浏览同步方法和装置与流程
本发明涉及搜索引擎领域,特别是涉及一种网页搜索中章回实体的浏览同步方法和装置。
背景技术:
目前在搜索引擎技术领域,网络爬虫spider以不同站点的网页页面为单位进行抓取,搜索引擎也以站点为单位返回搜索结果。搜索引擎对各个搜索结果提供一小段网页文字摘要,用户通过搜索引擎寻找目标网页时通常需要经过多次阅读、寻找和点击才能找到满足需要的目标网页。与此同时,很多页面可能会以关键字堆砌的方式欺骗搜索引擎,吸引用户点击,也给用户访问目标网页带来不便。并且,采用上述搜索查找方式尤其给用户搜索查找需要的章回实体的相关内容造成困难。特别是用户在阅读访问章回性小说时,往往希望在本次中断阅读后,下次能够快速方便地查找到中断的章节,接着本次中断的章节继续向下阅读。而采用上述现有搜索查找方式时,则需要用户重新找到网页后,再重新找到中断章节。为此,一种现有的提高章回实体如章回性小说的搜索查找方式是,在当前阅读的网站内添加书签,在下次阅读时,只需找到该网站,即可根据该书签迅速地查找到中断章节,继续向下阅读。但是,如果用户选择了其他站点,因该站点没有该用户设置的书签的相关信息,则需要重新在该网站的章节目录中查找上次阅读的章节。可见,目前的搜索引擎在进行章回实体的搜索时,对于相同的章回实体查找,搜索引擎会同时将不同站点的章回实体的页面展示给查询用户,用户要花大量的时间进行章回实体的页面筛选。该种方式信息筛选的效率低,也无法筛选出能够满足用户需求的有效网页,降低了阅读效率,增加了服务器的检索负担。
技术实现要素:
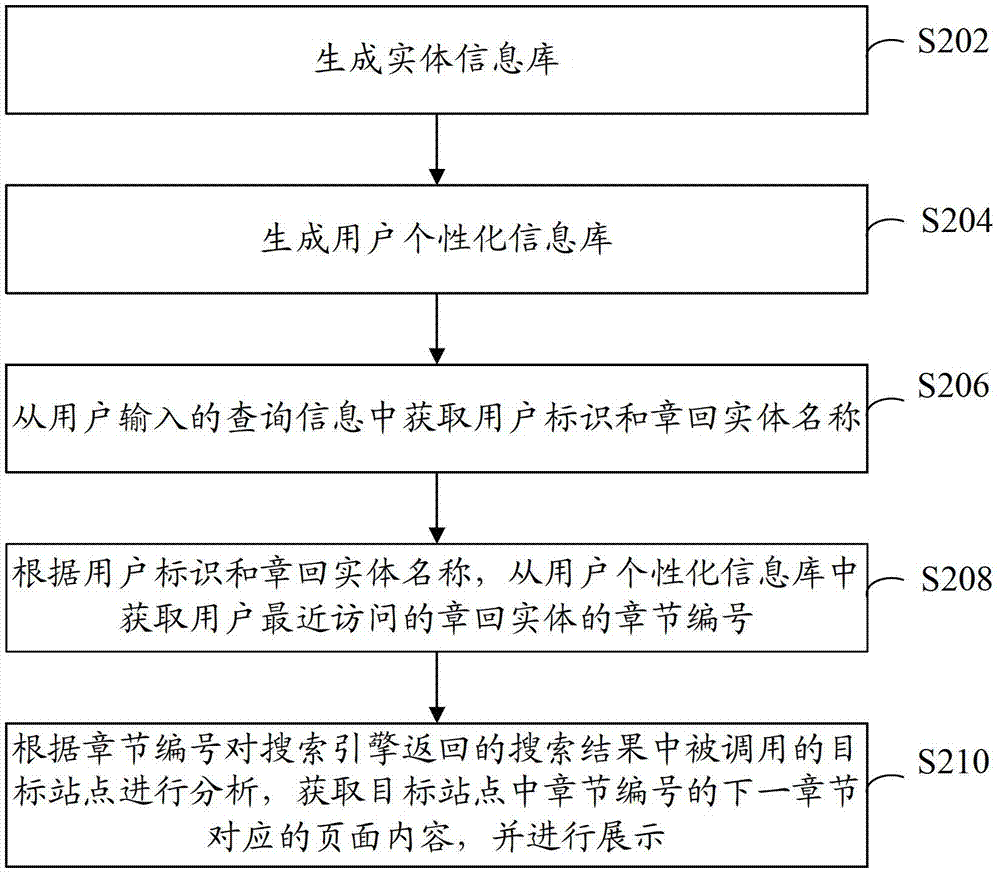
本发明提供了一种浏览同步方法与装置,以解决目前的搜索引擎在进行章回实体的搜索时,对于相同的章回实体查找,搜索引擎会同时将不同站点的章回实体的页面展示给查询用户,信息筛选效率低,无法筛选出能够满足用户需求的有效网页的问题。为了解决上述问题,本发明公开了一种浏览同步方法,包括:从输入的查询信息中获取用户标识和章回实体名称;根据所述用户标识、所述章回实体名称,从用户个性化信息库中获取所述用户最近访问的所述章回实体的章节编号;其中,所述用户个性化信息库包括各用户的用户标识、每个所述用户访问过的各章回实体的名称和每部章回实体分别被各用户最近访问的章节编号;根据所述章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取所述目标站点中所述章节编号的下一章节对应的页面内容。为了解决上述问题,本发明还公开了一种浏览同步装置,包括:第一获取模块,用于从输入的查询信息中获取用户标识和章回实体名称;第二获取模块,用于根据所述用户标识、所述章回实体名称,从用户个性化信息库中获取所述用户最近访问的所述章回实体的章节编号;其中,所述用户个性化信息库包括各用户的用户标识、每个所述用户访问过的各章回实体的名称和每部章回实体分别被各用户最近访问的章节编号;第一展示模块,用于根据所述章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取所述目标站点中所述章节编号的下一章节对应的页面内容。与现有技术相比,本发明具有以下优点:本发明公开的浏览同步方法与装置,当用户进行关于章回实体信息的查询时,通过用户个性化信息库确定用户最近访问过的章回实体对应的章节编号,进而将该章节编号应用到搜索引擎返回的目标站点中。这样,不论用户是否访问过该目标站点,也不论用户是否之前是通过该目标站点访问的章回实体,只要目标站点中存在用户待访问的章回实体,都可以获取到用户对该章回实体的最近访问章节,进而直接显示该章节的下一章节供用户浏览,而无须用户对目标站点经过多次操作才能访问到相应的章回实体。