一种基于语音识别的场景交互控制方法与流程
本发明属于场景交互控制技术领域,具体涉及一种基于语音识别的场景交互控制方法。
背景技术:
近年来,随着我国经济呈现出快速增长的态势,政府及企业会场的应用需求也逐渐从单一向多样化变化;会场应用涉及会议、调度控制、应急指挥、日常运营、集中监控等各种功能;会场设备种类繁多,例如,包括灯、音箱、拼接屏、电视、摄像机、投影仪、升降显示器、影碟机、矩阵、拼接屏处理器等设备。
目前,会场控制主要方法为:根据每一种会场模式,对各类会场设备进行手动控制,例如,在某种会场模式下,分别控制灯的亮度、开启音箱、开启摄像机以及将显示器调节到某一高度,以满足会议需求。在另一种会场模式下,再分别控制灯的亮度、开启影碟机、将显示器调节到另一高度,以满足会议需求。
上述会场控制方法具有以下问题:采用手工的方式,对各个被控设备进行控制和调节,具有控制效率低、工人工作量大的不足。
技术实现要素:
针对现有技术存在的缺陷,本发明提供一种基于语音识别的场景交互控制方法,可有效解决上述问题。
本发明采用的技术方案如下:
本发明提供一种基于语音识别的场景交互控制方法,包括以下步骤:
步骤1,中央控制系统预建立快照库;所述快照库存储若干条快照名称以及快照场景执行命令的对应关系;通过所述快照场景执行命令,所述中央控制系统对会场设备进行控制;
语音识别控制程序为避免误操作,平时处于未被唤醒的休眠状态;此时,唤醒语监听程序持续为打开状态;主语音监听程序持续关闭状态;
步骤2,所述唤醒语监听程序实时监听,判断是否监听到唤醒词;如果没有监听到唤醒词,则持续进行监听;如果监听到唤醒词,则执行步骤3;
步骤3,中央控制系统关闭所述唤醒语监听程序,开启所述主语音监听程序,进而唤醒所述中央控制系统的语音识别控制程序,此时所述中央控制系统的语音识别控制程序转变为激活状态;
步骤4,所述中央控制系统的语音识别控制程序启动语音录制模块,通过所述语音录制模块录制来自于用户的语音命令,并存储录制到的所述语音命令;同时,在所述语音录制模块录制所述语音命令的过程中,通过显示模块显示语音音量波形;
步骤5,所述语音录制模块将录制到的所述语音命令传输给语音识别模块;
步骤6,所述语音识别模块对所述语音命令进行初步语音有效性识别,如果识别成功,则执行步骤7;如果未识别成功,则向用户反馈识别失败的提示信息;
步骤7,所述语音识别模块对所述语音命令进行意图识别,识别出以下四种类型中的一种:快照类型、选项类型、确认/取消类型和其他类型;
如果所述语音命令为快照类型,则通过快照类型子模块执行步骤8;如果所述语音命令为选项类型,则通过选项类型子模块执行步骤9;如果所述语音命令为确认/取消类型,则通过确认/取消类型子模块执行步骤10;如果所述语音命令为其他类型,则通过其他类型子模块执行步骤11;
步骤8:通过快照类型子模块执行与快照类型对应的语音命令,包括以下步骤:
步骤8.1,如果所述语音命令为快照类型,得到所述语音命令的识别度分数,并判断所述识别度分数是否超过阈值,如果没有超过,表明所述语音命令不够明确,则执行步骤8.2;如果超过,表明所述语音命令明确,则执行步骤8.3;
步骤8.2,对所述语音命令进行进一步的识别结果唯一性判断,即:判断识别结果是否为多音情况,如果不是,则表明语音命令对应快照库里唯一读音的快照名称,并通过显示模块输出是否执行快照的进一步确认的提示信息,同时,在确认/取消上下文配置表中记录本次确认/取消的对象信息,然后由确认/取消类型子模块执行后续步骤;如果是,则表明语音命令对应快照库里多音的快照名称,并将多音的各个快照名称形成多音快照结果集合,并通过显示模块显示所述多音快照结果集合,同时,在选项上下文配置表中记录本次选项信息,并由所述选项类型子模块执行后续步骤;
