一种检测人体免疫状态的检测系统的制作方法
本发明涉及基因检测
技术领域:
,具体地,涉及一种通过检测目标基因的表达量来评价人体免疫状态的检测系统。
背景技术:
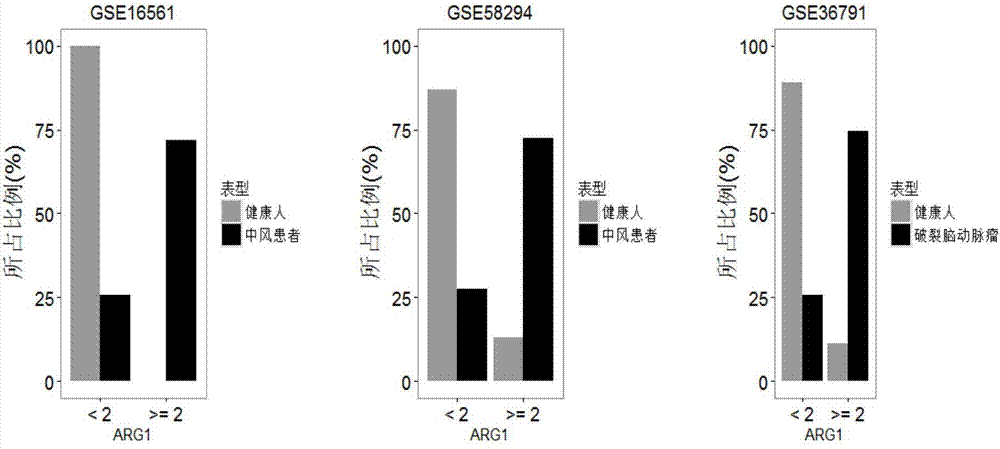
:免疫反应是人体对外源微生物入侵和内源机体异常的生理反应,表现在激活或抑制某些生物通路,因此人体免疫状态的异常可以指示人体受到外源微生物入侵或机体内有癌症等病变。检测人体免疫系统状态最常用的技术手段是血细胞计数,比如某种类型的白细胞数量。也有对血清中个别免疫相关蛋白的定量检测。无论是血细胞计数,还是免疫相关蛋白量检测,都只能大方向指示免疫失调。当今的精准医疗对免疫状态的检测有着更高的要求,需要对重要的分子通路进行检测,以利于疾病的精准分型。外周血作为一种微创源的检测方法,被广泛用于生物标志物的发现。文献中已经报道过一些不同的方法,例如:过敏性休克(septicshock)分类的问题。有文献报道过使用机器学习的方法对过敏性休克三种亚型的差异基因进行聚类。然而,对于机器学习的方法,如果不能有效的使用,很容易出现过拟合的现象。通常研究中都会采用机器学习中监督学习的方法,将研究在多个数据集中进行,其中一部分数据用于构建模型,而另一部分数据用于验证。在一个研究中,采用这种方法,发现11个基因在感染炎症(infectiousinflammation)中区分出无菌炎症(sterileinflammation)的分型中,效果良好。另外一种提高可重复性的方法是,抛弃使用个体基因,转而使用基因模型。这种方法在系统性红斑狼疮(systemiclupuserythematosus,sle)和一些其它疾病中被证明有很好的效果。为了从个体疾病中发现生物标记物,申请人猜想在更广泛的疾病类中可以观测到免疫系统的反馈。广泛的疾病类型指不限于感染免疫类疾病。事实上,免疫系统的功能紊乱在包括脑神经失调等在内的多种疾病类型中均有发现。一些免疫系统的紊乱可能以基因失调的方式反应在外周血中。在许多疾病中表现出的基因失调可能所揭示出的潜在的机理即是免疫应答。另外,申请人对发现有多大的潜在的临床应用更加感兴趣。临床应用包括疾病分类、疾病阶段、诊断以及治疗监测等多个方面。在这个方向上,gibson和他的同事们提出了“血液信息记录”的概念,该概念由10个从9条轴线中选出的具有代表性的基因。然而,申请人旨在找到检测更方便,花费更低,数量更少的基因集作为生物标记物。技术实现要素:本发明目的在于提供一种检测人体免疫状态的检测系统。本发明提供的一种检测人体免疫状态的检测系统,其检测包括如下基因的表达量:ifi27、isg15、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1、hp、anxa3、arg1、fcgr1b、s100a12、mmp9、il18r1、tlr5、gyg1、fcgr1a;前述任一或多个基因的表达量上调,则预示人体免疫状态不佳。本发明提供一种诊断/检测系统,能够检测如下任一或多个基因的表达量:ifi27、isg15、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1、hp、anxa3、arg1、fcgr1b、s100a12、mmp9、il18r1、tlr5、gyg1、fcgr1a,并将其应用于评价人体免疫状态或疾病诊断或愈后评估或用药评价,所述的疾病为感染类疾病、自免疫类疾病、癌症和脑血管疾病。。本发明提供的上述诊断/检测系统中,具体地,ifi27、isg15、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1任一或多个基因表达量的上调,提示机体罹患病毒类感染疾病;hp、anxa3、arg1、fcgr1b、s100a12、mmp9、il18r1、tlr5、gyg1、fcgr1a任一或多个基因表达量的上调,提示机体罹患细菌类感染疾病。进一步地,所述的疾病优选系统性红斑狼疮,前列腺癌、结直肠癌、川崎病、幼年特发性关节炎、脑血管病、艾滋病和/或肺结核。