通过本发明,在目前的搜索引擎在进行章回实体的搜索时,提供了高效率的章回实体访问方案,在用户访问任何一个存在章回实体的目标站点时,被访问的目标站点都能够直接显示出满足用户需求的有效网页,提高了网络中信息筛选效率,减轻了服务器的检索负担。附图说明图1是根据本发明实施例一的一种浏览同步方法的步骤流程图;图2是根据本发明实施例二的一种浏览同步方法的步骤流程图;图3是根据本发明实施例三的一种浏览同步方法的步骤流程图;图4是根据本发明实施例四的一种浏览同步装置的结构框图。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。实施例一参照图1,示出了本申请实施例一的一种浏览同步方法的步骤流程图。本实施例中,浏览同步方法包括以下步骤:步骤S102:从输入的查询信息中获取用户标识和章回实体名称。当用户通过搜索引擎提供的界面进行输入查询时,搜索引擎根据该输入的字符生成相应的查询信息,该查询信息中包括有用户的标识以及用户输入的查询词,具体到本实施例中,该查询词即为章回实体名称。如用户输入“小说遮天”,则“小说”表明用户待查询的为章回实体,而该章回实体的名称为《遮天》。如果搜索引擎接收到的查询词为《遮天》,同样可以经语义分析后得到《遮天》为“小说”类的章回实体,并将输入的查询词《遮天》作为章回实体名称。章回实体表示具有章回性体裁的实体,这样的实体一般具有多个连续的章节,例如章回性小说、电视连续剧、连续多章节的漫画、连续的多集的综艺节目等等。步骤S104:根据用户标识和章回实体名称,从用户个性化信息库中获取用户最近访问的该章回实体的章节编号。其中,用户个性化信息库包括各用户的用户标识、每个用户访问过的各章回实体的名称和每部章回实体分别被各用户最近访问的章节编号。步骤S106:根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取目标站点中章节编号的下一章节对应的页面内容。通过本实施例,当用户进行关于章回实体信息的查询时,通过服务器端预置的用户个性化信息库确定用户最近访问过的该章回实体对应的章节编号,进而将该章节编号应用到用户调用的目标站点中。这样,不论用户是否访问过该目标站点,也不论用户是否之前是通过该目标站点访问的章回实体,只要目标站点中存在用户待访问的章回实体,目标站点都可以获取到用户对该章回实体的最近访问章节,进而直接显示该最近访问章节的下一章节供用户浏览,而无须用户对目标站点经过多次操作才能访问到相应的章回实体。通过本实施例,解决了目前的搜索引擎在进行章回实体的搜索时,对于相同的章回实体查找,搜索引擎会同时将不同站点的相同内容的章回实体的页面展示给查询用户,筛选效率低,无法筛选出能够满足用户需求的有效网页的问题,提供了高效率的章回实体访问方案,在用户访问任何一个存在章回实体的目标站点时,被访问的目标站点都能够直接显示出满足用户需求的有效网页,提高了网络中信息筛选效率,减轻了服务器的检索负担。实施例二参照图2,示出了本申请实施例二的一种浏览同步方法的步骤流程图。本实施例的浏览同步方法包括以下步骤:步骤S202:生成实体信息库。实体信息库中存储有多个全网中各章回实体的信息,章回实体的信息包括章回实体的名称、各章回实体分别在全网的各网站中对应的链接。生成实体信息库的步骤包括:分别获取全网中各站点中的章回实体,并根据各站点包含的章回实体的对应网页进行解析,根据目录区域识别网页中的章回实体对应的目录页;从目录页中分别提取章回实体的名称和章回实体的链接;根据各链接对应的质量参数,确定网站链接的等级;对章回实体的名称、章回实体的分别在全网的各网站中对应的链接和链接对应的等级进行结构化存储,生成实体信息库。