细胞表面上非共价含Fc结构域的蛋白质展示的方法与流程
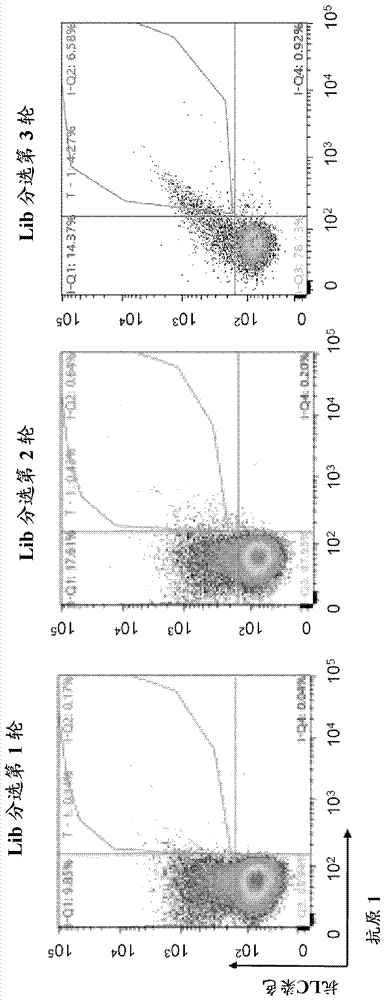
及其筛选方法发明领域。本发明涉及宿主细胞表面上蛋白质(例如单克隆抗体)展示及其筛选方法。具体地说,本发明涉及宿主细胞表面上展示的抗体或抗体文库或含fc结构域的融合蛋白的筛选和用于鉴定和选择所需表型的含fc结构域的蛋白质的方法。本发明的方法特别可用于在表达免疫球蛋白或其片段的真核寄主细胞中筛选免疫球蛋白文库。发明背景在学术界和制药业,很多资源被投入基于靶标的疗法的单克隆抗体的发现和开发中。在迄今开发的可用技术中,筛选抗体文库的高通量技术使得能够通过亲和力成熟鉴定新的候选分子并快速优化预选择的结合剂。由于新的候选分子的鉴定是一个巨大的驱动性延伸技术,因此新的高效筛选技术的发明已被证明是进一步加快抗体发现和发展过程的总体策略的一个关键部分。自80年代中期出现噬菌体展示技术及其应用于抗体展示以来,已涌现出若干体外展示技术。紧接噬菌体展示,有4种主要的展示技术,称为细胞展示、核糖体展示、mrna展示和dna展示,其中噬菌体展示为最被认可的一种。噬菌体展示目前是用于展示和选择大批抗体和用于进一步工程改造所选抗体的最普遍方法。抗体通常以所谓的“单价”形式展示,其中抗体-外被蛋白融合基因携带在噬菌粒载体上,通过用辅助噬菌体感染携带噬菌粒的细菌进行展示。最优选这种形式(亦称为3x3形式),因为在噬菌粒载体中构建文库赋予噬菌粒载体与噬菌体载体相比较高的转化效率,因为它提供对最高的亲和力结合剂的选择,亲合力作用不会使之偏斜(saggy等(2012)proteineng.des.sel.25,539-549)。噬菌体抗体展示的最成功应用包括例如重新从非免疫和合成文库中分离高亲和力人抗体(包括针对自身抗原的抗体),通过体外亲和力成熟产生具有皮摩尔亲和力的高亲和力抗体,并从来自动物或人供体的非免疫和免疫文库发现具有独特性质的抗体(hogenboom(2005)nat.biotech23,1105–1116)。尽管噬菌体抗体展示的优势,但该技术还具有限制其应用的缺点:在大肠杆菌(e.coli)中,功能抗体片段有效分泌到周质间隙通常需要蛋白伴侣和异构酶共表达以防止因有限分泌能力所致的抗体片段的错折叠和聚集(bothmann和plückthun(2000),j.biol.chem.第275卷(22),17100-17105))。另外,似乎存在针对奇数的半胱氨酸、正电荷的运行和所展示肽内固定位置的某些残基的生物选择,这因此导致抗体片段的固有的偏向性选择。第二最常用的技术是酵母展示,这是一种从组合文库选择并工程改造抗体片段的稳健技术。酵母展示技术对寡聚体分子(例如全长igg免疫球蛋白)的表达是有利的,因为与细菌表达的抗体相比,抗体不得不通过真核生物的分泌途径,这导致总体较大数目的正确折叠的免疫球蛋白。酵母展示利用若干天然存在的细胞壁锚定蛋白的存在,这可用来通过c端糖基磷脂酰肌醇附着信号(通常称为gpi锚)的附着使异源蛋白质靶向最外面的细胞表面。首先,酵母展示依赖于抗体编码dna序列与酵母细胞壁甘露糖蛋白(mannoprotein)序列以符合读框的方式遗传融合(doerner等(2014),febsletters588,278-287)。用于表面展示的蛋白质库经扩增,届时包括例如a-凝集素、flo1p和α-凝集素。这其中,最常使用a-凝集素应用系统。a-凝集素是在合适的酵母细胞配对时介导细胞-细胞接触的两种配对型特异性凝集素之一。它由1个核心亚基aga1p形成,所述核心亚基aga1p通过2个二硫桥与较小的结合亚基aga2p连接。由于aga1p的gpi附着信号所致,核心亚基使aga复合物共价锚在细胞壁上。由于所需要的c端gpi-附着信号所致,与只允许异源蛋白质的n端融合的单个单元的gpi-锚定蛋白相比,a-凝集素的模块结构此外能够使待展示的异源蛋白质与aga2p的c端或n端融合。基于flo1p的系统不同,因为它们可通过与被认为与细胞表面上的糖单元结合的n端絮凝功能结构域融合,非共价地附着并固定异源蛋白质。染色体编码的aga1和附加体编码的aga2-融合蛋白的过量表达通常由诱导型gal10启动子驱动,这说明了在内质网中缔合的两种亚基的化学计量表达水平。半乳糖诱导的表达导致约104–105拷贝的融合蛋白在宿主细胞表面上展示(doerner等(2014),febsletters588,278-287;boder和witrup(1997)nat.biotechnol.15,553-557)。通过表位标签或借助其活性(这在抗体的情况下是其与可溶性抗原的结合亲和力)进行表面暴露的融合蛋白的检测。检测通常用各自的生物素化抗原和第二试剂(例如链霉抗生物素缀合的荧光团)或以别的方式标记的抗原进行。在一种方法中,酵母展示被改进,其被称为用于靶结合蛋白的选择的分泌俘获细胞表面展示(secretion-and-capturecell-surfacedisplay)(secant™,rakestraw等(2011)proteinengdessel.jun;24(6):525-30)。该技术被成功地用于在酵母细胞表面展示全长免疫球蛋白g(igg)抗体。在secant™技术中,目标蛋白质(poi)与小的生物素接纳体肽(bap)遗传融合,所述生物素接纳体肽(bap)接着一个tev蛋白酶切割位点以利于纯化。tev-bap肽可与poi的n端或c端融合。在与tev-bap标签相对的poi的末端,poi与标签(通常为flag标签)遗传融合,整个bap、poi和flag标签基因籍此位于酵母分泌信号,通常工程改造的amfpp8前导序列、转化酶前导序列或合成前导序列的3’,所述酵母分泌信号接着kex2蛋白水解切割位点(rakestraw等(2011)proteinengdessel.jun;24(6):525-30)。对于poi的选择,poi的基因作为与bira生物素连接酶和蛋白伴侣共表达的bap的n端或c端融合物表达。bira生物素连接酶使poi上的bap标签生物素化。在分泌时,poi然后被表面定位的抗生物素蛋白结合,并可用荧光团标记的抗表位抗体或荧光团标记的抗原标记用于后续检测和选择。虽然secant技术允许分泌和选择复杂分子例如igg免疫球蛋白,但该技术仍需要poi的遗传修饰和生物素连接酶的共表达,这在筛选和选择过程中增加了额外的步骤。对酵母展示和特别对复杂分子的展示及其在抗体鉴定和成熟中的应用存在持续需求,还存在对降低与鉴定新的抗体候选物的筛选方法有关的成本和时间的持续需要。因此本发明的目的是提供在不需要遗传编码的锚蛋白或胞内抗体修饰的情况下允许在宿主细胞表面上展示复杂分子以鉴定目标蛋白质的方法。发明概述本发明出乎意料地发现用于在宿主细胞表面上展示、检测和选择所需表型的目标蛋白质的方法,本发明的方法籍此不需要目标蛋白质的遗传修饰。在第一个实施方案中,本发明提供用于在宿主细胞表面展示蛋白质的方法,所述方法包括以下步骤:(a)将编码待在所述宿主细胞表面展示的目标蛋白质的至少一个或多个多核苷酸导入宿主细胞;(b)使所述宿主细胞表面与第一标记接触;(c)使(b)的所述宿主细胞的表面与第二标记接触,第二标记籍此与所述第一标记和由所述至少一个或多个多核苷酸编码的所述目标蛋白质特异地且非共价地结合;(d)在足以分泌由至少一个或多个多核苷酸编码的所述目标蛋白质的条件下在所述宿主细胞中表达所述至少一个或多个多核苷酸;(e)使步骤(d)的所述宿主细胞与用于特异性检测被所述第二标记非共价结合的所述目标蛋白质的工具(means)接触和检测在其表面上展示目标蛋白质的宿主细胞。按照本发明的一个实施方案,由至少一个或多个多核苷酸编码的蛋白质是单体或多聚体。按照本发明的一个实施方案,由至少一个或多个多核苷酸编码的蛋白质包含信号肽。在另一个实施方案中,用于本发明方法的第一标记与宿主细胞表面共价结合。按照一个实施方案,用于本发明方法的第一标记是生物素或生物素衍生物。在另一个实施方案中,用于本发明方法的第二标记是另外的蛋白质或另外的多肽。在一个实施方案中,作为本发明方法的第二标记的另外的蛋白质或另外的肽是多聚体蛋白质。在一个实施方案中,本发明方法的第二标记是或包含与抗生物素蛋白、链霉抗生物素或其序列变体融合的a蛋白、l蛋白、g蛋白、a-g蛋白融合物、a蛋白的结构域e、d、a、b之一。按照一个实施方案,本发明方法的宿主细胞选自本文公开的哺乳动物、酵母或昆虫细胞。在一个实施方案中,用于特异性检测本发明方法的所述目标蛋白质的工具选自抗体或抗体片段、量子点、酶、荧光团或嵌入染料和神经节苷脂。在一个实施方案中,用于特异性检测本发明方法的所述目标蛋白质的工具可为多克隆抗体、单克隆抗体、scfv-fc、scfv、(fab’)2、fab、微型抗体(minibody)、双抗体或vhh抗体之一;其所有可任选与另外的标记再偶联(becoupled)。在一个实施方案中,上文公开的本发明方法进一步包括选择宿主细胞(例如本发明方法步骤(d)中检出的细胞)的步骤。按照一个实施方案,在上文公开的本发明方法中选出的宿主细胞展示表型改变的目标蛋白质。按照一个实施方案,本发明的目标蛋白质的表型改变是表面表达水平、蛋白质稳定性、蛋白质折叠或亲和力之一。在一个实施方案中,本发明方法的目标蛋白质的表型改变通过将本发明方法步骤(e)的所述宿主细胞与参比样品比较来测定。在一个实施方案中,由本发明方法步骤(a)的至少一个或多个多核苷酸编码的蛋白质包含本文公开的至少一个fc结构域。在一个优选的实施方案中,上面公开的本发明的至少一个fc结构域是人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3之一或其序列变体。在一个优选的实施方案中,本发明的含fc结构域的蛋白质是n端fc结构域融合蛋白、c端fc结构域融合蛋白或抗体。在一个优选的实施方案中,由本发明方法步骤(a)的多核苷酸编码的抗体是单克隆抗体,优选单克隆抗体是鼠单克隆抗体、小鼠-人嵌合单克隆抗体人源化单克隆抗体或人单克隆抗体。按照一个实施方案,本发明方法的第二标记特异性结合人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的fc结构域。按照一个实施方案,本发明方法的第二标记对抗体结合的亲和力至少为kd=10-8、2.5x10-8、5x10-8、7.5x10-8、10-9或5x10-9m。在一个实施方案中,以上公开的本发明方法的第二标记包含seqidno:1的氨基酸序列和/或seqidno:2的氨基酸序列。在一个实施方案中,本发明方法的第二标记包含seqidno:3的氨基酸序列。在一个优选的实施方案中,以上公开的本发明方法的步骤(e)进一步包括:(i)使所述宿主细胞与可检测标记的抗体或抗体片段接触,所述可检测标记的抗体或抗体片段与人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的fc结构域或其序列变体特异性结合;(ii)使宿主细胞与结合第二标记的抗体的抗原和/或表位接触,所述第二标记与不同于(i)所用标记的另外的可检测标记偶联;(iii)检测所述宿主细胞中(i)和/或(ii)的标记。(iv)选择与参比样品相比显示(i)中所用标记和/或(ii)所用标记的量改变和/或显示两种标记的量改变的宿主细胞。在一个优选的实施方案中,本发明的步骤(e)(i)的可检测标记的抗体或抗体片段与人或鼠igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的κ或λ轻链或其序列变体特异性结合。在一个优选的实施方案中,本发明方法的(i)和(ii)的标记和/或选择步骤(iv)包括流式细胞术和/或facs和/或微流体。按照一个实施方案,可重复本文公开的本发明方法的步骤(a)–(e)。在一个实施方案中,用于本发明方法的宿主细胞是酵母细胞,且本发明方法的步骤(a)进一步包括至少第一和第二酵母细胞的配对,藉此所述第一和第二宿主细胞包含不同的多核苷酸,所述多核苷酸中至少一个编码含fc结构域的融合蛋白,且藉此所述第一和第二宿主细胞的所述多核苷酸包含至少一个不同的选择标志物。在一个实施方案中,上述用于本发明方法的所述第一酵母细胞包含编码免疫球蛋白轻链的多核苷酸和/或其中用于本发明方法的所述第二酵母细胞包含编码免疫球蛋白重链的多核苷酸。在本发明方法的一个实施方案中,所述第一酵母细胞包含编码免疫球蛋白轻链文库的多核苷酸,且其中所述第二酵母细胞包含编码对目标蛋白质有预定亲和力的免疫球蛋白重链的多核苷酸。在一个实施方案中,本发明提供包含seqidno:5的核苷酸序列的分离的核酸分子。按照一个实施方案,本发明提供由seqidno:5的核酸序列编码的分离的蛋白质,其中除去了seqidno:4的氨基酸序列。在一个实施方案中,本发明涉及宿主细胞的制备,所述细胞含有包含seqidno:5的核苷酸序列的至少一个核酸分子。按照一个实施方案,本发明提供用于产生由seqidno:5的核酸序列编码的蛋白质(其中除去了seqidno:4的氨基酸序列)的方法,所述方法包括:-在足以蛋白质表达的条件下体外培养上文公开的宿主细胞;-表达由包含seqidno:5的核酸序列的多核苷酸编码的蛋白质;-分离和纯化所述蛋白质。按照一个实施方案,本发明方法的分离的蛋白质包含seqidno:3的氨基酸序列。在一个实施方案中,本发明的分离和纯化的蛋白质是多聚体。按照一个实施方案,本发明涉及通过上文公开的本发明过程可获得的蛋白质在上文公开的本发明方法中的用途。在一个实施方案中,本发明提供组件试剂盒,其包含:-上文公开的本发明的第一标记,-上文公开的本发明的分离的蛋白质和/或包含seqidno:5的核苷酸序列的上文公开的本发明的多核苷酸,其用于上文公开的蛋白质生产的方法,-宿主细胞用于上文公开的本发明方法的蛋白质表面展示的方法。在一个实施方案中,本发明的试剂盒包含本文公开的宿主细胞。按照一个实施方案,本发明的试剂盒可包含上文公开的冻干的第二标记和/或包含上文公开的seqidno:5的核苷酸序列的冻干的多核苷酸。附图简述图1:(a)考马斯蓝凝胶分析显示sa-zz四聚体(泳道4)和天然单体和四聚体(泳道3),(b)蛋白质印迹分析显示sa-zz结合igg(左)和生物素化蛋白质(右)。单体的表观大小为31kd(泳道3),四聚体为91kd(泳道2)。图2:sa-zz与抗人fc俘获触头(ahc触头)上俘获的igg(左)和sa-zz与链霉抗生物素触头上俘获的生物素化hrp(右)结合的octet分析。图3:出于内源抗体细胞表面展示目的通过real-select修饰的宿主细胞的示意图。