一种伴奏纯净度评估方法以及相关设备与流程
本发明涉及计算机技术领域,尤其涉及一种伴奏纯净度评估方法以及相关设备。
背景技术:
随着生活水平和科技水平的提高,人们已经能够通过移动终端(如手机)实现随时随地想唱就唱的目的。这就需要伴奏给用户提供唱歌支持,如果所唱歌曲的伴奏是原版伴奏,其纯净度高,给人以优美的体验;而如果所唱歌曲的伴奏是消音伴奏,其纯净度低,包含较多的背景噪声,会大大降低用户体验。
这些消音伴奏的产生原因是:一方面是很多老歌因为发行年代久远并不存在与其对应的原版伴奏,或者发行年代较新的新歌难以获取到对应的原版伴奏;另一方面是因为音频技术的不断发展,使得人们能够通过音频技术处理一些原唱歌曲,从而获得消音伴奏,而通过音频技术处理得到的消音伴奏仍然存在较多的背景噪声,使得主观听感上比原版伴奏要差。
目前,消音伴奏已经在网络中大量出现,音乐内容提供方主要依靠人工标记的方法来分辨消音伴奏,其效率、准确率都较低,且需要消耗大量的人力成本。如何高效准确地分辨消音伴奏和原版伴奏目前仍为一种严峻的技术挑战。
技术实现要素:
本发明实施例提供一种伴奏纯净度评估方法,可实现高效准确地分辨歌曲伴奏是纯器乐伴奏还是存在背景噪声的器乐伴奏。
第一方面,本发明实施例提供了一种伴奏纯净度评估方法,该方法包括:
获取多个第一伴奏数据以及各个第一伴奏数据对应的标签;所述各个第一伴奏数据对应的标签用于指示对应的第一伴奏数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据;
提取所述各个第一伴奏数据的音频特征;
根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,获得用于伴奏纯净度评估的神经网络模型;所述神经网络模型的模型参数是由所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签之间的关联关系确定的。
在一些实施例中,在提取所述各个第一伴奏数据的音频特征之前,所述方法还包括:对所述各个第一伴奏数据进行调整,以使所述各个第一伴奏数据的播放时长与预设播放时长相符;对所述各个第一伴奏数据进行归一化处理,以使所述各个第一伴奏数据的音强符合预设音强。
在一些实施例中,在根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练之前,所述方法还包括:根据Z-score算法对所述各个第一伴奏数据的音频特征进行处理,以使所述各个第一伴奏数据的音频特征标准化;其中所述各个第一伴奏数据的标准化后的音频特征符合正态分布。
在一些实施例中,在获得用于伴奏纯净度评估的神经网络模型之后,所述方法还包括:获取多个第二伴奏数据的音频特征以及各个第二伴奏数据的对应的标签;将所述多个第二伴奏数据的音频特征输入到所述神经网路模型中,以获得各个第二伴奏数据的评估结果;根据所述各个第二伴奏数据的评估结果与所述各个第二伴奏数据的对应的标签的差距,获得所述神经网络模型的准确率;在所述神经网络模型的准确率低于预设阈值的情况下,调节模型参数重新对所述神经网络模型进行训练,直至所述神经网络模型的准确率大于等于预设阈值,且所述模型参数的变化幅度小于等于预设幅度。
在一些实施例中,所述音频特征包括:梅尔频谱特征、相关谱感知线性预测特征、谱熵特征、感知线性预测特征中的任意一种或者任意多种组合。
第二方面,本发明还提供另一种伴奏纯净度评估方法,该方法包括:
获取待检测数据,所述待检测数据包括伴奏数据;
提取所述伴奏数据的音频特征;
将所述音频特征输入到神经网络模型中,获得所述伴奏数据的纯净度评估结果;所述评估结果用于指示所述待检测数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据,所述神经网络模型是根据多个样本训练得到的,所述多个样本包括多个伴奏数据的音频特征以及各个伴奏数据对应的标签,所述神经网络模型的模型参数是由所述各个伴奏数据的音频特征以及各个伴奏数据对应的标签之间的关联关系确定的。
在一些实施例中,在提取所述伴奏数据的音频特征之前,所述方法还包括:对所述伴奏数据进行调整,以使所述伴奏数据的播放时长与预设播放时长相符;对所述伴奏数据进行归一化处理,以使所述伴奏数据的音强符合预设音强。
在一些实施例中,在将所述音频特征输入到神经网络模型中之前,所述方法还包括:根据Z-score算法对所述伴奏数据的音频特征进行处理,以使所述伴奏数据的音频特征标准化;其中所述伴奏数据标准化后的音频特征符合正太分布。
在一些实施例中,在获得所述伴奏数据的纯净度评估结果之后,所述方法还包括:若所述伴奏数据的纯净度大于或等于预设阈值,确定所述纯净度评估结果为所述纯器乐伴奏数据;若所述待检测伴奏数据的的纯净度小于所述预设阈值,确定所述纯净度评估结果为所述存在背景噪声的器乐伴奏数据。
第三方面,本发明还提供一种伴奏纯净度评估装置,该装置包括:
通信模块,用于获取多个第一伴奏数据以及各个第一伴奏数据对应的标签;所述各个第一伴奏数据对应的标签用于指示对应的第一伴奏数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据;
