使用具有独特分子索引(UMI)的冗余读段在测序DNA片段中抑制误差的制作方法
使用具有独特分子索引(umi)的冗余读段在测序dna片段中抑制误差
1.本技术是基于申请日为2016年4月20日,优先权日为2015年4月28日,申请号为201680036120.4,发明名称为:“使用具有独特分子索引(umi)的冗余读段在测序dna片段中抑制误差”的专利申请的分案申请。
2.对相关申请的交叉引用
3.本技术要求根据35u.s.c.第119(e)节,于2015年4月28日提交的美国临时专利申请号62/153,699,代理人案卷号ilmnp008p,于2015年7月16日提交的美国临时专利申请号62/193,469,代理人案卷号ilmnp008p2,以及于2015年12月18日提交的美国临时专利申请号62/269,485,代理人案号ilmnp008p3的权益,将其通过引用整体并入本文用于所有目的。
4.序列表
5.本技术含有序列表,其以ascii格式电子提交并通过引用以其整体并入本文。创建于2016年4月20日的所述ascii拷贝命名为ilmnp008wo_st25.txt并且大小为1164字节。
6.发明背景
7.下一代测序技术正在提供越来越高的测序速度,允许更大的测序深度。然而,由于测序精确度和灵敏度受到各种来源(如样品缺陷、文库制备期间的pcr、富集、成簇和测序)的误差(error)和噪声的影响,单独增加测序的深度不能确保检测到非常低等位基因频率的序列,如母体血浆中的胎儿无细胞dna(cfdna)中的序列、循环肿瘤dna(ctdna)中的序列、病原体亚克隆突变中的序列。因此,期望开发在抑制由于各种误差来源所致的测序不精确性的情况下测定少量和/或低等位基因频率的dna分子的序列的方法。
8.发明概述
9.公开的实施方案关注用于使用独特分子索引(umi)序列来测定核酸片段序列的方法、装置、系统和计算机程序产品。在各种实施方案中,测序方法测定来自核酸片段的两条链的核酸片段的序列。在一些实施方案中,该方法采用位于测序衔接头的一条或两条链上的物理umi。在一些实施方案中,该方法还采用位于核酸片段的两条链上的虚拟umi。
10.本公开的一方面涉及使用独特分子索引(umi)对来自样品的核酸分子测序的方法。每个独特分子索引(umi)是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列。所述方法包括:(a)将衔接头应用于所述样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述衔接头的一条链或每条链上的物理umi,从而获得dna
‑
衔接头产物;(b)扩增所述dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;(d)鉴定与所述多个读段相关联的多个物理umi;(e)鉴定与所述多个读段相关联的多个虚拟umi,其中每个虚拟umi是所述样品中dna片段中发现的序列;以及(f)使用(c)中获得的所述多个读段、(d)中鉴定的所述多个物理umi、和(e)中鉴定的所述多个虚拟umi来测定所述样品中的所述双链dna片段的序列。在一些实施方案中,所述方法包括操作(f),其包括:(i)对于所述样品中的一个或多个所述双链dna片段中的每个,组合(1)在5’至3’方向上,具有第一物理umi和至少一个虚拟umi的读段和(2)在5’至3’方向上,具有第二物理umi
和至少一个虚拟umi的读段以测定共有核苷酸序列;和(ii)对于所述样品中的一个或多个所述双链dna片段中的每个,使用共有核苷酸序列来测定序列。
11.在一些实施方案中,多个物理umi包含随机umi。在一些实施方案中,多个物理umi包含非随机umi。在一些实施方案中,每个非随机umi与衔接头的每个其它非随机umi相差所述非随机umi的对应序列位置处的至少两个核苷酸(every nonrandom umi differs from every other nonrandom umi of the adapters by at least two nucleotides at corresponding sequence positions of the nonrandom umis)。在一些实施方案中,多个物理umi包括不超过约10,000、约1,000、约500,或约100种独特非随机umi。在一些实施方案中,多个物理umi包括约96种独特非随机umi。
12.在以上方法的一些实施方案中,将衔接头应用于双链dna片段的两个末端包括将所述衔接头连接到所述双链dna片段的两个末端。在一些实施方案中,操作(f)包括使用共享共同物理umi和共同虚拟umi的读段来测定所述样品的dna片段的序列。
13.在以上方法的一些实施方案中,多个物理umi包括少于12个核苷酸。在一些实施方案中,多个mui包括不超过6个核苷酸。在一些实施方案中,所述多个umi包括不超过4个核苷酸。
14.在一些实施方案中,衔接头各自包含所述双链杂交区中衔接头的每条链上的物理umi。在一些实施方案中,物理umi在双链杂交区的末端处,所述双链杂交区的末端与3'臂或5'臂相反,或距离所述双链杂交区的末端为一个核苷酸。在一些实施方案中,衔接头各自包含与物理umi接近的双链杂交区上的5'
‑
tgg
‑
3'三核苷酸或者3'
‑
acc
‑
5'三核苷酸。在一些实施方案中,衔接头各自包含双链杂交区的每条链上的读段引物序列(read primer sequence)。
15.在一些实施方案中,衔接头各自包含单链5’臂或单链3’臂上在衔接头的仅一条链上的物理umi。在这些实施方案中的一些中,(f)包括:(i)将具有相同第一物理umi的读段折拢(collapsing)成第一组以获得第一共有核苷酸序列;(ii)将具有相同第二物理umi的读段折拢成第二组以获得第二共有核苷酸序列;以及(iii)使用第一和第二共有核苷酸序列来测定样品中双链dna片段之一的序列。在一些实施方案中,(iii)包括:(1)使用第一和第二共有核苷酸序列的定位信息和序列信息来获得第三共有核苷酸序列,并(2)使用第三共有核苷酸序列来测定双链dna片段之一的序列。在一些实施方案中,操作(e)包括鉴定多个虚拟umi,其中衔接头各自包含仅在单链5’臂区或单链3’臂区中在衔接头的仅一条链上的物理umi。在一些实施方案中,(f)包括:(i)将在5’至3’方向上具有第一物理umi和至少一个虚拟umi的读段与在5’至3’方向上具有第二物理umi和至少一个虚拟umi的读段组合以测定共有核苷酸序列;并且(ii)使用共有核苷酸序列来测定样品中双链dna片段之一的序列。
16.在一些实施方案中,衔接头各自包含在所述衔接头的双链区中在所述衔接头的每条链上的物理umi,其中一条链上的所述物理umi与另一条链上的所述物理umi互补。在一些实施方案中,操作(f)包括:(i)将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向上具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的读段组合以测定共有核苷酸序列;并且(ii)使用所述共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
17.在一些实施方案中,衔接头各自包含所述衔接头的3’臂上的第一物理umi和所述
衔接头的5’臂上的第二物理umi,其中所述第一物理umi和所述第二物理umi彼此不互补。在一些此类实施方案中,(f)包括:(i)将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向上具有第三物理umi、至少一个虚拟umi、和第四物理umi的读段组合以测定共有核苷酸序列;并且(ii)使用所述共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
18.在一些实施方案中,虚拟umi中的至少一些源自样品中双链dna片段的末端处或附近的亚序列。
19.在一些实施方案中,一个或多个物理umi和/或一个或多个虚拟umi与样品中双链dna片段独特地相关联。
20.在一些实施方案中,样品中双链dna片段包含超过约1,000个dna片段。
21.在一些实施方案中,多个虚拟umi包含约6bp至约24bp的umi。在一些实施方案中,多个虚拟umi包含约6bp至约10bp的umi。
22.在以上方法的一些实施方案中,操作(c)中获得所述多个读段包括:从每个扩增的多核苷酸中获得两个配对末端读段(pair
‑
end read),其中所述两个配对末端读段包含长读段和短读段,所述长读段比所述短读段长。在这些实施方案中的一些中,操作(f)包括:将与第一物理umi相关联的读段对组合成第一组并且将与第二物理umi相关联的读段对组合成第二组,其中所述第一和所述第二物理umi与所述样品中的双链片段独特地相关联;并且使用所述第一组中长读段的序列信息和所述第二组中长读段的序列信息来测定所述样品中所述双链片段的序列。在一些实施方案中,长读段具有约500bp或更多的读段长度。在一些实施方案中,短读段具有约50bp或更少的读段长度。
23.在一些实施方案中,所述方法抑制在以下一个或多个操作中出现的误差:pcr、文库制备、成簇(clustering)、和测序。
24.在一些实施方案中,扩增的多核苷酸包括具有低于约1%的等位基因频率的等位基因。
25.在一些实施方案中,扩增的多核苷酸包括源自肿瘤的无细胞dna分子,并且所述等位基因指示所述肿瘤。
26.在一些实施方案中,对多个扩增的多核苷酸测序包括获得具有至少约100bp的读段。
27.本公开的另一方面涉及对来自样品的核酸分子测序的方法,其包括(a)将衔接头附接至样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述单链5’臂或所述单链3’臂上的物理独特分子索引(umi);(b)扩增来自(a)的连接产物的两条链,从而获得多个单链扩增多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;(d)鉴定与多个读段相关联的多个物理umi;并且(e)使用(c)中获得的所述多个序列和(d)中鉴定的所述多个物理umi测定所述样品中所述双链dna片段的序列。
28.本公开的另一方面涉及对来自样品的核酸分子测序的方法。所述方法包括:(a)将衔接头附接至所述样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述衔接头的一条链或每条链上短于12个核苷酸的物理独特分子索引(umi);(b)扩增来自(a)的连接产物的两条链,从而获得各自包含物理umi的多个单
链扩增多核苷酸;(c)对所述多个扩增多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;(d)鉴定与所述多个读段相关联的多个物理umi;并且(e)使用(c)中获得的所述多个读段和(d)中鉴定的所述多个物理umi来测定所述样品中所述双链dna片段的序列。
29.本公开的另一方面涉及制备每条链上具有物理umi的双链体测序衔接头的方法。所述方法包括:提供初步测序衔接头,其包含双链杂交区、两个单链臂、和与所述两个单链臂离得较远的突出端,所述突出端在所述双链杂交区末端包含5'
‑
ccannnnannnntgg
‑
3';使用所述突出端作为模板来延伸所述双链杂交区的一条链,从而产生延伸产物;并且应用限制酶xcm1来消化所述延伸产物的双链末端,从而产生在每条链上具有物理umi的所述双链体测序衔接头。在一些实施方案中,初步测序衔接头包含每条链上的读段引物序列。
30.本公开的另一方面涉及计算机程序产品,其包含存储程序代码的非暂时机器可读介质,所述程序代码当由计算机系统的一个或多个处理器执行时,使所述计算机系统执行使用独特分子索引(umi)来测定样品中感兴趣的序列的序列信息的方法,所述程序代码包含:(a)用于获得多个扩增的多核苷酸的读段的代码,其中通过扩增包括所述感兴趣的序列的所述样品中的双链dna片段并且将衔接头附接至所述双链dna片段来获得所述多个扩增的多核苷酸;(b)用于鉴定所述多个扩增的多核苷酸的所述读段中的多个物理umi的代码,其中每个物理umi存在于附接至所述双链dna片段之一的衔接头中;(c)用于鉴定所述多个扩增的多核苷酸的所述读段中的多个虚拟umi的代码,其中每个虚拟umi存在于所述双链dna片段之一的单独分子中;和(c)用于测定所述双链dna片段的序列的代码,所述测定使用所述多个扩增的多核苷酸、所述多个物理umi、和所述多个虚拟umi的读段进行,从而减少所述双链dna片段的测定序列中的误差。在一些实施方案中,所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂、和在所述衔接头的一条链或每条链上的物理独特分子索引(umi)。
31.在一些实施方案中,用于测定双链dna片段的序列的代码包含:(i)用于将具有相同第一物理umi的读段折拢为第一组以获得第一共有核苷酸序列的代码;(ii)用于将具有相同第二物理umi的读段折拢为第二组以获得第二共有核苷酸序列的代码;和(iii)用于使用所述第一和第二共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列的代码。
32.在一些实施方案中,用于测定双链dna片段的序列的代码包含:(i)用于将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向上具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的读段组合以测定共有核苷酸序列的代码;和(ii)用于使用所述共有核苷酸序列来测定所述样品中双链dna片段之一的序列的代码。
33.本公开的另一方面涉及计算机系统,其包含:一个或多个处理器;系统存储器;和一个或多个计算机可读存储介质。所述介质具有其上存储的计算机可执行指令,所述指令使所述计算机系统执行使用独特分子索引(umi)来测定样品中感兴趣的序列的序列信息的方法,所述独特分子索引是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列。所述指令包括:(a)接收多个扩增的多核苷酸的读段,其中通过扩增包括所述感兴趣的序列的所述样品中的双链dna片段并将衔接头附接至所述双链dna片段来获得所述多个扩增的多核苷酸;(b)在所述多个扩增的多核苷酸的接收读段中鉴定多个物理umi,其中每个物理umi存在于附接至所述双链dna片段之一的衔接头中;(c)在所述多个扩增的多核苷酸
的接收读段中鉴定多个虚拟umi,其中每个虚拟umi存在于所述双链dna片段之一的单独分子中;并且(d)使用所述多个扩增的多核苷酸、所述多个物理umi和所述多个虚拟umi的序列来测定所述双链dna片段的序列,从而减少所述双链dna片段的测定序列中的误差。
34.在一些实施方案中,测定双链dna片段的序列包括:(i)将具有相同第一物理umi的读段折拢成第一组以获得第一共有核苷酸序列;(ii)将具有相同第二物理umi的读段折拢成第二组以获得第二共有核苷酸序列;并且(iii)使用所述第一和所述第二共有核苷酸序列来测定所述双链dna片段之一的序列。
35.在一些实施方案中,测定双链dna片段的序列包括:(i)将在5’至3’方向中具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向中具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的读段组合以测定共有核苷酸序列;并且(ii)使用所述共有核苷酸序列来测定所述双链dna片段之一的序列。
36.本公开的一方面提供了使用非随机独特分子索引(umi)对来自样品的核酸分子测序的方法。所述方法涉及:(a)将衔接头附接至所述样品中dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物;(b)扩增所述dna
‑
衔接头产物以获得多个扩增的多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得多个与多个非随机umi相关联的读段;(d)从所述多个读段中鉴定共享共同非随机umi的读段;和(e)从所述鉴定的共享共同非随机umi的读段中测定来自样品的dna片段的至少一部分的序列,其具有带有所述共同非随机umi的应用衔接子(applied adaptor)。
37.在一些实施方案中,方法还涉及:从共享所述共同非随机umi的读段中,选择共享所述共同非随机umi和共同读段位置两者的读段,其中(e)中测定dna片段的序列仅使用参考序列中共享所述共同非随机umi和共同读段位置两者的读段。在一些实施方案中,每个非随机umi与每个其它非随机umi相差所述非随机umi的对应序列位置处的至少两个核苷酸。
38.公开的另一方面涉及使用非随机独特分子索引(umi)对来自样品的核酸分子测序的方法。在一些实施方案中,所述方法涉及:(a)将衔接头应用于样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物,其中所述非随机umi能与其它信息组合以独特地鉴定双链dna片段的单独分子;(b)扩增所述dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与非随机umi相关联;(d)鉴定与所述多个读段相关联的多个非随机umi;以及(e)使用多个读段和多个非随机umi以测定样品中双链dna片段的序列。
39.在一些实施方案中,使用多个读段和多个非随机umi以测定样品中双链dna片段的序列涉及:鉴定共享共同非随机umi的读段,并使用所述鉴定的读段来测定样品中dna片段的序列。在一些实施方案中,使用多个读段和多个非随机umi以测定样品中双链dna片段的序列涉及:鉴定共享共同非随机umi和共同读段位置的读段,并使用所述鉴定的读段以测定样品中dna片段的序列。
40.在一些实施方案中,使用多个读段和多个非随机umi以测定样品中双链dna片段的序列涉及:鉴定共享共同非随机umi和共同虚拟umi的读段,其中所述共同虚拟umi在所述样品中dna片段中发现;以及使用所述鉴定的读段来测量样品中dna片段的序列。
41.在一些实施方案中,使用多个读段和多个非随机umi以测定样品中双链dna片段的序列涉及:鉴定共享共同非随机umi、共同读段位置,和共同虚拟umi的读段,其中所述共同虚拟umi在所述样品中dna片段中发现;以及使用所述鉴定的读段来测量样品中dna片段的序列。
42.在一些实施方案中,每个非随机umi与衔接头的每个其它非随机umi相差所述非随机umi的对应序列位置处的至少两个核苷酸。在一些实施方案中,衔接头各自包含所述双链杂交区中所述衔接头的每条链上的物理umi。在一些实施方案中,多个非随机umi包括不超过约10,000、约1,000、或约100种独特非随机umi。在一些实施方案中,多个非随机umi包括约96种独特非随机umi。
43.在一些实施方案中,多个读段各自包含非随机umi。在一些实施方案中,多个读段各自包含非随机umi或通过配对末端读段(paired
‑
end read)与所述非随机umi相关联。在一些实施方案中,多个扩增的多核苷酸各自在一个末端具有非随机umi或在第一末端具有第一非随机umi和在第二末端具有第二非随机umi。
44.还提供了执行所公开的方法的用于测定dna片段序列的系统、装置,和计算机程序产品。
45.本公开的一方面提供了计算机程序产品,其包含存储程序代码的非暂时机器可读介质,所述程序代码当由计算机系统的一个或多个处理器执行时,使所述计算机系统执行使用独特分子索引(umi)来测定样品中感兴趣的序列的序列信息。所述程序代码包含执行上述方法的指令。