携带编码抗体的质粒的宿主细胞首先通过使用市购可获得的生物素化试剂进行生物素化(a)。该修饰接着通过用重组融合蛋白链霉抗生物素-zz(sa-zz)装饰(decoration)细胞(b),这使得能够将分泌的抗体再俘获到细胞表面上(c)。图4:用于生物素标记和sa-zz固定在酵母细胞上的试剂的滴定。相应的间接荧光信号通过流式细胞术分析。(a)1×107个细胞用1mg-6mg生物素试剂标记,并用链霉抗生物素-dylight633染色。(b)将用1mg生物素标记的1×107个细胞与2、3或4µgsa-zz一起孵育以固定fc俘获部分。随后使用fitc缀合的山羊-抗a蛋白抗体检测表面zz结构域。图5:通过流式细胞术分析的3种不同mab的real-select功能化酵母细胞表型。(a)抗cmet-b10,(b)阿达木单抗,(c)马妥珠单抗和无(d)cmet,(e)tnfα,(f)egfr的各自的对照。使用各自的荧光标记的抗原(表1)和fc特异性检测抗体(igg展示)检测功能抗体的展示。图6:real-select功能化酵母细胞的俘获结构域饱和的流式细胞分析。(a)携带马妥珠单抗重链和轻链质粒的sa-zz装饰的细胞,(b)马妥珠单抗(蓝色抗体)或外部添加的戈利木单抗(golimumab)(红色抗体)的表面俘获。(c-e)表面装饰和引入马妥珠单抗表达后0小时、6小时和20小时用sa-zz融合蛋白与山羊-抗a蛋白-fitc装饰的酵母细胞的分析。(f-h)通过使细胞与戈利木单抗一起孵育接着在规定的时间点用tnfα-dylight650标记检测未占用的fc俘获结构域。(i,j)通过在表达6小时和20小时时用山羊-抗fcf(ab`)2-alexafluor647标记细胞监测重新俘获的马妥珠单抗的表面展示。图7:马妥珠单抗展示细胞的real-select富集的facs分析。将展示(a)马妥珠单抗或(b)曲妥珠单抗的功能化酵母细胞1:1,000,000混合(c),并使用egfr-pe和山羊-抗fcf(ab`)2alexafluor647标记。(c-f)在连续4轮分选期间通过facs富集马妥珠单抗展示细胞。图8:cdr-h3文库酵母细胞表型和有助于用递减的抗原浓度(b)250nm,(d)62nm,(f)15nmcmet和展示检测用抗fcalexafluor647的3轮facs筛选的cmet特异性抗体的亲和力成熟的选择策略。作为每轮分选的特定对照,针对igg分泌诱导富集的文库细胞,并只用抗fcalexafluor647缀合的抗体标记(a,c,e)。图9:cmet结合改进的抗体的功能表征。(a,b)(a)展示亲代抗体的酵母细胞,(b)展示用100nmcmet-pe和抗fcalexafluor647标记的所选抗体的细胞的facs分析。通过生物层干涉量度法测量的(c)expi293表达的亲代抗体和(d)亲和力-成熟抗体变体与cmet(100nm、50nm、10nm)的结合动力学。假设1:1结合模型,测定两种抗体的相关联速率常数(kon)、解离速率常数(kdis)和结合亲和力(kd)。图10:real-select与酿酒酵母(s.cerevisiae)以外的其它表达宿主相容,采用该项新技术检查作为哺乳动物表达宿主实例的expi293f™细胞上全长igg分子的展示。图11:使用抗轻链抗体用于标记表面展示的抗体的realselect(参见实施例12)。(a)轻链标记的示意图(左图)。完整抗体的细胞表面表达与右图所示染色强度相关。(b)在识别抗原-a和抗原-b的两种独立的抗体克隆中评价轻链标记的可行性。图12:描述了实施例13所述的克隆富集实验的分选结果。结果表明对alexa647缀合的抗原-y的结合特异性,显示了从起始库成功地富集正确的抗体克隆,其中富集的克隆最初以1:106稀释度存在。图13:realselect在亲和力成熟中的应用。描述了通过实施例14所述的轻链改组(shuffling)的3轮亲和力成熟和选择的结果。(a)富集克隆的facs分析,其中选择在选通参数内的那些用于进一步分选。(b)在连续的3轮选择和富集后亲和力成熟抗体克隆的biacore™分析。序列表seqidno:1第二标记所包含的fc结构域结合(zz)结构域的氨基酸序列seqidno:2第二标记所包含的链霉抗生物素(sa)的氨基酸序列seqidno:3sa-zz融合蛋白的氨基酸序列seqidno:4信号肽的氨基酸序列seqidno:5第二标记的核苷酸序列seqidno:6包括信号序列的本发明第二标记的氨基酸序列seqidno:7用于文库生成的引物seqidno:8用于文库生成的引物seqidno:9人工前导序列seqidno:10人工前导序列seqidno:11人工前导序列seqidno:12人工前导序列seqidno:13人工前导序列seqidno:14人工前导序列seqidno:15人工前导序列seqidno:16人工前导序列seqidno:17人工前导序列seqidno:18人工前导序列seqidno:19人工前导序列seqidno:20人工前导序列seqidno:21人工前导序列seqidno:22人工前导序列seqidno:23人工前导序列seqidno:24人工前导序列seqidno:25人工前导序列seqidno:26人工前导序列seqidno:27人工前导序列seqidno:28人工前导序列发明详述虽然下面详细地描述了本发明,但要了解,本发明不限于本文所述具体的方法、方案和试剂,因为这些都可改变。还要了解,本文所用术语仅用于描述具体实施方案的目的,并无意限制只由随附权利要求书限定的本发明的范围。除非另有说明,否则本文所用的所有技术和科学术语具有本领域普通技术人员通常理解的相同含义。下面,将描述本发明的要素。这些要素与具体实施方案一起列出,然而应了解,它们可以任何方式和以任何数目组合以产生额外的实施方案。个别描述的实例和优选的实施方案不应解释为只将本发明限于明确描述的实施方案。该描述应理解为支持和包括将明确描述的实施方案与具有任何数目的公开的和/或优选的要素组合的实施方案。此外,本申请中所有所描述的要素的任何排列和组合都应视为通过本申请的描述而公开,除非文中另有说明。在整个本说明书和随附的权利要求书中,除非文中另有要求,否则术语“包含”和变体例如“包括”和“含有”应理解为必然包含规定的成员、整数或步骤但不排除任何其它未规定的成员、整数或步骤。术语“由……组成”是术语“包含”的一个具体实施方案,其中不包括任何未规定的成员、整数或步骤。在本发明的情况下,术语“包含”包括术语“由……组成”。在描述本发明的情况下(尤其在权利要求书的情况下)使用的术语“a”和“an”和“the”和类似指代要解释为涵盖单数和复数,除非本文另有说明或文中显然抵触。本文值的范围的引述仅仅只是用作各别提及落入该范围的每个单独的值的简写方法。除非本文另有说明,否则每个单独的值都并入到本说明书中,就像本文分别引述一样。本说明书的用语都不应解释为说明对实施本发明是必要的任何非要求保护的要素。在本说明书的文本中引用了若干文件。本文引用的每份文件(包括所有专利、专利申请、科技出版物、生产商说明书、使用说明等),不论在上文还是在下文,都通过引用以其整体并入到本文中。本文任何东西都不得解释为承认本发明因在前的发明而无资格先于这类公开内容。所述目标通过本发明、优选通过随附权利要求书的主题解决。本申请人出乎意料地发现蛋白质可通过本发明方法在宿主细胞表面非共价展示。本发明按照第一个实施方案通过用于在宿主细胞表面展示蛋白质的方法解决,本发明方法在此包括以下步骤:(a)将至少一个或多个多核苷酸导入宿主细胞中,所述多核苷酸编码将在所述宿主细胞表面展示的目标蛋白质,(b)使所述宿主细胞表面与第一标记接触;(c)使(b)的所述宿主细胞的表面与第二标记接触,第二标记籍此与所述第一标记和由所述至少一个或多个多核苷酸编码的所述目标蛋白质特异性和非共价地结合;(d)在由至少一个或多个多核苷酸编码的所述目标蛋白质足以分泌的条件下在所述宿主细胞中表达所述至少一个或多个多核苷酸;(e)检测宿主细胞,其展示被所述宿主细胞表面上的第二标记结合的步骤(d)的所述目标蛋白质,(f)使步骤(e)的所述宿主细胞与用于特异性检测被所述第二标记结合的所述目标蛋白质的工具接触。术语“宿主”细胞在用于本发明的方法时可以是任何适于表达目标蛋白质的细胞,例如酵母细胞、昆虫细胞、鱼或哺乳动物细胞。术语“导入”当与本发明方法一起使用时应是指适于通过本领域已知的任何技术将多核苷酸引入或转移至宿主细胞的任何方法,例如转化、转导、转染。在本文中,术语“转化”在与本发明方法一起使用时用来描述将多核苷酸(例如质粒)导入酵母细胞或真菌细胞中,术语“转导”在用于本发明的方法时是指多核苷酸或遗传物质的病毒引入或病毒转移至哺乳动物、鱼或昆虫细胞中。可使用任何已知的病毒系统用于转导本发明的宿主细胞,例如基于腺病毒的系统、基于腺伴随病毒(aav)的系统、反转录病毒系统例如基于莫洛尼鼠白血病毒(mo-mlv)的e系统或慢病毒表达系统或基于单纯疱疹病毒(hsv)的系统,或基于其它病毒的系统例如基于痘苗、eb病毒、仙台病毒、辛德毕斯病毒、多瘤病毒和麻疹病毒的系统(参见例如mah等(2002)clin.pharmocokin(12):901-911)。如果用于本发明方法的宿主细胞是昆虫细胞,则可使用例如杆状病毒表达系统将至少一个或多个多核苷酸导入宿主细胞中,然而,也可使用杆状病毒将本发明的多核苷酸导入宿主细胞中(参见例如hofmann等,procnatlacadsciusa(1995),92:10099-10103;boycefm,procnatlacadsciusa(1996),93:2348-23522)。术语“转染”在用于本发明的方法时是指通过本领域已知的任何合适方法使宿主细胞摄入核酸,例如公开于graham等(1973);sambrook等(1989)molecularcloning,alaboratorymanual,coldspringharborlaboratories,newyork,davis等(1986)basicmethodsinmolecularbiology,elsevier的方法,特别是磷酸钙共沉淀、直接显微注射进入培养的细胞中、超声介导的基因转染、电穿孔、脂转染或核转染(nucleofection)。例如,酵母细胞可用于本发明的方法,并且可按benatuil等,proteinengineering,design&selection,第23卷第4期第155–159页,2010所述培养和转化。例如为了获得电感受态(electrocompetent)酵母细胞,可使酿酒酵母细胞(eby100)在台式振荡器上以225rpm和30℃在ypd培养基(10g/l酵母氮源基础、20g/l胨和20g/ld-(+)-葡萄糖)中生长过夜至稳定期(od600至3或约3)。随后,可将等分的过夜培养物例如以0.3的初始od600接种。例如,可使细胞随后在台式振荡器上以30℃和225rpm继续生长直到od600为约1.6。可通过以3000rpm离心3分钟收集细胞,并除去培养基。然后将细胞在例如50ml冰冷的水中洗涤两次,在50ml冰冷的电穿孔缓冲液(1m山梨糖醇/1mmcacl2)洗涤一次。通过将细胞沉淀重新悬浮于20ml0.1mliac/10mmdtt中,并在培养瓶中在225rpm、30℃下振荡30分钟,来处理酵母细胞。随后,处理的细胞可通过离心收集,在50ml冰冷的电穿孔缓冲液中洗涤例如1次,通过离心沉淀,重新悬浮于例如100-200μl电穿孔缓冲液以达到1ml的最终体积,相当于约1.6×109个细胞/ml。例如酵母细胞的电穿孔,可使用400µl,并保持在冰上直到电穿孔。如有需要,例如对于大量多核苷酸的转化,例如当转化人抗体文库时,用于电穿孔的酵母细胞的量可按比例增加,例如可使用500µl、600µl、700µl、800µl、900µl或1ml的处理细胞。本发明方法中用于转化(电穿孔)酵母细胞的多核苷酸例如优选应提前制备。对于本发明的多核苷酸的电穿孔,可使用约1-约50µg多核苷酸,例如约2µg-约48µg,或约4µg-约45µg,或约6µg-约40µg,约8µg-约35µg,约10µg-约25µg,或约12µg-约20µg,或约4µg-约18µg,或约6µg-约16µg,或约7µg-约14µg,或约5µg-约12µg,或者2µg、3µg、4µg、5µg、6µg、7µg、8µg、9µg、10µg、11µg、12µg、13µg、14µg、15µg、16µg、17µg、18µg、19µg、20µg、21µg、22µg、23µg、24µg、25µg、26µg、27µg、28µg、29µg、30µg、31µg、32µg、33µg、34µg、35µg、36µg、37µg、38µg、39µg、40µg、41µg、42µg、43µg、44µg、45µg、46µg、47µg、48µg、49µg或50µg多核苷酸可用于电穿孔。优选多核苷酸的体积应小于50µl。然后,例如可将处理的酵母细胞与多核苷酸轻轻混合,转移到预冷的电穿孔杯(例如0.2cm电极间距)并在冰上孵育约5分钟,之后可以例如2.5kv和25µf将酵母细胞电穿孔,此时时间常数的范围为例如3.0-4.5毫秒。然后可将电穿孔的酵母细胞转移到8ml的1m山梨糖醇:ypd培养基的1:1混合物中,并在例如台式振荡器上以225rpm和30°c孵育1小时。细胞然后可通过离心收集,并重新悬浮于sd-ut培养基(20g/l葡萄糖、6.7g/l不含氨基酸的酵母氮源基础、5.4g/lna2hpo4、8.6g/lnah2po4×h2o和5g/l酪蛋白氨基酸[csm-trp-ura])中。例如,对于每400µl电穿孔的酵母细胞,可使用250mlsd-ut培养基。术语多核苷酸或核酸在用于本发明的方法时一般是指包含大量核苷酸的分子。示例性的多核苷酸包括脱氧核糖核酸、核糖核酸及其合成类似物,包括肽核酸。例如,本发明的多核苷酸可含有包含至少一个,例如1、2、3、4、5、6、7、8、9或10个或多个编码目标蛋白质的核苷酸序列的病毒rna或dna。用于本发明的至少一个多核苷酸还可例如作为一个或多个表达载体(质粒),例如1、2、3、4、5、6或更多个表达载体提供,其中术语表达载体是指载体或附加型载体,其通常是用来将特定基因(例如将在本发明的宿主细胞表面上非共价展示的目标蛋白质)导入靶细胞并表达的质粒。表达载体允许产生大量的稳定的mrna。一旦表达载体进入细胞,被基因编码的蛋白质便通过细胞转录和翻译机器产生。对质粒进行工程改造,使得它含有引起大量mrna产生的高活性启动子。