基于EKF的模板匹配VO与轮式里程计融合定位方法与流程
基于ekf的模板匹配vo与轮式里程计融合定位方法
技术领域
1.本发明涉及基于ekf的模板匹配vo与轮式里程计融合定位方法,属于机器人定位技术领域。
背景技术:
2.近年来,轮式机器人在日常生活、工业生产等多个领域广泛应用,比如巡检、物流、施工作业等。但随着轮式机器人应用领域的不断发展以及其应用场景的逐渐复杂,不可避免地会对机器人的环境适应性提出更高的要求。因此轮式机器人如何在不同的场景中实现高效且准确的定位已成为研究的热点和难点。
3.slam(simultaneous localization and mapping,即时定位与地图构建)主要用于解决移动机器人在运动中定位导航与地图构建的问题。gmapping是一种基于2d激光雷达完成二维栅格地图构建的slam算法。该算法可以实时构建室内地图,在构建小场景地图所需的计算量较小且精度较高。
4.目前应用较广泛的自定位技术包括轮式里程计、惯性里程计、视觉里程计等,它们都有各自的优缺点,如轮式里程计直接通过轮式编码器的输出对机器人的位姿进行航迹推算,在地形颠簸或车轮打滑的情况下存在一定的误差;惯性里程计不受外界环境干扰,但其误差会随着时间累积;视觉里程计受环境光影响较大,主要分为基于特征和外观,基于特征的方法适用于纹理丰富的场景,例如具有大量特征点的城市环境。这种方法无法处理单一模式的无纹理或低纹理环境(例如沙土、沥青、混凝土等),因为在这些环境中无法检测到足够的显著特征,相比之下,基于外观的模板匹配方法非常适合在低纹理场景中使用。
5.基于模板匹配的视觉里程计(visual odometry,vo)系统在车辆的定位系统中主要的优点是其仅需要通过相机来实现,且不需要场景、运动姿态等先验知识,且能够适应车辆的打滑、侧移以及非平地运动等容易导致轮式里程计产生误差的问题,且能够在低纹理的场景中依然具备出色的场景识别功能。但其局限主要体现在于模板匹配的过程中模板的选取严重的影响着算法的效果,如何最优的选取模板成为了决定了模板匹配vo算法优劣的关键。
技术实现要素:
6.本发明所要解决的技术问题是:提供基于ekf的模板匹配vo与轮式里程计融合定位方法,在里程计坐标系下将基于cnn和图像熵改进的模板匹配的视觉定位结果与轮式里程计进行融合,得到更精准、更鲁棒的定位结果。
7.本发明为解决上述技术问题采用以下技术方案:
8.基于ekf的模板匹配vo与轮式里程计融合定位方法,包括如下步骤:
9.步骤1,采集不同类型地面的图像数据,创建地面图像数据集,为地面图像数据集中的每幅图像添加地形复杂度作为标签;
10.步骤2,利用添加标签后的地面图像数据集训练卷积神经网络模型,得到训练好的
卷积神经网络模型;
11.步骤3,利用机器人上安装的摄像头采集地面图像输入训练好的卷积神经网络模型中,得到当前地面的地形复杂度;
12.步骤4,计算当前地面的图像熵;
13.步骤5,根据地形复杂度和图像熵,实时计算当前地面的模板选取策略,根据模板选取策略进行模板匹配vo估算,得到位姿结果;
14.步骤6,将轮式里程计估算出的位姿和经过惯性测量单元解算出的位姿通过扩展卡尔曼滤波方法即初级滤波器进行融合,将融合后得到的位姿作为次级滤波器的预测值,结合模板匹配vo估算出的位姿结果作为次级滤波器的观测值,得到最终的机器人定位结果。
15.作为本发明的一种优选方案,步骤1所述地形复杂度的决定因素包括地面材质以及颠簸程度。
16.作为本发明的一种优选方案,步骤4所述图像熵的计算公式如下:
[0017][0018][0019]
其中,s表示图像熵,pj表示灰度值为j的像素点在图像中出现的概率,nj表示灰度值为j的像素点的数量,tw和th分别为图像的宽和高。