46.尽管本文关注人类,并且语言主要针对人类关注,但本文所述的概念可适用于来自任何病毒、植物、动物,或其它生物体的核酸,和适用于其群体(宏基因组、病毒群体等)。本公开的这些和其它特征通过参考附图从下述描述,和所附权利要求书中变得更充分地显而易见,或者可以通过下文示出的本公开的实践而得知。
47.本发明包括以下内容:
48.实施方式1.使用独特分子索引(umi)对来自样品的核酸分子测序的方法,其中每个独特分子索引(umi)是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列,所述方法包括:
49.(a)将衔接头应用于所述样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂、和所述衔接头的一条链或每条链上的物理umi,从而获得dna
‑
衔接头产物;
50.(b)扩增所述dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸;
51.(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;
52.(d)鉴定与所述多个读段相关联的多个物理umi;
53.(e)鉴定与所述多个读段相关联的多个虚拟umi,其中每个虚拟umi是所述样品中dna片段中发现的序列;以及
54.(f)使用(c)中获得的所述多个读段、(d)中鉴定的所述多个物理umi、和(e)中鉴定的所述多个虚拟umi来测定所述样品中的所述双链dna片段的序列。
55.实施方式2.实施方式1的方法,其中(f)包括:
56.对于所述样品中的一个或多个所述双链dna片段中的每个,组合(i)具有第一物理umi和至少一个虚拟umi的读段和(ii)具有第二物理umi和所述至少一个虚拟umi的读段,以测定共有核苷酸序列;以及
57.对于所述样品中的一个或多个所述双链dna片段中的每个,使用所述共有核苷酸序列测定序列。
58.实施方式3.实施方式1的方法,其中所述多个物理umi包含随机umi。
59.实施方式4.实施方式1的方法,其中所述多个物理umi包含非随机umi。
60.实施方式5.实施方式4的方法,其中每个非随机umi与所述衔接头的每个其它(every other)非随机umi相差所述非随机umi的对应序列位置处的至少两个核苷酸。
61.实施方式6.实施方式5的方法,其中所述多个物理umi包括不超过约10,000种独特非随机umi。
62.实施方式7.实施方式6的方法,其中所述多个物理umi包括不超过约1,000种独特非随机umi。
63.实施方式8.实施方式7的方法,其中所述多个物理umi包括不超过约500种独特非随机umi。
64.实施方式9.实施方式8的方法,其中所述多个物理umi包括不超过约100种独特非随机umi。
65.实施方式10.实施方式9的方法,其中所述多个物理umi包括约96种独特非随机umi。
66.实施方式11.实施方式1的方法,其中将衔接头应用于双链dna片段的两个末端包括将所述衔接头连接到所述双链dna片段的两个末端。
67.实施方式12.实施方式1的方法,其中(f)包括使用共享共同物理umi和共同虚拟umi的读段来测定所述样品的dna片段的序列。
68.实施方式13.实施方式1的方法,其中所述多个物理umi包括少于12个核苷酸。
69.实施方式14.实施方式13的方法,其中所述多个mui包括不超过6个核苷酸。
70.实施方式15.实施方式13的方法,其中所述多个umi包括不超过4个核苷酸。
71.实施方式16.实施方式1的方法,其中所述衔接头各自包含所述双链杂交区中所述衔接头的每条链上的物理umi。
72.实施方式17.实施方式16的方法,其中所述物理umi在所述双链杂交区的末端处或附近,所述双链杂交区的所述末端与所述3’臂或所述5’臂相反。
73.实施方式18.实施方式17的方法,其中所述物理umi位于所述双链杂交区的所述末端处,或者距离所述双链杂交区的所述末端一个核苷酸。
74.实施方式19.实施方式18的方法,其中所述衔接头各自包含与物理umi接近的所述双链杂交区上的5
’‑
tgg
‑3’
三核苷酸或者3
’‑
acc
‑5’
三核苷酸。
75.实施方式20.实施方式19的方法,其中所述衔接头各自包含所述双链杂交区的每条链上的读段引物序列。
76.实施方式21.实施方式1的方法,其中所述衔接头各自包含所述单链5’臂或所述单链3’臂上在所述衔接头的仅一条链上的物理umi。
77.实施方式22.实施方式21的方法,其中(f)包括:
78.(i)将具有相同第一物理umi的读段折拢(collapsing)成第一组以获得第一共有核苷酸序列;
79.(ii)将具有相同第二物理umi的读段折拢成第二组以获得第二共有核苷酸序列;以及
80.(iii)使用所述第一和第二共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
81.实施方式23.实施方式22的方法,其中(iii)包括:(1)使用所述第一和第二共有核苷酸序列的定位信息和序列信息来获得第三共有核苷酸序列,并(2)使用所述第三共有核苷酸序列来测定所述双链dna片段之一的序列。
82.实施方式24.实施方式21的方法,其中(e)包括鉴定所述多个虚拟umi,其中所述衔接头各自包含仅在所述单链5’臂或所述单链3’臂上的所述物理umi。
83.实施方式25.实施方式24的方法,其中(f)包括:
84.(i)将在阅读方向上具有第一物理umi和至少一个虚拟umi的读段与在所述阅读方向上具有第二物理umi和所述至少一个虚拟umi的读段组合以测定共有核苷酸序列;并且
85.(ii)使用所述共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
86.实施方式26.实施方式1的方法,其中所述衔接头各自包含在所述衔接头的双链区中在所述衔接头的每条链上的物理umi,其中一条链上的所述物理umi与另一条链上的所述物理umi互补。
87.实施方式27.实施方式26的方法,其中(f)包括:
88.(i)将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向上具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的读段组合以测定共有核苷酸序列;并且
89.(ii)使用所述共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
90.实施方式28.实施方式1的方法,其中所述衔接头各自包含所述衔接头的3’臂上的第一物理umi和所述衔接头的5’臂上的第二物理umi,其中所述第一物理umi和所述第二物理umi彼此不互补。
91.实施方式29.实施方式28的方法,其中(f)包括:
92.(i)将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向上具有第三物理umi、所述至少一个虚拟umi、和第四物理umi的读段组合以测定共有核苷酸序列;并且
93.(ii)使用所述共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列。
94.实施方式30.实施方式1的方法,其中所述虚拟umi中的至少一些源自所述样品中所述双链dna片段的末端处或附近的亚序列。
95.实施方式31.实施方式1的方法,其中一个或多个物理umi和/或一个或多个虚拟umi与所述样品中双链dna片段独特地相关联。
96.实施方式32.实施方式1的方法,其中所述样品中所述双链dna片段包含超过约1,000个dna片段。
97.实施方式33.实施方式1的方法,其中所述多个虚拟umi包含约6bp至约24bp的umi。
98.实施方式34.实施方式33的方法,其中所述多个虚拟umi包含约6bp至约10bp的
umi。
99.实施方式35.实施方式1的方法,其中操作(c)中获得所述多个读段包括:从每个扩增的多核苷酸中获得两个配对末端读段,其中所述两个配对末端读段包含长读段和短读段,所述长读段比所述短读段长。
100.实施方式36.实施方式35的方法,其中(f)包括:
101.将与第一物理umi相关联的读段对组合成第一组并且将与第二物理umi相关联的读段对组合成第二组,其中所述第一和所述第二物理umi与所述样品中的双链片段独特地相关联;并且
102.使用所述第一组中长读段的序列信息和所述第二组中长读段的序列信息来测定所述样品中所述双链片段的序列。
103.实施方式37.实施方式35的方法,其中所述长读段具有约500bp或更多的读段长度。
104.实施方式38.实施方式35的方法,其中所述短读段具有约50bp或更少的读段长度。
105.实施方式39.实施方式1的方法,其中所述方法抑制在以下一个或多个操作中出现的误差:pcr、文库制备、成簇、和测序。
106.实施方式40.实施方式1的方法,其中扩增的多核苷酸包括具有低于约1%的等位基因频率的等位基因。
107.实施方式41.实施方式40的方法,其中所述扩增的多核苷酸包括源自肿瘤的无细胞dna分子,并且所述等位基因指示所述肿瘤。
108.实施方式42.实施方式1的方法,其中对多个扩增的多核苷酸测序包括获得具有至少约100bp的读段。
109.实施方式43.用于制备每条链上具有物理umi的双链体测序衔接头的方法,其包括:
110.提供初步测序衔接头,其包含双链杂交区、两个单链臂、和与所述两个单链臂离得较远的双联杂交区末端的突出端,所述突出端包含5'
‑
ccannnnannnntgg
‑
3';
111.使用所述突出端作为模板来延伸所述双链杂交区的一条链,从而产生延伸产物;并且
112.应用限制酶xcm1来消化所述延伸产物的双链末端,从而产生在每条链上具有物理umi的所述双链体测序衔接头。
113.实施方式44.实施方式43的方法,其中所述初步测序衔接头包含每条链上的读段引物序列。
114.实施方式45.计算机程序产品,其包含存储程序代码的非暂时机器可读介质,所述程序代码当由计算机系统的一个或多个处理器执行时使所述计算机系统执行使用独特分子索引(umi)来测定样品中感兴趣的序列的序列信息的方法,所述独特分子索引是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列,所述程序代码包含:
115.用于获得多个扩增的多核苷酸的读段的代码,其中通过扩增包括所述感兴趣的序列的所述样品中的双链dna片段并且将衔接头附接至所述双链dna片段来获得所述多个扩增的多核苷酸;
116.用于鉴定所述多个扩增的多核苷酸的所述读段中的多个物理umi的代码,其中每
个物理umi存在于附接至所述双链dna片段之一的衔接头中;
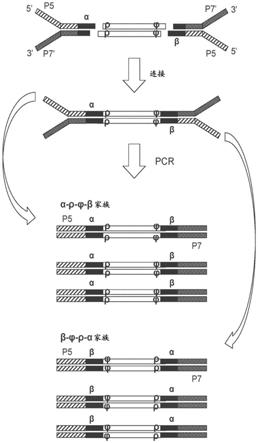
117.用于鉴定所述多个扩增的多核苷酸的所述读段中的多个虚拟umi的代码,其中每个虚拟umi存在于所述双链dna片段之一的单独分子中;和
118.用于测定所述双链dna片段的序列的代码,所述测定使用所述多个扩增的多核苷酸、所述多个物理umi、和所述多个虚拟umi的读段进行,从而减少所述双链dna片段的测定序列中的误差。
119.实施方式46.实施方式45的计算机程序产品,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂、和在所述衔接头的一条链或每条链上的物理独特分子索引(umi)。
120.实施方式47.实施方式45的计算机程序产品,其中所述用于测定双链dna片段的序列的代码包含:
121.(i)用于将具有相同第一物理umi的读段折拢为第一组以获得第一共有核苷酸序列的代码;
122.(ii)用于将具有相同第二物理umi的读段折拢为第二组以获得第二共有核苷酸序列的代码;和
123.(iii)用于使用所述第一和第二共有核苷酸序列来测定所述样品中所述双链dna片段之一的序列的代码。
124.实施方式48.实施方式45的计算机程序产品,其中所述用于测定双链dna片段的序列的代码包含:
125.(i)用于将在5’至3’方向上具有第一物理umi、至少一个虚拟umi和第二物理umi的序列读段与在5’至3’方向上具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的序列读段组合以测定共有核苷酸序列的代码;和
126.(ii)用于使用所述共有核苷酸序列来测定所述样品中双链dna片段之一的序列的代码。
127.实施方式49.计算机系统,其包含:
128.一个或多个处理器;
129.系统存储器;和
130.一个或多个计算机可读存储介质,所述计算机可读存储介质已经在其上存储计算机可执行指令,所述指令使所述计算机系统执行使用独特分子索引(umi)来测定样品中感兴趣的序列的序列信息的方法,所述独特分子索引是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列,所述指令包括:
131.接收多个扩增的多核苷酸的读段,其中通过扩增包括所述感兴趣的序列的所述样品中的双链dna片段并将衔接头附接至所述双链dna片段来获得所述多个扩增的多核苷酸;
132.在所述多个扩增的多核苷酸的接收读段中鉴定多个物理umi,其中每个物理umi存在于附接至所述双链dna片段之一的衔接头中;
133.在所述多个扩增的多核苷酸的接收读段中鉴定多个虚拟umi,其中每个虚拟umi存在于所述双链dna片段之一的单独分子中;并且
134.使用所述多个扩增的多核苷酸、所述多个物理umi和所述多个虚拟umi的序列来测定所述双链dna片段的序列,从而减少所述双链dna片段的测定序列中的误差。
135.实施方式50.实施方式49的计算机系统,其中测定所述双链dna片段的序列包括:
136.(i)将具有相同第一物理umi的读段折拢成第一组以获得第一共有核苷酸序列;
137.(ii)将具有相同第二物理umi的读段折拢成第二组以获得第二共有核苷酸序列;并且
138.(iii)使用所述第一和所述第二共有核苷酸序列来测定所述双链dna片段之一的序列。
139.实施方式51.实施方式49的计算机系统,其中测定所述双链dna片段的序列包括:
140.(i)将在5’至3’方向中具有第一物理umi、至少一个虚拟umi和第二物理umi的读段与在5’至3’方向中具有所述第二物理umi、所述至少一个虚拟umi、和所述第一物理umi的读段组合以测定共有核苷酸序列;并且
141.(ii)使用所述共有核苷酸序列来测定所述双链dna片段之一的序列。
142.实施方式52.用于对来自样品的核酸分子测序的方法,其包括
143.(a)将衔接头附接至所述样品中双链dna片段的两个末端,
144.其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述单链5’臂或所述单链3’臂上的物理独特分子索引(umi),和
145.其中umi是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列;
146.(b)扩增来自(a)的连接产物的两条链,从而获得多个单链扩增的多核苷酸;
147.(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;
148.(d)鉴定与所述多个读段相关联的多个物理umi;并且
149.(e)使用(c)中获得的所述多个序列和(d)中鉴定的所述多个物理umi测定所述样品中所述双链dna片段的序列。
150.实施方式53.用于对来自样品的核酸分子测序的方法,其包括:
151.(a)将衔接头附接至所述样品中双链dna片段的两个末端,
152.其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和在所述衔接头的一条链或每条链上短于12个核苷酸的物理独特分子索引(umi),并且
153.其中umi是能用于鉴定所述样品中双链dna片段的单独分子的寡核苷酸序列;
154.(b)扩增来自(a)的连接产物的两条链,从而获得各自包含物理umi的多个单链扩增的多核苷酸;
155.(c)对所述多个扩增的多核苷酸测序,从而获得多个读段,每个读段与物理umi相关联;
156.(d)鉴定与所述多个读段相关联的多个物理umi;并且
157.(e)使用(c)中获得的所述多个读段和(d)中鉴定的所述多个物理umi来测定所述样品中所述双链dna片段的序列。
158.通过引用并入
159.本文提及的所有专利、专利申请和其它出版物(包括这些参考文件中公开的所有序列)通过引用明确地并入本文,其程度如同单独出版物、专利或专利申请各自具体地和单独地表示为通过引用并入。为了通过本文其引用的上下文所表示的目的,在相关部分引用的所有文件通过引用整体并入本文。然而,任何文件的引用不应解释为承认其为关于本公开的现有技术。
160.附图简述
161.图1a的流程图显示了使用umi来对核酸片段测序的示例工作流图。
162.图1b显示了图1a中所示工作流的初始步骤中所采用的dna片段/分子和衔接头。
163.图2a示意性地显示了可以适用于各种实施方案中的五种不同的衔接头设计。
164.图2b显示了假定的过程,其中umi跳跃(jumping)发生在涉及两个臂上具有两种物理umi的衔接头的pcr反应中。
165.图2c显示了制备衔接头的过程,所述衔接头具有在双链杂交区中所述衔接头的两条链上的umi,其中所述过程使用作为用于限制酶xcm1识别序列的15
‑
mer序列(seq id no:1)。
166.图2d显示了具有p7臂顶部链(seq id no:2)和p5臂底部链(seq id no:3)的衔接头的图。
167.图2e示意性地显示了非随机umi设计,该设计提供了检测测序过程中umi序列中发生的误差的机制。
168.图3a和图3b的图显示了根据本文公开的一些方法将衔接头与双链片段连接的材料和反应产物。
169.图4a
‑
图4e显示了如本公开的方法如何能抑制测定双链dna片段的序列中的不同的误差来源。
170.图5示意性地显示了应用物理umi和虚拟umi以有效地获得长配对末端读段。
171.图6是用于处理测试样品的分散系统的框图。
172.图7a和图7b显示了实验数据,其证明了使用本文公开的方法的误差抑制的有效性。
173.图8显示的数据指示了单独使用位置信息来折拢读段会倾向于折拢实际上源于不同来源分子的读段。
174.图9绘制的经验数据显示了使用非随机umi和位置信息来折拢读段可以比单独使用位置信息提供更准确的片段估计。
175.图10以表格形式显示了用随机umi处理的三个样品中不同的误差发生。
176.图11a显示了用两种不同工具:varscan和denovo使用两种折拢方法,在gdna样品中调用(calling)体细胞突变和cnv的灵敏度和选择性。
177.图11b
‑
图11d显示了用两个不同工具:varscan和denovo使用两种折拢方法,在具有增加的样品输入的三个cfdna样品中调用体细胞突变和cnv的选择性(即假阳性率)。
178.发明详述
179.本公开关注用于对核酸测序的方法、装置、系统和计算机程序产品,所述核酸特别是具有有限数量或低浓度的核酸,如母体血浆中的胎儿cfdna或者癌症患者的血液中循环肿瘤dna(ctdna)。
180.除非另外指出,否则本文公开的方法和系统的实践涉及在本领域技术范围内的分子生物学、微生物学、蛋白质纯化、蛋白质工程、蛋白质和dna测序、以及重组dna领域中常用的常规技术和装置。此类技术和装置为本领域技术人员已知的,并且描述在许多文章和参考著作(参见,例如,sambrook et al.,“molecular cloning:a laboratory manual,”第三版(冷泉港),[2001])中。
[0181]