附加型载体能够在宿主细胞内自主地自我复制。术语“蛋白质”,其将通过本发明方法在宿主细胞表面展示的至少一个或多个多核苷酸编码,是指全长蛋白质、蛋白质片段、呈其天然状态的蛋白质或变性蛋白质。例如,将在本发明的宿主细胞表面展示的蛋白质或蛋白质片段可包含约50-约35000个氨基酸,或约100-约32500个氨基酸,或约125个氨基酸-约30000个氨基酸,或约150-约27500个氨基酸,或约200个氨基酸-约27000个氨基酸,或约220-约26750个氨基酸,或约250-约26500个氨基酸,或约300个氨基酸-约26000个氨基酸,或约60、70、80、90、100、110、120、130、140、160、170、180、190、200、210、220、230、240、260、270、280、290、325、350、375、400、425、450、475、500、525、550、575、600、625、650、675、700、725、750、775、800、850、900、950、1000-约1100、1150、1200、1250、1300、1350、1400、1450、1500、1550、1600、1650、1700、1750、1800、1850、1900、1950、2000个氨基酸。本发明方法进一步包括使宿主细胞的表面与第一标记接触,其中术语“接触”是指使至少2个不同的实体(例如至少一个宿主细胞和至少一个第一标记)进行接触的方法,使得它们可与宿主细胞表面反应或结合。本发明的第一标记可为例如糖、氨基酸、蛋白质、肽、酶、脂质、维生素、核酸、肽核酸、神经节苷脂或量子点、a蛋白,其每一种例如可被官能化以与本发明方法的宿主细胞表面反应,例如上述化合物可包含反应基团例如n-羟基琥珀酰亚胺(nhs)酯或tetrafluorophyl酯(thf)。本发明的方法进一步包括使上文公开的宿主细胞表面与第二标记接触,籍此第二标记与所述第一标记和由所述至少一个或多个多核苷酸编码的所述目标蛋白质特异性和非共价地结合。本发明的第二标记可包括例如神经节苷脂结合蛋白(凝集素)、酶伪底物、酶例如激酶、融合蛋白,其结合本发明的宿主细胞表面上的第一标记并能够结合目标蛋白质,例如第二标记可以是多聚体蛋白质,其中至少一个蛋白质结构域或片段能够与第一标记结合,且至少一个第二结构域能够与目标蛋白质结合。本发明的方法进一步包括在足以分泌目标蛋白质的条件下表达由至少一个或多个多核苷酸编码的目标蛋白质。例如,可利用细胞培养基例如dmem、rpmi1640、mem、hamdmem/f12或无血清或无蛋白质培养基,例如expi293™(lifetechnologies)或freestyle™培养基(lifetechnologies),按basictechniquesinmammaliancelltissueculture(phelan,currentprotocolsincellbiology1.1.1-1.1.18,2007年9月)所述,培养哺乳动物细胞。例如,可在graceinsecttc培养基或schneider果蝇培养基中培养昆虫细胞。本发明的方法进一步包括步骤(e)检测宿主细胞,所述细胞展示通过由上文公开的至少一个多核苷酸编码的目标蛋白质,其被宿主细胞表面上的本发明方法的第二标记结合。本发明的方法进一步包括使上文公开的宿主细胞与特异性检测被第二标记非共价结合的目标蛋白质的工具接触。“检测”在用于本发明的方法时是指定量或定性测定目标蛋白质通过第二标记与其表面非共价结合的宿主细胞存在与否,其中第二标记与宿主细胞表面上的第一标记结合。在一个实施方案中,在本发明的宿主细胞表面上展示的目标蛋白质可以是单体或多聚体蛋白质,例如目标蛋白质可由一个多肽链组成或可包含2-22、3-20、4-18、5-17、6-16、7-15、8-14、9-13、10-12或2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22个亚基,其每一个可含有包含上文公开的多个氨基酸的多肽或蛋白质。多聚体蛋白质的多肽链还可通过例如二硫键连接,所述二硫键可在例如各个多肽链或蛋白质片段的半胱氨酸残基之间形成。因此,目标蛋白质可为例如多聚体蛋白质,其包含超过35000个氨基酸。通过本发明方法展示的目标蛋白质可以是例如同聚蛋白质,其由相同的多肽或蛋白质组成,例如目标蛋白质可包含例如可通过二硫键连接的2-22、4-18、6-16、8-14、10-12、或2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22个相同的多肽链(亚基),或可通过非共价相互作用(例如疏水蛋白质-蛋白质相互作用)形成例如多聚体复合物。可通过化合物从气相、液相或固相至水的转移的自由能δgtr,估算指定化合物(例如目标蛋白质)的疏水作用的幅度。δgtr的正值意味着分子更喜欢水性环境。在氨基酸的情况下,可用游离氨基酸或经修饰以更好地代表掺入蛋白质链中的氨基酸的变体进行测量。例如,目标蛋白质还可以是异聚蛋白质,并包含两个或更多个不同的多肽或亚基,或蛋白质,例如目标蛋白质可包含2-22,或3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21或22个不同的多肽或亚基,其可例如通过二硫键、疏水相互作用连接或通过接头或人工接头连接。术语“接头”或“键合”在用于本发明方法的目标蛋白质时是指连接2个蛋白质或多肽并具有长为约5-约20个原子的骨架的连接部分。例如,接头或连接可以是连接本发明的目标蛋白质的2个多肽或蛋白质的共价键,或链长为1和20个原子例如长为约1、2、3、4、5、6、8、10、12、14、16、18、19或20个碳原子,其中接头可以是直链、支链、环状或单个原子。在某些情况下,接头骨架的1、2、3、4或5或更多个碳原子可被硫、氮或氧杂原子任选取代。骨架原子间的键可以是例如饱和或不饱和的,因此通常不超过1、2或3个不饱和键可存在于接头骨架中。接头可包括例如一个或多个取代基,例如烷基、芳基或烯基。接头可包括而不限于聚乙二醇、醚、硫醚、叔胺、可以是直链或支链的烷基,例如甲基、乙基、正丙基、1-甲基乙基(异丙基)、正丁基、正戊基、1,1-二甲基乙基(叔丁基)等。接头骨架可包括例如环状基团,例如芳基、杂环基或环烷基,其中环状基团的两个或更多个原子(例如2、3或4个原子)可包括在骨架中,并且可为可切割的或不可切割的。目标蛋白质可为例如人工蛋白质,例如非天然存在的蛋白质,并包含例如天然存在的蛋白质或蛋白质片段的融合物,或例如可包含保守或非保守氨基酸取代,或可包含一个或多个氨基酸的取代、缺失或添加,例如与天然存在的蛋白质或蛋白质片段相比,人工目标蛋白质可包含1-100、5-90、10-80、15-75、20-70、25-65、30-55、35-50、40-45、或2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、35、36、37、38、39、40、41、42、43、44、46、47、48、49、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69或70个保守或非保守的氨基酸取代。例如,本发明的目标蛋白质的保守氨基酸取代是指一个氨基酸被具有类似性质(例如大小、电荷、疏水性、亲水性和/或芳香性)另一个氨基酸置换,并包括以下5组内之一的交换:本发明的目标蛋白质中的非保守氨基酸取代包括例如上文公开的不同组i-v间,例如组i和ii、i和iii、i和iv、i和v、ii和iii、ii和iv、ii和v、iii和iv、iii和v之间的取代。按照一个实施方案,由至少一个多核苷酸编码的本发明的目标蛋白质包含信号肽。在本文中,用于本发明方法的目标蛋白质的信号序列是指能够使例如通过肽键与之有效连接的多肽穿过宿主细胞的内质网(er)的氨基酸序列。信号肽一般被内肽酶(例如特异性定位于er的信号肽酶)切割以释放(成熟的)多肽。信号肽的长度范围通常为约10-约40个氨基酸。在本文所用的一个实施方案中,术语“编码信号肽的核酸序列”不包括编码其信号肽天然使之启动穿过内质网的同源多肽的全长序列的核酸序列的范围内。具体地说,所述信号肽能够指导多肽进入细胞的分泌途径。例如,如果本发明的宿主细胞是哺乳动物细胞,则与本发明的目标蛋白质连接的前导序列可包括melglswifllailkgvqc(seqidno:9)、melglrwvflvailegvqc(seqidno:10)、mkhlwfflllvaaprwvls(seqidno:11)、mdwtwrilflvaaatgahs(seqidno:12)、mdwtwrflfwaaatgvqs(seqidno:13)、mefglswlflvailkgvqc((seqidno:14)、mefglswvflvalfrgvqc(seqidno:15)、mdllhknmkhlwfflllvaaprwvls((seqidno:16)、mdmrvpaqllgllllwlsgarc(seqidno:17)、mkyllptaaagllllaaqpama(seqidno:18)、mplllllpllwagala(seqidno:19)、mkvlilaclvalala,mkwvtfisllflfssays…rgvfrr((seqidno:20)。例如,如果昆虫细胞在本发明方法中用作宿主细胞,可使用昆虫细胞的合适的信号序列,其作为一个实例可包括mkflvnvalvfmvvyisyiya(seqidno:28)。例如,如酵母细胞在本发明方法中用作宿主细胞,则可使用酵母细胞的合适信号序列,例如公开于massahi等,journaloftheoreticalbiology364(2015)179–188中的那些,其可包括例如优选氨基末端的mfα1pp分泌前导序列mqvksivnlllacslava((seqidno:21)、mqfnwniktvasilsaltlaqa(seqidno:22)、mqfnsvvisqllltlasvsmg(seqidno:23)、mrfsttlataatalfftasqvsa(seqidno:24)、mesvsslfnifstimvnykslvlallsvsnlkyarg(seqidno:25)、mrfpsiftavlfaassala(seqidno:26)、mfksvvysilaaslana(seqidno:27)。按照本发明的一个实施方案,本发明方法的第一标记与宿主细胞的表面共价结合。因此,第一标记例如可与哺乳动物细胞的表面共价结合,或例如可与昆虫细胞的表面共价结合,或例如可与酵母细胞的表面共价结合。与本发明方法一起使用时,术语“共价结合”或“共价键”是指通过共有至少一对电子所形成的2个原子的键,例如在c-c、c=c、n-c或s-s之间形成的键。按照一个优选的实施方案,本发明的第一标记是生物素或生物素衍生物。因此,本发明方法的第一标记可包括例如生物素或生物素类似物例如脱硫生物素、氧代生物素、2′-亚氨基生物素、二氨基生物素、生物素亚砜、生物胞素等,其可通过反应基团例如n-羟基琥珀酰亚胺(nhs)酯或tetrafluorophyl酯(thf)与本发明的宿主细胞的表面共价结合。例如,可在本发明方法中用作第一标记的生物素衍生物还可包括接头,例如-lc-生物素、-lc-lc-生物素、-slc-生物素或-pegn-生物素其中n为3-12(例如n=1、2、3、4、5、6、7、8、9、10、11或12)。例如,第一标记可包括nhs-peo4-生物素、nhs-dpeg4-生物素、nhs-peg12-生物素、nhs-dpeg12-生物素、生物素(biotion)-peg-scm(3.4kd)、磺基-nhs-生物素、磺基-nhs-lc-生物素、磺基-nhs-lc-lc-生物素、烷氧基胺-peg12-生物素、烷氧基胺-peg4-生物素、酰肼-生物胞素、肼-peg4-生物素、吡啶基二硫化物-生物素、生物素-bmcc(1-生物素氨基-4-[4'-(马来酰亚胺甲基)环己烷甲酰氨基]丁烷)、马来酰亚胺-peo2-生物素、mal-dpeg2-生物素、马来酰亚胺-peg2-生物素、马来酰亚胺-peo11-生物素、mal-dpeg11-生物素、马来酰亚胺-peg11-生物素或长链(lc)碘乙酰基-生物素。按照一个实施方案,本发明方法的第二标记是另外的蛋白质或多肽。例如,本发明方法的第二标记可以是结合生物素或上文公开的生物素-衍生物的另外的蛋白质。在本发明的一个优选的实施方案中,本发明方法的第二标记是多聚体蛋白质。因此,另外的蛋白质(第二标记)可包含一种以上的蛋白质,例如第二标记可包含2、3、4、5、6、7、8、9或10种蛋白质,其可通过第二标记中所包含的各种蛋白质间的例如一个或多个二硫键共价连接。然而本发明方法的第二标记中包含的蛋白质还可通过例如疏水相互作用、第二标记的各个蛋白质组分间带电荷的氨基酸残基之间的静电相互作用非共价连接。按照一个实施方案,本发明方法的第二标记包含a蛋白、l蛋白、g蛋白、a-g蛋白融合物或a蛋白的结构域e、d、a、b之一。因此,第二标记a蛋白、l蛋白、g蛋白、a-g蛋白融合物或a蛋白的结构域e、d、a、b,并与上文公开的本发明的第一标记特异性非共价结合。因此,除a蛋白、l蛋白、g蛋白、a-g蛋白融合物或蛋白质的结构域e、d、a、b以外,第二标记可例如包含抗生物素蛋白或链霉抗生物素。例如,本发明方法的第二标记可包含例如a蛋白-抗生物素蛋白融合蛋白,或l蛋白-抗生物素蛋白融合蛋白,或g蛋白抗生物素蛋白融合蛋白,或与抗生物素蛋白融合的蛋白a-g融合蛋白,或与抗生物素蛋白融合的a蛋白的结构域e,或与抗生物素蛋白融合的a蛋白的结构域d,或与抗生物素蛋白融合的a蛋白的结构域a,或与抗生物素蛋白融合的a蛋白的结构域b,或例如a蛋白-链霉抗生物素融合蛋白,或l蛋白-链霉抗生物素融合蛋白,或g蛋白链霉抗生物素融合蛋白,或与链霉抗生物素融合的蛋白a-g融合蛋白,或与链霉抗生物素融合的a蛋白的结构域e,或与链霉抗生物素融合的a蛋白的结构域d,或与链霉抗生物素融合的a蛋白的结构域a,或与链霉抗生物素融合的a蛋白的结构域b。术语“融合蛋白”或“融合物”在与本发明第二标记一起使用时是指通过肽键连接的组分例如蛋白质或多肽。本发明的融合蛋白可以是氨基端或羧基端融合物。