[0020]
作为本发明的一种优选方案,步骤5所述根据地形复杂度和图像熵,实时计算当前地面的模板选取策略,具体如下:
[0021]
预先设置地形复杂度阈值e和图像熵阈值f,对于大小为640*480像素尺寸的第i帧地面图像,根据步骤3和步骤4得到第i帧地面图像的地形复杂度ρi和图像熵si,若ρi小于e且si小于f,则在地面图像中初始化大小为240
×
240像素尺寸的模板;若ρi大于e且si小于f,则在地面图像中初始化大小为180
×
180像素尺寸的模板;若ρi小于e且si大于f,则在地面图像中初始化大小为200
×
200像素尺寸的模板;若ρi大于e且si大于f,则在地面图像中初始化大小为160
×
160像素尺寸的模板;模板的中心与地面图像的中心重合。
[0022]
作为本发明的一种优选方案,步骤5所述根据模板选取策略进行模板匹配vo估算,得到位姿结果,具体如下:
[0023]
1)根据模板选取策略在第i帧地面图像中初始化模板a;
[0024]
2)利用归一化互相关匹配方法在第i+1帧地面图像中从左到右、从上到下搜索与模板a相似度最大的匹配区域b,匹配区域b的大小与模板a大小相同;
[0025]
3)根据匹配区域b与模板a的左上角像素位置计算像素位移增量δu和δv;
[0026]
4)将像素位移增量δu和δv转换到相机在世界物理坐标系中的真实位移增量;
[0027]
5)根据真实位移增量解算得到i+1时刻模板匹配vo估算的机器人位姿结果;
[0028]
6)根据模板选取策略在第i+1帧地面图像中初始化模板并重复上述过程,得到i+2时刻模板匹配vo估算的机器人位姿结果,以此类推。
[0029]
作为本发明的一种优选方案,所述惯性测量单元的观测模型如下:
[0030]
惯性测量单元的姿态更新方程为:
[0031][0032]
其中,和分别表示当前t时刻和上一时刻机器人坐标系到导航坐标系的姿态变换矩阵;表示当前时刻与上一时刻之间的相对旋转构成的反对称矩阵;
[0033]
惯性测量单元在导航坐标系下的速度和位置分别为:
[0034][0035][0036]
其中,v
t
表示机器人当前时刻速度;v
t-1
表示机器人上一时刻速度;a
t
表示imu测量到的当前时刻加速度;a
t-1
表示imu测量到的上一时刻加速度;p
t
表示机器人当前时刻位置信息;p
t-1
表示机器人上一时刻位置信息;δt为当前时刻与上一时刻之间的时间差。
[0037]
作为本发明的一种优选方案,所述扩展卡尔曼滤波方法根据系统的运动模型和观测模型实现预测和更新两个步骤,运动模型和观测模型分别为:
[0038]
x
t
=g
t
x
t-1
+w
t
[0039]zt
=h
t
x
t
+v
t
[0040]
其中,x
t
为当前t时刻系统状态矩阵;x
t-1
为上一时刻系统状态矩阵;g
t
为当前时刻系统状态传递矩阵;z
t
为当前时刻系统的观测值矩阵;h
t
为系统当前时刻状态量与观测值之间的传递矩阵;w
t
和v
t
分别为当前时刻系统的过程噪声矩阵和观测噪声矩阵;
[0041]
预测过程:
[0042][0043][0044]
其中,为当前时刻系统状态矩阵估计值;为当前时刻系统的状态估计协方差;r
t
为当前时刻系统的过程噪声协方差;σ
t-1
为上一时刻系统状态协方差;
[0045]
更新过程:
[0046]
计算卡尔曼增益k
t
:
[0047][0048]
其中,q
t
为观测值误差协方差矩阵;
[0049]
利用k
t
和观测值更新移动机器人的状态矩阵x
t
和系统协方差矩阵:
[0050][0051][0052]
其中,i为单位矩阵。
[0053]
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
