测量核酸修饰酶活性的测定的制作方法
测量核酸修饰酶活性的测定
1.相关申请的交叉引用
2.本技术要求于2019年10月15日提交的新加坡临时申请号10201909632p的优先权的权益,其内容以全文引用的方式并入本文以用于所有目的。
技术领域
3.本发明涉及生物技术领域,特别是适用于测量酶活性的多重化测定(multiplex assay)的开发。
背景技术:
4.核酸修饰酶,如锌指核酸酶(zfn)、转录激活因子样效应物核酸酶(talen)和成簇的规律间隔的短回文重复序列(crispr)相关核酸酶已成为生物医学研究和生物技术行业中极有用的工具。作为治疗方式,这些核酸修饰酶可以通过直接修饰dna或rna来治疗以前无法治愈的遗传疾病。为了实现核酸修饰酶的巨大工业和医学潜力,必须解决天然存在的组分的局限性。这些局限性包括靶向效率、靶向特异性、免疫原性以及与递送载体和赋予功能的蛋白质融合部分的相容性问题。为了解决这些局限性,必须在称为蛋白质工程化的过程中对酶进行修饰并测定酶活性。通过改变蛋白质氨基酸序列或将赋予功能的蛋白质结构域融合/共定位到cas蛋白或crispr复合物上,诸如crispr-cas的酶也可以被工程化为具有增强的功能性(例如,对其靶标更特异,靶向方面更有效)和/或具有新功能(例如,碱基编辑、免疫规避、表观遗传修饰)。
5.工程化酶的常规方法始于(i)设计和创建编码许多不同酶序列(与天然存在的野生型相比具有氨基酸变化)的dna变体的文库,(ii)在隔室中,例如在细胞中或体外表达这些变体;(iii)通过下游生化反应或细胞表型测量酶活性或关联酶活性,然后进行“筛选”(其中不施加选择压力来分离活性变体和无活性变体)或“选择”(其中施加选择压力以分离活性变体和无活性变体)。蛋白质工程化,特别是像crispr-cas这样的可编程核酸内切酶,主要是通过后一种“选择”方法进行的。这种方法以二元方式偏向活性变体(细胞在表达蛋白质的活性形式时存活,而在表达蛋白质的无活性形式时死亡;也称为正选择),而不提供蛋白质活性程度的信息(例如,不区分高活性蛋白质与一半活性的蛋白质),也不考虑/提供有关无活性蛋白质变体的信息。也可以进行阴性选择(negative selection),借此仅保留和鉴定无活性变体而耗竭活性变体,并且不直接测量。在这两种情况下,活性测试都与文库成员的富集/耗竭有关并通过文库成员的富集/耗竭表现。该“筛选”方法不可扩展,因为维持和测量活性变体和无活性变体所需的资源增加。因此,核酸修饰酶如crispr-cas蛋白的工程化和测定在可测试变体的数量和每个变体可能的突变数量方面都受到限制。虽然crispr-cas蛋白可以被工程化为更好、更快、更安全地将多个氨基酸取代工程化到蛋白质中,但目前的方法不允许探索这个功能空间。
6.因此,需要一种高通量筛选技术来检测和鉴定数百万到数十亿并且超过候选酶文库的功能变体,而这些功能变体仍然可以准确且有效地识别、裂解或修饰其核酸靶标。这类
技术将能够筛选和工程化新型核酸修饰酶,以及筛选和优化影响酶活性的其他因素,例如向导rna和靶序列。因此,本发明的目的是提供一种解决上述需要的改进的方法。
7.发明概述
8.在一个方面,本公开涉及一种包括以下步骤的方法:
9.a)将多个多核苷酸构建体分隔到隔室中,其中每个隔室包含单个多核苷酸构建体,其中每个多核苷酸构建体包含
10.i)可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列;和
11.ii)包含dna靶标或编码rna靶标的dna模板的第二多核苷酸序列,其中当所述第二多核苷酸序列包含编码rna靶标的dna模板时,所述rna靶标与所述核酸修饰酶作为单个rna转录物被所述第一启动子驱动而连续共表达;
12.并且其中所述多个多核苷酸构建体编码所述核酸修饰酶的不同变体,和/或不同的dna或rna靶标;
13.b)使所述隔室经受允许rna和蛋白质的体外表达的条件;
14.c)使多个所述隔室经受允许通过对dna或rna靶标具有修饰活性的核酸修饰酶修饰所述dna/rna靶标的条件,从而产生包含以下中的一个或多个的dna/rna分子群体:
15.i.已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段;
16.ii.未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物;
17.d)收获步骤(c)中产生的所述dna/rna分子群体,并对其进行单分子测序;
18.e)基于测序结果对步骤c)i和c)ii中提到的dna/rna分子进行检测和计数。
19.在另一方面,本公开涉及一种包括以下步骤的方法:
20.a)将多个多核苷酸构建体分隔到隔室中,其中每个隔室包含单个多核苷酸构建体,其中每个多核苷酸构建体包含:
21.i)可操作地连接至第一启动子的编码向导rna(grna)的第一多核苷酸序列;
22.ii)包含dna靶标或编码rna靶标的dna模板的第二多核苷酸序列,其中当所述第二多核苷酸序列包含编码rna靶标的dna模板时,所述rna靶标与所述grna作为单个rna转录物被所述第一启动子驱动而连续共表达;
23.其中所述多个多核苷酸构建体编码不同的grna,和/或不同的dna或rna靶标;并且其中每个隔室还包含rna引导的核酸修饰酶或其变体或编码其的核苷酸模板;
24.b)使所述隔室经受允许rna和蛋白质的体外转录和/或翻译的条件;
25.c)使所述隔室经受允许通过对dna或rna靶标具有功能活性的rna引导的核酸修饰酶在grna存在下修饰所述dna和/或rna靶标的条件,从而产生包含以下中的一个或多个的dna/rna分子群体:
26.i.已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段;
27.ii.未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物;
28.d)收获步骤(c)中产生的所述dna/rna分子群体,并对其进行单分子长读段测序;
29.e)基于测序结果对步骤c)i和/或c)ii中提到的dna/rna分子进行检测和计数。
30.在另一方面,本公开涉及一种多核苷酸构建体,其包含:可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列;和包含dna靶标的第二多核苷酸序列。
england biolabs purexpress#e6800)在冰上混合以产生75μlivtt水性混合物。在2分钟内将50μl的该水性混合物分5份10μl添加到冰上的油表面活性剂混合物中,同时将搅拌棒以1150rpm旋转以产生乳液混合物。让乳液混合物在冰上继续混合另外的一分钟。在一个实施例中,然后对乳液混合物进行均质化(8000rpm持续3分钟;ika ultraturrax t10均质器)以产生乳液液滴尺寸的单分散性更高的分布。将剩余的25μl水性混合物保持在冰上以进行大体积ivtt反应,作为对照。对sp dcas9构建体也重复了此操作。然后将乳液和大体积ivtt混合物在37℃孵育4小时以进行ivtt,然后在65℃孵育15分钟以使蛋白质失活。然后单独纯化来自所有ivtt反应的dna,并在琼脂糖凝胶上通过凝胶电泳进行尺寸分离后观察等分试样。该数据表明,ivtt试剂在大体积反应和乳液液滴中都成功地转录和翻译蛋白质。
43.图5.来自乳液ivtt自裂解测定的纳米孔测序读段,其中使用高输入浓度的sp cas9构建体。该子文库中的一个小的读段子集被映射到sp dcas9,因此在图表(plot)上归类为错误分配(浅灰色部分;图5),因为只有sp cas9 dna被提供为该乳液ivtt反应的输入。sp cas9乳液ivtt纳米孔测序读段显示检测到的裂解和未裂解的构建体片段(分别为白色和黑色部分;图5)的混合物。因此,该数据表明,纳米孔单分子测序可以检测来自乳液ivtt反应的修饰和未修饰的多核苷酸构建体(具有酶活性或无活性的产物)。
44.图6.来自乳液ivtt自裂解测定的纳米孔测序读数,其中使用高输入浓度的sp dcas9构建体。未能通过比对质量过滤器的读段被相应地归类。sp dcas9乳液ivtt纳米孔测序读段绝大多数显示为未裂解的构建体片段,正如预期的那样(带条纹的灰色部分;图6)。该子文库中的一个小的读段子集被映射到sp cas9,因此在图表上归类为错误分配(浅灰色部分;图6),因为只有sp dcas9 dna被提供为该乳液ivtt反应的输入。该结果支持该方法的稳健性,因为sp dcas9的失活通过测序读段被准确地检测和测量。
45.图7.描绘了用于大体积ivtt和自裂解测定时程实验与纳米孔测序结果的读出的示例性工作流程的图表。在本实例中,对于不同的crispr-cas构建体(例如sp cas9、sa cas9、as cpf1、lb cpf1),在冰上建立大体积ivtt反应,这些构建体的组分排列都与对上述核酸模板序列所描述的相似。然后对于每个时间点将它们平均分成5个相应的等分试样(图7第1部分)。然后将这些大体积ivtt等分试样在37℃孵育,并在每个指定的时间点取出,用edta抑制剂和酶猝灭,以停止ivtt反应和编码dna构建体的cas裂解(图7第2部分)。然后使用spriselect珠净化处理猝灭的ivtt反应体系以纯化dna片段(图7第3部分)。然后在琼脂糖凝胶上通过凝胶电泳进行尺寸分选后观察来自不同ivtt时间点的不同cas直系同源物的这些dna片段的小等分试样,如以下图8所示。然后将剩余的纯化的dna片段的等分试样按它们各自的时间点汇集,但不考虑cas种类,即在每个时间点将sp cas9、sa cas9等的dna片段混合在一起,并使用ont exp-nbd104 pcr-free无扩增条形码扩展试剂盒单独进行条形码化(图7第4部分),以将这些汇集的子文库多重化以供单纳米孔测序运行之用(图7第5部分)。然后对纳米孔测序结果进行质量过滤,并使用公开可用的生物信息学工具,然后使用本文中公开的分析方法进行分析。