在一个实施方案中,本发明的第二标记还可包含neutravidin、鸡抗生物素蛋白相关蛋白(avr,例如avr4)、双链抗生物素蛋白(dcavd)或其与本发明第一标记结合的序列变体,例如抗生物素蛋白突变型y33h、抗生物素蛋白突变型h117c、抗生物素蛋白突变型[w110k][n54a]、链霉抗生物素突变型v47g、链霉抗生物素突变型s112f、链霉抗生物素突变型s112r或链霉抗生物素突变型s112k。结合目标蛋白质的本发明第二标记的优选蛋白质是例如对抗体fc结构域或抗体fab区或抗体轻链(vl-κ)显示高亲和力,例如具有至少kd=10-9m、10-10m、10-11m或10-12m的结合常数的那些。在一个实施方案中,本发明方法的宿主细胞例如可选自哺乳动物、酵母或昆虫细胞。在一个优选的实施方案中,本发明方法的宿主细胞是选自以下的酵母细胞:酿酒酵母(saccharomycescerevisiae)、多形汉逊酵母(hansenulapolymorpha)、粟酒裂殖酵母(schizosaccharomycespombe)、许旺酵母(schwanniomycesoccidentalis)、乳酸克鲁维酵母(kluyveromyceslactis)、亚罗解脂酵母(yarrowialipolytica)和巴斯德毕赤酵母(pichiapastoris)。按照一个优选的实施方案,本发明方法的宿主细胞是哺乳动物细胞。例如,哺乳动物细胞可选自hek293、hek293t、hek293e、hek293f、ns0、per.c6、mcf-7、hela、cos-1、cos-7、pc-12、3t3、vero、vero-76、pc3、u87、saos-2、lncap、du145、a431、a549、b35、h1299、huvec、jurkat、mda-mb-231、mda-mb-468、mda-mb-435、caco-2、cho、cho-k1、cho-b11、cho-dg44、bhk、age1.hn、namalwa、wi-38、mrc-5、hepg2、l-929、rab-9、sirc、rk13、11b11、1d3、2.4g2、a-10、b-35、c-6、f4/80、iec-18、l2、mh1c1、nrk、nrk-49f、nrk-52e、rmc、cv-1、bt、mdbk、cpae、mdck.1、mdck.2和d-17。在一个实施方案中,本发明方法的宿主细胞是昆虫细胞,其可选自sf9、sf21、s2或bti-tn-5b1-4细胞。按照一个实施方案,在本发明方法中用于特异性检测宿主细胞表面上的目标蛋白质的工具选自抗体或抗体片段、量子点、酶、荧光团或嵌入染料和神经节苷脂。因此,用于特异性检测目标蛋白质的工具可为例如抗体,其中术语“抗体”是指(a)免疫球蛋白多肽和免疫球蛋白多肽的免疫活性部分,即免疫球蛋白家族的多肽或其含有与特定抗原(例如目标蛋白质)免疫特异性结合的抗原结合部位的片段,或(b)所述免疫球蛋白多肽或与抗原(例如目标蛋白质(poi))免疫特异性结合的片段的保守取代的衍生物。抗体一般描述于harlow和lane,antibodies:alaboratorymanual(coldspringharborlaboratorypress,1988),其中术语“免疫特异性”在用于本发明的方法时是指本文公开的各个抗体或抗体片段仅与一个抗原决定簇反应且不与其它多肽特异性结合的的能力。例如,量子点可用来在本发明方法中特异性检测目标蛋白质。在本发明方法中(例如在本发明方法的步骤(e)中),术语“量子点”是指半导体材料的单个球状纳米晶体,其中纳米晶体的半径小于或等于该半导体材料的激子玻尔半径的大小(激子玻尔半径的值可从存在于以下含有有关半导体性质信息的手册中的数据计算,例如crchandbookofchemistryandphysics,第83版,lide,davidr.(编辑),crcpress,bocaraton,fla.(2002))。量子点是本领域已知的,因为它们描述于以下参考文献中,例如weller,angew.chem.int.ed.engl.32:41-53(1993);alivisatos,j.phys.chem.100:13226-13239(1996);以及alivisatos,science271:933-937(1996)。量子点可为例如约1nm-约1000nm直径,例如10nm、20nm、30nm、40nm、50nm、60nm、70nm、80nm、90nm、100nm、150nm、200nm、250nm、300nm、350nm、400nm、450nm或500nm、优选至少约2nm-约50nm、更优选qd的直径为至少约2nm-约20nm(例如约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20nm)。qd的特征在于其基本均一的纳米大小,常常显示约10%-15%多分散性或大小范围。qd在激发时能够发射电磁辐射(即qd是光致发光的),包括一种或多种第一半导体材料的“核”,并可被第二半导体材料的“壳”包绕。被半导体壳包绕的qd核称为“核/壳”qd。包“壳”材料可优选具有大于核心材料的能带隙能的能带隙能,并可选择以在接近“核”基质处具有原子间距。核和/或壳可为半导体材料,包括但不限于第ii-vi族(zns、znse、znte、us、cdse、cdte、hgs、hgse、hgte、mgs、mgse、mgte、cas、case、cate、srs、srse、srte、bas、base、bate等)和第iii-v族(gan、gap、gaas、gasb、inn、inp、inas、insb等)和第iv族(ge、si等)材料、pbs、pbse及其合金或混合物。优选的壳材料包括zns。术语“荧光团”、“荧光标记”或“荧光染料”或“荧光团”在用于本发明方法以特异性检测宿主细胞表面上的目标蛋白质时是指在规定激发波长下吸收光能并在不同波长下发射光能的部分。可用于特异性检测本发明的目标蛋白质的荧光标记的实例可包括但不限于:丹酰氯、dapoxyl、二烷基氨基香豆素、异硫氰酸罗丹明、alexa350、alexa430、alexafluor488、alexafluor532、alexafluor546、alexafluor568、alexafluor594、alexafluor633、alexafluor660、alexafluor680、amca、氨基吖啶、bodipy630/650、bodipy650/665、bodipy-fl、bodipy-r6g、bodipy-tmr、bodipy-trx、bodipyfl、bodipyr6g、bodipytmr、bodipytr、bodipy530/550、bodipy558/568、bodipy564/570、bodipy576/589、bodipy581/591、bodipy630/650、bodipy650/665)、羧基罗丹明6g、羧基-x-罗丹明(rox)、cascadeblue、cascadeyellow、香豆素343、花青染料(cy3、cy5、cy3.5、cy5.5)、丹酰、dapoxyl、二烷基氨基香豆素、4',5'-二氯-2',7'-二甲氧基-荧光素、dm-nerf、伊红、赤藓红、荧光素、fam、羟基香豆素、ir染料(ird40、ird700、ird800)、joe、丽丝胺罗丹明b、marinablue、甲氧基香豆素、naphtho荧光素、oregongreen488、oregongreen500、oregongreen514、pacificblue、pympo、5-羧基-4',5'-二氯-2',7'-二甲氧基荧光素、5-羧基-2',4',5',7'-四氯荧光素、5-羧基荧光素、5-羧基罗丹明、6-羧基罗丹明、6-羧基四甲基氨基、cascadeblue、cy2、cy3、cy5、6-fam、丹酰氯、荧光素、hex、6-joe、nbd(7-硝基苯并-2-氧杂-l,3-二唑)、oregongreen488、oregongreen500、oregongreen514、pacificblue、酞酸、对苯二甲酸、间苯二酸、甲酚紫(cresylfastviolet)、甲酚蓝紫(cresylblueviolet)、亮甲酚蓝、对氨基苯甲酸、赤藓红、酞菁、偶氮甲碱、花青、黄嘌呤、琥珀酰荧光素、稀土金属穴状络合物、三联吡啶二胺铕(europiumtrisbipyridinediamine)、铕穴状化合物或螯合物、二胺、双花青、lajollablue染料、别藻蓝蛋白(allopycocyanin)、allococyaninb、藻蓝蛋白c、藻蓝蛋白r、硫胺、藻红青素、藻红蛋白r、reg、rhodaminegreen、异硫氰酸罗丹明、rhodaminered、tamra、tet、trit(tetramethylrhodamineisothiol)、四甲基罗丹明或德克萨斯红。例如,可用于本发明的方法的嵌入染料通常是平面芳族环形生色团分子。在一些实施方案中,嵌入染料包括荧光染料。多种嵌入染料是本领域已知的。一些非限制性实例包括picogreen(p-7581,molecularprobes)、eb(e-8751,sigma)、碘化丙锭(p-4170,sigma)、吖啶橙(a-6014,sigma)、7-氨基放线菌素d(a-1310,molecularprobes)、花青染料(例如toto、yoyo、bobo和popo)、syto、sybrgreeni、sybrgreenii、sybrdx、oligreen、cyquantgr、sytoxgreen、syto9、syto10、syto17、sybr14、fun-1、deadred、hexidiumiodide、二氢乙锭、9-氨基-6-氯-2-甲氧基吖啶、dapi、dipi、吲哚染料、咪唑染料、放线菌素d、羟茋巴脒、boxto、lcgreen、evagreen、bebo。在一个实施方案中,例如,如果目标蛋白质与神经节苷脂结合,则神经节苷脂可用来检测本发明方法的目标蛋白质。术语“神经节苷脂”用于本发明时是指每分子含有几个单糖单元的鞘糖脂。神经节苷脂或神经节苷脂衍生物所含的合适单糖单元的实例为d-半乳糖、n-乙酰基d-半乳糖胺、葡萄糖和n-乙酰基神经氨酸。根据每分子结合的唾液酸残基或残基的数目,可将神经节苷脂大致分成单唾液酸神经节苷脂(gm)、二唾液酸神经节苷脂(gd)、三唾液酸神经节苷脂(gt)和结合4个唾液酸残基的四唾液酸神经节苷脂(gq)。还可根据结合的一个或多个唾液酸残基的一个或多个位置进一步分类。神经节苷脂可包括例如gm1[n=0,m=1,在通式(1)中]作为gm,gd1a(n=1,m=1)和gd1b(n=o,m=2)作为gd,gt1b(n=1,m=2)作为gt和gq1b(n=2,m=2)作为gq。本文公开的神经节苷脂例如可进一步包含本文公开的荧光团,或例如可用放射性同位素(例如14c、3h、32p、125i、131i或125i)标记以允许或有助于其检测。在一个实施方案中,本发明方法包括使上文公开的宿主细胞与特异性检测与本发明第二标记非共价结合的目标蛋白质的工具接触。因此,用于特异性检测被本发明的第二标记非共价结合的目标蛋白质的工具可为例如任选可与其它标记偶联的多克隆抗体、单克隆抗体、scfv-fc、scfv、(fab’)2、fab、双抗体或vhh抗体之一。例如,可通过与目标蛋白质中的至少一个表位特异性结合,或例如还可与由本发明的第二标记和与之非共价结合的目标蛋白质形成的表位结合的多克隆抗体或多克隆血清、单克隆抗体、scfv-fc、scfv、(fab’)2、fab、微型抗体、双抗体或vhh抗体,来检测目标蛋白质。可按照本发明方法的实施方案使用的术语“fab片段”是指含有包含vl和cl区的轻链和包含vn和ch1区的重链的一部分的抗体片段。fab片段不含ch2或ch3区(参见例如kuby,immunology,第二版,第110-11页w.h.freemanandco.,newyork(1994))。不同类型的fab片段可不含铰链区、含铰链区的一部分或整个铰链区。“scfv-fc”当可用于本发明的方法时是作为scfv与fc区的融合物的重组蛋白(参见例如li等(2000),cancerimmunol,immunother.49:243-252)。术语“fc结构域”或“fc区”在用于本发明的方法时是指免疫球蛋白的一部分,例如与通过木瓜蛋白酶消化igg分子获得的可结晶片段有关的igg分子。fc区包含通过二硫键连接的igg分子的2条重链的c端一半。它没有抗原结合活性,但含有糖部分及补体和fc受体(包括fcrn受体)的结合部位。“fc结构域”包括例如天然序列fc区和变体fc区,例如公开于wo02/094852中那些),以及在fc结构域的多个位置,包括但不限于270、272、312、315、356和358位观察到多态性。在本发明方法内,术语“fc”可指分离的这个区或在抗体、抗体片段或fc融合蛋白情况下的这个区。例如,iggfc区可包含iggch2和iggch3结构域。人iggfc区的“ch2结构域”常常从约第231位的氨基酸残基延伸到约第340位的氨基酸残基,糖链籍此可与ch2结构域连接。“ch3结构域”可包含氨基酸c端至fc区中的ch2结构域的一段,例如从igg的约第341位的氨基酸残基至约第447位的氨基酸残基。用于本发明方法的术语“双抗体”是指通过2个可变重链-可变轻链片段聚合产生的二价、单特异性或双特异性分子的工程改造的抗体和/或抗体片段。术语“vhh”在用于本发明的方法时是指没有轻链的单一重链可变结构域抗体。优选vhh是可存在于例如天然没有轻链的骆驼科(camelidae)或软骨鱼的类型的抗体片段中,或vhh可以是可由此构建的合成vhh(参见例如kim等,biochimicaetbiophysicaacta1844(2014)1983–2001;janssens,r.等,proc.natl.acad.sci.u.s.a.2006,103(41),15130–15135)。术语“多克隆抗体”或“多克隆血清”在用于检测本发明的目标蛋白质时是指由多种不同的b淋巴细胞产生的异源抗体库。库中的不同抗体识别并特异性结合不同的表位,其通常为至少约3-5、优选约5-10或15,例如3、4、5、6、7、8、9、10、11、12、13、14或15个氨基酸,但通常不超过约1,000个氨基酸(或其之间的任何整数)的多肽序列,其界定了独自或作为较大序列的一部分与在响应所述序列时产生的抗体结合的序列。靶抗原可含有线性和/或不连续的表位。对于片段的长度没有决定性的上限,其可(例如)包含几乎抗原序列的全长,或甚至包含来自所述靶抗原的两个或更多个表位的融合蛋白。用于主题发明的表位不限于具有目标蛋白质来源于其中的部分的确切序列的多肽,可包含序列变体。