[0054]
1、本发明根据图像的信息熵作为主要的影响因子之一,结合卷积神经网络(convolutional neural networks,cnn)识别出来的地形复杂度动态调整匹配过程中使用的模板尺寸,极大程度的削减了由于地面环境因素导致的算法误差,从而达到在保证计算效率的同时提高匹配准确率的目的。
[0055]
2、针对单一传感器在复杂环境下不能准确估计机器人位姿的问题,本发明提出基于扩展卡尔曼滤波(extended kalman filter,ekf)将改进的模板匹配vo和轮式里程计融合,从而提高定位结果的稳定性,实现更精准、更鲁棒的定位。
附图说明
[0056]
图1是本发明基于ekf的模板匹配vo与轮式里程计融合定位方法流程图;
[0057]
图2是卷积操作示意图;
[0058]
图3是池化示意图;
[0059]
图4是轮式里程计测速模型图;
[0060]
图5是目标匹配示意图。
具体实施方式
[0061]
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
[0062]
针对单一传感器在复杂环境下不能准确估计机器人位姿的问题,本发明提出了基于改进模板匹配与轮式里程计ekf融合的定位方法。该方法是在里程计坐标系下将基于cnn和图像熵改进的模板匹配的视觉定位结果与轮式里程计进行融合,将融合后的定位信息输入gmapping算法中,从而实现更精准、更鲁棒的定位与建图。
[0063]
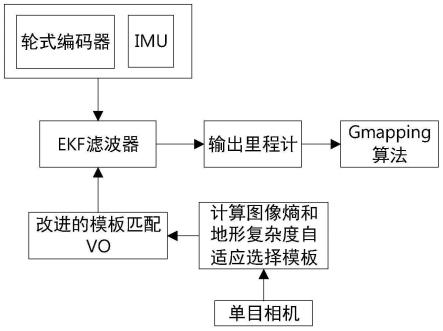
首先,提出将图像熵与深度学习结合的模板匹配vo算法,充分的利用了朝下放置的摄像头的图像数据,根据图像的信息熵作为主要的影响因子之一,结合卷积神经网络(cnn)计算得到场景环境类型,计算得到当前图像的最优目标匹配策略,极大程度的削减了由于地面环境因素导致的算法误差,增强了模板匹配vo算法的鲁棒性和精度。然后,在得到改进后的模板匹配vo后,将机器人的轮式编码器估算出的位姿和经过惯性测量单元(inertial measurement unit,imu)姿态解算过后的位姿通过扩展卡尔曼滤波(ekf)方法进行融合,将融合过后得到的机器人位姿,作为初级滤波器的预测值,结合视觉里程计的观测值,得到最终姿态数据。如图1所示,为本发明基于ekf的模板匹配vo与轮式里程计融合定位方法流程图。具体步骤如下:
[0064]
步骤1:采集不同类型地面的图像数据,创建地面图像数据集,为数据集添加表征地形复杂程度的变量(地形复杂度ρ)作为标签,地形复杂度由地面材质以及颠簸程度等因素决定,如草地、瓷砖地、水泥地等。
[0065]
步骤2:使用该数据集训练卷积神经网络模型,训练完成后的预测模型可以根据移动机器人安装的朝下的摄像头采集的输入图像拟合不同类别的地面信息,并预测该地面图像的地形复杂度。
[0066]
步骤3:将摄像头采集的图像输入训练好的卷积神经网络模型可以得到当前地面的地形复杂度ρ。该预测模型包含了输入层、卷积层、池化层、全连接层等主要神经网络层。其中,卷积层负责特征提取,由多个卷积核构成,能够根据目标函数,突破传统滤波器的限制,自动调整权重。卷积层参数量应按下式计算:
[0067]
weight=c_h
*
c_w
*
in_channel
*
out_channel+out_channel
[0068]
式中,weight为卷积层参数量,c_h、c_w分别为卷积核高和宽,in_channel、out_
channel分别为输入输出通道数,而输入输出尺寸关系如下式:
[0069][0070]
