复杂样本GC-MS自动解析实现化合物准确鉴别与差异性组分筛查的方法与流程
本发明属于气相色谱-质谱联用数据解析技术领域,具体涉及复杂样本gc-ms自动解析实现化合物准确鉴别与差异性组分筛查的方法。
背景技术:
gc-ms在众多实验室用于高通量表征复杂样本中的小分子挥发、半性成分。作为目前普及率最高的分析测试仪器之一,gc-ms本身提供的物质谱库为复杂样本分析提供了非常有帮助的工具。但在gc-ms的应用中,复杂样本中化合物的精准解析是当前应用中面临的一个难题。化合物解析包含了两个核心步骤,一是色谱峰的识别,二是共流出组分的解析。在代谢组学等涉及多样本同时分析进行比较的研究中,还包含了如何实现峰对齐的问题。当前,色谱峰的识别多针对tic中峰提取,围绕这个问题,目前已有一部分卓有成效的方法,但如何在tic提取的基础上实现共流出化合物的高通量、自动化解析,却是当前应用中的亟待解决的难题。
当前方法中对于峰对齐步骤没有给予太多的重视。根据我们的经验,化合物峰对齐不能只是依靠质谱谱图。样本构成复杂时,有可能存在共流出化合物质谱谱图相似的情况。此时,若仅仅依靠质谱谱图进行化合物峰对齐,会导致样本与样本之间存在多重匹配,给出错误的峰对齐结果,最终导致筛查出来的差异性化合物结果不可靠。
同时,发展智能化、可靠的gc-ms自动化解析方法实现化合物解析与识别,实现差异性代谢物的筛查,是当前gc-ms技术涉及的科研、检测、工业应用等领域,如食品分析、药物分析、香精香料、工业化学品分析等亟待解决的需求。
技术实现要素:
有鉴于此,本发明提供一种能够高效完成复杂样本gc-ms自动解析实现化合物准确鉴别与差异性组分筛查的方法。
本发明解决其技术问题所采用的技术手段是:
一种复杂样本gc-ms自动解析实现化合物准确鉴别与差异性组分筛查的方法,包括以下步骤:
a.提取gc-ms质谱中的tic色谱峰及eic色谱峰;
b.明确每个所述tic色谱峰的解析范围,查找解析范围内的所述eic色谱峰信息;
c.根据所查找得到eic色谱峰信息对所述eic色谱峰进行聚类,获得每一个类的代表性色谱轮廓谱图;
d.构建初始色谱谱图矩阵,利用修正的多元曲线分辨-交替最小二乘法对初始色谱谱图矩阵进行优化解析,获得每个所述tic色谱峰下的化学成分的质谱谱图;
e.构建质谱谱库,所述质谱谱库中包含标准化合物质谱谱图,将解析所得的每个tic色谱峰下的化学成分的质谱谱图导入至所述质谱谱库,进行单一样本的自动识别;
f.对不同样本分组,利用统计分析方法筛选组间有差异的代谢物;
其中,步骤c中,“对eic色谱峰进行聚类”方法为:根据每个所述eic色谱峰色谱轮廓谱图的形状,采用层次聚类法进行聚类,包括以下步骤:
c1.采用pearson相关系数衡量色谱轮廓之间的相似度;
c2.将相似度低于预定相似度阈值,并且eic色谱峰之间的距离大于预定距离阈值的相似度设置为0;
c3.根据相关系数从大到小,将eic色谱峰进行聚类。