例如,表位可含有包含上文公开的约1-10个保守或非保守氨基酸取代的序列,优选被多克隆抗体或多克隆血清识别的表位的氨基酸序列为与相应的序列或目标蛋白质的序列有至少85%、或至少90%、或至少95%、或至少98%同一性。因此术语“表位”在用于本发明的方法时包括与天然序列相同的序列以及天然序列的突变或修饰,例如缺失、添加和取代(在性质上通常是保守的)。例如,本发明的目标蛋白质或本发明公开的任何蛋白质的氨基酸序列的序列同一性定义为在比对序列和必要时引入空位以获得最大百分比序列同一性后,且不考虑任何保守取代作为序列同一性的一部分,与本发明的目标蛋白质中的氨基酸残基相同的候选序列中的氨基酸残基的百分比。可用本领域技术内的各种方法,例如应用可公开获得的计算机软件例如blast、blast-2、align、align-2或megalign(dnastar)软件,实现用于测定百分比氨基酸序列同一性的目的的比对。本领域技术人员可确定用于测量比对的合适参数,包括实现待比较序列全长内的最大比对所需的任何算法。例如,还可通过公开于altschul等,bullmath.bio.48:603(1986)和henikoff和henikoff,proc.natlacad.sci.usa1992nov15;89(22):10915-9的方法,测定百分比序列同一性。简单地说,使用10的空位开放罚分(gapopeningpenalty)、1的空位延伸罚分(gapextensionpenalty)和下文公开的henikoff和henikoff的“blosum62”评分矩阵(氨基酸用标准一字母代码表示),对2个氨基酸序列进行比对以使比对评分最优化。然后如下计算百分比同一性:([相同匹配的总数]/[较长序列的长度加引入较长序列中以比对2个序列的空位数])*100)。例如,可获得的其它确立的算法可用来比对和测定两个或更多个氨基酸序列的相似性。pearson和lipman的“fasta”相似性搜索算法是用于检查两个或更多个氨基酸序列具有同一性水平的合适的蛋白质比对方法(参见例如pearson和lipman,proc.natl.acad.sci.usa&5:2444(1988)和pearson,meth.enzymol.183:63(1990))。简单地说,fasta首先通过鉴定具有最高同一性密度(densityofidentities)(如果ktup变量为1)或成对同一性(pairsofidentities)(如果ktup=2)的查询序列和测试序列共有的区,来表征序列相似性,而不考虑保守氨基酸取代、插入或缺失。使用氨基酸取代矩阵,通过比较所有配对氨基酸的相似性,对具有最高同一性密度的10个区重新评分,并“修整”各区的末端以只包括有助于最高评分的那些残基。如果有其评分大于“截断值(根据序列的长度和ktup值通过预先确定的方程式计算)”的几个区,则检测修整的起始区以确定各区是否可连接形成具有空位的近似比对。最后,利用needleman-wunsch-sellers算法的修改(needleman和wunsch,j.molbiol.48:444(1970);sellers,siamj.appl.math.25:787(1974)),这允许氨基酸插入和缺失,对2个氨基酸序列的最高评分区进行比对。fasta分析的说明性参数为:ktup=1,空位开放罚分=10,空位延伸罚分=1,取代矩阵=blosum62。可按pearson,meth.enzymol.183:63(1990)的附录2的说明,通过修改评分矩阵文件(“smatrk”),将这些参数引入fasta程序。本文所用术语“单克隆抗体”是指获自基本同源的抗体群的抗体,即,包含各个抗体的群相同,不同的是可能少量存在的可能的天然存在的突变,或例如翻译后修饰扩展中的差异,例如糖基化或末端赖氨酸加工。在一个实施方案中,可用于本发明的方法的多克隆抗体、单克隆抗体、scfv-fc、scfv、(fab’)2、fab、双抗体或vhh抗体任选与其它标记偶联或包含其它标记。用于本发明方法的其它标记例如可为放射性同位素或荧光标记。术语“荧光标记”、“荧光染料”或“荧光团”在用于本发明的其它标记时如上定义,术语放射性同位素是指可用于本发明的方法以检测目标蛋白质的放射性同位素的任一种,例如14c、3h、32p、125i、131i或125i。按照一个实施方案,本发明方法包括选择上文公开的本发明方法的步骤(d)的宿主细胞。因此,本发明方法包括选择在其表面展示目标蛋白质的上文公开的宿主细胞。术语“选择”在用于本发明的方法时是指鉴定和/或分离在其表面上展示与本发明的第二标记非共价结合的目标蛋白质和通过上文公开的方法检出的细胞,并将宿主细胞与例如不在其表面上展示目标蛋白质的宿主细胞分离的过程。本发明方法中的选择可包括本领域技术人员已知的各种技术,例如免疫淘选(immuno-panning)(参见例如wysocki等,proc.nati.acad.sci.usa第75卷,第6期,第2844-2848页,1978年6月)、磁激活细胞分选(macs)、流式细胞术、荧光激活细胞分选(facs)或基于液滴的微流体法(参见例如mazutis等,2013,natureprotocols8,870–891)。本发明的选择细胞可作为例如待从与通过上文所公开的方法不在其表面展示目标蛋白质的宿主细胞分离或分开的选择的一部分。例如,facs可用来将细胞分捡到不同的小瓶或容器中,或macs可用来分离在其表面展示蛋白质的宿主细胞,或基于液滴的微流体法可用来选择和分离在其表面展示目标蛋白质的本发明的宿主细胞。在一个实施方案中,可采用本发明方法选择展示表型改变的蛋白质的细胞。因此,通过本发明方法选择宿主细胞可用来选择表达例如表型改变的目标蛋白质或表型改变的至少一种目标蛋白质的宿主细胞。术语“表型改变的”与本发明方法一起使用时是指本发明的宿主细胞表面上展示的目标蛋白质或至少一种目标蛋白质的一个或多个改变的性质。按照一个实施方案,本发明的宿主细胞上展示的目标蛋白质的改变的表型可以是表面表达水平、蛋白质稳定性、蛋白质折叠或亲和力之一。因此,本发明方法例如可用来选择与不表达蛋白质或至少一种目标蛋白质的宿主细胞参比群相比展示增量的目标蛋白质的宿主细胞。例如,本发明方法可用来选择带有编码更有效指导目标蛋白质进入细胞的分泌途径的信号肽的多核苷酸的宿主细胞,或选择其中调节序列被改变(例如突变)并导致目标蛋白质表达增加的多核苷酸。对本领域技术人员是显而易见的是,上文公开的本发明方法和选择可重复例如至少一次,或2、3、4、5、6、7、8、9或10次以选择或富集展示增量的目标蛋白质的宿主细胞。选出的细胞然后可例如用来分离其中所包含的多核苷酸且随后对所述多核苷酸进行测序。可按照本领域已知的标准方案,例如公开于“molecularcloning”,第4版,cshlpress的方案,进行dna分离和测序。例如,还可使用市购可获得的试剂盒,例如qiagen’sdneasybloodandtissue试剂盒,或例如masterpure™yeastdnapurificationkit(epicenter),实现在本发明的选择的宿主细胞中的多核苷酸(例如质粒)。例如,还可采用本发明方法以检查使本发明第二标记突变的作用以评价突变或至少一个或多个突变对目标蛋白质的非共价结合的作用,例如可检查第二标记内的非保守氨基酸交换对目标蛋白质非共价结合的作用。例如,目标蛋白质的表面表达降低可能是与其中第二标记未被修饰的参比样品相比,目标蛋白质与本发明第二标记结合降低的结果。参比样品,例如可包含在任何操作前,例如在一个或多个氨基酸交换(保守或非保守)、氨基酸序列(例如n联糖基化信号)的添加或例如亲和力成熟之前,通过本发明方法在所述宿主细胞表面展示的目标蛋白质的至少一个,优选例如至少10、100、103、104、105或106个宿主细胞。因此,参比样品例如可包含宿主细胞,或由未落入facs选择参数(gates)内且包含在待分析的样品中的宿主细胞组成。因此,本发明的方法例如可用来工程改造和选择本发明的第二标记,并选择与目标蛋白质的结合亲和力提高或降低的第二标记类。优选本发明的方法例如可用来选择显示与目标蛋白质结合提高的本发明的第二标记。例如,上文公开的本发明方法还可用来选择展示目标蛋白质或表型改变的至少一种目标蛋白质的宿主细胞,其中改变的表型是蛋白质稳定性。在本发明的方法中,在结构背景(即有关蛋白质的结构完整性)下,或在功能背景(即有关蛋白质随时间推移保持其功能和/或活性的能力)下使用术语“蛋白质稳定性”。因此,本发明的方法可用来选择上文公开的宿主细胞,其如上文公开的在其表面上展示蛋白质稳定性提高或降低的目标蛋白质。蛋白质稳定性的提高或降低可通过例如识别或特异性结合目标蛋白质上的构象敏感性表位的抗体测定。例如,还可通过例如通过使用荧光标记的抗体定量检测本发明方法的宿主细胞表面上展示的目标蛋白质来评价蛋白质稳定性,例如可与上文公开的一个或多个荧光团连接或偶联的上文公开的抗体可用来检测宿主细胞表面上的目标蛋白质(poi)。这样,然后可对宿主细胞进行例如facs分析以评价与参比样品相比整体荧光信号的变化。在一个实施方案中,本发明的方法可用来选择其中改变的表型是亲和力的宿主细胞。例如,本发明的方法可用来选择对靶蛋白质或表位的亲和力提高或降低的poi(例如上文公开的抗体或抗体片段)。因此,本发明的方法可用来选择选择例如对表位的亲和力提高的抗体,在此可重复本发明方法以选择对表位的亲和力提高的抗体,在此可使用编码抗体或抗体片段,例如包含例如轻链和/或重链的互补决定区(cdr)例如cdr1、cdr2或cdr3的片段的质粒。即本发明的方法可用于本文公开的抗体或抗体片段的亲和力成熟。如本发明方法所用,术语“亲和力成熟”可指连续突变和选择由此选择较高亲和力的抗体的过程。术语“亲和力”或“结合亲和力”在本发明方法一起使用时,包括结合相互作用的强度,因此包括实际结合亲和力以及表观结合亲和力两者。实际结合亲和力是关联速率相对于解离速率的比率。因此,赋予或使结合亲和力优化包括改变这些分量的任一个或两个以实现所需的结合亲和力水平。表观亲和力可包括例如相互作用的亲合力。例如二价改变的可变区结合片段由于其化合价可显示改变或优化的结合亲和力。例如,所谓的“变体文库”也可用于本发明的方法,并可选择展示例如对指定表位有所需亲和力的cdr的宿主细胞,宿主细胞可通过本发明的方法选择。变体文库通常包括来源于命中文库(hitlibrary)变体概况的组合列举的计算机芯片上的氨基酸序列文库。命中变体文库进而是通过用于功能筛选的简并寡核苷酸文库体外表达的氨基酸序列文库。由于反向翻译(backtranslation)、优化密码子选择、核苷酸水平上的重组和所得组合核酸文库的表达所致,命中变体文库扩展了其它命中变体文库的序列空间。在一个实施方案中,通过使用包含序列变体轻链cdr序列与编码例如序列无变化的vh序列、例如编码序列无变化的vhcdr1、cdr2、cdr3和fr(例如fr1、fr2、fr3和fr4)序列、例如编码对目标蛋白质有预定亲和力的vh的序列无变化的多核苷酸组合的变体文库,上文公开的本发明的方法可用来选择对表位亲和力提高的抗体。例如,vl变体文库可包含轻链cdr的任一个(例如cdr1、cdr2、cdr3)的序列变体或vl变体文库,其中构架序列(fr)固定,并且编码vlcdr1、cdr2、cdr3的多核苷酸在其序列中是可变的,例如变体文库编码具有可变的cdr1、cdr2和cdr3多核苷酸序列的vlfr1-cdr1-fr2-cdr2-fr3-cdr3-fr4。编码vlfr1-cdr1-fr2-cdr2-fr3-cdr3-fr4的变体文库例如还可以是构架序列fr1、fr2、fr3或fr4的任一个或例如在cdr和fr序列两者中的序列变体,例如fr1、cdr1、fr2、cdr2、fr3、cdr3、fr4的至少1、2、3、4、或5、6或全部的序列变体。除上文公开的那些以外,例如可用于本发明方法的序列文库可包括通过基于pcr的技术,例如描述于proc.natl.acad.sci.usa第86卷,第3833-3837页,1989年5月;science(1989)246(4935):1275-1281或nucleicacidsresearch,2005,第33卷,第9期e81中的那些产生的文库,其中上文所述序列变体文库包含在合适的表达载体中,例如适于在酵母中表达vl或vh的表达载体,例如本文公开的表达载体,或例如pesc-leu、pesc-leu2d、p4x3、p4x4、p4x5、p4x6,或例如描述于yeast1993dec;9(12):1309-18中的那些。例如,本发明的方法可应用至少1次、2次、3、4、5或6次以选择目标蛋白质(例如具有所需性质的抗体),以例如选择展示具有对目标抗原或表位有所需亲和力的vl和vh链的抗体的酵母细胞克隆。例如,通过上文公开的本发明方法,通过使用合适的vhcdr序列变体文库,还可将本发明方法用于重链cdr的任一个的亲和力成熟,例如vhfr1-cdr1-fr2-cdr2-fr3-cdr3-fr4序列变体文库与编码vl链的序列无变化的多核苷酸组合可用于亲和力成熟。编码vhfr1-cdr1-fr2-cdr2-fr3-cdr3-fr4的变体文库可为例如构架序列fr1、fr2、fr3或fr4的任一个、或例如cdr和fr序列两者中的序列变体,例如fr1、cdr1、fr2、cdr2、fr3、cdr3、fr4的至少1、2、3、4、或5、6个或全部的序列变体。在一个实施方案中,本发明方法的选择步骤进一步包括将所选的宿主细胞与参比样品进行比较。因此,本发明方法的选择步骤包括将通过本发明方法选择的poi的表型与展示未改变表型的poi的参比宿主细胞的同一表型进行比较。例如,可将例如在上文公开的宿主细胞表面上展示、进行了至少一轮亲和力成熟的抗体或抗体片段的结合亲和力与亲和力成熟之前各个抗体的亲和力进行比较。其它实例可包括将通过上文公开的本发明方法选择的宿主细胞的荧光强度与其中宿主细胞不是通过本发明的方法选择的参比样品进行比较。例如,采用facs分析,可将通过本发明方法选择的宿主细胞与参比样品进行比较,或例如在典型的facs分析内,未落入facs分析设定的选择标准内的宿主细胞可用作参比样品。按照一个实施方案,目标由本发明方法的步骤(a)的至少一个或多个多核苷酸编码的蛋白质包至少一个含上文公开的fc结构域或fc结构域同二聚体。因此,本发明的目标蛋白质可例如包含上文公开的至少一个fc结构域,或上文公开的至少2个fc结构域,或例如3、4、5或6个fc结构域。