该生成的实体信息库为动态的信息库,也即,其中存储的内容可以根据实时监测网络中各行业网站的章回实体更新情况实时或定时进行更新。例如,当检测到有新的章回实体发布时,可以实时抓取该新发布的章回实体的相关信息,添加到实体信息库中;或者,当检测到实体信息库中已存储的章回实体有更新时,将更新的相关信息从特定的行业网站更新到该实体信息库中,即将该章回实体对应的最新章节进行更新;当检测到实体信息库中已存储的章回实体的章节链接有修改时,将该修改也从特定的行业网站更新到该实体信息库中,替换原有链接等等。更为重要的是,各行业网站链接的等级也将动态更新,包括:每隔设定的时间间隔,重新获取各行业网站链接的质量参数,并重新确定提供章回实体对应内容的各行业网站链接的等级;根据重新确定的各行业网站链接的等级,对实体信息库中的网站链接的等级进行更新。例如,对应于某一章回性小说的网站链接包括站点A、站点B和站点C,初始时,根据站点A、站点B和站点C对应的网页级别、访问速度、访问量、广告因数中的一个或多个质量参数,确定该章回性小说对应的网站链接的等级从高到低依次为站点A、站点B和站点C。若本实施例中仅提供前二个等级的网站链接,则搜索引擎返回该章回性小说对应的链接时,从实体信息库中获取站点A和站点B对应的链接。经过设定的时间间隔(如24小时)后,系统再次获取该章回性小说在全网中各站点对应的链接,以及各个链接对应的质量参数,假设仍为站点A、站点B和站点C,重新根据站点A、站点B和站点C指示的网页级别、访问速度、访问量、广告因数中的一个或多个质量参数进行计算评估,确定该章回性小说对应的网站链接的等级从高到低依次为站点B、站点C和站点A。在更新后,当用户再对该章回性小说进行查询时,则搜索引擎返回该章回性小说对应的链接时,从实体信息库中获取站点B和站点C对应链接供用户进行触发。通过分析全网中各章回性小说对应的网站链接的等级,向用户返回各章回性小说对应的满足高质量的链接,以满足提高信息筛选的效率。例如,当希望搜索引擎返回的章回体小说中,对应网站中广告尽可能地少时,则将全网中的各站点在设定时间间隔内的广告因数对各网站进行排序,进而返回高等级的网站链接;再例如,当希望搜索引擎返回的章回体小说中,对应网站中的链接速度尽可能地快时,则将全网中的各站点在设定时间间隔内的访问速度对各站点进行排序,进而返回高等级的网站链接。此外,优选地,实体信息库中还存储有各个章回实体对应的标识。通过该标识,可以快速对章回实体进行查询和定位。步骤S204:生成用户个性化信息库。用户个性化信息库中存储有各用户的用户标识、每个用户访问过的各章回实体的名称、和每部章回实体分别被各用户最近访问的章节编号。生成用户个性化信息库的步骤包括:获取全网用户的网络访问日志;对网络访问日志进行解析,提取各用户的用户标识、每个用户访问过的各章回实体的名称、以及每部章回实体分别被各用户最近访问的章节编号之间的对应关系,结构化存储生成用户个性化信息库。但不限于此,在实际应用中,本领域技术人员也可以通过其它途径获取用户标识、访问过的章回实体的信息,进而生成用户个性化信息库。同样,在生成用户个性化信息库之后,每隔设定的时间间隔,重新获取全网用户的网络访问日志,更新每部章回实体分别被各用户最近访问的章节编号等信息,并根据重新获取的网络访问日志对用户个性化信息库进行更新。需要说明的是,上述步骤S202和S204的执行不分先后顺序,也可以并行执行。步骤S206:从用户输入的查询信息中获取用户标识和章回实体名称。步骤S208:根据用户标识和章回实体名称,从用户个性化信息库中获取用户最近访问的章回实体的章节编号。