一株高产吩嗪-1-羧酸的基因工程菌株及其构建方法和应用与流程
本发明属于基因工程技术领域,具体涉及一株高产吩嗪-1-羧酸的基因工程菌株及其构建方法和应用。
背景技术:
公开该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不必然被视为承认或以任何形式暗示该信息构成已经成为本领域一般技术人员所公知的现有技术。
化学农药污染严重,不可持续发展,生物农药是一类很好的替代品,与化学农药相比,生物农药具有毒性低、对环境友好和不易产生抗药性等明显优势,已经吸引了越来越多学者的关注并逐渐应用到生物防治实践当中。其中,上海交通大学许煜泉课题组率先利用铜绿假单胞菌株m18开发出了具有广谱、高效、安全和能有效控制真菌性根腐和茎腐的生物农药吩嗪-1-羧酸(phenazine-1-carboxylicacid,简称pca,cas号为2538-68-3),定名为“申嗪霉素”,主要用于防治水稻纹枯病、小麦赤霉病、黄瓜和西瓜的枯萎病、甜瓜蔓枯病、辣椒根腐病等,2011年被中国农业部授予农药证书,并被命名为“申嗪霉素”。
目前吩嗪-1-羧酸生产方法虽有化工方法,但条件苛刻,并且向环境释放有毒有害物质,所以主要由假单胞菌中的铜绿假单胞菌生产,但铜绿假单胞菌则是目前医院中一种比较常见的机会致病菌,并不太适合作为生产菌株来推广应用。
技术实现要素:
为了克服上述技术问题,本发明提供一株高产吩嗪-1-羧酸的基因工程菌株及其构建方法和应用。本发明以相对安全的绿针假单胞菌为出发菌株,通过基因工程技术在其基因组上敲除具有负调控作用的双元调控相关基因和中心碳代谢途径调控基因等,使得pca产量由初始408mg/l提升至7854mg/l,从而为pca的大规模生产奠定重要基础。
为实现上述技术目的,本发明采用的技术方案如下:
本发明的第一个方面,提供一株高产吩嗪-1-羧酸的基因工程菌株,具体是敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因中的一个或多个即得。
其中,所述绿针假单胞菌(pseudomonaschlororaphis)qlu-1是一株筛选自中国潍坊蔬菜大棚菜椒根际的绿针假单胞菌,经测序得知含有phzabcdefg基因簇,以及吩嗪类的修饰基因phzo,可以产生吩嗪-1-羧酸以及2-羟基吩嗪。该菌株已送至中国典型培养物保藏中心(地址:湖北省武汉市武昌珞珈山武汉大学),保藏日期为2020年05月08日,保藏编号为cctccno:m2020108。
优选的,所述高产吩嗪-1-羧酸的基因工程菌株,具体是敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因。
本发明的第二个方面,提供上述高产吩嗪-1-羧酸的基因工程菌株的构建方法,所述方法包括:
敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因中的一个或多个即得。
本发明的第三个方面,提供上述基因工程菌株在生产吩嗪-1-羧酸中的应用。
本发明的第四个方面,提供一种吩嗪-1-羧酸的生产方法,所述方法包括:将上述高产吩嗪-1-羧酸的基因工程菌株接种于发酵培养基中进行培养。
上述一个或多个技术方案的有益技术效果在于:
上述技术方案是以绿针假单胞菌qlu-1为出发菌株,通过基因工程技术从qlu-1菌株基因组中敲除phzo基因以及双元调控相关基因和中心碳代谢途径调控基因等,并构建相应基因工程菌株,从而使得吩嗪-1-羧酸的产量大幅提高,能够更加有效用于生物防治。经试验验证,基因工程菌株qpca-7具有最佳效果,其pca产量高达7854mg/l,且生长性能良好,因此具有良好的实际应用之价值。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
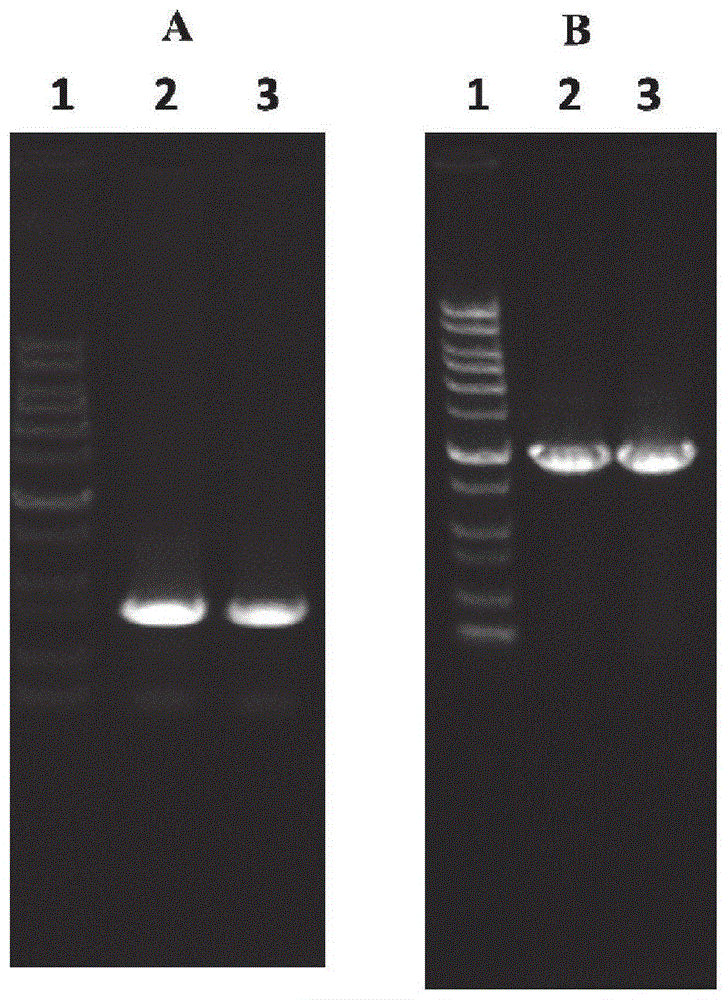
图1为本发明实施例中突变质粒pk18-phzo-ud构建电泳图;
(a)phzo上下游同源臂的扩增:1,dnaladder;2,phzo上游同源臂扩增;3,phzo下游游同源臂扩增(b)phzo上游同源臂融合片段扩增:1,dnaladder;2,3phzo基因上下游臂融合片段;
图2为本发明实施例中phzo基因双亲杂交双抗性平板筛选图;
图3为本发明实施例中影印法筛选phzo基因双交换阳性单克隆;
图4为本发明实施例中phzo敲除株pcr验证图;外部引物检测:1,phzo敲除株基因组为模板扩增片段;2,野生株基因组为模板扩增片段;3,空白对照;4,dnaladder;内部引物检测:1,dnaladder;2,野生株基因组为模板扩增片段;3,phzo敲除株基因组为模板扩增片段;4,空白对照;
图5为本发明实施例中不同菌株发酵液萃取物hplc检测结果图;其中,a为菌株qlu-1;b为菌株qpca-1;
图6为本发明实施例中不同菌株pca产量图。
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。应理解,本发明的保护范围不局限于下述特定的具体实施方案;还应当理解,本发明实施例中使用的术语是为了描述特定的具体实施方案,而不是为了限制本发明的保护范围。
本发明的一个典型具体实施方式中,提供一株高产吩嗪-1-羧酸的基因工程菌株,具体是敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因中的一个或多个即得。
其中,所述绿针假单胞菌(pseudomonaschlororaphis)qlu-1是一株筛选自潍坊蔬菜大棚菜椒根际的绿针假单胞菌,经测序得知含有phzabcdefg基因簇,以及吩嗪类的修饰基因phzo,可以产生吩嗪-1-羧酸以及2-羟基吩嗪。该菌株已送至中国典型培养物保藏中心(地址:湖北省武汉市武昌珞珈山武汉大学),保藏日期为2020年05月08日,保藏编号为:cctccno:m2020108。
所述phzo基因的碱基序列如seqidno.1所示。
所述lon基因、rsme基因、psra基因、pars基因和rpea基因的碱基序列分别如seqidno.2、seqidno.3、seqidno.4、seqidno.5和seqidno.6所示。
所述pykf基因的碱基序列如seqidno.7所示。
本发明的又一具体实施方式中,所述高产吩嗪-1-羧酸的基因工程菌株,具体是敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因即得。
本发明的又一具体实施方式中,提供上述高产吩嗪-1-羧酸的基因工程菌株的构建方法,所述方法包括:
敲除绿针假单胞菌(pseudomonaschlororaphis)qlu-1及其衍生物基因组中的phzo基因、lon基因、rsme基因、psra基因、pars基因、rpea基因和pykf基因中的一个或多个。
所述敲除phzo基因步骤包括:
i、扩增phzo基因片段的上下游同源臂;采用融合pcr法连接上下游同源臂并插入pk18mobsacb质粒中得phzo基因重组质粒;
ii、将phzo基因重组质粒导入大肠杆菌s17-1(λ)后与绿针假单胞菌qlu-1进行双亲杂交培养,从而将phzo基因重组质粒导入绿针假单胞菌qlu-1;
iii、筛选阳性克隆,即得菌株qpca-1;
其中,扩增phzo基因片段上游同源臂的引物包括phzo-f1和phzo-r1,序列分别如seqidno.8和seqidno.9所示;
扩增phzo基因片段下游同源臂的引物包括phzo-f2和phzo-r2,序列分别如seqidno.10和seqidno.11所示;
采用融合pcr法连接上下游同源臂获得的phzo基因上下游融合片段序列如seqidno.12所示。
筛选阳性克隆的方法具体包括蔗糖平板筛选、影印筛选和pcr筛选。
优选的,敲除lon基因、rsme基因、psra基因、pars基因、rpea和pykf基因的方法与敲除phzo基因的方法相同。
其中,敲除lon基因方法中,
扩增lon基因片段上游同源臂的引物包括lon-f1和lon-r1,序列分别如seqidno.13和seqidno.14所示;
扩增lon基因片段下游同源臂的引物包括lon-f2和lon-r2,序列分别如seqidno.15和seqidno.16所示;
采用融合pcr法连接上下游同源臂获得的lon基因上下游融合片段序列如seqidno.17所示。
其中,敲除rsme基因方法中,
扩增rsme基因片段上游同源臂的引物包括rsme-f1和rsme-r1,序列分别如seqidno.18和seqidno.19所示;
扩增rsme基因片段下游同源臂的引物包括rsme-f2和rsme-r2,序列分别如seqidno.20和seqidno.21所示;
