一种筛选抗体的非人模式动物的构建方法及其应用与流程
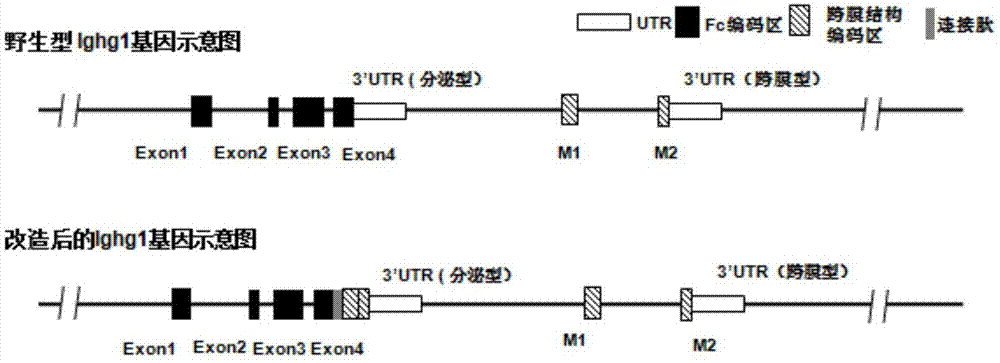
本申请涉及基因改造动物模型的建立方法及应用,具体而言,涉及基于一种基因改造动物模型的构建方法及其在生物医药领域的应用。
背景技术:
:抗体(antibody)指机体的免疫系统在抗原刺激下,由b淋巴细胞分化成的浆细胞所产生的、可与相应抗原发生特异性结合反应的免疫球蛋白。全世界范围内不断有抗体药物进入临床研究并且上市销售,已成为生物技术类药物中最重要的一大类产品。抗体药物也以其独特的优势,逐步超越化学药,成为制药行业中发展最快的领域之一,从1992年首个抗体药物orthoclone上市以来,截至2016年12月,欧美日等主要市场共上市了超过63个抗体药物,平均每年上市2.6个抗体药物;1999年,全球抗体药物的市场销售额仅有12亿美元,而根据汤森路透数据,2016年全球抗体类药物的市场已超过1000亿美元,预计到2020年,仅top5销售的抗体药物销售额将达到419亿美元。抗体药物的快速增长促成了一大批生物技术公司和机构参与抗体药物研发,2016年初cfda的统计数据表明,仅我国就有超过600家企业在抗体药物领域布局。越来越多的公司和研究机构参与了抗体药物研发,研发竞争呈现白热化状态,而由于抗体(生物类似物)本身特殊性,能否快速从众多抗体中的筛选出可以作为新药的抗体是研发的关键(倪健,《中国医药技术经济与管理》,2012年,第(4)卷,第41-45页。在抗体的研发过程中,目前主要的抗体筛选技术分为两类:(1)体外组装抗体库技术:该技术是从b淋巴细胞中扩增全套抗体的轻链和重链基因,利用丝状噬菌体表面展示技术将抗体外扩的基因片段展示于噬菌体表面构成抗体库,通过数个“吸附-洗脱-扩增”循环筛选出抗体基因。除展示在噬菌体表面外,还可以展示在酵母、细菌表面和核糖体上;(2)以杂交瘤技术为基础,通过免疫小鼠产生抗体:一般是使用人抗原免疫小鼠,然后取小鼠的脾脏细胞与永生化骨髓瘤细胞融合,得到杂交瘤细胞,利用选择性培养基挑选杂交瘤细胞,然后再次筛选找到分泌抗体的阳性杂交瘤细胞。无论使用哪种技术,上述筛选的最终目的都是得到抗体序列,再进行后续的优化、测试和工业化生产。而这两种筛选方法各有优劣:抗体库技术首先需要建立筛选平台,有一定的技术要求,其次,库容量相对较小,而体外筛选过程没有经过体细胞高突变过程,还需要进行亲和力优化,总体来说筛选效率低。以杂交瘤技术为基础的第二种技术在筛选上具有先天优势(在动物体内完成vdj重排,并经历体细胞突变过程,筛选的效率和亲和性上都具有优势),所获得的抗体类型更丰富,但需要的人工操作和重复步骤太多,尤其是阳性杂交瘤的筛选过程通常采用有限稀释法,一般需要重复3-4次才能确定培养板孔中增殖的细胞为单克隆细胞,速度慢、效率低、人工和耗时都较多。综上所述,本领域急需一种更为简便的抗体筛选方法。本发明旨在克服现有不足,提供一种快速获得表达抗体细胞的基因工程小鼠,对该小鼠进行抗原免疫后可直接检测、鉴定和分离得到表达抗体的浆细胞,对获得的细胞进行序列分析,可直接获得抗体序列信息,避免上述繁琐的制备抗体库和筛选杂交瘤的过程,进而大大提高抗体研发速度和准确率。技术实现要素:本发明的第一方面,涉及一种基因改造的非人模式动物的构建方法,所述模式动物基因组中编码抗体重链序列区域敲进可编码跨膜区多肽的序列;使得模式动物接受抗原免疫后,体内产生的具有正常活性的抗体“挂”(保留)在模式动物浆细胞表面。优选的,可编码跨膜区多肽的序列为内源性序列。优选的,所述抗体为igm、igd、igg、iga或者ige;更优选的,所述抗体为igg抗体;更为优选的,所述抗体为igg1抗体。优选的,所述编码抗体重链序列区域敲进的序列还包含编码连接肽的序列;进一步优选的,所述编码连接肽的序列选自f2a、p2a或ires。在本发明的一个具体实施例中,所述编码连接肽的序列为f2a。在本发明的一个具体实施方式中,所述的基因为ighg1基因;更优选的,所述模式动物ighg1基因的第4外显子后3’utr的终止密码子前敲进可编码跨膜区多肽的序列,其中,所述的可编码跨膜区多肽的序列通过连接肽序列与第4外显子连接。本发明所述的构建方法,使用基因编辑技术进行ighg1基因非人模式动物的构建,所述基因编辑技术包括基于胚胎干细胞的dna同源重组技术、crispr/cas9技术、锌指核酸酶技术、转录激活子样效应因子核酸酶技术、归巢核酸内切酶或其他分子生物学技术。优选的,使用基于crispr/cas9的基因编辑技术进行ighg1基因非人模式动物的构建。再优选的,所述非人模式动物为非人类哺乳动物;优选的,所述非人类哺乳动物为啮齿类动物;再优选的,所述啮齿类动物为小鼠;最优选的,所述小鼠为c57bl/6或balb/c。优选的,所述编码跨膜区多肽的dna序列的全部或部分片段如seqidno:3和/或seqidno:45中的全部或部分片段所示,所述编码跨膜区多肽的蛋白序列的全部或部分片段如seqidno:4中的全部或部分片段所示。优选的,所述编码连接肽的dna序列的全部或部分片段如seqidno:1中的全部或部分片段所示,所述编码连接肽的蛋白序列的全部或部分片段如seqidno:2中的全部或部分片段所示。优选的,所述模式动物基因组中包括嵌合ighg1基因,所述的嵌合ighg1基因选自下列组中的一种:a)表达跨膜区多肽和连接肽序列的dna序列如seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列的部分或全部所示;b)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列同一性程度为至少大约为80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或至少99.9%;c)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的核苷酸序列杂交;d)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列差异不超过10、9、8、7、6、5、4、3、2或不超过1个核苷酸;e)表达跨膜区多肽和连接肽序列的dna序列具有seqidno:7、seqidno:8、seqidno:20或seqidno:21所示包括取代、缺失和/或插入一个或多个核苷酸的核苷酸序列。在本发明的一个具体实施方式中,所述模式动物基因组中包括嵌合ighg1基因,所述嵌合ighg1基因包括编码跨膜区多肽的基因部分和编码连接肽的基因部分,所述嵌合ighg1基因的嵌合dna序列如seqidno:7、seqidno:8、seqidno:20或seqidno:21的全部或部分所示。进一步优选的,所述模式动物基因组中包括嵌合ighg1基因,所述嵌合ighg1基因包括编码跨膜区多肽的基因部分和编码连接肽的基因部分,所述嵌合ighg1基因编码的蛋白序列选自下列组中的一种:a)所述蛋白序列为seqidno:9或seqidno:22所述氨基酸序列的部分或全部;b)所述蛋白序列与seqidno:9或seqidno:22所示氨基酸的序列同一性程度为至少大约为80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或至少99.9%;c)所述蛋白的核酸序列在严格条件下,与编码seqidno:9或seqidno:22所示蛋白的核苷酸序列杂交;d)所述蛋白序列与seqidno:9或seqidno:22所示的氨基酸的序列差异不超过10、9、8、7、6、5、4、3、2或不超过1个氨基酸;e)所述蛋白序列具有seqidno:9或seqidno:22所示的,包括取代、缺失和/或插入一个或多个氨基酸残基的氨基酸序列。在本发明的一个具体实施方式中,所述模式动物基因组中包括嵌合ighg1基因,所述嵌合ighg1基因包括编码跨膜区多肽的基因部分和编码连接肽的基因部分,所述嵌合ighg1基因的蛋白序列如seqidno:9或seqidno:22的全部或部分所示。优选的,所述的的构建方法,在动物的编码抗体重链序列区域敲进可编码跨膜区多肽序列和连接肽序列,其中,使用sgrna靶位点序列如seqidno:29-37任一项所示;进一步优选的,使用的sgrna靶位点序列为seqidno:32。本发明的第二方面,涉及一种上述的构建方法制备的非人模式动物或其后代。本发明的第三方面,涉及一种制备sgrna载体的方法,包括如下步骤:(1)将序列如seqidno:29-37所示的任一项sgrna靶序列,设计sgrna的上、下游序列,制备获得正向寡核苷酸序列和反向寡核苷酸序列;优选的,所述sgrna靶序列为seqidno:32,设计靶序列的上游序列如seqidno:46所示、下游序列如seqidno:47所示,在上游序列5’端加上tagg得到正向寡核苷酸,在下游序列5’端加上aaac得到反向寡核苷酸,获得的正向寡核苷酸序列如seqidno:38所示;反向寡核苷酸序列如seqidno:39所示;(2)合成含有t7启动子及sgrnascaffold的片段dna,其中含有t7启动子及sgrnascaffold的片段dna如seqidno:40所示,将上述片段依次通过ecori和bamhi酶切连接至骨架载体phsg299上,经测序验证,获得pt7-sgrnag2载体;(3)分别合成步骤(1)中所述的正向寡核苷酸和反向寡核苷酸,优选为seqidno:38和seqidno:39,将合成的sgrna寡聚核苷酸变性、退火,形成可以连入步骤(2)所述的pt7-sgrnag2载体的双链;(4)将步骤(3)中退火的双链sgrna寡聚核苷酸分别与pt7-sgrnag2载体进行连接,筛选获得sgrna载体。本发明的第四方面,涉及一种靶向载体,其包含:a)与待改变的转换区5’端同源的dna片段,即5’臂;b)插入的供体dna序列,其编码供体转换区;和c)与待改变的转换区3’端同源的第二个dna片段,即3’臂。优选的,所述的待改变的转换区位于ighg1基因组中编码抗体重链序列区域。优选的,所述的5’臂序列如seqidno:5或seqidno:18所示。优选的,所述的3’臂序列如seqidno:6或seqidno:19所示。优选的,所述插入的dna序列如seqidno:7或seqidno:20所示。本发明的第五方面,涉及一种基因改造的非人模式动物的制备方法,包括以下步骤:第一步:按照所述的制备sgrna载体的方法步骤1-4,获得sgrna载体;第二步:将sgrna载体的体外转录产物、所述的靶向载体和cas9mrna进行混合,将混合液注射至动物受精卵细胞质或细胞核中,将注射后的受精卵转移至培养液中进行培养,然后移植至受体动物的输卵管中发育,得到f0代动物;第三步:将f0代动物利用pcr技术进行检验,验证细胞中的ighg1基因改造嵌合动物;优选的,所述第三步中使用的pcr检测的5'端引物对如seqidno:41和seqidno:42所示;3'端引物对如seqidno:43和seqidno:44所示。优选的,所述的非人模式动物为非人类哺乳动物;再优选的,所述的非人类哺乳动物为啮齿类动物;进一步优选的,所述的啮齿类动物为小鼠;最优选的,所述小鼠为c57bl/6或balb/c。本发明的第六方面,涉及一种可稳定传代的基因改造非人模式动物,所述非人模式动物体内表达跨膜区多肽和连接肽,其中所述非人模式动物由上述任一项所述的方法制备获得。