智能水下机器人垂直面路径跟随的深度强化学习控制方法与流程
本发明涉及的是一种水下航行器控制方法,具体地说是一种智能水下机器人垂直面路径跟随的深度强化学习控制方法。
背景技术:
随着海洋开发的不断深入,智能水下机器人由于其具有运动灵活、携带方便、可自主作业等特点已被广泛应用于海洋环境保护、海洋资源开发,其地位日益重要。此外通过准确控制智能水下机器人,使得一些极其危险的任务变得安全,例如探索海底石油,修复海底管道,以及追踪和记录易爆物的位置。
传统的路径跟随控制方法诸如模糊逻辑控制、pid控制、s面控制需要人为的调整控制参数,控制效果依赖于人的经验,智能水下机器人不能主动的与环境进行交互。近年来,随着人工智能技术的快速发展,作为人工智能的重要内容之一,强化学习近年来取得了一系列的重大突破。在强化学习中,学习者不会被告知要采取哪些行动,而是必须通过尝试来发现哪些行动会产生最大的回报。行动不仅可以影响直接奖励,还可以影响下一个时刻的状态,并通过这种状态影响所有后续的奖励。
技术实现要素:
本发明的目的在于提供一种具有自学习、精度高的特点,可以适应各种复杂海洋环境的智能水下机器人垂直面路径跟随的深度强化学习控制方法。
本发明的目的是这样实现的:
步骤一,根据智能水下机器人的路径跟随控制要求,建立与代理人进行交互的智能水下机器人环境;
步骤二,建立代理人集合;
步骤三,建立经验缓存池;
步骤四,建立学习者;
步骤五,使用分布式确定性策略梯度进行智能水下机器人路径跟随控制。
本发明还可以包括:
1.所述建立与代理人进行交互的智能水下机器人环境是将智能水下机器人的路径跟随控制过程建模成一个马尔可夫决策过程,确定马尔可夫决策过程的主要组成部分:动作空间、状态空间、观测空间、奖励函数。
2.所述确定马尔可夫决策过程的主要组成部分具体包括:
(1)确定动作空间
动作空间表达式为f=[dels],其中dels表示智能水下机器人水平舵的舵角;
(2)确定状态空间
状态空间表达式为s=[w,q,z,theta],其中w表示智能水下机器人在随体坐标系下的升沉速度,q表示智能水下机器人在随体坐标系下的俯仰角速度,z表示智能水下机器人在大地坐标系下的深度,theta表示智能水下机器人在大地坐标系下的俯仰角;
(3)确定观测空间
观测空间是状态空间的函数:o=f(s),其中跟随直线路径为:o=[w,q,zdelta,cos(theta),sin(theta)],zdelta=z-zr,zr表示直线路径所在的深度;
(4)确定奖励函数
在强化学习中,代理的目的或目标是根据特殊信号形成的,称为奖励或奖励函数,从环境传递给代理人,用于评价智能水下机器人在前一时刻采取动作后导致产生的当前状态的效果:
r(s,a)=r(s)+r(a)
其中:
r(s)=-(αww2+αqq2+αzzdelta2+αttheta2)
r(a)=-(αa1dels2)
其中αw、αq、αz、αt、αa1是权重系数。
3.所述建立代理人集合具体包括:
(1)同时建立k个动作网络,k个动作网络同时与智能水下机器人环境进行交互来建立代理人集合;
(2)代理人集合从学习者处接收网络参数用于代理人集合中动作网络的更新,代理人集合将动作网络与智能水下机器人环境进行交互得到的经验元祖传递到经验缓存池,单个经验元祖的表达式是:
(oi,ai,r(s,a)i)。
4.所述建立经验缓存池具体包括:
经验缓存池从代理人集合处接收代理人集合中是动作网络与智能水下机器人环境进行交互得到的经验元祖,经验缓存池将依据优先级采样得到的经验元祖传递到学习者,优先级采样的表达式为:
其中,pi是经验元祖i的优先级,α是一个大于0的很小的系数、用来决定优先级的程度,如果α=0,那么优先级采样就变为随机均匀采样。
5.所述建立学习者具体包括:
(1)学习者网络从经验缓存池处接收依据优先级采样得到的经验元祖,并将其学习得到的网络参数传递到代理人集合;
(2)学习者采用演员—评论家结构,其中演员网络的输入是观测空间,输出是动作空间,即控制变量,表达式为f=[dels],动作网络与演员网络结构相同;评论家网络的输入是观测空间和动作空间,输出是z的分布,进而通过分布求得z的均值,z表示在第t时间步,根据策略π,在状态是s时,采取动作a后期望得到的回报,即状态-动作值,采用求状态-动作值分布的形式比单纯直接求状态-动作值的平均值或只求一个状态-动作值的形式。