采用融合pcr法连接上下游同源臂获得的rsme基因上下游融合片段序列如seqidno.22所示。
其中,敲除psra基因方法中,
扩增psra基因片段上游同源臂的引物包括psra-f1和psra-r1,序列分别如seqidno.23和seqidno.24所示;
扩增psra基因片段下游同源臂的引物包括psra-f2和psra-r2,序列分别如seqidno.25和seqidno.26所示;
采用融合pcr法连接上下游同源臂获得的psra基因上下游融合片段序列如seqidno.27所示。
其中,敲除pars基因方法中,
扩增pars基因片段上游同源臂的引物包括pars-f1和pars-r1,序列分别如seqidno.28和seqidno.29所示;
扩增pars基因片段下游同源臂的引物包括pars-f2和pars-r2,序列分别如seqidno.30和seqidno.31所示;
采用融合pcr法连接上下游同源臂获得的pars基因上下游融合片段序列如seqidno.32所示。
其中,敲除rpea基因方法中,
扩增rpea基因片段上游同源臂的引物包括rpea-f1和rpea-r1,序列分别如seqidno.33和seqidno.34所示;
扩增rpea基因片段下游同源臂的引物包括rpea-f2和rpea-r2,序列分别如seqidno.35和seqidno.36所示;
采用融合pcr法连接上下游同源臂获得的rpea基因上下游融合片段序列如seqidno.37所示。
其中,敲除pykf基因方法中,
扩增pykf基因片段上游同源臂的引物包括pykf-f1和pykf-r1,序列分别如seqidno.38和seqidno.39所示;
扩增pykf基因片段下游同源臂的引物包括pykf-f2和pykf-r2,序列分别如seqidno.40和seqidno.41所示;
采用融合pcr法连接上下游同源臂获得的pykf基因上下游融合片段序列如seqidno.42所示。
本发明的又一具体实施方式中,提供上述基因工程菌株在生产吩嗪-1-羧酸中的应用。
本发明的又一具体实施方式中,提供一种吩嗪-1-羧酸的生产方法,所述方法包括:将上述高产吩嗪-1-羧酸的基因工程菌株接种于发酵培养基中进行培养。
其中,所述发酵培养基可以是kb培养基。
为了更好的说明本发明的目的、技术方案和优点,下面将结合具体实施例对本发明做进一步说明。
实施例
1、将绿针假单胞菌qlu-1接种进kb(a+)培养基,30℃摇床180rpm提取荡培养过夜,利用基因组提取试剂盒提取qlu-1的基因组,-20℃下保藏备用。
2、在已经测序的qlu-1基因组数据中搜索phzo基因及其基因上下游序列,利用qlu-1菌株基因组为模板,以phzo-f1/phzo-r1,phzo-f2/phzo-r2分别为引物扩增phzo基因的上游片段phzo-u及线下游片段phzo-d;以phzo-u及phzo-d为模板,phzo-f1/phzo-r1为模板扩增phzo基因上下游融合片段phzo-ud。
3、将融合片段phzo-ud通过酶切连接的方法与敲除质粒pk18mobsacb构建重组质粒pk18-phzo-ud。
4、将重组质粒pk18-phzo-ud通过热击转化的方式导入大肠杆菌s17-1(λ)。
5、将大肠杆菌s17-1(λ)与假单胞菌qlu-1进行双亲杂交培养,将重组质粒pk18-phzo-ud导入假单胞菌qlu-1。
6、通过蔗糖平板筛选、影印筛选及pcr筛选等方法共同筛选qlu-1phzo敲除株,发酵后经hplc检测,发酵液中只积累吩嗪-1-羧酸,将菌株命名为qpca-1。
7、双元调控系统在假单胞菌吩嗪类物质的生产中起到重要作用,假单胞菌中双元调控系统众多,如rpea/rpeb系统、pars/parr系统、gacs/gaca系统等,我们在qpca-1的基础上,利用敲除phzo的方法先后累计无痕敲除了rsme、lon、rpea、psra、pars双元调控相关基因,并命名为qpca-2(qpca-1δrsme)、qpca-3(qpca-1δrsmeδlon)、qpca-4(qpca-1δrsmeδlonδrpea)、qpca-5(qpca-1δrsmeδlonδrpeaδpsra)、qpca-6(qpca-1δrsmeδlonδrpeaδpsraδpars),经发酵后,hplc检测pca产量相应提高到1109mg/l、1987mg/l、3265mg/l、4356mg/l、5408mg/l、
8、我们在qpca-6基础上敲除了中心碳代谢途径中起到重要作用的pykf基因,获得菌株qpca-7(qpca-1δrsmeδlonδrpeaδpsraδparsδpykf),经发酵后hplc检测发现其产量进一步提高,达到7854mg/l。
最后应该说明的是,以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。上述虽然对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
sequencelisting
<110>齐鲁工业大学
<120>一株高产吩嗪-1-羧酸的基因工程菌株及其构建方法和应用
<130>
<160>42
<170>patentinversion3.3
<210>1
<211>1476
<212>dna
<213>phzo基因
<400>1
atgctagatcttcaaaacaagcgtaaatatctgaaaagtgcagaatccttcaaagcttca60
ctgcgtgatgaccgcactgttatttatcaaggccaagttgttgaggatgtgactacacac120
ttctctacggctggaggcatatcgcaagttgcagaaatctacgaagaacaattcagcggt180
gaacacgacgacattctgacttacgtacgccccgacggttacctggcctcttctgcctat240
atgccccctagaaacaaagaagacttggcgttgcgacgccgcgcaatcacgtacgtctcg300
caaaaaacctggggcacccactgccgtaacctggacatgatcgccagcttcaccgtcggc360
atgatgggatatcggccgacattcaggaaaaaatgccctgagtacgcagaaaacattacc420
gaataccatgactacgccgagcgcaacagcctgtatttgtctgaggccattgttgatcca480
cagggctatcgggcacgtacccacggcaccgacctcaacctgccgccgcccgatcgtgcc540
gtgatgaggatcaacaagcagaacgccgagggcatctggatcagcggcgtcaaaggcgtg600
ggcacggtagcaccgcagtccaatgaaatatttgttggcagcttgttccccgcagcgccc660
aacgagtcattctgggcttacgtccctgccgatgcgccgggggtgaagattttttgccga720
gagattgtctcccagcctcacgccagcgcctatgaccacccgctcatatccaaaggtgaa780
gaagccgaggcgatggtggtattcgataacgtgttcattccacgctggcgaatcatggcg840
gcgaacgtgccggaactggccaacgccggcttcttcagcctgtggacctcatacagccat900
tggtacacgctcgtgcgcctggaaaccaaggctgacctgtatgccggactggccaaggtg960
atcatggaagtcctgggccttgaggggattgcggtggttcgccagcgggtcagcgaaata1020
gtgcagcttgcggaaatactcaaaggcatgtgcatcgcctccatcgaaacggccgagatg1080
tccgaaggcgacatattgctgcctggccccaacgcactggccgccggaaggatttttgcc1140
atggagaaattgcctcgggtgctgcatttgctcagagagctgtgcggacagggcttgatc1200
ctcaggttcaacgagaaagacttggccaccgacgccgcctttggccagaagttctcctgg1260
tttcttgacacgcaaagcgtgggcgccagagagaagaacctgctgatgaatctggtgtgg1320
gacgtggctgccagtgagcactccacacgtgcattggtgtttgaagaacagcacgcactc1380
