一种改进的多扩展目标跟踪方法与流程
本发明属于目标跟踪领域,特别是一种改进的多扩展目标跟踪方法。
背景技术:
随着高分辨率传感器的广泛应用,扩展目标跟踪(ett)技术的研究成为一个热点。特别是雷达分辨率的不断提高,在每一时刻能接收到同一目标不同等效散射中心的多个量测,此时,目标不再是点目标,而是扩展目标。近年来,ronaldp.s.mahler教授提出了基于随机有限集(rfs)理论的概率假设密度(probabilityhypothesisdensity,phd)滤波算法,该算法在不考虑数据关联的情况下,可同时实现目标数目和目标状态的估计。它首先跟踪整个目标群,随后再去检测每个变量。然而phd滤波存在漏检敏感,无数目分布的问题。针对这些问题,势概率假设密度(cphd)滤波器应运而生,相比较phd滤波器,cphd滤波器能对目标的势分布也进行更新,尤其适用于多扩展目标跟踪(mett)问题。
量测集划分是多扩展目标跟踪中首要解决的关键问题之一,理论上,基于rfs的扩展目标滤波器需要考虑量测集的所有可能划分,但所有可能的划分个数随目标个数的增加急速增大。granstrm等人率先提出采用距离划分、k-means、预测划分和期望最大划分等方法划分量测集,但这些方法都存在一些问题。density-basedspatialclusteringofapplicationswithnoise(dbscan)作为基于密度算法的经典代表,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类,适用于杂波环境下的扩展目标跟踪。
在实际雷达量测信息中,特别在扩展目标跟踪时,多普勒盲区不可避免的会存在并导致部分目标测量信息的丢失,从而影响滤波精度。因此,需要在目标量测数据丢失(雷达盲区)情况下保持其滤波精度;其次,在跟踪精度提高的同时,cphd滤波器的计算复杂度也远大于phd滤波器,因此,算法的计算复杂度需要得到优化;最后,dbscan算法与cphd滤波器的结合问题也需要解决。综上所述,在实际雷达量测信息中,存在多扩展目标量测集划分、量测数据丢失及计算复杂的问题,
技术实现要素:
本发明的目的在于提供一种计算简单、精度高的改进的多扩展目标跟踪方法,从而提高多扩展目标跟踪性能。
实现本发明的目的技术解决方案为:一种改进的多扩展目标跟踪方法,包括以下步骤:
步骤1、聚类:对传感器的量测数据集进行聚类划分;
步骤2、初始化:初始目标的概率假设密度d0(x)及势分布p0(n);
步骤3、预测更新:对目标状态集xk在k+1时刻的概率假设密度及势分布进行预测并更新,得到此时刻的概率假设密度dk+1(x)及势分布pk+1(n),其中k≥1;
步骤4、修剪合并:对目标的强度函数的高斯项进行修剪合并,提取目标状态估计,进行性能评估;
步骤5、重复步骤3~4,跟踪目标直到目标消失。
进一步地,步骤1中所述的对传感器的量测数据集进行聚类划分,具体步骤如下:
1.1)初始化dbscan算法的两个参数:半径参数б和邻域密度阀值minpts;
对象p的б邻域:对于数据空间,即量测数据集中任意一个数据对象p,其б邻域是以p为圆心、以б为半径的圆形区域内的对象的集合,记为
nб(p)={q|q∈d∩d(p,q)<б}
式中d为量测数据集,d(p,q)为对象p与点q间的距离;
核心对象:如果对象p的б邻域内至少包含minpts个对象,则对象p为核心对象;
直接密度可达:对于样本集合d,如果样本点q在p的б领域内,并且p为核心对象,那么对象q从对象p直接密度可达;
密度可达:对于样本集合d,给定一串样本点p1,p2….pn,其中p=p1,q=pn,如果对象pi从pi-1直接密度可达,那么对象q从对象p密度可达;
密度相连:对于样本集合d中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联;