特征提取模块,用于提取所述各个第一伴奏数据的音频特征;
训练模块,用于根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,获得用于伴奏纯净度评估的神经网络模型;所述神经网络模型的模型参数是由所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签之间的关联关系确定的。
在一些实施例中,所述装置还包括数据优化模块,所述数据优化模块用于,对所述各个第一伴奏数据进行调整,以使所述各个第一伴奏数据的播放时长与预设播放时长相符;对所述各个第一伴奏数据进行归一化处理,以使所述各个第一伴奏数据的音强符合预设音强。
在一些实施例中,所述装置还包括特征标准化模块,所述特征标准化模块用于,在根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练之前,根据Z-score算法对所述各个第一伴奏数据的音频特征进行处理,以使所述各个第一伴奏数据的音频特征标准化;其中所述各个第一伴奏数据的标准化后的音频特征符合正态分布。
在一些实施例中,所述装置还包括验证模块,所述验证模块用于:获取多个第二伴奏数据的音频特征以及各个第二伴奏数据的对应的标签;将所述多个第二伴奏数据的音频特征输入到所述神经网路模型中,以获得各个第二伴奏数据的评估结果;根据所述各个第二伴奏数据的评估结果与所述各个第二伴奏数据的对应的标签的差距,获得所述神经网络模型的准确率;在所述神经网络模型的准确率低于预设阈值的情况下,调节模型参数重新对所述神经网络模型进行训练,直至所述神经网络模型的准确率大于等于预设阈值,且所述模型参数的变化幅度小于等于预设幅度。
在一些实施例中,所述音频特征包括:梅尔频谱特征、相关谱感知线性预测特征、谱熵特征、感知线性预测特征中的任意一种或者任意多种组合。
第四方面,提供一种伴奏纯净度评估装置,所述装置包括:
通信模块,用于获取待检测数据,所述待检测数据包括伴奏数据;
特征提取模块,用于提取所述伴奏数据的音频特征;
评估模块,用于将所述音频特征输入到神经网络模型中,获得所述伴奏数据的纯净度评估结果;所述评估结果用于指示所述待检测数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据,所述神经网络模型是根据多个样本训练得到的,所述多个样本包括多个伴奏数据的音频特征以及各个伴奏数据对应的标签,所述神经网络模型的模型参数是由所述各个伴奏数据的音频特征以及各个伴奏数据对应的标签之间的关联关系确定的。
在一些实施例中,所述装置还包括数据优化模块,所述数据优化模块用于,在提取所述伴奏数据的音频特征之前,对所述伴奏数据进行调整,以使所述伴奏数据的播放时长与预设播放时长相符;对所述伴奏数据进行归一化处理,以使所述伴奏数据的音强符合预设音强。
在一些实施例中,所述装置还包括特征标准化模块,所述特征标准化模块用于,在将所述音频特征输入到神经网络模型中之前,根据Z-score算法对所述伴奏数据的音频特征进行处理,以使所述伴奏数据的音频特征标准化;其中所述伴奏数据标准化后的音频特征符合正太分布。
在一些实施例中,所述评估单元还用于,若所述伴奏数据的纯净度大于或等于预设阈值,确定所述纯净度评估结果为所述纯器乐伴奏数据;若所述待检测伴奏数据的的纯净度小于所述预设阈值,确定所述纯净度评估结果为所述存在背景噪声的器乐伴奏数据。
第五方面,提供了一种电子设备,该电子设备包括处理器和存储器,所述处理器和存储器相互连接,其中,所述存储器用于存储计算机程序,所述计算机程序包括程序指令,所述处理器被配置用于调用所述程序指令,执行第一方面任一实施例所述的方法,和/或,执行第二方面任一实施例所述的方法。
第六方面,提供了一种计算机可读存储介质,所述计算机存储介质存储有计算机程序,所述计算机程序包括程序指令,所述程序指令当被处理器执行时使所述处理器执行第一方面任一实施例所述的方法,和/或,执行第二方面任一实施例所述的方法。
本发明实施例中,先提取纯器乐伴奏数据的音频特征以及提取存在背景噪声的器乐伴奏数据的音频特征,然后使用提取到音频特征以及音频特征对应的标签对神经网络模型进行训练,获得用于伴奏纯净度评估的神经网络模型,接着就可以基于所述神经网络模型对待检测的伴奏数据的纯净度进行评估,从而得到所述待检测的伴奏数据纯净度。通过实施本发明实施例,可实现高效准确地分辨歌曲伴奏是纯器乐伴奏还是存在背景噪声的器乐伴奏。
附图说明
为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
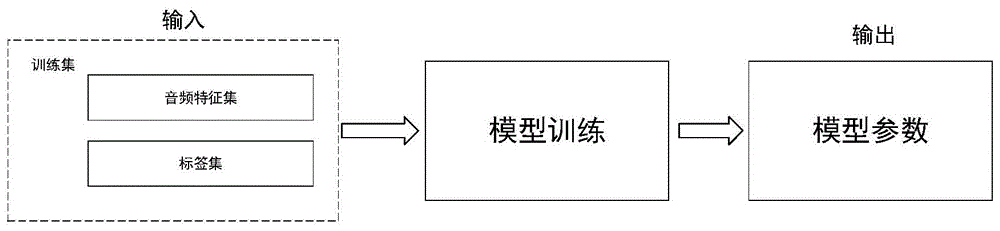
图1是本发明实施例提供的一种神经网络模型训练过程架构示意图;
图2是本发明实施例提供的一种神经网络模型验证过程架构示意图;
图3是本发明实施例提供的一种基于神经网络模型的伴奏纯净度评估架构示意图;
图4是本发明实施例提供的一种伴奏纯净度评估方法的示意流程图;