步骤S210:根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取目标站点中章节编号的下一章节对应的页面内容,并进行展示。首先,一种优选的搜索引擎返回搜索结果的方式是:根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体分别在全网的各网站中对应的链接;根据章回实体分别在全网的各网站中对应的链接向用户返回包含章回实体名称的搜索结果。其中,在根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体分别在全网的各网站中对应的链接时,一种优选方式是:当实体信息库中还存储有各个章回实体对应的标识时,根据存储的章回实体的标识和章回实体名称之间的对应关系,确定与从用户输入的查询信息中获取的章回实体名称相对应的章回实体的标识;根据章回实体的标识,从实体信息库中获取与章回实体的标识相对应的、且满足设定标准的至少一个网站的链接。在用户触发作为目标站点的链接时,分析目标站点中对应章回实体的目录页,从中提取对应章回实体的目录区域,从用户个性化信息库中获取用户最近访问的所述章回实体的章节编号,在目录区域中查找所述章节编号的下一章节,并调用所述章节编号的下一章节的页面内容,并进行展示。在其他实施例中,搜索引擎从实体信息库中获取与章回实体的标识相对应的、且满足设定标准的至少一个网站的链接的同时,同时对各链接对应的网站均作为目标站点进行分析,分析各目标站点中对应章回实体各自的目录页,从中分别提取对应章回实体的目录区域,从用户个性化信息库中获取用户最近访问的所述章回实体的章节编号,在目录区域中分别获取所述章节编号的下一章节对应的链接,并各自在各网站的链接的附近以副标题或子链接的形式分别对应加载。用户触发对应的副标题或子链接时,获取所述目标站点中所述章节编号的下一章节对应的页面内容,并进行展示。也即,在获取目标站点中章节编号的下一章节对应的页面内容之后,还缓存章节编号的下一章节对应的页面内容;当根据用户的操作确定用户需要浏览页面内容时,从缓存中加载页面内容并进行展示。章回实体的标识和章回实体名称之间的对应关系依据实体信息库中相应的信息生成,可以以任意适当的形式存储,如数据表、设定的数据结构、文档等等,本发明对此不作限制。在查询实体信息库之前,先确定与章回实体名称相对应的章回实体的标识,若无与章回实体名称相对应的章回实体的标识,则无须再到实体信息库中进行查询;若有与章回实体名称相对应的章回实体的标识,则可以直接使用章回实体的标识在实体信息库中查询。这样,一方面,通过标识查询实体信息库的速度优于通过名称的查询,可以提高查询效率;另一方面,当不存在与章回实体名称相对应的章回实体的标识时,则不再进行实体信息库查询,也提高了查询效率,减轻了查询负担。当然,该方式仅为优选方式,在实际应用中,直接使用章回实体名称进行实体信息库的查询也同样适用。优选地,在根据章回实体对应的链接向用户返回包含章回实体名称的搜索结果时,可以根据章回实体对应的链接中各个网站链接的质量参数,确定向用户返回包含所述章回实体名称的搜索结果;其中,质量参数包括以下至少之一:网站的网页级别、网站的访问速度、网站的访问量、网站的广告因数。当然,不对网站链接进行等级区分,直接返回设定个数的或全部的网站链接的方式同样适用本实施例。在搜索引擎返回搜索结果的基础上,根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取目标站点中章节编号的下一章节对应的页面内容时:一种可行方式是:根据章回实体的名称在目标站点中进行搜索,获得章回实体在目标站点中的对应主页;根据章节编号在主页的目录区域中进行查找,得到章节编号的下一章节对应的链接,从而获得下一章节的页面内容。