所述的一种可稳定传代的基因改造非人模式动物,选自下列组中的一种:a)表达跨膜区多肽和连接肽序列的dna序列如seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列的部分或全部所示;b)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列同一性程度为至少大约为80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或至少99.9%;c)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的核苷酸序列杂交;d)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列差异不超过10、9、8、7、6、5、4、3、2或不超过1个核苷酸;e)表达跨膜区多肽和连接肽序列的dna序列具有seqidno:7、seqidno:8、seqidno:20或seqidno:21所示包括取代、缺失和/或插入一个或多个核苷酸的核苷酸序列。优选的,所述非人模式动物为非人类哺乳动物;进一步优选的,所述的非人类哺乳动物为啮齿类动物;最优选的,所述的啮齿类动物为小鼠;优选的,所述小鼠为c57bl/6或balb/c。本发明的第七方面,涉及一种能够特异的靶向ighg1基因的sgrna序列,所述sgrna序列在动物的编码抗体重链序列区域敲进可编码跨膜区多肽序列和连接肽序列,所述靶向的靶位点序列如seqidno:29-37任一项所示;优选的,sgrna靶向的靶位点的序列如seqidno:32所示。优选的,编码所述sgrna的dna分子,所述dna双链分别如seqidno:46和seqidno:47所示。本发明的第八方面,涉及一种构建模式动物的载体,所述载体能够产生所述的sgrna序列,用于在编码抗体重链序列区域敲进可编码跨膜区多肽和连接肽的序列;优选的,使用所述制备sgrna的方法获得。本发明的第九方面,涉及一种上述的靶向载体、上述的sgrna序列或上述的载体用于在编码抗体重链序列区域敲进可编码跨膜区多肽和连接肽的序列。本发明的第十方面,涉及一种基因改造细胞株,所述细胞株中编码抗体重链序列区域敲进可编码跨膜区多肽的序列;优选的,可编码跨膜区多肽的序列为内源性序列。优选的,所述编码抗体重链序列区域敲进的序列还包含编码连接肽的序列;所述编码连接肽的序列选自f2a、p2a或ires。优选的,所述抗体为igm、igd、igg、iga或者ige;更优选的,所述抗体为igg抗体;进一步优选的,所述抗体的基因为ighg1基因,更进一步优选的,所述细胞株中ighg1基因的第4外显子后3’utr的终止密码子前敲进可编码跨膜区多肽的序列,其中,所述的可编码跨膜区多肽的序列通过连接肽序列与第4外显子连接。优选的,在细胞株的编码抗体重链序列区域敲进可编码跨膜区多肽序列和连接肽序列,其中,使用sgrna靶位点序列如seqidno:29-37任一项所示;优选的,使用sgrna靶位点序列为seqidno:32。本发明的第十一方面,涉及一种细胞或细胞系或原代细胞培养物,所述细胞或细胞系或原代细胞培养物来源于上述的非人模式动物或其后代。本发明的第十二方面,涉及一种组织或器官或其培养物,所述组织或器官或其培养物来源于上述的非人模式动物或其后代。本发明的第十三方面,涉及一种嵌合ighg1基因,所述的嵌合ighg1基因选自下列组中的一种:a)表达跨膜区多肽和连接肽序列的dna序列如seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列的部分或全部所示;b)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列同一性程度为至少大约为80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或至少99.9%;c)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的核苷酸序列杂交;d)表达跨膜区多肽和连接肽序列的dna序列与seqidno:7、seqidno:8、seqidno:20或seqidno:21所示的序列差异不超过10、9、8、7、6、5、4、3、2或不超过1个核苷酸;e)表达跨膜区多肽和连接肽序列的dna序列具有seqidno:7、seqidno:8、seqidno:20或seqidno:21所示包括取代、缺失和/或插入一个或多个核苷酸的核苷酸序列。优选的,所述的嵌合ighg1基因编码的蛋白序列选自下列组中的一种:a)所述蛋白序列为seqidno:9或seqidno:22所述氨基酸序列的部分或全部;b)所述蛋白序列与seqidno:9或seqidno:22所示氨基酸的序列同一性程度为至少大约为80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或至少99.9%;c)所述蛋白的核酸序列在严格条件下,与编码seqidno:9或seqidno:22所示蛋白的核苷酸序列杂交;d)所述蛋白序列与seqidno:9或seqidno:22所示的氨基酸的序列差异不超过10、9、8、7、6、5、4、3、2或不超过1个氨基酸;e)所述蛋白序列具有seqidno:9或seqidno:22所示的,包括取代、缺失和/或插入一个或多个氨基酸残基的氨基酸序列。本发明的第十四方面,涉及一种表达上述的嵌合ighg1基因或所述嵌合ighg1基因编码的蛋白的构建体。本发明的第十五方面,涉及一种包含上述构建体的细胞。本发明的第十六方面,涉及一种包含上述细胞的组织。本发明的第十七方面,涉及来源于所述的非人模式动物或其后代、所述的可稳定传代的基因改造非人模式动物在抗体筛选方面的应用。本发明的第十八方面,涉及一种快速筛选抗体的方法,包括以下步骤:(1)免疫上述任一所述的非人模式动物;(2)对步骤(1)中免疫后的基因改造动物进行脾细胞分离;(3)对步骤(2)中分离的脾细胞进行筛选,获得表达抗体的脾细胞。所述步骤(1)中所述免疫使用hcd27蛋白胞外区经皮下注射,在2-5个月每隔2-4周加强免疫。所述步骤(2)中所述脾细胞分离包括如下步骤:a)取出所述免疫后的基因改造动物脾脏;b)对所述动物脾脏进行研磨,过筛,得到过滤好的细胞悬液;c)将过滤好的细胞悬液离心去上清,加入红细胞裂解液,置于冰上;d)将步骤c)中获得的溶液进行清洗,离心去上清;e)重悬细胞,获得脾细胞。优选的,所述步骤b)中过筛的筛网孔径为70μm;优选的,所述步骤c)中置于冰上3-5min;优选的,所述步骤d)中清洗溶液选择pbs溶液;优选的,所述步骤e)中重悬细胞为加入anti-mousecd16/32,随后冰上放置10-20min,进一步优选为10min。所述步骤(3)中所述筛选步骤如下:a)加入相关抗体,混匀细胞后冰上孵育;b)将步骤a)中孵育后的溶液进行清洗,离心去上清,获得初筛物;c)对步骤b)获得的初筛物进行标记,随后清洗、重悬并检测。优选的,所述步骤a)中相关抗体为biotinylatedhumancd27fctag和/或humancd27fctag,所述冰上孵育时间为10-20min,进一步优选为15min;优选的,所述步骤b)中清洗使用pbs溶液,多次重复清洗,离心去上清;优选的,所述步骤c)中所述标记的标记物为pestreptavidin/fitcanti-mousecd19antibody或peanti-humaniggfc/fitcanti-mousecd19antibody,所述标记的步骤为加入标记物后,冰上孵育10-20min,进一步优选为15min,所述清洗为加入pbs溶液后离心去上清,所述重悬为加入pbs溶液进行重悬细胞。本发明的第十九方面,涉及所述的非人模式动物在涉及细胞的免疫过程的产品开发,制造抗体,或者作为药理学、免疫学、微生物学和医学研究的模型系统中的应用。优选的,所述细胞为哺乳动物细胞,进一步优选的所述细胞为人类细胞。优选的,所述抗体为哺乳动物抗体,进一步优选的所述抗体为人类抗体。本发明的第二十方面,涉及所述非人模式动物在生产和利用动物实验疾病模型,用于病原学研究和/或用于开发新的诊断策略和/或治疗策略中的应用。本发明的第二十一方面,涉及所述非人模式动物在筛选、验证、评价、评估或研究抗体药物和药效,免疫相关疾病药物以及抗肿瘤药物方面的用途。本发明所述的非人动物的构建方法制备的非人模式动物可以稳定性遗传,解决了传统转基因方法制备的动物经一定次数的拷贝后出现稀释后遗传不稳定的缺陷。同时本发明所述的非人模式动物基因组敲进可编码跨膜区多肽的序列和连接肽序列,可以实现体内的亲和力优化,并可以直接检测、鉴定和分离得到表达抗体的浆细胞,因而具有速度快、效率高、准确率高、操作简便的优势,适合大规模推广。本发明所述“治疗(treating)”(或“治疗(treat)”或“治疗(treatment)”)表示减缓、中断、阻止、控制、停止、减轻、或逆转一种体征、症状、失调、病症、或疾病的进展或严重性,但不一定涉及所有疾病相关体征、症状、病症、或失调的完全消除。术语“治疗(treating)”等是指在疾病已开始发展后改善疾病或病理状态的体征、症状等等的治疗干预。本发明所述“同源性”,是指在使用蛋白序列或核苷酸序列的方面,本领域技术人员可以根据实际工作需要对序列进行调整,使使用序列与现有技术获得的序列相比,具有(包括但不限于)1%,2%,3%,4%,5%,6%,7%,8%,9%,10%,11%,12%,13%,14%,15%,16%,17%,18%,19%,20%,21%,22%,23%,24%,25%,26%,27%,28%,29%,30%,31%,32%,33%,34%,35%,36%,37%,38%,39%,40%,41%,42%,43%,44%,45%,46%,47%,48%,49%,50%,51%,52%,53%,54%,55%,56%,57%,58%,59%,60%,70%,80%,81%,82%,83%,84%,85%,86%,87%,88%,89%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,99.1%,99.2%,99.3%,99.4%,99.5%,99.6%,99.7%,99.8%,99.9%的同源性。本领域的技术人员能够确定并比较序列元件或同一性程度,以区分另外的小鼠和人序列。在一个方面,所述非人动物是哺乳动物。在一个方面,所述非人动物是小型哺乳动物,例如跳鼠科或鼠总科超家族。在一个实施方式中,所述基因修饰的动物是啮齿动物。在一个实施方式中,所述啮齿动物选自小鼠、大鼠和仓鼠。在一个实施方式中,所述啮齿动物选自鼠家族。在一个实施方式中,所述基因修饰的动物来自选自丽仓鼠科(例如小鼠样仓鼠)、仓鼠科(例如仓鼠、新世界大鼠和小鼠、田鼠)、鼠总科(真小鼠和大鼠、沙鼠、刺毛鼠、冠毛大鼠)、马岛鼠科(登山小鼠、岩小鼠、有尾大鼠、马达加斯加大鼠和小鼠)、刺睡鼠科(例如多刺睡鼠)和鼹形鼠科(例如摩尔大鼠、竹大鼠和鼢鼠)家族。在一个特定实施方式中,所述基因修饰的啮齿动物选自真小鼠或大鼠(鼠总科)、沙鼠、刺毛鼠和冠毛大鼠。在一个实施方式中,所述基因修饰的小鼠来自鼠科家族成员。在一个实施方式中,所述动物是啮齿动物。在一个特定实施方式中,所述啮齿动物选自小鼠和大鼠。在一个实施方式中,所述非人动物是小鼠。在一个特定实施方式中,所述非人动物是啮齿动物,其为选自balb/c、c57bl/a、c57bl/an、c57bl/grfa、c57bl/kalwn、c57bl/6、c57bl/6j、c57bl/6byj、c57bl/6nj、c57bl/10、c57bl/10scsn、c57bl/10cr和c57bl/ola的c57bl品系的小鼠。除非特别说明,本发明的实践将采取细胞生物学、细胞培养、分子生物学、转基因生物学、微生物学、重组dna和免疫学的传统技术。这些技术在以下文献中进行了详细的解释。