数值范围包括限定范围的数值。预期在整个本说明书中给出的每个最大的数值限制包括每个较低的数值限制,如同此类较低的数值限制在本文明确写出一样。在整个本说明书中给出的每个最小的数值限制包括每个较高的数值限制,如同此类较高的数值限制在本文明确写出一样。在整个本说明书中给出的每个数值范围包括落入此类较宽数值范围内的每个较窄数值范围,如同此类较窄数值范围均在本文明确写出一样。
[0182]
本文提供的标题不旨在限制本公开。
[0183]
除非本文另有限定,否则本文使用的所有技术和科学术语与本领域普通技术人员通常理解的具有相同的意义。包括本文所包括的术语的各种科学词典为本领域技术人员公知且可获得的。虽然与本文所述的方法和材料类似或等同的任何方法和材料可用于本文所公开的实施方案的实践或检验,但仍描述了一些方法和材料。
[0184]
下文紧接着定义的术语通过参考整个说明书进行更充分地描述。应理解本公开不限于所述的特定方法、方案和试剂,因为这些可根据本领域技术人员使用的语境而改变。
[0185]
定义
[0186]
如本文所用,除非上下文另外清楚地指示,否则单数术语“一个/种(a/an)”和“所述(the)”包括复数指代物。
[0187]
除非另外指出,否则核酸以5’至3’的方向从左至右书写,以及氨基酸序列以氨基至羧基的方向从左至右书写。
[0188]
独特分子索引(umi)是应用于dna分子或dna分子中鉴定的核苷酸序列,其可用于将单独的dna分子彼此区分开来。由于使用umi来鉴定dna分子,还将它们称作独特分子标识符(unique molecular identifiers)。例如参见kivioja,nature methods 9,72
‑
74(2012)。umi可以与同它们关联的dna分子一起测序以确定读段序列是否为一种源dna分子或另一种源dna分子的那些。本文中术语“umi”用于指多核苷酸的序列信息和物理多核苷酸本身两者。
[0189]
通常,对单个源分子的多种情况测序。在使用illumina的测序技术进行边合成边测序的情况下,可以在递送到流动池之前对源分子进行pcr扩增。无论是否进行pcr扩增,对应用于流动池的单独dna分子进行桥式扩增(bridge amplified)或examp扩增以生成簇。簇中的每个分子源自相同的源dna分子但是分别测序。出于误差纠正和其它目的,可以重要的是确定来自单个簇的所有读段鉴定为源自相同的源分子。umi允许此分组。通过扩增或以其它方式复制以产生dna分子的多种情况的dna分子被称为源dna分子。
[0190]
umi类似于条形码,所述条形码通常用于将一个样品的读段与其它样品的读段相区分,但是当对许多dna分子一起测序时,取而代之使用umi以将一个源dna分子与另一种相区分。由于可以有比测序运行中的样品多许多的样品中的dna分子,通常有比测序运行中的独特条形码多许多的独特umi。
[0191]
如上所述,可将umi应用于单独dna分子或在单独dna分子中鉴定。在一些实施方案中,可通过将umi物理地连接或键合至dna分子的方法(如通过经由聚合酶、核酸内切酶、转座酶等的连接(ligation)或转座等)将umi应用到dna分子。因此这些“应用”的umi还称为物理umi。在一些语境中,还可以将它们称为外源umi。将在源dna分子内鉴定出的umi称为虚拟umi。在一些语境中,还可以将虚拟umi称为内源umi。
[0192]
可以以许多方式定义物理umi。例如,它们可以是插入衔接头中或者以其它方式渗
入要测序的源dna分子中的随机、假随机或部分随机、或非随机核苷酸序列。在一些实施方案中,物理umi可以是如此独特的,以致预期它们中的每个独特地鉴定样品中存在的任何给定的源dna分子。生成了衔接头的集合,每个衔接头具有物理umi,并且将那些衔接头附接至要被测序的片段或其它源dna分子,并且单独测序的分子各自具有帮助区分它与其它片段的umi。在此类实施方案中,可以使用非常大量的不同物理umi(如数千到数百万)以独特地鉴定样品中的dna片段。
[0193]
当然,物理umi必须具有足够的长度以确保对于各个(each)和每个(every)源dna分子的这种独特性。在一些实施方案中,不太独特的分子标识符可与其它鉴定技术结合使用以确保在测序过程中独特地鉴定每个源dna分子。在此类实施方案中,多个片段或衔接头可以具有相同的物理umi。可以将其它信息(如比对位置或虚拟umi)与物理umi相组合以独特地将读段鉴定为源自单一源dna分子/片段。在一些实施方案中,衔接子包含限于相对较少数量的非随机序列的物理umi,如96个非随机序列。此类物理umi也称为非随机umi。在一些实施方案中,可以将非随机umi与序列位置信息和/或虚拟umi相组合以鉴定可归因于相同源dna分子的读段。可以将鉴定的读段可以折拢以获得反映如本文所述的源dna分子的序列的共有序列。
[0194]“虚拟独特分子索引”或“虚拟umi”是源dna分子中独特的亚序列。在一些实施方案中,虚拟umi位于源dna分子的末端处或附近。一种或多种此类独特末端位置可以独自或与其它信息相结合独特地鉴定源dna分子。取决于独特的源dna分子的数目和虚拟umi中核苷酸的数目,一种或多种虚拟umi可以独特地鉴定样品中的源dna分子。在一些情况下,需要两个虚拟独特分子标识符的组合来鉴定源dna分子。此类组合可以是非常罕见的,在样品中可能只发现一次。在一些情况下,与一种或多种物理umi组合的一种或多种虚拟umi可以一起独特地鉴定源dna分子。
[0195]“随机umi”可以认为是自一组由给予一种或多种序列长度的所有可能的不同寡核苷酸序列组成的umi中在具有或没有替换的情况下作为随机样品选择的物理umi。例如,如果umi组中的umi各自具有n个核苷酸,则该组包含4^n个彼此不同序列的umi。从4^n个umi中选出的随机样品构成随机umi。
[0196]
相反,如本文所用的“非随机umi”是指不是随机umi的物理umi。在一些实施方案中,可用的非随机umi是为特定实验或应用程序预定义的。在某些实施方案中,使用规则来为组生成序列或从组中选择样品以获得非随机umi。例如,可以生成组的序列,使得序列具有一种或多种特定的模式。在一些实施方案中,每个序列与组中每个其它序列相差特定数目(如2、3或4个)的核苷酸。也就是说,通过替换少于特定数量的核苷酸,不能将非随机umi序列转换为任何其它可用的非随机umi序列。在一些实施方案中,非随机umi选自一组umi,该组包含给予特定序列长度的少于所有可能的umi。例如,具有6个核苷酸的非随机umi可以从总共96个不同的序列中选择(而不是总共4^6=4096个可能的不同序列)。在其它实施方案中,序列不是从组中随机选择的。相反,一些序列比其它序列以更高的可能性选出。
[0197]
在一些实施方案中,其中非随机umi从具有少于所有可能的不同序列的组中选择,非随机umi的数目少于(有时甚至显著少于)源dna分子的数目。在此类实施方案中,非随机umi信息可以与其它信息(如虚拟umi和/或序列信息)相组合,以鉴定源自相同源dna分子的测序读段。
[0198]
术语“配对末端读段(paired end reads)”是指获自配对末端测序的读段,所述配对末端测序获得来自核酸片段的每个末端的一个读段。配对末端测序涉及将dna片段化成被称为插入物的序列。在诸如illumina使用的一些方案中,来自较短插入物(例如,大约数十至数百个bp)的读段被称为短插入物配对末端读段或仅仅为配对末端读段。相比之下,来自较长插入物(例如大约数千个bp)的读段被称为配偶(mate)配对读段。在本公开中,短插入物配对末端读段和长插入物配偶配对读段均可以使用并且对于测定dna片段序列的过程而言不区分。因此,术语“配对末端读段”可以指短插入物配对末端读段和长插入物配偶配对读段,这在下文中会进一步描述。在一些实施方案中,配对末端读段包含约20bp至1000bp的读段。在一些实施方案中,配对末端读段包含约50bp至500bp、约80bp至150bp或约100bp的读段。
[0199]
如本文所用,术语“比对(alignment/aligning)”是指将读段与参考序列比较,从而确定参考序列是否含有读段序列的过程。比对过程试图确定读段是否可以定位(map)至参考序列,但并不总是产生与参考序列比对的读段。如果参考序列含有读段,则读段可以被定位至参考序列,或在某些实施方案中,定位至参考序列的特定位置。在一些情况下,比对仅能判断读段是否是特定参考序列的成员(即读段是否存在于参考序列中)。例如,读段序列与人类13号染色体的参考序列的比对判断读段序列是否存在于13号染色体的参考序列中。提供该信息的工具可以被称为组成员资格测试仪(set membership tester)。在一些情况下,比对另外地指示读段序列定位于参考序列中的位置。例如,如果参考序列是整个人类基因组序列,则比对可以指示读段序列存在于13号染色体,以及还可以还指示读段序列在13号染色体的特定链和/或位点。在一些情况下,比对工具是不完善的,因为a)不能找到所有有效的比对,和b)一些获得的比对是无效的。这由于各种原因而发生,例如读段可以含有误差,并且由于单倍型差异,读段可以与参考基因组不同。在一些应用中,比对工具包括内置的错配容忍度(tolerance),其容忍一定程度的碱基对错配并仍允许将读段与参考序列比对。这能帮助鉴定读段的有效比对,所述读段在其它情况下会被错过。
[0200]
比对的读段是就其核酸分子的次序而言与诸如参考基因组的已知参考序列鉴定为匹配的一种或多种序列。比对的读段及其在参考序列上确定的位置构成序列标签。可以手动进行比对,尽管通常通过计算机算法实施该比对,因为为了实施本文公开的方法,将不可能在合理的时间段内比对读段。来自比对序列的算法的一个实例是作为illumina基因组分析流水线(illumina genomics analysis pipeline)的一部分销售的高效核苷酸数据局部比对(efficient local alignment of nucleotide data)(eland)计算机程序。或者,可以采用布隆过滤器(bloom filter)或类似的组成员资格测试仪以将读段与参考基因组比对。参见2014年4月25日提交的美国专利申请第14/354,528号,将其通过引用整体并入本文。比对中测序读段的匹配可以为100%的序列匹配或小于100%(即不完全匹配)。
[0201]
本文使用的术语“定位(mapping)”是指通过比对将读段序列归于较大序列,例如参考基因组。
[0202]
术语“多核苷酸”、“核酸”和“核酸分子”可互换使用,并且是指共价连接的核苷酸(即,对于rna,为核糖核苷酸;以及对于dna,为脱氧核糖核苷酸)序列,其中一个核苷酸的戊糖的3’位与下一个核苷酸的戊糖的5’位通过磷酸二酯基团连接。核苷酸包括任何形式的核酸的序列,包括但不限于rna和dna分子,如无细胞dna(cfdna)分子。术语“多核苷酸”包括但
不限于单链多核苷酸和双链多核苷酸。
[0203]
术语“测试样品”在本文是指通常来源于生物流体、细胞、组织、器官或生物体的样品,其包含具有待筛选拷贝数变异和其它遗传变异(例如但不限于单核苷酸多态性、插入、缺失和结构变异)的至少一种核酸序列的核酸或核酸的混合物。在某些实施方案中,样品具有至少一种核酸序列,该核酸序列的拷贝数疑似经历了变异。此类样品包括但不限于痰液/口液、羊水、血液、血液级分或细针活检样品、尿液、腹水、胸液等。虽然样品通常取自人受试者(例如,患者),但可以将分析用于来自任何哺乳动物(包括但不限于犬、猫、马、山羊、绵羊、牛、猪等),以及混合群体(如来自野外的微生物群体或来自患者的病毒群体)的样品,样品可以如从生物来源获得的那样直接使用,或者在预处理以改变样品的特性后使用。例如,此类预处理可以包括由血液制备血浆、稀释粘性流体等。预处理的方法还可以涉及但不限于过滤、沉淀、稀释、蒸馏、混合、离心、冷冻、冻干、浓缩、扩增、核酸片段化、干扰组分的灭活、试剂的添加、裂解等。如果对于样品采用此类预处理方法,则此类预处理方法通常使得感兴趣的核酸保留在测试样品中(有时以与未经处理的测试样品(例如,即未经受任何此类预处理方法的样品)中感兴趣的核酸成比例的浓度)。对于本文所述的方法,此类“经处理的”或“经加工的”样品仍被认为是生物“测试”样品。
[0204]
术语“下一代测序(ngs)”在本文是指允许克隆扩增的分子和单核酸分子的大规模平行测序的测序方法。ngs的非限制性实例包括使用可逆染料终止剂的边合成边测序和边连接边测序。
[0205]
术语“读段”是指来自一部分核酸样品的测序读段。通常,尽管非必要,读段代表样品中连续碱基对的短序列。读段可以由样品部分的a、t、c、和g中的碱基对序列,以及对碱基的正确性的概率估计(质量得分)以符号表示。其可以被存储在存储器装置中,并且视情况处理以确定其是否匹配参考序列或满足其它标准。读段可以从测序设备直接获得,或者从关于样品的存储序列信息间接获得。在一些情况下,读段是足够长度(如至少约20bp)的dna序列,其可以用于鉴定较长序列或区域,例如其可以被比对并定位至染色体或基因组区域或基因。
[0206]
术语“位点”和“比对位置”可互换使用以指代参考基因组上的独特位置(即染色体id、染色体位置和方向)。在一些实施方案中,位点可以是参考序列上的残基、序列标签或区段的位置。
[0207]
如本文所用,术语“参考基因组”或“参考序列”是指任何生物体或病毒的任何特定的已知基因组序列(不论部分或全部),其可以用于参考来自受试者的鉴定序列。例如,用于人受试者以及多种其它生物体的参考基因组见于ncbi.nlm.nih.gov的美国国家生物技术信息中心(national center for biotechnology information)。“基因组”是指以核酸序列表示的生物体或病毒的全部遗传信息。然而,应当了解,“完整”是一个相对的概念,因为即使是黄金标准参考基因组也预期包括缺口和误差。
[0208]
在多个实施方案中,参考序列显著大于与其比对的读段。例如,其可以大至少约100倍、或大至少约1000倍、或大至少约10,000倍、或大至少约105倍、或大至少约106倍、或大至少约107倍。
[0209]
在一个实例中,参考序列为全长的人基因组序列。此类序列可以被称为基因组参考序列。在另一实例中,参考序列限于特定的人染色体,如13号染色体。在一些实施方案中,
参考y染色体是来自人基因组版本hg19的y染色体序列。此类序列可以被称为染色体参考序列。参考序列的其它实例包括其它物种的基因组以及任何物种的染色体、亚染色体区域(如链)等。
[0210]
在一些实施方案中,用于比对的参考序列可以具有读段长度的约1至约100倍的序列长度。在此类实施方案中,比对和测序被认为是靶向比对或测序,而非全基因组比对或测序。在这些实施方案中,参考序列通常包含感兴趣的基因和/或其它约束序列(constrained sequence)。
[0211]
在多个实施方案中,参考序列是来源于多个个体的共有序列或其它组合。然而,在某些应用中,参考序列可以取自特定个体。
[0212]
当在核酸或核酸的混合物的上下文中使用时,术语“来源(derived)”在本文是指核酸获自其所源于的来源的手段。例如,在一个实施方案中,来源于两种不同基因组的核酸的混合物意指核酸(如cfdna)通过诸如坏死或细胞凋亡的天然存在的过程由细胞自然地释放。在另一实施方案中,来源于两种不同基因组的核酸的混合物意指从来自受试者的两种不同类型的细胞中提取核酸。
[0213]
术语“生物流体”在本文是指取自生物来源的液体,并且包括例如血液、血清、血浆、痰、灌洗液、脑脊液、尿液、精液、汗液、泪液、唾液等。如本文所用,术语“血液”、“血浆”和“血清”明确涵盖其级分或经处理的部分。类似地,如果样品取自活检、拭子、涂片等,则“样品”明确地涵盖来源于活检、拭子、涂片等的经处理的级分或部分。
[0214]
如本文所用,术语“染色体”是指活细胞的具有遗传性的基因载体,其来源于包含dna和蛋白质组分(特别是组蛋白)的染色质链。本文采用国际上认可的惯用个体人基因组染色体编号系统。
[0215]
如本文所用,术语“多核苷酸长度”是指参考基因组的序列或区域中核酸分子(核苷酸)的绝对数。术语“染色体长度”是指以碱基对给出的染色体的已知长度,例如人染色体的ncbi36/hg18装配中提供,参见万维网上的|genome|.|ucsc|.|edu/cgi
‑
bin/hgtracks?hgsid=167155613&chrominfopage=。
[0216]
如本文使用的术语“引物”是指当置于诱导延伸产物合成的条件(例如该条件包括核苷酸、诱导剂如dna聚合酶、必要的离子和分子,以及合适的温度和ph)下时,能够充当合成起始点的分离的寡核苷酸。为了扩增的最大效率,引物可以优选是单链的,但可选地可以是双链的。如果是双链的,则首先处理引物以使其链分开,然后用于制备延伸产物。引物可以为寡脱氧核糖核苷酸。引物足够长以在诱导剂的存在下引发延伸产物的合成。引物的确切长度取决于多种因素,包括温度、引物来源、方法的使用和用于引物设计的参数。
[0217]
引言和背景
[0218]
下一代测序(ngs)技术发展迅速,为推动研究和科学,以及依赖于遗传和相关生物信息的医疗保健和服务提供了新的工具。以大量平行的方式进行ngs方法,为测定生物分子序列信息提供越来越高的速度。然而,许多ngs方法和相关的样品操作技术引入了误差,使得所得到的序列具有相对较高的误差率,范围从几百个碱基对中一个误差到几千个碱基对中一个误差。此类误差率有时对于测定遗传基因信息(如种系突变)是可接受的,因为此类信息在大多数体细胞中是一致的,所述体细胞提供了测试样品中许多拷贝的相同基因组。当在无误差的情况下读取相同序列的许多拷贝时,源自读取序列的一个拷贝的误差具有轻
微或可移除的影响。例如,如果来自序列的一个拷贝的误差读段不能被适当地比对到参考序列,可以简单地将其从分析中丢弃。来自相同序列的其它拷贝的无误差读段仍可以为有效分析提供足够信息。或者,可以将不同碱基对无视为源自已知或无知的误差来源,而非丢弃具有与来自相同序列中的其它读段不同的碱基对的读段。
[0219]
然而,此类误差纠正方法未良好运行以检测具有低等位基因频率的序列,如在肿瘤组织的核酸、循环肿瘤dna、母体血浆中低浓度胎儿cfdna中发现的亚克隆体细胞突变、病原体耐药性突变等。在这些例子中,一个dna片段可以在序列位点处携带感兴趣的体细胞突变,而相同序列位点处的许多其它片段不具有感兴趣的突变。在这种情况下,在常规测序中可能未使用或错误解读来自突变dna片段的测序读段或碱基对,从而丢失了用于检测感兴趣突变的信息。
[0220]
由于这些各种误差来源,单独增加测序的深度不能确保检测具有非常低的等位基因频率(如<1%)的体细胞变异。本文公开的一些实施方案提供了双链体测序方法,该方法在感兴趣的有效序列的信号较低(例如具有低等位基因频率的样品)的情况下能够有效抑制误差。方法将虚拟独特分子索引(umi)和位于测序衔接头(如illumina衔接头)的一个臂或两个臂上的短物理独特分子索引结合使用。这些实施方案基于使用在衔接头序列上的物理umi和在样品dna片段序列上的虚拟umi的策略。在一些实施方案中,读段的比对位置也用于抑制误差。例如,当多个读段(或读段对)共享物理umi并在参考上的相同间隔内(约束的位置范围)比对时,预期所述读段源自单个dna片段。与读段相关联的物理umi、虚拟umi,和比对位置提供了“索引”,其(单独或组合)独特地与来自样品的特定双链dna片段相关联。使用这些索引,可以鉴定源自单一dna片段(单分子)的多个读段,该片段可以只是来自相同基因组位点的许多片段之一。使用来自单一dna分子的多个读段,可以有效地进行误差纠正。例如,测序方法可以获得来自源自相同dna片段的多个读段的共有核苷酸序列(以下简称“共有序列”),其中纠正不丢弃该dna片段的有效序列信息。
[0221]
