声音处理系统以及声音处理方法与流程
本申请要求2016年3月8日申请、申请号为2016-044653的日本专利申请的优先权,其全部内容通过引用并入本文。
本发明涉及声音处理系统,特别涉及能够针对来自用户的反问快速地应答的声音处理系统。
背景技术:
伴随声音识别技术的发展,车内空间内的声音用户接口的利用正在增加。另一方面,车内空间是噪音多的环境,需要强劲地识别噪音。另外,要求构筑以有多次反问为前提的系统。
在此,“反问”是指,关于a要求之后的“不是a,而是b的情况?”这样的发声。例如,“检索涩谷附近的意大利餐厅”这样的要求之后的、“不是涩谷而是横浜的话是怎么样?”、“代替意大利餐厅而检索法国餐厅”这样的发声相当于“反问”。
在美国专利号no.7353176、美国专利号no.8036877、美国专利号no.8515752中公开了考虑上下文来掌握反问的内容并准确地处理的内容。
然而,美国专利号no.7353176、美国专利号no.8036877、美国专利号no.8515752是以能够应对反问为主要目标的发明,并未公开使反问处理快速化。
技术实现要素:
本发明的目的在于在声音处理系统中,能够针对反问的要求快速地应答。
本发明的声音处理系统具备:声音取得单元,取得用户的发声;声音识别单元,识别声音取得单元取得的发声的内容;执行单元,根据所述声音识别单元的结果执行处理;以及决定单元,决定代替某个词的词的候补。而且,在由所述声音识别单元识别出包括第1词的要求的情况下,通过所述执行单元执行包括所述第1词的要求并将处理结果提供给所述用户,并且通过所述决定单元决定作为所述第1词的代替候补的第2词,通过所述执行单元还执行代替所述第1词而包括所述第2词的要求并将处理结果存储到存储单元。
在本发明中,优选为在由所述声音识别单元识别出包括所述第1词的要求之后识别出代替所述第1词而包括所述第2词的要求的情况下,所述执行单元取得所述存储单元中存储的处理结果并提供给所述用户。
这样,利用决定单元决定成为反问的候补的词的对,预先执行与反问的候补有关的处理并存储结果,从而能够缩短实际发生了将第1词置换为第2词的反问时的处理时间。
在本发明中,所述决定单元能够将在从所述用户取得了包括某个词的要求之后从所述用户取得了代替所述某个词而包括其它词的要求的次数,按照所述某个词和所述其它词的对存储,将与输入的词成对的词中的所述次数是阈值以上的词决定为所述输入的词的代替候补。在此,“从所述用户取得了代替所述某个词而包括其它词的要求的次数”可以是取得了指示为进行代替所述某个词而包括其它词的要求的发声的次数。即,决定单元优选为将关于a的要求之后的、“代替a而b的情况?”那样的反问的次数针对用语a和b的对进行存储。此外,决定单元存储的上述次数未必仅根据实际用户的发声内容来决定,关于设想为反问的频度高的用语对,也可以将上述次数预先设定得较大。
另外,在本发明中,决定单元还能够将某个词和该词的代替候补关联起来存储,将与输入的词关联起来存储的词决定为该输入的词的代替候补。另外,决定单元也可以根据词汇辞典判断用语的类似性,将与输入的词类似的词决定为代替候补。不论在哪一个情况下,都优选为还考虑发声中的上下文来决定代替候补。
另外,在本发明中,还优选为在所述用户在包括所述第1词的要求之后代替包括所述第1词的要求而发声了包括所述第2词的要求的情况下,所述声音识别单元根据包括所述第1词的要求的上下文信息决定所述第2词的属性,进行所述第2词的识别。