本发明采用上述技术方案,其有益效果在于:本发明提供的复杂样本gc-ms自动解析实现化合物准确鉴别与差异性组分筛查的方法,采用层次聚类法,对所述eic色谱峰进行聚类,利用修正的多元曲线分辨-交替最小二乘法对初始色谱谱图矩阵进行优化解析,能够快速实现对复杂样本化合物的gc-ms数据精准解析,克服传统方法针对共流出组分解析中存在的解析不准确的问题,同时提供了一种复杂样本化合物自动识别以及差异性组分的筛查方法,达到自动高通量的精准解析。
附图说明
图1是tic色谱峰提取与确定解析范围示例。
图2是tic色谱峰下化合物解析与识别示例。
图3是考察本发明定性定量结果示例。
图4是样本中组分时间漂移校准与化合物注册示例。
图5是本发明筛选出来的差异性代谢中分析不提产地烟叶样品的聚类结果。
图6是当前不同方法解析所得结果。
具体实施方式
结合本发明的附图,对发明实施例的技术方案做进一步的详细阐述。
本发明通过以下示例展示智能化解析gc-ms数据准确实现化合物识别与差异性组分筛查。
s1.gc-ms信号采集
为了获得烟草植物样本中尽可能多的挥发性、半挥发性成分,对样本进行衍生化处理。具体如下:(1)称样20mg,甲醇氯仿提取其中的化学成分后,用bstfa与室温下衍生60min。取1μl进入gc-ms分析。
gc-ms条件设置如下:色谱柱db-5ms60m×0.25µm×0.25mm。程序升温,从70℃升温至310℃,升温速率3℃min-1。进样口温度180℃。传输线温度280℃。质谱采集范围50-500da,采样频率3scans-1。
s2.tic和eic色谱峰的提取与tic解析范围确定
以tic中峰提取为例。提取tic信号中的极小值,利用稳健统计分析剔除来源于色谱峰的极小值后,利用线性插值法估计背景漂移,并从原始信号中剔除出去,获得基线校正后的tic信号,作为原始信号。针对该信号,采用高斯平滑法实现色谱峰的提取。高斯平滑法采用一系列不同尺度的高斯函数作为平滑函数,通过卷积运算实现信号平滑。tic平滑后,获得一系列平滑后信号,提取每一个平滑信号的极大值,筛选不同平滑后均存在的极大值,作为初始色谱峰。在原始tic信号中剔除初始色谱峰左侧连续上升和右侧连续下降的部分,估计出原始信号中的噪声。将初始色谱峰中高于噪声的部分设置为流出范围。剔除信噪比低的色谱峰,优选剔除信噪比低于3的色谱峰,最终实现tic色谱峰的提取。eic色谱峰的提取与tic提取类似。
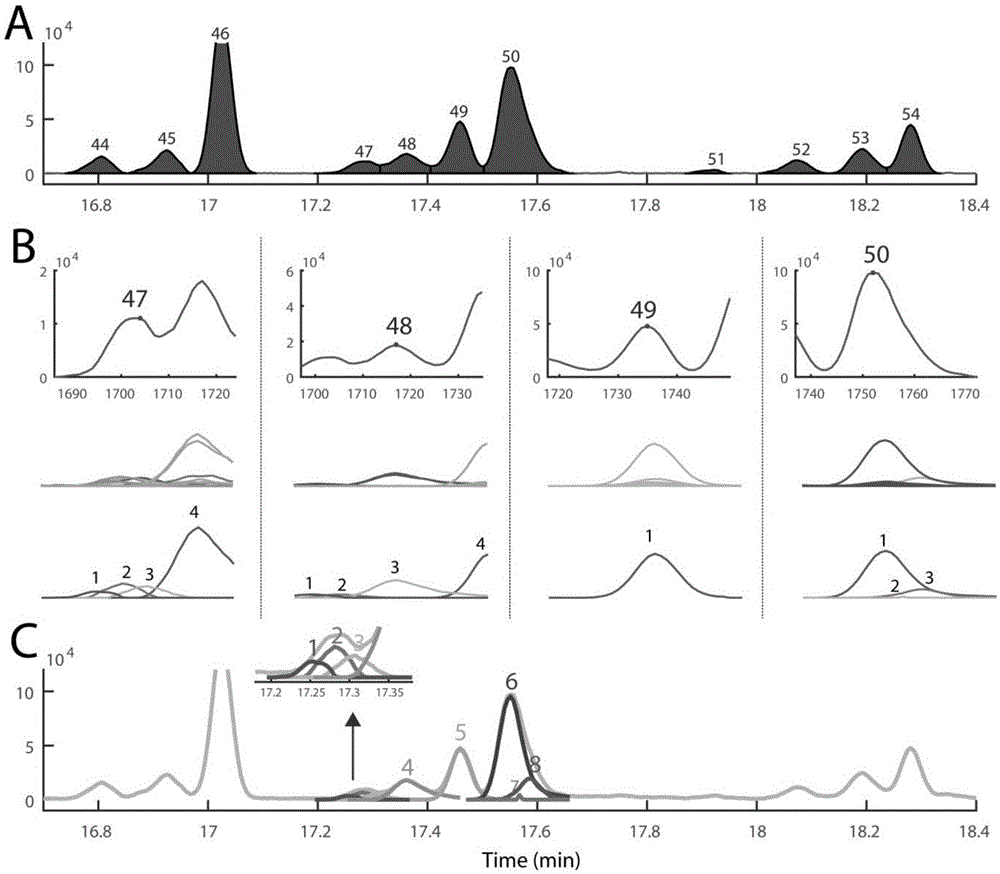
请参看图1,图中,(a)表示在一个流出范围内提取得到的tic色谱峰,用颜色标记出每个tic色谱峰的范围。(b)根据本发明设计获得每个tic色谱峰的解析范围(b中第一行),以及解析范围内的eic色谱峰(b中第二行),在此基础上解析得到的组分信息(b中第三行)。(c)经过解析后的组分,表明tic色谱峰的解析范围能够有效、完整地解析其中的共流出组分。
图1a给出了经过本方法获得tic中的色谱峰,并用深色标注出了每个色谱峰的流出范围,从图中可以看出,tic中的色谱峰能得到较好的提取,其范围能够得到较好的估计。