本领域技术人员应当理解,采用real-timercr、微阵列芯片、rna-seq测序、定制芯片和靶向测序等技术手段实现上述20个基因的表达量的检测并用于人体免疫状态或疾病诊断或愈后评估或用药评价的仪器或系统均属于本申请的保护范围。本发明提供了vrg基因和brg基因在制备检测病毒类感染和细菌类感染的检测试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用,所述vrg基因包括ifi27、isg15、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1;所述brg基因包括hp、anxa3、arg1、fcgr1b、s100a12、mmp9、il18r1、tlr5、gyg1、fcgr1a。进一步地,若待测机体外周血液中vrg基因任一或多个基因的表达量显著上调,提示待测机体罹患病毒类感染疾病,若待测机体外周血液中brg基因的任一或多个基因的表达量显著上调,提示待测机体罹患细菌类感染疾病。本发明提供了vrg基因在制备系统性红斑狼疮鉴定试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用,所述vrg基因包括ifi27、isg15、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1。进一步地,若待测机体外周血液中vrg基因任一或多个基因的表达量显著上调,提示待测机体罹患sle(系统性红斑狼疮)而非细菌类感染。本发明提供了hp基因在制备烧伤、创伤、败血症鉴别诊断试剂盒或制备中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中hp基因表达量显著上调,则提示待测机体罹患烧伤、创伤、或败血症。本发明提供了hp基因在制备前列腺癌和结直肠癌鉴别诊断试剂盒中的应用。进一步地,若待测机体外周血液中hp基因表达量显著上调,则提示待测机体罹患晚期前列腺癌或结直肠癌。本发明提供了anxa3基因在制备川崎病诊断试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中anxa3基因表达量显著上调,则提示待测机体罹患川崎病。本发明提供了anxa3基因在制备系统性幼年特发性关节炎和非系统性幼年特发性关节炎的鉴别诊断试剂盒中的应用。进一步地,若待测机体外周血液中anxa3基因表达量显著上调,则提示待测机体罹患系统性幼年特发性关节炎。本发明提供了anxa3基因在制备幼年特发性关节炎疗效评估试剂盒中的应用。进一步地,若待测机体外周血液中anxa3基因表达量显著下降,则提示幼年特发性关节炎疗效较好。本发明提供了arg1基因在制备脑血管病诊断试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中arg1基因表达量显著上调,则提示待测机体罹患脑血管病。本发明提供了isg15基因在制备hiv-1病毒感染出现明显症状和非明显症状的检测试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中isg15基因表达量显著上调,则提示待测机体hiv-1病毒感染者有明显症状。本发明提供了isg15基因在制备艾滋病疗效评估试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中isg15基因表达量显著或下降,则提示hiv-1病毒感染者疗效较好。本发明提供了fcgr1a基因在制备鉴定活跃型肺结核和潜伏型肺结核试剂盒中的应用或在制备检测人体免疫状态的检测系统中的应用。进一步地,若待测机体外周血液中fcgr1a基因表达量显著上调,则提示待测机体罹患活跃型肺结核。本发明提供了fcgr1a基因在制备肺结核疗效评估试剂盒中的应用。进一步地,若待测机体外周血液中fcgr1a基因表达量显著下调,则提示活跃型肺结核患者疗效较好。本发明的有益效果在于:本发明所声明的基因在外周血的表达水平可以指导多种疾病的精准分型、预后和疗效评估等方面。