。
所述步骤四具体为:术后恢复状态共有n类,那么每种分类的理论占比为1/n,如果在数据集中,属于某一类型的患者人数与患者总数的比例小于1/n的20%,则此类型观测值为少数类,对于数据集中的少数类,用以下方法人工合成数据,进行数据集的补充,再利用补充后的新数据集,构建预测模型。假设步骤三得到的患者的术后恢复状态共有5类,那么每种分类的理论占比为
(1)如果数据集中只有一个少数类。
①对于少数类
yo≠ya+βy(yb-ya),βy∈(0,1)
或
xo1≠xa1+βx1(xb1-xa1),βx1∈(0,1)
或
xo2≠xa2+βx2(xb2-xa2),βx2∈(0,1)
…
且
②如图2所示,在这两个样本间的连线上,随机选择一个点,生成一个人工合成数据
yab=ya+βy(yb-ya),βy∈(0,1)
xab1=xa1+βx1(xb1-xa1),βx1∈(0,1)
xab2=xa2+βx2(xb2-xa2),βx2∈(0,1)
…
③将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入④。
④利用新数据集,寻找少数类
且以三个样本为顶点形成的三角形中没有其他类的样本
yo=c1ya+c2yb+c3yc
xo1=c1xa1+c2xb1+c3xc1
xp2=c1xa2+c2xb2+c3xc2
…
且满足c1+c2+c3≠1或c1,c2,c3至少有一个不在[0,1]。
⑤如图3所示,在着三个样本形成的三角形中,随机选择一个点,生成一个人工合成数据
yabc=c1ya+c2yb+c3yc
xabc1=c1xa1+c2xb1+c3xc1
xabc2=c1xa2+c2xb2+c3xc2
…
c1+c2+c3=1
c1,c2,c3∈[0,1]
⑥将新合成的数据与原始数据合并,形成新数据集,重新计算这一少数类在新数据集中所占比例。如果比例大于等于理论占比的40%,停止人工合成数据;否则,进入⑦。
⑦按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本人工合成数据,直到新数据集中少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
(2)如果数据集包含两个以上(包含两个)少数类
①对于每一个少数类
②将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
③对于每一个少数类
④将新合成的数据与原始数据合并,形成新数据集,重新计算每一个少数类在新数据集中所占比例。对于比例小于理论占比的40%的少数类
⑤按照上述步骤,利用新数据集,依次基于四个、五个、六个等样本对每一个少数类人工合成数据,直到新数据集中所有少数类所占比例大于等于理论占比的40%,或无法寻找到不覆盖其它类样本的少数类样本组合,停止人工合成数据。
综上可见,本发明(1)对于描述患者术后恢复状态的时间序列变量,通过将其转化为趋势变量,进而对每个术后恢复指标形成一个综合术后恢复状态指示变量。(2)如果数据集是不平衡数据,则利用少数类样本为顶点形成的区域,对少数类进行人工合成数据,使用包含新合成数据和原数据的新数据集,训练预测模型。有助于对外科患者术后恢复状态进行有效评估,对患者的术后恢复状态进行预测。
以上对本发明的有关内容进行了说明。本领域普通技术人员在基于这些说明的情况下将能够实现本发明。基于本发明的上述内容,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他优选实施方式和实施例,都应当属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!