图5是本发明实施例提供的一种神经网络模型的结构示意图;
图6是本发明另一实施例提供的一种伴奏纯净度评估方法的示意流程图;
图7是本发明另一实施例提供的一种伴奏纯净度评估方法的示意流程图;
图8是本发明另一实施例提供的一种伴奏纯净度评估装置的结构示意图;
图9是本发明另一实施例提供的一种伴奏纯净度评估装置的结构示意图;
图10是本发明实施例提供的一种电子设备硬件结构示意性框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的说明书和权利要求书及上述附图中的术语“包括”和“具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产品或设备固有的其他步骤或单元。
为了便于本发明的理解,下面介绍本发明实施例涉及的架构。
参见图1,图1是本发明实施例提供的一种神经网络模型训练过程架构示意图,由图1可知,服务器将训练集中的音频特征集以及音频特征集对应的标签集输入到神经网络模型中进行模型训练,以获得所述神经网络模型的模型参数。所述训练集中的音频特征集可以从各个原版伴奏数据和各个消音伴奏数据中提取得到的,所述原版伴奏数据为纯器乐伴奏数据,所述消音伴奏数据是根据消音软件去除原创歌曲中人声部分获得的,然而消音伴奏数据仍然存在部分背景噪声。所述标签集用于指示对应的音频特征是来自原版伴奏数据或消音伴奏数据。
参见图2,图2是本发明实施例提供的一种神经网络模型验证过程架构示意图,由图2可知,服务器将验证集中的音频特征集输入到经过图1训练集训练得到的神经网络模型中,从而获得所述音频特征集合中各个音频特征的伴奏纯净度评估结果,并将所述各个音频特征的伴奏纯净度评估结果与所述标签集对应的标签进行比较,从而获得所述神经网络模型对验证集的准确率,并根据所述准确率评估所述神经网络模型是否训练完成。所述验证集中的音频特征集同样可以从原版伴奏数据和消音伴奏数据中提取得到的,所述原版伴奏数据、消音伴奏数据、以及标签集的描述可参考上文的描述,为了简洁,这里不再赘述。
参加图3,图3是本发明实施例提供的一种基于神经网络模型的伴奏纯净度评估架构示意图,在经过图1的模型训练以及图2的模型评估以后,所述服务器获得训练完成的神经网络模型。因此,若需要对待检测伴奏数据进行评估时,所述服务器将获取到的待检测伴奏数据的音频特征输入到所述训练好的神经网络模型中,通过神经网络模型对所述待检测伴奏数据的音频特征的评估,即可获得所述伴奏数据的纯净度评估结果。
首先需要说明的,为了便于本发明实施例的描述,将本发明实施例的执行主体称为服务器。
下面结合附图详细描述本发明实施例提供的伴奏纯净度评估方法,该方法可实现高效准确地分辨消音伴奏和原版伴奏。
参见图4,图4是本发明实施例提供的一种伴奏纯净度评估方法的流程示意图。该过程包括但不限于以下步骤:
S101、获取多个第一伴奏数据以及各个第一伴奏数据对应的标签。
在本发明实施例中,所述多个第一伴奏数据包括原版伴奏数据和消音伴奏数据,相应地,所述各个第一伴奏数据对应的标签可以包括原版伴奏数据标签和消音伴奏数据标签,例如,可以将所述原版伴奏数据的标签设置为1,将消音伴奏数据的标签设置为0。需要说明的,所述原版伴奏数据可以是纯器乐伴奏数据,所述消音伴奏数据可以是存在背景噪声的器乐伴奏数据。在一些具体的实施例中,所述消音伴奏数据可以根据特定的消音技术去除原创歌曲中的人声部分获得,一般情况下,消音版伴奏音质比较差,音乐中的模配乐部分比较糊,不清晰,只能听到大致的旋律。
在一些实施例中,所述获取多个第一伴奏数据以及各个第一伴奏数据对应的标签,可以通过如下方式实现:服务器可以从本地音乐数据库中获取多个第一伴奏数据以及相应获取各个第一伴奏数据对应的标签,并将各个第一伴奏数据与该伴奏数据对应的标签绑定。所述服务器还可以通过有线或者无线的方式接收其他服务器发送的多个第一伴奏数据以及各个第一伴奏数据对应的标签,具体的,无线的方式可以包括传输控制协议(TCP,Transmission Control Protocol),用户数据报协议(User Datagram Protocol,UDP),超文本传输协议(HTTP,Hyper Text Transfer Protocol),文件传输协议(File Transfer Protocol,FTP)等通信协议中的一种或者任意多种组合。另外,所述服务器还可以通过网络爬虫,从网络中获取所述多个第一伴奏数据以及各个第一伴奏数据对应的标签。应理解,上述例子仅仅用于举例,本发明不限定获取多个第一伴奏数据以及各个第一伴奏数据对应的标签的具体方式。
在本发明实施例中,所述第一伴奏数据的音频格式可以是MP3(MPEG_Audio_Layer3)、FLAC(Free Lossless Audio Codec)、WAV(WAVE)、OGG(oggVorbis)等音频格式中的任意一种。另外,所述第一伴奏数据的声道可以是单声道、双声道、多声道中的任意一种。应理解,上述例子仅仅用于举例,本发明对第一伴奏数据的音频格式和声道数量不做具体限定。
S102、提取各个第一伴奏数据的音频特征。