衔接头设计可以提供物理umi,其允许确定读段源自dna片段的哪条链。一些实施方案利用这一点来确定源自dna片段的一条链的读段的第一共有序列,和互补链的第二共有序列。在许多实施方案中,共有序列包括在所有或大部分读段中检测到的碱基对而排除在少数读段中出现的碱基对。可以实施共有(consensus)的不同标准。基于umi或比对位置来组合读段以获得共有序列的步骤还称为“折拢”所述读段。使用物理umi、虚拟umi,和/或比对位置,可以确定第一和第二共有序列的读段来源于相同的双链片段。因此,在一些实施方案中,使用对相同dna分子/片段获得的第一和第二共有序列来确定第三共有序列,其中所述第三共有序列包括第一和第二共有序列共同的碱基对而排除两者之间不一致的那些。在替代实施方案中,可以通过折拢源自相同片段的两条链的所有读段而不是通过比较获得自两条链的两条共有序列来直接获得仅一条共有序列。最后,可以从第三或仅一条共有序列来测定片段的序列,所述共有序列包含与源自片段的两条链的读段间相一致的碱基对。
[0222]
各种实施方案结合dna片段的两条链的读段来抑制误差。然而,在一些实施方案中,所述方法将物理和虚拟umi应用至单链核酸(如dna或rna)片段,并组合共享相同物理和虚拟umi的读段来抑制误差。可以采用各种方法来捕获样品中的单链核酸片段。
[0223]
在一些实施方案中,所述方法组合不同类型的索引来确定其上衍生读段的源多核苷酸。例如,所述方法可以使用物理和虚拟umi两者来鉴定源自单一dna分子的读段。除了物
理umi以外,通过使用umi的第二种形式,物理umi可以短于当仅使用物理umi来确定源多核苷酸时。这种方法对文库制备的性能影响最小,并且不需要额外的测序读段长度。
[0224]
本公开方法的应用包括:
[0225]
·
体细胞突变检测的误差抑制。例如,具有小于0.1%等位基因频率的突变检测在循环肿瘤dna的液体活检中是非常关键的。
[0226]
·
纠正前定相(prephasing),定相(phasing)和其它测序误差以实现高质量的长读段(如1x1000 bp)。
[0227]
·
降低固定读段长度的循环时间,并且通过该方法纠正增加的定相和前定相。
[0228]
·
使用片段两侧的umi以创建虚拟长配对末端读段。例如,通过在重复上做出500+50来缝合(stitch)2x500读段。
[0229]
使用umi对核酸片段测序的实例工作流
[0230]
图1a的流程图显示了使用umi对核酸片段测序的示例工作流100。操作102提供了双链dna的片段。可以例如通过片段化基因组dna,收集天然片段化的dna(如cfdna或ctdna),或从rna合成dna片段来获得dna片段。在一些实施方案中,为了自rna合成dna片段,使用多聚a选择或消耗核糖体rna首先纯化了选择的mrna,然后将选择的mrna化学地片段化并使用随机六聚体引发而转化为单链cdna。产生cdna的互补链以创建准备用于文库构建的双链cdna。为了从基因组dna(gdna)获得双链dna片段,对输入gdna片段化(如通过流体力学剪切,雾化,酶促片段化等),以产生适当长度,如约1000bp、800bp、500,或200bp的片段。例如,雾化可以在短时间内将dna打碎为不到800bp的片段。该过程产生含有3’和/或5’突出端的双链dna片段。
[0231]
图1b显示了图1a中工作流100的初始步骤中采用的dna片段/分子和衔接头。尽管在图1b中仅显示了一个双链片段,但在该工作流中可以同时制备数千到数百万个样品片段。通过物理方法的dna片段化来产生包括3’突出端、5’突出端和平端的混合物的异质末端。突出端将具有不同的长度并且末端可以是或可以不是磷酸化的。获得自操作102对基因组dna片段化的双链dna片段的例子示为图1b中的片段123。
[0232]
片段123具有在左侧末端处的3’突出端和示于右侧末端处的5’突出端两者,并且用ρ和标记,这指示可用作虚拟umi的片段中的两条序列,当单独使用或与要连接到片段的衔接头的物理umi组合使用时,该虚拟umi可以独特地鉴定片段。umi独特地与样品中的单一dna片段相关联,所述样品包含源多核苷酸和其互补链。物理umi是连接至源多核苷酸,其互补链或源自源多核苷酸的多核苷酸的寡核苷酸序列。虚拟umi是源多核苷酸、其互补链,或源自源多核苷酸的多核苷酸内的序列。在这个方案中,还可以将物理umi称为外在umi,并将虚拟umi称为内在umi。
[0233]
两个序列ρ和实际上各自是指在相同基因组位点处的两个互补序列,但为了简单起见,它们仅在本文示出的一些双链片段的一条链上指示。可以在工作流的后续步骤中使用虚拟umi(如ρ和)以帮助鉴定源自单一dna源片段的一条或两条链的读段。凭借如此鉴定的读段,可以折拢它们以获得共有序列。
[0234]
如果通过物理方法来产生dna片段,则进行工作流100以执行末端修复操作104,该末端修复操作产生具有5
’‑
磷酸化末端的平端片段。在一些实施方案中,该步骤使用t4 dna聚合酶和klenow酶将从片段化产生的突出端转化为平端。这些酶的3’至5’核酸外切酶活性
除去3’突出端并且5’至3’聚合酶活性添补5’突出端。另外,该反应中t4多核苷酸激酶磷酸化dna片段的5’末端。图1b中的片段125是末端修复的平端产物的例子。
[0235]
末端修复后,工作流100进行至操作106以在片段的3’末端腺苷酸化,其也称作a加尾(a
‑
tailing)或da加尾(da
‑
tailing),因为将单个datp添加到平片段的3’末端以阻止它们在衔接头连接反应中相互连接。图1b中的双链分子127显示了具有平端的a加尾的片段,具有3
’‑
da突出端和5
’‑
磷酸末端。如图1b的项129中看到的两个测序衔接头各自的3’末端上的单个“t”核苷酸提供了与插入物的每个末端上的3
’‑
da突出端互补的突出端,用于将两个衔接头连接至插入物。
[0236]
在对3’末端腺苷酸化后,工作流100进行至操作108以将部分双链衔接头与片段的两个末端连接。在一些实施方案中,反应中使用的衔接头包含均彼此不同的寡核苷酸,所述寡核苷酸提供物理umi以将测序读段与单一源多核苷酸相关联,所述单一源多核苷酸可以是单链或双链dna片段。因为所有物理umi寡核苷酸是不同的,所以连接到特定片段的两端的两个umi寡核苷酸彼此不同。此外,用于特定片段的两个物理umi不同于每个其它片段的物理umi。在这方面,两个物理umi独特地与特定片段相关联。
[0237]
图1b的项129显示了要连接至双链片段的两个衔接头,所述双链片段包含该片段末端附近的两个虚拟umiρ和由于各种实施方案可以使用illumina的ngs平台来获得读段并检测感兴趣的序列,因此基于illumina平台的测序衔接头来显示这些衔接头。左侧所示的衔接头包含在其p5臂上的物理umiα,而在右侧的衔接头包含在其p5臂上的物理umiβ。在具有5’变性末端的链上,在从5’到3’方向上,衔接头具有p5序列、物理umi(α或β),和读段2引物序列。在具有3’变性末端的链上,在从3’到5’方向上,衔接头具有p7’序列、索引序列,和读段1引物序列。p5和p7’寡核苷酸与结合到illumina测序平台的流动池表面的扩增引物互补。在一些实施方案中,索引序列提供了跟踪样品来源的手段,从而允许在测序平台上多个样本的多路复用(multiplexing)。衔接头和测序平台的其它设计可用于各种实施方案。衔接头和测序技术在以下部分进一步描述。描述于图1b中的反应将不同序列添加到基因组片段中每条连的5’和3’末端。在图1b中示出了来自上述相同片段的连接产物131。在5’到3’方向上,该连接产物131在其顶部链上具有物理umiα,虚拟umiρ和虚拟在5’到3’方向上,该连接产物在其底部链也具有物理umiβ、虚拟和虚拟umiρ。示于132中的连接产物和其中包含的物理umi和虚拟umi类似于图3a上半部分中的那些。本公开体现了使用与illumina提供的那些不同的测序技术和衔接头的方法。
[0238]
在一些实施方案中,通过琼脂糖凝胶电泳或磁珠来纯化和/或按大小选择该连接反应的产物。然后pcr扩增该按大小选择的dna以富集在两个末端具有衔接头的片段。参见块110。图3a的下半部分显示了连接产物的两条链经历pcr扩增,产生具有不同物理umi(α和β)的两个片段家族。两个家族各自仅具有一个物理umi。所述两个家族均具有虚拟umiρ和但参照物理umi,虚拟umi的顺序是不同的:相对于一些实施方案纯化pcr产物并选择适合于后续簇生成的大小范围的模板
[0239]
然后进行工作流100以在illumina平台上簇扩增pcr产物。参见操作112。通过将pcr产物成簇,使用衔接头上的不同索引序列跟踪不同样品,可以合并文库用于多路复用,例如每道直至12个样品。
[0240]
簇扩增后,可以通过在illumina平台上边合成边测序来获得测序读段。参见操作
114。尽管这里描述的衔接头和测序过程基于illumina平台,代替illumina平台或在illumina平台外可以使用其它测序技术,特别是ngs方法
[0241]
还预期源自图1b和图3a中所示片段的测序读段包含umi或工作流100使用该特征以将具有相同物理umi和/或相同虚拟umi的读段折拢成一个或多个组,从而获得一种或多种共有序列。参见操作116。共有序列包含核苷酸碱基,其在折拢组中的读段间是一致的或满足共有标准。如操作116中所示,可以以各种方式组合物理umi、虚拟umi和位置信息以折拢读段来获得共有序列,用于测定片段或其至少一部分的序列。在一些实施方案中,将物理umi与虚拟umi相组合以折拢读段。在其它实施方案中,将物理umi与读段位置组合以折拢读段。可以通过各种技术,使用不同位置测量法(如读段的基因组坐标、参考序列上的位置,或染色体位置)获得读段位置信息。在进一步的实施方案中,将物理umi、虚拟umi和读段位置相组合以折拢读段。
[0242]
最后,工作流100使用一种或多种共有序列以测定来自样品的核酸片段的序列。参见操作118。这可以涉及测定核酸片段的序列为第三共有序列或上述的单一共有序列。
[0243]
在包含与操作108
‑
119类似的操作的具体实施方案中,使用非随机umi对来自样品的核酸分子测序的方法涉及以下:(a)将衔接头应用至样品中dna片段的两端,其中衔接头各自包含双链杂交区、单链5’臂,单链3’臂,和非随机umi,从而获得dna
‑
衔接头产物;(b)扩增所述dna
‑
衔接头产物以获得多个扩增的多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得与多个非随机umi相关联的多个读段;(d)从多个读段,鉴定共享共同非随机umi和共同读段位置的读段;以及(e)从所鉴定的读段,测定dna片段至少一个部分的序列。
[0244]
在各种实施方案中,获得的测序读段与物理umi(即随机或非随机umi)相关联。在此类实施方案中,umi为读段序列的部分或不同读段序列的部分,其中已知不同的读段和所讨论的读段来自相同的片段;例如,通过配对末端阅读或位置特异性信息。如虚拟umi。
[0245]
在一些实施方案中,测序读段是配对末端读段。每个读段包含非随机umi或通过配对末端读段与非随机umi相关联。在一些实施方案中,读段长度短于dna片段或短于片段长度的一半。在此类情况下,有时不测定整个片段的完整序列。确切地,测定片段的两个末端。例如,dna片段可以是500bp长,从中能衍生出两个100bp的配对末端读段。在该实例中,可以测定位于片段的每个末端的100个碱基,并且在不使用其它读段信息的情况下,不能测定片段中部的300个bp。在一些实施方案中,如果两个配对末端读段足够的长以重叠,则可以从两个读段测定整个片段的完整序列。例如,参见结合图5描述的示例。
[0246]
在一些实施方案中,每个非随机umi与每个其它非随机umi在所述非随机umi的相应位置处相差至少两个核苷酸。在各种实施方案中,多个非随机umi包含不超过约10,000个、1,000个,或100个独特非随机umi。在一些实施方案中,多个非随机umi包含96个独特非随机umi。
[0247]
在一些实施方案中,衔接子在该衔接子的双链区域中具有双链体非随机umi,并且读段各自包含一个末端上的第一非随机umi和在另一末端上的第二非随机umi。
[0248]
衔接头和umi
[0249]
衔接头
[0250]
除了上述示例工作流中描述的衔接头设计之外,衔接头的其它设计可以用在本文公开的方法和系统的各种实施方案中。图2a示意性显示了带有umi的五种不同的衔接头设
计,其可以在各种实施方案中采用。
[0251]
图2a(i)显示了标准illumina双重索引衔接头。衔接头是部分双链的,并且通过退火对应于两条链的两个寡核苷酸形成。两条链具有许多互补碱基对(如12
‑
17bp),其允许两条寡核苷酸在要与dsdna片段连接的末端处退火。要在配对末端读段两个末端上连接的dsdna片段也称为插入物。其它碱基对在两条链上不互补,导致具有两个松散(floppy)突出端的叉形衔接头。在图2a(i)的实例中,互补碱基对是读段2引物序列和读段1引物序列的部分。读段2引物序列的下游是单个核苷酸3
’‑
t突出端,其提供与要测序的dsdna片段的单个核苷酸3
’‑
a突出端互补的突出端,这能促进两个突出端的杂交。读段1引物序列位于附接磷酸基团的互补链的5’末端。磷酸基团促进读段1引物序列的5’末端与dna片段的3
’‑
a突出端相连接。在具有5’松散突出端的链(顶部链)上,在从5’到3’的方向上,衔接头具有p5序列、i5索引序列,和读段2引物序列。在具有3’松散突出端的链上,在从3’到5’的方向上,衔接头具有p7’序列,i7索引序列,和读段1引物序列。p5和p7’寡核苷酸与结合至illumina测序平台流动池表面的扩增引物互补。在一些实施方案中,索引序列提供了追踪样品来源的手段,从而允许测序平台上多种样品的多路复用。
[0252]
图2a(ii)显示了衔接头,所述衔接头具有单一物理umi,替换示于图2a(i)中的标准双重(dual)索引衔接头的i7索引区域。衔接头的该种设计反映了上文结合图1b描述的示例工作流中显示的。在某些实施方案中,将物理umiα和β设计为仅在双链衔接头的5’臂上,导致在每条链上仅具有一个物理umi的连接产物。相比之下,掺入衔接头两条链中的物理umi导致在每条链上具有两个物理umi的连接产物,加倍了对物理umi测序的时间和成本。然而,本公开体现了在衔接头的两条上采用物理umi的方法,如图2a(iii)
‑
2a(vi)中描绘,所述方法提供了可用于折拢不同读段以获得共有序列的额外信息。
[0253]
在一些实施方案中,衔接头中的物理umi包含随机umi。在一些实施方案中,衔接头中的物理umi包含非随机umi。
[0254]
图2a(iii)显示了具有添加到标准双重索引衔接头的两个物理umi的衔接头。这里所示的物理umi可以是随机umi或非随机umi。第一物理umi位于i7索引序列的上游,并且第二物理umi位于i5索引序列的上游。图2a(iv)显示了也具有添加至标准双重索引衔接头的两个物理umi的衔接头。第一物理umi位于i7索引序列的下游,并且第二物理umi位于i5索引序列的下游。类似地,两个物理umi可以是随机umi或非随机umi。
[0255]
如若已知有关两个非互补物理umi的先验或后验信息,则在单链区的两个臂上具有两个物理umi的衔接头(如图2a(iii)和2(iv)中所示的那些)可以连接双链dna片段的两条链。例如,研究人员可以知道umi 1和umi 2的序列,之后将它们并入图2a(iv)中所示的设计中的相同衔接头。该关联信息可以用于推断具有umi 1和umi 2的读段源自与衔接头连接的dna片段的两条链。因此,不仅可以折拢具有相同物理umi的读段,而且还可以折拢具有两个未互补物理umi之任一的读段。有趣的是,并如下讨论,称为“umi跳跃”的现象可能使衔接头单链区上物理umi之间的关联的推断复杂化。
[0256]
图2a(iii)和图2a(iv)中的衔接头的两条链上的两个物理umi既不位于相同位点处,也不彼此互补。然而,本公开体现了采用物理umi的方法,所述物理umi在衔接头两条链上的相同位点处和/或彼此互补。图2a(v)显示了双链体衔接头,其中两个物理umi在双链区上在衔接头的末端处或附近互补。在一些实施方案中,衔接头末端附近的物理umi可以距离
衔接头的双链区末端1个核苷酸、2个核苷酸、3个核苷酸、4个核苷酸、5个核苷酸,或约10个核苷酸,所述末端与衔接头的分叉区相反。两个物理umi可以是随机umi或非随机umi。图2a(vi)显示了与图2a(v)的衔接头相似但更短的衔接头,但是它不包含索引序列或与流动池表面扩增引物互补的p5和p7’序列。类似地,两个物理umi可以是随机umi或非随机umi。
[0257]
如图2a(v)和图2a(vi)所示,与在单链臂上具有一种或多种单链物理umi的衔接头相比,在双链区上具有双链物理umi的衔接头可以提供与衔接头连接的双链dna片段的双链之间的直接联系。由于双链物理umi的两条链彼此互补,双链umi的两条链之间的关联固有地由互补序列反映,并可以在无需先验信息或后验信息的情况下建立。该信息可以用于推断具有衔接头的双链物理umi的两个互补序列的读段源自与衔接头连接的相同dna片段,但是物理umi的两条互补序列连接到dna片段的一条链上的3’末端和另一条链上的5’末端。因此,不仅可以折拢两个末端上具有两个物理umi序列的相同顺序的读段,而且还可以折拢两个末端上具有两个互补序列的相反顺序的读段。
[0258]
在一些实施方案中,使用相对短的物理umi可以是有利的,因为短物理umi更易于掺入衔接头中。此外,更短的物理umi在扩增片段中更快和更易于测序。然而,随着物理umi变得很短,不同物理umi的总数可以变得小于样品处理所需的衔接头分子数。为了提供足够的衔接头,必须在两个或更多个衔接头分子中重复相同的umi。在此类情况下,可以将具有相同物理umi的衔接头连接到多种源dna分子。然而,当与其它信息(如虚拟umi和/或读段的比对位置)相组合时,这些短物理umi可以提供足够的信息以将读段独特地鉴定为源自样品中特定源多核苷酸或dna片段。这是如此,因为即使可以将相同的物理umi连接到两个不同的片段,不太可能的是两个不同的片段也碰巧具有相同的比对位置,或充当虚拟umi的匹配亚序列。因此,如果两个读段具有相同的短物理umi和相同的比对位置(或相同的虚拟umi),则该两个读段可能源自相同的dna片段。
[0259]
此外,在一些实施方案中,读段折拢基于插入物的两个末端上的两个物理umi。在此类实施方案中,将两个非常短的物理umi(如4bp)相组合以确定dna片段的来源,两个物理umi的组合长度为区分不同的片段提供足够的信息。
[0260]
在各种实施方案中,物理umi为约12个碱基对或更短、约11个碱基对或更短、约10个碱基对或更短、约9个碱基对或更短、约8个碱基对或更短、约7个碱基对或更短、约6个碱基对或更短、约5个碱基对或更短、约4个碱基对或更短、或约3个碱基对或更短。在一些实施方案中,其中物理umi是非随机umi,该umi为约12个碱基对或更短、约11个碱基对或更短、约10个碱基对或更短、约9个碱基对或更短、约8个碱基对或更短、约7个碱基对或更短、或约6个碱基对。
[0261]
umi跳跃可影响对衔接头(如图2a(ii)
‑
(iv)的衔接头中)的一个臂或两个臂上物理umi之间关联的推断。已经观察到,当将这些衔接头应用到dna片段时,扩增产物可包含比样品中实际片段数目更大数目的具有独特物理umi的片段。
[0262]
此外,当应用在两个臂上具有物理umi的衔接头时,认为在一个末端上具有共同物理umi的扩增片段在另一末端具有另一个共同物理umi。然而,有时情况并非如此。例如,在一个扩增反应的反应产物中,一些片段可以在它们的两个末端上具有第一物理umi和第二物理umi;其它片段可以具有第二物理umi和第三物理umi;其它片段可以具有第一物理umi和第三物理umi;还有其它片段可以具有第三物理umi和第四物理umi,等等。在该实例中,可
能难以确定这些扩增片段的源片段。显然,在扩增过程中,可以已经通过另一个物理umi将该物理umi“交换掉”。
