特征自动挖掘和参数自动寻优的配电变压器故障诊断方法与流程
[0001]
本发明涉及一种特征自动挖掘和参数自动寻优的配电变压器故障诊断方法。
背景技术:
[0002]
配电系统中的变压器是我国电力系统变电传输环节中一个极为重要的输变电设备,而用户使用的配电变压器就是面向用户的一种终端输变电设备,数量多应用范围广,其可靠的运行对整个电网的稳定和安全运行至关重要,一旦变压器发生了故障就有可能给用户造成巨大的经济损失。而根据相关的统计显示,变压器绕组的故障在我国变压器总事故中约占一半以上。因此极为有必要对配电系统变压器绕组的正常工作运行状态和可靠性进行实时有效地的监测,及时发现可能造成故障的原因和隐患。
[0003]
目前,电力变压器的运行状态检测的方法可以大致分为两个主要的大类:分别是离线运行状态检测和在线运行状态监测。离线监测的方法主要有频率响应法、短路阻抗法和低压脉冲法等;在线监测的方法很多,但目前研究最多的是油色谱分析法和振动分析法,且对油色谱分析法的研究更加成熟,应用也更加广泛。但油色谱分析法能检测的故障类型主要是过热和放电等引起的绝缘油性质发生变化的故障,对变压器的机械故障反应比较迟钝甚至无法检测,且用于油色谱分析的设备大多价格昂贵、安装不便。因此,相对于油色谱分析法,基于振动分析法的变压器在线检测方法不仅对变压器主要部件的机械结构变化或故障反应灵敏(主要是变压器铁芯、绕组以及分接开关等部件发生位移、松动、磨损、变形等),而且基于振动分析法的变压器检测系统与整个电力系统之间没有电气连接,可以再电力系统正常运行时进行监测,从而可以快速高效、安全可靠地达到变压器在线状态检测、故障诊断以及潜伏性故障诊断的目的。振动信号主要有时域特征量和频域特征量这两类特征量。时域上的特征量包括波形平均值、方差、幅值、波形相似度、动态时间距离等:频域上的特征量包括频谱包络、时频能量熵、能-频分布等。这些特征量在一定程度上能够刻画振动信号的形态特征,但实际应用的效果不理想,易受扰动和噪声等因素的影响。
[0004]
多年来经过研究人员的努力,已经在振动信号获取、特征信号提取和故障检测模型建立等方面取得了一些进展,但是基于振动分析法的变压器在线检测方法尚不成熟,仍然需要做更深入的研究。
[0005]
为有效解决配电变压器故障诊断中面临的数据特征提取、局部最优、实时故障分类等问题,本发明提出了一种基于自动调参的堆栈自编码器(auto-encoders,sae)和随机深林(random forest,rf)分类器的配电变压器故障诊断方法。
技术实现要素:
[0006]
本发明的目的在于提供一种特征自动挖掘和参数自动寻优的配电变压器故障诊断方法,能够显著提高配电变压器故障诊断的准确性,并具有良好的鲁棒性和突出的诊断性能。
[0007]
为实现上述目的,本发明的技术方案是:一种特征自动挖掘和参数自动寻优的配
电变压器故障诊断方法,包括如下步骤:
[0008]
步骤s1、将振动信号采集装置安装在配电变压器上,并从振动信号采集装置中采集配电变压器运行时的振动波形;
[0009]
步骤s2、构建基于二次调优后的堆栈自编码器的配电变压器故障特征提取模型;
[0010]
步骤s3、利用二次调优后的堆栈自编码器提取振动信号特征向量yn,并对相应的特征打上标签,建立一个包含正常及各类故障的数据库;
[0011]
步骤s4、分割数据集,即将数据集按x1:x2的比例拆分为训练集和测试集;
[0012]
步骤s5、利用训练集训练随机森林分类器;
[0013]
步骤s6、基于步骤s5训练的随机森林分类器的网络参数,建立配电变压器故障诊断模型,实现配电变压器故障诊断。
[0014]
在本发明一实施例中,所述步骤s2具体实现如下:
[0015]
s21、创建一个堆栈自编码器模型,利用测量得到的振动数据逐层学习数据,提取数据特征,得到每层自编码器的偏差和权重;再通过前馈反向神经网络来缩小网络损失值,从而不断更新权重和偏差,得到堆栈自编码器中每个编码器的权重和偏差,具体实现方式如下:
[0016]
假设一训练样本x=[x1,x2,...,x
n
]
t
∈r
n
,由公式(1)可将其向隐含层进行映射,映射后的隐含层表示为y1=[y1,y2,...,y
m
]
t
∈r
m
;
[0017]
y1=f