在一些实施例中,提取所述各个第一伴奏数据的音频特征包括:梅尔频谱特征(Mel Frequency Cepstrum Coefficient,MFCC)、相关谱感知线性预测特征(RelAtiveSpecTrAPerceptual Linear Predictive,RASTA-PLP)、谱熵特征(Spectral Entropy)、感知线性预测特征(Perceptual Linear Predictive,PLP)中的任意一种或者任意多种组合。需要说明的,从音频数据中提取上述各个音频特征可以通过一些开源的算法库对应的特征提取算法实现,属于音频领域从业人员所熟知的方法,但是需要理解的,开源算法库中提取音频特征的算法极其繁多,不同的音频特征具有不同的表征意义,例如有的音频特征能够表征音频数据的音色,有的音频特征能够表征音频数据的音调等。而在本方案中,提取到的音频特征要能够表征伴奏数据的纯净度,换句话说,提取到的音频特征所代表的特点能够将纯器乐伴奏数据和存在背景噪声的伴奏数据明显地区分开。而通过上述所列举的音频特征中的一种或者多种组合能够较优地获得代表伴奏数据纯净度的特点。另外,应理解的,本发明提取各个第一伴奏数据的音频特征还可以是其他的音频特征,本发明对此不做具体限定。
S103、根据各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,获得用于伴奏纯净度评估的神经网络模型。
在一些实施例中,建立所述神经网络模型,所述神经网络模型为卷积神经网络模型,具体可参见图5,图5是本发明实施例提供的卷积神经网络结构示意图,所述卷积神经网络模型包括:输入层,中间层,全局平均池化层,激活层,DropOut层,以及输出层等,其中所述输入层的输入可以是各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签;所述中间层可以包括N个子层,每个子层包括至少一个卷积层和至少一个池化层,所述卷积层用于对所述第一伴奏数据的音频特征进行局部采样,从而获得所述音频特征不同维度的特征信息,所述池化层用于对所述音频特征不同维度的特征信息进行下采样,从而对所述特征信息进行降维,以防止所述卷积神经网络模型过拟合;所述全局平均池化层用于对所述中间层的N个子层输出的特征信息进行降维,以防止所述卷积神经网络过拟合;所述激活层用于增加所述卷积神经网络模型的非线性结构;所述DropOut层用于在训练过程中每次更新参数时按照一定的概率随机断开输入神经元,以防止所述卷积神经网络模型过拟合;所述输入层用于输入所述卷积神经网络模型的分类结果。
在一些实施例中,所述卷积神经网络模型还可以是其他卷积神经网络模型,例如可以是LeNet、AlexNet、GoogLeNet、VGGNet、ResNet等任意类型的神经网络模型,本发明对卷积神经网络的类型不做具体限定。
在本发明实施例中,在完成建立所述卷积神经网络模型之后,所述服务器根据各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签对所述卷积神经网络模型进行模型训练,获得用于伴奏纯净度评估的神经网络模型,其中所述神经网络模型的模型参数是由所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签之间的关联关系确定的。具体的,所述服务器将所述多个第一伴奏的音频特征封装成一个音频特征集,以及将所述各个第一伴奏数据对应的标签封装成一个标签集,其中所述特征集中的各个音频特征与所述标签集中的各个标签一一对应,所述特征集中的各个音频特征顺序可以与该音频特征对应的标签在标签集中的顺序相同,每一个音频特征以及该音频特征对应的标签构成一个训练样本。所述服务器将所述特征集和所述标签集输入到所述卷积神经网络模型中进行模型训练,以使所述卷积神经网络模型根据所述特征集和所述标签集进行学习并拟合模型参数,而模型参数是由所述特征集中的各个音频特征以及标签集中的各个标签之间的关联关系确定的。
在本发明实施例中,服务器先获取多个第一伴奏数据以及各个第一伴奏数据对应的标签,然后提取获取到的各个第一伴奏数据的音频特征,并根据提取到的各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,从而得到可用于伴奏纯净度评估的神经网络模型。相比于常规方案中基于人工筛选的方式来识别伴奏的纯净度,本方案中可利用所述神经网络模型来进行伴奏纯净度评估,进而分辨出所述伴奏是纯器乐伴奏的原版伴奏数据还是存在背景噪声的消音伴奏数据。若需要对大量伴奏数据的纯净度进行识别时,本方案在实现上较为经济,且在效率及识别的准确率更高。
参见图6,图6是本发明另一实施例提供的一种伴奏纯净度评估方法的示意流程图。该过程包括但不限于以下步骤:
S201、获取多个第一伴奏数据以及各个第一伴奏数据对应的标签。
在一些实施例中,步骤S201中多个第一伴奏数据以及各个第一伴奏数据对应的标签的描述可以参考图4方法实施例S101中的描述,为了简洁,这里不再赘述。
