基于BP神经网络和遗传算法的高炉多目标优化控制算法的制作方法
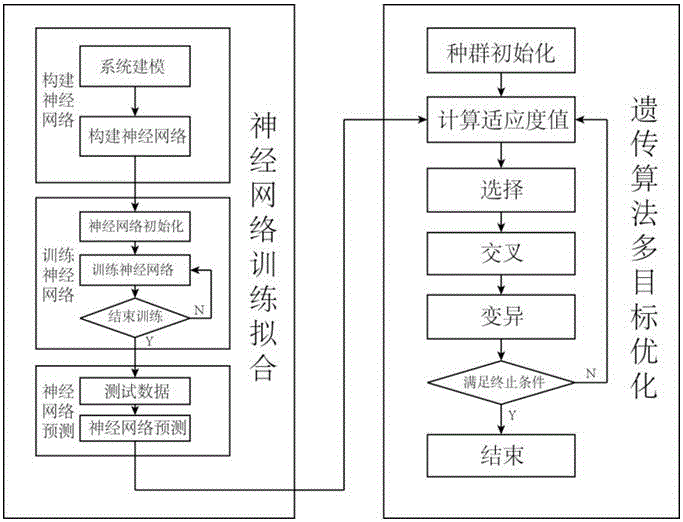
本发明属于工业过程监控、建模和仿真领域,特别涉及一种基于BP神经网络和遗传算法的高炉多目标优化控制算法。技术背景因为高炉内复杂的传质传热、化学反应和相变化,炼铁过程呈现非线性和动态特性。鉴于高炉内的极端条件,很难控制高炉保持平稳安全运行,因此多余的原燃料的消耗是可以理解的。但是,高炉炼铁占了整个钢铁生产流程能耗的百分子四十,而钢铁行业的能耗占了全世界的百分之八,即使是高炉效率微小的提升也能够节省很大能源,对环保做出巨大的贡献。高炉内影响焦比、成本、铁水品质的核心是“三传一反”,而质量传递、热量传递、动量传递和化学反应又受到如热风温度、矿石品位、冷却条件等因素影响,这些影响因素还是高度相关的。研究者为了找出变量间的潜在联系,构建了大量模型,希望选择并优化合适的参数能够使高炉安全稳定的运行。已经提出的遗传算法和自适应加权法都有各自的优势,但在多变量和高维度的复杂情况下表现不尽如人意。鉴于高炉的复杂性和封闭性,操作人员通常根据以往的经验来操作高炉。保证高炉的稳定顺行是第一要务,所以人们会留很大的富余量,造成矿石和燃料的额外消耗。近年来,研究者们一直通过机理或数据驱动建模来寻找高炉操作的最优点。常规的单目标分析方法很难解决多目标优化的问题,因为高炉中的各种变量是高度相互关联的,很难单独分析某个元素的变化规律。技术实现要素:针对常规的单目标分析方法很难解决多目标优化的问题,而一般模型不适用于高维度、多变量的情况。为了能够同时优化相互矛盾的目标,例如最低的铁水硫含量、CO2排放量和焦比,我们提出了一种基于BP神经网络和遗传算法的高炉多目标优化控制算法。这种算法利用神经网络建立一种输入输出的映射关系,然后用遗传算法找出多目标情况下的Pareto最优和与之对应的输入变量的值。一种基于BP神经网络和遗传算法的高炉多目标优化控制算法,步骤如下:步骤一:选取模型的输入输出变量,根据工厂的具体要求和生产过程的实际情况确定需要优化的目标函数和能够操作的控制变量;步骤二:建立、初始化、训练BP神经网络,通过学习使其具有输入输出的映射规则;步骤三:建立NSGA-II多目标优化算法,种群初始化后,通过选择、变异、交叉操作计算适应度函数;步骤四:将BP神经网络的输出作为NSGA-II遗传算法的适应度函数,寻找Pareto最优和对应的输入变量的值。步骤一所述的模型的参数的选取方法如下:选择七个变量:鼓风动能、热风压力、热风温度、冷风流量、全塔压差、富氧率和煤比,作为模型的输入参数;选择焦比、硫含量和CO2排放量为优化目标。步骤二所述的建立、初始化、训练BP神经网络步骤如下:①初始化神经网络:根据输入输出的变量,需要预先设置输入层、隐层和输出层的节点数、学习率和激活函数,此外,还需要设定层间的权值和层内的阈值;②隐层计算:根据以下方程计算隐层输出H,其中f是激活函数,式中ωij是输入层和隐层的连接权值,而a是隐层的阈值;③输出层计算:根据BP神经网络的输出H、权值ωjk和阈值b计算预测值Ok,④误差计算:根据实际值和神经网络的预测值计算误差,ek=Yk-Ok,k=1,...m(1.3)⑤权值更新:更新输入层和隐层的权值ωij、隐层和输出层的权值ωjk,ωjk=ωjk+ηHjek,(j=1,...l;k=1,...m)⑥阈值更新:更新隐层的阈值a、输出层的阈值b,bk=bk+ek,k=1,...m步骤三所述的NSGA-II遗传算法的具体算法步骤如下:①初始化:在遗传算法中,不同的数据类型都可以用二进制数来表示,一组数据就是一条染色体,