agcgagcccctgctgcgcgatagcctggtgctggactacgactaccgcaaaagcacaagc1440
ctgatacgccgcatggtggggctcaacgccaaatag1476
<210>2
<211>2421
<212>dna
<213>lon基因
<400>2
atgagcgaccagcaagaacttcctgaaaccatgagtgaatacgccgacccggaaaacgcc60
gaactccatacatcctccggcaagggtctggccctgcccgggcagaatctgccggacaag120
gtctacatcatcccgatccacaatcggccgttcttccccgcgcaagtcttgccggtgatc180
gtcaacgaagaaccctgggccgaaaccctggaactggtgagcaagtccgaacaccattcg240
ctggcgctgttcttcatggacaccccaccggaagacccacggcatttcgacacctcggcc300
ctgccgctgtacggcaccctggtcaaggtgcaccacgccagccgcgaaaacggcaagttg360
cagttcgtggcccagggcctgacccgcgtacgcatccgcacctggctcaagcaccatcgc420
ccaccgtacctggtggaggtcgagtacccgcaccagccgagcgagccgaccgacgaggtc480
aaggcctacggcatggcgctgatcaacgcgatcaaggaactgctgccgctcaacccgctg540
tacagcgaagagctgaagaactacctcaaccgcttcagccccaacgacccgtcgccgctg600
accgacttcgccgccgcgctgacctcggccaccggcaacgaactgcaggaagtgctggac660
tgcgtaccgatgctcaagcgcatggaaaaagtcctgccgatgctgcgcaaggaagtcgag720
gtcgcgcgcctgcagaaagagatttccgccgaggtcaatcgcaagatcggcgagcatcag780
cgcgagttcttcctcaaggaacagctcaaggtcatccagcaggagctgggtctgaccaag840
gacgatcgcagcgccgacatcgagcagttcgagcagcgcctggcaggcaaggtcctgccg900
ccccaggcccagaagcgcatcgtggaagagatgaataaactgtcgatcctcgagaccggc960
tcgccggagtacgcggtcacccgcaactacctggaatgggccaccgcggtgccctggggc1020
gtgtacggcgaggacaagctcgacctcaagcatgcgcgcaaggtgctggaccagcatcac1080
gccgggctcgacgacatcaagagccggatcctcgaattcctcgcagtcggcgcctacaag1140
ggcgagatcagcggttccatcgtactgctggtgggcccgcccggcgtgggcaagaccagc1200
gtcggcaagtccatcgccgagtccctgggccggccgttctaccgcttcagcgtcggcggc1260
atgcgtgacgaggccgagatcaagggccaccgccgcacctacatcggcgccctgccgggc1320
aagctggtgcaggcgttgaaagacgtcgaagtgatgaacccggtgatcatgctcgacgag1380
atcgacaagatgggccagagctaccagggcgacccggcctcggcgctgctggaaaccctc1440
gacccggaacagaacgtggaatttctcgaccactacctggacctgcgcctggacctgtcg1500
aaagtgctgttcgtgtgcaccgccaacaccctggattcgattcccggcccgttgctggac1560
cggatggaagtgattcgcctgtcgggctacatcaccgaggaaaaactggccatcgccaag1620
cgccacctgtggcccaagcagctggaaaaggccggtgtgtccaaggcccacctgagcatc1680
agcgacgccgccctgcgcgcggtgatcgatggttacgcccgcgaggccggggtgcgccag1740
ctggaaaaacagctgggcaaactggtgcgcaaggccgtggtgcggctgctggaagatccg1800
gatgcggtgatcaagctcggcaccaaggacctggaagcctccctgggcatgccggtgttc1860
cgcaacgagcaggtgctcagcggcaccggggtgatcaccggcctggcctggaccagcctg1920
ggcggcgccacgctgccgatcgaagccacgcggattcataccctcaaccgtggtttcaag1980
ctcaccgggcaactgggggatgtgatgaaggagtcggcggaaatcgcctacagctacgtc2040
acctcgcacctcaagcagttcggtggcgatgcgaagttcttcgacgaggcgttcgtccac2100
ctgcacgtgccggaaggcgccacgccgaaggatggcccgagcgccggggtgaccatggcc2160
agcgccctgctgtccctggcgcgtaaccagccgccgaaaaagggcgtggccatgaccggc2220
gagctgaccctgaccgggcatgtcctgcccatcggcggggtgcgcgagaaagtcatcgcg2280
gcgcgccggcagaagctctacgagctgatcctgccggaagccaaccgcggccacttcgaa2340
gagctgccggactacctcaaggaaggcatcaccgtgcacttcgccaagcgtttcgccgat2400
gtggcgaaagtgctgttctaa2421
<210>3
<211>195
<212>dna
<213>rsme基因
<400>3
atgctgatactcacccgcaaagtcggtgaaagcataaatatcggtgacgacatcacgatc60
accattctgggcgtgagcggccagcaagtccggattggcatcaatgccccgaaagacgtc120
gcagtccatcgcgaagaaatctaccaacggatccaagccggcctcaccgccccggacaaa180
cgcgaaacaccttga195
<210>4
<211>708
<212>dna
<213>psra基因
<400>4
atggcccagtcggaaaccgttgaacgcattctcgatgctgccgagcagttgttcgcggaa60
aaaggttttgccgaaacctcattgcggctgatcaccagcaaggccggggtcaacctggcg120
gcggtgaattatcatttcggttccaagaaggccctgattcaggcagtgttctcgcgcttc180
ctcgggccgttctgcatcagcctcgaccgtgagctggagcggcgttcggccaagccggac240
agcaagccaagcctcgaagagctgctggaaatcctcgtcgagcaggccctggtggtccag300
cctcgcagcggcaacgatctgtccatcttcatgcgtcttctgggcctggccttcagccag360
agccaggggcacctgcggcgttatctggaagacatgtacggcaaggtcttccgccgctac420
atgctgctggtcaacgaagctgcgccgcgcatccctccgatcgaactgttctggcgtgtg480
cacttcatgctcggagcggcggcgttcagcatgtcggggatcaaggcgttgcgggcgatt540
gccgagaccgacttcggggtcaatacctcgatcgagcaggtaatgcgcctgatggtgcca600
ttcctcgcggccggcatgcgcgctgaaaccggcgtcaccgacgatgccatggctgcggcg660