θ
(x)=s
e
(wx+b)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0018]
其中,s
e
(
·
)为编码阶段的激活函数;θ={w,b}为编码阶段的参数,其中包含权值矩阵w∈r
m
×
n
、偏置矩阵b∈r
m
;
[0019]
接着,采用解码器公式(2)将隐含表示变换回x的重构向量
[0020][0021]
其中,s
d
(
·
)为解码阶段的激活函数;为解码阶段的参数,包含权值矩阵偏置矩阵偏置矩阵近似于x的程度越高,自编码器网络的性能越优良;因此,要不断最小化和x之间的误差,即最小化损失函数:
[0022][0023]
对于网络参数的调整,同bp神经网络的调节机制,采用梯度下降法来最小化平均重构误差;具体的损失函数为:
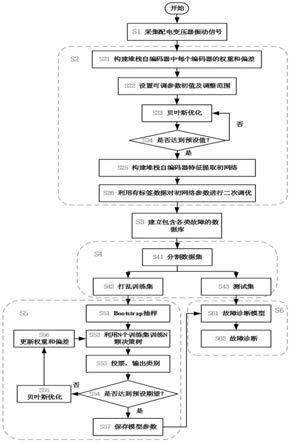
[0024][0025]
其中,为交叉熵,用于度量输入向量与重构向量之间的差异,两者差异越小,交叉熵的值越小,即损失函数的值越小;
[0026]
随后将此编码器提取出的隐含层表示特征y1作为下一个编码器的输入,同样利用公式(1)可得y1映射后的隐含层表示为y2;再采用公式(2)可得y2的重构向量此时同样利用公式(4)来不断最小化y1和之间的误差;利用此步骤依次对n个编码器进行训练,可得每个自编码器的权重和偏差;
[0027]
s22、设置堆栈自编码器特征提取网络中的迭代次数和学习率为可调超参数,并设
定可调超参数调整范围,将这些可调超参数传递给步骤s23;
[0028]
s23、利用贝叶斯优化进行超参数自动寻优,贝叶斯优化公式表示为:
[0029][0030]
其中,d={(x1,y1),(x2,y2),...,(x
n
,y
n
)}表示已采集样本点,p(f)为f的先验概率,p(f|d)为f的后验概率,f表示目标函数或模型中的参数,后验概率分布是通过已采集样本点对先验概率进行修正后目标函数或模型中参数的置信度;采用高斯过程作为概率代理模型,该过程是多元高斯概率分布的泛化,由协方差函数和均值函数构成,表达式为:
[0031]
y=gp(m(x),k(x,x'))
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0032]
其中,m(x)为均值函数,k(x,x')为协方差函数,该过程对一系列离散数据点(x
i
,y
i
)进行函数拟合,得到一个逼近真实值的目标函数;
[0033]
采用pi函数作为采集函数,其形式为:
[0034][0035]
其中f(x)为目标函数,f(x
+
)是目前为止最优的目标函数,μ(x)是f(x)后验分布的均值,δ(x)是协差矩阵,ν是权衡系数,用于避免陷入局部最优;采集函数求解的过程就是找到一个新的x,使pi(x)最大;
[0036]
s24、判断超参数寻优的目标函数是否达到预设的期望值,若是则转至s25,否则转至s23;
[0037]
s25、得到基于堆栈自编码器的配电变压器故障初始特征提取模型;
[0038]
s26、对堆栈自编码器进行二次调优,得到基于二次调优后的堆栈自编码器的配电变压器故障特征提取模型。
[0039]
在本发明一实施例中,所述步骤s26具体实现如下:
[0040]
s261、根据式(8)和式(9)计算各层的激励响应;
[0041]
z
(l)
=w
(l-1)
a
(l-1)
+b
(l-1)
ꢀꢀꢀꢀꢀꢀꢀ
(8)
[0042]
a
(l)
=f(z
(l)
)
ꢀꢀꢀꢀꢀꢀ
(9)
[0043]
s262、根据式(10)计算残差;
[0044][0045]
s263、根据式(11)、式(12)计算权重和偏差的更新公式;
[0046][0047][0048]
s264、根据式(13)、(14)计算权重和偏差的改变值;
[0049][0050]
[0051]
其中δw
(l)
和w
(l)
是大小相同的矩阵,δb
(l)
和b
(l)
是行数相同的向量,初始值都设置为0;
[0052]
s265、根据式(15)、(16)得到更新后的权重和偏差;
[0053][0054][0055]
其中,m表示样本数量,μ为学习速率。
[0056]
在本发明一实施例中,所述步骤s5具体实现如下:
[0057]
s51、利用bootstrap抽样从原始数据中有放回的随机抽取x个样本构成n个子训练集,每个样本的样本容量与原始数据集一样;
[0058]
s52、根据n个子训练集训练生成n个决策树模型,从而得到n个分类结果;
[0059]
s53、通过投票表决得出最终的分类结果,此处投票表决服从“少数服从多数”的原则,即最终的分类结果为n个结果中获得票数最多的那个类别;
[0060]
s54、判断随机森林分类器网络是否达到预设的期望值,若是则转至步骤s57,否则转至步骤s55;
[0061]
s55、设置随机森林分类器中迭代次数、学习率以及决策树棵树为可调超参数,给定初值及调整范围,然后对预设模型参数采用贝叶斯优化算法进行优化;
[0062]
s56、贝叶斯优化后,更新随机森林模型的权重和偏差,并转入s52;
[0063]
s57、保存训练好的随机森林分类器网络参数,并转至步骤s61。
[0064]
在本发明一实施例中,所述步骤s6具体实现如下:
[0065]
s61、基于步骤s5训练的随机森林分类器的网络参数,建立配电变压器故障诊断模型,并将测试集输入到该配电变压器故障诊断模型;
[0066]
s62、实现配电变压器故障诊断。
[0067]
相较于现有技术,本发明具有以下有益效果:
[0068]
1、本发明利用贝叶斯优化算法自动调整网络的超参数,获得网络的最优参数,这样极大节省了人力和时间;
[0069]
2、将堆栈自编码器与随机森林结合起来,利用堆栈自编码器逐层学习数据、提取数据特征,再利用随机森林对已提取的特征进行深入学习,从而可将配电变压器振动信号中蕴含的更为丰富的故障特征提取出来,进而显著提高配电变压器故障诊断的准确性;
[0070]
3、本发明建立的配电变压器故障诊断系统可应用于工程实践中,其同时实现振动信号的自动特征提取和故障诊断并具有良好的鲁棒性和突出的诊断性能。
附图说明
[0071]
图1为本发明配电变压器故障诊断过程示意图。
[0072]
图2为堆栈自编码构建流程图。
[0073]
图3为贝叶斯优化流程。
[0074]
图4为随机森林建模过程。
[0075]
图5为本发明配电变压器故障诊断方法的诊断过程流程图。
[0076]
图6为本发明堆栈自编码器模型提取特征展示图。
具体实施方式
[0077]
下面结合附图,对本发明的技术方案进行具体说明。
[0078]
如图1所示,本发明提供了一种特征自动挖掘和参数自动寻优的配电变压器故障诊断方法,包括如下步骤:
[0079]
步骤s1、将振动信号采集装置安装在配电变压器上,并从振动信号采集装置中采集配电变压器运行时的振动波形;
[0080]
步骤s2、构建基于二次调优后的堆栈自编码器的配电变压器故障特征提取模型;
[0081]
步骤s3、利用二次调优后的堆栈自编码器提取振动信号特征向量yn,并对相应的特征打上标签,建立一个包含正常及各类故障的数据库;
[0082]
步骤s4、分割数据集,即将数据集按x1:x2的比例拆分为训练集和测试集;
[0083]
步骤s5、利用训练集训练随机森林分类器;
[0084]
步骤s6、基于步骤s5训练的随机森林分类器的网络参数,建立配电变压器故障诊断模型,实现配电变压器故障诊断。
[0085]
如图5所示,本发明配电变压器故障诊断方法的诊断过程,具体如下:
[0086]
s1:将振动信号采集装置安装在配电变压器上,并从振动信号采集装置中采集配电变压器运行时的振动波形;
[0087]
s2:构建基于堆栈自编码器的配电变压器故障特征提取模型;
[0088]
s21:创建一个堆栈自编码器模型,利用采集得到的振动数据逐层学习数据,提取数据特征,得到每层自编码器的偏差和权重;再通过前馈反向神经网络来缩小网络损失值,从而不断更新权重和偏差,得到堆栈自编码器中每个编码器的权重和偏差,具体实现方法如下:
[0089]
假设一训练样本x=[x1,x2,...,x
n
]
t
∈r
n
,由公式(1)可将其向隐含层进行映射,映射后的隐含层表示为y1=[y1,y2,...,y
m
]
t
∈r
m
;
[0090]
y1=f
θ
(x)=s
e
(wx+b)
ꢀꢀꢀꢀꢀꢀꢀ
(1)
[0091]
其中,s
e
(
·