例如:molecularcloning:alaboratorymanual,2nded.,ed;bysambrook,fritschandmaniatis(coldspringharborlaboratorypress:1989);dnacloning,volumesiandii(d.n.glovered.,1985);oligonucleotidesynthesis(m.j.gaited.,1984);mullisetal.u.s.pat.no.4,683,195;nucleicacidhybridization(b.d.hames&s.j.higginseds.1984);transcriptionandtranslation(b.d.hames&s.j.higginseds.1984);cultureofanimalcells(r.i.freshney,alanr.liss,inc.,1987);immobilizedcellsandenzymes(irlpress,1986);b.perbal,apracticalguidetomolecularcloning(1984);theseries,methodsinenzymology(j.abelsonandm.simon,eds.-in-chief,academicpress,inc.,newyork),sspecifically,vols.154and155(wuetal.eds.)andvol.185,″geneexpressiontechnology″(d.goeddel,ed.);genetransfervectorsformammaliancells(j.h.millerandm.p.caloseds.,1987,coldspringharborlaboratory);immunochemicalmethodsincellandmolecularbiology(mayerandwalker,eds.,academicpress,london,1987);handbookofexperimentalimmunology,volumesv(d.m.weirandc.c.blackwell,eds.,1986);andmanipulatingthemouseembryo,(coldspringharborlaboratorypress,coldspringharbor,n.y.,1986)。以上只是概括了本发明的一些方面,不是也不应该认为是在任何方面限制本发明。本说明书提到的所有专利和出版物都是通过参考文献作为整体而引入本发明的。本领域的技术人员应认识到,对本发明可作某些改变并不偏离本发明的构思或范围。下面的实施例进一步详细说明本发明,不能认为是限制本发明或本发明所说明的具体方法的范围。附图说明以下,结合附图来详细说明本发明的实施例,其中:图1:鼠野生型ighg1基因示意图和改造后的ighg1基因示意图(非按比例);图2:打靶策略示意图(非按比例);图3:tv-4g-ighg1质粒酶切电泳结果图,图中1、2、3、4分别指4个tv-4g-ighg1克隆,m为marker,ck代表未经酶切的质粒对照;图4:tv-4g-ighg1-b质粒酶切电泳结果图,图中1-6分别指6个tv-4g-ighg1-b克隆,m为marker,ck代表未经酶切的质粒对照;图5:sgrna活性检测结果,其中con为阴性对照,pc为阳性对照;图6:pt7-sgrnag2质粒图谱示意图;图7:c57bl/6背景f0代阳性小鼠pcr鉴定结果,其中,wt为野生型,h2o为水对照,m为marker,编号为5的小鼠为阳性小鼠;图8:balb/c背景f0代阳性小鼠pcr鉴定结果,其中,wt为野生型,h2o为水对照,m为marker,编号为1、2、3的小鼠为阳性小鼠;图9:c57bl/6背景f1代阳性小鼠pcr鉴定结果,其中,wt为野生型,h2o为水对照,m为marker,+为阳性对照,编号为f1-1、f1-2、f1-3的小鼠为阳性小鼠;图10:流式分析结果,取野生型c57bl/6小鼠(a、b、c、d)和ighg1(a、b、c、d)基因改造纯合子小鼠(c57bl/6背景),经hcd27蛋白胞外区免疫后取脾脏细胞,加入anti-mousecd16/32封闭fc受体,然后分别加入biotinylatedhumancd27fctag(a、a)、humancd27fctag(c、c),并选择无关抗原作阴性对照:biotinylatedhumantigitfctag(b、b)和humantigitfctag(d、d);再加入pestreptavidin/fitcanti-mousecd19antibody(a、a、b、b)或peanti-humaniggfc/fitcanti-mousecd19antibody(c、c、d、d)进行细胞标记;图11:ighg1基因改造纯合子小鼠经hcd27蛋白胞外区免疫后脾细胞分选检测结果;图12:基于胚胎干细胞的方法制备本发明所述模式动物的打靶策略。具体实施方式下面结合具体实施例来进一步描述本发明,本发明的优点和特点将会随着描述而更为清楚。但这些实施例仅是范例性的,并不对本发明的范围构成任何限制。本领域技术人员应该理解的是,在不偏离本发明的精神和范围下可以对本发明技术方案的细节和形式进行修改或替换,但这些修改和替换均落入本发明的保护范围内。根据抗体的重链恒定区不同,抗体类型可分为iga、igd、ige、igg和igm等5种,其中免疫反应中提供最主要作用的抗体是抗体igg(immunoglobuling),约占血清免疫球蛋白的70%。作为血清中最主要、半衰期最长的免疫球蛋白,igg抗体在免疫应答中起着激活补体、中和多种毒素等生理功能,目前开发的重组单克隆抗体主要是以igg为框架开发的。人igg有4种亚型,含量比例分别为:igg1约60%、igg2约25%、igg3约10%、igg4约5%。它们在宿主中的生物功能也各有侧重,igg1和igg3主要结合蛋白质抗原,igg2结合糖类抗原,igg4则响应慢性刺激并且具有抗炎的活性。鉴于igg1型抗体占血清中免疫球蛋白的主要部分,本发明将以筛选igg1型抗体为例,对本
发明内容作出进一步的说明。本发明通过在igg1抗体fc段尾部增加具有跨膜结构的多肽片段,使得小鼠接受抗原免疫后,体内产生的具有正常活性的igg1抗体“挂”(保留)在小鼠浆细胞表面,通过检测和分选这部分浆细胞,可以直接获得表达该特定抗体的浆细胞,用于抗体序列的捕获和后续表达、修饰、改造等应用,从而避免繁琐的抗体库的制备和杂交瘤制备及筛选等过程。为了达到上述目的,本发明在编码igg1fc段的基因组序列上敲进编码连接肽(如f2a、p2a、ires等)和跨膜多肽的片段dna,使得小鼠体内产生的具有正常活性的抗体可以通过连接肽与具有跨膜结构的多肽片段连接,从而能够产生具有跨膜结构的融合抗体。由于连接肽具有“自我剪切”的特点,部分通过连接肽连接的融合抗体会因连接肽的“自我剪切”而分离,但仍会有部分未经剪切的跨膜融合抗体保留在小鼠浆细胞表面,这部分浆细胞将可被检测和分选出来用于抗体序列的捕获和后续表达、修饰、改造等应用。在下述每一实施例中,设备和材料是从以下所指出的几家公司获得:c57bl/6小鼠购自中国食品药品检定研究院国家啮齿类实验动物种子中心;balb/c小鼠购自北京维通利华实验动物技术有限公司;ecori、bamhi、ecorv、scai、saci、ndei、bstxi、stui酶购自neb,货号分别为r3101m、r3136m、r0195s、r3122m、r0165s、r0111s、r0113s、r0187m;ambion体外转录试剂盒购自ambion,货号am1354;uca试剂盒来源百奥赛图公司,货号bcg-dx-001;cas9mrna来源sigma,货号cas9mrna-1ea;aio试剂盒来源百奥赛图公司,货号bcg-dx-004;phsg299质粒购自takara,货号3299;biotinylatedhumancd27fctag购自acrobiosystems,货号tn7-h82f6;biotinylatedhumantigitfctag购自acrobiosystems,货号tit-h82f1;anti-mousecd16/32购自biolegend,货号101301;humancd27fctag购自acrobiosystems,货号cd7-h5254;humantigitfctag购自acrobiosystems,货号tit-h5254;biotinylatedhumancd27ligand/cd70protein,fctag来源acrobiosystems,货号tn7-h82f4;anti-biotinmicrobeads来源miltenyibbiotec,货号130-090-485;pestreptavidin购自biolegend,货号405203;fitcanti-mousecd19antibody购自biolegend,货号101505;peanti-humaniggfc购自biolegend,货号409303;流式细胞仪生产厂家bd,型号为calibur。实施例1序列设计和打靶方案小鼠ighg1基因(geneid:16017)在转录和翻译过程中存在可变剪切形式(见图1示意图),在第一个3’utr的终止密码子前插入可编码连接肽f2a和跨膜结构多肽的dna片段,所述编码f2a的dna片段序列如seqidno:1所示,编码的f2a氨基酸序列如seqidno:2所示;所述编码m1跨膜结构多肽的dna片段序列如seqidno:3所示,所述编码m2跨膜结构多肽的dna片段序列如seqidno:45所示,编码的跨膜结构多肽氨基酸序列如seqidno:4所示。gtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaacccagggccc(seqidno:1)vkqtlnfdllklagdvesnpgp(seqidno:2)seqidno:3gggctgcaactggacgagacctgtgctgaggcccaggacggggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagcgctgctgtcacactcttcaagseqidno:45gtaaagtggatcttctcctcggtggtggagctgaagcagacactggttcctgaatacaagaacatgattgggcaagcacccseqidno:4:glqldetcaeaqdgeldglwttitifislfllsvcysaavtlfkvkwifssvvelkqtlvpeyknmigqap最终得到的改造后的小鼠ighg1基因示意图见图1,并进一步的设计了如图2所示的打靶策略,其中,打靶载体的设计包含5’同源臂、插入的dna片段(简称“a片段”)、3’同源臂的载体。实施例2载体构建以c57bl/6背景小鼠为例,构建的打靶载体5’同源臂(seqidno:5)选自ncbi登录号为nc_000078.6的第113328979-113331115位核苷酸;3’同源臂(seqidno:6)与ncbi登录号为nc_000078.6的第113327084-113328975位核苷酸相比有一处突变:该序列第10位碱基c→g,但该突变对蛋白表达无影响;a片段(seqidno:7)为包含编码f2a和跨膜结构多肽的dna片段。改造后的小鼠ighg1基因dna序列如seqidno:8所示:ctcctggtaaaccggtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaacccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacggggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagcgctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtggagctgaagcagacactggttcctgaatacaagaacatgattgggcaagcaccctgaagatcttcccagtgtgc(seqidno:8仅列出涉及改造部分的dna序列)得到的改造后的基因工程小鼠ighg1基因编码的融合抗体蛋白的部分序列如seqidno:9所示。