6.所述使用分布式确定性策略梯度进行智能水下机器人路径跟随控制具体包括:
(1)初始化依据优先级采样得到的经验元祖的大小为m=256,经验缓存池的大小为r=1000000,动作网络的个数k不超过10个,学习者中的演员网络和评论家网络的学习率为α0=β0=0.0001,探索常数ε=0.00001,最大探索次数e=100,每次探索的最大探索步数是t=1000;
(2)采用随机方式初始化动作网络和学习者中演员—评论家网络的网络权重参数(θ,w),其中θ是动作网络和学习者中演员网络的参数,w是学习者中评论家网络的参数;
(3)使用第(2)步的初始化参数为学习者中的演员网络和评论家网络分别建立一个目标网络,目标网络的参数记为(θ',w');
(4)并行运行k个动作网络;
(5)从经验缓存池中根据优先级pi选取长度为n的样本经验元祖m((oi:i+n,ai:i+n-1,r(o,a)i:i+n-1);
(6)构造z的分布
(7)依据下式计算动作网络和学习者中演员—评论家网络的更新
(8)更新网络参数
θ←θ+αtδθ,
w←w+βtδw;
(9)如果每次探索的步数到达1000,结束当前次数的探索;如果没有达到,返回第(5)步;
(10)如果探索次数达到100,结束实验;如果没有达到,返回第(2)步;
(11)返回动作网络,即包含合适参数θ的智能水下机器人路径跟随控制模型。
7.所述并行运行k个动作网络具体包括:
1)选择动作a,
2)执行动作a,得到回报r(s,a)和下一时刻的观测状态o';
3)将经验元祖(oi,ai,r(s,a)i)存储在经验缓存池中;
4)重复步骤1)-3),直至收敛或训练结束。
本发明提供了一种智能水下机器人垂直面路径跟随的深度强化学习控制方法,针对智能水下机器人所处海洋环境复杂多变,传统控制方法无法与环境主动进行交互的现象,设计智能水下机器人垂直面路径跟随的深度强化学习控制方法。
本发明利用强化学习能主动与环境进行交互的特点,提出使用确定性策略梯度通过分布式的方法来完成智能水下机器人的路径跟随控制任务,具有自学习,精度高,适应性好,学习过程稳定的优点。
本发明的有益效果为:
1.本发明具有自学习,适应性好的特点,由于强化学习天生与环境交互学习的特点,本发明提供的智能水下机器人垂直面路径跟随的深度强化学习控制方法可以主动与环境进行交互,可以适应各种复杂海洋环境。
2.本发明具有学习过程稳定,学习结果可扩展性好的特点。本发明提供的智能水下机器人垂直面路径跟随的深度强化学习控制方法通过使用分布式的方法,提供了更好,更稳定的学习信号;同时学习所得的控制策略在目标路径变化不是特别剧烈的情况下可以直接使用,无需再次训练,节省了时间,提高了效率。
附图说明
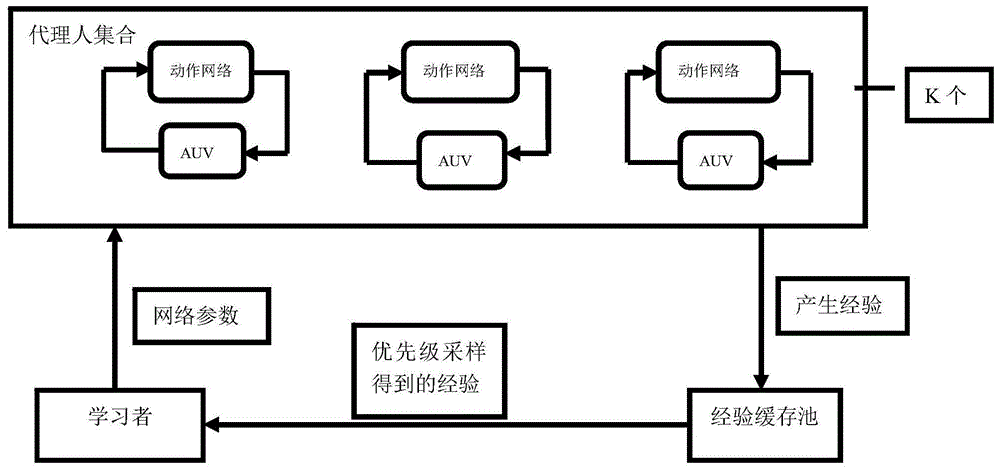
图1是本发明的总体结构图;
图2是本发明动作网络和学习者结构中演员网络的示意图;
图3是本发明学习者结构中评论家网络的示意图;
图4是使用本发明方法进行正弦曲线路径跟随得到的仿真结果。
具体实施方式
下面举例对本发明做更详细的描述。
结合图1所示,是本发明的总体结构图,主要包括:
步骤一,根据智能水下机器人的路径跟随控制要求,建立与代理人进行交互的智能水下机器人环境。
步骤二,建立代理人集合。
步骤三,建立经验缓存池。
步骤四,建立学习者。
步骤五,使用分布式确定性策略梯度进行智能水下机器人路径跟随控制。
本发明提出的智能水下机器人垂直面路径跟随的深度强化学习控制方法,下面结合附图和具体实施例对本发明做更详细地描述。
本发明的详细实现方法包括以下步骤:
1.将智能水下机器人的路径跟随控制任务过程建模成一个马尔可夫决策过程,确定马尔可夫决策过程的主要组成部分:动作空间,状态空间,观测空间,奖励函数。
第一步,确定动作空间
动作空间表达式为f=[dels],其中dels表示智能水下机器人水平舵的舵角;
第二步,确定状态空间
状态空间表达式为s=[w,q,z,theta],其中w表示智能水下机器人在随体坐标系下的升沉速度,q表示智能水下机器人在随体坐标系下的俯仰角速度,z表示智能水下机器人在大地坐标系下的深度,theta表示智能水下机器人在大地坐标系下的俯仰角。
第三步,确定观测空间