基于密度的簇:基于密度可达性的最大的密度相连对象的集合;
1.2)输入量测数据集d,从数据集d中随机抽取一个未被处理的对象p,对p的б邻域内对象数目进行统计,若p的б邻域内对象数目达到minpts,则将p记为核心对象,否则将对象p标记为已处理,从数据集d中抽取下一个未被处理的对象p进行统计;
1.3)遍历量测数据集d,记录所有的核心对象,找到所有核心对象的密度可达对象,形成一个新的簇,进而通过密度相连得到最终簇结果;
1.4)对量测数据集d进行更新,用得到的最终簇结果代替之前的量测数据集d,完成聚类步骤。
进一步地,步骤3中所述的预测更新,具体步骤如下:
3.1)预测:对目标状态集xk在k+1时刻的概率假设密度dk+1|k(x)及势分布pk+1|k(n)进行预测:
在k时刻,已知的参数有:概率假设密度dk(x)、目标数的期望nk、势分布pk(x),则k时刻存活下来的目标状态集xk的概率假设密度为:
dk+1|k(ξ)=∫ps(x')·fk+1|k(x|x')·dk|k(x')dx'
其中:ps(x')为目标存活概率,fk+1|k(x|x')为单目标马儿可夫转移密度;dk|k(x')为前一时刻目标状态集xk的概率假设密度;
势分布pk+1|k(n)为:
其中:
3.2)更新:对目标状态集xk在k+1时刻的概率假设密度dk+1(x)及势分布pk+1(n)进行更新:
在预测目标状态的强度函数υk+1|k(x)和势分布pk+1|k已知情况下,得到cphd滤波器的更新方程如下:
势分布更新:
目标状态的强度函数更新:
目标数更新:
其中
其中,δj(·)为均衡函数,κk(·)为杂波强度函数,
进一步地,步骤3中所述的预测更新,具体如下:
a)比例因子的引入
在三维坐标系中,目标运动时的多普勒频移fd表示为:
其中vt和va分别是目标和载机的运动速度,φ是载机航线与雷达间的偏角,β是目标与载机间的航向偏角;
多普勒盲区fd≤δf,此时的多普勒盲区为[-δf,δf],目标多普勒频移为:
其中,vr是目标相对于传感器的径向速度,f0是目标辐射源的发射频率,c是目标辐射源信号的传播速度;
基于gm-cphd算法框架,结合dbscan聚类,提出dbscan-cphd滤波算法,具体如下:
首先,采用dbscan算法对传感器的量测数据集进行聚类划分;
然后,在增益矩阵求取公式中添加一个n维方阵λ(k)用来调节gm-cphd滤波器的增益矩阵,得:
s(k+1)=h(k+1)p(k+1|k)ht(k+1)+(λ(k)-i)r0(k+1)+r(k+1)
式中,i是单位阵,r0(k+1)是对角阵,其取值为r(k+1)的对角元素,h为观测矩阵;
其中,s(k+1)的计算公式为:
ξ是滑动窗口数目,e(k+1)为量测误差向量;
最后,计算λ(k):
设增益调节矩阵为λ*(k),求取公式如下:
式中,λii(k)是λ(k)的i行i列元素,即λ(k)对角线上的第i个元素;
b)自适应门限的设计
首先设置门限γ:
其中,pd为检测概率,β为新源密度;
从公式可知,门限γ与残差协方差矩阵s(k)有关,而s(k)是一个变量;
然后,将门限区域的量测集合表示为:
最后,由于量测集合由zk变化为
其中,
进一步地,步骤4中所述的对目标的强度函数的高斯项进行修剪合并,提取目标状态估计,进行性能评估,具体如下:
修剪:将小于权值τ的高斯成分滤掉;
合并:当高斯成分间的距离小于阈值u时,将这些高斯成分合并;
状态估计:提取权值大于τ1的高斯成分;
性能评价:采用ospa距离误差作为指标,对目标跟踪结果进行评价。
本发明与现有技术相比,其显著优点在于:(1)在高斯混合势概率假设密度滤波框架下引入dbscan算法,克服了gm-cphd滤波器难以对多扩展目标进行有效跟踪的问题,提高了杂波环境下的目标跟踪精度;(2)比例因子的引入和自适应门限的设计,解决了量测数据丢失及计算复杂度优化问题,提高多扩展目标跟踪性能,使gm-cphd滤波器的工程应用成为可能。