按照一个优选的实施方案,本发明目标蛋白质的fc结构域是人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3之一或其序列变体。因此,本发明的poi可包含至少1个,例如1、2、3、4、5或6个本文公开的人igg1fc结构域,或例如人igg2fc结构域、或鼠igg2afc结构域、或鼠igg2bfc结构域、或鼠igg3fc结构域或其序列变体。本发明poi的fc结构域序列变体可另包含上文定义的一个或多个保守或非保守氨基酸取代,其优选不降低fc结构域与本发明第二标记的结合。一方面,本发明的目标蛋白质可以是n端fc结构域融合蛋白、c端fc结构域融合蛋白或抗体,优选本发明方法的目标蛋白质是上文公开的单克隆抗体。按照一个优选的实施方案,本发明的目标蛋白质是单克隆抗体,其可以是鼠单克隆抗体、小鼠-人嵌合单克隆抗体人源化单克隆抗体或人单克隆抗体。术语“嵌合抗体”在与本发明方法一起使用或用于本发明方法时包括单价、二价或多价免疫球蛋白。单价嵌合抗体可为例如由嵌合h链通过二硫桥与嵌合l链关联所形成的二聚体(hl),或例如二价嵌合抗体是2个hl二聚体通过至少一个二硫桥关联所形成的四聚体(h2l2)。例如,多价嵌合抗体还可通过使用聚集的ch区(例如来自igmh链)获得。本发明的鼠和嵌合抗体、片段和区可包含各自的重链(h)和/或轻链(l)免疫球蛋白。例如,嵌合h链可包含来源于对目标蛋白质有特异性的非人抗体h链的抗原结合区,其与人h链c区(ch)的至少一部分例如ch1或ch2连接。本发明的嵌合l链包含来源于与人l链c区(cl)的至少一部分连接的对目标蛋白质有特异性的非人抗体的l链的抗原结合区。例如,还可按照已知的方法步骤,通过各个多肽链的适当结合,制备具有相同或不同的可变区结合特异性的嵌合h链和l链的本发明的抗体、片段或衍生物(参见例如harlow和lane,antibodies:alaboratorymanual,coldspringharborlaboratorypress(1988))。嵌合抗体可通过重组dna技术构建,并描述于例如shaw等,j.immun.,138:4534(1987);sun,l.k等,proc.natl.acad.sci.usa,84:214-218(1987);waldmann(1991),science252:1657。一方面,本发明的目标蛋白质是人源化抗体,在此所用术语“人源化抗体”包括这样的抗体,其中来源于另一哺乳动物物种(例如小鼠、兔或大鼠)种系的cdr序列移植入人构架序列。其它构架区修饰可在人构架序列内以及在来源于另一哺乳动物物种种系的cdr序列内实现。本发明的人源化抗体可为任何抗体形式,例如上文公开的形式。在一些实施方案中,它们是完整的免疫球蛋白分子(全长抗体),包括igg、iga、igd、ige和igm、fab、f(ab')2、fv、微型抗体或双抗体。例如,可用于本发明的方法的人源化抗体还可从例如利用人种系免疫球蛋白基因的转基因动物的b细胞获得(参见例如macdonald等(2014)procnatlacadsciusa.apr8;111(14):5147-52)。本发明的目标蛋白质还可为例如人抗体,在此术语“人抗体”包括具有其中构架和cdr区两者来源于人种系免疫球蛋白序列的可变区的抗体。如果人抗体含有恒定区,则恒定区也来源于人种系免疫球蛋白序列。本发明的人抗体可包括不是通过人种系免疫球蛋白序列编码的氨基酸残基(例如通过随机或体外位点特异性诱变或体内体细胞突变引入的突变)。然而,术语“人抗体”在用于本发明时无意包括其中来源于另一哺乳动物物种(例如小鼠、大鼠或兔)种系的已植入人构架序列的cdr序列的抗体。人抗体或编码所述抗体的多核苷酸可获自例如携带人免疫系统而非小鼠免疫系统的部分的转基因小鼠。例如,可通过使针对人免疫球蛋白重链和轻链基因座是转基因的小鼠免疫,来制备可用于本发明的方法的编码完全人单克隆抗体的多核苷酸序列(参见例如us6,150,584)。编码人源化抗体的多核苷酸可通过例如本领域已知的标准方法获得。按照一个实施方案,本发明的第二标记特异性结合人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的fc结构域。术语“特异性地结合”和“特异性结合”,在整个本发明和对于本发明第二标记使用时,通常是指结合结构域例如本发明的第二标记或本文公开的抗体优先与存在于不同的蛋白质、蛋白质片段、肽或抗原的均质混合物中的特定蛋白质、蛋白质片段、多肽或抗原结合。通常,特异性结合相互作用可区分样品中需要的和不需要的蛋白质、蛋白质片段、肽或抗原超过107、108、109、5x109或1010,例如特异性结合可包括至少约10-7m-至少约10-12m,或例如至少1x10-7m、2.5x10-7m、5x107m、7,5x10-7m、10-8m、2.5x10-8m、5x10-8m、7.5x10-8m、10-9m、2.5x10-9m、5x10-9m、7.5x10-9m、10-10m、2.5x10-10m、5x10-10m、7.5x10-10m、10-11m、2.5x10-11m、5x10-11m、7.5x10-11m或10-12m的结合亲和力。例如,第二标记可包含a蛋白、l蛋白、g蛋白、a-g蛋白融合物、a蛋白的结构域e、d、a、b或其与人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的fc结构域结合的片段。除了特异性结合上文公开的fc结构域的上文提供的蛋白质以外,蛋白质例如免疫球蛋白新抗原受体(ignar)、hcab、anticalins(参见例如beste等,proc.natl.acad.sci.usa第96卷,第1898–1903页,1999年3月)、胱氨酸结微小蛋白(cystineknotminiprotein)/knottins(参见例如kolmar,febsj.2008年6月;275(11):2684-90)、亲和体(affibodies)(参见例如nord等,natbiotechnol.1997年8月;15(8):772-7)、适配体,darpin(参见例如binz等(2003)j.mol.biol.332,489-503)或affilins(参见例如ebersbach等(2007)j.mol.biol.372,172-185)可用于本发明的方法以特异性结合本文定义的抗体或可包含fc结构域或可能没有fc结构域的目标蛋白质。例如,免疫球蛋白新抗原受体(ignar)可用于本发明作为第二标记或例如包含在本发明的第二标记中。ignar来源于软骨鱼(例如鲨鱼),并且是重链抗体。ignar显示与其它抗体显著的结构差异,因为它们包含每链5个恒定结构域(ch)而非通常的3个,不常见位置上的几个二硫键和互补决定区3(cdr3)形成遮掩与其它抗体中的轻链结合的部位的延伸环(参见例如barelle等(2009)advexpmedbiol.655:49-62)。例如,术语“hcab”在用于本发明的方法时是存在于来自骆驼科物种(即单峰驼(camelusdromedarius)、双峰驼(camelusbactrianus)、大羊驼(lamaglama)、lamaguanoco、lamaalpaca和驼马(lamavicugna))中、缺乏其l链的抗体(参见例如muyldermans等(2009)veterinaryimmunologyandimmunopathology128,178–183)。hcab内的h链由3个而不是4个球状结构域组成,且2个恒定结构域与典型抗体的fc结构域(ch2–ch3)高度同源。对应于典型抗体的ch1结构域的结构域在hcab中缺失。因此,典型抗体的抗原结合片段fab在hcab中被简化成单一可变结构域。使称为vhh的这个可变结构域适于在不存在可变轻(vl)链结构域时在抗原结合中有功能。在一个优选的实施方案中,本发明的第二标记包含seqidno:1的氨基酸序列和/或seqidno:2的氨基酸序列。因此,本发明的第二标记可包含seqidno:1的氨基酸序列,或seqidno:2的氨基序列,或seqidno:1和seqidno:2两者的氨基序列。本发明的第二标记还可包含seqidno:1或seqidno:2的每一个或两个的序列变体,例如序列变体可包含上文定义的保守和非保守氨基酸取代。优选,氨基酸取代不导致第二标记与目标蛋白质特异性结合的丧失,例如结合亲和力不应大于1x10-7m、2.5x10-7m、5x107m、7.5x10-7m、10-8m、2.5x10-8m、5x10-8m。包含seqidno:1、seqidno:2或两者的氨基酸序列的本发明标记的序列变体与seqidno:1和/或seqidno:2有至少80%、85%、90%、95%或98%,或约92%-约98%,例如92%、93%、94%、95%、96%、97%或98%同一性,在此序列相似性可如上文所述计算。序列相似性可在seqidno:1和/或seqidno:2的氨基酸序列的全长内计算,但也可在长为10-100个氨基酸或20-90个氨基酸、30-80个氨基酸、40-70个氨基酸、50-60个氨基酸,例如长为约15-55个氨基酸、或长为约25-115个氨基酸、或长为约35-95个氨基酸、或长为约45-85个氨基酸、或长为约12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、32、34、35、36、37、38、39、40、42、46、48、51、54、56、57、59或60个氨基酸的氨基酸序列seqidno1和/或seqidno:2的任何部分或位置内计算。按照一个优选的实施方案,本发明的第二标记包含seqidno:3的氨基酸序列。因此本发明第二标记包含seqidno:6的氨基酸序列,其中seqidno:4的信号肽被除去。本发明的第二标记还可包含序列变体,其与seqidno:3有至少80%、85%、90%、95%或98%同一性,在此%同一性可按上文公开的计算,例如在整个seqidno:3的氨基酸序列内,或例如在上文公开的seqidno:3的氨基酸序列的任何部分或长度内计算。在本发明的一个方面,上文公开的第二标记,例如seqidno:3的第二标记可被进一步修饰以包含指导n-联糖基化的一个或多个氨基酸序列(糖基化共有序列)。例如,本发明的第二标记可进一步修饰以包含氨基酸序列n-x-s/t,其中x可以是脯氨酸以外的任何氨基酸。可将所公开的糖基化共有序列加入氨基端或羧基端或嵌入seqidno:3的本发明第二标记的氨基酸序列中,其中可将糖基化共有序列例如插入蛋白质结构域之间,例如插入seqidno:1和seqidno:2之间。将糖基化共有序列纳入本发明第二标记可用于例如提高宿主细胞中本发明第二标记的表达水平,所述第二标记与目标蛋白质共表达,或例如通过合适的细胞表达以获得足够量的本发明标记用于纯化和随后用于本发明方法。本发明的第二标记例如还可包含分隔其各个结构域的氨基酸序列(例如“间隔基”),例如公开于wo2014/101287的间隔基。在一个优选的实施方案中,本发明方法的分离和/或检测步骤进一步包括以下步骤:(i)使宿主细胞与特异性结合人igg1、人igg2、鼠igg2a、鼠igg2b或鼠igg3的fc结构域或其序列变体的可检测标记的抗体或抗体片段接触;(ii)使宿主细胞与被与第二标记结合的抗体特异性结合的抗原和/或表位接触,所述第二标记与不同于(i)中所用标记的另外的可检测标记偶联;(iii)检测所述宿主细胞中(i)和/或(ii)的标记;(iv)选择与参比样品相比显示(i)中所用标记和/或(ii)所用标记的量改变和/或显示两种标记的量改变的宿主细胞。术语“可检测”或“可检测地”在用于本发明的方法时是指可被检出的分子或颗粒,包括但不限于荧光、化学发光、放射,例如荧光标记包括上文公开的那些。例如,上文公开的本发明方法的分离和/或检测步骤还可通过使宿主细胞与以下特异性结合的可检测标记的抗体或抗体片段接触来进行:人igg1、人igg2、人igg3、人igg4、鼠igg2a、鼠igg2b或鼠igg3的轻链或其序列变体,例如人κ或λ轻链、鼠κ或λ轻链,或例如人igg1、igg2、鼠igg2a、igg2b或igg3的任一种的iggf(ab’)2片段。例如,与人轻链表位特异性结合的抗体可包括例如描述于clinimmunolimmunopathol.1991apr;59(1):139-55中的那些。例如,本发明方法的分离和/或检测步骤可包括以下步骤:(i)使宿主细胞与人igg1、人igg2、人igg3、人igg4、鼠igg2a、鼠igg2b或鼠igg3的轻链(例如人κ或λ轻链)或其序列变体特异性结合的可检测标记的抗体或抗体片段接触;(ii)使宿主细胞与被结合第二标记的抗体特异性结合的抗原和/或表位接触,所述第二标记与不同于(i)所用标记的另外的可检测标记偶联;(iii)检测所述宿主细胞中(i)和/或(ii)的标记;(iv)选择与参比样品相比显示(i)中所用标记和/或(ii)所用标记的量改变和/或显示两种标记的量改变的宿主细胞。按照一个优选的实施方案,检测和/或选择用于步骤(i)和(ii)的标记和选择本发明方法步骤(iv)中的宿主细胞包括上文公开的流式细胞术和/或facs和/或微流体术。在一个实施方案中,可重复上文公开的本发明方法。例如,可通过上文公开的本发明方法,对通过采用上文公开的本发明方法选出的宿主细胞进行例如至少1、2、3、4、5、6、7、8、9或10轮选择。通过本发明的方法选择的宿主细胞例如还可用来从中分离多核苷酸,并对分离的核苷酸进行例如测序、pcr扩增、基于pcr的诱变。pcr扩增在本发明的情况下使用时是指实际上任何靶dna序列可籍此选择性扩增的方法。该方法利用正向和反向序列特异性探针对,该探针对对侧接与靶dna的相对链杂交并界定待扩增序列的界限的靶dna序列的区有特异性。特别设计的寡核苷酸启动由热稳定dna聚合酶,例如水生栖热菌(thermusaquaticus)(taq)聚合酶或thermococcuslitoralis(vent™,newenglandbiolabs)聚合酶或tthi聚合酶(perkin-elmer)催化的多轮连续的dna合成。合成的每一轮通常被解链和重退火步骤分开,允许指定dna序列在小于1小时内扩增几百倍。本领域描述了用于pcr扩增的方法(参见例如pcrtechnology:principlesandapplicationsfordnaamplificationed.haerlich,stocktonpress,newyork,n.y.