步骤8.3,对所述语音命令进行进一步的识别结果唯一性判断,即:判断识别结果是否为多音情况,如果不是,则表明语音命令对应快照库里唯一读音的快照名称,并直接执行与所述快照名称对应的快照场景命令;如果是,则表明语音命令对应快照库里多音的快照名称,并将多音的各个快照名称形成多音快照结果集合,并通过显示模块显示所述多音快照结果集合,同时,在选项配置表中记录本次选项信息,并由所述选项类型子模块执行后续步骤;
每当所述选项上下文配置表存储选项信息后,当任意下一条来自于用户的语音命令被执行后,即清空所述选项上下文配置表;
每当所述确认/取消上下文配置表存储确认/取消的对象信息后,当任意下一条来自于用户的语音命令被执行后,即清空所述确认/取消上下文配置表;
步骤9,通过选项类型子模块执行与选项类型对应的语音命令,包括以下步骤:
如果所述语音命令为选项类型,首先查找所述选项上下文配置表,判断所述选项上下文配置表是否为空,如果不为空,表明存在与所述语音命令对应的上文信息,则根据所述选项上下文配置表中存储的所述选项信息以及所述语音命令,直接执行对应的快照场景命令;如果所述选项上下文配置表为空,则表明不存在上文信息,则通过显示模块输出语音识别失败的提示信息;
步骤10,通过确认/取消类型子模块执行与确认/取消类型对应的语音命令,包括以下步骤:
如果所述语音命令为确认/取消类型,首先查找所述确认/取消上下文配置表,判断所述确认/取消上下文配置表是否为空,如果不为空,表明存在与所述语音命令对应的上文信息,则根据所述确认/取消上下文配置表中存储的确认/取消的对象信息以及所述语音命令,直接执行对应的快照场景命令;如果所述确认/取消上下文配置表为空,则表明不存在上文信息,则通过显示模块输出语音识别失败的提示信息;
步骤11,通过其他类型子模块执行与其他类型对应的语音命令,包括以下步骤:通过显示模块输出语音识别失败的提示信息。
优选的,配置唤醒按钮,当所述唤醒按钮被点击时,手动将所述中央控制系统的语音识别控制程序从休眠状态唤醒为激活状态。
优选的,通过显示模块输出语音识别失败的提示信息具体为:播放语音提示道歉语句,同时输出更换语音命令的提示类语句。
优选的,步骤1中,所述中央控制系统所建立的快照库实时动态更新。
优选的,所述中央控制系统对会场设备的控制方式包括:触摸点击屏幕、遥控笔按键触发和语音识别控制。
本发明提供的一种基于语音识别的场景交互控制方法具有以下优点:
本发明提供的一种基于语音识别的场景交互控制方法,将中央控制系统和语音识别技术结合,实现了用语言代替传统输入设备控制中央控制系统的功能,具有用户体验好的优点。
附图说明
图1为本发明提供的一种基于语音识别的场景交互控制方法的流程示意图。
具体实施方式
为了使本发明所解决的技术问题、技术方案及有益效果更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
关键术语解释:
被控设备:支撑现场业务大厅功能的基础设备,如大屏幕系统、中央空调、工作站、扩声系统、灯光管理模块等。
场景模式(以下称为快照):为现场各被控设备进行组合控制在业务层面定义的名称,如应急模式、日常监控模式等。
中央控制系统:控制系统是指对声、光、电等各种设备进行集中控制的设备。它应用于多媒体教室、多功能会议厅、指挥控制中心、智能化家庭等,用户可用按钮式控制面板、计算机显示器、触摸屏和无线遥控等设备,通过计算机和中央控制系统软件控制投影机、展示台、影碟机、录像机等设备。