在一些实施例中,在获取多个第一伴奏数据以及各个第一伴奏数据对应的标签之后,所述服务器根据各个第一伴奏数据对应的标签,将所述多个第一伴奏数据划分为纯器乐伴奏数据以及存在背景噪声的纯器乐伴奏数据,然后根据预设比例将纯器乐伴奏数据分为正样本训练数据集、正样本验证数据集、正样本测试数据集,以及根据同样的预设比例将存在背景噪声的器乐伴奏数据分为负样本训练数据集、负样本验证数据集、负样本测试数据集。具体的,例如第一伴奏数据包括5万个正样本(纯器乐伴奏数据)以及5万个负样本(存在背景噪声的器乐伴奏数据),所述服务器根据8:1:1的比例,从5万个正样本中随机抽样,从而得到正样本训练数据集、正样本验证数据集、正样本测试数据集,同样的,所述服务器根据8:1:1的比例,从5万个负样本中随机抽样,从而得到负样本训练数据集、负样本验证数据集、负样本测试数据集。
S202、对各个第一伴奏数据进行调整,以使各个第一伴奏数据的播放时长与预设播放时长相符。
在一些实施例中,所述服务器对各个第一伴奏数据进行音频解码,从而获得各个第一伴奏数据的声音波形数据,然后根据所述声音波形数据剔除各个第一伴奏数据中开头和结尾的静音部分。由于消音伴奏(即前文描述的存在背景噪声的器乐伴奏数据)可以是通过音频技术对原创歌曲去除人声部分得到的,而原创歌曲在开头部分往往为纯器乐伴奏,不包括人声部分,因此大多数消音伴奏的开头部分音质较好。而通过大数据统计可知,消音伴奏往往从剔除开头静音部分以后的再过30秒音质才开始变差,为了让神经网络有针对性地学习消音伴奏的音频特征,在本发明实施中,除了剔除各个第一伴奏数据中开头和结尾的静音部分,还去除了开头静音部分以后的30秒音频数据,然后开始读取剩余部分长度为100秒的数据,对于剩余部分超多100秒的数据,采取舍前不舍后,对于剩余部分少于100秒的数据,在剩余部分的末尾进行补零操作。上述操作的目的在于:一是提取各个第一伴奏数据中的核心部分以使神经网络模型有针对性地学习,二是让各个第一伴奏数据的播放时长相同,以排除他因影响神经网络模型的学习方向。
S203、对各个第一伴奏数据进行归一化处理,以使各个第一伴奏数据的音强符合预设音强。
在一些实施例中,由于不同的伴奏是通过不同的音频设备录制的,因而即使在相同的终端设备设置了相同的播放音量,不同的伴奏的声音大小各有差异。为了避免引入音强的差异导致神经网络模型的模型参数有所差异,本发明实施例中,所述服务器在对各个第一伴奏数据进行调整,以使各个第一伴奏数据的播放时长与预设播放时长相符之后,还对调整后的各个第一伴奏数据进行时域的幅度归一化,以及进行频域的能量归一化,从而使得各个第一伴奏数据的音强统一化,并且符合预设音强。
S204、提取各个第一伴奏数据的音频特征。
在本发明实施中,步骤S204的提取各个第一伴奏数据的音频特征可以参考图4方法实施例中步骤S102的描述,为了简洁,这里不再赘述。
在一些实施例中,将各个第一伴奏数据的音频特征以矩阵的形式存储,具体的,存储数据格式可以包括:numpy格式,h5格式等数据格式,本发明对音频特征的存储数据格式不做具体限定。
S205、根据阿特曼(Z-score)算法对各个第一伴奏数据的音频特征进行处理,以使各个第一伴奏数据的音频特征标准化。
在一些实施例中,根据公式(1)对各个第一伴奏数据的音频特征进行数据的标准化处理,从而使得超出取值范围的离群音频特征收敛在所述取值范围内,其中所述公式(1)为所述Z-score算法的公式,其中X’为新数据,这里对应标准化处理后的第一伴奏数据,X为原数据,这里对应第一伴奏数据的音频特征,μ为原数据的均值,这里对应为各个第一伴奏数据的音频特征的特征均值,b为标准差,这里对应为各个第一伴奏数据的音频特征的标准差。
通过上述公式(1)对各个第一伴奏数据的音频特征进行标准化处理后,各个第一伴奏数据的音频特征均符合标准的正太分布规律。
S206、根据各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,获得用于伴奏纯净度评估的神经网络模型。
在本发明实施例中,步骤S206的描述可以参考图4方法实施例中步骤S103的描述,为了简洁,这里不再赘述。
在一些实施例中,在获得用于伴奏纯净度评估的神经网络模型之后,获取正样本验证数据集对应的音频特征集、负样本验证数据集对应的音频特征集以及正样本验证数据集对应的标签集、负样本验证数据集对应的标签集,其中正样本验证数据集中的各个数据为原版伴奏(纯器乐伴奏),负样本验证数据集中的各个数据为消音伴奏(存在背景噪声的器乐伴奏);然后所述服务器将正样本验证数据集对应的音频特征集以及负样本验证数据集对应的音频特征集输入到所述神经网路模型中,以获得各个伴奏数据的评估结果,其中所述评估结果为所述各个伴奏数据纯净度评分;所述服务器再根据所述各个伴奏数据纯净度评分以及所述各个第二伴奏数据的对应的标签的差距,获得所述神经网络模型的准确率;在所述神经网络模型的准确率低于预设阈值的情况下,调节模型参数重新对所述神经网络模型进行训练,直至所述神经网络模型的准确率大于等于预设阈值,且所述模型参数的变化幅度小于等于预设幅度,其中所述模型参数包括损失函数的输出以及模型的学习率等。