观测空间是状态空间的函数:o=f(s)。以跟随直线路径为例,o=[w,q,zdelta,cos(theta),sin(theta)],其中zdelta=z-zr,zr表示直线路径所在的深度。
第四步,确定奖励函数
在强化学习中,代理的目的或目标是根据特殊信号形成的,称为奖励或奖励函数,从环境传递给代理人,用于评价智能水下机器人在前一时刻采取动作后导致产生的当前状态的效果:
r(s,a)=r(s)+r(a)
其中:
r(s)=-(αww2+αqq2+αzzdelta2+αttheta2)
r(a)=-(αa1dels2)
其中αw=0.5、αq=0.5、αz=1、αt=1、αa1=0.001。
2.建立代理人集合,具体为:
第一步,通过同时建立k=3个动作网络,k=3个动作网络同时与智能水下机器人环境进行交互来建立代理人集合;
第二步,代理人集合从学习者处接收网络参数用于代理人集合中动作网络的更新,代理人集合将动作网络与智能水下机器人环境进行交互得到的经验元祖传递到经验缓存池,单个经验元祖的表达式是:
(oi,ai,r(s,a)i);
第三步,每个动作网络(图2)包含两个隐藏层h1,h2和一个输出层output,其中h1有400个节点,h2有300个节点,输出层采用双曲正切函数tanh。
3.建立经验缓存池,具体为:
经验缓存池从代理人集合处接收代理人集合中是动作网络与环境进行交互得到的经验元祖,经验缓存池将依据优先级采样得到的经验元祖传递到学习者,优先级采样的表达式如下:
其中,pi是经验元祖i的优先级,α是一个大于0的很小的系数,用来决定优先级的程度,如果α=0,那么优先级采样就变为随机均匀采样。
4.建立学习者网络,具体为:
第一步学习者网络从经验缓存池处接收依据优先级采样得到的经验元祖,并将其学习得到的网络参数传递到代理人集合。
第二步学习者采用演员—评论家结构,其中演员网络(图2)的输入是观测空间,输出是动作空间,即控制变量,表达式为f=[dels].演员网络包含两个隐藏层h1,h2和一个输出层output,其中h1有400个节点,h2有300个节点,输出层采用双曲正切函数tanh;评论家网络(图3)的输入是观测空间和动作空间,输出是z的分布,z表示在第t时间步,根据策略π,在状态是s时,采取动作a后期望得到的回报,即状态-动作值。采用求状态-动作值分布的形式比单纯直接求状态-动作值的平均值或只求一个状态-动作值的形式,学习过程更稳定。包含两个隐藏层h1,h2和一个输出层output,其中h1有400个节点,h2有300个节点,输出层采用softmax函数。
5.使用分布式确定性策略梯度进行智能水下机器人路径跟随控制,包括以下步骤:
第一步:初始化依据优先级采样得到的经验元祖的大小为m=256,经验缓存池的大小为r=1000000,动作网络的个数k(k值依据具体的路径跟随任务进行调整,一般不超过10个)学习者网络中的演员网络和评论家网络的学习率为α0=β0=0.0001,探索常数ε=0.00001,最大探索次数e=100,每次探索的最大探索步数是t=1000。
第二步:采用随机方式初始化动作网络和学习者网络的网络权重参数(θ,w),其中θ是动作网络和学习者网络中演员网络的参数;w是学习者网络中评论家网络的参数。
第三步:使用第二步的初始化参数为学习者网络中的演员网络和评论家网络分别建立一个目标网络以减小学习过程中的震荡,目标网络的参数记为(θ',w')。
第四步:并行运行k个动作网络。
第五步:从经验缓存池中根据优先级pi选取长度为n的样本经验元祖m((oi:i+n,ai:i+n-1,r(o,a)i:i+n-1)。
第六步:构造z的分布
第七步:依据下式计算动作网络和学习者网络的更新
第八步:更新网络参数
θ←θ+αtδθ
w←w+βtδw。
第九步:如果每次探索的步数到达1000,结束当前次数的探索;如果没有达到,返回第五步。
第十步:如果探索次数达到100,结束实验;如果没有达到,返回第二步。
第十一步:返回动作网络,即包含合适参数θ的智能水下机器人路径跟随控制模型。
6.使用分布式确定性策略梯度进行智能水下机器人路径跟随控制,其中第四步具体为:
第一步,选择动作a,
第二步,执行动作a,得到回报r(s,a)和下一时刻的观测状态o'。
第三步,将经验元祖(oi,ai,r(s,a)i)存储在经验缓存池中。
第四步,重复上述步骤,直至收敛或训练结束。
- 还没有人留言评论。精彩留言会获得点赞!