而包含染色体的解空间被称作种群,种群的大小在一开始就被给定;②选择:自然界中染色体会通过选择一代代传下去,NSGA-II算法中通过快速非劣排序方法和拥挤距离算子选出数据中占优势的解并组成新的解集,进行下一步的计算;③操作:通过选择操作筛选出优秀的子空间,还需经过交叉和变异等操作进一步计算;其中交叉是操作中的核心步骤,通过交叉操作可以最大程度继承父辈的主要特性,中间种群y=(y1,...yn)中的解yk能够通过DE交叉运算从父辈中的x1,x2,x3得到,式中F和CR是控制参数;此外,新的种群通过指数变异算子得到,式中rand表示一个0到1之间的随机数,β表示分布指数,pm是变异率,ak、bk是优化变量值的下限和上线。所述的步骤四中:BP神经网络学习得到输入输出的映射关系,输出作为NSGA-II遗传算法的适应度值,遗传算法找出目标的Pareto最优,和对应的输入变量的值,从而得到目标变量铁水硫含量、二氧化碳排放量和焦比的最小值,还有在目标最小值下对应的输入变量鼓风动能、热风压力、热风温度、冷风流量、全塔压差、富氧率和煤比的数值。本发明具有以下优势:针对高炉中恶劣、极端的环境和多变量、高维度的数据,提出了一种基于BP神经网络和遗传算法的高炉多目标优化控制算法。本算法能够同时优化多种互相关联或矛盾的目标,通过BP神经网络学习输入输出变量的对应关系,然后通过NSGA-II遗传算法寻找目标参数的Pareto最优解空间和与之对应的输入变量的值,达到优化控制的目的,提升高炉运行的效率。附图说明图1是BP神经网络结构示意图,图2是遗传算法流程图,图3是高炉优化模型,图4是高炉历史数据。具体实施方法本发明提出了一种基于BP神经网络和遗传算法的高炉多目标优化控制算法,步骤如下:步骤一:选取模型的输入输出变量,根据工厂的具体要求和生产过程的实际情况确定需要优化的目标函数和能够操作的控制变量。步骤二:建立、初始化、训练BP神经网络,通过学习使其具有输入输出的映射规则。步骤三:建立NSGA-II多目标优化算法,种群初始化后,通过选择、变异、交叉操作计算适应度函数。步骤四:将BP神经网络的输出作为NSGA-II遗传算法的适应度函数,寻找Pareto最优和对应的输入变量的值。步骤一所述的模型参数的选取方法如下:从现场工程师处了解到,对高炉运行影响最大的状态变量是鼓风动能、热风压力、热风温度、冷风流量、全塔压差、富氧率和煤比,因此我们选择这7个变量作为模型的输入参数。焦比是高炉最重要的技术经济指标之一,它表示生产每吨生铁所消耗的焦炭的量,较低的焦比不仅表示高炉运行的稳定顺利,也是企业赚取利益的保障。在钢铁生产中,硫是一种有害元素,它会导致钢材产生“热脆性”,因此铁水中低水平的硫含量是优质产品的象征。此外,炼铁是一个高耗能的产业,而高炉的能量消耗占了整个生产流程的百分之七十,这代表高炉也是二氧化碳排放大户。在环境日益恶化、温室效应不断增加的今天,节能减排显得尤为重要,环境保护的一大目标就是降低二氧化碳排放量。基于以上理由,我们将焦比、硫含量和CO2排放量设定为优化目标。步骤二所述的BP神经网络的结构如下:如图1所示,BP神经网络是一种多层前馈的反向传播神经网络,它由输入层、隐层和输出层构成,信号在其中向后传播而误差向前传播。在学习的过程中,如果输出层不能得到需要的值,则迫使输入信号反向传播用以更新权值和阈值,使输出信号逐渐接近设定的目标。应用BP神经网络做预测应首先完成以下构建、初始化和训练步骤:①初始化神经网络:根据输入输出的变量,需要预先设置输入层、隐层和输出层的节点数、学习率和激活函数。此外,还需要设定层间的权值和层内的阈值。②隐层计算:根据以下方程计算隐层输出H,其中f是激活函数。