另一种可行方式是:根据章节编号直接在目标站点对应的搜索结果中进行搜索,获得章节编号对应的页面内容;根据章节编号对应的页面内容中的提示链接获得章节编号的下一章节对应的链接,从而获得下一章节的页面内容。再一种可行方式是:当用户个性化信息库还包括每个用户访问过的各章回实体分别在全网的各网站中对应的链接时,可以根据被调用的目标站点在用户个性化信息库中进行搜索,得到章回实体在目标站点中的对应链接;根据章回实体在目标站点中的对应链接的页面进行页面分析,获得章回实体在目标站点中的目录区域;根据从用户个性化信息库中获取的章节编号在目录区域中进行查找,得到章节编号的下一章节对应的页面链接,从而获得下一章节的页面内容。通过本实施例,当用户进行关于章回实体信息的查询时,通过用户个性化信息库、实体信息库、章回实体的标识和章回实体的名称之间的对应关系,一方面可以直接获得满足设定标准的含有所述章回实体的网站;另一方面,满足设定标准的网站中,根据用户以往对章回实体的访问情况,即用户最近访问的所述章回实体的章节编号,直接向用户返回接续的章回实体的内容,从而解决了目前的搜索引擎在进行章回实体的搜索时,对于相同的章回实体查找,搜索引擎会同时将不同站点的相同内容的章回实体的页面展示给查询用户,筛选效率低,无法筛选出能够满足用户需求的有效网页的问题,本实施例将存储的用户最近访问的对应章回实体的章节编号同步至被触发的目标站点,提供了高效率的网页筛选方案,能够直接筛选出满足用户需求的有效网页,提高了信息筛选的效率,减轻了搜索引擎服务器由于多次检索造成的检索负担。实施例三参照图3,示出了本申请实施例三的一种网页搜索中的浏览同步方法的步骤流程图。本实施例以A用户上次在“万卷书屋”阅读到小说《遮天》第155章,当A用户再次查询“遮天”,搜索引擎会自动为用户A推荐“笔趣阁”的小说《遮天》第156章为例,对本发明的网页浏览同步方案进行说明。本实施例的网页搜索中的浏览同步方法包括以下步骤:步骤S302:生成实体信息库和用户个性化信息库。生成用户个性化信息库时,可以通过获取全网用户的网络访问日志;对网络访问日志进行解析,获取各用户的用户标识、每个用户访问过的各章回实体的名称、和每部章回实体分别被各用户最近访问的章节编号之间的对应关系,结构化存储生成用户个性化信息库。比如,以用户为单位,从点击日志中分析其感兴趣的章回实体,并记录其最近点击过的该章回实体链接所对应章节,形成用户个性化信息库。生成实体信息库时,通过获取包含有章回实体的网页并对网页进行解析,识别网页中的章回实体的目录页;从目录页中提取章回实体的名称和章回实体的网站链接;根据各个网站链接对应的质量参数,确定网站链接的等级;对章回实体的名称、章回实体的网站链接和网站链接的等级进行结构化存储,生成实体信息库。生成实体信息库和用户个性化信息库时,一方面,以站点为单位,对海量互联网数据如海量网页索引库中的页面进行分析,分析各站点中章回实体对应的目录结构,确定各站点中包含的高质量连续性内容,按所属的不同连续性实体聚合。如,分别按照有效的高质量页面和页面间的连续性进行聚合,生成实体信息库;另一方面,获取多个用户的网络访问日志,基于网络访问日志统计全网中各用户的阅览进度并生成用户个性化信息库。具体地,在生成实体信息库时,以站点为单位,对海量网页索引库中的页面进行解析,根据页面结构和关键词识别相关站点中的章回实体目录页,抽取实体名称,记录其对应的链接。多个站点解析出的同一实体数据需要根据最大化原则,进行信息融合,最终生成章回实体信息表。