虽然有同一词根据上下文不同而具有不同的含意的情况,但在代替包括第1词的要求而发声了包括第2词的要求的情况下,设想第1词和第2词具有相同的属性。因此,通过考虑包括第1词的要求的上下文信息,能够精度良好地求出第2词的属性,能够精度良好地识别第2词。
根据本发明,在声音处理系统中,能够针对反问的要求快速地应答。
参照附图,本发明的进一步特征将从以下具体实施例的描述中变得清晰。
附图说明
图1是示出实施方式的声音处理系统的结构例的图。
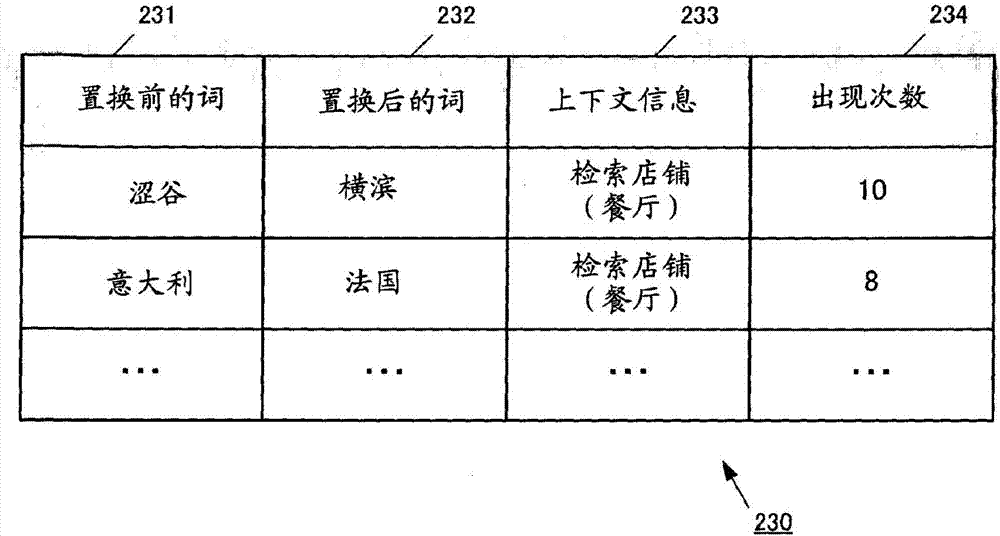
图2是示出实施方式的词对存储部的例子的图。
图3是示出实施方式的声音处理方法的流程的流程图。
图4是示出实施方式的声音处理方法的流程的流程图。
具体实施方式
以下,参照附图,说明本发明的示例性的实施方式。此外,以下的说明示例地说明了本发明,本发明不限于以下的实施方式。
<反问>
在说明本实施方式的声音处理系统之前,说明“反问”。设想用户的发声内容是针对声音处理系统要求某种处理的状况。例如,考虑进行“检索涩谷附近处的意大利餐厅”这样的要求的状况。在之后用户进行“检索横浜附近处的意大利餐厅”这样的要求的情况下,考虑为“不是涩谷而是横浜的话是怎么样?”这样发声。在本说明书中,这样将包括某个词a的要求/指示之后的“不是a而是b的情况?”那样的发声称为“反问”。在上述例子中,除了变更“涩谷”这样的词的反问以外,还设想将“意大利”变更为“法国”的反问。即,反问的模式设想与某个要求中包含的词的数量相当的量。
<系统结构>
图1是示出本实施方式的声音处理系统的系统结构的图。本实施方式的声音处理系统是通过声音处理服务器200识别车辆100内的用户的发声,并执行与发声内容对应的处理来对车辆100内的用户提供处理结果的系统。
车辆100具备包括声音取得部110和信息提供部120的信息处理装置(计算机)。信息处理装置包括运算装置、存储装置、输入输出装置等,通过由运算装置执行存储装置中保存的程序来提供下述的功能。
声音取得部110由一个或者多个麦克风或者麦克风阵列构成,取得用户发出的声音。声音取得部110取得的声音通过无线通信被发送到声音处理服务器200。此外,声音取得部110不需要将所取得的声音原样地发送到声音处理服务器200,而可以取得声音的特征量并仅发送特征量。信息提供部120是用于将车辆100从声音处理服务器200取得的信息提供给用户的装置,包括图像显示装置、声音输出装置等。
声音处理服务器200具备包括声音识别部210、执行部220、词对存储部230、决定部240的信息处理装置(计算机)。信息处理装置包括运算装置、存储装置、输入输出装置等,通过由运算装置执行存储装置中保存的程序来提供下述的功能。
声音识别部210是用于识别从车辆100的声音取得部110发送的声音,并掌握其内容(文本)以及含意的功能部。声音识别部210根据词汇辞典、语言模型,进行声音识别。作为具体的声音识别手法,能够利用现有的任意的手法。在图中记载为声音识别部210仅从1台车辆100取得声音,但还能够从许多车辆100取得声音并识别。
此外,声音识别部210在识别反问的发声时,优选为根据反问之前的发声内容的上下文来决定并识别反问中包含的词的属性等。在反问中被置换的词是在同一上下文中使用的词,所以能够通过使用上下文信息来更高精度地识别反问中包含的词。
执行部220是执行与利用声音识别部210进行声音识别的结果对应的处理的功能部。例如,如果用户的发声是要求取得满足预定的条件的信息的发声,则执行部220从检索服务器300取得满足该条件的信息,并发送给车辆100。