46.图8.来自图7第3部分所示的步骤之后的大体积ivtt反应的不同crispr-cas直系同源物的纯化的ivtt构建体的凝胶可视化。该数据表明不同的cas蛋白(变体或直系同源物)在大体积反应中被成功转录和翻译。
47.图9.通过来自大体积ivtt和自裂解测定时程实验的纳米孔测序检测到的cas编码
dna片段的图表。该数据表明,单分子测序可以以多重化方式检测酶产物并测量不同核酸修饰酶的酶活性。
48.图10.来自大体积ivtt反应的纯化的ivtt sp cas9和dcas9 dna构建体的凝胶可视化。将500ng的sp cas9(序列如上文所描绘)与ivtt试剂(new england biolabs purexpress#e6800)在冰上混合以产生50μl ivtt水性混合物。对sp dcas9构建体也进行了同样的操作;sp dcas9构建体包含与sp cas9构建体的dna序列基本相同的dna序列,不同之处在于sp cas9基因中的2个失活突变(d10a和h840a)而产生sp dcas9基因。将这些50μl大体积ivtt反应在37℃孵育4小时以进行ivtt,然后在65℃孵育15分钟以使蛋白质失活。将20mm edta(ph 8.0)抑制剂与rnase混合物和蛋白酶k添加到大体积ivtt反应中,在37℃持续30分钟,以从ivtt反应中去除多余的rna和蛋白质。然后使用spriselect顺磁珠单独纯化来自这两个大体积ivtt反应的dna(多核苷酸构建体),然后在琼脂糖凝胶上通过凝胶电泳进行尺寸分选后观察dna的等分试样。该数据表明cas蛋白在大体积ivtt反应中被成功转录和翻译。
49.图11.对已被核酸修饰酶修饰或未被修饰的多核苷酸进行直接检测和计数的图示。从大体积ivtt反应中纯化的sp cas9和sp dcas9 dna构建体(其凝胶可视化描绘于图10中)以不同的比率混合在一起。然后准备这些纯化的dna构建体的混合物用于纳米孔测序。通过将所有纳米孔测序读段与sp dcas9构建体参考序列比对,使用测序数据分析领域的普通技术人员可以进行的生物信息学工具检测裂解的sp cas9读段的存在。该工作流程能够检测与参考序列比对的测序读段中的变异(indel-插入和缺失或snp-单核苷酸多态性);特别关注snp的检测,这些snp代表了在其他方面相同的sp dcas9和sp cas9构建体之间的预期序列差异,即相对于sp cas9,sp dcas9中的d10a和h840a催化失活突变。如图3所示,通过针对sp dcas9参考序列的序列映射将对齐的原始纳米孔测序读段归类为裂解与未裂解,然后进行snp检测,snp导致氨基酸残基变化。将每个过滤的对齐读段上的sp cas9序列翻译成其相应的氨基酸序列,并对检测到的导致与sp dcas9参考氨基酸序列的氨基酸变化的snp计数。在以上图表中,检测到的snp在热图中显示在相对于sp dcas9参考物包含sp dcas9中的d10a和h840a催化失活突变的选定目的区域。被分类为裂解的读段(左侧的2个子图;图11)富含对应于具有d10和h840残基的snp(热图中的深灰色方块;图11),即这些裂解的读段包含催化上有活性的sp cas9序列。以上图表中显示的其他检测到的导致氨基酸突变并在热图中具有灰色更浅的方块的snp是假阳性的,这是由当前可用的纳米孔测序技术中固有的原始测序错误引起的。该数据阐明了裂解和未裂解的sp cas9 dna片段的检测,裂解和未裂解的sp cas9 dna片段可以通过在原始纳米孔测序数据中检测未裂解的sp dcas9 dna片段而区分开来。值得注意的是,该方法甚至能够分别在纯化的sp dcas9和sp cas9大体积ivtt dna产物的1:10-5
混合物中检测裂解的sp cas9 dna片段的存在(图11)。
50.图12.来自乳液ivtt自裂解测定的纳米孔测序读段,其中使用有限输入浓度的sp cas9构建体。正如对sp cas9酶预期的,乳液ivtt纳米孔测序读段显示为检测到的裂解(白色部分;图12)和未裂解(黑色部分;图12)的构建体片段的混合物。因此,该数据支持其中在乳液液滴中进行ivtt和酶促反应的测定的稳健性。该子文库中的一个小的读段子集被映射到sp dcas9,因此在图表上归类为错误分配(浅灰色部分;图12),因为只有sp cas9 dna被提供为该乳液ivtt反应的输入。
51.图13.来自乳液ivtt自裂解测定的纳米孔测序读段,其中使用有限输入浓度的sp dcas9构建体。sp dcas9乳液ivtt纳米孔测序读段绝大多数显示为未裂解的(带条纹的灰色部分;图13)构建体片段,这表明sp dcas9在大多数时间下是无活性的,正如预期的那样。因此,该数据也支持其中在乳液液滴中进行ivtt和酶促反应的测定的稳健性。该子文库中的一个小的读段子集被映射到sp cas9,因此在图表上归类为错误分配(浅灰色部分;图13),因为只有sp dcas9dna被提供为该乳液ivtt反应的输入。
52.图14.来自乳液ivtt自裂解测定的纳米孔测序读段,其中以等摩尔比提供有限输入浓度的sp cas9和sp dcas9构建体。纳米孔测序读数显示sp cas9和sp dcas9映射读段的大致相等的分布,正如预期的那样。此外,sp cas9映射读段显示为裂解和未裂解片段几乎相等的划分(分别为白色和黑色部分;图14),而极大部分sp dcas9映射读数被归类为未裂解(带条纹的灰色部分;图14)。因此,该数据进一步证明本文公开的方法可以测量不同变体的酶活性(在本实例中为cas变体,但该方法也可用于筛选酶促反应中其他组分的变体,例如靶标或grna)。
53.定义
54.在整个说明书中使用的若干术语在以下段落中定义。其他定义也可以在说明书的正文中找到。
55.如本文所用,关于数字的术语“约(about)”和“大约(approximately)”在本文中用于包括在任一方向(大于或小于)落入该数字的20%、10%、5%、2.5%、2%、1.5%或1%的范围内的数字,除非另有说明或从上下文中可以明显看出(除了该数字将会超过可能值的100%的情况)。
56.术语“多核苷酸”、“核酸”和“寡核苷酸”可互换使用,是指任何长度的核苷酸(脱氧核糖核苷酸或核糖核苷酸或其类似物)的聚合形式。多核苷酸可以具有任何三维结构并且可以执行任何已知或未知的功能。以下是多核苷酸的非限制性实例:基因或基因片段(例如探针、引物、est或sage标签)、外显子、内含子、信使rna(mrna)、转移rna、核糖体rna、核酶、cdna、重组多核苷酸、分支多核苷酸、质粒、载体、任何序列的分离的dna、任何序列的分离的rna、核酸探针和引物。多核苷酸可以包含修饰的核苷酸,例如甲基化核苷酸和核苷酸类似物。如果存在对核苷酸结构的修饰的话,则该修饰可以在多核苷酸组装之前或之后赋予。核苷酸序列可以被非核苷酸组分打断。多核苷酸可在聚合后被进一步修饰,例如通过与标记组分缀合。该术语还指双链和单链分子。除非另有说明或要求,多核苷酸包括双链形式,和已知或预计构成双链形式的两条互补单链形式中的每一条。如本文所用,术语“多肽”通常具有本领域公认的氨基酸聚合物的含义。该术语还用于指代特定功能类别的多肽,例如诸如核酸酶、抗体等。
57.如本文所用,术语“可操作地连接”是指并列,其中所描述的组分处于允许它们以它们预期的方式发挥功能的关系。“可操作地连接”至功能元件的控制元件,例如启动子,以在与该控制元件相容的条件下实现功能元件的表达和/或活性的方式缔合。在一些实施方案中,“可操作地连接的”控制元件与目的编码元件邻接(例如,共价连接);在一些实施方案中,控制元件以反式或以其他方式作用于目的功能元件。
58.术语“核酸修饰酶”是指大分子生物催化剂,其本质上可以是蛋白质或核酸,并且能够修饰核酸。术语“rna引导的核酸修饰酶”泛指与向导rna相互作用或形成复合物,并能
特异性地靶向或结合具有特定序列的多核苷酸的酶,该特定序列通常包含与grna的靶向结构域互补的序列。在与靶多核苷酸结合时,rna引导的核酸修饰酶可以保持与靶多核苷酸的结合,或者如果rna引导的核酸修饰酶是核酸酶,则它可以裂解靶多核苷酸;或者如果rna引导的核酸修饰酶具有功能域,则它可以以其他方式修饰多核苷酸。在一个实例中,rna引导的核酸修饰酶是crispr相关蛋白(cas)。许多cas蛋白具有核酸内切酶活性,也称为cas核酸酶。在一个具体实例中,rna引导的核酸修饰酶选自由cas3、cas9、cas10、cas12a(也称为cpf1)、cas13a(也称为c2c2)、cas13b、cas13c、cas13d、cas14、casx、casφ及其变体组成的组。
59.术语“向导rna”和“grna”是指在细胞或无细胞环境中促进rna引导的核酸修饰酶与靶序列特异性结合(或“靶向”)的任何核酸。grna可以是单分子的(包含单个rna分子,或者称为嵌合体)或模块化的(包含一个以上,通常是两个单独的rna分子,例如crrna和tracrrna,它们通常相互缔合,例如通过形成双链体(duplexing))。