)为编码阶段的激活函数;θ={w,b}为编码阶段的参数,其中包含权值矩阵w∈r
m
×
n
、偏置矩阵b∈r
m
;
[0092]
接着,采用解码器公式(2)将隐含表示变换回x的重构向量
[0093][0094]
其中,s
d
(
·
)为解码阶段的激活函数;为解码阶段的参数,包含权值矩阵偏置矩阵偏置矩阵近似于x的程度越高,自编码器网络的性能越优良;因此,要不断最小化和x之间的误差,即最小化损失函数:
[0095][0096]
对于网络参数的调整,同bp神经网络的调节机制,采用梯度下降法来最小化平均重构误差;本申请采用的损失函数为:
[0097][0098]
其中,为交叉熵,用于度量输入向量与重构向量之间的差异,两者差异越小,交叉熵的值越小;
[0099]
随后将此编码器提取出的隐含层表示特征y1作为下一个编码器的输入,同样利用公式(1)可得y1映射后的隐含层表示为y2;再采用公式(2)可得y2的重构向量此时同样利用公式(4)来不断最小化y1和之间的误差;利用此步骤依次对n个编码器进行训练,可得每个自编码器的权重和偏差;该过程的流程图如图2所示。
[0100]
s22:设置堆栈自编码器特征提取网络中的迭代次数和学习率为可调超参数,并设定参数可调范围,将这些可调超参数传递给s23的贝叶斯优化网络中。
[0101]
s23:利用贝叶斯优化进行超参数自动寻优。
[0102]
贝叶斯优化算法是基于贝叶斯定理而提出的,表示为:
[0103][0104]
其中,d={(x1,y1),(x2,y2),...,(x
n
,y
n
)}表示已采集样本点,p(f)为f的先验概率,p(f|d)为f的后验概率,f表示目标函数或模型中的参数,后验概率分布是通过已采集样本点对先验概率进行修正后目标函数或模型中参数的置信度;本申请采用的概率代理模型为高斯过程,该过程是多元高斯概率分布的泛化,由协方差函数和均值函数构成,表达式为:
[0105]
y=gp(m(x),k(x,x'))
ꢀꢀꢀꢀꢀꢀ
(6)
[0106]
其中,m(x)为均值函数,k(x,x')为协方差函数,该过程对一系列离散数据点(x
i
,y
i
)进行函数拟合,得到一个逼近真实值的目标函数;
[0107]
常见的采集函数有上置信边界(ucb)、改进期望(ei)和改进概率(pi)三种,本申请采用pi函数,其形式为:
[0108][0109]
其中f(x)为目标函数,f(x
+
)是目前为止最优的目标函数,μ(x)是f(x)后验分布的均值,δ(x)是协差矩阵,ν是权衡系数,用于避免陷入局部最优;采集函数求解的过程就是找到一个新的x,使pi(x)最大;
[0110]
贝叶斯优化与其他调参方法不同之处在于,它考虑了上一次参数信息,通过不断地更新先验,使迭代次数更少、速度更快。实现流程如图3所示。
[0111]
s24:判断超参数寻优的目标函数是否达到预设的期望值,若是则转至s25,否则转至s23;
[0112]
s25:得到基于堆栈自编码器的配电变压器故障初始特征提取模型;
[0113]
s26:堆栈自编码器二次调优;
[0114]
二次调优是指将堆栈自编码器看作一个多层神经网络,利用有标签的训练样本集,对该神经网络的权重和偏差进行调整。二次调优可以很好地提高堆栈自编码器的性能。
本研究采用对误差进行反向传播来进行二次调优,具体步骤如下:
[0115]
步骤一:根据式(8)和式(9)计算各层的激励响应;
[0116]
z
(l)
=w
(l-1)
a
(l-1)
+b
(l-1)
ꢀꢀꢀꢀꢀꢀꢀ
(8)
[0117]
a
(l)
=f(z
(l)
)
ꢀꢀꢀꢀꢀꢀꢀ
(9)
[0118]
步骤二:根据式(10)计算残差;
[0119][0120]
步骤三:根据式(11)、式(12)计算权重和偏差的更新公式;
[0121][0122][0123]
步骤四:根据式(13)、(14)计算权重和偏差的改变值;
[0124][0125][0126]
其中δw
(l)
和w
(l)
是大小相同的矩阵,δb
(l)
和b
(l)
是行数相同的向量,初始值都设置为0;
[0127]
步骤五:根据式(15)、(16)得到更新后的权重和偏差;
[0128][0129][0130]
其中,m表示样本数量,μ为学习速率。
[0131]