(1989);pcrprotocols:aguidetomethodsandapplications,编辑innis,gelfland,snisky和white,academicpress,sandiego,calif.(1990);mattila等(1991)nucleicacidsres.19:4967))。例如如果poi是抗体或与抗体构架融合或连接的抗体的抗体片段(例如cdr1、cdr2或cdr3),则pcr也可在本发明中用于poi的亲和力成熟(参见例如gram等,procnatlacadsciusa.1992apr15;89(8):3576-80)。在一个实施方案中,本发明方法的宿主细胞是酵母细胞,且其中本发明方法的步骤(a)进一步包括至少第一和第二酵母细胞的配对,在此所述第一和第二宿主细胞包含不同的多核苷酸,其至少一个编码含fc结构域的融合蛋白,且在此所述第一和第二宿主细胞的所述多核苷酸包含至少一个不同的选择标志物。可按照本领域的标准方案,例如按照公开于weaver-feldhaus等(2004)febsletters564,24-34,或例如公开于baek等,j.microbiol.biotechnol.(2014),24(3),408–420的方法,进行本发明方法中酵母细胞的配对。因此,在本发明方法的一个方面,一个或多个第一酵母细胞可带有重链文库,第二宿主细胞可带有轻链文库,在此两种宿主细胞或重链和轻链的多核苷酸包含不同的选择标记。例如,本发明方法中酵母细胞的配对可如下进行:可构建重链文库,并在具有下列营养缺陷型标志物的jar300酵母细胞中展示:ura3-52、trp1、leu2n200、his3n200、pep4:his3、prbd1.6r、can1和gal;该菌株以来源于bj5465并且是mata的eby100为基础。例如可通过编码侧接45bp的ura3基因的kanmu4基因的聚合酶链反应(pcr)产物的同源重组插入赋予g418抗性的kanmu4基因。轻链fab可在例如是(ura3、trp3、bj5464、mat-α)的yvh10细胞中表达。例如配对条件可如下:可使yvh10/ppnl30-lc(matk菌株)和jar300/ppnl20-hc(mat“a”菌株)的新培养物在可选择培养基(例如sdcaa+色氨酸或sdcaa+尿嘧啶)中生长。例如可将各培养物的1od600/ml(2u107酵母)混合在一起,沉淀,重新悬浮于200wlypd中后,接种在预热30℃ypd板中心,无需随后铺展。然后例如将板在30℃下孵育约4-6小时。然后可将酵母点重新悬浮于sdcaa培养基中。可根据10%二倍体形成接种合适的稀释物并接种在sdcaa琼脂板上,或可以边搅拌时在30℃下在液体sdcaa培养基中生长。开始生长时od600读数例如优选低于0.1od600/ml以允许二倍体生长超过非生长性的单倍体。对于fab文库产生,可使用较大量的酵母,因此可调整体积。在一个实施方案中,本发明提供seqidno:5的分离的核酸。术语“分离的”在用于本发明的核酸时是指基本不含其它核酸序列,例如通过琼脂糖电泳或例如通过测定比率od260/od280测定的例如至少约20%纯、优选至少约40%纯、更优选至少约60%纯、甚至更优选至少约80%纯和最优选至少约90%纯的核酸序列。分离的核酸序列可通过用于基因工程的标准克隆方法获得以将核酸序列从其天然位置移到它将在其中再扩增的不同位点。克隆方法可包括例如切下和分离包含编码多肽的核酸序列的所需核酸片段,将片段插入载体分子或质粒中,在此统称为“构建体”、“质粒”或“载体”,并将重组载体掺入多拷贝或克隆的核酸序列将在其中复制的宿主细胞中。核酸序列可以是基因组的、cdna、rna、半合成或合成源的或其任何组合。该术语涵盖例如(a)具有天然存在的基因组分子的一部分的序列但不被侧接它天然存在于其中的物种的基因组中的分子一部分的编码序列的至少一个侧接的dna;(b)以所得分子不同于任何载体或天然存在的基因组dna的方式掺入载体或原核生物或真核生物的基因组核酸中的核酸;(c)不同的分子例如cdna、基因组片段、通过聚合酶链反应(pcr)、连接酶链反应(lcr)或化学合成产生的片段或限制酶切片段;(d)是杂种基因(即编码融合蛋白的基因)的一部分的重组核苷酸序列,和(e)作为不是天然存在的杂种序列的一部分的重组核苷酸序列。术语“核酸”在用于本发明时进一步包括修饰的或衍生化核苷酸和核苷,例如但不限于卤化核苷酸,例如但不仅仅是5-溴尿嘧啶和衍生化核苷酸例如生物素标记的核苷酸。一方面,本发明还提供在严格条件下与seqidno:4的核酸分子杂交的核酸分子。术语“严格条件”在用于本发明的任何分离的核酸时是指本领域已知的参数,例如本文所用严格条件,是指在3.5×ssc、1×denhardt溶液、25mm磷酸钠缓冲液(ph7.0)、0.5%sds和2mmedta中在65℃下杂交18小时。这之后是在65℃下在2×ssc、0.1%sds中的4次滤器洗涤20分钟和在0.3×ssc、0.1%sds中的一次洗涤直到20分钟。可使用产生相同严格性程度的其它条件、试剂等。在一个实施方案中,本发明提供由seqidno:5的核酸序列编码的分离的蛋白质,其中氨基酸序列为seqidno:4。因此,本发明提供的蛋白质包含seqidno:3的氨基酸序列。术语“分离的蛋白质”在用于本发明的蛋白质时是指基本不含其它细胞组分例如脂质、dna、rna和细胞蛋白质的蛋白质。因此如果本发明蛋白质为至少60%、或至少70%、或至少80%、优选至少90%、95%纯时,则本发明的蛋白质被称为基本不含细胞组分;例如,术语分离的蛋白质还可是指通过在合适的宿主细胞表达分离的核酸分子所产生的蛋白质。在一个实施方案中,本发明提供含有包含seqidno:5的核酸序列或在严格条件下与seqidno:5的核酸序列杂交的核酸的至少一个核酸分子的宿主细胞。因此,本发明提供上文公开的宿主细胞,其含有包含seqidno:5的核酸序列的至少一个核酸分子。例如,本发明的宿主细胞可包含适于在该宿主细胞中表达seqidno:5的核苷酸序列的载体或质粒。用于指导表达本发明的seqidno:5核酸的确切表达载体可取决于宿主细胞,但可包括例如pcmv、pcdna、p4x3、p4x4、p4x5、p4x6、pvl1392、pvl1393、pacyc177、prs420,或如果基于病毒的载体系统,则可使用例如pbabepuro、pwpxl、pxp衍生载体。在一个实施方案中,本发明提供通过培养包含核酸分子(例如可包含seqidno:5的核酸序列)的宿主细胞来产生蛋白质的方法,将所述宿主细胞在足以表达蛋白质的条件下培养,表达由seqidno:5的核酸序列编码的蛋白质,并分离和纯化由seqidno:5编码的蛋白质。例如,可通过本领域已知的任何技术,例如脂转染、电穿孔、磷酸钙转染、病毒转导,进行可应用引入包含seqidno:5的核酸分子的上文公开的方法。然后可使细胞在足以表达蛋白质的条件下生长。例如,可使含有包含seqidno:3的至少一个核酸分子的哺乳动物细胞在含有10%fbs的dmem中生长,并在37℃下在10%co2中孵育,或例如在无蛋白质培养基中孵育以利于随后的分离和纯化,或例如在grace昆虫培养基、expressfive®sfm或highfive®培养基(lifetechnologies)、ynm培养基、ypd液体培养基或例如pichiapink(lifetechnologies)中孵育。在接种后,可允许细胞生长例如12-408小时,例如约12-约400小时,例如14小时、16小时、18小时、20小时、24小时、36小时、48小时、72小时、96小时-约120小时、144小时、168小时、192、216小时、240小时、264小时、288小时、312小时、336小时、360小时、384小时、408小时。随后,可分离并纯化由包含本发明的seqidno:5的核酸编码的蛋白质。例如,可通过层析法,例如离子交换层析法、大小排阻层析法、硫酸铵沉淀或超滤,分离并纯化本发明的蛋白质。在本发明的一个优选的实施方案中,纯化的蛋白质包含seqidno:3的氨基酸。因此,本发明的纯化的蛋白质缺乏信号序列,例如其中除去了seqidno:4的氨基酸序列的肽序列。按照本发明的一个优选实施方案,分离和纯化的蛋白质是多聚体,例如分离和纯化的蛋白质包含至少2或4个亚基,其每一个包含seqidno:3的蛋白质,优选本发明的分离和纯化的蛋白质是四聚体。在本发明的一个实施方案中,上文公开的分离和纯化的蛋白质可用于上文公开的本发明方法。例如,本发明的分离和纯化的蛋白质在本文的方法中可用作第二标记用于上文公开的含fc蛋白质的非共价表面展示。例如,本发明的蛋白质可用于单克隆抗体的表面展示,或例如含fc结构域的抗体片段的表面展示,以选择例如具有所需表型(例如对指定表位或抗原的亲和力提高)的抗体或抗体片段。在一个实施方案中,本发明提供组件试剂盒,其包含上文公开的第一标记、上文公开的包含seqidno:3的氨基酸序列的分离的蛋白质或上文公开的包含seqidno:5的核苷酸序列的核酸分子和上文公开的宿主细胞。本发明组件试剂盒中所包含的核酸分子和/或蛋白质可以冻干形式提供。在本发明的一个方面,宿主细胞、第一标记和第二标记可以单独的小瓶或包装提供。本发明组件试剂盒可进一步包含本发明方法和其中所含材料的使用的使用说明。要了解,本发明不限于本文所述具体的方法、方案和试剂,因为这些可变化。还要了解,本文所用术语是仅用于描述具体实施方案的目的,并无意限制仅受随附权利要求书限制的本发明的范围。除非另有说明,否则本文所有技术和科学术语具有本领域普通技术人员通常理解的相同含义。实施例实施例1:链霉抗生物素-zz(sa-zz)的产生和制备链霉抗生物素和金黄色葡萄球菌(staphylococcusaureus)a蛋白衍生的zz-结构域的嵌合构建体的dna序列在geneart®(lifetechnologies)中合成,并克隆至含有pac选择标志物的基于pcmv的载体中。合成的序列含有:人生长激素信号肽、链霉抗生物素基因、gs-接头和2拷贝的z-结构域。将cho-s细胞用该质粒转染以产生蛋白质。然后使用与igg连接的nhs激活的琼脂糖(通过蛋白质上的伯氨基)的亲和层析法和大小排阻层析法(hiloadsuperdex200pg柱,gehealthcare),从上清液中纯化蛋白质。选出稳定的细胞,并用来产生sa-zz。在与igg连接的nhs激活的琼脂糖(通过蛋白质上的伯氨基)(di-17e6)上纯化分泌的粗物质。考马斯蓝凝胶分析显示表观分子量为91kd(图1),其单体具有31kd的预期大小。octet分析显示sa与生物素化靶标和zz与抗体两者的结合(图2)。蛋白质印迹分析还表明sa-zz融合蛋白结合igg和生物素化蛋白质两者(图1)。实施例2:质粒用于酵母转化的所有载体基于市购可获自invitrogen的pyd1-质粒骨架(yeastdisplayvectorkit(酵母展示载体试剂盒),d版,#v835-01)。各载体的构建使用酿酒酵母中的同源重组机器进行。用于该目的的抗体基因使用phusion®high-fidelitydna聚合酶(newenglandbiolabs)与在两侧引入同源序列40-50bp突出端的hplc纯化的引物(eurofinsmwgbiotech)扩增。为了能够在酵母中选择重链和轻链质粒,轻链质粒含有leu营养缺陷型标志物,而重链质粒编码trp标志物。将来自待展示的各抗体(马妥珠单抗、阿达木单抗、抗cmet-b10、曲妥珠单抗)的vh和vl区克隆至已含有信号序列和igg1ch1-fc区(pyd-mcs-ch1-fc)或λ/κ恒定区的各自的质粒中。使用抗体基因5’符合读框克隆的αmfpp8信号序列指导可溶性抗体分泌。抗体基因的表达通过半乳糖诱导型gal1-启动子驱动。实施例3:cdr-h3文库产生从geneart®(lifetechnologies)订购并获取含有内部选出的人cmet特异性噬菌体展示衍生抗体的vh区的cdr-h3突变文库。在包含30个核苷酸dna序列段的文库内,选择掺杂混合物以保持亲代cdr-h3的各个氨基酸具有60-70%频率,并避免引入终止密码子以及半胱氨酸和甲硫氨酸残基。合成的dsdna构建体用作pcr扩增的模板。在pcr期间,实现了在酵母中文库两端的45bp突出端用于缺口修复克隆。按照生产商的方案,使用phusion®high-fidelitydna聚合酶(newenglandbiolabs)进行96次反应。对于每次反应,以50µl的总体积使用50ng预扩增的模板dna。在完成pcr后将反应物混合,并使用wizard®svgel和pcrclean-up系统(promega)纯化,得到携带与序列的接纳体-质粒5’和3’的同源序列连接的最终量为102µg文库-dna。下列引物用于扩增:正向引物(up-primer)5`-ctattgccagcattgctgctaaagaagaaggggtacaactcgataaaagagaagtgcagctggtgcagtctg-3`,反向引物(low-primer)5`-ctcttggaggagggtgccagggggaagaccgatgggcccttggtggaggctgaggagacggtgaccaggg-3`)使文库与已包括在质粒骨架中的信号肽和人ch1-fc区符合读框地克隆。对于缺口修复克隆,pyd-mcs-ch1-fc使用限制性内切酶bamhi和ecori线性化,并通过wizard®svgel和pcrclean-up系统纯化。按照由benatuil和同事确立的方案,在eby100细胞中进行通过缺口修复克隆的文库产生。10次电穿孔用4µg线性化载体和10µgpcr产物进行。文库大小通过稀释接种估算,并显示1.5×109个转化子。实施例4:用于抗体俘获的细胞表面功能化对于抗体俘获,构建由链霉抗生物素和zz结构域组成的融合蛋白(sa-zz,参见实施例1),并从稳定转染的cho-s细胞中纯化。为了研究是否可将融合物俘获在细胞表面,同时保持抗体-结合能力,使用市购可获得的生物素-试剂(生物素-peg-scm3.4kda,creativepegworks)使细胞表面生物素化,接着加入重组sa-zz融合蛋白。首先,测试目标在于足够标记细胞表面的生物素试剂和sa-zz的量。为此目的,使用1–6mg生物素-peg-scm3.4kda/1×107个细胞,使bj5464酿酒酵母细胞生物素化。为了分析表面标记的程度,使细胞与链霉抗生物素-dylight633一起孵育,并通过流式细胞术检测荧光。