分析该章回实体信息表,在每个章回对应的不同站点链接表中,根据Pagerank(网页等级)、访问速度、访问量、广告因数等因素,计算链接对应的分数,入库保存。以下,以具体实例为例,对本实施例中生成实体信息库和用户个性化信息库的流程进行说明。服务器获取海量互联网数据,本实施例中为海量网页索引库中的页面,通过Spider抓取“万卷书屋”、“笔趣阁”等小说站点的对应页面,通过分析页面结构和关键词,解析出诸多小说名称,其中包括章回性小说《遮天》,以及诸多章回性小说对应的链接。保存上述解析出的页面中的信息,形成结构化页面数据集中实体对象的相关数据。将各站点数据按章回实体的名称归并,对每个小说,如《遮天》,分析其在每个站点的链接,结合链接对应的页面访问量、访问速度、站点分级、广告数等信息中的一种或多种,确定链接的等级。本实施例中,按CTR(点击率)、站点分级和广告数确定链接的等级。如,通过分析,获知站点“笔趣阁”提供的《遮天》的链接优于站点“万卷书屋”的链接。将上述有效信息均进行存储,生成实体信息库。该实体信息库包含:实体ID、实体名称、人物、章节数、链接地址(同名实体可以根据作者/导演等信息进行区分)等。另一方面,服务器通过网络访问日志获取不同用户对章回实体的浏览进度,形成结构化页面数据集中用户个性化数据。进而,服务器根据数据集中的网络访问日志的数据记录用户阅览进度,生成有关用户阅览进度的数据表,即用户个性化信息库。该用户个性化信息库包含:用户ID、用户访问过的章回实体、用户访问的章回实体的最新访问记录等。如,服务器记录下用户A最近访问过《遮天》的章节为“万卷书屋”中的《遮天》第155章,将各用户最近访问的章节编号“155”存入用户个性化信息库。再一方面,本实施例中,服务器还基于章回实体和章节号建立各站点间的页面间关系,即章回实体内容间的连续性关系。步骤S304:搜索引擎从用户输入的查询信息中获取用户标识和章回实体名称。本实施例中,以用户A输入的查询词为“遮天”为例,则包含有“遮天”的查询信息中携带了用户A对应的用户标识和章回实体名称《遮天》。步骤S306:搜索引擎根据用户标识和章回实体名称,从用户个性化信息库中获取用户最近访问的章回实体的章节编号。搜索引擎将章回实体名称和用户标识(可以根据cookie计算)发送到存储用户个性化信息库的服务器。该服务器查询用户标识对应的个性化信息,可得该用户最近访问的章回实体的信息。如,根据用户A的用户标识以及章回实体名称《遮天》查询用户个性化信息库,获取用户A最近访问的《遮天》的章节编号为第155章。步骤S308:搜索引擎根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体分别在全网的各网站中对应的链接并返回,每一个链接对应于一个目标站点。本实施例中,还设置有章回实体词表,所述章回实体词表中存储有章回实体的标识和章回实体的名称之间的对应关系。在根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体分别在全网的各网站中对应的链接时,首先根据章回实体词表,确定与章回实体名称相对应的章回实体的标识;再根据得到的章回实体的标识,从实体信息库中获取与章回实体的标识相对应的、且满足设定标准的至少一个网站的链接。具体到本实施例,先根据用户A输入的章回实体名称“遮天”在章回实体词表中进行匹配,得到《遮天》对应的标识;再在实体信息库中查找该标识对应的网站链接并返回作为目标站点。本实施例中,返回的网站链接中包括站点“笔趣阁”、站点“万卷书屋”等中关于章回性小说《遮天》的链接。步骤S310:搜索引擎根据用户的输入确定用户待访问的目标站点。