附图说明
图1是本发明改进的多扩展目标跟踪方法的总流程示意图。
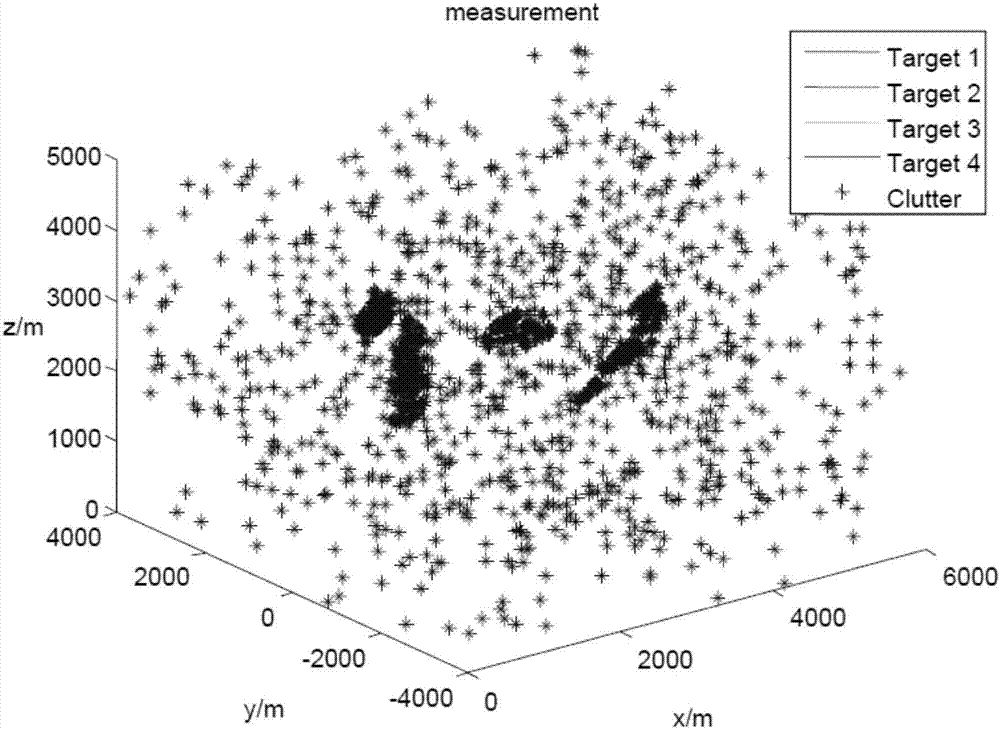
图2是本发明中目标量测信息示意图。
图3是本发明与传统方法滤波结果三维图。
图4是本发明滤波结果二维详细图。
图5是本发明与传统方法估计的目标个数图。
图6是本发明与传统算法运行耗费时间对比图。
图7是各算法ospa距离图。
图8是本发明算法ospa距离放大图。
具体实施方式
结合图1,本发明改进的多扩展目标跟踪方法,该方法在高斯混合势概率假设密度(gm-cphd)滤波框架下,在量测集处理过程中引入dbscan算法来划分量测集合,从而达到跟踪扩展目标的功能;然后利用比例因子和自适应门限,分别调节滤波器增益矩阵和观测体积,提高滤波器鲁棒性,减小计算量。具体步骤如下:
步骤1、聚类:对传感器的量测数据集进行聚类划分。
采用dbscan算法,对传感器的量测数据集进行聚类划分:
首先初始化dbscan算法的两个参数,分别是半径参数б和邻域密度阀值minpts。
对象p的б邻域:对于数据空间,即量测数据集中任意一个数据对象p,其б邻域是以p为圆心、以б为半径的圆形区域内的对象的集合,记为
nб(p)={q|q∈d∩d(p,q)<б}
式中d为量测数据集,d(p,q)为对象p与点q间的距离;
核心对象:如果对象p的б邻域内至少包含minpts个对象,则对象p为核心对象;
直接密度可达:对于样本集合d,如果样本点q在p的б领域内,并且p为核心对象,那么对象q从对象p直接密度可达;
密度可达:对于样本集合d,给定一串样本点p1,p2….pn,其中p=p1,q=pn,如果对象pi从pi-1直接密度可达,那么对象q从对象p密度可达;
密度相连:对于样本集合d中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联;
基于密度的簇:基于密度可达性的最大的密度相连对象的集合。
然后,输入量测数据集d,从数据集d中随机抽取一个未被处理的对象p,对p的б邻域内对象数目进行统计,若p的б邻域内对象数目达到minpts,则将p记为核心对象,否则将对象p标记为已处理,从d中抽取下一个未被处理的对象p进行统计。
最后,遍历量测数据集d,记录所有的核心对象,找到所有从核心对象的密度可达对象,形成一个新的簇,进而通过密度相连得到最终簇结果。最后对量测数据集d进行更新,用得到的最终簇结果代替之前的量测数据集d,完成聚类步骤。
针对多扩展目标的高斯白噪声现象,在dbscan算法中,可以通过设定合理的半径参数б和邻域密度阀值minpts,使最终簇中不包含噪声数据,从而达到去噪效果。
步骤2、初始化:初始化目标的概率假设密度d0(x)及势分布p0(n)。初始概率假设密度d0(x)符合高斯分布,可以用每个目标的正态分布概率和表示;势分布p0(n)为目标数n的概率分布。
步骤3、预测更新:
3.1)预测:对目标状态集xk在k+1时刻的概率假设密度dk+1|k(x)及势分布pk+1|k(n)进行预测。在k时刻,已知的参数有:概率假设密度dk(x)、目标数的期望nk、势分布pk(x),则k时刻存活下来的目标状态集xk的概率假设密度为:
dk+1|k(ξ)=∫ps(x')·fk+1|k(x|x')·dk|k(x')dx'
其中:ps(x')为目标存活概率,fk+1|k(x|x')为单目标马儿可夫转移密度;dk|k(x')为前一时刻目标状态集xk的概率假设密度。
势分布pk+1|k(n)为:
其中:
3.2)更新:对目标状态集xk在k+1时刻的概率假设密度dk+1(x)及势分布pk+1(n)进行更新。在预测目标状态的强度函数υk+1|k(x)和势分布pk+1|k已知情况下,可以得到cphd滤波器的更新方程如下:
势分布更新:
目标状态的强度函数更新:
目标数更新:
其中
其中,δj(·)为均衡函数,κk(·)为杂波强度函数,
a)比例因子的引入
在实际雷达量测信息中,特别在扩展目标跟踪时,多普勒盲区不可避免的会存在并导致部分目标测量信息的丢失,从而影响滤波精度。因此,需要在目标量测数据丢失(雷达盲区)情况下保持其滤波精度,而通过引入比例因子调节滤波算法的增益矩阵,可以降低算法在目标数据丢失时给滤波精度带来的影响。
在三维坐标系中,目标运动时的多普勒频移可以表示为:
其中vt和va分别是目标和载机的运动速度,φ是载机航线与雷达间的偏角,β是目标与载机间的航向偏角。
多普勒盲区|fd|≤δf,此时的多普勒盲区为[-δf,δf],目标多普勒频移为:
其中,vr是目标相对于传感器的径向速度,f0是目标辐射源的发射频率,c是目标辐射源信号的传播速度,
基于此,本发明基于gm-cphd算法框架,结合dbscan聚类,提出了一种鲁棒的dbscan-cphd滤波算法,具体如下:
首先,采用dbscan算法对传感器的量测数据集进行聚类划分。
然后,在增益矩阵求取公式中添加一个n维方阵λ(k)用来调节gm-cphd滤波器的增益矩阵,可得:
s(k+1)=h(k+1)p(k+1|k)ht(k+1)+(λ(k)-i)r0(k+1)+r(k+1)
式中,i是单位阵,r0(k+1)是对角阵,其取值为r(k+1)的对角元素,h为观测矩阵。
其中,s(k+1)的计算公式为:
ξ是滑动窗口数目,e(k+1)为量测误差向量。
最后,计算λ(k):
设增益调节矩阵为λ*(k),求取公式如下:
式中,λii(k)是λ(k)的i行i列元素,即λ(k)对角线上的第i个元素。
在gm-cphd框架中加入了比例因子λ*(k),当预测数据与量测数据误差很大时,比例因子λ*(k)通过之前的目标数据信息,对增益矩阵进行调节,减小盲区导致的数据丢失对滤波估计值和协方差的影响,提高算法的鲁棒性。
b)自适应门限的设计
作为一种经典的多目标跟踪算法,cphd算法在跟踪精度提高的同时也伴随着计算复杂度的提高,cphd和phd滤波器的计算复杂度分别为o(nm3)和o(nm)。所以,对于cphd滤波器,减小数据集的量测数目(m)能更有效的降低计算复杂度,而自适应门限可以降低m值。具体步骤如下:
首先设置门限γ:
其中,pd为检测概率,β为新源密度;从公式中可以看出,门限γ与残差协方差矩阵s(k)有关,而s(k)是一个变量。
然后,将门限区域的量测集合表示为:
最后,由于量测集合由zk变化为
其中,
通过设计自适应门限,减小量测集合zk,从而影响杂波强度函数κk(z),进而降低量测区域体积vk,降低量测数目m,达到减小滤波器计算复杂度的目的。
步骤4、修剪合并:对目标的强度函数的高斯项进行修剪合并,提取目标状态估计,进行性能评估。
首先修剪:将小于权值τ的高斯成分滤掉。
然后合并:当一些高斯成分间的距离小于阈值u时,将这些高斯成分合并。
最后状态估计:目标的状态估计是提取权值大于τ1的高斯成分。
性能评价:采用ospa距离误差作为指标,对多目标跟踪算法的性能进行评价。ospa距离定义如下:
其中,
步骤5、重复步骤3-4,跟踪目标直到目标消失。
实施例1
本发明的效果可以通过以下仿真实验进一步说明:
1.仿真条件
设定目标状态
xt1=[3000,3000,2400,-30,-30,-10,-0,-0,0.4,0,0,-0.01]t;
xt2=[2000,1000,1600,30,30,15,-1,-1,0,0,0,-0]t;
xt3=[2000,1000,1600,30,30,15,-1,-1,0,0.01,0,-0.01]t;
xt4=[4000,2000,2100,-20,-30,-10,1,1,0,0,0,0.01]t;