caactcaagccgcgcagcaaatcgactccggcggtcgccaaggcctga708
<210>5
<211>1284
<212>dna
<213>pars基因
<400>5
atgctgcggctgtttctgggtttgtacattgtcctggccataggttttgccggggcgatc60
accgcggtcgatcacatcttcacggccatcctcgaagacccgctggaagcctacaaccgc120
gatgcggtgcgcgggccggcttatagcctggtggaacagttgcggccgttcgacagcgcc180
gagcgcgaacggcaattgcaggcgttgcagccgcattacggcttgcagttgcgtctggtg240
aacgccgacgcgctgggcctgagcgcccgcgaacaggccttgctggcctccaaccagttg300
gtggtgcggcaagcgttcaccgagtttatcgccagcatcgaccagggcccgcaattgctc360
agcatcaagttgccggaagagccctcgctgacccgcttctataccaccgcggcctatttt420
ctcctcgctacgctggtgggcatcgtcctgtatttctgggtgcgcccgcactggcgcgat480
ctggagcaactgcggctggcggccgaacggttcggcgacaacgacctgagtacgcgcctg540
cacctgtcgcggcgctcgaacattcgcgagctggccgagcacttcaaccgcatggccagc600
cgcatcgaaggcctgatcgccaatcagcgcgagctgaccaacgcggtgtcccatgagctg660
cgcacgcccatcgcccgcctgtcgttcgaactcgaccagctcaagcagtccgatccgaaa720
cacaaccgcgagctgatcgccgacatgtacgccgacctcggcgagctggaggaaatggtc780
tccgaactgctgacctatgccagcctggaacacggcgccacggtgatcaaccgcgagact840
atccaggcccacagctggctcgacagcgtggtcggcagtgtcgccctggaggcggaagcg900
gcgggggtacagatcctgatccgcgcctgcgaggtcgagtgcatcagcatcgagccgcgg960
ttcatggcgcgggcggtgatcaacctgctgcgcaacgccattcgctacgccgagcggcgc1020
gtcgaggtgtccctggtgcgggtcgggcagggttatgaagtccaggtcaacgacgacggc1080
ccgggcgtgccggtggaaggacgcaagaaaatcttcgagccgttctcccggctcgacgcc1140
agccgcgaccgccgcaccggcggcttcggccttggcctggcgctggtgcggcgggtgtcg1200
cagtcccacggcggccaggtcgaggtgacggattcgcagtggggcggcgcgtcgtttcgc1260
atgacctgggcgcaggtcgagtag1284
<210>6
<211>1302
<212>dna
<213>rpea基因
<400>6
atgctgagaatcctgattcgcctgtacctggtgaccatcgtctcgttcagcgcggcgatc60
tacctggtcccggagctggtggtgaaggtcttccacgagcgtttcatcacctacaacctg120
gactattcccggggcctgcaaagcctgatcgtcaaacagtttcgcggcgtacccgcagag180
cagtggccggccctggccgcggaaatggaccaggagttccagccgctgcacatcgtcctg240
acccgcaacgacgatgccgatttcaccctgtacgagcgcgaacgcctgcaacgcggcgag300
aacgtggtgcgggtcggcgactggggctggcgcaccctcgcggtggcgccgctggacgag360
cagatggcggtgcagatggtggtgccgccggacccgatcgacgtcagcctgctgtactgg420
agcatcaacgtgctgatcggcgcgaccatgcttgcctgcctgttgctctggctgcggccg480
cactggcgcgacctggaacgcctgaaacacgccgccgagcgcttcggcaagggccacttg540
agcgagcgcacgcagatcccctcgagctccaacatcggcagcctggccaatgtcttcgac600
accatggccggcgacatcgaaaacctgctgaaccagcaacgcgacctgctcaacgcggtg660
tcccacgagctgcgcacgcccttgacccggctcgacttcggcctggccctggcgctctcc720
gacgacctgccggcgaccagccgcgaacgcctgcaagggctggtggcgcacattcgcgag780
ctcgacgaactggtgctcgagctgctgtcctacagccggttgcagatcccggcgcagttg840
ccggagcaggtcgaggtgtcgctggacgagttcatcgacagcatcctcggcagcgtcgac900
gacgagctggaatccccggacatcgtcatcgatgtgttgctgctcggcagcctggagcgt960
ttcaccctcgatccgcggctgaccgcccgggcgatccagaacctgctgcgcaacgccatg1020
cgttattgcgaaaagcgcatcaaggtcggggtgcaggtcagcgacagcggctgtgaaatc1080
tgggtcgacgacgatggcatcggcattcccgacgatgagcgtgagcgggtgttcgaaccg1140
ttctaccgcctggaccgcagccgcgatcgcgccactggcggcttcggcctcggcctggcg1200
atcagccgccgggccctggaagcccagggcgggaccctgaccgtcgaggcctcgccgctg1260
ggcggcgcgcgtttccgcctgtggctgccgacgccggcctga1302
<210>7
<211>1452
<212>dna
<213>pykf基因
<400>7
atgtccgtccgtcgtaccaaaatcgtcgctacccttggcccggccagtaactcgccggaa60
gttctcgaacagctgattctggctggcctggacgtcgcccgcctgaacttctcccatggc120
accccggacgagcacaaggctcgcgccaagctggtgcgtgacctggccgccaagcatggc180
cgcttcgtcgcgctgctgggtgacctgcaaggcccgaagatccgtatcgccaaattcgcc240
aacaagcgcatcgagctgaagatcggtgacaagttcaccttctccaccagccacccgctg300
accgaaggtaaccaggacatcgtcggcatcgactatccggacctggtcaaggactgcggc360
gtgggcgacgagctgctgctcgacgacggccgcgtggtgatgcgcgtcgaaaccgccacc420
agcaccgaactgcattgcgtcgtgaccatcggcggcccgctgtcggaccacaagggcatc480
aaccgtcgcggtggcggcctgaccgccccggccctgaccgaaaaagacaaggccgacatc540
aagctggccgcggccatggacctggactacctggccgtgtccttcccgcgcgacgccgct600
gacatggaatatgcccgccaactgcgcgacgaagccggcggcaccgcctggctggtggcg660
aagatcgagcgcgccgaagccgtggccaacgacgaaaccctcgacggcctgatcaaggcc720
tccgacgccgtgatggtggcccgtggtgacctgggtgtggaaatcggcgacgccgagctg780