对于解析范围的估计如下:待获得每一个tic色谱峰的流出范围后,估计其解析范围,以估计tic色谱峰前半部分的解析范围为例,具体计算如下:(1)计算流出峰起始位置信号响度与峰最高点位置之间的比值r(该比值小于1);(2)将tic前半部分流出宽度扩大(w/r)-5(w表示前半部分的宽度,-5表示向前面延伸5个扫描点),tic色谱峰后半部分的解析范围估计与之相似。只是需要向后延伸5个扫描点。
图1b中给出了几个基线未分离47-50号tic色谱峰的解析范围,从图中能够看出,每个tic色谱峰的解析范围基本能够涵盖色谱峰的范围。而最终的解析结果(图1c)证明能够实现每个tic下化合物的解析。
s3.eic聚类与初始化色谱矩阵构建
获得每个tic色谱峰的解析范围后。确定流出范围内所有eic色谱峰,根据每个eic色谱峰色谱轮廓谱图的形状,采用层次聚类法进行聚类。具体如下:(1)采用pearson相关系数衡量色谱轮廓之间的相似度;(2)将相似度低于一定阈值(如0.95),并且eic色谱峰之间的距离大于一定阈值(如0.02min)的相似度设置为0;(3)根据相关系数从大到小,将eic色谱峰进行聚类。
待获得聚类的eic结果后,通过奇异值分解获得代表每一类的色谱峰轮廓谱图。首先将色谱谱图矩阵设置为空矩阵。然后选择色谱离子数目最多的类的色谱峰轮廓谱图,引入到色谱谱图矩阵中,在剩下的类中,筛选与色谱谱图矩阵最不相关的类的色谱峰轮廓谱图,引入到色谱谱图矩阵中。如果色谱谱图的矩阵条件数大于设定阈值(如30)或者全部类的色谱峰轮廓谱图均已引入,则该过程终止,最终获得每一个tic的初始色谱谱图矩阵。
请参看图2,(a)、(b)、(c)给出了3个连续修流出的tic色谱峰。经过峰提取后,获得各自范围内的eic色谱峰,将eic色谱峰经过聚类后,获得初始化色谱矩阵,经过修正的多元曲线分辨交替最小二乘法(mcr-als)解析后,获得对应于不同tic色谱峰的解析组分,将解析所得质谱谱图导入本实验室的谱库中准确识别出其中的化合物。
图2中以3个tic色谱峰为例,说明了相应的色谱谱图矩阵构建。从图2中可以看出,3个tic色谱峰的流出情况各不相同,117号峰能够轻松看出是一个共流出组分,但是118号峰则完全不同,即使经验丰富的研究人员,也会认为118号峰只有一个组分,119号峰看上去像是一个拖尾的色谱峰。从eic色谱峰可以看出,117号峰中存在2个组分,118号峰中存在一个小组分,119号峰则非常复杂,有多个共流出组分。经过eic聚类后,我们能够看到,117号峰存在2个组分的初始化色谱矩阵,118号峰同样获得含有2个组分的初始化色谱矩阵,而119号峰则比较复杂,获得5个组分的初始化色谱矩阵。
s4.化合物解析与识别
通过修正的mcr-als实现tic色谱峰的解析,具体如下:(1)将权力要求4中的初始色谱谱图矩阵设定为c。每一个tic分流出范围内的eic构建成一个待解析矩阵x;(2)计算质谱矩阵s,s=(c+x)t;(3)计算c,c=x(st)+;重复步骤(2)和(3),直至收敛。本发明中设计了一个优化过程,用于保障最终的解析结果质量。在每一步的计算中,判断计算出来的色谱矩阵c是否病态,如果色谱矩阵的条件数大于一定阈值,则剔除其中与其它组分最相关的色谱谱图。经过修正的mcr-als解析后,最终获得每一个tic色谱峰下组分的色谱谱图和质谱谱图。