kttppsvyplapgsaaqtnsmvtlgclvkgyfpepvtvtwnsgslssgvhtfpavlqsdlytlsssvtvpsstwpsqtvtcnvahpasstkvdkkivprdcgckpcictvpevssvfifppkpkdvltitltpkvtcvvvdiskddpevqfswfvddvevhtaqtkpreeqinstfrsvselpimhqdwlngkefkcrvnsaafpapiektisktkgrpkapqvytipppkeqmakdkvsltcmitnffpeditvewqwngqpaenykntqpimdtdgsyfvysklnvqksnweagntftcsvlheglhnhhtekslshspgkpvkqtlnfdllklagdvesnpgpglqldetcaeaqdgeldglwttitifislfllsvcysaavtlfkvkwifssvvelkqtlvpeyknmigqap(seqidno:9)其中,斜体下划线为f2a序列,下划波浪线为跨膜多肽序列。具体的载体构建过程如下:设计扩增4段同源重组片段(lr、a1、a2、rr)的上游引物和与其匹配的下游引物以及相关序列,其中5’同源臂对应lr,含编码f2a和跨膜结构(m1、m2)多肽的a片段对应a1+a2,3’同源臂对应rr。引物序列见表1。表1引物序列以c57bl/6小鼠基因组dna为模板pcr分别扩增获得lr、rr、a1、a2片段。将片段a1与a2通过pcr反应连接(反应体系和反应条件见表2、3),测序验证正确后,利用aio试剂盒将lr、a1+a2和rr片段连接至试剂盒配备的pclon-4g质粒上,最终获得载体tv-4g-ighg1。表2pcr反应体系(20μl)表3pcr扩增反应条件实施例3载体验证随机挑选4个tv-4g-ighg1克隆,使用3组限制性内切酶进行酶切验证,其中,ecorv+scai应出现2709bp+5114bp,saci应出现2878bp+4945bp,ndei应出现982bp+6841bp。酶切结果参见图3,所有质粒的酶切结果均符合预期,表明这些质粒酶切验证结果正确。其中编号1和4的质粒经测序公司测序验证正确。选择质粒4进行后续试验。实施例4载体构建以balb/c背景小鼠为例,构建的打靶载体5’同源臂如序列seqidno:18所示;3’同源臂如序列seqidno:19所示;a片段包含编码f2a和跨膜结构多肽的dna片段,如序列seqidno:20所示。改造后的小鼠ighg1基因dna序列如seqidno:21所示:tcctggtaaaccggtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaacccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacggggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagcgctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtggagctgaagcagacactggttcctgaatacaagaacatgattgggcaagcaccctgacctggacaaggtcccagtgtgcttggagccctctgg(seqidno:21仅列出涉及改造部分的dna序列)得到的改造后的基因工程小鼠ighg1基因编码的融合抗体蛋白的部分序列如seqidno:22所示。mvtlgclvkgyfpepvtvtwnsgslssgvhtfpavlesdlytlsssvtvpssprpsetvtcnvahpasstkvdkkivprdcgckpcictvpevssvfifppkpkdvltitltpkvtcvvvdiskddpevqfswfvddvevhtaqtqpreeqfnstfrsvselpimhqdwlngkefkcrvnsaafpapiektisktkgrpkapqvytipppkeqmakdkvsltcmitdffpeditvewqwngqpaenykntqpimntngsyfvysklnvqksnweagntftcsvlheglhnhhtekslshspgkpvkqtlnfdllklagdvesnpgpglqldetcaeaqdgeldglwttitifislfllsvcysaavtlfkvkwifssvvelkqtlvpeyknmigqap(说明:其中,斜体下划线为f2a序列,下划波浪线为跨膜多肽序列)具体的载体构建过程如下:设计扩增3段同源重组片段(lr-b、m-b、rr-b)的上游引物和与其匹配的下游引物以及相关序列,其中5’同源臂对应lr-b,含编码f2a和跨膜结构(m1、m2)多肽的a片段对应m-b,3’同源臂对应rr-b。引物序列见表4:表4引物序列以balb/c小鼠基因组dna为模板pcr分别扩增获得lr-b、rr-b片段;以tv-4g-ighg1克隆为模板pcr扩增获得m-b片段,利用aio试剂盒将lr-b、rr-b和m-b片段连接至试剂盒配备的tv-4g质粒上,最终获得载体tv-4g-ighg1-b。实施例5载体验证随机挑选6个tv-4g-ighg1-b克隆,使用2组限制性内切酶进行酶切验证,其中,bstxi+stui应出现508bp+946bp+1176bp+5203bp,bamhi应出现3595bp+4238bp。酶切结果参见图4,所有质粒的酶切结果均符合预期,表明这些质粒酶切验证结果正确。其中编号1和6的质粒经测序公司测序验证正确。选择质粒1进行后续试验。实施例6sgrna的设计靶序列决定了sgrna的靶向特异性和诱导cas9切割目的基因的效率。因此,高效特异的靶序列选择和设计是构建sgrna表达载体的前提。根据打靶方案,在ighg1基因上设计多个sgrna,其中,各个sgrna靶向的靶位点序列如下:sgrna-1靶位点序列(seqidno:29):5’-ggacactgggatcatttaccagg-3’sgrna-2靶位点序列(seqidno:30):5’-ttggagccctctggtcctacagg-3’sgrna-3靶位点序列(seqidno:31):5’-ccagtgtccttggagccctctgg-3’sgrna-4靶位点序列(seqidno:32):5’-tgtaggaccagagggctccaagg-3’sgrna-5靶位点序列(seqidno:33):5’-gggatcatttaccaggagagtgg-3’sgrna-6靶位点序列(seqidno:34):5’-ggatcatttaccaggagagtggg-3’sgrna-7靶位点序列(seqidno:35):5’-agaggctcttctcagtatggtgg-3’sgrna-8靶位点序列(seqidno:36):5’-gtaaatgatcccagtgtccttgg-3’sgrna-9靶位点序列(seqidno:37):5’-cagagggctccaaggacactggg-3’实施例7sgrna的筛选利用uca试剂盒检测上述多个sgrna的活性,从结果可见sgrna具有不同活性,检测结果参见图5和表5。从中优先选择sgrna-4并在其上游序列的5’端加上tagg得到正向寡核苷酸,在其互补链(下游序列)的5’端加上aaac得到反向寡核苷酸,合成正向、反向寡核苷酸后进行后续实验。sgrna-4序列上游:5’-taggaccagagggctcca-3’(seqidno:46)正向寡核苷酸:5’-taggtaggaccagagggctcca-3’(seqidno:38)sgrna-4序列下游:5’-tggagccctctggtccta-3’(seqidno:47)反向寡核苷酸:5’-aaactggagccctctggtccta-3’(seqidno:39)表5sgrna的活性检测结果实施例8pt7-sgrnag2质粒构建pt7-sgrnag2质粒来源:pt7-sgrnag2载体图谱,参见图6。由质粒合成公司合成含有t7启动子及sgrnascaffold的片段dna(seqidno:40)并通过酶切(ecori及bamhi)连接至骨架载体phsg299质粒上,经专业测序公司测序验证,结果表明获得了目的质粒。含有t7启动子及sgrnascaffold的片段dna(seqidno:40):gaattctaatacgactcactatagggggtcttcgagaagacctgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcttttaaaggatcc实施例9pt7-ighg1-4表达载体的构建将实施例7中获得的正向、反向寡核苷酸退火后将退火产物分别连接至pt7-sgrnag2质粒,获得表达载体pt7-ighg1-4。连接反应体系见表6:表6连接反应体系sgrna退火产物1μl(0.5μm)pt7-sgrnag2载体1μl(10ng)t4dnaligase1μl(5u)10×t4dnaligasebuffer1μl50%peg40001μlh2o补至10μl反应条件为:室温连接10-30min,转化至30μltop10感受态细胞中,然后取200μl涂布于kan抗性的平板,37℃培养至少12小时后挑选2个克隆接种含有kan抗性的lb培养基(5ml)中,37℃,250rpm摇培至少12小时。随机挑选克隆送测序公司进行测序验证,选择连接正确的表达载体pt7-ighg1-4进行后续实验。实施例10显微注射及胚胎移植取c57bl/6小鼠的受精卵,利用显微注射仪将预混好的pt7-ighg1-4质粒的体外转录产物(使用ambion体外转录试剂盒,按照说明书方法进行转录)和cas9mrna,tv-4g-ighg1质粒注射至小鼠受精卵细胞质或细胞核中。按照《小鼠胚胎操作实验手册(第三版)》中的方法进行胚胎的显微注射,注射后的受精卵转移至培养液中短暂培养,然后移植至受体母鼠的输卵管,生产基因改造小鼠,得到c57bl/6背景的首建鼠(即founder鼠,为f0代)。将获得的f0代小鼠,通过鼠尾基因型检测筛选获得阳性f1代小鼠后,再通过后续的杂交和自交,扩大种群数量,建立稳定的小鼠品系。实施例11显微注射及胚胎移植取balb/c小鼠的受精卵,利用显微注射仪将预混好的pt7-ighg1-4质粒的体外转录产物(使用ambion体外转录试剂盒,按照说明书方法进行转录)和cas9mrna,tv-4g-ighg1-b质粒注射至小鼠受精卵细胞质或细胞核中。按照《小鼠胚胎操作实验手册(第三版)》中的方法进行胚胎的显微注射,注射后的受精卵转移至培养液中短暂培养,然后移植至受体母鼠的输卵管,生产基因改造小鼠,得到balb/c背景的首建鼠(即founder鼠,为f0代)。将获得的f0代小鼠,通过鼠尾基因型检测筛选获得阳性f1代小鼠后,再通过后续的杂交和自交,扩大种群数量,建立稳定的小鼠品系。实施例12基因改造小鼠的基因型鉴定1、f0代基因型鉴定分别使用两对引物对得到的c57bl/6背景和balb/c背景的f0代小鼠的鼠尾基因组dna进行pcr分析,引物位置l-gt-f位于5’同源臂左侧,r-gt-r位于3’同源臂右侧,r-gt-f和l-gt-r均位于a片段上,具体序列如下:5’端引物:上游引物:l-gt-f(seqidno:41):5’-ccacatgtttaggagcctgggttgacttc-3’下游引物:l-gt-r(seqidno:42):5’-gggccctgggttggactccac-3’3’端引物:上游引物:r-gt-f(seqidno:43):5’-ccggtgaaacagactttgaattttgaccttc-3’下游引物:r-gt-r(seqidno:44):5’-gcacggaacaaggtacacctgggacagag-3’具体pcr反应体系和反应条件如表7、8所示。