gtgggcatccagaagaaaatcattctgcacgcccgtcgccacaacaaggcggtgatcgtc840
gcgacccagatgatggagtcgatgatccagaacccgatgccaacccgcgccgaagtgtcc900
gacgtggccaacgccgtgctcgactacaccgacgccgtgatgctctcggccgaatccgcc960
gccggcgcctacccgctcgaagcggtccaggccatggcgcgtatctgcatcggcgcggaa1020
aaacacccgaccagcaagacctccagccaccgcatcggcaagaccttcgagcgctgcgac1080
gagagcattgccctggccaccatgtacaccgccaaccacttcccgggcgttaaagcgatc1140
atcgccttgactgaaagcggctacaccccgctgatcatgtcgcgtatccgctcctcggtg1200
ccgatctacgcgttcaccccgcaccgcgaagcccaggcccgcaccgcgatgttccgtggc1260
gtctacaccatcccgttcgacccggcatccctgccgccaagcgaagtcagccagaaggcc1320
atcgacgagctggtcaagcgcggcgtcgtggagaaaggcgactgggtgatcctgaccaag1380
ggcgacagctaccacaccaccggcggcaccaacggcatgaagatcctgcacgttggcgac1440
ccgatggtctga1452
<210>8
<211>36
<212>dna
<213>phzo-f1
<400>8
gttgaattcacacgcatcgtggtgatcagtgagatc36
<210>9
<211>32
<212>dna
<213>phzo-r1
<400>9
ctagcatggtagcagcctcagtaatgtctgac32
<210>10
<211>32
<212>dna
<213>phzo-f2
<400>10
tgctaccatgctagacctgattgccgtgtagg32
<210>11
<211>31
<212>dna
<213>phzo-r2
<400>11
taggatccgtcagcaccgcttgcatggcaat31
<210>12
<211>1498
<212>dna
<213>phzo基因上下游融合片段
<400>12
acacgcatcgtggtgatcagtgagatcagtgacaccggggtagtgttcagcacccatgcc60
ggaagccagaaaggtcgcgaactgacagaaaacccctgggcctcggggacgctgtattgg120
cgcgaaaccagccagcagatcatcctcaatggccaggccgtgcgcatgccggatgccaag180
gctgacgaggcctggttgaagcgcccttatgccacgcatccgatgtcatcggcgtctcgc240
cagagtgaagagctcacggatgtcgaggccctgcgcaacgccgccagggaactggccgag300
gttccaggtccgctgccgcgtcccgagggttattgcgtgtttgagttgcggcttgaatcg360
ctggagttctggggtaacggccaggatcgcctgcatgaacgcttgcgctatgaccgcagc420
gctgaaggctggaaacatcgccgattacagccgtagggtaccgagataaatatgctttga480
agtgctggctgctccaacttcgaactcattgcgcgaacttcaacacttatgacacccggt540
caacatgagaagagtccagatgcgaaagaacgcgtattcgaaataccaaacagagagtcc600
ggatcaccaaagtgtgtaacgacattaattcctatctgaatcttatagttgctctagaac660
gttgtccttgacccagcgatagacatcgggccaaagactacacaaacaaagtcagacatt720
actgaggctgctaccatgctagacctgattgccgtgtaggcgccgcgcaacccttcattc780
gtgccgactgaactcggcacgaatgaagggttgtccgcctccggcccctggcatcccgta840
agtttccaaccttcaacggtagtacaccgccccattagcatccaaatgaatacagcagga900
gcccgttacagcgctggcgctggatgcctggctacgcttgcatgggatctcggtccgaga960
cgagccaggtttaccggccccccctttgttcgagccatgccacttggcaggctcgttcag1020
tcgtagcggtcagcctgtcgccggttggcttgccacccgccacctccaggccagcgtctg1080
gcatcgggccttgcccggaagcgccagccatatcggcaccgtagcgatcaacgaaaggct1140
cagcatgggcccgttcactgctgtacattcctccccacggacgacacatcatttacccag1200
tgaacggagttcaacgcgtgttctcgaccctcaatccgcgtcaccgccggcttgccagtt1260
tctcgctgatagccgtcgccctcagcctcgccgcctgcaacgcttccgccccctcccaca1320
ccgccctgccccccgccccggaaatcgcttcgggttatcgcaccgacctgcaagtgcagc1380
gcgccgaccagcatatggcggccgcggccaacccgttggcggccgaagccgggcgcgaga1440
tgttgcgcaagggcggttcggccatcgatgcggcgattgccatgcaagcggtgctgac1498
<210>13
<211>29
<212>dna
<213>lon-f1
<400>13
cgtctagaagcacgaacagctcgctgcca29
<210>14
<211>24
<212>dna
<213>lon-r1
<400>14
tcgctcatggggcacctgcgcaat24
<210>15
<211>28
<212>dna
<213>lon-f2
<400>15
cccatgagcgaacgcagacctgtaggag28
<210>16
<211>34
<212>dna
<213>lon-r2
<400>16
ctaagcttagaacaacaggccgaggctgatccag34
<210>17
<211>1493
<212>dna
<213>lon基因上下游融合片段
<400>17
agcacgaacagctcgctgccacgggtgccagtgccatgctggcgcagcgcctcgagaatc60
tgctgcgagtcgccgctgatcaccgcctggcgaaactgcgcatccaccaccagccagtcc120
acgccataacgcaagcgccggccgcgcagttcgagcaggcgttcgaagacccgggtgccg180
gtttgcagttgcacttgcgcctggttttccactgcatggttggtcgcggccttgacggcg240
aagtacaccaccccgatcacgatcaacagcaacaacgccaataccccagtgatccttacc300
tggaacgtatggcgccacttcatgagccggctctcgtcgccgcgacctcactgttgtcga360
ctctgcacacccacggcgacacccgccgctccccgctgaaaagtcccttgatcattacgc420
gtccctctgggcagctaaagatgcgtcaaataaatgccatttccctgacagcatttaatc480
ggtccagattagaccgccaagacaagaagatcacgcaataaaatcagggggtttacaatg540
tcatttttctgtcgccgccaatttaccagcgttcctgcgcagaaatgacagcctcgccct600