式中,om是输出特征图尺寸,im是输入特征图尺寸,c是卷积核尺寸,p是填充,s是步长。单一通道中,卷积实现过程与一般数字图像处理中所用卷积方法原理基本一致,即通过卷积核与图像局部的相乘相加,得到一个特征点,然后进行滑窗操作,对整张图像进行运算,得到输出特征图。图2显示使用了一个3*3卷积核,对9*9特征图进行卷积操作的过程。
[0071]
池化层通常放置于卷积层之后,对特征图进行降采样,提炼特征图有效信息,减少网络计算量。常用的池化方法有最大池化(maxpooling)、平均池化(averagepooling),最大池化通常用于卷积层之后的降采样操作,而平均池化通常用于替代全连接层,组成全卷积神经网络。池化层常用大小为2*2、步长为2的池化核进行池化操作,由于池化核并不含有需要学习的参数,可用一个池化核对所有输入通道的特征图进行处理,所以输出通道数等于输入通道数。为方便理解,图3展示了对4*4的特征图分别进行2*2最大池化和平均池化的过程。
[0072]
根据经验对每一张图片标定复杂度后(打标签),通过多层卷积层,池化层,全连接层合理的搭配,在模型训练完成后可以通过图像输入里的纹理、阴影、形状、分类,预测地形复杂度,得到地形复杂度ρ为预测结果。
[0073]
步骤4:图像熵是一种特征的统计形式,是衡量图像中信息量丰富程度的重要指标。熵值越大意味着图像中含有的信息量越丰富,或是图像中信息分布越混乱。通过计算地面的图像熵s,可以克服神经网络模型中存在的误差,提高对地形描述的精确度。图像一维熵的计算公式为:
[0074][0075][0076]
其中,pj表示灰度值为j的点在图像中出现的概率,nj表示灰度值为j的像素点的数量,tw和th分别为图像的宽和高。
[0077]
步骤5:通过获取地形复杂度ρ和地面图像熵s,实时计算获得当前区域的模板选取策略,以达到高鲁棒性高精度的模板匹配vo算法。我们可以根据模板的地面复杂度和熵值大小进行模板尺寸的动态切换。为复杂度ρ和图像熵s分别设定一个阈值e和f,当地形复杂度ρ和图像熵s均小于其阈值时,说明地面特征点少,需要选择大模板进行匹配,即240
×
240像素尺寸的模板窗口。若地形复杂度ρ大于e而s小于f时,选择180
×
180像素尺寸的模板;当ρ小于e而s大于f时,这时的地面类型可能是两种地面的过渡类型,使用200
×
200像素尺寸的模板进行匹配,以保证准确度;当ρ和s均大于阈值时,使用160
×
160像素尺寸的模板进行匹配,以保证计算效率。阈值e大小的确定并没有具体公式,可通过对大量图像的统计分析及实验效果来确定。
[0078]
步骤6:得到改进后的模板匹配vo后,将机器人的轮式编码器估算出的位姿和经过imu姿态解算过后的位姿通过扩展卡尔曼滤波(ekf)方法进行融合,将融合过后得到的机器
人位姿,作为初级滤波器的预测值,结合视觉里程计的观测值,得到最终姿态数据。
[0079]
(1)编码器的测速模型
[0080]
如图4所示,左右两个轮子上安装的编码器测得的脉冲数可通过下式转化为左右轮的线速度,其中n为每秒钟接收的脉冲数,r为车轮半径,f为编码器旋转一圈发出的脉冲数,即:
[0081][0082]
里程计速度模型:
[0083][0084][0085]
其中v,w分别为机器人绕机器人中心的线速度与角速度,vr、v
l
为机器人左右两轮的速度,d为轮距。
[0086]
理想情况下机器人运动模型如下式所示:
[0087][0088]
其中,(x
′
,y
′
,θ
′
)为在世界坐标系下的当前时刻位姿,(x,y,θ)为世界坐标系下的上一时刻位姿,(dx,dy,dθ)为机器人坐标系下的运动增量。
[0089]
(2)imu观测模型
[0090]
imu内部包括陀螺仪和加速度计,可依靠惯性导航解算得到机器人位姿。考虑二维环境中imu姿态更新方程为:
[0091][0092]