在另一些实施例中,在停止所述神经网络的训练后,获取正样本测试数据集对应的音频特征集以及标签集、负样本测试数据集对应的音频特征集以及标签集,然后基于所述正样本测试数据集对应的音频特征集以及标签集、负样本测试数据集对应的音频特征集以及标签集对所述神经网络模型进行评估,以评价所述神经网络模型是否具备伴奏纯净度评估的能力。
在本发明实施例中,服务器先获取多个第一伴奏数据以及各个第一伴奏数据对应的标签,然后对多个第一伴奏数据的播放时长以及播放音强统一化为预设播放时长以及预设播放音强,以排除他因影响神经网络模型的训练,接着对统一化后的各个第一伴奏数据进行提取音频特征并将该音频特征进行标准化处理,以使得各个音频特征都符合正太分布规律,然后根据上述操作获得的各个音频特征以及各个音频特征对应的标签对神经网络模型进行训练,从而得到可用于伴奏纯净度评估的神经网络模型。通过实施本发明实施例,可进一步提高所述神经网络模型对伴奏纯净度识别的准确率。
参见图7,图7是本发明另一实施例提供的一种伴奏纯净度评估方法的示意流程图。该过程包括但不限于以下步骤:
S301、获取待检测数据,所述待检测数据包括伴奏数据。
在本发明实施中,所述待检测数据包括伴奏数据,所述获取待检测数据,可以通过如下方式实现:服务器可以从本地音乐数据库中获取待检测数据;所述服务器还可以通过有线或者无线的方式接收其他终端设备发送的待检测伴奏数据,具体的,无线的方式可以包括TCP协议,UDP协议,HTTP协议,FTP协议等通信协议中的一种或者任意多种组合。
在一些实施例中,所述待检测数据的音频格式可以是MP3、FLAC、WAV、OGG等音频格式中的任意一种。另外,所述待检测数据的声道可以是单声道、双声道、多声道中的任意一种。应理解,上述例子仅仅用于举例,本发明对待检测数据的音频格式和声道数量不做具体限定。
S302、提取所述伴奏数据的音频特征。
在一些实施例中,提取所述伴奏数据的音频特征包括:梅尔频谱特征(Mel Frequency Cepstrum Coefficient,MFCC)、相关谱感知线性预测特征(RelAtiveSpecTrAPerceptual Linear Predictive,RASTA-PLP)、谱熵特征(Spectral Entropy)、感知线性预测特征(Perceptual Linear Predictive,PLP)中的任意一种或者任意多种组合。需要说明的,这里提取所述伴奏数据的音频特征的类型应与图4方法实施例步骤S102以及图6方法实施步骤S204中提取各个第一伴奏数据的音频特征的类型一致,举例来说,例如图4以及图6方法实施例中均提取了第一伴奏数据中的MFCC特征、RASTA-PLP特征、谱熵特征以及PLP特征,则相应地,这里同样需要提取伴奏数据中上述4种类型的音频特征。
在一些实施例中,在提取所述伴奏数据的音频特征之前,所述服务器对所述伴奏数据进行调整,以使所述伴奏数据的播放时长与预设播放时长相符;并且所述服务器还对所述伴奏数据进行归一化处理,以使所述伴奏数据的音强符合预设音强。
在一些实施例中,所述服务器对所述伴奏数据进行音频解码,从而获得所述伴奏数据的声音波形数据,然后根据所述声音波形数据剔除所述伴奏数据中开头和结尾的静音部分。通过大数据统计可知,消音伴奏往往从剔除开头静音部分以后的再过30秒音质才开始变差,为了让神经网络有针对性地学习消音伴奏的音频特征,在本发明实施中,除了剔除各个第一伴奏数据中开头和结尾的静音部分,还剔除了开头静音部分以后的30秒音频数据,然后开始读取剩余部分长度为100秒的数据,对于剩余部分超多100秒的数据,采取舍前不舍后,对于剩余部分少于100秒的数据,在剩余部分的末尾进行补零操作。
在一些实施例中,由于不同的伴奏是通过不同的音频设备录制的,因而即使在相同的终端设备设置了相同的播放音量,不同的伴奏的声音大小各有差异。为了避免引入音强的差异导致神经网络模型的评估结果存在误差,本发明实施例中,所述服务器在对伴奏数据进行调整,以使伴奏数据的播放时长与预设播放时长相符之后,还对调整后的伴奏数据进行时域的幅度归一化,以及进行频域的能量归一化,从而使得伴奏数据的音强统一化,并且符合预设音强。
在一些实施例中,由于提取所述伴奏数据的音频特征包括不同维度的子特征,例如所述伴奏数据的音频特征包括500个子特征,而在这500个子特征中的最大值以及最小值均不能确定,500个子特征存在超过预设取值范围。因此,在将所述伴奏数据的音频特征输入到神经网络模型之前,根据公式(1)对所述伴奏数据的音频特征进行数据的标准化处理,从而使得超出取值范围的离群音频特征收敛在所述取值范围内,进而使得所述伴奏数据的音频特征中的各个子特征符合正太分布规律。
S303、将所述音频特征输入到神经网络模型中,获得所述伴奏数据的纯净度评估结果。
在本发明实施中,所述评估结果用于指示所述待检测数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据,所述神经网络模型是根据多个样本训练得到的,所述多个样本包括多个伴奏数据的音频特征以及各个伴奏数据对应的标签,所述神经网络模型的模型参数是由所述各个伴奏数据的音频特征以及各个伴奏数据对应的标签之间的关联关系确定的。