60.如本文所用,术语“靶”(或“靶位点”)是指核酸序列,其定义结合分子将结合的核酸(或多核苷酸)的一部分,条件是存在足够的结合条件。在一些实施方案中,靶位点是本文所述的核酸修饰酶所结合和/或被这种核酸修饰酶修饰的核酸序列。在一些实施方案中,靶标是本文描述的向导rna所结合的核酸序列。靶标可以是单链或双链的。如本文所公开的核酸修饰酶可以修饰dna或rna。因此,“靶标”可以是dna序列或rna序列,分别称为“dna靶标”和“rna靶标”。在二聚化的核酸酶,例如包含fokl dna裂解结构域的核酸酶的情况下,靶标通常包含左半位点(由核酸酶的一个单体结合)、右半位点(由核酸酶的第二个单体结合)以及在进行切割的半位点之间的间隔序列。在一些实施方案中,左半位点和/或右半位点的长度在10-18个核苷酸之间。在一些实施方案中,一个或两个半位点更短或更长。在一些实施方案中,左半位点和右半位点包含不同的核酸序列。在锌指核酸酶的情况下,在一些实施方案中,靶标可以包含两个半位点,每个半位点的长度均为6-18bp,位于4-8bp长的非指定间隔区的两侧。在talen的情况下,在一些实施方案中,靶标可以包含两个半位点,每个半位点的长度均为10-23bp,位于10-30bp长的非指定间隔区的两侧。在rna引导的(例如,rna可编程的)核酸修饰酶的情况下,靶标通常包含与向导rna(grna)互补的核苷酸序列(例如,crispr-cas中的“原型间隔区”),以及在3'端或5'端与向导rna互补序列相邻的原型间隔区相邻基序(pam)。对于靶向rna的crispr-cas酶(例如cas13家族),rna靶标可以包含原型间隔区侧翼序列(pfs)而不是pam序列。在一些实施方案中,cas酶的dna或rna靶标可以包含与grna互补的长度为16-24个的核苷酸,以及3-6个碱基对pam/pfs(例如,nnn,其中n代表任何核苷酸)。
61.如本文所用,“结合”是指大分子之间(例如,蛋白质和多核苷酸之间)的非共价相互作用。
62.多核苷酸的“修饰”是指该多核苷酸的组分或结构的任何化学或物理变化,包括使该多核苷酸断裂/裂解、在双链多核苷酸中产生切口(单链断裂)、取代一个或多个核苷酸碱基、插入或缺失一个或多个核苷酸碱基,或用化学和表观遗传标志物共价修饰核苷酸碱基(例如胞嘧啶甲基化和羟甲基化)。
63.如本文所用,术语“变体”是指与参考实体显示极大结构同一性,但与参考实体相比在一个或多个化学部分的存在或水平方面在结构上不同于参考实体的实体。在许多实施
方案中,变体在功能上也与其参考实体不同。一般而言,特定实体是否被恰当地视为参考实体的“变体”基于其与参考实体的结构同一性程度。如本领域技术人员将理解的,任何生物或化学参考实体都具有某些特征性结构元件。根据定义,变体是共享一个或多个此类特征结构元件的独特化学实体。仅举几个例子,多肽可以具有包含多个氨基酸的特征序列元件,所述氨基酸在线性或三维空间中相对于彼此具有指定位置和/或有助于特定生物学功能;核酸可以具有由多个核苷酸残基构成的特征序列元件,所述核苷酸残基在线性或三维空间中相对于彼此具有指定位置。例如,变体多肽可能由于氨基酸序列的一种或多种差异和/或共价附着于多肽骨架的化学部分(例如碳水化合物、脂质等)的一种或多种差异而不同于参考多肽。在一些实施方案中,变体多肽显示与参考多肽(例如,本文所述的核酸修饰酶)的总体序列同一性为至少60%、65%、70%、75%、80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%或99%。可选择地或另外,在一些实施方案中,变体多肽不与参考多肽共享至少一个特征序列元件。在一些实施方案中,参考多肽具有一种或多种生物活性。在一些实施方案中,变体多肽共享参考多肽的一种或多种生物活性,例如酶活性。在一些实施方案中,变体多肽缺乏参考多肽的一种或多种生物活性。在一些实施方案中,与参考多肽相比,变体多肽显示出降低的一种或多种生物活性(例如酶活性)水平。在一些实施方案中,如果目的多肽具有与亲本的氨基酸序列相同但在特定位置有少量序列改变的氨基酸序列,则目的多肽被认为是亲本或参考多肽的“变体”。通常,与亲本相比,变体中少于20%、15%、10%、9%、8%、7%、6%、5%、4%、3%、2%的残基被取代。在一些实施方案中,变体与亲本相比具有10、9、8、7、6、5、4、3、2或1个取代的残基。通常,变体具有非常少量(例如,少于5、4、3、2或1个)的取代的功能性残基(即,参与特定生物活性的残基)。此外,与亲本相比,变体通常具有不超过5、4、3、2或1个添加或缺失,并且通常没有添加或缺失。此外,任何添加或缺失通常少于约25、约20、约19、约18、约17、约16、约15、约14、约13、约10、约9、约8、约7、约6个,并且通常少于约5、约4、约3或约2个残基。在一些实施方案中,亲本或参考多肽是在自然界中存在的一种多肽。
64.如本文在核酸或蛋白质的上下文中使用的,术语“文库”分别指两种或更多种不同的多核苷酸构建体或蛋白质的群体。在一些实施方案中,多核苷酸构建体文库包含至少两个包含编码核酸修饰酶的不同序列的多核苷酸构建体,至少两个包含编码向导rna的不同序列的多核苷酸构建体,至少两个包含不同pam的多核苷酸构建体,和/或至少两个包含不同靶位点的核酸分子。在一些实例中,文库包含至少101、至少102、至少103、至少104、至少105、至少106、至少107、至少108、至少109、至少10
10
、至少10
11
、至少10
12
、至少10
13
、至少10
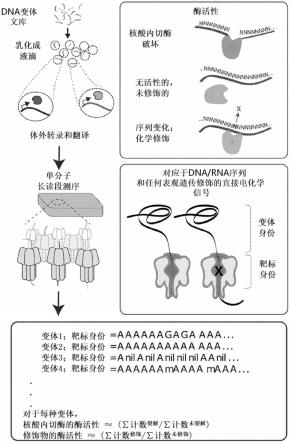
14
或至少10
15
个不同的核酸模板。在一些实施方案中,文库的成员可以包含随机化序列,例如完全或部分随机化序列。在一些实施方案中,文库包含彼此不相关的核酸分子,例如包含完全随机化序列的核酸。在其他实施方案中,文库的至少一些成员可能是相关的,例如,它们可能是具有特定序列的变体或衍生物。
65.如本文所用,术语核酸序列的“表达”是指从该核酸序列产生任何基因产物。在一些实例中,基因产物可以是rna转录物。在一些实施方案中,基因产物可以是多肽。在一些实施方案中,核酸序列的表达涉及以下一项或多项:(1)从dna序列产生rna模板(例如,通过转录);(2)rna转录物的加工(例如,通过剪接、编辑、5'帽形成和/或3'末端形成);(3)将rna翻译成多肽或蛋白质;和/或(4)多肽或蛋白质的翻译后修饰。
66.如本文在将多核苷酸构建体分隔到隔室中的上下文中使用的,术语“隔室”可以指任何物理或虚拟隔室,例如乳液液滴和纳米孔,以及虚拟隔室,例如能够分隔试剂和反应体系的微流体或水凝胶。
67.如本文所用,术语“启动子”是指赋予准确转录起始的转录启动子。如本文所用的启动子包括可用于产生编码蛋白质(例如cas蛋白质)或rna转录物(例如向导rna)的mrna的任何启动子。在一些实例中,启动子与无细胞体外转录和翻译反应相容。可以在本发明的上下文中使用的启动子的实例包括但不限于:t7启动子、sp6启动子、lac启动子等。如本文所用,术语“终止子”是指转录终止子,其定义转录单位(例如基因)的末端并启动从转录机器中释放新合成的rna的过程。终止子的实例包括但不限于:t7终止子和rrnb终止子。
68.发明的详细描述
69.特别地,本发明的发明人开发了一种多重化方法来测量核酸修饰酶的活性并筛选酶促反应的一个或多个可变元件。例如,该方法可以将核酸修饰酶变体的活性与其自身的编码dna/rna及其dna/rna靶分子物理联系起来,同时不管活性水平如何,在分子上直接测量每个变体对个体靶分子的酶活性和失活(即对活性变体的活性程度定量,也可以将无活性变体测量为
‘
失活’)。这实现了工程化核酸修饰酶(例如crispr-cas)以使其具有增强的或新颖的功能(通过活性变体)的直接途径,同时构建了当前无用序列变异(通过无活性或活性较低的变体)的适应度景观图(fitness landscape map)。类似地,还可以使用本文公开的方法筛选向导rna和/或dna/rna靶标的变体。
70.本发明的关键概念的非限制性和非详尽列表描述如下:(i)编码dna/rna靶位点和待测试的可变元件(例如,核酸修饰酶变体)的多核苷酸构建体,(ii)将dna与任何常用的rna和蛋白质表达试剂混合(也称为无细胞转录-翻译(txtl)/体外转录-翻译(ivtt)反应),(iii)将dna构建体变体的单拷贝与ivtt试剂一起封装或区室化,(iv)允许在单独隔室中的ivtt反应,在与其他众多隔室隔离的每个隔室中表达核酸修饰酶和sgrna(如果酶是rna引导的酶)(并且在一些实施方案中,rna靶标作为cas转录物的一部分共同转录),(v)取决于编码的核酸修饰酶的功能性,单个多核苷酸构建体(或在一些实施方案中为从构建体转录的rna靶标)被裂解、保持完整或以其他方式被修饰,(vi)对裂解的、完整的或修饰的多核苷酸构建体(或在一些实施方案中为rna靶标)平行定量,例如通过单分子长读段测序,从而以分子平行的方式直接鉴定和直接定量与每个可变元件相关的酶活性。该技术将编码的可变元件(例如核酸修饰酶变体)的表型与其编码序列直接联系起来,从而允许快速确定大型变体文库的序列-功能关系。图1描绘了本发明的关键概念的非限制性列表。
71.方法
72.本文公开的方法可以表征为测量酶活性的方法。由于该方法是高度可扩展的并且能够筛选大量变体多核苷酸,因此该方法还可表征为筛选核酸修饰酶和/或(核酸修饰酶的)dna/rna靶标和/或向导rna和/或可以在多核苷酸构建体上编码的酶促反应的其他组分的方法。因此,在一个方面,本公开涉及一种包括以下步骤的方法:
73.a)将多个多核苷酸构建体分隔到隔室中,其中每个隔室包含单个多核苷酸构建体,其中每个多核苷酸构建体包含:
74.i)可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列;和
75.ii)包含dna靶标或编码rna靶标的dna模板的第二多核苷酸序列,其中当所述第二多核苷酸序列包含编码rna靶标的dna模板时,所述rna靶标与所述核酸修饰酶作为单个转录物被所述第一启动子驱动而连续共表达;
76.并且其中所述多个多核苷酸构建体编码所述核酸修饰酶的不同变体,和/或不同的dna或rna靶标;
77.b)使所述隔室经受允许rna和蛋白质的体外表达的条件;
78.c)使多个所述隔室经受允许通过对dna或rna靶标具有修饰活性的核酸修饰酶修饰所述dna/rna靶标的条件,从而产生包含以下中的一个或多个的dna/rna分子群体:
79.iii.已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna靶标或其片段;