执行部220在从用户受理了要求的情况下,推测所设想的反问,并执行与推测出的反问的要求对应的处理,将处理结果存储到存储部(未图示)。即,执行部220预取(先取)所推测的反问的要求的结果。然后,在实际从用户接受到反问的情况下,如果已预取到结果,则将其结果发送到车辆100。另外,执行部220在发生了反问的情况下,将哪个词被哪个词置换的情况记录到词对存储部230。关于这些处理的详细内容后述。
词对存储部230存储反问中的置换前的词和置换后的词的对的出现次数。图2是示出词对存储部230的表格结构的图。词对存储部230保存置换前的词231、置换后的词232、上下文信息233、出现次数234。置换前的词231是通过反问置换前的词,置换后的词232是通过反问置换后的词。上下文信息233是确定发声中的上下文的信息。出现次数234是通过利用上下文信息233确定的上下文而置换前的词231被置换后的词232置换的反问出现的次数。
此外,不需要仅根据实际发生的反问来决定词对存储部230中的出现次数。例如,在要求“检索a”之后发生了“不是a而是b的情况?”这样的反问的情况下,增加将词a置换为词b的反问的出现次数。此时,也可以增加将词b置换为词a的反问的出现次数。另外,在进而接下来继续了“c的情况?”这样的反问的情况下,增加将词a置换为词c的反问的出现次数。此时,除了增加将词a置换为词c的反问的出现次数以外,还可以增加将词b置换为词c的反问、将词c置换为词a的反问、将词c置换为词b的反问的出现次数。这是因为考虑在发生反问的情况下成为反问的对象的词是可相互置换的缘故。
决定部240是在取得了来自用户的发声时,推测用户的发声的反问的功能部。决定部240参照词对存储部230,推测在反问中哪个词被置换为哪个词。具体而言,决定部240参照词对存储部230,将用户的发声中包含的词以及该发声的上下文中出现次数是阈值以上的词对推测为在反问中被置换的词对。在有多个阈值以上的词对的情况下,词候补决定部240选择所有词对即可。但是,也可以仅选择居上位的预定数个的词对。
<处理内容>
首先,参照图3、图4说明本实施方式的声音处理系统中的处理。最初,在步骤s102中,声音取得部110取得用户的发声并发送给声音识别部210,声音识别部210识别发声的内容。在此,假设从用户接受到“检索从a到c的路径”这样的发声。实际上,a、c是具体的地名、店铺名等。另外,以下将该发声表示为{a、c}。
在步骤s104中,声音识别部210临时地存储当识别出发声{a、c}时得到的上下文信息、各词的领域。
在步骤s106中,执行部220执行与发声{a、c}对应的处理,将其结果发送到车辆100。具体而言,执行部220对检索服务器300发出求从a到c的路径的要求,取得其结果。然后,执行部220将从检索服务器300得到的处理结果发送到车辆100。在车辆100中,信息提供部120对用户提供处理结果。
在步骤s108中,决定部240决定针对发声{a、c}设想的反问中的候补词。例如,决定对发声{a、c}内的词a进行置换的词的候补集合{bi}。具体而言,决定部240参照词对存储部230,将置换前的词是词a且上下文信息与发声{a、c}的上下文信息(已在s104中存储)一致的记录项中所包含的置换后的词,决定为候补词。在该说明中,仅说明置换词a的候补词,但同样地决定置换词c的候补词也是优选的。
