一种基于全频带声波定向系统降低功耗的方法与流程
本发明涉及声学参量阵技术,特别是涉及一种全频带声波技术以及降低功耗的方法。
背景技术:
全频带声波定向系统是基于声学参量阵原理,其基本原理是通过不同高频声波在介质中的非线性自解调作用产生高指向性的差频可听声,可以用来实现全频带自然音效定向扬声器。
声波定向技术的研究最早可追溯到18世纪中叶心理学中的Tartini音调发现,即当两个稳定的音调一起发出时,产生的第三声也可听见。1962年布朗大学的物理学教授Peter Westervelt提出了参量声学阵的概念,1965年,Berktay为Westvelt所提出的声参量阵给出了更完整的理论解释,推导出了远场中参量声学阵的非线性自解调声压值与原波输入信号包络平方的二次时间到成正比,即“Berktay远场解”。但由于当时超声换能器性能和复杂数字信号处理技术的限制,对于声波定向系统的研制还一直出于实验研究阶段。随着超声换能器性能的提高以及集成电路的快速发展,20世纪80年代初,日本开始了声波定向系统的具体制作,2001年左右美国ATC公司首次推出了一款名“超音频声音的商业化声波定向系统”,之后几年,国内也开始了对声波定向系统的研制工作。
利用传统的声波定向系统实现声波定向传输的同时,是以牺牲大功率消耗以及的低转换效率为代价。基本原理为通过调制后的超声宽带信号进超声功放放大后加载到阵列换能器上,利用发出的超声波信号在空气中经过非线性自解调作用产生了高指向性的低频可听声。但在这自解调作用下产生的可听声能量相对于原超声能量是很小的一部分,从而导致能量转换效率较低,无效功率消耗较大。
传统的声波定向系统在连续不间断工作时处于较大功率下进行,因此如果不采取有效的方法进行降低功耗,将会给系统的稳定性问题。传统的声波定向系统因没有输入音频信号时,外界噪声传入以及系统电流噪声信号中间经过超声功放放大,最后经阵列换能器发出带来强烈的噪声问题。
技术实现要素:
本发明的目的是提供一种基于全频带声波定向系统降低功耗的方法,以解决传统的声频定向系统因连续不间断发送载波信号而带来不必要的功率损耗问题,同时该方法使得系统功放无需连续长时间工作进一步使系统的稳定性得到了很大提高。同时,降低系统电流噪声,解决系统在没有输入音频信号时,因外界噪声传入以及系统电流噪声信号中间经过超声功放放大,最后经阵列换能器发出带来强烈的噪声问题。
本发明所涉及的全频带声波定向系统包括:前级信号调理和ADC信号采样,采集20~20kHz的音频信号;信号调制处理,信号调制处理的方式可以是基于SSB、DSB、平方根调制算法结合声参量阵学原理实现声波定向技术的信号调制算法。
具体的,本发明的一种基于全频带声波定向系统降低功耗的方法,包括下列步骤:
步骤1:系统开启后,检测输入端口是否存在音频信号;若是,则执行步骤2;否则执行步骤3;
步骤2:将输出端的载波信号幅值降低,例如降低到原来的0.2~0.5倍;
步骤3:判断当前音频信号是否达到阈值,若是,则恢复输出端载波信号幅值;否则执行步骤2。
本发明根据原声波定向系统因持续输出大功率载频信号带来不必要的功率消耗而提出的一种自适应调整载频幅值的方法。同时,本发明还可以带来较小输出噪声。在系统正常开启但不放音乐或使用麦克不讲话,由于有小的噪声输入或者因电路引起的噪声或因换能器激振引起噪声信号时,该噪声信号会和载频信号一起通过超声换能器发射出去,由于在空气中非线性作用自解调出可听声干扰噪声,然而本方法可以很好的解决该问题。
进一步的,判断当前音频信号是否达到阈值的具体方式可以从下述任选其一即可:
判决方式1:在系统初始化时,对输入端口进行信号采集,提取一段时序内的信号s2[n],即环境噪声,其中n∈[n1,n2],n1、n2分别表示一段时序的起点和终点;并设置阈值其中d表示直流偏置值;当输入端口存在音频信时,采集一段时序内的音频信号s1[n],其中n∈[n1,n2];并对音频信号s1[n]进行减直流偏置后平方求和处理,得到将与阈值T比较,若大于或等于阈值T,则判定当前音频信号达到阈值T。