式中,和分别表示当前时刻和上一时刻机器人坐标系到导航坐标系的姿态变换矩阵;表示当前时刻与上一时刻之间的相对旋转构成的反对称矩阵。
[0093]
imu在导航坐标系下的速度和位置分别为:
[0094][0095][0096]
式中,v
t
表示机器人当前时刻速度;v
t-1
表示机器人上一时刻速度;a
t
表示imu测量到的当前时刻加速度;a
t-1
表示imu测量到的上一时刻加速度;p
t
表示当前时刻机器人位置信息;p
t-1
表示机器人上一时刻位置信息;δt为当前时刻与上一时刻之间的时间差。
[0097]
(3)如图5所示,通过单目摄像头模板匹配得到的视觉里程计步骤如下:
[0098]
a、从相机中获取连续图像帧;
[0099]
b、在第i图像帧中初始化模板,在第i+1图像帧中确定搜索区域;
[0100]
c、利用归一化互相关匹配方法在第i+1图像帧中匹配第i图像帧中的模板,获取最
大相似度的匹配结果;
[0101]
d、根据匹配区域与原始模板的左上角像素位置计算出像素位移增量δu和δv;
[0102]
e、将像素位移增量转换到相机在世界物理坐标系中的真实位移增量;
[0103]
f、获取第i+1时刻imu输出的偏航角;
[0104]
g、利用位置递推公式,解算并输出第i+1时刻的机器人位置;
[0105]
h、返回步骤1,重复上述步骤。
[0106]
(4)扩展卡尔曼滤波融合过程
[0107]
扩展卡尔曼滤波(ekf)主要思想是通过对非线性方程一阶泰勒展开为线性方程,然后再使用卡尔曼滤波算法对系统状态进行估计。ekf算法根据系统的运动模型和观测模型实现预测和更新两个步骤,运动模型和观测模型分别为:
[0108]
x
t
=g
t
x
t-1
+w
t
[0109]zt
=h
t
x
t
+v
t
[0110]
式中,x
t
为当前t时刻系统状态矩阵;x
t-1
为上一时刻系统状态矩阵;g
t
为当前时刻系统状态传递矩阵;z
t
为当前时刻系统的观测值矩阵;h
t
为系统当前时刻状态量与观测值之间的传递矩阵;w
t
和v
t
分别为当前时刻系统的过程噪声矩阵和观测噪声矩阵;
[0111]
预测过程:
[0112][0113][0114]
式中,为当前时刻系统状态矩阵估计值;为当前时刻系统的状态估计协方差;r
t
为当前时刻系统的过程噪声协方差;σ
t-1
为上一时刻系统状态协方差;
[0115]
更新过程:
[0116]
首先,计算卡尔曼增益k
t
:
[0117][0118]
其中,q
t
为观测值误差协方差矩阵;
[0119]
利用k
t
和观测值更新移动机器人的状态矩阵x
t
和系统协方差矩阵:
[0120][0121][0122]
其中,i为单位矩阵。
[0123]
扩展卡尔曼滤波融合轮式里程计和imu的过程为:通过编码器测速模型得到左右轮线速度,将其输入到运动模型中进行状态估计,对imu预积分输入到观测方程进行状态更新。通过卡尔曼增益和公式的不断迭代,最终得到系统状态的最优估计。轮式里程计与imu融合后的结果作为次级滤波器的预测值,模板匹配vo解算出的位姿结果作为次级滤波器的观测值,代入(4)中的预测过程和更新过程,利用卡尔曼增益和观测值更新移动机器人的状态矩阵和系统协方差矩阵,得到系统状态的最终估计值。
[0124]
随着时间的变化,里程计累积的误差会越来越大,所以在滤波器中用模板匹配vo的观测来弥补里程计的累积误差,就可以大大减少算法收敛到局部最优的情况。
[0125]
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围
之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1