cgccgttttggaggatgcaccgcgtcgcggcgacaaggactgaaataattgatccggccc660
gcccgccattgaaaccgctcgtcacctgccccatctaacctggcataccccattgcgcag720
gtgccccatgagcgaacgcagacctgtaggagcggagcttgctcgcgatagccgcacagc780
ggcggtgtatccgccgcccagcgctatccttgatggcttatcgcgagcaagctcgctcct840
acaacgtctcgcctaccccaccacagattcccccatcttcggttatgctcgccctttgtc900
atgaccggagctttctgacccatgtcaccgattcgtctgttgctacccctcagccttgcc960
ctgctcgccgcctgcgccagccaacccaagcaaaacgtcacggtcgagaaccagagcgaa1020
tgcccagtgcaactgagcaacgggcaaaacctgatcctgaccctgccgagcaacccgacc1080
acgggttatcgctgggcgatccaggactcggccggcggcgtgctgcgcaaagtcagcccc1140
gaggtctacagcaatcccgaagacagcggcctggtgggcagcgccggccagtccacctgg1200
cgcttccaggccttcgccgccggcaccgggcgcctgttgctgacctatcagcaaccctgg1260
gccccggaagtcgcaccggtgaaagccttcgactgcgccatttcggtcaagtgacatggg1320
ctggctgatcctggcgctgatgggcgcggcgaccttcctctacggcctgagcatccacgc1380
caccctgctgtgcttgctggtcaagccgctgccggtgctggccctgctcggctggctgca1440
cgatgcgccccccggcgactatcgccgctggatcagcctcggcctgttgttct1493
<210>18
<211>35
<212>dna
<213>rsme-f1
<400>18
aactctagatcaacctgaaggcctgcggctgattc35
<210>19
<211>33
<212>dna
<213>rsme-r2
<400>19
catgatcttctccttgattgctttgtagggcac33
<210>20
<211>31
<212>dna
<213>rsme-f2
<400>20
tcaaggagaagatcatggcgtcatgagcggc31
<210>21
<211>32
<212>dna
<213>rsme-r2
<400>21
agaagcttaggcgctgttgatcgtgctgctgg32
<210>22
<211>1514
<212>dna
<213>rsme基因上下游融合片段
<400>22
tcaacctgaaggcctgcggctgattccgtccggattaccgataaacacctggggcatgga60
cagccccttcaagatgactgagcgccgaccaggccggtcgctcaacgtcgctgcgacgac120
ctggcctggcactcagaagaacggcttactgcgcgacgcggtgctcgatcacttgcggtt180
cgatattgcgcttcttggccttggtcagcttttcgaccagctcggttttcttggcttcgg240
cttcggcctgggaatcgaacgggccgatcagcacccgatccttgccctcttcgacgacga300
cataggaaacgatcccgtgctcgatcagccagccagccagatcgctcgtcgcctgaggca360
gggtgccggcgaccagcacatcccattgcggtttcgtggcggcctgcggcggctgtgcct420
ggacgaccggcgccaccttcttgtcgacctcgaccttcttgccctcaccgcatcccgcca480
atgccaggaccgccatcatcatcgctactgtgcgcacaacctaccccttgaaagtctgag540
gcggcgattttagcaccccaatcccctgcgcaaacgccacaaaatcagcgcaaaacaagg600
agaatgatatttatcgcctctgtatagttgcagctcgggaattaataccgcgtctgcgcg660
tcagaaagaggcacccacacagtggtacttcgcagtaatctatacgcactactaccgaca720
tctgcactgtctgaatcaggtgccctacaaagcaatcaaggagaagatcatggcgtcatg780
agcggccagccctttgtctcatcacaatggctggcgcagcgtcgtcgttgattgattccc840
ccgcagcacactcccctcttcaaatggcagcggcgcagttcaggccgccagcgccagccc900
tggcaaagtgcgttacccaagccctccaccgatagcgctccatcccggcaatctgtcgat960
acgactcggccgggagaaagccctccctcgtttttgtataaatactcagtagcgtggcaa1020
cgagcaggaggagtaatttcaagacctaccgcctccgcgagcctgccgaggctccccctt1080
gccaccggcagacgctttacgaacaaggagcggtcaatgcaagagttcgcttaccttctg1140
atcaccaacgacctgaatgcaatgcgcaccattgccgcctgctcgacggaggggctctac1200
gaagtcaaacgcggaatattcaccttccgctcccaggccaacgtcgactacctgcaccgt1260
gcgctggccatcgtcagcgacgagttcggcatcattcctgtgcagcaggccgagttcaaa1320
accaaccgggccaccatcagcaaggctttcagccaactctgctagcgcgcgcggcgctcg1380
gtgatgcacaacaacccacatcgagccaaagcacactcgactcgctgctccttcctcacc1440
tcatggctggctgaacatgaccccacgcgccatgccgctggccgccaccaccagcagcac1500
gatcaacagcgcct1514
<210>23
<211>28
<212>dna
<213>psra-f1
<400>23
gcggattcgtttcacggtgacttcgtcg28
<210>24
<211>25
<212>dna
<213>psra-r1
<400>24
gtttccgactgggccatggctactc25
<210>25
<211>32
<212>dna
<213>psra-f2
<400>25
atggcccagtcggaaacaaggcctgaccgtcc32
<210>26
<211>31
<212>dna
<213>psra-r2
<400>26
tcaagctttcgtcgttggggatcgccacgtg31
<210>27
<211>1505
<212>dna
<213>psra基因上下游融合片段
<400>27
gtttcacggtgacttcgtcgccaatgcgggcgacgacgacctggccattgcgggcctcgc60
gagtggtgtgcaccgccagcaggtcgccatcgaagatgccgatgtccttcatgctcatgc120
cgtgaacccgcagcaggtagtccgcgcgtggatggaagaaggccgggttgatattgcagg180
actcttcgatgtgctgctcggcgaggatcggcgcgccggcggcaacccggccgatgatgg240
gcaggctggagtcgtcgggcttggcttcgaaccccgggatgcgaatgccgcgggaggcgc300
ctggagtcatttcgatcgcacccttgcgggccagcgccttgaggtgttcttcggcggcgt360
tgggcgacttgaaacccagttcctgggcgatttccgcgcgggtcggtgggtagccgttgt420
cttcgaggcaacgtttgataaaagccagaatctcagcttggcgtggcgtcagttttagca480
tatcgatcgctctgtctttttatacagtgactggaattatatacagtgaatggcgcttgg540
caatcctcctttttccagtcgccgctggacggtcgggtcgccgctgcgcatgcctggtgt600
cgcgtggctggctacaggacgcggcaggtatggttaaatagctgactgaccggccgcaaa660
acggacaggcaggcttgacaagactggggctgaaacgtatgtttcaaacaagtgtttgtc720
aggcggagtagccatggcccagtcggaaacaaggcctgaccgtccgggtgggcgcggcag780
cttacatccgctaagctagccgcccatgtcgactctcgtttcctacctcctttcacatct840
ttcgccgatcgtcgcttgccgggctttgccgccggcaatggactcgtgcgtccgcgccac900
gccagcaccctttgcgatgccgtgcgcgcacttcgttactaaggaattgctatgaccaca960
ggcctgcaaggctccttgatggtggatgtcgccggtacctggctgacagctgaagatcgc1020
cagctcctgcgccagcccgaagtgggtgggttgatcatctttgcccgcaatatcgagcat1080
ccgcggcaggtgcgtgagttgagcgcgtccattcgggcgattcgcccggacctgctgctg1140
gcggtggaccaggagggcggtcgcgtgcagcgcctgcgccagggcttcgtgcggctgccg1200
gccatgcgtgccatcgccgacaacccgaatgccgaatacctggccgagcagtgcggctgg1260
atcatggccaccgaagtgctggccgtcggcctggacctgagcttcgcgccggtgctggac1320
ctcgatcatcagcgcagcgctgtggtgggtactcgttccttcgagggcgaccccgagcgc1380
gccgcgttgctggcgggtgcctttatccgtggcatgaacagtgccggcatggcggccacg1440
ggcaagcatttccccgggcacggctgggccgaggcggactcccacgtggcgatccccaac1500
gacga1505
<210>28
<211>37
<212>dna
<213>pars-f1
<400>28
ttggattccccaattgtgcgcactcagactggtattt37
<210>29
<211>26
<212>dna
<213>pars-r1
<400>29
atctagagctcccacgcgaacggatt26
<210>30
<211>36
<212>dna
<213>pars-f2
<400>30
gtgggagctctagattcgaggtgacggattcgcagt36
<210>31
<211>33
<212>dna
<213>pars-r2
<400>31
aaaagcttgcaaggaccgcaagagcggctacaa33
<210>32
<211>1527
<212>dna
<213>pars基因上下游融合片段
<400>32
cccaattgtgcgcactcagactggtatttatggataacccgggtcttggcaaagtattgc60
tggtggaagatgacgagaagctcgccgggctgatcgcgcacttcctgtcccaacacggtt120
tcgaggtcctgacggtacatcgtggcgatgtggcgctggcggcctttctcgagttcaagc180
cgaaaatcgtcgtcctcgacctgatgctgccgggccagagcggcctgcacgtgtgccggg240
agatccgcaacgtggcggacacgcccatcgtcatcctcaccgccaaggaagacgacctgg300
accatatcctgggcctggagtccggcgccgacgactacgtgatcaagccgatcaagccag360
cggtgctgctggcccgcctgcgcgccctgcaacggcgccagttgccggagccgacggtgc420
gcggcgcgctggaattcggccgcctgaccctcgaccgcagttgccgcgaagtgcgcctgg480
ccggcgagccgatcgagctgaccaccatggagttcgagctgctgtggctgctggccagtt540
cggcgggcaagatcctctcccgcgacgacatcctcaaccgcatgcgcggcatcgccttcg600
acggcctcaaccgcagcgtcgatgtctacatcagcaagctgcgcggcaaactccaggaca660
accctcgcgagccggtgtgcatcaagaccatctggggcaagggctatctgttcaatccgt720
tcgcgtgggagctctagattcgaggtgacggattcgcagtggggcggcgcgtcgtttcgc780
atgacctgggcgcaggtcgagtagccccggcccataggcacatacccgcggaattgcgca840
tgcttctgtaggagcgcagcttgcgcgcgatgaacgataacgcggtggatcaggcggtcc900
gcgtcgtggtcatcgcgggcaagcctcgctcctacagaagcacgcggttctgtaggagcg960
agcgggcggcgatccgacttgcccgcgatagcgtcagaacggccaacgccgcttagaagc1020
tgtactccagggtcgtcgccagcgacgtctgcagccgccgctcgacaatcgggctgtccg1080
ccgcttcccggcccaggtactgcagcgccagtaccgtcgacacgttcatctgttcgctga1140
ccggcactgtccaggtcaggtcgccgccccggctgagaaagccgcccttggggcgatagg1200
ctgcgaaacgggtcctgccggcctgggccgtgctgacgccataccaggtgtgcaggtagt1260
cgccgtcgccgaactggctgttgaggctgccttcgaggcggccgtagcggccttcataca1320
gcgtgctgccaatgctcagttgcaggtggttgtaggccgagccggtgtccgggtcgtcat1380
tcttcttcagcgcatgctgcagcgtggccccgagctccacggtgcccagggtgtagccca1440
ggtgggcgccgaactgcgcgcgggacttgatcgagcccatgccggccagatggtccgaac1500
ccttgtagccgctcttgcggtccttgc1527
<210>33
<211>33
<212>dna
<213>rpea-f1
<400>33
ccaagcttactcaaagacgctcattcccatgcc33
<210>34
<211>30
<212>dna
<213>rpea-f2
<400>34
caggattctcagcatcgactcagcattccc30
<210>35
<211>30
<212>dna
<213>rpea-r1
<400>35
actcagcattccctgagccatgccgggcat30
<210>36
<211>31
<212>dna
<213>rpea-r2
<400>36
aaatctagaccgtcgctcacgcaaggcgctg31
<210>37
<211>1443
<212>dna
<213>rpea基因上下游融合片段
<400>37
actcaaagacgctcattcccatgcccaacattcttctggtcgaagacgaccccgcgctct60
ctgaactgatcgccagttacctggagcgcaacggctatcaggtcaatgtcatcagccgcg120
gcgaccaggtgcgtgaacgggcgcgggtcaatccgccggacctggtgattctcgacctga180