判决方式2:在系统初始化时,对输出端口进行信号采集,提取一段信号序列y2[n](环境噪声的输出信号),设置阈值T为所述信号序列的频谱线;当输入端口存在音频信时,对输出端口进行信号采集,提取一段音频信号的输出信号序列y1[n],并将输出信号序列的频谱线与阈值T比较,若大于或等于阈值T,则判定当前音频信号达到阈值T。
另外,还可以将上述两种判决方式进行融合判决,即设置第一、第二两个判别器(第一判别器采用判决方式1,第二判别器采用判决方式2),分别通过第一、第二判别器对当前音频信号是否达到阈值进行判定,若到达阈值,则将判别结果记为1,否则记为0;对第一、第二判别器的判别结果进行加权求和,并与融合阈值进行比较,若大于或等于融合阈值(经验值),则恢复输出端载波信号幅值;否则执行步骤2。
综上,本发明的优点在于可以基于已有的硬件平台,无需增加任何硬件电路基础上进行软件程序设计,为声波定向系统减小了很大不必要的功率损耗,同时减少一定干扰噪声。
附图说明
图1为本发明中所运用的声波定向技术原理分析图。
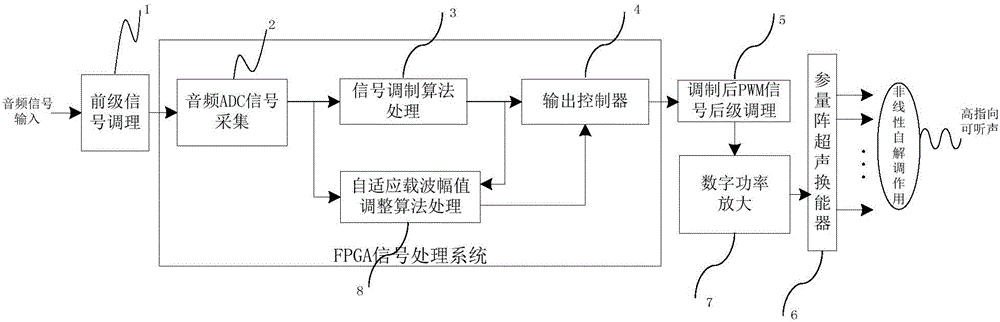
图2为实现本发明降低功耗方法的声波定向系统框图。
图3为本发明中自适应载波幅值调整算法的实现框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
本发明的实现是在基本声波定向系统的硬件平台上进行的,因此对于本发明的实现需要根据具体的平台给予讲述,具体实施步骤如下:
图1示出了为声波定向系统实现声波定向传播的最基本原理。在超声波阵列上发出两个不同频率的波f1和f2,在空气中经过非线性自解调作用产生了频谱为f1+f2,f1-f2,2f1,2f2,以及还有原波f1,f2。由于原波f1,f2及f1+f2,2f1,2f2等均是超声波,在空气中会很快得到衰减,而f1-f2正是我们所需要的高指向差频可听声。
图2示出了实现本发明降低功耗方法的声波定向系统框图,具体包括:
前级信号调理电路1,音频ADC采样电路2,信号调制算法3,输出控制器4,调制后PWM信号后级处理5,超声阵列换能器6,数字功率放大器7,自适应载波幅值调整算法处理8。20Hz-20kHz的信号经过信号调理电路1给ADC采集电路2,获得的数字音频信号一方面用于信号调制算法处理3;另一方面用于自适应载波幅值调整算法处理8,之后由输出控制器控制PWM信号输出。输出的PWM信号电压需要作电平转换处理,最后由数字功放输出到超声阵列换能器上。
图3示出了本发明中自适应载波幅值调整的实现框图。系统开启一段时间内,先初始化音频信号缓冲区数据,由FPGA处理器采集并计算环境噪声能量图3中图标10,由获得阈值1并传给判别器1;以及对输入信号s3[n]调制后的信号序列y2[n]的噪声频谱分析14,拓展序列y2[n]计算DFS(或FFT,下同),其中n=0,...,N-1,获得阈值2:其中(N表示每次获取序列中的数据个数,e表示自然底数,j为虚数单位,K表示序列个数),并将阈值2传给判别器2;
当音频信号输入系统工作后,将间隔采集一段音频序列并计算图3中图标9,并将传给判别器1;并对输入信号s4[n]调制后的信号序列y1[n]进行频谱分析,拓展序列y1[n]计算DFS,(n=0,...,N-1),获得并传给判别器2,其中
判别器1对与阈值1进行比较,若大于或等于,则判决结果为1;否则为0。并向判别器3输出判决结果;判别器2对与阈值2进行比较,若大于或等于,则判决结果为1;否则为0。并向判别器3输出判决结果。
判别器3对判别器1和判别器2的判决结果进行加权求和,与预设的融合阈值进行比较,并向输出控制器发出对应指令:若大于等于融合阈值,则发出恢复指令,由输出控制器将输出端的载波信号幅值下降到原来的1倍;若小于融合阈值,则发出下降指令,由输出控制器将将输出端的载波信号幅值下降到原来的0.2~0.5倍。
然后分别结合前面求的环境噪声能量和调制后信号频谱进入判别器1或者判别器2,对判别结果进行权值加权计算,最后对通过控制输出控制器进行输出。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!