将解析出的质谱谱图直接导入到质谱谱库中进行化合物识别。采用pearson相关系数来表征解析组分的质谱谱图与谱库中谱图间的相似性,根据相似性大小,自动筛选出相关系数最大的组分作为最佳匹配。
优选地,自动筛选出前10个组分,并以第一个化成成分作为最佳匹配。
此外,本发明能够给出与nist兼容的msp文件,可以在nist中逐一鉴别解析出的化合物。
图2中给出了经过本发明修正后mcr-als的解析结果。可以看出各tic色谱峰下的组分能够获得较好的解析。经过解析后,将质谱自动化地导入到谱库中进行化合物匹配,图2给出了相应的匹配结果,3个tic色谱峰解析出9个化学成分,其中8个得到识别,匹配度均大于800。
s5.方法解析结果验证
为了进一步证明本发明能够给出合理的解析结果,我们用一组标准品的gc-ms数据予以说明。
请参看图3,图中,(a)配置4个标准品混合物,经过不同倍数稀释后所得tic色谱峰,经过解析后,能够准确获得相应的色谱(见图a)和质谱谱图(b),并精准识别各个组分。(c)将解析所得峰面积对真实浓度回归,所得回归直线的相关系数。
图3给出了不同稀释倍数下4个有机酸甲酯的tic色谱峰,其中的亚麻酸甲酯和油酸甲酯严重重叠。但本发明能够准确解析出了这几个成分,质谱解析后化合物匹配度大于900。解析所得的峰面积与真实浓度之间建立的相关系数均高于0.99,证明本发明不仅能够获得准确的定性解析结果,还能够提供可靠的定量解析结果。
s9.化合物注册
计算测样中每一个组分与参比样本中每一个组分之间的质谱pearson相关系数,获得组分相似度矩阵。将组分之间保留时间差值大于2min或者相关系数小于0.7的,设定为0,表示组分之间不相关。利用动态规划算法,查找相似度矩阵累积加和最大的路径,从而获得测样组分所匹配到的参比样本中的组分,根据线性插值方法,实现测样中色谱峰的时间漂移校正。获得每个样本中所有组分经时间漂移校正后的保留时间,并将每个组分以其质谱谱图予以表征。不同样本中组分之间的相似性以质谱谱图的pearson相关系数予以表征,最终获得一个涵盖所有样本中各个组分之间相关系数的相似度矩阵;(2)将相似度矩阵中来自于同一个样本中组分之间的相似度设置为0,同时将相关系数低于某一阈值(如0.7)的设置为0;按照相关系数,从小到大进行聚类。在聚类的过程中,引入约束条件,及一个类别中不能有2个(或2个以上)组分来自同一个样本,注册到一个化合物列表中的同一行,样本号确定组分在列表中列的位置。
请参看图4,图中,(a)tic经过解析后,获得组分信息(①-②)。通过质谱谱图构建参比和测样中组分相似度矩阵(③),通过动态规划方法,获得最优累积加和路径(④),最终实现测样中色谱峰的时间校正(⑤)。(b)原始组分的保留时间结果经过时间漂移校正后得到初步校正结果(①),经过自适应链接算法,将不同样本中对应于相同化合物的组分聚类(②)并最终实现化合物注册(③)。