tgctgccgggcctggacggcctgcaggtctgccgcctgctgcgggccgactcggcgtcgc240
tgccgatcctgatgctgaccgcccgtgatgatagccacgatcaggtgctgggtctggaaa300
tgggcgccgacgattatgtgacaaaaccgtgcgaaccgcgcgtgctgctggcgcgggtgc360
gtaccctgttgcgccgcagcagcctcggcgagccgcagaccgccagcgaccggatcctca420
tgggcaacctgtgcatcgacctgtcggagcgcaccgtgagctggcgcgatcaattggtgg480
aactgtccagcggcgagtacaacctgctggtggtgctggcccggcatgccggcgaggtgc540
tgagccgcgaccagatcctgcaacgcctgcggggcatcgagttcaacggcaccgaccgct600
cggtggacgtggcgatttccaagctgcggcgcaagttcgacgaccacgccggcgaggcgc660
gcaagatcaagaccgtatggggcaagggctacctgttcagccgttccgaatgggaatgct720
gagtcgatgctgagaatcctgtgagccatgccgggcatccccagcgacgggaaggcccgg780
cagtcggcgttatggaagaggctgcatcagcacagcgcggtcggctgtagctcgctggcc840
ttgatcaggttcacgcctgccgcgcgcatctgccgggtggccttgtccagcgagccgtcc900
atgtcgatggcccggcaggcatcgacgatcacgaaggtattgaagcccgccgcccgcgca960
tccagcgccgaccaggccacgcagtagtccagggccagccccaccagatacaccgtgtcg1020
atgccgcgctggctcaggtagccggccaggccggtcgtggtgctgcggtccgcctcgacg1080
aaggccgagtaactgtcgatatccggattgcaacccttgcgcaggatcagctgggcatgg1140
ggcaggttgagtttcgggtgcagttcggcgccacggctggcctgcacgcaatggtccggc1200
cagagcacctgcgggccatagggcagctggatgatgtcgttcggcgcgtggccttcgtgg1260
ctggaggcgaacgagatatgcccggccgggtgccagtcctgggcgatcaccacctgcttg1320
aagtggccgcccaggcgattgatcaagggcacgatctggtcgccccccggcaccgccagc1380
gcgccgccggggatgaagtcgttctgtacgtcgatgaccagcagcgccttgcgtgagcga1440
cgg1443
<210>38
<211>31
<212>dna
<213>pykf-f1
<400>38
cacgaattcatcggtcagccgattgaacact31
<210>39
<211>29
<212>dna
<213>pykf-r1
<400>39
acggacggacatgcaaagactcctgagtt29
<210>40
<211>29
<212>dna
<213>pykf-f2
<400>40
ttgcatgtccgtccgtatggtctgagtcc29
<210>41
<211>34
<212>dna
<213>pykf-r2
<400>41
aagtctagacaacgacattgccgacttcctccag34
<210>42
<211>1522
<212>dna
<213>pykf基因上下游融合片段
<400>42
atcggtcagccgattgaacactttcaaaaaacacggcaactggtgccgctcgatccgccg60
gtccgtgaacatgtcatgcatcgctattcaagaaggtcattcaacatcgtcgcgccgagg120
actgtcggccccggtcggcccattttagaaacaatactctaaaacaggctcacagatgtt180
agctcaaggctcatgcgggatcagcaatagcctgatgacgattgttacaacgcggtcgga240
cgcgcttgagcgctgccgcgcgaagggaaatgccccagttgctgcagggtttccaggcgc300
gcgcgggcgcggtaggcgtattcgctgttggggtgctcggtgatgatgtactgataggtc360
tgcgccgcatcgaggaacagcttctgccgctccaggcactgtccgcgcagcatcgatacc420
tcgggctggatataagggcgcgagcgactcgtgcggtcgacctggctcagttcgagtatc480
acccgttcgcagttgccggcgtcataggcgcggtaggcggtattcagatgatggtccatc540
gaccagcgggtacagccgacaacactgacggccagggcagcaatgagcacgaatcgcatg600
ggggttctcctgtcttgtgcacgttatcgacccgcgttggaaaatcttcaggaatgttcg660
tttaaagaaacaaacgaataagtagtgcaaacgaacaatgactacagctgcggaccatag720
tagcctctcgttgcgcttgaactcaggagtctttgcatgtccgtccgtatggtctgagtc780
cccctgatgcaacaataaaaagccccgcagtgaagactgcggggcttttttatggatcct840
gcgaacctgtaggagcaagcgggcggcgatccgacttgcccgcgatagctacaccgcggt900
ccaccagaaacaacgcgttgcccgcgatcgcgagcaagcttcgttcctacaaggctggaa960
tcagcccttggcaagaaaccccgacaaggcagccagtgcttccggcgaatgcaggcgctg1020
ggtgaacagggtgccctcctcctcgatcaccttgcgcagttgttcgcgatcgggcgtgcg1080
catcagctgcttgctgatctgcaccgcctgcggcgccagcttctcgaaacgcagcgccat1140
ctcccgggccttgtccagggtcgccacgccatcggccaaggccaggttggcaatgcccca1200
ctgcgccgcctgttcaccgctgaaaccttcgcccagcagcaacagctccgcggctctggc1260
cggcccgagcaggcgcggcaggatcaggctggaaccgaactccgggcacaagccgagatt1320
gacaaaaggcatgcgcaagcgggcatcgcggctgacgtacaccaggtcgcaatgcagcaa1380
cagggtggtgccgatccccacggccgggcccgcgaccgcggcgaccaccggcttgcggca1440
ttcgaacaggctgcgcatgaactggaagaccgggctgtcgagcccgctgggcggctgctg1500
gaggaagtcggcaatgtcgttg1522
- 还没有人留言评论。精彩留言会获得点赞!
- 大豆低温诱导人工合成启动子SP5及应用的制造方法与工艺
- 一种来源于虎眼万年青的尿苷-5’-二磷酸半乳糖差向异构酶,其核苷酸序列及应用的制造方法与工艺
- 一种来源于虎眼万年青的尿苷-5’-二磷酸木糖差向异构酶,其核苷酸序列及应用的制造方法与工艺
- 新的赖氨酸脱羧酶突变体及其应用的制造方法与工艺
- 一种嗜热中性蛋白酶基因、工程菌、酶及其应用的制造方法与工艺
- 一种碱性耐盐普鲁兰酶PulA及其基因和应用的制造方法与工艺
- 一种热稳定性提高的β‑淀粉酶突变体的制造方法与工艺
- 一类耐热型植酸酶突变体及其编码基因和应用的制造方法与工艺
- 含CCL5和SSTR2基因的重组痘病毒及其制备方法与流程
- 一种催化黄酮类化合物葡萄糖苷化的基因工程菌及其应用的制造方法与工艺