随着试剂的量增加,荧光信号持续增强(图4a)。因为用1mg生物素试剂标记的细胞已显示与阴性对照相比荧光增加达约1个数量级,因此选择1mg试剂用于后续sa-zz固定以避免在高密度抗体加载到细胞表面上可能引起的抗原结合时的亲合力作用。使用不同量的sa-zz(2µg、3µg、4µg)与生物素化细胞一起孵育以使具有igg俘获结构域的细胞表面功能化。使功能化细胞与a蛋白特异性fitc缀合的山羊抗体(ab7244,abcam)一起孵育,允许流式细胞分析固定化细胞表面。sa-zz的量的增加导致由固定化俘获结构域的较高表面密度引起的荧光信号加强(图4b)。对于所检测的所有sa-zz浓度,检出比阴性对照明显的荧光迁移。实施例5:igg俘获检查了功能化细胞仍分泌可溶性高质量抗体的能力。将bj5464细胞用编码3种不同的单克隆抗体的重链和轻链质粒转化。这些抗体是马妥珠单抗(kd113nm)、阿达木单抗(kd30pm)和抗cmet-b10(以kd40nm分析)(参见:表1)。通过将修饰的细胞与表1所列的荧光标记的抗原和抗fc特异性alexafluor647缀合的f(ab`)2片段(109-606-008,jacksonimmunoresearch)或山羊抗fcpe缀合的抗体(109-115-098,jacksonimmunoresearch)一起孵育进行igg俘获的分析用于通过流式细胞术检测igg展示(图5a-c)。作为阴性对照,仅对细胞染色以检测igg展示(图5d-f)。3种所测的双重染色细胞样品显示抗体展示和抗原结合的阳性信号,表明与仅用抗fc标记的各自的阴性对照相比的双重阳性荧光信号。为了进一步分析igg表达和zz结构域占据的程度,通过本发明的方法使携带马妥珠单抗的重链和轻链质粒的bj5464细胞功能化,并使用半乳糖培养基诱导抗体表达。在细胞用zz结构域标记后,允许细胞生长,并分泌马妥珠单抗。正如所预期的,与细胞壁共价连接的zz结构域的数目在固化后6和20小时降低,很可能因细胞生长和发育以及在20℃下在培养基中长期孵育时融合蛋白降解或失活所致(图6c-e)。使用山羊抗fcpe缀合的抗体(图6i,j)同时监测固定化zz结构域被马妥珠单抗占据(图6b),显示有关zz结构域的类似标记形式。为了研究未占用的zz结构域是否定居在未被分泌的马妥珠单抗覆盖的细胞表面,在诱导马妥珠单抗分泌且过量与戈利木单抗抗体孵育后3个时间点上收集细胞。通过加入相应的荧光标记的抗原tnfα,监测戈利木单抗与酵母细胞表面上的未占用的zz结构域结合。表达6小时后,所有功能化细胞俘获内源马妥珠单抗(图4i),而在20小时孵育后,用外部添加的抗体染色的细胞低和完全不存在(图4h),表明居住在酵母细胞表面的zz结构域全部被内源产生的抗体饱和。实施例6:酵母菌株、培养基和配对带有抗体轻链的酵母菌株是获自美国典型培养物保藏中心(americantypeculturecollection,atcc)的酿酒酵母菌株bj5464。酿酒酵母菌株eby100带有抗体重链,并用来产生极俭重链文库(parsimoniousheavychainlibrary)。该菌株获自invitrogen作为pyd1酵母展示载体试剂盒(#v835-01,lifetechnologies)的组件。整个抗体和文库由配对后得到的二倍体细胞分泌。对于携带重链和/或轻链质粒的酵母细胞的培养,使用市购可获得的drop-out混合物和最小sd基料混合物(#630414、#630413、#630417和#630411,clontech),制备含有全部必需试剂(色氨酸和/或亮氨基酸除外)的培养基。基因表达的诱导在与最小sd基料gal/raf(#630421,clontech)、含有8.56gnah2po4和5.4gna2hpo4,ph7.4和11%w/vpeg8000的1m缓冲液混合的同一drop-out混合物中进行。用于酵母细胞配对的丰富培养基(ypd)从20g葡萄糖、20g胨和10g酵母提取物(merckkgaa)中制备。使用2%甘油和0.67%difco™酵母氮源基础(bd)制备冷冻培养基(freezingmedium)。配对酵母配对被用于使单倍体eby100细胞(mata)中的cdr-h3文库与单倍体bj5464细胞(matα)中相应的轻链组合得到携带重链和轻链质粒的二倍体细胞。因此首先将分别携带针对抗体、重链或轻链的质粒的酵母细胞在30℃和250rpm下在其各自的选择培养基中独立培养过夜。次日,将各菌株1×108个细胞重新悬浮于50µlypd-培养基中,混合,并滴入预热的ypd板中间,之后将板在30℃下培养过夜。然后用10mlypd-培养基洗出薄的细胞层。为了计算配对过程的效率,测量细胞悬液的od600,并制备稀释板。将细胞悬液在500ml双重选择培养基中培养。随后在培养后24和48小时,将2×109个细胞转移到新的培养基中。然后将二倍体细胞重新悬浮于冷冻培养基中,转移到冷冻小瓶中,并保存在-80℃下。实施例7:基因型-表型偶合和文库筛选为了证实对于本发明方法存在基因型-表型连接,进行了混合实验。以1:1,000,000比率将egfr-结合马妥珠单抗展示细胞(图5a)与曲妥珠单抗展示细胞(图5b)混合,模拟常规免疫文库的大小。将sa-zz固定在酵母细胞表面,并将混合物转移到诱导培养基,孵育20小时,随后用egfr-藻红蛋白(egfr-pe)缀合物和抗fcalexafluor647缀合的抗体进行荧光标记,并进行连续4轮分选(图5c-f)。在4轮分选和再分选后,通过流式细胞术进行针对egfr结合的细胞的单细胞分析。10个分析的克隆中,9个显示与egfr-pe结合,证实了成功富集(数据未显示)。受该结果的鼓舞,进行了来源于内部噬菌体展示文库筛选活动的cmet特异性抗体的亲和力成熟(kd40nm)。为此,进行了重链可变结构域cdr-h3环的极俭诱变,其中所有10个残基用除cys和met以外的所有19个氨基酸随机变化,保持该位置的原有氨基酸的频率为约60-70%。在酿酒酵母菌株eby100中构建文库,产生约1.5×109个转化子。随机挑选的克隆的序列分析显示cdr-h3的10个残基中平均有3.4个取代。使单倍体文库细胞与单倍体bj5464(携带抗体的亲代轻链的mat-α细胞)配对,其配对效率为15%。通过其在双重选择培养基中生长的能力和被sa-zz装饰来选择二倍体。分泌的抗体被细胞表面重新俘获,用抗fcalexafluor647缀合的f(ab`)2和pe缀合的cmet标记,通过facs分离双重染色细胞(图6)。为了获得具有较高亲和力的结合剂,在3轮分选中将cmet浓度从250nm连续降到15nm。在3轮分选后,分离酵母细胞的质粒dna,并用于转化大肠杆菌细胞。对来自所得单个集落的重链质粒的vh区测序,使用独特序列与亲代轻链质粒一起通过电穿孔共转化酵母细胞。在酵母细胞表面进行有关cmet-结合的表型分析。在100nmcmet浓度下,一个变体显示在展示比归一化时与亲代抗体相比对抗原结合的荧光信号略有增强(图7)。随后将所选的序列亚克隆至哺乳动物载体用于在expi293f™细胞中的可溶性表达。在抗体表达和纯化后,抗体变体的动力学分析显示与亲代抗体(图7c)相比,与cmet(图7d)的亲和力提高5倍。这个差异主要由kdis降低驱动。实施例8:细胞表面操作使用3.4kda生物素-peg-scm(creativepegworks)使用酵母细胞生物素化。为此,将1×107个细胞用碳酸盐缓冲液(4.2%nahco3和0.034%na2co3,ph8)洗涤2次,并重新悬浮于含有1-4mg溶解的生物素试剂的缓冲液40µl的最终含量中。然后将混合物在室温下孵育15分钟。使细胞沉淀,用含有100mm甘氨酸的1mlpbs洗涤2次以使游离生物素-peg-scm饱和。随后通过将细胞与0.76–1.52µm链霉抗生物素-zz融合物在pbs中在冰上再孵育15分钟,进行生物素化细胞的功能化。在最后的步骤中,将细胞用1mlpbs洗涤1次。实施例9:igg展示、荧光染色和facs对于分泌的igg-分子在酵母细胞上的再俘获和展示,使用培养皿或深孔板以1×107个细胞/ml的起始细胞浓度在20℃下20小时,在静置培养中进行了表达。为了特异性标记表面生物素,使1×107个生物素化细胞与1.3µm链霉抗生物素-dylight633缀合物(thermoscientific/pierce)一起在20µl中在4℃下避光孵育15分钟,在标记后用pbs洗涤一次。通过将1×107个细胞与20µl中的3.3µm来源于山羊的a蛋白特异性fitc缀合的检测抗体(abcam)一起在4℃下避光孵育15分钟,来进行表面固定化zz结构域的染色。在抗体孵育后,细胞用pbs洗涤一次,并保持在冰上直到分析。使用20µl中的0.5µmalexafluor647缀合的山羊抗fcf(ab´)2-片段或pe缀合的山羊抗fc抗体(均为jacksonimmunoresearch)和不同浓度的相应的荧光标记的抗原(cmet或egfr,merckserono和tnfα,r&dsystems),进行展示抗体的染色。抗原cmet和egfr的标记使用lynx快速rpe试剂盒(biorad)实现。tnfα的标记使用dylight650nhs酯(thermoscientific)实现。对于用pe缀合的抗原染色,将细胞在冰上并避光孵育15分钟,用1mlpbs洗涤一次。在实验前,滴定外部给予的抗体戈利木单抗(msd)以标记游离表面zz结构域的浓度以确定最大信号强度。然后将戈利木单抗处理的细胞与250nmdyligt650缀合的tnfα一起孵育。使用summit5.3,用mofloxdp细胞分选仪(beckmancoulter)进行cdr-h3文库的选择。在最初的选择中,处理2×108个细胞。在接下来的2轮分选中,剩余的文库多样性为至少100倍超采样的。实施例10:亚克隆、哺乳动物表达和蛋白质纯化进行了抗体基因亚克隆至哺乳动物表达质粒,以使得能够在expi293f™细胞(lifetechnologies)中可溶性地产生igg分子。因此通过pcr扩增具有与接纳体质粒(lucigen)的同源重叠的目标基因。然后使1种shot®top10化学感受态大肠杆菌细胞(lifetechnologies)与1µlpcr产物和1µl质粒一起孵育30分钟,并按照生产商的方案转化。克隆的选择发生在lb-amp板中。在37℃下孵育24小时后,挑选集落,分离质粒-dna,送往mwgbiotech用于测序。然后按照生产商的方案,通过expifectamine™293转染试剂盒(lifetechnologies),使用正确的质粒-dna用于转染expi293f™细胞。使细胞在37℃、180rpm和5%co2下孵育5天。通过将细胞悬液以1500×g离心10分钟,收获含有igg的上清液。使用prosep®-aspincolumns(merckmillipore),从上清液中纯化抗体。实施例11:结合动力学采用octetred系统(fortebio,palllifescience),分析亚克隆和纯化的igg-分子的结合动力学。将2.5µg/mlpbs的抗体在抗人-fc(ahc)生物传感器上俘获600s。所有测量在动力学缓冲液(pbsph7.4、0.1%(w/v)bsa、0.02%tween®20)中进行。测量与cmet(10nm,50nm,100nm)的关联300s接着600s的解离。仅使用动力学缓冲液分析每种抗体的一个对照,并从产生于与cmet相互作用的全部结合曲线中减去。在savitzky–golay过滤后使用1:1结合模型,用fortebio数据分析软件8.0评价处理的结合曲线。实施例12:igg展示酵母群的标记为了从总的酵母细胞库鉴定展示完整igg的酵母细胞(其以轻链和重链在其表面的装配为标志),如上文所述诱导酵母细胞的非共价表面展示(参见实施例9),并用pe缀合的山羊抗人λ或κf(ab’)2连同alexa647缀合的抗原(thermofisher)染色。实验中得到的结果表明抗原结合和igg展示水平之间的相关性(图11a)。用分别对2种抗原即抗原-a和抗原-b有特异性的2种独立的抗体克隆进行了轻链实验。如图11b所示,所得结果在用抗fc抗体和用抗轻链抗体染色之间相当。出乎意料的是,抗轻链染色显示相关性提高(图11b)。实施例13:通过轻链标记和选择的克隆富集在应用轻链染色方法用于克隆富集的一个实施例中使用本发明的酵母展示系统(参见实施例12)。为了克隆富集,将应用上文公开的本发明方法在其表面展示y-抗原特异性抗体的酵母细胞克隆(抗原y特异性酵母展示克隆)与抗原z特异性酵母展示克隆以1:1,000,000的比率混合。y-抗原特异性抗体针对存在若干同种型的目标蛋白质(poi),其之一包含抗原-x,但不含抗原-y。因此,y-抗原特异性抗体不识别包含抗原-x的poi同种型。在实施例1-6所述酵母操作程序后,使用pe缀合的山羊抗人λf(ab’)2(southernbiotech)以标记igg展示群,筛选108个酵母细胞并针对3轮富集进行分选用于后继的facs分选。在使用sonysh800细胞分选仪进行3轮细胞分选和富集后,随后通过将其与alexa647缀合的抗原-x、抗原-y或抗原–z(无关蛋白质,阴性对照)一起孵育,对分选的细胞(即图11b所示选通参数内的细胞)进行分析。从所选的细胞中观察到对alexa647缀合的抗原-y的明显的结合特异性,表明从其最初的1:1,000,000比率成功地富集正确的抗体克隆,并且在选择过程中成功消除了不需要的背景克隆(图12)。实施例14:通过轻链改组的亲和力成熟选择作为本发明的酵母展示方法还可用于轻链改组亲和力成熟的概念验证,构建与来自亲代抗抗原-1克隆的重链配对的轻链改组文库。在按上文实施例公开一样进行3轮分选和富集后,分离高亲和力抗原结合酵母细胞(图13a),并分离酵母质粒dna。重定抗体序列重新的格式,亚克隆至哺乳动物表达载体中,并在哺乳动物表达系统中表达,接着igg抗体纯化和结合动力学测量(biacoreinstrument,gehealthcare或octet,pallfortebio)。来自轻链改组筛选的所选克隆的结合亲和力与亲代克隆相比提高约5倍(图13b)。表表1:通过本发明方法在bj5464细胞上展示的抗体的抗原特异性和kd值抗体抗原kd马妥珠单抗huegfr0.34nm阿达木单抗hutnfα30pm抗cmetb10hucmet40nm当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1