表7pcr反应体系(20μl)10×缓冲液2μldntp(2mm)2μlmgso4(25mm)0.8μl上游引物(10μm)0.6μl下游引物(10μm)0.6μl鼠尾基因组dna200ngkod-plus-(1u/μl)0.6μl表8pcr扩增反应条件如果重组载体插入位置正确,则理论上,使用l-gt-f/l-gt-r进行pcr后,使用凝胶电泳验证应在2290bp存在条带;使用r-gt-f/r-gt-r进行pcr后,使用凝胶电泳验证应在2304bp存在条带。c57bl/6背景的f0代小鼠的pcr鉴定结果见图7,其中编号为5的小鼠为阳性小鼠。balb/c背景的f0代小鼠的pcr鉴定结果见图8,其中编号为1、2、3的小鼠为阳性小鼠。2、f1代基因型鉴定将f0鉴定为阳性的小鼠分别与相同背景的野生型小鼠交配得到f1代小鼠。对f1代鼠尾基因组dna进行pcr分析。pcr条件及引物同f0代基因型鉴定。以c57bl/6背景为例,将f0阳性小鼠与c57bl/6小鼠交配后得到的f1代小鼠pcr实验结果见图9,其中编号为f1-1、f1-2、f1-3的小鼠为阳性小鼠。这表明使用本方法能构建出可稳定传代的基因工程小鼠。实施例13抗体筛选验证本实施例将以筛选抗人cd27抗体为例,阐述如何利用本发明制备的基因工程小鼠进行抗体筛选。分别选用1只c57bl/6背景的ighg1基因改造纯合子小鼠和1只野生型小鼠,使用hcd27蛋白胞外区经皮下免疫,随后每隔2-4周加强免疫,对动物执行该方案2-5个月。随后执行安乐死后取脾脏进行脾细胞分离,用注射器尾部对脾脏进行研磨,过70μm细胞筛网,将过滤好的细胞悬液离心弃上清,加入红细胞裂解液,冰上放置3-5min后,pbs溶液中和裂解反应,离心弃上清后,再加入anti-mousecd16/32重悬细胞,冰上放置15min后分装于1.5mlep管(每组共4管),随机加入biotinylatedhumancd27fctag(图10a、a)、humancd27fctag(图10c、c),选择无关抗体作阴性对照:biotinylatedhumantigitfctag(图10b、b)和humantigitfctag(图10d、d),混匀细胞后冰上孵育15min,重复pbs清洗、离心弃上清步骤,再加入pestreptavidin/fitcanti-mousecd19antibody(图10a、a、b、b)或peanti-humaniggfc/fitcanti-mousecd19antibody(图10c、c、d、d),冰上孵育15min,加入pbs清洗细胞1次,离心弃上清后,pbs重悬细胞后进行流式检测蛋白表达。结果显示,与野生型小鼠相比,基因改造小鼠经hcd27免疫后,q1区出现明显的阳性细胞群(图10a、c),野生型对照(图10a、c)及无关抗体对照(图10b、b;d、d)的q1区无阳性细胞群出现,表明用抗人cd27抗体在小鼠脾细胞表面可检测到人cd27抗体,证明使用本方法制备的小鼠脾细胞表面,可以保留抗体并被识别和检测。进一步的,采用常规的磁珠分选法,可用biotinylatedhumancd27ligand/cd70protein,fctag标记,再利用anti-biotinmicrobeads进行脾细胞分选,结果表明可以分选得到分泌cd27特异性抗体的b细胞(图11)。证明通过本方法制备的小鼠脾细胞表面可以保留抗体,并可利用相应的抗体进行特异性抗体分泌脾细胞的分离,用于之后的抗体序列的捕获和后续表达、修饰、改造等应用。实施例14基于胚胎干细胞的制备方法采用其它基因编辑系统和制备方法也可以得到本发明的非人哺乳动物,包括但不限于基于胚胎干细胞(embryonicstemcell,es)的基因同源重组技术、锌指核酸酶(zfn)技术、转录激活子样效应因子核酸酶(talen)技术、归巢核酸内切酶(兆碱基大范围核酶)或其他分子生物学技术。本实施例以传统的es细胞基因同源重组技术为例,阐述如何采用其它方法制备获得ighg1基因改造小鼠。根据本发明的基因编辑策略和ighg1基因改造后的示意图(图1),发明人设计了图12所示的打靶策略,图12中还显示了重组载体的设计。鉴于本发明的目的之一是在小鼠ighg1基因特定序列后敲进一段可编码跨膜结构的序列,为此,发明人设计了包含5’同源臂、3’同源臂和包含敲进基因片段(seqidno:3和seqidno:45)的重组载体,在重组载体上构建了用于阳性克隆筛选的抗性基因,如新霉素磷酸转移酶编码序列neo,并在抗性基因的两侧装上两个同向排列的位点特异性重组系统,如frt或loxp重组位点。进一步的,还在重组载体3’同源臂下游构建了具有负筛选标记的编码基因,如白喉毒素a亚基的编码基因(dta)。载体构建可采用常规方法进行,如酶切连接等。将构建正确的重组载体转染小鼠胚胎干细胞,如c57bl/6小鼠的胚胎干细胞,利用阳性克隆筛选标记基因对得到的重组载体转染细胞进行筛选,并利用southernblot技术进行dna重组鉴定。将筛选出的正确阳性克隆按照《小鼠胚胎操作实验手册(第三版)》中的方法将阳性克隆细胞(黑色鼠)通过显微注射进入已分离好的囊胚中(白色鼠),注射后的嵌合囊胚转移至培养液中短暂培养,然后移植至受体母鼠(白色鼠)的输卵管,可生产f0代嵌合体鼠(黑白相间)。通过提取鼠尾基因组和pcr检测,挑选基因正确重组的f0代嵌合鼠用于后续繁殖和鉴定。将f0代嵌合鼠与野生型鼠交配获得f1代鼠,通过提取鼠尾基因组和pcr检测,挑选可以稳定遗传的基因重组阳性f1代杂合子小鼠。再将f1代杂合小鼠互相交配即可获得基因重组阳性f2代纯合子鼠。此外,可将f1代杂合鼠与flp或cre工具鼠交配去除阳性克隆筛选标记基因(neo等)后,再通过互相交配即可得到基因人源化纯合子小鼠。对获得的f1代杂合或f2代纯合鼠进行基因型和表型检测的方法与前述实施例12一致。以上详细描述了本发明的优选实施方式,但是,本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,这些简单变型均属于本发明的保护范围。另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本发明对各种可能的组合方式不再另行说明。此外,本发明的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明的思想,其同样应当视为本发明所公开的内容。序列表<110>北京百奥赛图基因生物技术有限公司<120>一种筛选抗体的非人模式动物的构建方法及其应用<130>1<160>47<170>patentinversion3.5<210>1<211>66<212>dna/rna<213>人工序列(artificialsequence)<400>1gtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaaccca60gggccc66<210>2<211>22<212>prt<213>人工序列(artificialsequence)<400>2vallysglnthrleuasnpheaspleuleulysleualaglyaspval151015gluserasnproglypro20<210>3<211>132<212>dna/rna<213>人工序列(artificialsequence)<400>3gggctgcaactggacgagacctgtgctgaggcccaggacggggagctggacgggctctgg60acgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagcgctgctgtc120acactcttcaag132<210>4<211>71<212>prt<213>人工序列(artificialsequence)<400>4glyleuglnleuaspgluthrcysalaglualaglnaspglygluleu151015aspglyleutrpthrthrilethrilepheileserleupheleuleu202530servalcystyrseralaalavalthrleuphelysvallystrpile354045pheserservalvalgluleulysglnthrleuvalproglutyrlys505560asnmetileglyglnalapro6570<210>5<211>2137<212>dna/rna<213>人工序列(artificialsequence)<400>5tcctgacccaagaatagagagtgctaaacggacttagttcaaagacaactgaaaaagaca60atgcctgcaaaacaaagctaaggccagagctcttggactatgaagagttcagggaaccta120agaacagggaccatctgtgtacaggccaaggccggtagaagcagcctaggaagtgtcaag180agccaacgtggctgggtgggcaaagacaggaagggactgttaggctgcagggatgtgccg240acttcaatgtgcttcagtattgtccagattgtgtgcagccatatggcccaggtataagag300gtttaacagtggaacacagatgcccacatcagacagctggggggcgggggtgaacacaga360tacccatactggaaagcaggtggggcattttcctaggaacgggactgggctcaatggcct420caggtctcatctggtctggtgatcctgacattgataggcccaaatgttggatatcaccta480ctccatgtagagagtcggggacatgggaagggtgcaaaagagcggccttctagaaggttt540ggtcctgtcctgtcctgtctgacagtgtaatcacatatactttttcttgtagccaaaacg600acacccccatctgtctatccactggcccctggatctgctgcccaaactaactccatggtg660accctgggatgcctggtcaagggctatttccctgagccagtgacagtgacctggaactct720ggatccctgtccagcggtgtgcacaccttcccagctgtcctgcagtctgacctctacact780ctgagcagctcagtgactgtcccctccagcacctggcccagccagaccgtcacctgcaac840gttgcccacccggccagcagcaccaaggtggacaagaaaattggtgagaggacgtatagg900gaggaggggttcactagaggtgaggctcaagccattagcctgcctaaaccaaccaggctg960gacagccatcaccaggaaatggatctcagcccagaagatcgaaagttgttcttctccctt1020ctggagatttctatgtcctttacactcattggttaatatcctgggttggattcccacaca1080tcttgacaaacagagacaattgagtatcaccagccaaaagtcatacccaaaaacagcctg1140gcatgacctcacaccagactcaaacttaccctacctttatcctggtggcttctcatctcc1200agaccccagtaacacatagctttctctccacagtgcccagggattgtggttgtaagcctt1260gcatatgtacaggtaagtcagtaggcctttcaccctgaccccagatgcaacaagtggcca1320tgttagagggtggcccaggtattgacctatttccacctttcttcttcatccttagtccca1380gaagtatcatctgtcttcatcttccccccaaagcccaaggatgtgctcaccattactctg1440actcctaaggtcacgtgtgttgtggtagacatcagcaaggatgatcccgaggtccagttc1500agctggtttgtagatgatgtggaggtgcacacagctcagacgaaaccccgggaggagcag1560atcaacagcactttccgttcagtcagtgaacttcccatcatgcaccaggactggctcaat1620ggcaaggagttcaaatgcagggtcaacagtgcagctttccctgcccccatcgagaaaacc1680atctccaaaaccaaaggtgagagctgcagtgtgtgacatagaagctgcaatagtcagtcc1740atagacagagcttggcataacagacccctgccttgtccatgacctctgtgctaaccaatc1800tctttacccacccacaggcagaccgaaggctccacaggtgtacaccattccacctcccaa1860ggagcagatggccaaggataaagtcagtctgacctgcatgataacaaacttcttccctga1920agacattactgtggagtggcagtggaatgggcagccagcggagaactacaagaacactca1980gcccatcatggacacagatggctcttacttcgtctacagcaagctcaatgtgcagaagag2040caactgggaggcaggaaatactttcacctgctctgtgttacatgagggcctgcacaacca2100ccatactgagaagagcctctcccactctcctggtaaa2137<210>6<211>1892<212>dna/rna<213>人工序列(artificialsequence)<400>6tcccagtgtgcttggagccctctggtcctacaggactctgacacctacctccacccctcc60ctgtgtaaataaagcacccagcactgccttgggaccctgcaataatgtcctggtgatttc120tgagatgtagagtctagctaggtcatggaatgaggggtctccatggtttgaggcctgagt180tgtgactaaggaaaaacccataggcctacactgccacacccagcacttttgaatttgcct240gacatgaaaagaatttacctctccctggaaagtggagccttatccctaggcagttccctt300accagaccttcctctagcttgcactttgttctgggcacagaatgtgtctaaccccccaaa360gcaaggaagacacaacctctacctccctcactctgtccttaccccttttcctggctaagc420atctcactgagtgcgctgaatagatgcatgtggccacagtcttgcagacagacccttgcc480atctctccactcagctttccagaggctaagtctagcccgtatggtgataatgcagggagc540tctatgctatctcagtgctatcagactcccaagtggaggatgaacatggacccattaaaa600ccaacctgcgcagcaacaccctgccaataaggcccgtatgtgaaaatgtgcacacatcta660cacatgcacaggcacacacacacacacatgcatgggcacacacacatacagagagagaga720atcacagaaactcccatgagcatcctatacagtactcaaagataaaaaggtaccaggtct780acccacatgatcatcctcggcatttacaagtgggccaactgatacagataaaacttttct840atgccaaggacgccaacatatacacaagtccgctcatgacaaatctgtccctgaacctca900gactggcgcccgtgactcatacagtggacactcctccaaagctgtatagcttcctttact960tccctgtgtgtactttctctgaagtacactcatcacacagaagaggccctgtgattactc1020tggccctctgttcttggtcatcagagaatagacagaagatcaggcaaactacacagacac1080ttcccacaatcatcacaggccctgactctgctctccagtctcaaaactgaaggctggagc1140acacagaataagctcctgcacaggccaggccagtatcgggtccagtgtgtctgactgagc1200ccagggacaaaatggcagcactttggggaactgaggtttctggtccaagaaggagagatg1260gaggcccagggagggtctgctgacccagcccagcccagcccagctgcagctttctcctgg1320gcctccatacagcctcctgccacacagggaatggccctagccccaccttattgggacaaa1380cactgaccgccctctctgtccagggctgcaactggacgagacctgtgctgaggcccagga1440cggggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcag1500tgtgtgctacagcgctgctgtcacactcttcaaggtcagccatactgtccccacagtgtc1560tacaatgtcctcatactcttccccatactgtccctgtggtgacctataccccacactgtc1620ccatgctaatgaccacagtcttacatgctatgtaatgctgtctacccttctgtatgcaca1680gtctcacaatgtcccatgcagtctccacgatgctccatactgtccccattccaacccatg1740ctgccccttgttccccgctatgctgtcccatgctattgtctgtattttcatgctcttttc1800acactgtccctagtgtcacattctgcccatgttgtccaccacattgtccccactctgtac1860acagcctcacactgtaccctgctacccgataa1892<210>7<211>291<212>dna<213>人工序列(artificialsequence)<400>7ccggtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaac60ccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacggggagctggac120gggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagc180gctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtggagctgaagcag240acactggttcctgaatacaagaacatgattgggcaagcaccctgaagatct291<210>8<211>313<212>dna<213>人工序列(artificialsequence)<400>8ctcctggtaaaccggtgaaacagactttgaattttgaccttctcaagttggcgggagacg60tggagtccaacccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacg120gggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtg180tgtgctacagcgctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtgg240agctgaagcagacactggttcctgaatacaagaacatgattgggcaagcaccctgaagat300cttcccagtgtgc313<210>9<211>417<212>prt<213>人工序列(artificialsequence)<400>9lysthrthrproproservaltyrproleualaproglyseralaala151015glnthrasnsermetvalthrleuglycysleuvallysglytyrphe202530progluprovalthrvalthrtrpasnserglyserleusersergly354045valhisthrpheproalavalleuglnseraspleutyrthrleuser505560serservalthrvalproserserthrtrpproserglnthrvalthr65707580cysasnvalalahisproalaserserthrlysvalasplyslysile859095valproargaspcysglycyslysprocysilecysthrvalproglu100105110valserservalpheilepheproprolysprolysaspvalleuthr115120125ilethrleuthrprolysvalthrcysvalvalvalaspileserlys130135140aspaspprogluvalglnphesertrpphevalaspaspvalgluval145150155160histhralaglnthrlysproargglugluglnileasnserthrphe165170175argservalsergluleuproilemethisglnasptrpleuasngly180185190lysgluphelyscysargvalasnseralaalapheproalaproile195200205glulysthrileserlysthrlysglyargprolysalaproglnval210215220tyrthrileproproprolysgluglnmetalalysasplysvalser225230235240leuthrcysmetilethrasnphepheprogluaspilethrvalglu245250255trpglntrpasnglyglnproalagluasntyrlysasnthrglnpro260265270ilemetaspthraspglysertyrphevaltyrserlysleuasnval275280285glnlysserasntrpglualaglyasnthrphethrcysservalleu290295300hisgluglyleuhisasnhishisthrglulysserleuserhisser305310315320proglylysprovallysglnthrleuasnpheaspleuleulysleu325330335alaglyaspvalgluserasnproglyproglyleuglnleuaspglu340345350thrcysalaglualaglnaspglygluleuaspglyleutrpthrthr355360365ilethrilepheileserleupheleuleuservalcystyrserala370375380alavalthrleuphelysvallystrpilepheserservalvalglu385390395400leulysglnthrleuvalproglutyrlysasnmetileglyglnala405410415pro<