近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
中央控制系统在实际应用中根据业务需求不断衍生出多种应用场景,如演示汇报、日常监控、生产调度等。用户在与系统交互的终端逐渐由台式计算机往更为小巧、移动方面方向发展。
因此,本发明提供一种基于语音识别的场景交互控制方法,将语音识别技术和中央控制系统相结合,涉及一种使用语音作为指令媒介的场景交互控制方法,该场景交互控制方法应用于商业监控、调度等大厅控制现场,如电网调度中心、公安监控大厅、军队作战指挥大厅等。
本发明利用语音识别技术,将说话人的语音消息进行识别,并进行分析处理,如识别到包含有效快照名字即交由中央控制系统进行执行具体操作,实现解放双手控制设备的目的。
本方法的实现分为硬件和软件处理两部分组成。
1、硬件部署
需要音频采集设备连接至中央控制系统控制终端:带有蓝牙功能的移动终端使用蓝牙耳机连接,语言采集和语音反馈均由蓝牙耳机完成;没有蓝牙功能的控制终端使用有线麦克风,语音反馈需要额外配置扬声器(可使用麦克风音响一体机或按需介入现场的扩声系统)。
2、软件实现流程
本系统分为语音识别模块和中央控制系统,其中语音识别模块是本系统重点申请保护的技术点,中央控制系统在接收到语音识别模块的指令后根据快照映射的设备控制协议和物理链路配置向目标设备发出控制指令,快速得到所需的场景模式,提高控制效率。本发明的重点是,如何对来自于用户的语音进行识别,并对应到快照库中的快照名称;而在匹配到快照库中的快照名称后,只需要执行对应的控制指令,就能向目标设备发出控制指令。
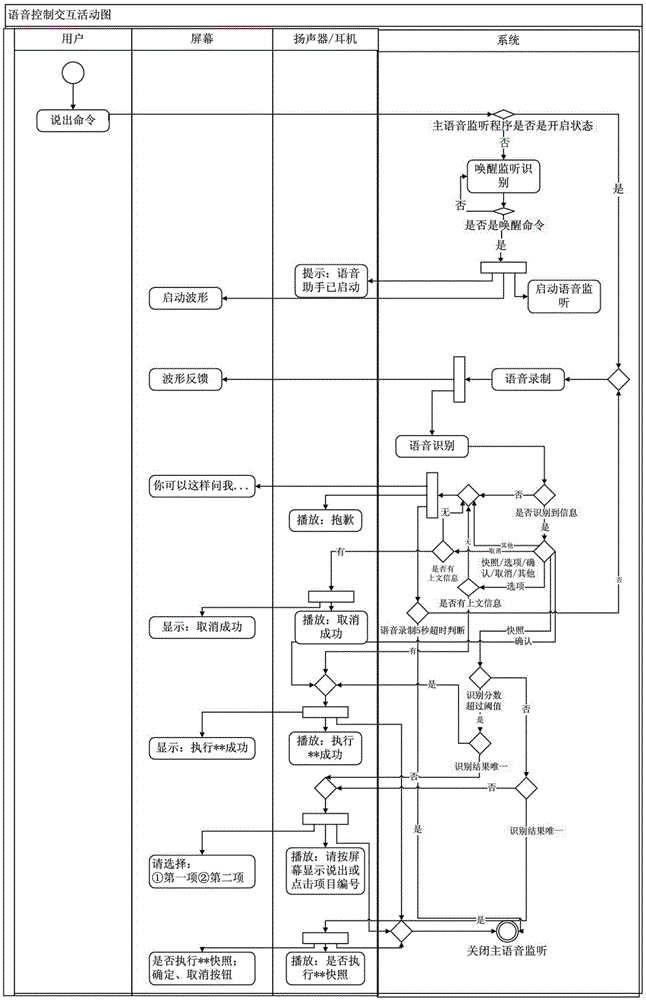
本发明中,为避免误操作加入唤醒环节,因此业务场景分为唤醒和语音识别两部分,并根据用户的不同意图设计了对应的逻辑处理方法,具体的业务判断流程如图1所示。对于系统来说,用户的唯一操作路径就是说出语音,系统设计了唯一的服务入口用于监听用户说出的语音。
参考图1,一种基于语音识别的场景交互控制方法,包括以下步骤:
步骤1,中央控制系统预建立快照库;所述快照库存储若干条快照名称以及快照场景执行命令的对应关系;通过所述快照场景执行命令,所述中央控制系统对会场设备进行控制;中央控制系统对会场设备的控制方式包括但不限于:触摸点击屏幕、遥控笔按键触发和语音识别控制。
例如:快照名称分别为:会议模式、惠宜模式、可视化调度场景、科石化调度场景、灯光全凯模式、灯光全开漠式等。每一种模式均对应一组对各个被控设备进行执行的对应指令。其中,实际应用中,快照名称存在错别字、多音字的情况。例如,灯光全开漠式中的“漠”为错别字;惠宜模式和会议模式这两个快照名称拼音相同,只是部分字的音调不同,被认为是多音快照名称。
本发明后续的基于语音识别的场景交互控制方法,能够实现对存在错别字、存在多音字的快照名称的识别和执行。
另外,所述中央控制系统所建立的快照库能够实时动态更新。即:中央控制系统允许用户根据业务需要创建不同快照(每个快照内部实际包含的是一个或多个被控设备的预控制消息),并为该快照自定义一个名字。而这些快照的名字集合即为语音控制功能的有效范围。
语音识别控制程序为避免误操作,平时处于未被唤醒的休眠状态;此时,唤醒语监听程序持续为打开状态;主语音监听程序持续关闭状态;
实际应用中,也可以配置唤醒按钮,当所述唤醒按钮被点击时,手动将所述中央控制系统的语音识别控制程序从休眠状态唤醒为激活状态。
唤醒过程的设计原理为:
系统为了避免用户误操作(如多个用户正在谈话,可能会提及系统可识别的命令语句造成快照误执行)所以增加了唤醒机制,类似手机的锁屏/解锁机制。即:在没有唤醒时,系统类似于锁屏状态;当激活状态时,系统处于解锁状态。
在同一时刻,唤醒语监听程序和主语音监听程序,二者只有一个为打开状态,另一个为关闭状态。
步骤2,所述唤醒语监听程序实时监听,判断是否监听到唤醒词;如果没有监听到唤醒词,则持续进行监听;如果监听到唤醒词,则执行步骤3;
步骤3,中央控制系统关闭所述唤醒语监听程序,开启所述主语音监听程序,进而唤醒所述中央控制系统的语音识别控制程序,此时所述中央控制系统的语音识别控制程序转变为激活状态;
例如,当中央控制系统处于未被唤醒的休眠状态时,用户说出某个词语,该词语被唤醒语监听程序监听到,然后,唤醒语监听程序判断该词语是否为唤醒词;其中,唤醒词为系统根据需求预定制的词,例如,“小恒小恒”;如果是唤醒词,则开启主语音监听程序;同时,显示模块输出语音波形反馈,提示用户当前正在捕获声音,并有语音输出提示“语音助手已启动”;如识别不到唤醒词,系统不给出任何反馈。
步骤4,所述中央控制系统的语音识别控制程序启动语音录制模块,通过所述语音录制模块录制来自于用户的语音命令,并存储录制到的所述语音命令;同时,在所述语音录制模块录制所述语音命令的过程中,通过显示模块显示语音音量波形;
具体的,中央控制系统在激活状态下,用户采用普通话说出语音命令,中央控制系统既执行“语音录制”操作和“波形反馈”。“语音录制”是为了等待用户完成当前语音信息的表达,并将该语音信息进行内存存储交与语音识别模块进行分析;“波形反馈”是为了给予用户表述语音信息时候录制质量的反馈,如波形不明显,则表示用户语音质量低,提示用户提高音量或拉近与音频采集设备的距离。
步骤5,所述语音录制模块将录制到的所述语音命令传输给语音识别模块;
步骤6,所述语音识别模块对所述语音命令进行初步语音有效性识别,如果识别成功,则执行步骤7;如果未识别成功,则向用户反馈识别失败的提示信息;
具体的,语音录制模块将录制到的语音命令传输给语音识别模块;语音识别模块判断是否识别到信息,如果识别到,进行后续处理;如果没有识别到,则播放语音提示道歉语句,同时显示模块输出提示类语句,如“您可以这样问我…”。
步骤7,所述语音识别模块对所述语音命令进行意图识别,识别出以下四种类型中的一种:快照类型、选项类型、确认/取消类型和其他类型;
如果所述语音命令为快照类型,则通过快照类型子模块执行步骤8;如果所述语音命令为选项类型,则通过选项类型子模块执行步骤9;如果所述语音命令为确认/取消类型,则通过确认/取消类型子模块执行步骤10;如果所述语音命令为其他类型,则通过其他类型子模块执行步骤11;
本发明中,将语音识别的有效结果进行分类,并进行分别处理。分类包括有:快照、选项(多音集合选项)、确认/取消(低于阈值的指令确认)和其他(超出系统处理能力)。
步骤8:通过快照类型子模块执行与快照类型对应的语音命令,包括以下步骤:
步骤8.1,如果所述语音命令为快照类型,得到所述语音命令的识别度分数,并判断所述识别度分数是否超过阈值,如果没有超过,表明所述语音命令不够明确,则执行步骤8.2;如果超过,表明所述语音命令明确,则执行步骤8.3;
步骤8.2,对所述语音命令进行进一步的识别结果唯一性判断,即:判断识别结果是否为多音情况,如果不是,则表明语音命令对应快照库里唯一读音的快照名称,并通过显示模块输出是否执行快照的进一步确认的提示信息,同时,在确认/取消上下文配置表中记录本次确认/取消的对象信息,然后由确认/取消类型子模块执行后续步骤;如果是,则表明语音命令对应快照库里多音的快照名称,并将多音的各个快照名称形成多音快照结果集合,并通过显示模块显示所述多音快照结果集合,同时,在选项上下文配置表中记录本次选项信息,并由所述选项类型子模块执行后续步骤;