80.iv.未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna靶标;
81.d)收获步骤(c)中产生的所述dna/rna分子群体,并对其进行单分子测序;
82.e)基于测序结果对步骤c)i和c)ii中提到的dna/rna分子进行检测和计数。
83.在该第一方面,多核苷酸构建体编码核酸修饰酶(或其变体)和dna/rna靶标二者。因此,可以将核酸修饰酶或dna/rna靶标作为可变元件进行测试或筛选。在该方法用于测试或测量不同核酸修饰酶对特定靶标的活性(即筛选酶)的一些实例中,多个多核苷酸构建体可以编码相同的dna/rna靶标,但编码不同的核酸酸修饰酶(或同一核酸修饰酶的不同变体)。在该方法用于测试或测量特定核酸修饰酶对不同dna/rna靶标的活性(即筛选dna/rna靶标)的一些实例中,多个多核苷酸构建体可以编码相同的核酸修饰酶,但编码不同的dna/rna靶标。在crispr-cas靶标的情况下,表述“不同的dna/rna靶标”可以指原型间隔区(与向导rna互补的序列)或pam/pfs序列不同的dna/rna靶标。
84.在其中由每个多核苷酸构建体编码的核酸修饰酶是rna引导的核酸修饰酶(例如crispr-cas核酸酶或其变体)的一些实例中,核酸修饰酶可能需要向导rna(grna)以结合和/或修饰dna/rna靶标。在一些实例中,grna被以grna的形式或以编码该grna的dna模板的形式直接提供给每个隔室。因此,在其中核酸修饰酶是rna引导的核酸修饰酶的一个实例中,每个隔室还包含向导rna或编码其的核苷酸模板。
85.在一些其他实例中,grna可以在编码酶和dna/rna靶标的同一个多核苷酸构建体上编码。因此在一个实例中,核酸修饰酶是rna引导的核酸修饰酶,其中每个多核苷酸还包含编码变体向导rna(grna)的第三多核苷酸序列;并且其中多个多核苷酸构建体编码核酸修饰酶的不同变体,和/或不同的dna或rna靶标,和/或不同的grna。在该实例中,本文公开的方法包括以下步骤:
86.a)将多个多核苷酸构建体分隔到隔室中,其中每个隔室包含单个多核苷酸构建体,其中每个多核苷酸构建体包含:
87.i)可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列,其中所述核酸修饰酶是rna引导的核酸修饰酶;
88.ii)包含dna靶标或编码rna靶标的dna模板的第二多核苷酸序列,其中当所述第二多核苷酸序列包含编码rna靶标的dna模板时,所述rna靶标与所述核酸修饰酶作为单个转录物被所述第一启动子驱动而连续共表达;和
89.iii)编码变体向导rna(grna)的第三多核苷酸序列;
90.其中多个多核苷酸构建体编码核酸修饰酶的不同变体,和/或不同的dna或rna靶
标,和/或不同的grna;
91.b)使所述隔室经受允许rna和蛋白质的体外表达的条件;
92.c)使多个所述隔室经受允许通过对dna或rna靶标具有功能活性的核酸修饰酶在grna存在下修饰所述dna/rna靶标的条件,从而产生包含以下中的一个或多个的dna/rna分子群体:
93.i.已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna靶标或其片段;
94.ii.未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna靶标;
95.d)收获步骤(c)中产生的所述dna/rna分子群体,并对其进行单分子长读段测序;
96.e)基于测序结果对步骤c)i和c)ii中提到的dna/rna分子进行检测和计数。
97.在上述实例中,由于grna(或编码所述grna的序列)与核酸修饰酶和dna/rna靶标物理连接,因此可以将grna、dna/rna靶标和核酸修饰酶中的任何一种作为可变元件进行测试和筛选。所编码的grna将从多核苷酸构建体中表达(例如在隔室中),因此多核苷酸构建体可以包含促进grna表达的其他元件,这些其他元件对于本领域技术人员来说是普遍已知的。在一些实例中,第三多核苷酸序列可操作地连接至第二启动子。在一些实例中,第二启动子是t7启动子。
98.筛选核酸修饰酶
99.在该方法用于测试或测量不同核酸修饰酶对特定靶标的活性的一些实例中,多个多核苷酸构建体可以编码相同的dna/rna靶标和grna,但编码不同的核酸酸修饰酶(或同一核酸修饰酶的不同变体)。
100.可以使用这种方法测试、筛选和优化的核酸修饰酶的一个实例是cas核酸酶家族。近年来开发了各种用于dna和rna编辑的crispr-cas系统,从而能够广泛应用于影响医学和生物技术的所有领域。2类cas(crispr相关)蛋白特别令人感兴趣,包括在文献中已被充分表征的cas9、cas12(以前称为cpf1)、cas13和cas14核酸酶。这些cas蛋白是单组分核酸酶效应物(即单个cas蛋白,而不是不同蛋白的多聚体复合物);它们通常利用rna寡核苷酸(向导rna、grna;也称为单向导rna的工程化形式,sgrna;可互换使用)对cas蛋白进行编程和共定位到dna和/或rna上的特定位点,随后酶活性可以发生,例如裂解(dna/rna中的核苷酸内切裂解断裂)。grna序列的一个区段(间隔区)与dna/rna的靶序列(原型间隔区)互补。与原型间隔区相邻的另一个短序列(长度通常为2-6nt)是功能靶向所必需的,所述短序列也称为原型间隔区相邻基序(pam;当在dna上时)或原型间隔区侧翼序列(pfs;当在rna上时)。每个cas-grna系统都可以识别独特的pam/pfs位点并具有不同的grna:原型间隔区要求。cas蛋白已经并且可以进一步被工程化以识别新的pam/pfs位点,具有不太严格的grna长度或结构,并且更特异和有效。为了使用cas核酸酶作为治疗剂同时最大限度地减少不良免疫反应,也可以去除或掩盖cas蛋白中的免疫原性表位,特别是通过删除或改变氨基酸序列同时保持cas功能。还可以将新功能工程化到cas蛋白或cas融合蛋白中,例如以实现碱基编辑(将靶核苷酸更改为另一个)、表观遗传修饰或许多其他尚未证实的修饰。这些工作通常需要cas变体库的某种形式的定向进化、蛋白质工程化、选择和筛选。本文公开的方法可用于测量和筛选大型酶文库(例如cas)突变体的活性,因为它是i)高度可扩展的,每毫升》109个区室化ivtt反应液滴能够平行运行;和ii)与更大的序列空间相容,这在与大蛋白质(》103aa长),例如crispr-cas蛋白一起工作时尤其重要和有用。
101.筛选核酸修饰酶的dna/rna靶标
102.在其中该方法用于在特定grna存在下测试或测量特定核酸修饰酶对不同dna/rna靶标的活性的一些实例中,多个多核苷酸构建体可以编码相同的核酸修饰酶和grna,但编码不同的dna/rna靶标。
103.在这些实例中,本文公开的方法可用于评估pam或pfs变体通过rna引导的核酸修饰酶指导dna/rna靶标的结合或修饰的能力。本文公开的方法允许同时评估任何给定靶位点的多个pam/pfs变体。因此,从此类方法获得的数据可用于编制修饰(例如裂解)特定dna/rna靶标的pam变体列表。对本领域技术人员来说显而易见的是,也可以使用该方法测试和筛选靶位点上可能对酶活性有影响的任何非pam/pfs序列。
104.筛选向导rna
105.在其中该方法用于在不同的特定grna存在下测试或测量特定核酸修饰酶对特定dna/rna靶标的活性的一些实例中,多个多核苷酸构建体可以编码相同的核酸修饰酶和dna/rna目标,但编码不同的grna。
106.在这些实例中,本公开提供了评估不同grna介导核酸修饰酶对特定dna/rna靶标的结合和/或修饰的能力的方法。因此,从这些方法获得的结果可用于编制介导特定核酸修饰酶对特定靶标的修饰的向导rna变体的列表。
107.在另一方面,本公开涉及一种包括以下步骤的方法:
108.a)将多个多核苷酸构建体分隔到隔室中,其中每个隔室包含单个多核苷酸构建体,其中每个多核苷酸构建体包含:
109.i)可操作地连接至第一启动子的编码向导rna(grna)的第一多核苷酸序列;
110.ii)包含dna靶标或编码rna靶标的dna模板的第二多核苷酸序列,其中当所述第二多核苷酸序列包含编码rna靶标的dna模板时,所述rna靶标与所述grna作为单个rna转录物被所述第一启动子驱动而连续共表达;
111.其中所述多个多核苷酸构建体编码不同的grna,和/或不同的dna或rna靶标;并且其中每个隔室还包含rna引导的核酸修饰酶或其变体或编码其的核苷酸模板;
112.b)使所述隔室经受允许rna和蛋白质的体外转录和/或翻译的条件;
113.c)使所述隔室经受允许通过对dna或rna靶标具有功能活性的rna引导的核酸修饰酶在grna存在下修饰所述dna/rna靶标的条件,从而产生包含以下中的一个或多个的dna/rna分子群体:
114.i)已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段;
115.ii)未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物;
116.d)收获步骤(c)中产生的所述dna/rna分子群体,并对其进行单分子长读段测序;
117.e)基于测序结果对步骤c)i和c)ii中提到的dna/rna分子进行检测和计数。
118.在这方面,多核苷酸构建体编码向导rna(grna)和dna/rna靶标,而rna引导的核酸修饰酶被分别提供给每个隔室。因此,可以将grna或dna/rna靶标作为可变元件进行测试或筛选。在该方法用于在不同的grna存在下测试或测量特定核酸修饰酶对特定靶标的活性(即筛选grna)的一些实例中,多个多核苷酸构建体可以编码相同的dna/rna靶标,但编码不同的核酸酸修饰酶(或同一核酸修饰酶的不同变体)。在该方法用于测试或测量特定核酸修饰酶对不同dna/rna靶标的活性(即筛选dna/rna靶标)的一些实例中,多个多核苷酸构建体