图4a中给出了一个测样中解析组分的时间校正示例,分别对参比和测样的tic进行解析,获得了7个参比组分和6个测样组分,根据组分的质谱相似度,构建相似度矩阵,通过动态规划算法获得了最优累积加和路径,从而获得测样中各组分对应的参比组分,实现了时间校正。图4b中首先给出了原始测量gc-ms信号中解析所得不同样本中组分的的保留时间,时间漂移让不同样本中对应于同一个化合物组分难以有效识别,这一点在色谱谱图中同样得以证实。经过时间校正后,随有所改善,但对于个别成分,仍然难以识别。经过自适应链接算法,则能够准确识别来自同一个化合物的组分,散点图中结果呈规律性分布,并且在色谱谱图中予以证实。
s7.不同产地,不同生长阶段烟叶样品分析
将本发明专利用于贵州、河南、云南产地的烟叶进行分析。每一个产地搜集了30个烟叶样品,其中12个来自生长阶段(6个团课期,6个旺长期),18个来自成熟烟叶(上、中、下三个部位各6个样品)。
请参看图5,图中,g1-t:团课期样品;g2-w:旺长期样品;g3-x:下部叶;g4-z:中部叶;g5-s:上部叶。
经过本发明解析,三个产地分别获得了275×30,469×30和394×30的化合物列表。通过方差分析,筛选前100个最具有差异性的代谢物,对不同组别的样本进行聚类,所得结果展示于图5中。能够看出不同组别(团课期、旺长期、上部叶、中部叶、下部叶)能够在主成分分析途中得到较好区分。系统聚类图中同样支持了这一结果,只是在分析下部和中部叶时,河南和云南地区的烟叶在系统聚类图中未有效区分,不过于上部叶区别明显。考虑到实际烟叶采收过程中两个部位烟叶采收时间相近,这一结果可以接受。证明本发明能够用于实际的工业生成和科学研究中,具有实际价值。
s7.与不同方法比较
请参看图6,图中,1-2行:ms-dial结果;3-4行:met-idea结果;5-6行:xcms结果;7-8行:erah结果。g1-t:团课期样品;g2-w:旺长期样品;g3-x:下部叶;g4-z:中部叶;g5-s:上部叶。
将实际的样本用当前世界上最为先进的几个方法进行了分析,其中包括ms-dial、met-idea、xcms、erah。上述四种方法所得结果展示于图6中,从图中可以看出,不同方法在分析贵州、河南、云南地区烟叶时表现不一致。整体来看,met-idea和xcms给出的结果较差,其主成分分析图上未能有效区分云南地区成熟期不同部位的烟叶,这一缺陷在erah中同样能够看出,只是erah中95%置信椭圆重叠不明显。ms-dial和erah虽能够给出合理主成分分布结果,但在系统聚类图上,ms-dial和erah均不能将云南地区成熟期和生长阶段的烟叶予以准确分类,这是无法接受的。通过比较可以看出,本发明所得结果最优,与实际的生产认识一致。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,本领域普通技术人员可以理解实现上述实施例的全部或部分流程,并依本发明权利要求所作的等同变化,仍属于发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!