附图说明图1的上面3幅图为表1中10个vrg基因在3组sle(系统性红斑狼疮)数据中的整体变化倍数,其中,左上第一幅为外周血单核细胞的数据,第二幅为外周血全血数据,第三幅为rnaseq的数据;下面两幅为sle和其它疾病对比的vrgs的分布。图中sojia为系统性幼年特发性关节炎,staph为细菌性感染,psle为幼年系统性红斑狼疮。图2自左向右,左、中两幅为中风病人中arg1基因的变化倍数的分布;右图为arg1的变化倍数在颅内破裂动脉瘤病人中的分布。图3上面两幅为isg15基因变化倍数在进展和无进展型hiv病人中的分布情况;下面两幅为hiv病人给药处理后isg15变化倍数的分布情况。图中chloroq为一种药物名称;placebo为一种安慰剂。图4的左上和右上两幅图为fcgr1a基因的变化倍数在活动型和潜伏型肺结核病人中的分布;左下图为肺结核病人治疗前和治疗26周后fcgr1a变化倍数的分布;右下图为肺结核病人病中和康复后fcgr1a变化倍数的分布。图5左图为系统性幼年特发性关节炎和其它类疾病对比中anx3基因变化倍数的分布;右图为幼年特发性关节炎病人给药后anx3变化倍数的分布。图中,canakinumab为药物名称;placebo为一种安慰剂。图6上图为不同hp基因变化倍数的前列腺癌病人的生存曲线;下图左一为hp基因变化倍数在结直肠癌不同阶段病人中的分布;下图中间图为前列腺癌病人治疗反馈不同,hp变化倍数的分布;下图右一为不同数目肿瘤病人中hp变化倍数的分布。具体实施方式以下实施例用于说明本发明,但不用来限制本发明的范围。在不背离本发明精神和实质的情况下,对本发明方法、步骤或条件所作的修改或替换,均属于本发明的范围。若未特别指明,实施例中所用的化学试剂均为常规市售试剂,实施例中所用的技术手段为本领域技术人员所熟知的常规手段。实施例1公共数据的收集本发明用到的所有数据集均为公共数据集,且全部来自于美国生物技术信息中心(nationalcenterforbiotechnologyinformation,ncbi)的基因表达数据仓库(geneexpressionomnibus,geo)。研究主要包含两个阶段:甄选候选基因和验证测试候选基因,所用的数据集也分为两个批次:1、甄选候选基因用到的数据集候选基因的甄选作为本发明的研究基础,数据集的选择必须有严格的筛选标准:(1)数据必须通过预处理的过滤,即,数据质量必须过关,尽可能从数据源头上降低误差;(2)在保证数据质量的前提下,尽可能多的获取感染或自身免疫类疾病的数据;(3)数据必须是全血数据;(4)为保证后续差异表达基因筛选时,每种疾病数据贡献出的权重尽量平衡,对于对应疾病类型筛选出多组数据的疾病,本发明选取一组具有代表性的数据。代表性有以下几个方面的考虑:①数据样本量尽量大,以降低数据噪声;②检测时间尽量和现在接近,随着检测技术的越来越好,相信离现在越近的数据,检测也越准确;③数据样本尽可能纯净,即样本或是健康人,或是仅患有研究对应的疾病,保证数据的纯净也是为了降低数据噪声。经过以上几步的筛选后,最终,本发明第一批用于甄选候选基因的数据集共包含18组数据,20种疾病类型(其中,数据集gse33341和gse72810各包含两种疾病类型),如表1。需要说明的是,数据集gse68310和gse45536是时间序列的数据,本发明均是选用了数据样本第一个时间点作为试验组数据的。对于表1中的前10个疾病,将其分为两大类:①细菌感染类疾病和②病毒感染类疾病,每类包含5组数据。在候选基因筛选中,基因失调频率在每一类中的表现也是本发明选取的一个重要参考。2、验证测试候选基因用到的数据集选取候选基因后,需要在多组独立的数据中进行验证。用于验证的数据集一样需要通过预处理的过滤。本实施例主要介绍6个方面验证使用到的数据集:(1)用于区分细菌感染和病毒感染所用到的数据集:gse72829、gse60244、gse6269和gse42026。每组数据选取细菌感染和病毒感染的样本用于聚类;(2)对系统性红斑狼疮(systemiclupuserythematosus,sle)疾病验证中共用到6组数据,分别是:gse11907、gse49454、gse72509、gse17755、gse29536和gse22098。其中gse11907为外周血单核细胞(peripheralbloodmononuclearcell,pbmc)基因表达的数据,其它均为全血基因表达的数据;而gse72509为rnaseq二代测序的数据,其它为芯片数据;(3)单个基因建模在独立数据中验证,此模块共使用4类疾病(烧伤,败血病,创伤,川崎病),8组数据:gse37069和gse19743、gse69528和gse80496、gse36809和gse11375、gse63881和gse68004;(4)单基因标志物在艾滋病毒(humanimmunodeficiencyvirus,hiv)感染数据中的验证;共包含4组数据:gse6740、gse56837、gse71063和gse44228。其中,前两组数据是艾滋病毒在样本中有无进展的数据,后两组数据是对艾滋病病人药物治疗的数据;(5)在肺结核(tuberculosis,tb)中验证基因fcgr1a的标志作用;共收集4组数据:gse37250、gse40553、gse31348和gse56153。其中前两组是活动性肺结核(activetb)和潜伏性肺结核(latenttb)数据,后两组是肺结核病人治疗或治愈的数据;(6)对于系统性幼年特发性关节炎(systemicjuvenileidiopathicarthritis,sjia),本发明收集了两组数据:gse13501和gse80060。前一组用于系统性幼年特发性关节炎和其它疾病的对比,后一组是此类疾病的治疗数据。一些用于其它验证所用到的数据,由于不是本次研究的重点,这里就不一一列举了。上面列举出来的数据有近50组,一些未被列举出来的和一些预处理后被过滤掉数据,本实施例没有一一展示,研究中处理的数据有近百组,可谓是数据量极大,且覆盖全面。针对本表1中所涉及疾病的20个基因和4个在外周血稳定表达的对照基因(actb、b2m、ubc和gusb),本发明设立健康对照组和相关疾病组,确定标本采集和实验所需试剂盒的规模。使用paxgene采血管采集健康对照人群和本专利所涉及疾病患者外周静脉血,并转移至冻存管-80℃冻存。将paxgenebloodrna管4℃下5000rpm离心10min,弃上清后加350μlbufferbr1溶解沉淀,将溶解后的样品转移至1.5mleppendorf管中,再加300μlbufferbr2和40μl蛋白酶k,漩涡震荡混匀5秒,然后在55℃1000rpm摇床中孵育10min。裂解后将液体转移至套有paxgeneshredderspincolumn的2ml离心管中,15000rpm离心3min,小心将上清转移至新的1.5mleppendorf管中。详细步骤参照paxgenebloodrnakit试剂盒说明书。用紫外分光光度计检测提取总rna的260/280比值和rna浓度。提取总rna260/280比值在1.7-2.3之间时可按照ncounterxtcodesetgeneexpressionassays说明书操作要求进行检测。首先在包含reportercodeset的管中加入70μlhybridizationbuffer,翻转混匀而制成初始混合反应液。然后在每个杂交反应管中分别加入8μl初始混合反应液和1.5-5μl提取的样本总rna。再向每个反应管中加入2μl捕获probeset并翻转混匀,制成15μl杂交反应体系,立即放入预热至65℃的热循环加热器中,孵育至少16h。详细步骤参照xtassay说明书。用ncounter分析系统和配套软件nanostring’sfreensolvertm分析软件分析杂交后反应液的探针荧光强度影像,为保证数据的可靠性,将样品浓度稀释一倍进行分析。实施例2数据的处理方法1、本发明中所有的芯片数据处理流程由于数据量非常大,本发明并没有使用原始芯片数据,而是使用各个研究中提供的表达值矩阵数据。这些表达值矩阵都是各个研究组预处理过的,然而,由于芯片平台不同,研究的实验室不同,试验环境不同,以及各个实验室预处理的方式不同,拿到的数据并不能直接使用,而要经过严格的筛选和过滤。