可以编码相同的grna,但编码不同的dna/rna靶标。
119.将多核苷酸构建体分隔到隔室中
120.多种将多核苷酸构建体分隔到隔室中的方法是本领域技术人员已知的。在一个实例中,通过本领域通常已知的乳化方法将多核苷酸构建体分隔到乳液液滴中。通常,乳液可以由不混溶液体的任何合适的组合制备。在典型的实例中,乳液包含水相,所述水相包含(a)体外转录和翻译所需的组分;和(b)本文所述的核酸模板文库。在乳液中,水相以细小液滴的形式(分散相、内相或不连续相)存在。乳液还包含疏水性的不混溶液体(“油”),作为液滴悬浮的基质(非分散相、连续相或外相)。这类乳液称为“油包水”(w/o),而液滴称为“油包水液滴”。许多油和许多乳化剂是本领域已知的并且可用于产生油包水乳液。合适的乳化剂包括例如轻质白色矿物油和表面活性剂,例如脱水山梨糖醇单油酸酯(span80;ici)和聚氧乙烯脱水山梨糖醇单油酸酯(tween 80;ici),或它们的任何组合。在一个实例中,乳化剂包含矿物油、span 80和表面活性剂,例如tween 80;例如矿物油+4.5%(v/v)span 80+0.5%(v/v)tween 80。对不同乳化剂的测试在本领域技术人员的知识范围内。在一些实例中,使用机械能将这些相强制到一起来产生乳液。可以采用各种方法,包括但不限于使用机械装置,包括搅拌器(例如磁力搅拌棒、螺旋桨和涡轮搅拌器、桨式装置和搅拌器(whisk))、均质器(包括转子-定子均质器、高压阀均质器和喷射均质器)、胶体磨、超声波和“膜乳化”装置。本领域技术人员可以通过根据选择系统的要求定制用于形成乳液的乳液条件而改变乳液液滴(隔室)的尺寸。
121.本文描述了一个非限制性实例:使用以下步骤或本领域普通技术人员已知的其他方法产生油包水(w/o)乳液液滴。概括地讲,将950μl的油表面活性剂混合物(矿物油+4.5%(v/v)span 80+0.5%(v/v)tween 80)添加到带有3
×
8mm磁力搅拌棒的冷冻管中;放在冰上。将≤1.66fmol的dna文库与ivtt试剂(new england biolabs purexpress#e6800)在冰上混合以产生50μl的ivtt水性混合物。在2分钟内将50μl的该水性混合物分5份10μl添加到冰上的油表面活性剂混合物中,同时使搅拌棒以1150rpm的转速旋转以产生乳液混合物。让乳液混合物在冰上再混合一分钟。在一个实例中,使用均质器(例如ika ultraturrax t10均质器)以8000rpm的速度将搅拌的乳液混合物再混合3分钟,以实现乳液液滴直径的单分散性更高的分布。
122.产生乳液液滴的其他方法也是可能的并且对于本领域技术人员来说是已知的,包括涡旋震荡水和油混合物,或使用微流体装置(例如dolomite-bio的μ封装器)控制进料到微流体芯片连接处的水和油输入物的流速,从而以乳液液滴的形式用油包封水溶液。
123.其他区室化方法也是本领域普通技术人员已知的。如本文所用,术语“隔室”涵盖虚拟和物理区室化二者,只要区室化能够在不产生物理封装的情况下分隔多核苷酸构建体、试剂和反应体系。在一个实例中,隔室的分隔是使用微流体、水凝胶限制扩散或分隔井(或纳米井)来实现的。
124.ivtt系统
125.在本文公开的方法的一些实例中,每个隔室都包含体外转录和翻译(ivtt)试剂,所述ivtt试剂能够实现蛋白质和/或rna的体外转录和/或翻译。在隔室中包括ivtt绕过了在测定中使用细胞。在一些实施方案中,ivtt系统包括细胞提取物,例如来自细菌、兔网织红细胞或小麦胚芽的细胞提取物。许多合适的系统是可商购的(例如从thermofisher、
promega和new england biolabs)。在一个实例中,该系统可以与多核苷酸构建体一起乳化。通过参考文献或商业试剂盒的手册,适用于步骤b)中提到的体外转录和翻译的条件对于本领域技术人员来说是显而易见的或可获得的。在一个非限制性实例中,合适的条件是4小时37℃孵育。ivtt反应可以通过本领域熟知的或商业试剂盒手册中描述的方法来终止。在一个实例中,将包含ivtt的隔室在65℃孵育15分钟,以使ivtt试剂和任何表达的核酸修饰酶热失活。在另一个实例中,将20mm edta(ph 8.0)抑制剂添加到隔室(例如乳液液滴)中并混合。
126.通过控制ivtt试剂与dna的区室化条件,可以确保每个隔室中不超过一个多核苷酸构建体拷贝与ivtt试剂一起封装,体积从飞升到纳升不等。这使得每个隔室内的每个变体拷贝dna(以及ivtt rna和蛋白质产物)都能够被物理隔离,这允许用户对表达的rna和蛋白质与其各自的编码dna进行物理限制。
127.允许通过已知的核酸修饰酶修饰dna/rna靶标的条件在本领域中通常是已知的和/或可以容易地被发现或优化。对于新发现的酶,这些条件通常可以使用有关被更好表征的相关核酸酶(例如,同源物和直系同源物)的信息来模拟。修饰可以指靶标的组分或结构的任何化学或物理变化,包括断裂/裂解多核苷酸、在双链多核苷酸中产生切口(单链断裂)、取代一个或多个核苷酸碱基、插入或缺失一个或多个核苷酸碱基,或用化学和表观遗传标志物共价修饰核苷酸碱基(例如胞嘧啶甲基化和羟甲基化)。
128.由于每个隔室包含多核苷酸构建体的单个拷贝,因此dna/rna靶标(其包含在多核苷酸构建体上或从所述构建体表达)和核酸修饰酶也被限制在所述隔室中。特定构建体上编码的核酸修饰酶对同一构建体上编码的dna/rna靶标的活性(或无活性)将以dna/rna靶标的修饰(或无修饰)体现。由于这些隔室整体上包含多个不同的多核苷酸构建体,因此步骤c)产生包含以下中的一个或多个的dna/rna分子群:
129.i.已被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段;
130.ii.未被所述核酸修饰酶修饰的多核苷酸构建体和/或rna转录物;
131.其中多核苷酸构建体包含dna靶标,如果编码的核酸修饰酶对所述dna靶标具有活性,则多核苷酸构建体将被修饰。因此,多核苷酸构建体的状态(修饰或未修饰)通过包含在同一构建体上的酶特异性序列与酶相关联。其中多核苷酸构建体包含编码rna靶标的dna模板,rna靶标将包含在从所述dna模板表达的转录物rna上。由于rna靶标与核酸修饰酶作为单个转录物连续共表达,因此rna靶标的状态(修饰或未修饰)也通过包含在rna转录物上的酶特异性序列与酶相关联。
132.收获dna/rna分子
133.为了测量核酸修饰酶对dna/rna靶标的活性,收获步骤c)中产生的dna/rna分子群体,然后进行测序。在一些实例中,dna/rna分子的收获需要破坏隔室。因此,在如本文所公开的方法的一个实例中,步骤d)进一步包括通过物理或化学方法破坏隔室。在隔室是乳液液滴的实例中,收获dna/rna分子包括乳液液滴的破坏。
134.破坏乳液液滴的方法是本领域普通技术人员已知的。该方法的一个非限制性实例如下:将乳液混合物转移到2ml离心管中,并在室温下以13000g离心5分钟。丢弃上层油层。向剩余的水层中添加1ml水饱和二乙醚,涡旋震荡,并除去上层溶剂;重复此步骤一次。将剩余的水层在真空下室温离心5分钟。在一个实例中,收获dna/rna分子的步骤还包括ivtt猝
灭步骤。例如,可以通过用rnase混合液和蛋白酶k处理剩余的水层以从ivtt反应中去除过量的rna和蛋白质来进行ivtt猝灭步骤。在一些实例中,收获dna/rna分子的步骤还包括净化步骤以纯化dna/rna分子。dna/rna净化的方法对于本领域普通技术人员来说是熟知的,并且有许多用于该方法的商业试剂盒,例如dna clean&concentrator-5(zymo research)或spriselect bead cleanup(beckman coulter)。
135.在一些实例中,dna/rna分子的收获需要纯化收获的dna/rna分子以从反应中去除过量或不想要的dna、rna和/或蛋白质。因此,在本文公开的方法的一个实例中,步骤d)还包括纯化收获的dna/rna分子以从反应中去除过量的dna、rna和/或蛋白质。在一些实例中,过量的dna、rna和/或蛋白质可以包括但不限于grna、核酸修饰酶和ivtt试剂。在一些实例中,术语“过量”描述待测序的分子。
136.测序
137.在一个优选的实例中,测序是单分子测序。“单分子测序”是指可以直接从样品中存在的dna或rna的单条链读取碱基序列的技术。至少两种类型的单分子测序是市售的:(a)pacific biosciences的单分子实时测序(smrt),基于以小于波长的波导(zmw)检测和鉴定荧光团标记的核苷酸,和(b)使用电子装置读取核酸(dna/rna)片段穿过oxford nanopore technologies所使用的纳米孔时的信号的无标记测序方法。长读段有助于单分子测序,其也可称为“长读段测序”或“单分子长读段测序”。单分子测序的使用提供了对变体序列的直接鉴定,它绕过了(i)将寡核苷酸连接到预定的dna/rna末端,和(ii)pcr扩增。
[0138]“直接”检测单个变体的酶产物和对修饰的:未修饰的dna/rna靶标(或多核苷酸构建体/rna转录物)进行分子计数以对各个变体的分子活性定量是本发明的一个重要特征。术语“直接”可以指直接检测反应产物,或直接测量单个变体的酶活性。在后一种含义中,表述“酶促功能的直接测量”以通过关联的基因型信息(也在单个分子(多核苷酸构建体或rna转录物)内编码)直接计算变体分子的表型活性(在变体的大规模调查中)为背景。因此,酶活性是直接在实际相互作用的分子上测量的。基于本文公开的方法,酶活性的精确水平可以基于修饰与未修饰(或总数)的计数直接测量。在一个实例中,与1:1修饰:未修饰的靶位点相关联的特定变体被确定为在50%的时间内对靶位点有活性。
[0139]