步骤8.3,对所述语音命令进行进一步的识别结果唯一性判断,即:判断识别结果是否为多音情况,如果不是,则表明语音命令对应快照库里唯一读音的快照名称,并直接执行与所述快照名称对应的快照场景命令;如果是,则表明语音命令对应快照库里多音的快照名称,并将多音的各个快照名称形成多音快照结果集合,并通过显示模块显示所述多音快照结果集合,同时,在选项配置表中记录本次选项信息,并由所述选项类型子模块执行后续步骤;
每当所述选项上下文配置表存储选项信息后,当任意下一条来自于用户的语音命令被执行后,即清空所述选项上下文配置表;
每当所述确认/取消上下文配置表存储确认/取消的对象信息后,当任意下一条来自于用户的语音命令被执行后,即清空所述确认/取消上下文配置表;
具体的,快照类型子模块将快照类型的语音命令进行“识别分数超过阈值”(该阈值依据是“语音识别”结果的识别度高低)判断,如超过阈值,系统认为该指令明确,进行后续的“识别结果唯一”性判断,如果识别结果唯一,不需要向用户确认,可直接进行快照执行指令;如果识别结果不唯一,表明为多音快照名称,则向用户推送对应的快照名称列表,待用户从列表中选择对应的快照名称后,不再进一步向用户确认,直接进行快照执行指令;如识别度低于阈值,系统认为该指令不够明确,先进行“识别结果唯一”判断,如是识别结果唯一,则仍然需要在显示模块输出提示信息,请用户进一步确认是否执行该快照,系统播放语音提示“是否执行某某快照”。如果是多音情况,则交由多音处理模块处理(多音处理本身也是进一步确认的行为)。
步骤9,通过选项类型子模块执行与选项类型对应的语音命令,包括以下步骤:
如果所述语音命令为选项类型,首先查找所述选项上下文配置表,判断所述选项上下文配置表是否为空,如果不为空,表明存在与所述语音命令对应的上文信息,则根据所述选项上下文配置表中存储的所述选项信息以及所述语音命令,直接执行对应的快照场景命令;如果所述选项上下文配置表为空,则表明不存在上文信息,则通过显示模块输出语音识别失败的提示信息;
具体的,选项类型子模块需要具备上下文记忆能力,当遇到多音快照名称时,系统会进行“多音处理”,提供用户多音快照名称集合选择。系统识别到语音命令为选项类型后,会先基于选项上下文配置表判断是否有上文信息,如果有,则与上一回合对话的选项进行匹配,并将明确的选项进行快照执行,系统语音会给予播放执行某某快照成功的信息,显示设备输出执行某某快照成功的信息。如果没有上文信息,系统设计从拟人角度考虑,当一个没有上文支持的话题,认为该情况是一个非法操作,系统则播放语音提示道歉语句,同时显示设备输出提示类语句,如“您可以这样问我…”。
步骤10,通过确认/取消类型子模块执行与确认/取消类型对应的语音命令,包括以下步骤:
如果所述语音命令为确认/取消类型,首先查找所述确认/取消上下文配置表,判断所述确认/取消上下文配置表是否为空,如果不为空,表明存在与所述语音命令对应的上文信息,则根据所述确认/取消上下文配置表中存储的确认/取消的对象信息以及所述语音命令,直接执行对应的快照场景命令;如果所述确认/取消上下文配置表为空,则表明不存在上文信息,则通过显示模块输出语音识别失败的提示信息;
具体的,确认/取消类型子模块同样是上下文处理情况,用于处理低于语音识别度设定阈值的结果二次确认,系统识别到确认/取消类型后,首先基于确认/取消上下文配置表判断是否有上文信息,如果有上文信息,则进行快照执行,系统语音会给予播放执行某某快照成功的信息,显示设备输出执行某某快照成功的信息。如果没有上文信息,系统设计从拟人角度考虑,当一个没有上文支持的话题,认为该情况是一个非法操作,系统则播放语音提示道歉语句,同时显示设备输出提示类语句,如“您可以这样问我…”。