在一些实施例中,所述神经网络模型的训练方法可以参考图4方法实施例的描述,或者参考图6方法实施例的描述,为了简洁,这里不再赘述。
在一些实施例中,在获得所述伴奏数据的纯净度评估结果之后,所述方法还包括:若所述伴奏数据的纯净度大于或等于预设阈值,确定所述纯净度评估结果为所述纯器乐伴奏数据;若所述待检测伴奏数据的的纯净度小于所述预设阈值,确定所述纯净度评估结果为所述存在背景噪声的器乐伴奏数据。具体的,举例来说,若所述预设阈值为0.9,则当从所述神经网络模型中获得的纯净度评分大于或等于0.9,则可以确定所述伴奏数据为纯器乐伴奏数据,当从所述神经网络模型中获得的纯净度评分小于0.9,则可以确定所述伴奏数据为存在背景噪声的器乐伴奏数据。
在一些实施例中,在获得所述伴奏数据的纯净度评估结果之后,所述服务器将所述纯净度评估结果发送至对应的终端设备,以使所述终端设备将纯净度评估结果显示在终端设备的显示装置中,或者,所述服务器将所述纯净度评估结果存储至相应地的磁盘中。
本发明实施例中,服务器先获取待检测的伴奏数据,然后提取所述伴奏数据中的音频特征,并将提取到所述音频特征输入到训练好的用于伴奏纯净度评估的神经网络模型中,就能获得待检测的伴奏数据的纯净度评估结果,而通过纯净度评估结果就能确定待检测的伴奏数据是纯器乐伴奏数据或存在背景噪声的器乐伴奏数据。通过实施上述实施例,以神经网络模型来分辨待检测伴奏数据的纯净度,相比于人工分辨伴奏纯净度的方式,本方案在实现上不仅效率更高成本更低,而且分辨伴奏纯净度的准确度以及精度都更高。
上文描述了本发明实施例的相关方法,基于相同的发明构思,下面描述本发明实施例的相关装置。
参见图8,图8是本发明实施例提供的一种伴奏纯净度评估装置的结构示意图。如图8所示,伴奏纯净度评估装置800,包括:
通信模块801,用于获取多个第一伴奏数据以及各个第一伴奏数据对应的标签;所述各个第一伴奏数据对应的标签用于指示对应的第一伴奏数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据;
特征提取模块802,用于提取所述各个第一伴奏数据的音频特征;
训练模块803,用于根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,获得用于伴奏纯净度评估的神经网络模型;所述神经网络模型的模型参数是由所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签之间的关联关系确定的。
可能实施例中,所述装置还包括数据优化模块804,所述数据优化模块804用于,对所述各个第一伴奏数据进行调整,以使所述各个第一伴奏数据的播放时长与预设播放时长相符;对所述各个第一伴奏数据进行归一化处理,以使所述各个第一伴奏数据的音强符合预设音强。
可能实施例中,所述装置还包括特征标准化模块805,所述特征标准化模块805用于,在根据所述各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练之前,根据Z-score算法对所述各个第一伴奏数据的音频特征进行处理,以使所述各个第一伴奏数据的音频特征标准化;其中所述各个第一伴奏数据的标准化后的音频特征符合正态分布。
可能实施例中,所述装置还包括验证模块806,所述验证模块806用于:获取多个第二伴奏数据的音频特征以及各个第二伴奏数据的对应的标签;将所述多个第二伴奏数据的音频特征输入到所述神经网路模型中,以获得各个第二伴奏数据的评估结果;根据所述各个第二伴奏数据的评估结果与所述各个第二伴奏数据的对应的标签的差距,获得所述神经网络模型的准确率;在所述神经网络模型的准确率低于预设阈值的情况下,调节模型参数重新对所述神经网络模型进行训练,直至所述神经网络模型的准确率大于等于预设阈值,且所述模型参数的变化幅度小于等于预设幅度。
可能实施例中,所述音频特征包括:梅尔频谱特征、相关谱感知线性预测特征、谱熵特征、感知线性预测特征中的任意一种或者任意多种组合。
在本发明实施例中,所述纯净度评估装置800先获取多个第一伴奏数据以及各个第一伴奏数据对应的标签,然后提取获取到的各个第一伴奏数据的音频特征,并根据提取到的各个第一伴奏数据的音频特征以及各个第一伴奏数据对应的标签进行模型训练,从而得到可用于伴奏纯净度评估的神经网络模型。相比于常规方案中基于人工筛选的方式来识别伴奏的纯净度,本方案中可利用所述神经网络模型来进行伴奏纯净度评估,进而分辨出所述伴奏是纯器乐伴奏的原版伴奏数据还是存在背景噪声的消音伴奏数据。若需要对大量伴奏数据的纯净度进行识别时,本方案在实现上较为经济,且在效率及识别的准确率更高。
参见图9,图9是本发明实施例提供的一种伴奏纯净度评估装置的结构示意图。如图9所示,伴奏纯净度评估装置900,包括:
通信模块901,用于获取待检测数据,所述待检测数据包括伴奏数据;
特征提取模块902,用于提取所述伴奏数据的音频特征;