s3:利用二次调优后的堆栈自编码器提取振动信号特征向量yn,并对相应的特征打上标签,建立一个包含正常及各类故障的数据库;
[0132]
s4:分割数据集;
[0133]
s41:将数据集按x1:x2的比例拆分为训练集和测试集;
[0134]
s42:将训练集随机打乱后,作为s5的数据输入;
[0135]
s43:将测试集作为s6的数据输入;
[0136]
s5:利用训练集训练随机森林分类器,随机森林算法思想如图4所示;
[0137]
s51:利用bootstrap抽样从原始数据中有放回的随机抽取x个样本构成n个子训练集,每个样本的样本容量与原始数据集一样;
[0138]
s52:根据n个子训练集训练生成n个决策树模型,从而得到n个分类结果;
[0139]
s53:通过投票表决得出最终的分类结果,此处投票表决服从“少数服从多数”的原则,即最终的分类结果为n个结果中获得票数最多的那个类别。
[0140]
s54:判断随机森林分类器网络是否达到预设的期望值,若是则转至s57,否则转至s55;
[0141]
s55:设置随机森林分类器中迭代次数、学习率以及决策树棵树为可调超参数,给定初值及调整范围,然后对预设模型参数进行s23中的贝叶斯优化算法。
[0142]
s56:贝叶斯优化后,更新随机森林分类器的权重和偏差,并转入执行s52;
[0143]
s57:保存训练好的随机森林分类器网络参数,并转至s61。
[0144]
s6:故障诊断阶段;
[0145]
s61:结合s57保存的网络参数,建立配电变压器故障诊断模型,并将s42制作好的测试样本输入到该模型;
[0146]
s62:实现配电变压器故障诊断。
[0147]
下面结合具体实例对本发明作进一步说明:
[0148]
在本实施例中,选用型号为s11-m-315/10的配电变压器;选用型号为lc0156a的压电加速度传感器;传感器采样频率设置为10khz,采样时间为1s,因此每个振动信号中包含10000个采样值。每类故障的样本各采集200个,其中150个用作训练集,50个用作测试集。
[0149]
在本实例中,研究的配电变压器的数据集为实测的配电变压器振动数据集,如表1所示。
[0150]
表1 实测的配电变压器振动数据集
[0151][0152]
由表1可知,实测数据中配电变压器状态包括:类别1:绕组变形、类别2:绕组螺丝松动、类别3:正常。鉴于配电变压器故障数据难以获取,本实施例中,通过人为制造故障的方式获得类别1和类别2的故障数据。
[0153]
为了验证本发明方法的有效性,构建一个3步(1000
→
500
→
250
→
100)降维的堆栈自编码器模型。根据上文s2步骤所述方法使用测得的数据对该模型进行预训练,然后使用有标签数据对该模型进行二次调整;再根据s3、s4步骤的方法将提取到的特征值建立数据库,并按3:1的比例分为训练集和测试集;然后根据s5步骤来训练rf分类器模型。最终得到网络的最优参数,并以此作为故障诊断模型的参数,其参数如表2所示。振动信号经堆栈自编码器提取特征信息后,可得到100维的特征向量,由于100维向量无法展示,此处利用t-sne将100维降为2维进行展示。图6中展示了堆栈自编码器模型有无二次调优时提取到的特征量。
[0154]
表2 网络参数
[0155][0156]
图6(a)为无调整情况下特征分布图。每个类别已经形成多个簇聚集在一起,但同一个类别的簇分散在不同的区域,图中还存在许多散乱分布的点游离于分布空间中,这种分布结果给分类器带来一定的挑战。图6(b)是经过调整后的效果。可以看出每个类别聚集程度相对于图6(a)有明显的改善,每个类别已经占据一定的区域,但图上依然有个别点存
在发散现象,原因是采样环境存在噪声干扰,导致这些数据质量不好。总之,使用本发明所提的堆栈自编码器网络提取的特征分类更为清晰明确,效果较为突出。因而,将此特征值重新构造数据库,划分训练集和测试集,使用训练集训练随机森林分类器,最终利用测试集对该分类模型进行验证,得到的测试集准确度可达96.67%。结果证明,本发明所提方法对配电变压器故障信号特征提取及分类具有良好的效果,证实了该方法的有效性。
[0157]
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1