对于这些数据的再次预处理及过滤,有几个严格的过滤标准,具体如下:(1)所有表达值需对数(log)处理;(2)每一个探针在所有样本中的不合格值(包括缺失,或不合理)比例不得高于设定的阈值(本研究中使用50%),否则过滤掉此探针;(3)每个样本不合格的探针(包括缺失值,或不合理值)的比例不得高于设定的阈值(50%),否则过滤掉此样本;(4)对所有表达值进行下界截断。通常情况下,一个研究的数据要么是全部表达值均取过对数的,要么是全部表达值均没有取过对数,针对没有取过对数的数据,只需全部对数处理,然后继续后面的过滤。当然,还有一些数据,从形式上看,应该是部分取了对数,部分没有取对数。对于这样的数据,由于对于数据质量有所保留,本发明的做法是舍弃。凡是这样的数据,一律不用。(2)(3)步中的不合理值指,由于芯片数据的采集是通过测量荧光值获取的,而表达值若过小,则已被背景所掩盖,从而测量的表达值将严重失真。因而在处理过程中,表达值较小的称为不合理值,本发明中,选用的标准是【log2(100)】。第(4)步截断指,经过(2)(3)步过滤后,仅仅过滤了探针和样本,对于有些探针,其在全部样本中,不合理值得比例不足50%,因而此探针并未被过滤掉,对于这样的情况,使用上面的基准值log2(100)。为了避免不同实验室测量和处理过程中的不同,本发明坚持绝不混用数据,即使两组数据样本目标一致,均是针对同一种疾病的数据。需要特别说明的是,有一些数据是以0为中心标准化的,这样的数据都是已经对数处理过的,通常也不需要做第(4)步的截断处理。2、差异表达选用r语言中rankprod包中的rp方法对数据进行差异表达分析。rp是一种非参数统计的方法,对于具有重复实验的数据,可以检测出一致失调的变量(基因、探针、代谢分子等),被广泛用于生物组学数据。该方法对于数据有一些假设:(1)在所有测量的特征中,失调的特征只占总数的一小部分;(2)在多次的重复实验中,检测是独立的;(3)所有的变异是独立的;(4)所有检测的检测方差稳定。在以上这些假设的基础上,该方法会计算每一个变量在所用重复实验中变异倍数(foldchange,fc)的排名(rank),对这些排名计算几何平均数,得到rp值,rp值越小越有可能是失调变量。为了最大可能的降低数据噪声,对于rp计算出的差异表达基因做了进一步的筛选,主要有两个指标:p值:所有差异表达基因的p值必须小于0.05;变异倍数:变异倍数的选取有两个阶段,对于差异表达基因的初步过滤时,选用阈值为1.5或0.7;在进一步候选基因的选取时,为了限制基因个数,降低噪声,改用阈值2或者0.5。3、使用到的机器学习模型本发明共使用到两个基本的机器学习模型:逻辑回归(logisticregression)模型和k均值(k-means)聚类模型。逻辑回归模型是一种广义线性回归模型(generalizedlinearmodel),但不同于一般的回归模型,逻辑回归模型主要用于数据分类问题,经典的逻辑回归模型用于二分类问题。对数几率函数是一种sigmoid函数,它将公式中的z的值转化为一个接近0或1的y值,并且其输出的值在z=0附近变化很陡峭。逻辑回归模型有许多优点:模型直接对分类可能性进行建模,不需要对数据分布有事先的假设;模型不仅可以预测出数据的类别,而且可以得到对应类别的预测概率,对于需要利用概率辅助决策的任务,这个信息尤为重要;此外,该模型可任意阶可导,其决定了其有非常优秀的数学性质,可以方便的求取最优解。逻辑回归是一种监督学习的方法。对于表3中几种具有独立数据集验证的疾病类型,采用该模型对相应的数据建模验证,收到了良好的效果。从字面上也可以看出,k均值聚类是一种聚类模型。聚类是一种无监督的学习,上述的逻辑回归分类是一种监督学习的模型。聚类和分类最大的不同在于,分类的目标事先已知,而聚类则不一样。聚类模型几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。之所以称为k均值聚类是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含的值得均值计算而来。