评估模块903,用于将所述音频特征输入到神经网络模型中,获得所述伴奏数据的纯净度评估结果;所述评估结果用于指示所述待检测数据为纯器乐伴奏数据或存在背景噪声的器乐伴奏数据,所述神经网络模型是根据多个样本训练得到的,所述多个样本包括多个伴奏数据的音频特征以及各个伴奏数据对应的标签,所述神经网络模型的模型参数是由所述各个伴奏数据的音频特征以及各个伴奏数据对应的标签之间的关联关系确定的。
可能的实施例中,所述装置900还包括数据优化模块904,所述数据优化模块904用于,在提取所述伴奏数据的音频特征之前,对所述伴奏数据进行调整,以使所述伴奏数据的播放时长与预设播放时长相符;对所述伴奏数据进行归一化处理,以使所述伴奏数据的音强符合预设音强。
可能的实施例中,所述装置900还包括特征标准化模块905,所述特征标准化模块905用于,在将所述音频特征输入到神经网络模型中之前,根据Z-score算法对所述伴奏数据的音频特征进行处理,以使所述伴奏数据的音频特征标准化;其中所述伴奏数据标准化后的音频特征符合正太分布。
可能的实施例中,所述评估模块903还用于,若所述伴奏数据的纯净度大于或等于预设阈值,确定所述纯净度评估结果为所述纯器乐伴奏数据;若所述待检测伴奏数据的的纯净度小于所述预设阈值,确定所述纯净度评估结果为所述存在背景噪声的器乐伴奏数据。
本发明实施例中,所述纯净度评估装置900先获取待检测的伴奏数据,然后提取所述伴奏数据中的音频特征,并将提取到所述音频特征输入到训练好的用于伴奏纯净度评估的神经网络模型中,就能获得待检测的伴奏数据的纯净度评估结果,而通过纯净度评估结果就能确定待检测的伴奏数据是纯器乐伴奏数据或存在背景噪声的器乐伴奏数据。通过实施上述实施例,以神经网络模型来分辨待检测伴奏数据的纯净度,相比于人工分辨伴奏纯净度的方式,本方案在实现上不仅效率更高成本更低,而且分辨伴奏纯净度的准确度以及精度都更高。
参见图10,图10是本发明实施例提供的电子设备硬件结构框图,所述电子设备可以是服务器。该服务器包括:处理器1001,用于存储处理器可执行指令的存储器,其中,所述处理器被配置为:执行图4、图6或图7方法实施例描述的方法步骤。
可能实施例中,所述服务器还可以包括:一个或多个输入接口1002,一个或多个输出接口1003和存储器1004。
上述处理器1001、输入接口1002、输出接口1003和存储器1004通过总线1005连接。存储器1004用于存储指令,处理器1001用于执行存储器1004存储的指令,输入接口1002用于接收数据,例如图4或图6方法实施中的第一伴奏数据以及各个第一伴奏数据对应的标签,以及图7方法实施例待检测数据,输出接口1003用于输出数据,例如图7方法实施例中的纯净度评估结果。
其中,处理器701被配置用于调用所述程序指令执行:图4、图6、图7方法实施例中涉及与服务器的处理器相关的方法步骤。
应当理解,在本公开实施例中,所称处理器1001可以是中央处理单元(Central Processing Unit,CPU),该处理器还可以是其他通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现成可编程门阵列(Field-Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
该存储器1004可以包括只读存储器和随机存取存储器,并向处理器1001提供指令和数据。存储器1004的一部分还可以包括非易失性随机存取存储器。例如,存储器1004还可以存储接口类型的信息。
在本发明实施例中,还提供一种计算机可读存储介质,所述计算机可读存储介质可以是前述任一实施例所述的终端设备的内部存储单元,例如终端设备的硬盘或内存。所述计算机可读存储介质也可以是所述终端设备的外部存储设备,例如所述终端设备上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。进一步地,所述计算机可读存储介质还可以既包括所述终端设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述终端设备所需的其他程序和数据。所述计算机可读存储介质还可以用于暂时地存储已经输出或者将要输出的数据。
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
在本发明所提供的几个实施例中,应该理解到,所揭露的伴奏纯净度评估装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另外,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口、装置或单元的间接耦合或通信连接,也可以是电的,机械的或其它的形式连接。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本发明实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以是两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!