对于不同的运动模型,目标的运动方程分别为:
jerk模型:
ct模型:
式中:p1=(2-2*alpha*t+alpha^2*t^2-2*exp(-alpha*t))/(2*alpha^3);
q1=(exp(-alpha*t)-1+alpha*t)/alpha^2;
r1=(1-exp(-alpha*t))/alpha;
s1=exp(-alpha*t);alpha为机动频率,ω为角速度,本案例中分别取0.1和0.5。
仿真实验假设各目标存在时间分别为t1=1-60s,t2=14-100s,t3=30-80s,和t4=39-100s。各目标各时间段运动模型分别为target1在1~26s&40~60s为ct模型,在26~40为jerk模型;target2在14~100s都为ct模型;target3在30~50s&65~80s为ct模型,在50~65s为jerk模型;target4在39-100s都为jerk模型。设雷达采样周期t=1s,检测概率pd=0.99,目标存活概率ps=0.9,状态估计阈值τ1=0.5,最大高斯数jmax=100。
2.仿真内容和结果分析
生成的目标量测信息如图2所示,量测信息中含有目标信息和杂波信息。
各算法目标位置估计与去除杂波后的量测值和真实值对比如图3所示。图中cphd代表本发明提出的基于dbscan的多扩展目标跟踪方法,cphd2代表加盲区情况下的ucm-ag-cphd,cphd3代表改进后的加盲区r-ucm-ag-cphd(“一种测量数据丢失情况下的多目标跟踪方法”(专利申请号201610816184.8)),phd代表传统的高斯混合概率假设密度滤波算法(gm-phd)。从图中可以看出,四个算法中,phd算法跟踪出现较大偏差,效果不够理想,其它三个基于cphd框架下的算法能够对各目标进行有效跟踪。
各目标二维轨迹如图4所示,黑点代表本发明算法(cphd)的滤波效果,从图中可以看出,算法对前三个目标的跟踪精度非常好,对目标4的jerk模型效果有所降低,这是因为目标4的运动特性发生改变,在65s,75s,83s和93s时,目标4的加速度和机动频率都发生了变化,故而影响了跟踪精度。
算法各个时刻估计的目标个数结果如图5所示,从图中可以看出,本发明算法(cphd)对目标数目的估计精度达到了98%,而其它三个算法的估计精度不足80%。
通过蒙特卡洛实验,得到本发明算法和传统gm-cphd算法耗费时间如图6所示,本发明算法dbscan-rag-cphd的自适应门限降低原算法计算复杂度的9.6%,与其它算法相比具有更好的工程应用前景。
由ospa距离结果图7可以看出,本发明算法(cphd)的ospa距离误差最小,跟踪精度最高(放大如图8所示),反映了聚类dbscan算法提高了扩展目标的跟踪精度;cphd3代表的改进后加盲区r-ucm-ag-cphd(“一种测量数据丢失情况下的多目标跟踪方法”(专利申请号201610816184.8))跟踪精度其次;phd代表的gm-phd算法跟踪精度最低,ospa距离误差在不断增大并发散。在16~18s,26~28s,31~33s和36~38s目标数据丢失时,本发明算法(cphd)和cphd3的ospa距离误差未发生明显变化,表明比例因子对跟踪精度的提高起到了好的作用,反观cphd2和phd算法在数据丢失段ospa距离误差发生了明显的增大,仿真表明,改进的算法对目标机动产生的盲区有良好的效果,对扩展目标能达到较高的跟踪精度。
综上所述,本发明一种改进的多扩展目标跟踪方法,克服了gm-cphd滤波器难以对多扩展目标进行有效跟踪的问题,提高了杂波环境下的目标跟踪精度,降低了雷达盲区造成的精度损失,减小了滤波器的计算量,有利于gm-cphd滤波器的工程应用。
- 还没有人留言评论。精彩留言会获得点赞!