具体工作流程如下:首先,随机确定k个初始点为质心;然后,对没个点对k个质心计算距离,其中离那个质心的距离最小,该点就分配到该质心所在的类;接着,等所有点分配完,对每一簇计算均值,从新指定为该簇的质心;重复上面的步骤,直到每簇包含的数据稳定。本发明中所用到的是二分的k均值算法,采用发明人找到的一些候选因子做向量,运用k均值算法,观测是否病毒感染类疾病的样本和细菌感染类疾病的样本确有不同,能够聚集在不同的类别中。实施例3候选基因的选择对于基于实施例1中表1披露的20组数据初步得到的差异表达基因,需要进一步的筛选,获取研究的候选基因。首先,对每一组的差异表达基因进行fc的过滤,选出fc>2或者fc<0.5的失调基因。可以看出使用的阈值近乎苛刻的,这是因为希望找到的候选基因有很强的抗干扰性。然后,将20组数据的差异表达基因计数合并,并按计数大小倒序排名。最后,基于以上的排名,结合对两类数据集(细菌相关疾病数据和病毒相关疾病数据)中基因表达的一致性的观察,最终选出10个brgs的基因和10个vrgs的基因。如表2。表2使用brgs和vrgs区分细菌感染和病毒感染.数据集因子tpfnfptnf1gse72829ng_v;ng_b2715180.90gse60244ng_v;ng_b55116210.87gse6269ng_v;ng_b61312150.89gse42026ng_v;ng_b3378110.81注:使用k-means聚类;tp:真阳性;fn:假阴性;fp:假阳性;tn:真阴性;f1:f1标准;ng_v:vrgs中变化倍数大于2的个数;ng_b:brgs中变化倍数大于2的个数。收集关于感染和自身免疫类的血液转录组的公共数据。依据数据质量,每一种疾病选出一组代表性的数据(必须是全血的数据,见表1)。首先对此20组数据进行差异表达分析(病人对健康人)。为了减少显著差异基因的数目,选用的非常严格的筛选条件——倍数变化(foldchange,fc)必须大于2(上调基因),或者小于0.5(下调基因)。而后,将这些显著的基因在上面的20组数据中出现的频率排序。观察到在这些疾病类中表现出显著的功能失调的,且出现频率高的这些基因,基本上都是上调的基因。在进一步的基因筛选中,本发明的目标是将基因数目缩减至20个,从而可以得到方便实惠的检测。由于在细菌感染疾病类和病毒感染疾病类中,基因的失调表现出很强的一致性,所以本发明选取了病毒感染类疾病相关的10个上调基因和细菌感染类疾病相关的10个上调基因。这些和病毒感染类疾病相关的上调基因多和干扰素信号有关,这其中包括了ifi27、ifi44l、rsad2、herc5、ifitm3、ifi44、ifit3、epsti1、ifit1和isg15。而和细菌感染类疾病相关的上调基因多和各种通路相关,这其中包括hp、anxa3、fcgr1b、s100a12、mmp9、il18r1、tlr5、gyg1、fcgr1a和arg1。此10个“病毒类基因(virus-responsegenes,vrgs)”在病毒感染类疾病中的平均倍数变化可到达4.61到29.13。对于10个“细菌类基因(bacteria-responsegenes,brgs)”在细菌感染类疾病中的倍数变化也可到达4.44到14.28。本发明还观察到,无论是“病毒类基因”还是“细菌类基因”都只在自身所对应的疾病类中有更高的表达,而在对方的疾病类中变化倍数均小于2。本发明收集了四种同时包含病毒感染和细菌感染的数据集,从表2可以看出,使用这些基因,对两类疾病分类非常的精确,f1值可以达到0.81到0.91。对除了病毒感染或者细菌感染的10组数据外的10组数据对应的疾病的验证中,本发明发现无论是“病毒类基因”或是“细菌类基因”在这些疾病类中,多是上调基因,如表3。在烧伤和一般性创伤(injury)的样本中,和其他疾病类不同,本发明发现“细菌类基因”表现出明显的上调,而“病毒类基因”却有几个表现出了下调。