在步骤s110中,执行部220关于置换词a的词的候补集合{bi}的各个,进行与发声内容{bi、c}对应的处理,即“检索从bi到c的路径”这样的处理,并存储到存储装置中。与步骤s102同样地,通过对检索服务器300发出要求来进行路径的检索即可。
在步骤s112中,取得来自用户的反问的发声,并识别其内容。在此,设想用户反问“不是从a而是从b1的话是怎么样?”的情况。以下,将这样的反问表示为(a、b1)。声音识别部210在识别词b1时,考虑在步骤s104中存储的发声{a、c}的上下文信息、领域,来决定词b1的属性信息。例如,词b1有具有地名和店铺名等多个含意的情况,但声音识别部210考虑发声{a、c}的上下文信息等来能够判断为反问(a、b1)中的词b1表示地名。
在步骤s114中,声音处理服务器200更新词对存储部230。具体而言,将与置换前的词是“a”、置换后的词是“b1”、上下文信息是发声{a、c}的上下文信息相应的记录项的出现次数增加1。在不存在这样的记录项的情况下,新制作该记录项而将其出现次数设为1即可。此时,也可以将置换前的词是“b1”且置换后的词是“a”的记录项的出现次数增加1。这是因为考虑反问的词的对是可双向地交换的。
在步骤s116中,执行部220判断是否已存储(已预取){b1、c}即“从b1向c的路径的检索”的处理结果。如果已存储,则执行部220从存储部取得其结果,发送到车辆100。如果未已存储,则执行{b1、c}的处理,并将其处理结果发送到车辆100。在车辆100中,信息提供部120对用户提供该处理结果。
<本发明的有利的效果>
根据本发明,在受理了基于来自用户的声音的要求时,预想发生反问,预先执行与预想的反问对应的处理来预取结果。因此,在实际发生了反问时,无需进行处理就能够立即返回结果。如本实施方式那样,在针对外部服务器发出要求来进行处理的情况下花费几秒程度的时间,但通过预取来能够将该时间缩短为小于1秒。即,能够使反问时的应答快速化。
另外,根据实际发生的反问次数来决定成为反问的对象的词,所以能够提高推测精度。如本实施方式那样,在声音处理服务器200一并处理来自多个车辆100的声音的情况下,能够存储更多的反问的历史,所以能够进行精度更良好的推测。
另外,在发生了反问的情况下,利用反问之前的发声的上下文信息、领域来识别反问中包含的词的属性信息,所以能够进行精度良好的声音识别。在车辆内由于道路噪声等的影响而取得的声音有时变得不清楚,但通过这样利用上下文信息,在车辆内也能够进行精度良好的声音识别。
<变形例>
在上述实施方式中,根据实际产生的反问的次数推测成为反问的对象的词,但成为反问的对象的词的推测方法不限于上述方法。例如,决定部240也可以构成为具有词汇辞典,在反问之前的发声的上下文中,将与该发声中包含的词的类似度是阈值以上的词推测为反问对象的词。这样,也能够得到与上述同样的效果。
另外,在反问对象的词的推测中,重视进行该发声的用户的历史也是优选的。在上述说明中,声音处理服务器200将从各种车辆(用户)得到的反问的发生次数存储于词对存储部230中,但对每个用户的反问次数进行计数,并根据用户的反问次数推测反问也是优选的。由此,能够进行反映了每个用户的特征的推测。
在上述实施方式中,设想了车辆内的利用,但本发明的声音处理系统的利用场景不限于车辆内,而能够在任意的环境中利用。另外,以声音取得部(麦克风)设置于车辆且声音识别部和执行部设置于服务器的、所谓中心型的声音处理系统为例子进行了说明,但既可以将这些所有功能包含于1个装置来实施本发明,也可以通过以与上述不同的方式分担了功能的结构来实施本发明。
- 还没有人留言评论。精彩留言会获得点赞!