式中ωij是输入层和隐层的连接权值,而a是隐层的阈值。③输出层计算:根据BP神经网络的输出H、权值ωjk和阈值b计算预测值Ok。④误差计算:根据实际值和神经网络的预测值计算误差。ek=Yk-Ok,k=1,...m(1.3)⑤权值更新:更新输入层和隐层的权值ωij、隐层和输出层的权值ωjk。ωjk=ωjk+ηHjek,(j=1,...l;k=1,...m)⑥阈值更新:更新隐层的阈值a、输出层的阈值b。bk=bk+ek,k=1,...m步骤三所述的NSGA-II遗传算法的结构如下:如图2所示,NSGA-II是一种类似“自然选择”的进化算法,数据集中最适应环境的解能够在选择、变异、交叉等进化过程中幸存下来,具体的算法步骤如下:①初始化:在遗传算法中,不同的数据类型都可以用二进制数来表示,一组数据就是一条染色体,而包含染色体的解空间被称作种群,种群的大小在一开始就被给定。②选择:自然界中染色体会通过选择一代代传下去,NSGA-II算法中通过快速非劣排序方法和拥挤距离算子选出数据中占优势的解并组成新的解集,进行下一步的计算。③操作:通过选择操作筛选出优秀的子空间,还需经过交叉和变异等操作进一步计算。其中交叉是操作中的核心步骤,通过交叉操作可以最大程度继承父辈的主要特性。例如,中间种群y=(y1,...yn)中的解yk能够通过DE交叉运算从父辈中的x1,x2,x3得到。式中F和CR是控制参数。此外,新的种群可以通过指数变异算子得到。式中rand表示一个0到1之间的随机数,β表示分布指数,pm是变异率,ak、bk是优化变量值的下限和上线。只有设置了合适的交叉概率、变异速率和种群大小,NSGA-II遗传算法才能发挥理想的功能。步骤四所述的步骤详细解释如下:BP神经网络学习得到输入输出的映射关系,其输出作为NSGA-II遗传算法的适应度值,遗传算法找出目标的Pareto最优,和对应的输入变量的值。从而得到目标变量铁水硫含量、二氧化碳排放量和焦比的最小值,还有在目标最小值下对应的输入变量鼓风动能、热风压力、热风温度、冷风流量、全塔压差、富氧率和煤比的数值。实施例在钢铁生产流程中,炼铁是最重要的一个环节,不仅决定着整个流程能够顺利运行,还关系着整个企业的生产效益。为了能够优化高炉的操作,达到多目标优化的目的。我们选取了鼓风动能、热风压力、热风温度、冷风流量、全塔压差、富氧率和煤比着7个操作参数作为模型的输入,焦比、硫含量和CO2排放量这3个指标作为模型的输出(图3是高炉优化模型),通过柳钢的300组历史数据训练神经网络(图4是高炉历史数据),让BP神经网络学习输入输出的映射关系,然后让NSGA-II遗传算法找到输出变量的最小值,和与之对应的输入变量的值,达到优化操作参数的目的。通过以上建模仿真过程,我们得到了以下优化的值:变量单位数值焦比kg/t240.92CO2排放量t/d9263.36铁水硫含量wt%0.01344煤比kg/t194.19富氧率vol%2.816全塔压差kPa177.46冷风流量104m3/h28.03热风温度℃1202.81热风压力MPa0.3958鼓风动能kW105.99本发明具有以下优点:1、解决了高炉多目标优化控制的问题,提出了一种通过优化目标指标来确定控制变量的方法。2、模型计算出焦比最低可达到240.92kg/t,这是实际生产中从未达到的,对实际生产操作具有指导意义。3、模型简单,易于理解。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都属于本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1