[0263]
解决该umi跳跃问题的一种可能的方法仅将共享两个umi的片段认为源自相同源分子,而将在分析中排除仅共享一个umi的片段。然而,仅共享一个物理umi的这些片段中的一些可以确实与共享两个物理umi的片段源自相同的分子。通过将仅共享一个物理umi的片段排除在考虑之外,可能会丢失有用的信息。另一种可能的方法将具有一个共同物理umi的任何片段认为源自相同的源分子。但是,该方法不允许组合片段的两个末端上的两个物理umi用于下游分析。此外,在任一方法下,对于上述实例,共享第一和第二物理umi的片段不会认为与共享第三和第四物理umi的片段源自相同的源分子。这可能是真的,也可能不是真的。第三种方法可以通过使用具有单链区的两条链上的物理umi的衔接头(如图2a(v)
‑
(vi)中的衔接头)解决umi跳跃问题。在描述umi跳跃根本的假设机制后,第三种方法进一步描述如下。
[0264]
图2b显示了假设的过程,其中umi跳跃发生在pcr反应中,所述反应涉及在两个臂上具有两个物理umi的衔接头。两个物理umi可以是随机umi或非随机umi。umi跳跃的实际的根本机制和这里描述的假设过程不影响本文公开的衔接头和方法的效用。pcr反应开始于提供至少一个双链源dna片段202和衔接头204和206。衔接头204和206与图2a(iii)
‑
(iv)中显示的衔接头类似。衔接头204在其5’臂上具有p5衔接头序列和α1物理umi。衔接头204在其3’臂上也具有p7’衔接头序列和α2物理umi。衔接头206在其5’臂上具有p5衔接头序列和β2物理umi,以及在其3’臂上的p7’衔接头序列和β1物理umi。该过程通过将衔接头204和衔接头206连接到片段202来进行,获得连接产物208。该过程通过变性连接产物208来进行,导致单链、变性的片段212。同时,反应混合物通常包括在此阶段的残留衔接头。由于即使这个过程已经涉及除去过多的衔接头(如使用固相可逆固定(spri)磁珠),一些衔接头仍然留在反应混合物中。这些留下的衔接头显示为衔接头210,该衔接头210类似于衔接头206,只是衔接头210在其3’和7’臂上分别具有物理umiγ1和γ2。产生变性片段212的变性条件也产生变性衔接头寡核苷酸216,所述变性衔接头寡核苷酸216在其p7’衔接头序列附近具有物理umiγ1。
[0265]
pcr反应涉及用pcr引物214引发变性的片段212并延伸所述引物214,从而形成双链片段,然后对该双链片段变性以形成与片段212互补的单链、中间片段220。pcr过程还用pcr引物218引发变性的寡核苷酸216并延伸引物218,从而形成双链片段,然后对该双链片段变性以形成与片段212互补的单链中间衔接头片段222。在pcr扩增的下一循环之前,将中间衔接头寡核苷酸222与中间片段220在p7’末端附近且物理umiβ1下游杂交。杂交区对应于衔接头206和衔接头210的单链区,因为这些单链区共享相同的序列。
[0266]
中间片段220和中间衔接头寡核苷酸222的杂交产物提供了模板,然后可以通过p7’pcr引物224在寡核苷酸222的5’末端处引发并加以延伸。延伸期间,当中间衔接头寡核苷酸222结束时,该延伸模板转换为中间片段220。模板转换为umi跳跃提供了可能的机制。延伸和变性后,产生了单链片段226,该片段与中间片段220互补,但其具有物理umiγ1而不是中间片段220中的物理umiβ1。类似地,单链片段226与片段212相同,只是它具有物理umiγ1而不是物理umiβ1。
[0267]
在本公开的一些实施方案中,使用在衔接头双链区的两条链上具有物理umi的衔
接头(如图2a(v)
‑
(vi)中的衔接头)可以阻止或减少umi跳跃。这可能是因为这样的事实,即在双链区域的一个衔接头上的物理umi不同于在所有其它衔接头上的物理umi。这有助于减少中间衔接头寡核苷酸与中间片段之间的互补性,从而避免杂交,诸如对中间寡核苷酸222和中间片段220所示的杂交,从而减少或阻止umi跳跃。
[0268]
随机物理umi和非随机物理umi
[0269]
在上述衔接头的一些实施方案中,衔接头中的物理umi包括随机umi。在一些实施方案中,每个随机umi与应用于dna片段的每个其它随机umi不同。换而言之,从包含给定序列长度的所有可能的不同umi的一组umi中在没有替换的情况下随机选择随机umi。在其它实施方案中,在具有替换的情况下随机选择随机umi。在这些实施方案中,由于随机几率,两个衔接头可以具有相同的umi。
[0270]
在一些实施方案中,衔接头中的物理umi包含非随机umi。在一些实施方案中,多个衔接头包含相同的非随机umi序列。例如,一组96个不同的非随机umi可以应用于来自样品的100,000个独特的分子/片段。在一些实施方案中,所述组的每个非随机umi与组的每个其它umi相差两个核苷酸。换而言之,每个非随机umi需要替换其核苷酸的至少两个,之后匹配用于测序的任何其它非随机umi的序列。在其它实施方案中,所述组的每个非随机umi与组的每个其它umi相差三个或更多个核苷酸。
[0271]
图2c显示了用于制备在双链区中衔接头两条链上具有随机umi的衔接头的过程,其中在两条链上的两个衔接头彼此互补。通过提供具有杂交的双链区和两个单链臂的测序衔接头230启动该过程。所产生的衔接头类似于图2a(v)所示的衔接头。在这里所示的例子中,d7xx序列对应于图2a(v)中的i7索引序列;sbs12’序列对应于图2a(v)中的读段1引物序列;d50x对应于图2a(v)中的i5索引序列;以及sbs3对应于图2a(v)中的读段2引物序列。测序衔接头232在sbs12’读段引物序列的双链杂交区上游的末端处包含15
‑
mer突出端ccannnnannnntgg(seq id no:1)。字母n表示随机核苷酸,其中a和tgg之间的四个将用于提供在sbs12’链5’末端处的物理umi。15
‑
mer突出端可以被限制酶xcm1识别,因为xcm1识别具有在5’末端的cca和在3’末端的tgg的15
‑
mer。然后,使用15
‑
mer作为延伸模板,继续过程230以延伸sps3链的3’末端,从而产生延伸产物234。延伸产物234在sbs3链上的15
‑
mer的中间点(对应于sbs12’链上的腺苷)处具有酪氨酸。酪氨酸残基将成为过程230的衔接头末端产物的双链区的3’末端的残基。酪氨酸残基可以与插入物的3’a
‑
尾处的腺苷残基杂交。
[0272]
过程230通过应用限制酶xcm1进行以消化延伸产物234的新延伸末端。xcm1是识别在5’具有cca且在3’具有tgg的15
‑
mer的限制性内切核酸酶,并且其磷酸二酯酶活性通过切断从caa 5’末端数第8个和第9个核苷酸之间的磷酸二酯键来消化核酸链。该消化机制消化延伸产物234的双链末端,直接在sbs12’链上的腺苷残基的下游且sbs3链上酪氨酸残基的下游。该消化导致衔接头236,所述衔接头236在sbs12’序列上游其双链区5’末端处具有4个随机核苷酸。衔接头236在sbs3序列下游其双链区的3’末端处也具有酪氨酸突出端和四个随机核苷酸。每条链上的四个随机核苷酸提供物理umi,并且两条链上的两个物理umi彼此互补。
[0273]
图2d显示了具有sbs13臂顶部链(seq id no:2)和sbs13臂底部链(seq id no:3)的衔接头的图,显示了衔接头中的核苷酸。该衔接头与图2c中的衔接头236类似,但其具有xcm1的识别位点与衔接头的读段序列之间的四个碱基对。此外,图2d所示的衔接头是衔接
头236的缩短版本,其消除了衔接头中的p7/p5和索引序列,这增加了衔接头的稳定性。在双链区中的衔接头的顶部链(seq id no:2)上,从5’末端开始,衔接头具有用于物理umi的四个随机核苷酸,接着是作为用于限制酶xcm1的识别位点的tgg,接着是读段序列上游的tcgc。掺入tcgc核苷酸以对衔接头提供稳定性。它们在一些实施方案中是可选的。
[0274]
可以添加核苷酸以在衔接头生产,样品制备和加工中提供稳定性。已经观察到,即使在室温下,在提供额外的tcgc碱基后增强了用于创建初始衔接头模板的顶部和底部寡聚物的退火效率。因为衔接头生产过程中的klenow延伸和xcm1消化在较高的温度下(分别为30℃和37℃)进行,所以添加tcgc可以增强衔接头稳定性。除了tcgc之外,可以使用不同的序列或不同的核苷酸长度来改善衔接头的稳定性。
[0275]
在一些实施方案中,可以将除稳定序列之外的附加序列掺入衔接头用于其它目的,而不影响衔接头为dna片段提供独特索引的功能。双链区中的衔接头的底部链(seq id no:3)与顶部链互补,只是它在3’末端包含t突出端。底部链处的四个随机核苷酸提供第二物理umi。
[0276]
随机umi,如图2c和2d中显示的随机umi提供了比相同序列长度的非随机umi更大数目的独特umi。换而言之,与非随机umi相比,随机umi更可能为独特的。然而,在一些实施方案中,非随机的umi可以更容易制造或具有较高的转化效率。当非随机umi与其它信息(如序列位置和虚拟umi)相结合时,它们可以提供有效的机制来对dna片段的源分子索引化。
[0277]
在各种实施方案中,考虑各种因素来鉴定非随机umi,所述因素包括但不限于检测umi序列内的误差的手段、转化效率、测定相容性、gc含量、均聚物,和生产事项(manufacturing considerations)等。
[0278]
例如,可以设计非随机umi以提供用于促进误差检测的机制。图2e示意性地显示了非随机umi设计,该设计为检测测序过程期间在umi序列中发生的误差提供了机制。根据该设计,非随机umi各自具有六个核苷酸并且与每个其它umi相差至少两个核苷酸。如图2e所示,非随机umi 244与非随机umi 242的差异在于从左边起的前两个核苷酸,如通过umi 244中加下划线的核苷酸t和g以及umi 242中的核苷酸a和c示出。umi 246是鉴定为读段的一部分的序列,并且它与过程中所提供的衔接头的所有其它umi不同。由于推测读段中的umi序列来源于衔接头中的umi,在测序过程中(如在扩增或测序过程中)可能已经出现误差。umi 242和umi 244示为与读段中的umi 246最相似的两个umi。可以看出,umi 246与umi 242的不同之处在于从左侧起的第一个核苷酸中的一个核苷酸,其是t而不是a。此外,umi 246与umi 244的之处也是一个核苷酸,尽管在从左边起的第二个核苷酸处,其是c而不是g。因为读段中的umi 246与umi 242和umi 244两者的不同之处是一个核苷酸(根据所示的信息),所以不能确定umi 246是否来源于umi 242或umi 244。然而,在许多其它情况下,读段中的umi误差与两个最相似umi不是同等不同的。如umi 248的例子中所示出的,umi 242和umi 244也是与umi 248最相似的两个umi。可以看出umi 248与umi 242的差异在于从左起的第三个核苷酸中的一个核苷酸,其是a而不是t。相比之下,umi 248与umi 244相差三个核苷酸。因此,不能确定umi 248来源于umi 242而非umi 244,并且可能在从左起的第三个核苷酸处发生误差。
[0279]
虚拟umi
[0280]
转到虚拟umi,源dna分子的末端位置处或相对于源dna分子的末端位置限定的那
些虚拟umi在末端位置的位置通常如同一些片段化程序一样且如同天然存在的cfdna一样随机时能够独特地或几乎独特地限定单独源dna分子。当样品含有相对较少的源dna分子时,虚拟umi本身可以独特地鉴别单独的源dna分子。使用两个虚拟umi的组合(每个虚拟umi与源dna分子的不同末端相关联)增加了单独的虚拟umi可以独特地鉴定源dna分子的可能性。当然,即使在一个或两个虚拟umi不能单独独特鉴定源dna分子的情况下,此类虚拟umi与一个或多个物理umi的组合可以成功。
[0281]
如果两个读段来源于相同的dna片段,则具有相同碱基对的两个亚序列在读段中也将具有相同的相对位置。反之,如果两个读段来源于两个不同的dna片段,则具有相同碱基对的两个亚序列在读段中具有完全相同的相对位置是不太可能的。因此,如果来自两个或更多个读段的两个或更多个亚序列在两个或更多个读段上具有相同的碱基对和相同的相对位置,则可以推断两个或更多个读段源自相同的片段。
[0282]
在一些实施方案中,将位于或邻近dna片段的末端的亚序列用作虚拟umi。这种设计选择有一些实际的优点。首先,容易确定位于读段上的这些亚序列的相对位置,因为它们在读段的起始处或附近并且系统不需要使用偏移(offset)来查找虚拟umi。此外,由于首先测序位于片段末端处的碱基对,即使读段相对较短,这些碱基对也是可用的。此外,在长读段中较早确定的碱基对具有比稍后确定的那些碱基对更低的测序误差率。然而,在其它实施方案中,位于远离读段末端的亚序列可以用作虚拟umi,但是可能需要确定它们在读段上的相对位置以推断读段获得自相同的片段。
[0283]
读段中的一种或多种亚序列可用作虚拟umi。在一些实施方案中,将两种亚序列(每种从源dna分子的不同末端追踪)用作虚拟umi。在各种实施方案中,虚拟umi是约24个碱基对或更短、约20个碱基对或更短、约15个碱基对或更短、约10个碱基对或更短、约9个碱基对或更短、约8个碱基对或更短、约7个碱基对或更短,或约6个碱基对或更短。在一些实施方案中,虚拟umi是约6个至10个碱基对。在其它实施方案中,虚拟umi是约6个至24个碱基对。
[0284]
折拢读段和获得共有序列
[0285]
在使用umi的各个实施方案中,折拢具有相同umi的多个测序读段以获得一种或多种共有序列,然后将所述共有序列用于测定源dna分子的序列。可以从相同源dna分子的独特情况中产生多个独特的读段,并且可以比较这些读段以产生共有序列,如本文所述。情况可以通过在测序之前扩增源dna分子来产生,使得在独特的扩增产物上进行独特的测序操作,所述扩增产物各自共享源dna分子的序列。当然,扩增可以引入误差,使得独特扩增产物的序列具有差异。在一些测序技术(如illumina的边合成边测序技术)的语境下,源dna分子或其扩增产物形成连接至流动池的区域的dna分子簇。簇的分子共同提供了读段。通常需要至少两个读段来提供共有序列。100、1000,和10,000的测序深度是在创建低等位基因频率(如约1%或更低)的共同读段的公开的实施方案中有用的测序深度的例子。
[0286]
在一些实施方案中,在100%的共享umi或umi组合的读段间一致的核苷酸包含在共有序列内。在其它实施方案中,共有标准可以低于100%。例如,可以使用90%的共有标准,这意味着存在于组中90%或更多读段中的碱基对包含在共有序列中。在各个实施方案中,共有标准可以设定在约30%、约40%、约50%、约60%、约70%、约80%、约90%、约95%,或约100%。
[0287]
通过物理umi和虚拟umi进行折拢
[0288]
可以使用多种技术来折拢包含多个umi的读段。在一些实施方案中,可以折拢共享共同物理umi的读段以获得共有序列。在一些实施方案中,如果共同物理umi是随机umi,则随机umi可以足够独特以鉴定样品中dna片段的特定源分子。在其它实施方案中,如果共同物理umi是非随机umi,则umi本身可能独特得不足以鉴定特定的源分子。在任一情况下,可以将物理umi与虚拟umi组合以提供源分子的索引。
[0289]
在上述的示例性工作流中并在图1b、图3a和图4中描绘,一些读段包含而其它包含物理umiα产生具有α的读段。如果工作流中使用的所有衔接头都具有不同的物理umi(例如不同的随机umi),则在衔接头区域处具有α的所有读段可能源自dna片段的相同链。类似地,物理umiβ产生具有β的读段,其均源自dna片段的相同互补链。因此,有用的是折拢包括α的所有读段以获得一个共有序列,以及折拢包括β的所有读段以获得另一个共有序列。这在图4b
‑
4c中描绘为第一级折拢(first level collapsing)。由于组中的所有读段源自样品中相同的源多核苷酸,共有序列中包含的碱基对可能反映了源多核苷酸的真实序列,而从共有序列中排除的碱基对可能反映了工作流中引入的变化或误差。
[0290]
另外,虚拟umiρ和可以提供信息以确定包含一种或两种虚拟umi的读段源自相同的源dna片段。由于虚拟umiρ和在源dna片段内部,利用虚拟umi实际上不会对制备或测序增加费用。获得来自读段的物理umi的序列后,可以将读段中的一种或多种亚序列确定为虚拟umi。如果虚拟umi包括足够的碱基对并且在读段上具有相同的相对位置,则它们可以将读段独特地鉴定为源自源dna片段。因此,可以折拢具有一种或两种虚拟umiρ和的读段以获得共有序列。当将仅一个物理umi分配至每条链的第一级共有序列时(如图3a和图4a
‑
图4c中所示)时,虚拟umi和物理umi的组合可以为指导二级折拢提供信息。然而,在一些实施方案中,如果存在过多输入的dna分子或片段化不是随机化的,则使用虚拟umi的该第二级折拢可能是困难的。
[0291]
在替代实施方案中,基于物理umi和虚拟umi的组合,可以在二级折拢中折拢在两个末端上具有两个物理umi的读段(如图3b和图4d和图4e中示出的那些)。这在当物理umi太短而不能在不使用虚拟umi的情况下独特地鉴定源dna片段时尤其有用。在这些实施方案中,可以通过折拢来自相同dna分子的共有读段和共有读段,从而获得包含在所有读段中一致的核苷酸的共有序列,用如图3b所示的物理umi来实施第二级折拢。
[0292]
使用本文描述的umi和折拢方案,即使片段包含具有非常低等位基因频率的等位基因,各种实施方案可以抑制影响所确定的片段序列的不同的误差源。将共享相同umi(物理和/或虚拟)的读段分组在一起。通过折拢分组的读段,可以消除由于pcr、文库制备、成簇,和测序误差所致的变异(snv和小的插入/缺失(indel))。图4a
‑
4e显示了如示例工作流中公开的方法可以如何抑制测定双链dna片段的序列中的不同误差来源。显示的读段包含图3a和图4a
‑
图4c中的或和图3b、图4d和图4e中的或或图3a和图4a
‑
图4c中,α和βumi是单重(singleplex)物理umi。图3b、图4d和图4e中,α和βumi是双链体umi。虚拟umiρ和位于dna片段的末端处。
[0293]
使用如示于图4a
‑
图4c中的单重物理umi的方法首先涉及折拢具有相同物理umiα或β的读段,作为第一级折拢加以说明。第一级折拢获得用于具有物理umiα的读段的α共有序列,所述读段源自双链片段的一条链。第一级折拢还获得用于具有物理umiβ的读段的β共
有序列,所述读段源自双链片段的另一条链。在第二级折拢,该方法自α共有序列和β共有序列获得第三共有序列。该第三共有序列反映来自具有相同双链体虚拟umiρ和的读段的共有碱基对,所述读段源自源片段的两条互补链。最后,将双链dna片段的序列确定为第三共有序列。
[0294]
使用如图4d
‑
图4e中所示的双链体物理umi的方法首先涉及折拢具有在5
’‑3’
方向上具有α
→
β顺序的物理umiα和β的读段,作为第一级折拢加以说明。第一级折拢获得用于具有物理umiα和β的读段的α
‑
β共有序列,所述读段源自双链片段的第一链。第一级折拢还获得具有在5
’‑3’
方向上具有β
→
α顺序的物理umiβ和α的读段的β
‑
α共有序列,该读段源自与双链片段的第一链互补的第二链。在第二级折拢,所述方法自α
‑
β共有序列和β
‑
α共有序列获得第三共有序列。该第三共有序列反映来自具有相同双链体虚拟umiρ和的读段的共有碱基对,所述读段源自源片段的两条链。最后,将双链dna片段的序列确定为第三共有序列。
[0295]