步骤11,通过其他类型子模块执行与其他类型对应的语音命令,包括以下步骤:通过显示模块输出语音识别失败的提示信息。
具体的,当语音命令为其他类型时,系统设计认为是超出了系统处理能力,统一处理为:系统播放语音提示道歉语句,同时显示设备输出提示类语句,如“您可以这样问我…”。
在本发明各步骤中,当通过显示模块输出语音识别失败的提示信息具体为:播放语音提示道歉语句,同时输出更换语音命令的提示类语句。
本发明中,在意图识别过程中,当判断出当前用户意图为快照类型后会进行“识别结果唯一”判断,结果如“是”,表示该结果在快照库里为唯一读音的快照名称,则直接执行该快照,系统语音会给予播放执行某某快照成功的信息,显示设备输出执行某某快照成功的信息;如“否”,则表示该结果在快照库里不是唯一读音的快照名称,系统会将所有该读音的快照集合通过显示设备列出选项让用户选择,并有语音反馈输出提示用户,如“请按照屏幕显示说出或点击项目编号”。例如,当识别到来自于用户的语音命令为“惠宜模式”时,系统搜索到的快照集合为“惠宜模式、会议模式1、会议模式2”,然后,系统以列表的形式显示“惠宜模式、会议模式1、会议模式2”,如果用户选择执行会议模式1,则“会议模式1”被点击,系统即执行与“会议模式1”对应的快照场景执行命令。
本发明提供的一种基于语音识别的场景交互控制方法具有以下特点:
1、系统在完成某些任务后均会及时关闭语音监听程序,避免现场环境复杂的声音对系统造成误操作,用户可使用声音或手动点击的方式快捷的唤醒智能语音识别系统。
用户在语音控制系统激活模式下,说出含有有效快照名字的语音命令即可控制现场设备,如说出“启动监控模式”、“执行会议模式”、“打开模式一”)等即可,具有用户操作简单的优点,从而提高用户的使用体验;
2、语音反馈机制:本方法注重用户交互体验,为用户在使用中说出的各种情况均提供了有效反馈信息,引导用户正确使用语音控制系统。
具体的:
1)高质的语音:当系统收到清晰、标准的语音命令时,系统视为安全、可确认的命令,将直接执行用户意图的任务。
2)一般的语音如果识别到的语音质量低于优秀语音分值时,系统为保证现场设备安全和其他问题的发生,先将语音识别出的任务与用户确认,用户可手动点击或说出提示命令词确认或取消该项任务。
3)多音词的命令:当系统内有多音模式被识别到时,系统会反馈给用户选项,请用户手动点击或说出选项。
4)超出有效场景关键词范围:系统对于用户说出知识范围外(听不懂)的情况,会有提示页面引导用户可参考的例句。
3、上下文能力:本方法在应对多识别结果(多音词)的情况,可将识别结果临时储存在计算机内存,待用户回答确认消息后再进行后续处理,实现了模拟人类的上下文的语言交流能力。
4、本系统支持动态加载新建的快照名字关键词。当用户新建一个快照并为该模式命名,保存成功后,语音识别系统即时支持该快照的语音识别功能。
因此,本发明提供的一种基于语音识别的场景交互控制方法,将中央控制系统和语音识别技术结合,实现了用语言代替传统输入设备控制中央控制系统的功能,具有用户体验好的优点。
本发明方法为一种辅助类的交互手段,采用人类最原始的表达语音作为消息传达媒介,是人机交互的最佳方式之一。将语音识别和中控控制系统结合将会更进一步提升商业控制现场的建设价值和科技感。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!