因此,在一些实例中,除了单分子测序所需的修饰以外,收获的dna/rna分子群体在进行单分子测序反应之前不进行进一步修饰。这些修饰可以包括常规测序所需的修饰,例如裂解末端与接头的连接、条形码的连接、通过pcr扩增dna/rna分子等修饰。
[0140]
在一个实例中,使用oxford nanopore technologies平台进行测序。下面描述测序过程的一个非限制性实例。
[0141]
按照测序装置制造商(例如oxford nanopore technologies(ont)minion mk1b装置)建议的文库制备方案,为长读段测序制备纯化的dna,并相应地对文库进行测序。在一些实例中,这可能涉及使用ont sqk-lsk109连接测序试剂盒进行通用dna文库制备,连同使用ont exp-nbd104 pcr-free无扩增(native)条形码扩展试剂盒以获得多重条形码化的dna子库。
[0142]
使用公共存储库上的生物信息学工具(例如,minimap2(li,h.(2018).minimap2:pairwise alignment for nucleotide sequences.bioinformatics,34:3094-3100.doi:10.1093/bioinformatics/bty191),nanopack(de coster,w.等人,(2018).nanopack:
visualizing and processing long-read sequencing data.bioinformatics,34:2666-2699.doi:10.1093/bioinformatics/bty149,samtools(li,h.等人,(2009).the sequence alignment/map format and samtools.bioinformatics,25:2078-9.doi:10.1093/bioinformatics/btp352、varscan 2(koboldt,d.c.等人,(2012).varscan 2:somatic mutation and copy number alteration discovery in cancer by exome sequencing.genome research,22:568-576.doi:10.1101/gr.129684.111))或可由测序数据分析领域的普通技术人员创建的定制脚本处理和分析长读段测序数据。例如,在一些实例中,测序分析领域的普通技术人员可以采取以下步骤来处理和分析从ont测序装置产生的原始纳米孔测序读段:
[0143]
1.使用ont提供的guppy工具包(https://community.nanoporetech.com/protocols/guppy-protocol/v/gpb_2003_v1_revm_14dec2018),在必要时使用工具包中的碱基调用和去多重化算法处理原始纳米孔测序读段。测序分析领域的普通技术人员可能希望根据他们的需要调整某些参数,例如用于多重化的条形码质量分数的过滤阈值。这些参数通常描述于相应的工具手册中进行。
[0144]
2.测序分析领域的普通技术人员可能希望使用诸如nanopack的软件工具基于诸如读段长度和读段质量分数的参数进一步过滤和处理读段。
[0145]
3.然后可以使用minimap2或其他序列比对工具将这些处理的读段与(一组)参考序列进行比对,以生成读段比对数据集。同样,测序分析领域的普通技术人员可能希望根据需要调整读段比对参数,例如比对评分矩阵。这些参数通常描述于相应的工具手册中。
[0146]
4.然后,用户可以解析生成的读段比对文件,以计算未修饰和已修饰读数的计段。在一些实施方案中,这可以通过使用其他比对处理工具例如samtools或varscan2来检测和鉴定比对的测序读段和测序读段所对照的参考序列之间的测序变化而进行。同样,测序分析领域的普通技术人员可以确定这些工具中的哪些参数应根据需要进行调整,例如,设置最小读段计数阈值,以从背景水平的测序错误中检测和鉴定真正的测序变化。这些参数通常描述于相应的工具手册中。
[0147]
分子检测和计数
[0148]
因此可以通过对已经被核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段以及未被核酸修饰酶修饰的多核苷酸构建体和/或rna转录物进行检测和计数来直接检测酶活性。多核苷酸构建体可以包含dna靶标,并且rna转录物可以包含rna靶标。
[0149]
因此在一些实例中,所述方法还包括评估一种或多种核酸修饰酶对一种或多种dna/rna靶标的修饰活性,所述评估通过以下方式进行:计算已被核酸修饰酶修饰的多核苷酸构建体和/或rna转录物的数量(∑计数
修饰
),并将其与未被核酸修饰酶修饰的多核苷酸构建体和/或rna转录物的数量(∑计数
未修饰
)或与多核苷酸构建体和/或rna转录物的总数量(∑计数
修饰+未修饰
)进行比较。
[0150]
在一个实例中,酶活性由使用以下任一公式计算的值表示:
[0151]
1)酶活性≈∑计数
修饰
/∑计数
未修饰
[0152]
2)酶活性≈∑计数
修饰
/∑计数
修饰+未修饰
。
[0153]
可以使用本领域技术人员可获得的测序平台生成的测序数据对已被或未被核酸修饰酶修饰的多核苷酸构建体和/或rna转录物或其片段进行检测和计数。由于dna/rna分
子是通过单分子测序直接测序的,因此在一个实例中,已被或未被核酸修饰酶修饰的dna/rna分子的检测和计数仅基于在单分子测序期间生成的数据,并且不需要对dna/rna分子的进一步修饰或处理。
[0154]
在一个实例中,其中修饰活性是裂解活性,并且修饰和未修饰的多核苷酸构建体或rna靶标的检测和计算是通过将dna/rna分子的测序读数与包含核酸修饰酶的裂解位点窗口的参考序列进行比对来实现,其中
[0155]
i)当dna/rna分子的3'端映射到所述裂解位点窗口3'下游的区域时,所述dna/rna分子是未修饰的多核苷酸构建体或rna靶标;
[0156]
ii)当dna/rna分子的3'端映射到所述裂解位点窗口内的区域时,所述dna/rna分子是修饰的多核苷酸构建体或rna靶标;
[0157]
iii)当dna/rna分子的3'端映射到所述裂解位点窗口5'上游的区域时,所述dna/rna分子是无信息性的并且不用于测量修饰活性。
[0158]
在一个实例中,测序读段由它们各自的映射终点(即测序读段结束的位置)确定,以确定终点是否位于预期裂解位点的小窗口内(“cas参考序列”上的灰色三角形和虚线);图3)。一个非限制性实例描述如下,其中dna靶位点位于编码的cas核酸酶变体的3'。通过这种方式,具有在预期cas裂解位点窗口3'下游的位点处映射到参考序列的3'末端的对齐的读段(与参考序列比对)被认为是未裂解的(深灰色;图3),而具有3'末端位于cas裂解位点窗口内的对齐的读段被认为是裂解的(浅灰色;图3),并且不满足任一标准的读段作为无信息性的读段最终被丢弃,因为无法凭经验确定这些读段是否被裂解(白色;图3)。在这些实例中,每个裂解的cas裂解位点代表一个已被修饰的多核苷酸构建体/rna转录物。类似地,每个未裂解的cas裂解位点代表一个未被修饰的多核苷酸构建体/rna转录物。
[0159]
在一些实例中,测序技术可以检测或判断靶位点的化学和序列同一性以确定靶标是否被cas变体修饰。例如,对核苷酸的化学修饰,例如甲基化,可以使用可公开获得的生物信息学工具检测,这些生物信息学工具被设计为在纳米孔测序读段中挑选出化学修饰的核苷酸(liu,q.等人(2019).detection of dna base modifications by deep recurrent neural network on oxford nanopore sequencing data.nat commun 10(1):2449,doi:10.1038/s41467-019-10168-2;liu,q.等人(2019).nanomod:a computational tool to detect dna modifications using nanopore long-read sequencing data.bmc genomics 20(增刊1):78,doi:10.1186/s12864-018-5372-8;rand,a.c.等人(2017).mapping dna methylation with high-throughput nanopore sequencing.)nat methods 14(4):411-413,doi:10.1038/nmeth.4189;simpson,j.t.等人(2017).detecting dna cytosine methylation using nanopore sequencing.nat methods 14(4):407-410,doi:10.1038/nmeth.4184)。在编码的cas核酸酶靶向rna构建体的其他实例中,可以在ivtt反应后使用商业试剂盒例如rna clean&concentrator-5(zymo research)收获和纯化rna分子,而oxford nanopore technologies则使用其市售sqk-rna002rna直接测序试剂盒对收获的rna分子进行直接纳米孔测序。因此,测序技术可用于检测各种类型的修饰,包括但不限于链断裂、序列变化和表观遗传生化标记。
[0160]
多核苷酸构建体和文库
[0161]
本公开还涉及各种多核苷酸构建体、构建体文库和隔室(关于多核苷酸构建体的
一些实例,参见例如图2)。
[0162]
构建体1:在一个方面,本公开涉及一种多核苷酸构建体,其包含:可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列;和包含dna靶标的第二多核苷酸序列。
[0163]