210>10<211>46<212>dna/rna<213>人工序列(artificialsequence)<400>10tttaagaaggagatatacatgtcctgacccaagaatagagagtgct46<210>11<211>74<212>dna/rna<213>人工序列(artificialsequence)<400>11cgtctcccgccaacttgagaaggtcaaaattcaaagtctgtttcaccggtttaccaggag60agtgggagaggctc74<210>12<211>69<212>dna/rna<213>人工序列(artificialsequence)<400>12ttgaccttctcaagttggcgggagacgtggagtccaacccagggcccgggctgcaactgg60acgagacct69<210>13<211>49<212>dna/rna<213>人工序列(artificialsequence)<400>13accaccgaggagaagatccactttaccttgaagagtgtgacagcagcgc49<210>14<211>49<212>dna/rna<213>人工序列(artificialsequence)<400>14gcgctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggt49<210>15<211>41<212>dna/rna<213>人工序列(artificialsequence)<400>15gacactgggaagatcttcagggtgcttgcccaatcatgttc41<210>16<211>40<212>dna/rna<213>人工序列(artificialsequence)<400>16aagcaccctgaagatcttcccagtgtgcttggagccctct40<210>17<211>48<212>dna/rna<213>人工序列(artificialsequence)<400>17ttgttagcagccggatctcagttatcgggtagcagggtacagtgtgag48<210>18<211>2143<212>dna/rna<213>人工序列(artificialsequence)<400>18tcctgacccaagaatagagagtgctaaacggacttagctcaaagacaactgaaaaagaca60atgcctgcaaaacaaagctaaggccagagctcttggactatgaagagttcagggaaccta120agaacagggaccatctgtgtacaggccaaggccggtagaagcagcctaggaaatgtcaag180agccaacgtggatgggtgggcaaagacaggaagggactgttaggctgcagggatgtgccg240acttcaatttgtgcttcagtgttgtccagattgtgtgcagccatatggcccaggtataag300aagtttaacagtggaacacagatgcccacatcagacagctggggggtggggggggtgaac360acagatacccatactggaaagcaggtggggcattttcctaggaacgggactgggctcaat420ggcctcaggtctcatctggtctggtgatcctgacattgacaggcccaaatgttggatatc480acctactccatgtagagagtcggggacatgggaagggtgcaaaagagcggccttctagaa540ggtttggtcctgtcctgtcctgtctgacagtgtaatcacatatactttttcttgtagcca600aaacgacacccccatctgtctatccactggcccctggatctgctgcccaaactaactcca660tggtgaccctgggatgcctggtcaagggctatttccctgagccagtgacagtgacctgga720actctggatccctgtccagcggtgtgcacaccttcccagctgtcctggagtctgacctct780acactctgagcagctcagtgactgtcccctccagccctcggcccagcgagaccgtcacct840gcaacgttgcccacccggccagcagcaccaaggtggacaagaaaattggtgagaggacat900atagggaggaggggttcactagaagtgaggctcaagccattagcctgcctaaaccaacca960ggctggacagccaaccaaccaggaaatggatctcagcccagaagatcaaaagttgttctt1020ctcccttctggagatttctatgtcctttacaactcaattggttaatatcctgggttggag1080tcccacacatcttgacaaacagagacaaatttgagtatcaccagccaaaagtcataccca1140aaaacagcctggcatgaccacacaccagactcaaacttaccctacctttatcctggtggc1200ttctcatctccagaccccagtaacacatagctttctctccacagtgcccagggattgtgg1260ttgtaagccttgcatatgtacaggtaagtcagtggccttcacctgacccagatgcaacaa1320gtggcaatgttggagggtggccaggtattgacctatttccacctttcttcttcatcctta1380gtcccagaagtatcatctgtcttcatcttccccccaaagcccaaggatgtgctcaccatt1440actctgactcctaaggtcacgtgtgttgtggtagacatcagcaaggatgatcccgaggtc1500cagttcagctggtttgtagatgatgtggaggtgcacacagctcagacgcaaccccgggag1560gagcagttcaacagcactttccgctcagtcagtgaacttcccatcatgcaccaggactgg1620ctcaatggcaaggagttcaaatgcagggtcaacagtgcagctttccctgcccccatcgag1680aaaaccatctccaaaaccaaaggtgagagctgcagtgtgtgacatagaagctgcaatagt1740cagtccatagacagagcttggcataacagacccctgccctgttcgtgacctctgtgctga1800ccaatctctttacccacccacaggcagaccgaaggctccacaggtgtacaccattccacc1860tcccaaggagcagatggccaaggataaagtcagtctgacctgcatgataacagacttctt1920ccctgaagacattactgtggagtggcagtggaatgggcagccagcggagaactacaagaa1980cactcagcccatcatgaacacgaatggctcttacttcgtctacagcaagctcaatgtgca2040gaagagcaactgggaggcaggaaatactttcacctgctctgtgttacatgagggcctgca2100caaccaccatactgagaagagcctctcccactctcctggtaaa2143<210>19<211>1866<212>dna/rna<213>人工序列(artificialsequence)<400>19agccctctggtcctacaggactctgacacctacctccacccctccctgtataaataaagc60acccagcactgccttgggaccctgcaataacgtcctggtgatttctgagatgtagagtct120agctaggtcatggaatgaggggtctccatggtttgagccctgagttgtgactaaggaaaa180actcataggcctacactgccacacccagcacttttgaatttgcctgacatgaaaagaatt240tacctctccctggaaagtggagccttatccctaggcagttcccttaccagaccttcctct300agcttgcactatgttctgggcacagaatgtgtctaaccccccaaagtaaggaagacacaa360cctctacttccctcactctgtccttaccccttttcctggctaagcatctcactgagtgcg420ctgaatagatgcatgtggccacagcttgcagacagacctttgccatctctccgctcagct480ttccagaggctaagtctagcccgtatggtgatgatgcagggagctctatgctatctcagt540gttatcagactcctaagtggaggatcaacatggtcccattaaaaccaacctgctcagcaa600caccctgccaataaggcccgtatgtgaaaatgtgcacacatctacacatgcacaggcaca660cacacacacacatgcatgggcacacacacatacagagagagagaatcacagaaactccca720tgagcatcctatacagtactcaaagataaaaaggtaccaggtctacccacatgatcatcc780tcggcatttacaagtgggccaactgatacagataaaacttttctatgccaaggacgccaa840caaccttcctcatatacacaagtccgctcatgacaaatctgtccctgaacctcagactgg900cgcccgtgactcacacagtggacactcctccaaagctgtatagcttcctttacttccctg960tgtgtactttctctgaagtacactcatcacacagaagaggccctgtgattactctggccc1020tctgttcttggtcatcagagaatagacagaagatcaggcaaactacacagacacttccca1080caatcatcacaggccctgactctgctctccagtctcaaaactgaaggctggagcacacag1140aaataagctcctacacagcccagaccagtatcgggtccagtgtgtctgaatgagcccagg1200gacaaaatggcagcactttggggaactgagatttctggtccaagaaggagagatggaggc1260ccagggagggtctgctgacccagcccagcccagcccagctgcagctttctcctgggcctc1320catgcagcttcctgccacacagggaatggccctagccccaccttattgggacaaacactg1380accgccctctctgtccagggctgcaactggacgagacctgtgctgaggcccaggacgggg1440agctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagcgtgt1500gctacagcgctgctgtcacactcttcaaggtcagccatactgtccccacagtgtctacaa1560tgtcctcatactcttccccatactgtccctgtggtgacctataccccacactgtcccatg1620ctaatgaccacagtcttacatgctatgtaatgctgtctacccttctgtatgcacagtctc1680acaatgtcccatgcagtctccacgatgctccatgctgccccttgttccacgctatgctgt1740cccatgctattgtctgtattttcatgctcttttcacactgtccctagtgtcacattctgc1800ccatgttgtccaccacattgtccccactctgcacacagcctcacactgtaccctgctacc1860cgataa1866<210>20<211>311<212>dna<213>人工序列(artificialsequence)<400>20ccggtgaaacagactttgaattttgaccttctcaagttggcgggagacgtggagtccaac60ccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacggggagctggac120gggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgtgtgctacagc180gctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtggagctgaagcag240acactggttcctgaatacaagaacatgattgggcaagcaccctgacctggacaaggtccc300agtgtgcttgg311<210>21<211>331<212>dna<213>人工序列(artificialsequence)<400>21tcctggtaaaccggtgaaacagactttgaattttgaccttctcaagttggcgggagacgt60ggagtccaacccagggcccgggctgcaactggacgagacctgtgctgaggcccaggacgg120ggagctggacgggctctggacgaccatcaccatcttcatcagcctcttcctgctcagtgt180gtgctacagcgctgctgtcacactcttcaaggtaaagtggatcttctcctcggtggtgga240gctgaagcagacactggttcctgaatacaagaacatgattgggcaagcaccctgacctgg300acaaggtcccagtgtgcttggagccctctgg331<210>22<211>397<212>prt<213>人工序列(artificialsequence)<400>22metvalthrleuglycysleuvallysglytyrpheprogluproval151015thrvalthrtrpasnserglyserleuserserglyvalhisthrphe202530proalavalleugluseraspleutyrthrleuserserservalthr354045valproserserproargprosergluthrvalthrcysasnvalala505560hisproalaserserthrlysvalasplyslysilevalproargasp65707580cysglycyslysprocysilecysthrvalprogluvalserserval859095pheilepheproprolysprolysaspvalleuthrilethrleuthr100105110prolysvalthrcysvalvalvalaspileserlysaspaspproglu115120125valglnphesertrpphevalaspaspvalgluvalhisthralagln130135140thrglnproargglugluglnpheasnserthrpheargservalser145150155160gluleuproilemethisglnasptrpleuasnglylysgluphelys165170175cysargvalasnseralaalapheproalaproileglulysthrile180185190serlysthrlysglyargprolysalaproglnvaltyrthrilepro195200205proprolysgluglnmetalalysasplysvalserleuthrcysmet210215220ilethraspphepheprogluaspilethrvalglutrpglntrpasn225230235240glyglnproalagluasntyrlysasnthrglnproilemetasnthr245250255asnglysertyrphevaltyrserlysleuasnvalglnlysserasn260265270trpglualaglyasnthrphethrcysservalleuhisgluglyleu275280285hisasnhishisthrglulysserleuserhisserproglylyspro290295300vallysglnthrleuasnpheaspleuleulysleualaglyaspval305310315320gluserasnproglyproglyleuglnleuaspgluthrcysalaglu325330335alaglnaspglygluleuaspglyleutrpthrthrilethrilephe340345350ileserleupheleuleuservalcystyrseralaalavalthrleu355360365phelysvallystrpilepheserservalvalgluleulysglnthr370375380leuvalproglutyrlysasnmetileglyglnalapro385390395<210>23<211>55<212>dna/rna<213>人工序列(artificialsequence)<400>23tttaagaaggagatatacatgaattctcctgacccaagaatagagagtgctaaac55<210>24<211>43<212>dna/rna<213>人工序列(artificialsequence)<400>24ttcaaagtctgtttcaccggtttaccaggagagtgggagaggc43<210>25<211>47<212>dna/rna<213>人工序列(artificialsequence)<400>25tctcccactctcctggtaaaccggtgaaacagactttgaattttgac47<210>26<211>49<212>dna/rna<213>人工序列(artificialsequence)<400>26ctccaagcacactgggaccttgtccaggtcagggtgcttgcccaatcat49<210>27<211>52<212>dna/rna<213>人工序列(artificialsequence)<400>27caccctgacctggacaaggtcccagtgtgcttggagccctctggtcctacag52<210>28<211>50<212>dna/rna<213>人工序列(artificialsequence)<400>28ttgttagcagccggatctcaggatccttatcgggtagcagggtacagtgt50<210>29<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>29ggacactgggatcatttaccagg23<210>30<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>30ttggagccctctggtcctacagg23<210>31<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>31ccagtgtccttggagccctctgg23<210>32<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>32tgtaggaccagagggctccaagg23<210>33<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>33gggatcatttaccaggagagtgg23<210>34<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>34ggatcatttaccaggagagtggg23<210>35<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>35agaggctcttctcagtatggtgg23<210>36<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>36gtaaatgatcccagtgtccttgg23<210>37<211>23<212>dna/rna<213>人工序列(artificialsequence)<400>37cagagggctccaaggacactggg23<210>38<211>22<212>dna/rna<213>人工序列(artificialsequence)<400>38taggtaggaccagagggctcca22<210>39<211>22<212>dna/rna<213>人工序列(artificialsequence)<400>39aaactggagccctctggtccta22<210>40<211>132<212>dna/rna<213>人工序列(artificialsequence)<400>40gaattctaatacgactcactatagggggtcttcgagaagacctgttttagagctagaaat60agcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgct120tttaaaggatcc132<210>41<211>29<212>dna/rna<213>人工序列(artificialsequence)<400>41ccacatgtttaggagcctgggttgacttc29<210>42<211>21<212>dna/rna<213>人工序列(artificialsequence)<400>42gggccctgggttggactccac21<210>43<211>31<212>dna/rna<213>人工序列(artificialsequence)<400>43ccggtgaaacagactttgaattttgaccttc31<210>44<211>29<212>dna/rna<213>人工序列(artificialsequence)<400>44gcacggaacaaggtacacctgggacagag29<210>45<211>81<212>dna/rna<213>人工序列(artificialsequence)<400>45gtaaagtggatcttctcctcggtggtggagctgaagcagacactggttcctgaatacaag60aacatgattgggcaagcaccc81<210>46<211>18<212>dna/rna<213>人工序列(artificialsequence)<400>46taggaccagagggctcca18<210>47<211>18<212>dna/rna<213>人工序列(artificialsequence)<400>47tggagccctctggtccta18当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1