在硬皮病(scleroderma)和原发性干燥综合症(primarysyndrome)样本中,“病毒类基因”表现出明显上调;在肉状瘤病和常见变异免疫缺陷疾病样本中,“病毒类基因”表现出适度的上调,同时伴随着“细菌类基因”中fcgr1a和fcgr1b的上调;在川崎病和系统性少年特发性关节炎的样本中,除了fcgr1a和fcgr1b,其它的“细菌类基因”均表现出显著的上调;另外,在风湿性关节炎样本中,“细菌类基因”也被观测到适度的上调;肺结核是唯一一个“病毒类基因”和“细菌类基因”均表现为上调的一种疾病,然而,“细菌类基因”中的fcgr1a和fcgr1b却表现出了异常突出的上调。总体上,20个包括“病毒类基因”和“细菌类基因”在感染和自身免疫疾病中表现出频繁的失调,而这些观察到的不同模式值得增加额外的研究对其深入理解。在尿毒症(uremia),牛皮癣(psoriasis),强直性脊柱炎(ankylosingspondylitis)以及慢性阻塞性肺病(chronicobstructivepulmonarydisease,copd)的数据集中,并没有观测到这些基因的失调。sle疾病中的基因失调系统性红斑狼疮是极少数具有高质量数据的一个疾病,因此,这个疾病成为一个比较好的可以用于测试的候选疾病。在系统性红斑狼疮全血的数据中,本发明观察到前述“病毒类基因”vrg有非常显著的上调,一些基因的变异倍数可达10倍之多,如图1。在外周血单细胞数据中同样出现了这样的极具夸张的上调图1,并且,在rna-seq的微芯片数据中,这样的上调模式依然存在。由于“病毒类基因”在系统性红斑狼疮疾病中表达上调多层次的高度一致性,很容易的使用“病毒类基因”将具有此种疾病的样本从包含有细菌感染和自身免疫的疾病中区分出来,如图1。可以观察到,超过90%的病人样本中,变异系数达2倍以上的“病毒类基因”个数至少在5个以上,而在其它类疾病中并没有这样的现象。单基因作为疾病下条件下的生物标志物从系统性红斑狼疮的案例中,观察到了“病毒类基因”和“细菌类基因”失调的共调节模式,经过多次的尝试,本发明找到4种同时具有训练集和测试集的数据,仅由1个基因的变异倍数便可以达到非常优秀的分型效果。其中,败血病、烧伤和一般性受伤仅由基因hp在区分病人和健康人样本在测试集中f1可达0.99-1。对于川崎病,仅由基因anxa3的表达变异就可以使病人和健康人的区分的f1达到0.97。如表3。表3在几类感染和自身免疫类疾病中的单基因生物标志物疾病训练集测试集基因tpfnfptnf1烧伤gse37069gse19743hp11221620.99败血病gse69528gse80496hp2400211.00创伤gse36809gse11375hp15530260.99川崎病gse63881gse68004anxa37514330.97注:使用了逻辑回归模型用单基因做生物标志物并不限于感染和自身免疫的疾病。本发明发现在脑血管类的一些疾病中,包括中风、颅内破裂动脉瘤等,前述的“细菌类基因brg”有一致的失调。在这些“细菌类基因”中,arg1的表达对患者和健康人有一个可靠的区分。如图2。在这几组数据中,有72-74%的患者的arg1的表达变异倍数超过的2。而有87-100%健康人的arg1的表达变异倍数却小于2。因而,arg1也许可以对脑血管疾病的恢复起到指示作用。hiv疾病的单基因生物标志物hiv感染会导致“病毒类基因”的明显上调(如图3)。由于ifi27在许多疾病,尤其是病毒感染相关的疾病中,有很显著的表达上调,因而,在数据中混杂的疾病较多时,ifi27就不适合作为生物标志物了。本发明发现isg15可以是一个可靠的标志物。使用isg15的表达,对进展型和无进展型的hiv感染患者有非常好的区分。在gse6740和gse56837两组验证数据中,91-95%的进展型hiv患者的isg15表达变异倍数超过2,而无进展型hiv感染样本中有87-100%的患者isg15的变异倍数小于2。另外,在给药治疗的数据中,isg15的表达也有明显的指示作用。从gse71063和gse44228两组数据中,可以看出,有50-67%的病人给药后,isg15的表达下调达2倍之多,而仅服用placebo的样本中,没有任何样本的isg15表达下调达到2。