图4a显示了第一级折拢如何可以抑制测序误差。样品和文库制备(如pcr扩增)后,测序误差发生在测序平台上。测序误差可以将不同误差碱基引入到不同读段中。真阳性碱基用实体字母(solid letters)表示,而假阳性碱基用阴影字母表示。家族中不同读段上的假阳性核苷酸已被排除在α共有序列之外。对于α共有序列保留家族读段的左侧末端处示出的真阳性核苷酸“a”。类似地,家族中不同读段上的假阳性核苷酸已被排除在β共有序列之外,保留了真阳性核苷酸“a”。如这里所示,第一级折拢可以有效地除去测序误差。图4a还显示了依赖于虚拟umiρ和的可选第二级折拢。该第二级折拢可以进一步抑制如上解释的误差,但此类误差未在图4a中示出。
[0296]
在成簇扩增之前发生pcr误差。因此,通过pcr过程引入单链dna中的一个误差碱基对可以在成簇扩增中扩增,从而出现在多个簇和读段中。如图4b和图4d中所示,通过pcr误差引入的假阳性碱基对可以出现在许多读段中。(图4b)或α
‑
β(图4d)家族读段中的“t”碱基和(图4b)或β
‑
α(图4d)家族读段中的“c”碱基是此类pcr误差。相反,图4a中所示的测序误差出现在同一家族中的一个或几个读段上。由于pcr测序误差出现在家族的许多读段中,链中读段的第一级折拢没有除去pcr误差,即使第一级折拢除去了测序误差(即,从图4b中家族和图4d中α
‑
β家族除去g和a)。然而,由于将pcr误差引入单链dna中,源片段和从其衍生的读段的互补链通常不具有相同的pcr误差。因此,如图4b和图4d底部所示,基于来自源片段的两条链的读段的第二级折拢可以有效除去pcr误差。
[0297]
在一些测序平台中,发生均聚物误差以将小的插入/缺失误差引入重复单一核苷酸的均聚物。图4c和图4e显示了使用本文描述的方法的均聚物误差纠正。在(图4c)或(图4e)家族读段中,从顶部的第二读段中缺失两个“t”核苷酸,并且从顶部的第三读段中缺失一个“t”核苷酸。在(图4c)或(图4e)家族读段中,将一个“a”核苷酸插入来自顶部的第一读段中。与图4a中所示的测序误差类似,在pcr扩增后发生均聚物误差,从而不同读段具有不同的均聚物误差。因此,第一级折拢可以有效除去插入/缺失误差。
[0298]
可以通过折拢具有一种或多种共同非随机umi和一种或多种共同虚拟umi的读段来获得共有序列。此外,还可以使用位置信息来获得如下所述的共有序列。
[0299]
通过位置进行的折拢
[0300]
在一些实施方案中,处理读段以与参考序列比对来确定参考序列上读段的比对位
置(定位)。然而,在上面没有示出的一些实施方案中,通过k
‑
mer相似性分析和读段
‑
读段比对来实现定位。该第二个实施方案具有两个优点:第一,其可以折拢(误差纠正)由于单倍型差异或易位而不与参考匹配的读段,并且第二,它不依赖于比对器算法(aligner algorithm),从而消除了比对诱导的伪像(artifacts)(比对器中的误差)的可能性。在一些实施方案中,可以折拢共享相同定位信息的读段以获得共有序列来测定源dna片段的序列。在一些背景下,比对过程也称为定位过程。序列读段经历比对过程以定位到参考序列。如本公开的其它部分所述,各种比对工具和算法可用于将读段与参考序列比对。通常,在比对算法中,一些读段与参考序列成功比对,而其它读段可能不能成功与参考序列比对或可能与参考序列较差比对。与参考序列连续比对的读段与参考序列上的位点相关联。比对的读段和它们的相关联位点还称为序列标签。含有大量重复的一些测序读段往往更难以与参考序列比对。当读段在高于某种标准的错配碱基数目的情况下与参考序列比对时,该读段认为是较差比对的。在各种实施方案中,认为读段在它们在至少约1、2、3、4、5、6、7、8、9,或10个错配的情况下比对时是较差比对的。在其它实施方案中,认为读段在它们在至少约5%的错配的情况下比对时是较差比对的。在其它实施方案中,认为读段在它们在至少约10%、15%、或20%错配碱基的情况下比对时是较差比对的。
[0301]
在一些实施方案中,公开的方法将位置信息与物理umi信息相组合以对dna片段的源分子索引化。可以折拢共享相同读段位置和相同非随机或随机物理umi的序列读段以获得共有序列,用于测定片段或其部分的序列。在一些实施方案中,可以折拢共享相同读段位置,相同非随机物理umi,和随机物理umi的测序读段以获得共有序列。在此类实施方案中,衔接头可以包含非随机物理umi和随机物理umi两者。在一些实施方案中,可以折拢共享相同读段位置和相同虚拟umi的测序读段以获得共有序列。
[0302]
可以通过不同的技术获得读段位置信息。例如,在一些实施方案中,可以使用基因组坐标来提供读段位置信息。在一些实施方案中,与读段比对的参考序列上的位置可用于提供读段位置信息。例如,染色体上读段的起始和终止位置可用于提供读段位置信息。在一些实施方案中,如果读段位置具有相同的位置信息,则认为它们是相同的。在一些实施方案中,如果位置信息之间的差异小于限定的标准,则认为读段位置是相同的。例如,可以认为具有相差少于2、3、4,或5个碱基对的起始基因组位置的两个读段是具有相同读段位置的读段。在其它实施方案中,如果读段位置的位置信息可以转换为特定位置空间并在特定位置空间中匹配,则认为读段位置是相同的。可以在测序前提供参考序列
‑‑
例如,它可以是公知和广泛使用的人类基因组序列
‑‑
或者它可以自对样品测序期间获得的读段确定。
[0303]
无论具体的测试平台和方案如何,对样品中含有的至少一部分核酸测序以生成数万,数十万或数百万个测序读段,例如,100bp读段。在一些实施方案中,测序读段包含约20bp、约25bp、约30bp、约35bp、约36bp、约40bp、约45bp、约50bp、约55bp、约60bp、约65bp、约70bp、约75bp、约80bp、约85bp、约90bp、约95bp、约100bp、约110bp、约120bp、约130bp、约140bp、约150bp、约200bp、约250bp、约300bp、约350bp、约400bp、约450bp、约500bp、约800bp、约1000bp,或约2000bp。
[0304]
在一些实施方案中,将读段比对到参考基因组,如hg19。在其它实施方案中,将读段比对到参考基因组的部分,如染色体或染色体片段。独特地定位到参考基因组上的读段称为序列标签。在一个实施方案中,从独特定位到参考基因组的读段获得至少约3x106个合
格的序列标签、至少约5x106个合格的序列标签、至少约8x106个合格的序列标签、至少约10x106个合格的序列标签、至少约15x106个合格的序列标签、至少约20x106个合格的序列标签、至少约30x106个合格的序列标签、至少约40x106个合格的序列标签,或至少约50x106个合格的序列标签。
[0305]
应用
[0306]
在各种应用中,如本文所公开的误差纠正策略可以提供一个或多个以下益处:(i)检测非常低的等位基因频率体细胞突变,(ii)通过减少定相/前定相误差来减少循环时间,和/或(iii)通过在读段的较晚部分提高碱基调用的质量来增加读段长度,等等。上文讨论了关于低等位基因频率体细胞突变检测的应用和原理。
[0307]
在某些实施方案中,本文描述的技术可以允许等位基因的可靠调用,所述等位基因具有约2%以下,或约1%以下,或约0.5%以下的频率。此类低频率在源自癌症患者中肿瘤细胞的cfdna中是常见的。在一些实施方案中,这里描述的技术可以允许在宏基因组(metagenomic)样品中稀有株的鉴定,以及当(例如)患者已经被多种病毒株感染,和/或已经经历医学治疗时检测病毒或其它群体中罕见的变体。
[0308]
在某些实施方案中,本文描述的技术可以允许更短的测序化学循环时间。缩短的循环时间增加了测序误差,其可以使用上面描述的方法纠正。
[0309]
在一些涉及umi的实施方案中,可以使用来自区段的两个末端的配对末端(pe)读段对的非对称读段长度从配对末端测序获得长读段。例如,在一个配对末端读段中具有50bp和在另一个配对末端读段中500bp的读段对可以与另一读段对“缝合”在一起以产生1000bp的长读段。这些实施方案可以提供更快的测序速度用以测定低等位基因频率的长片段。
[0310]
图5示意性地显示了实例以在这种应用中通过应用物理umi和虚拟umi来有效获得长配对末端读段。在流动池上将来自相同dna片段的两条链的文库成簇。文库的插入物大小长于1kb。用非对称读段长度(例如,读段1=500bp,读段2=50bp)进行测序,以确保长500bp读段的质量。缝合两条链,可以仅用500+50bp测序来创建1000bp长pe读段。
[0311]
样品
[0312]
用于测定dna片段序列的样品可以包括取自包含要测定感兴趣序列的核酸的任何细胞、流体、组织或器官的样品。在涉及癌症诊断的一些实施方案中,可以从受试者的体液(如血液或血浆)获得循环肿瘤dna。在涉及胎儿诊断的一些实施方案中,从母体体液获得无细胞核酸,例如无细胞dna(cfdna)是有利的。无细胞核酸(包括无细胞dna)可以通过本领域已知的多种方法从生物样品获得,所述生物样品包括但不限于血浆、血清和尿液(参见例如fan et al.,proc natl acad sci 105:16266
‑
16271[2008];koide et al.,prenatal diagnosis 25:604
‑
607[2005];chen et al.,nature med.2:1033
‑
1035[1996];lo et al.,lancet 350:485
‑
487[1997];botezatu et al.,clin chem.46:1078
‑
1084,2000;以及su et al.,j mol.diagn.6:101
‑
107[2004])。
[0313]
在多个实施方案中,在使用之前(例如在制备测序文库之前),可以特异性或非特异性富集样品中存在的核酸(例如dna或rna)。样品dna的非特异性富集是指样品的基因组dna片段的全基因组扩增,其可以用于在制备cfdna测序文库之前增加样品dna的水平。全基因组扩增的方法为本领域已知的。简并寡核苷酸引发的pcr(dop)、引物延伸pcr技术(pep)
和多重置换扩增(mda)是全基因组扩增方法的实例。在一些实施方案中,对于dna,样品是未富集的。
[0314]
应用本文所述方法的包含核酸的样品通常包括如上文所述的生物样品(“测试样品”)。在一些实施方案中,要测序的核酸通过许多公知方法中的任一种纯化或分离。
[0315]
因此,在某些实施方案中,样品包括纯化的或分离的多核苷酸,或基本上由纯化的或分离的多核苷酸组成,或者其可以包括诸如组织样品、生物流体样品、细胞样品等的样品。合适的生物流体样品包括但不限于血液、血浆、血清、汗液、泪液、痰、尿液、痰、耳流出物、淋巴液、唾液、脑脊液、灌洗液、骨髓悬液、阴道流出物、经宫颈灌洗液、脑液、腹水、乳液、呼吸道、肠道和泌尿生殖道的分泌物、羊水、乳液和白细胞采集物(leukophoresis)样品。在一些实施方案中,样品是通过非侵入性程序可容易获得的样品,例如血液、血浆、血清、汗液、泪液、痰、尿液、痰、耳流出物、唾液或排泄物。在某些实施方案中,样品是外周血样品、或外周血样品的血浆和/或血清级分。在其它实施方案中,生物样品是拭子或涂片、活检样本或细胞培养物。在另一实施方案中,样品是两种或更多种生物样品的混合物,例如生物样品可以包含生物流体样品、组织样品和细胞培养物样品中的两种或更多种。如本文所用,术语“血液”、“血浆”和“血清”明确涵盖其级分或经处理的部分。类似地,在样品取自活检、拭子、涂片等的情况下,“样品”明确涵盖来源于活检、拭子、涂片等的经处理的级分或部分。
[0316]
在某些实施方案中,样品可以从以下来源获得,所述来源包括但不限于来自不同个体的样品、来自相同或不同个体的不同发育阶段的样品、来自不同患病个体(例如疑似具有遗传病症的个体)的样品、来自正常个体的样品、在个体的疾病的不同阶段获得的样品、从经受疾病的不同治疗的个体获得的样品、来自经受不同环境因素的个体的样品、来自具有病理素因的个体的样品、来自暴露于疾病传染源的个体的样品等。
[0317]
在一个示例性但非限制性的实施方案中,样品是获自怀孕雌性,例如孕妇的母体样品。在该情况中,可以使用本文所述的方法分析样品以提供胎儿中可能的染色体异常的产前诊断。母体样品可以是组织样品、生物流体样品或细胞样品。作为非限制性的实例,生物流体包括血液、血浆、血清、汗液、泪液、痰、尿液、痰、耳流出物、淋巴液、唾液、脑脊液、灌洗液、骨髓悬液、阴道流出物、经宫颈灌洗液、脑液、腹水、乳液、呼吸道、肠道和泌尿生殖道的分泌物以及白细胞采集物样品。
[0318]
某些实施方案中,样品也可以获自体外培养的组织、细胞或其它含多核苷酸的来源。培养的样品可以取自以下来源,其包括但不限于保持在不同培养基和条件(例如ph、压力或温度)中的培养物(例如组织或细胞)、保持不同时间长度的培养物(例如组织或细胞)、用不同因子或试剂(例如药物候选物或调节剂)处理的培养物(例如组织或细胞)或不同类型的组织和/或细胞的培养物。
[0319]
从生物来源分离核酸的方法是公知的,并且将根据来源的性质而不同。对于本文所述的方法,本领域技术人员能够根据需要容易地从来源分离核酸。在一些情况下,将核酸样品中的核酸分子片段化可以是有利的。片段化可以是随机的,或者其可以是特异的,如例如使用限制性内切核酸酶消化所实现的。随机片段化的方法是本领域公知的,并且包括例如限制性dna酶消化、碱处理和物理剪切。
[0320]
测序文库的制备
[0321]
在多个实施方案中,可以在需要制备测序文库的各种测序平台上进行测序。制备
通常涉及将dna片段化(超声处理、雾化或剪切),随后进行dna修复和末端补齐(平端或a突出端)以及平台
‑
特异性衔接头连接。在一个实施方案中,本文所述的方法可以利用下一代测序技术(ngs),其允许多个样品在单一测序运行中作为基因组分子(即单重测序)或作为包含索引化基因组分子的合并样品(例如多重测序)个别测序。这些方法可以产生dna序列的多达数十亿个读段。在多个实施方案中,可以使用例如本文所述的下一代测序技术(ngs)测定基因组核酸和/或索引化基因组核酸的序列。在多个实施方案中,使用ngs获得的大量序列数据的分析可以使用如本文所述的一个或多个处理器进行。
[0322]
在多个实施方案中,此类测序技术的使用不涉及测序文库的制备。
[0323]
然而,在某些实施方案中,本文考虑的测序方法涉及测序文库的制备。在一个示例性方法中,测序文库的制备涉及产生准备好测序的衔接头
‑
修饰的dna片段(例如多核苷酸)的随机集合。多核苷酸的测序文库可以由以下制备:dna或rna,包括dna或cdna的等同物、类似物,例如,作为通过逆转录酶的作用由rna模板产生的互补或拷贝dna的cdna或dna。多核苷酸可以以双链形式(例如dsdna,如基因组dna片段、cdna、pcr扩增产物等)起源,或者,在某些实施方案中,多核苷酸可以以单链形式(例如ssdna、rna等)起源并且已经被转化成dsdna形式。举例来说,在某些实施方案中,可以将单链mrna分子复制成适合用于制备测序文库的双链cdna。主要多核苷酸分子的精确序列对于文库制备方法通常不是实质性的,并且可以是已知或未知的。在一个实施方案中,多核苷酸分子为dna分子。更具体地,在某些实施方案中,多核苷酸分子代表生物体的整个遗传互补物或生物体的基本上整个遗传互补物,并且为通常包含内含子序列和外显子序列(编码序列)两者以及非编码调控序列,如启动子和增强子序列的基因组dna分子(例如细胞dna、无细胞dna(cfdna)等)。在某些实施方案中,主要的多核苷酸分子包括人基因组dna分子,例如怀孕受试者的外周血中存在的cfdna分子。
[0324]
通过使用包含特定范围的片段大小的多核苷酸来促进一些ngs测序平台的测序文库的制备。此类文库的制备通常涉及大的多核苷酸(例如细胞基因组dna)的片段化以获得期望大小范围内的多核苷酸。
[0325]
配对末端读段可用于本文公开的测序方法和系统中。片段或插入物长度长于读段长度,并且有时长于两个读段的长度的总和。
[0326]
在一些示例性实施方案中,样品核酸以基因组dna获得,将该基因组dna片段化成长于大约50、100、200、300、400、500、600、700、800、900、1000、2000,或5000个碱基对的片段,对其可以容易地应用ngs方法。在一些实施方案中,配对末端读段获自约100
‑
5000bp的插入物。在一些实施方案中,插入物的长度为约100
‑
1000bp。这些有时以规则的短插入物配对末端读段实施。在一些实施方案中,插入物长度为约1000
‑
5000bp。这些有时以长插入物配偶配对读段(mate paired read)实施,如上文所述的。
[0327]
在一些实施方案中,长插入物设计成用于评价非常长的序列。在一些实施方案中,可以应用配偶对读段(mate pair read)以获得以数千个碱基对间隔开的读段。在这些实施方案中,插入物或片段的范围是几百至几千个碱基对,在插入物的两个末端上具有两个生物素接合(junction)衔接头。然后,生物素接合衔接头连接插入物的两个末端以形成环化分子,然后,其进一步被片段化。选择包含生物素接合衔接头和初始插入物的两个末端的亚片段以在设计成对较短片段进行测序的平台上测序。
[0328]
可以通过本领域技术人员已知的许多方法中的任一种实现片段化。例如,可以通过机械手段实现片段化,所述机械手段包括但不限于雾化、超声处理和水切力(hydroshear)。然而,机械片段化通常在c
‑
o、p
‑
o和c
‑
c键处切割dna主链,导致具有断裂的c
‑
o、p
‑
o和/c
‑
c键的平端以及3
’‑
和5
’‑
突出端的异质性混合物(参见,例如alnemri and liwack,j biol.chem 265:17323
‑
17333[1990];richards and boyer,j mol biol 11:327
‑
240[1965]),所述平端以及3
’‑
和5
’‑
突出端可能需要修复,因为它们可能缺乏对于后续酶促反应,例如测序衔接头的连接必不可少的5
’‑
磷酸,所述酶促反应对于制备测序用的dna是需要的。
[0329]
相比之下,cfdna通常以小于约300个碱基对的片段存在,因此,片段化对于使用cfdna样品生成测序文库通常不是必需的。
[0330]
通常,无论多核苷酸是强行片段化(例如在体外片段化)的还是以片段天然存在的,将它们转化成具有5
’‑
磷酸和3
’‑
羟基的平端dna。标准方案,例如使用例如如在上面参考图1a和图1b的示例工作流中描述的illumina平台进行测序的方案,指导用户末端修复样品dna、在对3’末端腺苷化或da
‑
加尾之前纯化末端修复的产物,以及在文库制备的衔接头连接步骤之前纯化da
‑
加尾产物。
[0331]
本文所述的序列文库的制备方法的多个实施方案避免进行通常由标准方案强制执行的一个或多个步骤以获得可以通过ngs进行测序的修饰的dna产物的需要。简化法(abb方法)、1
‑
步方法和2
‑
步方法为制备测序文库的方法的实例,其可见于2012年7月20日提交的专利申请13/555,037,将其通过引用整体并入。
[0332]
测序方法
[0333]
本文所述的方法和设备可以采用下一代测序技术(ngs),其允许大规模平行测序。在某些实施方案中,在流动池内以大规模平行方式对克隆扩增的dna模板或单一dna分子进行测序(例如,如volkerding et al.clin chem 55:641
‑
658[2009];metzker m nature rev 11:31
‑
46[2010]中所述)。ngs的测序技术包括但不限于焦磷酸测序、利用可逆染料终止剂的边合成边测序、通过寡核苷酸探针连接的测序和离子半导体测序。来自单独样品的dna可以单独地测序(即,单重测序),或者可以合并来自多个样品的dna,并在单次测序运行上以索引化的基因组分子进行测序(即多重测序),以产生dna序列的多达数亿个读段。在本文进一步描述根据本方法可以用于获得序列信息的测序技术的实例。
[0334]
一些测序技术为商业上可得的,如来自affymetrix inc.(sunnyvale,ca)的边杂交边测序平台和来自454life sciences(bradford,ct)、illumina/solexa(san diego,ca)和helicos biosciences(cambridge,ma)的边合成边测序平台,以及来自applied biosystems(foster city,ca)的边连接边测序平台,如下文所述。除使用helicos biosciences的边合成边测序进行的单分子测序之外,其它单分子测序技术包括但不限于pacific biosciences的smrt
tm
技术、ion torrent
tm
技术和例如,由oxford nanopore technologies研发的纳米孔测序。
[0335]
虽然自动化的sanger方法被认为是“第一代”技术,但也可以在本文所述的方法中采用包括自动化的sanger测序的sanger测序。其它合适的测序方法包括但不限于核酸成像技术,例如原子力显微术(afm)或透射电子显微术(tem)。下文更详细地描述示例性测序技术。
[0336]
在一些实施方案中,公开的方法涉及使用illumina的边合成边测序和基于可逆终止剂的测序化学方法通过数百万的dna片段的大规模平行测序获得测试样品中核酸的序列信息(例如,如bentley et al.,nature 6:53
‑
59[2009]中所述)。模板dna可以为基因组dna,例如细胞dna或cfdna。在一些实施方案中,来自分离的细胞的基因组dna用作模板,并将其片段化成数百个碱基对的长度。在其它实施方案中,cfdna或循环肿瘤dna(ctdna)用作模板,并且片段化不是必需的,因为cfdna或ctdna以短片段存在。例如,胎儿cfdna以长度为大约170个碱基对(bp)的片段在血流中循环(fan et al.,clin chem 56:1279
‑
1286[2010]),并且在测序之前,不需要dna的片段化。illumina的测序技术依赖于片段化基因组dna与结合有寡核苷酸锚定的平面透光表面的附接。对模板dna进行末端修复以产生5
’‑
磷酸化平端,以及klenow片段的聚合酶活性用于将单一a碱基添加至平端磷酸化dna片段的3’端。该添加制备dna片段,用于连接至寡核苷酸衔接头,所述寡核苷酸衔接头在其3’端具有单一t碱基的突出端以增加连接效率。衔接头寡核苷酸与流动池锚定寡核苷酸互补。在有限稀释条件下,将衔接头
‑
修饰的单链模板dna添加至流动池,以及通过与锚定寡聚物杂交而固定化。将附接的dna片段延伸并桥式扩增以产生具有数亿个簇的超高密度测序流动池,每个簇含有约1,000个拷贝的相同模板。在一个实施方案中,将随机片段化的基因组dna使用pcr进行扩增,之后将其进行簇扩增。或者,使用无扩增的基因组文库制备,以及使用单独的簇扩增富集随机片段化的基因组dna(kozarewa et al.,nature methods 6:291
‑
295[2009])。使用稳健的四色dna边合成边测序技术对模板进行测序,该技术采用具有可除去的荧光染料的可逆终止剂。使用激光激发和全内反射光学器件实现高灵敏度荧光检测。将约十至几百个碱基对的短测序读段相对于参考基因组比对,以及使用特别研发的数据分析管线软件鉴定短测序读段与参考基因组的独特定位。在第一读段完成之后,模板可以原位再生以启用来自片段的相对端的第二读段。因此,可以使用dna片段的单末端或配对末端测序。
[0337]
本公开的多个实施方案可以使用允许配对末端测序的边合成边测序。在一些实施方案中,通过illumina的边合成边测序平台涉及将片段聚簇。聚簇是每个片段分子等温扩增的过程。在一些实施方案中,作为此处所述的实例,片段具有与片段的两个末端附接的两个不同的衔接头,该衔接头允许片段与流动池道表面上的两个不同的寡聚物杂交。片段还包括在该片段的两个末端的两个索引序列或与所述索引序列连接,该索引序列提供鉴定多重测序中不同样品的标记物。在一些测序平台中,要自两个末端测序的片段也被称为插入物。
[0338]
在一些实施方案中,illumina平台中用于成簇的流动池为具有道的载玻片。每个道为涂覆有两种类型寡聚物(如p5和p7’寡聚物)的场地的玻璃通道。通过表面上的两种类型寡聚物中的第一类实现杂交。该寡聚物与片段的一个末端上的第一衔接头互补。聚合酶产生杂交片段的互补链。将双链分子变性,并且将最初的模板链冲洗掉。剩余链与许多其它剩余链平行地通过桥式应用进行克隆扩增。
[0339]
在桥式扩增和涉及成簇的其它测序方法中,链折叠(folds over),并且链的第二端的第二衔接头区与在流动池表面的第二类型的寡聚物杂交。聚合酶产生互补链,形成双链桥式分子。将该双链分子变性,导致两个单链分子通过两个不同的寡聚物拴系至流动池。然后,反复重复该过程,并且对数百万个簇同时进行该过程,导致所有片段的克隆扩增。在
桥式扩增之后,切割并洗掉反向链,仅留下正向链。封闭3’端以防止不需要的引发。
[0340]
成簇之后,测序起始于延伸第一测序引物以产生第一读段。对于每个循环,荧光标签化(tagged)的核苷酸竞争对生长链的添加。基于模板的序列仅掺入一个。在添加每个核苷酸之后,光源激发簇,并发射特征性荧光信号。循环数决定读段长度。发射波长和信号强度决定碱基调用(call)。对于给定簇,同时读取全部相同的链。以大规模平行方式对数亿个簇进行测序。在第一读段完成时,冲洗掉读段产物。
[0341]
在涉及两个索引引物的方案的下一步中,将索引1引物引入,并且与模板上的索引1区杂交。索引区提供片段的鉴定,其可用于在多重测序过程中对样品多路解编(de
‑
multiplexing)。产生索引1读段,其与第一读段类似。在索引1读段完成之后,冲洗掉读段产物,并且将链的3’端去保护。然后,模板链折叠,并且结合流动池上的第二寡聚物。索引2序列以与索引1相同的方式读取。然后,在步骤完成时,洗掉索引2读段产物。
[0342]
在读取两个索引之后,通过使用聚合酶启动读段2以延伸第二流动池寡聚物,形成双链桥。将该双链dna变性,并封闭3’端。切割并冲洗掉最初的正向链,留下反向链。读段2开始于读段2测序引物的引入。与读段1一样,重复测序步骤直至实现期望长度。冲洗掉读段2产物。该整个过程产生数百万个读段,代表所有片段。基于样品制备期间引入的独特索引分离来自合并样品文库的序列。对于每个样品,将碱基调用的类似区段的读段局部聚簇。将正向读段和反向读段配对,产生连续序列。将这些连续序列与参考基因组比对用于变体鉴定。
[0343]
以上所述的边合成边测序实例涉及配对末端读段,其用于所公开方法的多个实施方案中。配对末端测序涉及来自片段的两个末端的2个读段。配对末端读段用于解决不明确的比对。配对末端测序允许用户选择插入物(或待测序的片段)的长度和插入物任一端的序列,产生高质量、可比对的序列数据。因为每个配对读段之间的距离是已知的,所以比对算法可以使用该信息以更精确地将读段定位在重复区上。这导致读段的较好的比对,特别是在基因组的难以测序的重复区之间。配对末端测序可以检测重排,包括插入和缺失(插入和缺失)以及倒置。
[0344]
配对末端读段可以使用不同长度(即待测序的不同片段大小)的插入物。作为本公开中的默认含义,配对末端读段用于指获自各种插入物长度的读段。在一些情况下,为区分短插入物配对末端读段与长插入物配对末端读段,后者特别称为配偶对读段。在涉及配偶对读段的一些实施方案中,两个生物素接合衔接头首先附接至相对长的插入物(例如数kb)的两个末端。然后,生物素接合衔接头连接插入物的两个末端以形成环化分子。然后,可以通过使环化分子进一步片段化获得涵盖生物素接合衔接头的亚片段。然后,可以通过与以上所述的短插入物配对末端测序相同的程序对包含呈相反序列顺序的最初片段的两个末端的亚片段测序。使用illumina平台的配偶对测序的其它详细内容显示在下述地址的线上出版物中,将其通过引用整体并入:
[0345]
res.illumina.com/documents/products/technotes/technote_nextera_matepair_data_processing.pdf
[0346]
在dna片段测序之后,预定长度,例如100bp的测序读段通过定位(比对)至已知参考基因组来定位。定位的读段及其在参考序列上的相应位置也称为标签。在该程序的另一个实施方案中,通过k
‑
mer共享和读段
‑
读段比对来实现定位。本文公开的多个实施方案的分析利用比对较差或不能比对的读段,以及比对的读段(标签)。在一个实施方案中,参考基
因组序列为ncbi36/hg18序列,其可在万维网上以genome.ucsc.edu/cgi
‑
bin/hggateway?org=human&db=hg18&hgsid=166260105)获得。或者,参考基因组序列为grch37/hg19或grch38,其可在万维网上以genome.ucsc.edu/cgi
‑
bin/hggateway获得。公共序列信息的其它来源包括genbank、dbest、dbsts、embl(欧洲分子生物学实验室(european molecular biology laboratory))和ddbj(日本dna数据库(dna databank of japan))。用于比对序列的多个计算机算法是可获得的,包括但不限于blast(altschul et al.,1990))、blitz(mpsrch)(sturrock&collins,1993)、fasta(person&lipman,1988)、bowtie(langmead et al.,genome biology 10:r25.1
‑
r25.10[2009]),或eland(illumina,inc.,san diego,ca,usa)。在一个实施方案中,对血浆cfdna分子的克隆扩增的拷贝的一端测序,并通过illumina基因组分析仪的生物信息学比对分析对其进行处理,所述生物信息学比对分析使用核苷酸数据库的有效大规模比对(eland)软件。
[0347]
在一个示例性但非限制性实施方案中,本文所述的方法包括使用helicos真正单分子测序(tsms)技术的单分子测序技术,获得测试样品中核酸的序列信息(例如,如harris t.d.et al.,science 320:106
‑
109[2008]中所述的)。在tsms技术中,将dna样品切割成大约100至200个核苷酸的链,以及将polya序列添加至各dna链的3’端。通过添加荧光标记的腺苷核苷酸对各链进行标记。然后,dna链与流动池杂交,所述流动池含有固定在流动池表面上的数百万个oligo
‑
t捕获位点。在某些实施方案中,模板的密度可以为约1亿个模板/cm2。然后,将流动池装载至仪器,例如heliscope
tm
测序仪中,并且激光照射流动池的表面,揭示每个模板的位置。ccd相机能够定位流动池表面上模板的位置。然后,切割并冲洗掉模板荧光标记物。测序反应通过引入dna聚合酶和荧光标记的核苷酸开始。oligo
‑
t核酸用作引物。聚合酶将标记的核苷酸以模板指导的方式掺入引物。除去聚合酶和未掺入的核苷酸。指导荧光标记的核苷酸掺入的模板通过使流动池表面成像来识别。在成像之后,切割步骤除去荧光标记物,并且用其它荧光标记的核苷酸重复该过程直至实现期望的读段长度。利用每个核苷酸添加步骤收集序列信息。通过单分子测序技术的全基因组测序排除或通常避免测序文库制备中的基于pcr的扩增,并且该方法允许样品的直接测量,而不是该样品的拷贝的测量。
[0348]
在另一个示例性但非限制性实施方案中,本文所述的方法包括使用454测序(roche)获得测试样品中核酸的序列信息(例如,如margulies,m.et al.nature 437:376
‑
380[2005]中所述的)。454测序通常涉及两个步骤。在第一步中,将dna剪切成大约300
‑
800个碱基对的片段,并且片段为平端的。然后,将寡核苷酸衔接头连接至片段的末端。衔接头充当片段的扩增和测序的引物。使用例如含有5
’‑
生物素标签的衔接头b,可以将片段附接至dna捕获珠,例如链霉亲合素
‑
包被的珠。附接至珠的片段在油
‑
水乳剂的液滴中pcr扩增。结果为在每个珠上的多个拷贝的克隆扩增的dna片段。在第二步中,将珠捕获在孔(例如皮升
‑
大小的孔)中。在每个dna片段上平行进行焦磷酸测序。一个或多个核苷酸的添加产生由测序仪器中ccd相机记录的光信号。信号强度与掺入的核苷酸数目成比例。焦磷酸测序使用焦磷酸(ppi),其在核苷酸添加时被释放。在腺苷5’磷酰硫酸酯的存在下,通过atp硫酸化酶将ppi转化成atp。萤光素酶使用atp将萤光素转化成氧化萤光素,并且该反应产生被测量和分析的光。
[0349]
在另一示例性但非限制性实施方案中,本文所述的方法包括使用solid
tm
技术
(applied biosystems)获得测试样品中核酸的序列信息。在solid
tm
边连接边测序中,将基因组dna剪切成片段,以及将衔接头附接至片段的5’端和3’端以产生片段文库。或者,可以通过以下方式引入内部衔接头:将衔接头连接至片段的5’和3’端,使片段环化,消化环化的片段以产生内部衔接头,以及将衔接头附接至所得片段的5’端和3’端以产生配偶配对文库。然后,在含有珠、引物、模板和pcr组分的微反应器中制备克隆珠群。在pcr之后,使模板变性,以及富集珠以分离具有延伸模板的珠。在选定的珠上的模板经历允许与载玻片键合的3’修饰。可以通过部分随机的寡核苷酸与由特定荧光团所鉴定的中心确定的碱基(或碱基对)的相继杂交和连接来确定序列。在记录颜色之后,切割并去除连接的寡核苷酸,然后重复该过程。
[0350]
在另一示例性但非限制性实施方案中,本文所述的方法包括使用pacific biosciences的单分子实时(smrt
tm
)测序技术获得测试样品中核酸的序列信息。在smrt测序中,在dna合成期间,对染料标记的核苷酸的连续掺入成像。将单一dna聚合酶分子附接至单独的零模式波长检测器(zmw检测器)的底面,所述检测器在磷连接的核苷酸被掺入生长的引物链时获得序列信息。zmw检测器包括限制结构,其能够相对于荧光核苷酸背景观察到dna聚合酶对单核苷酸的掺入,所述荧光核苷酸在zmw外部迅速扩散(例如以微秒计)。将核苷酸掺入生长链通常花费数毫秒。在此时间期间,激发荧光标记物,并且产生荧光信号,并且切割荧光标签。染料的对应荧光的测量表明哪个碱基被掺入。重复该过程以提供序列。
[0351]
在另一示例性但非限制性实施方案中,本文所述的方法包括使用纳米孔测序获得测试样品中核酸的序列信息(例如,如soni gv and meller a.clin chem 53:1996
‑
2001[2007]中所述的)。纳米孔测序dna分析技术由多个公司研发,所述公司包括例如oxford nanopore technologies(oxford,united kingdom)、sequenom、nabsys等。纳米孔测序为单分子测序技术,其中当单dna分子通过纳米孔时,直接对其进行测序。纳米孔为直径通常是1纳米量级的小孔。将纳米孔浸入导电流体,并且施加跨越纳米孔的电势(电压)导致由于离子通过纳米孔的电导而产生的轻微电流。流动的电流的量对纳米孔的大小和形状是敏感的。当dna分子通过纳米孔时,dna分子上的每个核苷酸在不同程度上阻塞纳米孔,从而在不同程度上改变通过纳米孔的电流的量级。因此,当dna分子通过纳米孔时电流的这种变化提供dna序列的读段。
[0352]
在另一示例性但非限制性实施方案中,本文所述的方法包括使用化学敏感场效应晶体管(chemfet)阵列获得测试样品中核酸的序列信息(例如,如美国专利申请公开第2009/0026082号中所述)。在该技术的一个实例中,可以将dna分子置于反应室中,并且可以将模板分子与结合聚合酶的测序引物杂交。通过chemfet以电流变化辨别一个或多个三磷酸对测序引物3’端的新核酸链的掺入。阵列可以具有多个chemfet传感器。在另一实例中,可以将单一核酸附接至珠,并且可以在珠上扩增核酸,并且可以将单独的珠转移至chemfet阵列上的单独反应室中,其中每个室具有chemfet传感器,并且可以对核酸测序。
[0353]
在另一实施方案中,dna测序技术为ion torrent单分子测序,其使半导体技术与简单的测序化学方法成对以将化学编码的信息(a、c、g、t)直接译成半导体芯片上的数字信息(0、1)。本质上,当通过聚合酶将核苷酸掺入dna链时,氢离子作为副产物释放。ion torrent使用微机械孔的高密度阵列来以大规模平行方式进行该生化过程。每个孔保留不同的dna分子。在孔下方是离子敏感层,以及在离子敏感层下方是离子传感器。当核苷酸,例
如c添加至dna模板中,然后掺入dna链中时,氢离子将被释放。来自该离子的电荷改变溶液的ph,这可以被ion torrent的离子传感器检测到。测序仪
‑
基本上是世界上最小的固态ph计
‑
调用碱基,使化学信息直接变为数字信息。然后,ion个体基因组仪(personal genome machine)(pgm
tm
)测序仪以一个接一个的核苷酸序贯淹没芯片。如果淹没芯片的下一个核苷酸不匹配,则将记录不到电压变化,以及不调用碱基。如果dna链上存在两个相同的碱基,则电压会加倍,并且芯片会记录调用的两个相同碱基。直接检测允许以秒计的核苷酸掺入的记录。
[0354]
在另一实施方案中,本方法包括使用边杂交边测序获得测试样品中核酸的序列信息。边杂交边测序包括使多个多核苷酸序列与多个多核苷酸探针接触,其中多个多核苷酸探针各自可以任选地被拴系至基底。基底可以为包含已知核苷酸序列的阵列的平整表面。可以将与阵列杂交的模式用于确定样品中存在的多核苷酸序列。在其它实施方案中,将每个探针拴系至珠,例如磁珠等。可以测定与珠的杂交并且用于鉴定样品内的多个多核苷酸序列。
[0355]
在本文所述方法的一些实施方案中,测序读段为约20bp、约25bp、约30bp、约35bp、约40bp、约45bp、约50bp、约55bp、约60bp、约65bp、约70bp、约75bp、约80bp、约85bp、约90bp、约95bp、约100bp、约110bp、约120bp、约130、约140bp、约150bp、约200bp、约250bp、约300bp、约350bp、约400bp、约450bp或约500bp。预期技术进步能够启用大于500bp的单末端读段,当产生配对末端读段时,能够进行大于约1000bp的读段。在一些实施方案中,使用配对末端读段确定感兴趣的序列,其包含约20bp至1000bp、约50bp至500bp、或80bp至150bp的序列读段。在多个实施方案中,使用配对末端读段评价感兴趣的序列。感兴趣的序列比读段长。在一些实施方案中,感兴趣的序列长于约100bp、500bp、1000bp或4000bp。通过将读段序列与参考序列比较以确定测序的核酸分子的染色体来源来实现测序读段的定位,并且不需要特定的遗传序列信息。可以允许小程度的错配(0
‑
2个错配/读段)来解释参考基因组与混合样品中的基因组之间可能存在的次要多态性。在一些实施方案中,与参考序列比对的读段用作锚读段,并且与锚读段配对但不能与参考比对或比对较差的读段用作锚定读段。在一些实施方案中,比对较差的读段可能具有错配/读段百分比的相对较大数字,例如至少约5%、至少约10%、至少约15%或至少约20%的错配/读段。
[0356]
通常每个样品获得多个序列标签(即,与参考序列比对的读段)。在一些实施方案中,每个样品从读段到参考基因组的定位获得例如至少约3x106个序列标签、至少约5x106个序列标签、至少约8x106个序列标签、至少约10x106个序列标签、至少约15x106个序列标签、至少约20x106个序列标签、至少约30x106个序列标签、至少约40x106个序列标签或至少约50x106个序列标签,所述序列标签例如100bp。在一些实施方案中,所有序列读段定位参考基因组的所有区域,提供了全基因组读段。在其它实施方案中,读段定位感兴趣的序列。
[0357]