构建体2:在另一方面,本公开涉及一种多核苷酸构建体,其包含:可操作地连接至第一启动子的编码核酸修饰酶或其变体的第一多核苷酸序列;和包含编码rna靶标的dna模板的第二多核苷酸序列;并且其中所述rna靶标与所述核酸修饰酶作为单个rna转录物被所述第一启动子驱动而连续共表达。
[0164]
在另一方面,本公开涉及一种包含如本文作为构建体1或构建体2公开的多个多核苷酸构建体的构建体文库,其中所述文库的特征在于以下一项或多项:
[0165]
a.所述多个多核苷酸构建体编码核酸修饰酶的不同变体;
[0166]
b.所述多个多核苷酸构建体编码不同的dna或rna靶标。
[0167]
构建体3:在一个实例中,本公开还涉及一种根据构建体1或构建体2的多核苷酸构建体,其中所述多核苷酸构建体还包含编码向导rna(grna)的第三多核苷酸序列。编码的grna将从多核苷酸构建体中表达(例如在隔室中),因此多核苷酸构建体可以包含促进grna表达的其他元件,这些其他元件通常是本领域技术人员已知的。在一些实例中,第三多核苷酸序列可操作地连接至第二启动子。在一些实例中,第二启动子是t7启动子。
[0168]
在另一方面,本公开涉及一种包含如本文作为构建体3公开的多个多核苷酸构建体的构建体文库,其中所述文库的特征在于以下一项或多项:
[0169]
a.所述多个多核苷酸构建体编码核酸修饰酶的不同变体;
[0170]
b.所述多个多核苷酸构建体编码不同的dna或rna靶标;
[0171]
c.所述多个多核苷酸构建体编码不同的grna。
[0172]
构建体4:在又一方面,本公开涉及一种多核苷酸构建体,其包含:可操作地连接至第一启动子的编码向导rna(grna)的第一多核苷酸序列;和包含dna靶标的第二多核苷酸序列。
[0173]
构建体5:在又一方面,本公开涉及一种多核苷酸构建体,其包含:可操作地连接至第一启动子的编码向导rna(grna)的第一多核苷酸序列;和包含编码rna靶标的dna模板的第二多核苷酸序列;其中所述rna靶标与所述grna作为单个rna转录物被所述第一启动子驱动而连续共表达。
[0174]
在另一方面,本公开涉及一种包含如本文作为构建体4公开的多个多核苷酸构建体的构建体文库,其中所述文库的特征在于以下一项或多项:
[0175]
a.所述多个多核苷酸构建体编码不同的dna或rna靶标;
[0176]
b.所述多个多核苷酸构建体编码不同的grna。
[0177]
在如本文所公开的方法或多核苷酸构建体的一些实例中,第一和第二多核苷酸序列完全或部分重叠。例如,dna/rna靶标(“第二多核苷酸”)可以在核酸修饰酶的编码序列(“第一多核苷酸”)内编码。
[0178]
在如本文所公开的方法或多核苷酸构建体的一些实例中,dna或rna靶标包含与向导rna至少部分互补的原型间隔区。在如本文所公开的方法或多核苷酸构建体的一些实例中,其中dna靶标还包含近端原型间隔区相邻基序(pam)序列。在如本文所公开的方法或多
核苷酸构建体的一些实例中,其中当多核苷酸构建体包含编码rna靶标的dna模板时,rna靶标还包含近端原型间隔区侧翼序列(pfs)。
[0179]
在如本文所公开的方法或多核苷酸构建体的一些实例中,rna引导的核酸修饰酶是crispr相关(cas)蛋白。在一个具体实例中,rna引导的核酸修饰酶选自由cas3、cas9、cas10、cas12a(也称为cpf1)、cas13a(也称为c2c2)、cas13b、cas13c、cas13d、cas14、casx、casφ及其变体组成的组。
[0180]
在如本文所公开的方法或多核苷酸构建体的一些实例中,变体核酸修饰酶包含一个或多个失活的催化位点,并且能够结合和抑制dna靶标的表达,而不修饰dna靶标。
[0181]
在如本文所公开的方法或多核苷酸构建体的一些实例中,变体核酸修饰酶与一个或多个能够修饰dna或rna的另外的功能域融合。在一些具体实例中,附加功能域包括但不限于:胞苷脱氨酶结构域、从头dna甲基转移酶3a(dnmt3a)结构域、胞嘧啶-5甲基转移酶结构域、十-十一易位双加氧酶1(tet1)催化结构域、作用于rna的腺苷脱氨酶(adar2)脱氨酶结构域和dna脱氧腺苷脱氨酶结构域等。
[0182]
出于说明性和示例性目的,下文提供了多核苷酸构建体的序列。
[0183]
[0184]
[0185]
[0186][0187]
粗体和带下划线的序列是指将在下面单独注释的元件:
[0188]
t7/laco启动子:
[0189][0190]
rbs(核糖体结合位点):aaggag(seq id no:2)
[0191]
sq cas9基因(编码序列):
[0192]
[0193]
[0194][0195]
合成终止子序列(l3s1p52):
[0196][0197]
t7启动子:taatacgactcactatag(seq id no:5)
[0198]
grna靶序列(原型间隔区):tctgacagcagacgtgcactggccag(seq id no:6)
[0199]
spcas9 grna支架:
[0200][0201]
t7终止子:
[0202][0203]
靶区域(dna靶标):
[0204][0205]
在一些实例中,例如在以上例示的一个实例中,在靶序列(又名原型间隔区)旁边存在原型间隔区相邻基序(pam),例如:用于cpf1型(也称为cas12)cas蛋白的5’pam位点tttv(seq id no:11),用于sp cas9的3’pam位点ngg,和用于sa cas9蛋白的3’pam位点nngrrt(seq id no:12),位于tctgacagcagacgtgcactggccag(seq id no:6)原型间隔区序列两侧。标准iupac核酸符号在本文并贯穿整个说明书中使用。
[0206]
隔室
[0207]
在一方面,本公开涉及一个或多个隔室,每个隔室包含如本文公开的多核苷酸构建体,其中所述隔室彼此分隔。在一些实例中,每个隔室还包含体外转录和翻译(ivtt)试剂,所述ivtt试剂能够实现蛋白质和/或rna的体外转录和/或翻译。在一些实例中,隔室的体积小于1000μm3、100μm3、10μm3或1μm3。在一些实例中,隔室是油包水乳液液滴。在一些实例中,分离是使用微流体、水凝胶限制扩散或分隔井来实现的。
实施例
[0208]
实施例1:乳液液滴中spcas9构建体的ivtt和裂解
[0209]
按照上面提供的方案中概述的步骤生成油包水(w/o)乳液液滴。概括地讲,将950μl的油表面活性剂混合物(矿物油+4.5%(v/v)span 80+0.5%(v/v)tween80)添加到带有3
×
8mm磁力搅拌棒的冷冻管中,并放在冰上。
[0210]
高dna输入:每个乳液液滴封装》1个序列拷贝-证明乳化保持了cas活性,正如从大体积ivtt反应中表达的cas那样。
[0211]
对于本实验,将约750ng的sp cas9构建体(序列如上文所示)与ivtt试剂(new england biolabs purexpress#e6800)在冰上混合以产生75μl ivtt水性混合物。在2分钟内将50μl的该水性混合物分5份10μl添加到冰上的油表面活性剂混合物中,同时搅拌棒以1150rpm旋转以产生乳液混合物。让乳液混合物在冰上混合另外的一分钟。然后对乳液混合物进行均质化(8000rpm持续3分钟;ika ultraturrax t10均质器)以产生乳液液滴尺寸的单分散性更高的分布。将剩余的25μl水性混合物保持在冰上,进行大体积ivtt反应以作为对照。对sp dcas9构建体也重复了此操作。
[0212]
然后将乳液和大体积ivtt混合物在37℃孵育4小时以进行ivtt,然后在65℃孵育15分钟以使蛋白质失活。
[0213]
然后如上所述处理乳液ivtt混合物以破坏乳液。将20mm edta(ph 8.0)抑制剂添加到乳液中并通过涡旋震荡短暂混合。然后将乳液混合物在室温以13000g离心5分钟。去除上层油层。向剩余的水层中添加1ml水饱和二乙醚,涡旋震荡并除去上层溶剂层;重复此步
骤一次。剩余的水层在室温真空离心5分钟,然后用rnase混合液和蛋白酶k在37℃处理30分钟从ivtt反应中去除多余的rna和蛋白质。同样用20mm edta(ph 8.0)以及rnase混合液和蛋白酶k的混合物将大体积ivtt反应体系在37℃处理30分钟,以从ivtt反应中去除多余的rna和蛋白质。然后使用spriselect顺磁珠单独纯化来自所有ivtt反应的dna,并在琼脂糖凝胶上通过凝胶电泳进行尺寸分选后可视化等分试样(图4)。在乳液ivtt反应中,编码活性sp cas9的构建体被裂解(存在较小的条带),而编码无活性sp dcas9的构建体未被裂解(不存在较小的条带)。这表明无论编码dna构建体是在乳液液滴中区室化还是在大体积溶液(bulk solution)中自由浮动,crispr-cas ivtt自裂解测定都有效。
[0214]
还使用来自oxford nanopore technologies(ont)的可商购的sqk-lsk109连接测序试剂盒对来自乳液ivtt反应的纯化dna进行处理以供纳米孔测序之用,并使用ont exp-nbd104 pcr-free无扩增条形码扩展试剂盒进行条形码化,因此它们在单个汇集的dna文库中可能被任选地多重化。然后使用ont minion mk1b测序装置对汇集的dna文库进行单分子长读段纳米孔测序。然后对纳米孔测序结果进行质量过滤,并使用公开可用的生物信息学工具进行分析。sp cas9乳液ivtt纳米孔测序读段显示为检测到的裂解和未裂解的构建体片段的混合物(图5)。sp dcas9乳液ivtt纳米孔测序读段绝大多数显示为未裂解的构建体片段,正如预期的那样(图6);归类为“裂解”的sp dcas9构建体片段的极少数读段可能是纳米孔测序期间读段被截短/是不完整的和/或随机dna剪切事件和/或测序装置上的错误的结果。每个子文库中的一些读段被映射到错误的序列,例如对于只有sp cas9的子文库来说,读段被映射到sp dcas9而不是sp cas9。这些可能是测序装置上随机测序错误的结果,或者在条形码化的纳米孔测序读段的去多重化过程中被错误分配至其各自的子文库;因此,这些读段被归类为错误分配的并在图中如此描绘。