肺结核疾病的单基因生物标志物肺结核是一种非常特异的疾病,“病毒类”和“细菌类”两类基因均表现出了失调现象。然而,所有的“病毒类基因”vrg在病人样本中上调表达没有一致性,从而找到合适的单基因生物标志物。而在“细菌类基因”brg中,本发明发现fcgr1a可以作为一个可靠的生物标志物(图4)。使用fcgr1a的表达,可以准确的区分开活动性肺结核和潜伏性肺结核。在gse37250数据中,87%的活动性肺结核病人的fcgr1a的表达变异倍数高于5,而在gse40553数据中,所有的活动性肺结核病人的fcgr1a的表达高于4,而两组数据中,潜伏性肺结核病人的fcgr1a的表达在对应的阈值下,只有2-3%。在给药治疗的数据中,fcgr1a的表达依然有标志性作用。从gse31348和gse56153两组数据中可以看到,经过一段时间的治疗后,有85-96%的病人的fcgr1a表达有显著下调。系统性幼年特发性关节炎疾病的单基因生物标志物系统性幼年特发性关节炎病人往往伴随着“细菌类基因”的上调。本发明在所收集到的几组数据中发现anxa3可以作为此类疾病的生物标志物。如图5。在系统性和非系统性的幼年特发性关节炎的样本中,仅用anxa3的表达不同作为区分,就能得到很高的准确率。在gse13501这组数据中,81%的系统性幼年特发性关节炎病人的anxa3的表达变异倍数大于3,而非系统幼年特发性关节炎患者却有高于91%的样本中,anxa3的表达变异倍数小于3。anxa3的表达也可以用于检测此类病人给药治疗的情况。gse80060是一组系统性幼年特发性关节炎病人给药处理的数据,通过观察基因anxa3的表达,有42%的病人在给药后anxa3的表达下调超过2.5倍,而服用placebo的病人也没有发现anxa3的表达下调。癌症的单基因生物标志物癌症病人的外周血中免疫应答系统相关基因一样表现为上调。在本发明收集到的癌症相关的数据中,基因hp表现出了很好的生物标记物的性质。如图6。在这组结直肠癌的数据中,从图中可以看到,处于cd阶段的病人中,50%的病人hp基因的变异倍数大于5,而ab阶段的病人却没有变异倍数大于5的。在另一组原发性肿瘤数据中,只有双原发性肿瘤的样本中约有30%的样本的hp基因变异倍数大于2。基因hp的表达也可以用于临床诊断。在两组前列腺癌的数据中,hp的越高表达对应了越差的诊断。从图中的存活曲线中,清楚的看到一个现象:hp的越高表达,其样本最终的存活的时间反而越短。综上几个数据集中基因hp的表现,基因hp在这几类癌症中是可以做生物的标志物。多细胞类型组织的研究中,当细胞组分发生变化时,研究的复杂度和难度也大大的增加。因此,上述所描述的失调现象若有细胞组分发生变化,有可能会导致所找出的差异表达基因有偏差。然而,本发明在几组包含不同细胞组分的数据中,发现了相同的失调模式。例如,gse11907是一组系统性红斑狼疮疾病的pbmc数据,在这组数据的分析中,同样发现了“病毒类基因”的失调现象,见图1。在hiv感染数据的分析中,无论是全血的数据,又或是cd4+和cd8+的数据,均可以发现在进展型hiv样本和无进展型hiv样本在“病毒类基因”中的差异。尽管区分细胞组分的研究可以获得更多的细节信息,然而,从上述分析中,可以看到,对于许多疾病,仅仅使用全血的数据的分析可能已经足够。血液中的管家基因管家基因通常会作为实验的一种自检验标准,比如rt-pcr。本发明发现有一些基因在这些疾病的数据中都有非常稳定的表达,包括一些大家都比较熟悉的基因:actb、b2m、ubc和gusb。因此,发明人猜想是否可以使用20个基因和管家基因的表达比,替换上述工作中的变异倍数用于分类、诊断和治疗评估。作为一种验证,发明人使用b2m作为对照,在肺结核和癌症中做了一些验证。最后分析的结果和上述用健康人作对照的分析结果是非常一致的。这个结果非常的有意义,因为作为对照组的选用是比较复杂,或者选取的可能不合适,这些都会对后续的分析结果都是有影响的,而选用管家基因作为对照会使分析结果更加的稳定。虽然,上文中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1