使用umi测序的装置和系统
[0358]
通常使用各种计算机执行的算法和程序进行测序数据的分析和由其得到的诊断。因此,某些实施方案采用涉及存储在一个或多个计算机系统或其它处理系统中的或通过一个或多个计算机系统或其它处理系统转移的数据的过程。本文公开的实施方案还涉及进行这些操作的设备。该设备可以特别地针对所需目的构建,或者其可以为存储在计算机中的计算机程序和/或数据结构选择性激活或重新配置的通用计算机(或一组计算机)。在一些
实施方案中,一组处理器合作地(例如经由网络或云计算)和/或平行地进行所述分析性操作中的一些或全部。进行本文所述方法的处理器或处理器组可以为各种类型,包括微控制器和微处理器,如可编程设备(例如cpld和fpga)和不可编程设备,如门阵列asic或通用微处理器。
[0359]
一个实施方案提供用于确定包含核酸的测试样品中具有低等位基因频率的序列的系统,所述系统包括测序仪,其用于接收核酸样品并提供来自样品的核酸序列信息;处理器;和机器可读存储介质,所述机器可读存储介质在其上已经存储了用于在所述处理器上执行以如下测定测试样品中的感兴趣序列的指令:(a)接收多个扩增的多核苷酸的序列,其中所述多个扩增的多核苷酸通过扩增包含感兴趣的序列的样品中的双链dna片段并将衔接头附接至双链dna片段获得;(b)鉴定多个物理umi,其中每个物理umi存在于多个扩增多核苷酸之一,其中每个物理umi源自附接至双链dna片段之一的衔接头;(c)鉴定多个虚拟umi,其中每个虚拟umi存在于多个扩增的多核苷酸之一,其中每个虚拟umi来源于双链dna片段之一的单独分子;并且(d)使用多个扩增的多核苷酸的序列、多个物理umi的序列,和多个虚拟umi的序列来测定双链dna片段的序列,从而减少测定双链dna片段序列中的误差。
[0360]
另一个实施方案提供了系统,其包括测序仪,其用于接收核酸样品并提供来自样品的核酸序列信息;处理器;和机器可读存储介质,所述机器可读存储介质已经在其上存储用于在所述处理器上执行以如下测定测试样品中感兴趣的序列的指令。所述指令包括:(a)将衔接头应用于所述样品中dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和所述衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物;(b)扩增所述dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸;(c)对所述多个扩增的多核苷酸测序,从而获得与非随机umi相关联的多个读段;(d)从所述多个读段,鉴定共享共同非随机umi的读段;和(e)从所鉴定的共享共同非随机umi的读段,从样品中测定dna片段的至少一部分的序列,所述部分具有含共同非随机umi的应用的衔接头。在一些实施方案中,所述指令还包括:从共享共同非随机umi的读段,选择共享共同非随机umi和共同读段位置两者的读段,并且其中(e)中测定dna片段的序列在参考序列中仅使用共享共同非随机umi和共同读段位置两者的读段。
[0361]
在另一个实施方案中,指令包括:(a)将衔接头应用于所述样品中双链dna片段的两个末端,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和所述衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物;其中可以将所述非随机umi与其它信息相组合以独特地鉴定双链dna片段的单独分子;(b)扩增dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸;(c)对多个扩增的多核苷酸测序,从而获得各自与非随机umi相关联的多个读段;(d)鉴定与多个读段相关联的多个非随机umi;以及(e)使用多个读段和多个非随机umi来测定样品中双链dna片段的序列。
[0362]
在本文提供的任何系统的一些实施方案中,测序仪配置为进行下一代测序(ngs)。在一些实施方案中,测序仪配置为使用边合成边测序利用可逆染料终止剂进行大规模平行测序。在其它实施方案中,测序仪配置为进行边连接边测序。在其它实施方案中,测序仪配置为进行单分子测序。
[0363]
另外,某些实施方案涉及有形和/或非暂时性计算机可读介质或计算机程序产品,其包含用于进行各种计算机
‑
实施操作的程序指令和/或数据(包含数据结构)。计算机可读
介质的实例包括但不限于半导体存储器装置,磁性介质如磁盘驱动器、磁带,光学介质如cd、磁光介质以及特别地被配置成存储和执行程序指令的硬件装置,如只读存储器装置(rom)和随机存取存储器(ram)。计算机可读介质可以由最终用户直接控制,或者介质可以由最终用户间接控制。直接控制的介质的实例包括位于用户设施的介质和/或不与其它实体共享的介质。间接控制的介质的实例包括经由外部网络和/或经由提供共享资源如“云”的服务,用户可间接得到的介质。程序指令的实例包括诸如编译程序产生的机器代码,以及含有可以由计算机使用解释器执行的较高水平代码的文件。
[0364]
在多个实施方案中,公开的方法和设备中采用的数据或信息以电子格式提供。此类数据或信息可以包括来源于核酸样品的读段和标签、参考序列(包括仅提供或主要提供多态性的参考序列),调用如癌症诊断调用,咨询推荐,诊断等。如本文所用,以电子格式提供的数据或其它信息可用于在机器上存储和机器之间的传输。照惯例,电子格式的数据以数字方式提供,并且可以在各种数据结构、列表、数据库等中存储成二进制位和/或字节。数据可以以电子方式、光学方式等体现。
[0365]
一个实施方案提供用于产生输出的计算机程序产品,所述输出指示测试样品中感兴趣的dna片段的序列。计算机产品可以含有用于进行上述方法的任何一种或多种以测定感兴趣的序列的指令。如所解释的,计算机产品可以包括非暂时性和/或有形的计算机可读介质,其具有在其上记录的计算机可执行或可编译逻辑(例如指令),用于使处理器能够测定感兴趣的序列。在一个实例中,计算机产品包含计算机可读介质,其具有在其上记录的计算机可执行或可编译逻辑(例如指令),用于使处理器能够诊断病患或测定感兴趣的核酸序列。
[0366]
应理解,未受协助的人进行本文公开方法的计算操作是不切实际的,或者甚至在大多数情况下是不可能的。例如,在没有计算设备的帮助下,将来自样品的单一30bp读段定位至人类染色体中的任一个可能需要多年的努力。当然,问题是复杂的,因为低等位基因频率突变的可靠调用通常需要将数千(例如至少约10,000)或甚至数百万个读段定位至一个或多个染色体。
[0367]
可以使用用于测定样品中感兴趣的序列的系统进行本文公开的方法。系统可以包括:(a)测序仪,其用于接收来自测试样品的核酸,提供来自样品的核酸序列信息;(b)处理器;以及(c)一个或多个计算机可读存储介质,所述计算机可读存储介质已经在其上存储用于进行测定感兴趣的序列的方法的计算机可读指令。在一些实施方案中,方法通过计算机可读介质指导,该计算机可读介质已经在其上存储用于实施测定感兴趣的序列的方法的计算机可读指令。因此,一个实施方案提供包含存储程序代码的非瞬态机器可读介质的计算机程序产品,所述程序代码当由计算机系统的一个或多个处理器执行时,使计算机系统实施用于测定测试样品中核酸片段的序列的方法。程序代码可以包括:(a)用于接收多个扩增的多核苷酸的序列的代码,其中通过扩增包括感兴趣的序列的所述样品中的双链dna片段并且将衔接头附接至所述双链dna片段来获得所述多个扩增的多核苷酸;(b)用于鉴定多个物理umi的代码,每个umi存在于多个扩增的多核苷酸之一,其中其中每个物理umi来源于附接至所述双链dna片段之一的衔接头中;(c)用于鉴定多个虚拟umi的代码,所述虚拟umi各自存在于多个扩增的多核苷酸之一中,其中每个虚拟umi来源于双链dna片段之一的单独分子;和(d)用于测定所述双链dna片段的序列的代码,所述测定使用所述多个扩增的多核苷
酸、所述多个物理umi、和所述多个虚拟umi的读段进行,从而减少所述双链dna片段的测定序列中的误差。
[0368]
在一些实施方案中,物理umi包括非随机umi。在其它实施方案中,物理umi包括随机umi。
[0369]
另一个实施方案提供了包含存储程序代码的非瞬态机器可读介质的计算机程序产品,所述程序代码当由计算机系统的一个或多个处理器执行时,使计算机系统实施用于测定测试样品中核酸片段的序列的方法。程序代码可以包括:(a)用于将衔接头应用到样品中dna片段的两个末端的代码,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物;(b)用于扩增dna
‑
衔接头产物以获得多个扩增的多核苷酸的代码;(c)用于对多个扩增的多核苷酸测序以获得与多个非随机umi相关联的多个读段的代码;(d)用于从多个读段来鉴定共享共同非随机umi的读段的代码;以及(e)用于从共享共同非随机umi的鉴定读段测定来自样品的dna片段的至少一部分的序列的代码,所述部分具有含共同非随机umi的应用的衔接子。
[0370]
另一个实施方案中,所述程序代码包括:(a)用于将衔接头应用到样品中双链dna片段的两个末端的代码,其中所述衔接头各自包含双链杂交区、单链5’臂、单链3’臂,和衔接头的一条链或每条链上的非随机独特分子索引(umi),从而获得dna
‑
衔接头产物,其中非随机umi可以与其它信息相组合以独特地鉴定双链dna片段的单独分子;(b)用于扩增dna
‑
衔接头产物的两条链以获得多个扩增的多核苷酸的代码;(c)用于对多个扩增的多核苷酸测序,从而获得多个读段的代码,其中所述读段各自与非随机umi相关联;(d)鉴定与多个读段相关联的多个非随机umi;以及(e)用于使用多个读段和多个非随机umi以测定样品中双链dna片段的序列的代码。
[0371]
在一些实施方案中,指令还可以包括自动记录与方法有关的信息。患者医疗记录可以通过例如实验室、医师的办公室、医院、保健组织、保险公司或个人医疗记录网站保持。而且,基于处理器
‑
实施的分析的结果,方法还可以涉及规定、启动和/或改变测试样品所取自的人受试者的治疗。这可以涉及在取自受试者的额外样品上进行一个或多个额外的测试或分析。
[0372]
也可以使用适于或配置成进行测定感兴趣的序列的方法的计算机处理系统进行公开的方法。一个实施方案提供适于或配置成进行如本文所述方法的计算机处理系统。在一个实施方案中,设备包括测序装置,其适于或配置成用于对样品中的至少一部分核酸分子进行测序以获得本文别处所述的序列信息类型。设备还可以包括处理样品的组件。在本文别处描述了此类组件。
[0373]
可以将序列或其它数据输入计算机或者直接或间接地存储在计算机可读介质上。在一个实施方案中,计算机系统与读取和/或分析来自样品的核酸序列的测序装置直接连接。经由计算机系统中的界面提供来自此类工具的序列或其它信息。或者,通过系统处理的序列由序列存储源如数据库或其它存储库(repository)提供。一旦对处理设备可用,存储器装置或大容量存储装置至少临时地缓冲或存储核酸序列。另外,存储器装置可以存储各种染色体或基因组的标签计数,等等。存储器也可以存储用于分析呈现序列或定位数据的各种例程和/或程序。此类程序/例程可以包括进行统计分析的程序等。
[0374]
在一个实例中,用户向测序设备中提供样品。通过与计算机连接的测序设备收集和/或分析数据。计算机上的软件允许数据收集和/或分析。可以将数据存储、显示(经由显示器或其它类似装置)和/或发送至另一位置。可以将计算机连接至因特网,其用于将数据传输至远程用户(例如医师、科学家或分析师)利用的手持装置。应理解,在传输之前,可以存储和/或分析数据。在一些实施方案中,将原始数据收集并发送至分析和/或存储数据的远程用户或设备。传输可以经由因特网发生,但也可以经由卫星或其它连接发生。或者,可以将数据存储在计算机可读介质上,以及可以将介质运送到最终用户(例如经由邮件)。远程用户可以在相同或不同的地理位置,其包括但不限于建筑物、城市、州、国家或洲。
[0375]
在一些实施方案中,方法还包括收集关于多个多核苷酸序列(例如读段、标签和/或参考染色体序列)的数据,并将该数据发送至计算机或其它计算系统。例如,可以将计算机连接至实验室仪器,例如样品收集设备、核苷酸扩增设备、核苷酸测序设备或杂交设备。然后,计算机可以收集实验室装置收集的可适用的数据。可以在任何步骤将数据存储在计算机上,例如实时收集时、发送之前、在发送期间或与发送结合或发送后。可以将数据存储在可以从计算机拔出的计算机可读介质上。可以例如经由局部网络或广域网络如因特网将收集或存储的数据从计算机传输到远程位置。在远程位置,可以在传输的数据上进行各种操作,如下文所述。
[0376]
可以在本文公开的系统、设备和方法中存储、传输、分析和/或操作的电子格式数据的类型为下列各项:
[0377]
通过对测试样品中的核酸测序获得的读段
[0378]
通过将读段与参考基因组或其它参考序列比对获得的标签
[0379]
参考基因组或序列
[0380]
调用测试样品的阈值,作为受影响的调用、未受影响的调用、或无调用与感兴趣的序列相关的医疗病况的实际调用
[0381]
诊断(与调用相关的临床病况)
[0382]
来源于调用和/或诊断的进一步测试的推荐
[0383]
来源于调用和/或诊断的治疗和/或监测计划
[0384]
使用独特的装置在一个或多个位置处获得、存储、传输、分析和/或操作这些各种类型的数据。处理选项跨越宽范围。在范围的一端,全部或大量此信息在处理测试样品的位置,例如医生的办公室或其它临床环境存储和使用。在其它极端情况中,在一个位置获得样品,在不同位置对样品进行处理和任选测序,在一个或多个不同位置比对读段和进行调用,以及在另一位置(其可以为获得样品的位置)准备诊断、推荐和/或计划。
[0385]
在多个实施方案中,利用测序设备产生读段,然后将其传输至远程位置,在那里,对其进行处理以测定感兴趣的序列。在该远程位置,例如,将读段与参考序列比对以产生锚读段和锚定读段。可以在不同位置采用的处理操作为下述各项:
[0386]
样品收集
[0387]
在测序之前的样品处理
[0388]
测序
[0389]
分析序列数据和得到医用调用
[0390]
诊断
[0391]
向患者或健康护理提供者报告诊断和/或调用
[0392]
形成进一步治疗、测试和/或监测的计划
[0393]
执行计划
[0394]
咨询
[0395]
这些操作中的任何一个或多个可以是自动化的,如本文别处所述。通常,以计算方式进行序列数据的测序和分析以及得到医用调用。其它操作可以手动地或自动地进行。
[0396]
图6显示从测试样品产生调用或诊断的分散系统的一个实施方案。样品收集位置01用于从患者获得测试样品。然后,将样品提供至处理和测序位置03,在那里可以如上文所述对测试样品进行处理和测序。位置03包括用于处理样品的设备以及对处理的样品进行测序的设备。如在本文别处所述的,测序的结果为读段的集合,所述读段通常以电子格式提供,并且提供至诸如因特网的网络,其通过图6中的参考编号05指示。
[0397]
将序列数据提供至远程位置07,在那里进行分析和调用产生。该位置可以包括一个或多个强大的计算装置,如计算机或处理器。在位置07的计算资源已经完成它们的分析并从接收的序列信息产生调用之后,将调用中继回网络05。在一些实施方案中,不仅是在位置07产生的调用,而且还产生相关诊断。然后,调用和/或诊断在网络间传输并回到样品收集位置01,如图6所示。如所解释的,这仅仅是与产生调用或诊断相关的各种操作如何可以在各种位置间分开的许多变型之一。一种常见的变型涉及在单个位置提供样品收集以及处理和测序。另一变化涉及在与分析和调用产生相同的位置提供处理和测序。
实施例
[0398]
实施例1
[0399]
使用随机物理umi和虚拟umi的误差抑制
[0400]
图7a和图7b显示的实验数据证明了使用本文公开的方法抑制误差的有效性。实验者使用na12878的剪切gdna。他们使用truseq文库制备和用自定义组(custom panel)(约130kb)的富集。使用hiseq2500快速模式以2x150bp进行测序,并且平均靶物覆盖率(mean target coverage)为约10,000x。图7a显示了使用标准方法的高质量碱基(>q30)的误差率(第二高碱基的等位基因频率)概貌(profile)(平均误差率为0.04%)。图7b显示了折拢/umi管线的误差率概貌(平均误差率为0.007%)。注意,这些结果基于原型代码,并且可以使用改善的方法实现误差率的进一步降低。
[0401]
实施例2
[0402]
使用非随机物理umi和位置的误差抑制
[0403]
图8所示的数据说明了单独使用位置信息来折拢读段倾向于折拢实际上源自不同源分子的读段。这种现象也称为读段冲突(read collision)。因此,该方法倾向于低估样品中片段的数量。图8的y轴示出的是通过单独使用位置信息来折拢读段而观察到的片段计数。因此,图8的x轴上是考虑了不同的基因型(如不同的snp和其它基因型差异)的估计的片段计数。如图所示,该观察的片段计数少于调整了基因型的片段计数,这说明仅使用位置信息来折拢读段和鉴定片段的低估和读段冲突。
[0404]
图9描绘的经验数据说明了使用非随机umi和位置信息来折拢读段可以比单独使用位置信息提供更为精确的片段估计。非随机umi是位于衔接头双链末端的6bp、双链体
umi,该非随机umi选自96个不同的umi之一。描绘在y轴上的是平均折拢片段计数,其中基于位置的折拢方法位于每对柱(bar)的左侧,并且基于umi和位置的折拢方法位于每对柱的右侧。左侧的三对柱显示了三个增加输入的无细胞dna样品的数据。右侧的三对柱显示了三个剪切基因组dna样品的数据。两种折拢方法的成对比较显示了基于umi和位置的折拢比单独使用位置进行折拢提供更高的片段计数的估计。两种折拢方法的比较显示出对于无细胞dna样品比四种基因组dna样品更大的差异。此外,无细胞dna样品的差异随着样品输入增加而增加。该数据表明,使用非随机umi和位置信息两者的折拢能纠正读段冲突和片段低估,特别是对于无细胞dna。
[0405]
图10以表格形式显示了在用随机umi处理的三种样品中出现的不同误差。前三行数据表示43个样品的不同类型误差的百分比。最后一行显示了样品间平均的误差率。如表所示,97.58%的umi不包含误差,并且1.07%的umi包含一个可恢复的误差(era)。超过98.65%的所有umi可用于将个别dna片段索引化。当与上下文信息相结合时,其余许多仍然可以是可用的。
[0406]
图11a显示了使用两种不同的工具:varscan和denovo用两种折拢方法调用gdna样品中的体细胞突变和cnv的灵敏度和选择性。与varscan工具一起应用,使用umi和位置信息两者的折拢提供了稍高的灵敏度和显著更好的选择性(更低的假阳性率),如当umi与位置一起使用时roc曲线向左上方移动所示。与denovo工具一起应用,使用umi和位置信息两者的折拢提供了显著更高的灵敏度。
[0407]
图11b
‑
图11c显示了使两种不同的工具:varscan和denovo用两种折拢方法来调用具有增加的样品输入的三种cfdna样品中体细胞突变和cnv的选择性(即,假阳性率)。与varscan工具一起应用,使用umi和位置信息两者的折拢为所有三种样品提供了显著更好的选择性(更低的假阳性率)。与denovo工具一起应用,使用umi和位置信息两者的折拢仅在具有最大输入的样品中提供更好的选择性(更低的误报率(false alarm rate))。
[0408]
本公开可以在没有背离其精神或或基本特征的情况下以其它具体形式体现。所述实施方案在所有方面仅被视为示例性而非限制性的。因此,本公开的范围通过所附权利要求书而不是前述说明书指示。落入与权利要求书等同的意义和范围内的所有改变包含在其范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1