[0215]
实施例2:在大体积ivtt反应后通过dna构建体的多重化单分子长读段测序对crispr-cas的裂解活性定量
[0216]
对于不同的crispr-cas构建体(sp cas9、sa cas9、as cpf1、lb cpf1),在冰上建立大体积ivtt反应,这些构建体的组分排列都与对于上述核酸模板序列所描述的相似。然后对于每个时间点将它们平均分成5个相应的等分试样(图7第1部分)。然后将这些大体积ivtt的等分试样在37℃孵育,并在每个指定的时间点取出,用edta抑制剂和酶猝灭,以停止ivtt反应和编码dna构建体的cas裂解(图7第2部分)。然后使用spriselect珠净化处理猝灭的ivtt反应以纯化dna片段(图7第3部分)。
[0217]
然后在琼脂糖凝胶上通过凝胶电泳进行尺寸分选后观察来自不同ivtt时间点的不同cas直系同源物的这些dna片段的小等分试样,如图8所示。
[0218]
然后将剩余的纯化dna片段的等分试样按它们各自的时间点汇集,但不考虑cas种类,即在每个时间点将sp cas9、sa cas9等的dna片段混合在一起,并使用ont exp-nbd104 pcr-free无扩增条形码扩展试剂盒单独进行条形码化(图7第4部分),以将这些汇集的子文库多重化以进行单次纳米孔测序运行(图7第5部分)。然后对纳米孔测序结果进行质量过滤,并使用公开可用的生物信息学工具,然后使用本发明中公开的分析方法进行分析。
[0219]
图9描绘了在ivtt孵育的选定的5个时间点(0到4小时之间),编码裂解的dna片段的每个活性cas构建体的计数相对于编码裂解和未裂解的dna片段的各个cas构建体的总计数进行了标准化。随着ivtt孵育时间的增加,表达的cas蛋白有更多时间裂解更多的编码
dna构建体,从而导致每个种类的裂解片段的发生率在较后的时间点更高。图9中绘制的纳米孔测序分析结果显示与图8中的纯化的ivtt dna片段的凝胶图像定性地一致,两种测定具有相同的纯化dna输入,该输入是从图7第3部分中描绘的工作流程步骤中获得的。这个实施例展示了以我们的工作流程研究来自多个crispr-cas自裂解测定的单独ivtt反应的核酸产物的主张。
[0220]
实施例3:通过滴定来自大体积ivtt反应的纯化crispr-cas dna终产物的比率来证明纳米孔测序测定的灵敏度
[0221]
对于本实验,将500ng的sp cas9(序列如上文所示)与ivtt试剂(new england biolabs purexpress#e6800)在冰上混合以产生50μl ivtt水性混合物。对sp dcas9构建体也进行了同样的操作;sp dcas9构建体包含与sp cas9构建体的dna序列基本相同的dna序列,不同之处是sp cas9基因中的2个失活突变(d10a和h840a)而产生sp dcas9基因。将这些50μl大体积ivtt反应在37℃孵育4小时以进行ivtt,然后在65℃孵育15分钟以使蛋白质失活。将20mm edta(ph 8.0)抑制剂与rnase混合液和蛋白酶k添加到大体积ivtt反应中,在37℃下持续30分钟,以从ivtt反应中去除多余的rna和蛋白质。然后使用spriselect顺磁珠单独纯化来自这两种大体积ivtt反应的dna,然后在琼脂糖凝胶上通过凝胶电泳进行尺寸分选后观察dna的等分试样,如图10所示。
[0222]
对来自sp dcas9和sp cas9大体积ivtt反应的纯化dna的浓度进行定量,然后按以下质量比混合:1:1、1:10-1
、1:10-2
、1:10-3
、1:10-4
、1:10-5
、1:0。然后使用ont sqk-lsk109连接测序试剂盒对具有滴定纯化的sp dcas9和sp cas9大体积ivtt dna产物的7种比例的这些混合物进行处理,以进行纳米孔测序,而这7种混合物中的每一种都使用ont exp-nbd104 pcr-free无扩增条形码扩展试剂盒单独进行条形码化。然后使用ont minion mk1b测序装置对dna文库进行单分子长读段纳米孔测序。然后对纳米孔测序结果进行质量过滤,并使用公开可用的生物信息学工具,然后使用本发明中公开的分析方法进行分析。
[0223]
该测定的目的是评估用于dna/rna修饰事件的大规模调查的纳米孔测序测定的灵敏度,这是我们的发明中要求保护的能力。具体而言,在这种情况下,将sp cas9 ivtt构建体的自裂解事件针对sp dcas9 ivtt构建体的非裂解进行滴定。使用上述生物信息学方法的组合,发明人展示了裂解和未裂解的sp cas9dna片段的检测,在原始纳米孔测序数据中sp cas9 dna片段可以与未裂解的sp dcas9 dna片段的检测区分开来。值得注意的是,发明人甚至能够分别在纯化的sp dcas9和sp cas9大体积ivtt dna产物的1:10-5
混合物中检测到裂解的sp cas9 dna片段的存在(图11)。
[0224]
实施例4:乳液液滴中spcas9构建体的ivtt和裂解
[0225]
限制dna输入:每个乳液液滴封装≤1个序列拷贝-测量乳化dna构建体单拷贝的效率。
[0226]
在本实验中,将≤1.66fmol的sp cas9构建体(序列如上文所示)与ivtt试剂(new england biolabs purexpress#e6800)在冰上混合以产生50μl ivtt水性混合物。在2分钟内将50μl的该水性混合物分5份10μl添加到冰上的油表面活性剂混合物中,同时搅拌棒以1150rpm旋转以产生乳液混合物。让乳液混合物在冰上继续混合另外的一分钟。然后对乳液混合物进行均质化(8000rpm持续3分钟;ika ultraturrax t10均质器)以产生乳液液滴尺寸的单分散性更高的分布。对sp dcas9构建体以及sp cas9和sp dcas9构建体的1:1等摩尔
混合物重复此操作。
[0227]
请注意,使用sp cas9和sp dcas9 dna构建体的混合物测量每个乳液液滴封装≤1个dna构建体的效率。在每个液滴仅封装≤1个dna构建体的完美效率下,在混合dna输入条件的测定结束时,通过纳米孔测序检测到的sp dcas9序列均不应被裂解。在不完美的效率下,一些sp dcas9 dna构建体可能会被裂解,因为有些构建体会在同一液滴中暴露于活性sp cas9。因此,如果在混合sp cas9和sp dcas9构建体的测定中,裂解的sp dcas9构建体的检测率以与长读段纳米孔测序的随机测序错误率相当的非常低的比率发生,则数据将表明在这些条件下,≤1个序列拷贝被封装在每个乳液液滴中。这个实施例展示了我们的发明的完整工作流程,如图1所示。
[0228]
然后将生成的乳液ivtt混合物在37℃孵育4小时以进行ivtt,然后在65℃孵育15分钟以使蛋白质失活。
[0229]
然后如上所述处理乳液ivtt混合物以破坏乳液。将20mm edta(ph 8.0)抑制剂添加到乳液中并通过涡旋震荡短暂混合。然后将乳液混合物在室温以13000g离心5分钟。去除上层油层。向剩余的水层中添加1ml水饱和二乙醚,涡旋震荡并除去上层溶剂层;重复此步骤一次。将剩余的水层在室温下真空离心5分钟,然后在37℃用rnase混合液和蛋白酶k处理30分钟从ivtt反应中去除多余的rna和蛋白质。然后按照制造商的说明,使用商业柱纯化试剂盒(dna clean and concentrator-5,zymo research)单独纯化来自所有ivtt反应的dna。
[0230]
然后使用ont sqk-lsk109连接测序试剂盒对来自ivtt反应的纯化dna进行处理以供纳米孔测序之用,并使用ont exp-nbd104 pcr-free无扩增条形码扩展试剂盒单独进行条形码化。然后使用ont minion mk1b测序装置对dna文库进行单分子长读段纳米孔测序。然后对纳米孔测序结果进行质量过滤,并使用公开可用的生物信息学工具,然后使用本发明中公开的分析方法进行分析。
[0231]
sp cas9乳液ivtt纳米孔测序读段显示检测到的裂解和未裂解构建体片段的混合物(图12),表明sp cas9对一小部分靶标具有活性(如在大体积反应中所证明的那样)。sp dcas9乳液ivtt纳米孔测序读段绝大多数显示为未裂解的构建体片段,证明sp dcas9在绝大多数时候是无活性的,正如预期的那样(图13);归类为“裂解”的sp dcas9构建体片段的极少数读段可能是由纳米孔测序期间的截短/不完整读段和/或随机dna剪切事件导致的结果。
[0232]
请注意,仅sp cas9和仅sp dcas9的子文库中的一些读段被映射到错误的序列,例如在只有sp cas9的子文库中,读段映射到sp dcas9而不是sp cas9,这可能是测序装置上的测序错误或条形码化纳米孔测序读段的去多重化错误的结果,因此被归类为错误分配并如此在图中描绘。
[0233]
由以限制浓度添加的sp cas9和sp dcas9构建体的1:1混合物的乳液ivtt反应产生的纳米孔测序读段显示,sp cas9和sp dcas9映射读段的分布大致相等,正如预期的那样(图14)。sp cas9映射读段显示裂解和未裂解片段的几乎相等的划分,而大部分sp dcas9映射读段被归类为未裂解的。如由于测序或去多重化的错误而可能出现的,少数sp dcas9映射读段被归类为裂解的,因为已知这些测序错误会在对片段混合物进行测序时或通过酶复合物的交叉污染的错误而发生在测序装置上,这可以通过本发明构思内的技术优化进一步
减少。总之,该实施例体现并证明了所公开的发明,其中变体的酶活性的水平分级可以基于单分子直接计数和确定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1