本实施例中,设定用户A在返回的搜索结果中触发了站点“笔趣阁”的链接,则搜索引擎将站点“笔趣阁”作为目标站点,确定用户A要从“笔趣阁”这一目标站点中访问章回实体《遮天》。步骤S312:搜索引擎根据章回实体的名称在目标站点中进行搜索,获得章回实体在目标站点中的对应主页。本实施例中,搜索引擎在站点“笔趣阁”中搜索章回实体《遮天》,获得章回实体《遮天》在站点“笔趣阁”中对应的主页。主页中包括章回实体《遮天》的封面、目录、作者和最后更新等著录信息,也包括动态图片形式的广告、推荐阅读的其他修真类小说等相关信息。本实施例中,需要滤除主页中与章节无关的其他信息,进一步结合步骤306得到的,用户最近访问的章回实体的章节编号对著录信息中的目录进行分析,从而获得用户欲阅读的章节。步骤S314:搜索引擎根据章节编号在对应主页的目录区域中进行查找,得到章节编号的下一章节对应的页面内容,并进行展示。本实施例中,用户A之前在站点“万卷书屋”最近阅读到小说《遮天》的第155章,对应的下一章节为第156章。本次访问站点“笔趣阁”时,在站点“笔趣阁”的小说《遮天》对应的主页中,根据主页的DOM结构,获得小说《遮天》的目录区域,并进一步在目录区域中查找到《遮天》第156章对应的链接,加载第156章链接对应的页面内容并向用户A返回展示。再例如,通过上述过程,假设用户A上次在“起点中文网”中阅读到小说《遮天》第100章,搜索引擎记录其查询和浏览信息,并以用户A的唯一ID为用户标识存入用户个性化信息库。当用户A再次在搜索引擎中查询《遮天》时,搜索引擎在线上会为用户A做如下处理:通过相应搜索引擎判断出用户A的查询意图,并提取出其中的章回实体名称(遮天);识别用户,确定其浏览进度(如第100章);把《遮天》对应的简介,相关信息,图片,以及包含有《遮天》内容的网站的链接,用富媒体的方式在搜索结果中展现给用户。如,当用户A再次搜索,触发的为搜索结果对应的条目:站点“万卷书屋”中《遮天》的链接时,虽然在“万卷书屋”中没有设置书签,但搜索引擎会根据用户个性化信息库中记录的用户A的浏览进度,即第100章,直接抓取站点“万卷书屋”中《遮天》第101章的内容返回给用户,节省用户A查找时间,实现在不同网站中书签的同步。再例如,用户A上次在站点“万卷书屋”阅读到《遮天》第155章,且第155章对应的页面上有很多弹出广告,影响了信息的筛选效率。当其再次在搜索引擎中输入查询词“遮天”,搜索引擎根据章回实体《遮天》分别在全网的各网站中对应的链接中各个网站链接的质量参数会自动推荐包含有小说《遮天》内容,且没有广告的多个网站链接作为搜索结果。如用户在返回的搜索结果中触发站点“笔趣阁”对应的链接,搜索引擎将调用小说“笔趣阁”的《遮天》第156章(没有广告)的内容返回给用户。一方面这样节省了其查找时间(可读的156章),另一方面提升了信息的筛选效率(无广告)。再例如,用户A一直在追章回性的综艺节目《我是歌手》,需要每周搜索节目名称,点开各大视频网站看是否存在有效链接,期间除了多次点击还要忍受各种吵闹的广告,最后有可能发现最新版还未上映。采用本实施例的方案,用户A可以在搜索引擎中搜索“我是歌手”,然后直接点击结果页上搜索引擎分析用户行为后,即无论上次用户A在哪个视频网站中观看了《我是歌手》,则都会被记录到用户个性化信息库中,则当用户调用搜索结果页中的目标站点时,根据用户个性化信息库中记录的用户A最新浏览的一期《我是歌手》,如第12期,对调用的目标站点进行结构分析,获取目标站点中综艺节目《我是歌手》对应的目录页面,并从目录页面中查找最新浏览的一期《我是歌手》的下一期的对应链接,即第13期对应的页面内容,同时根据页面内容中的视频进行播放。在其他实施例中,步骤S312、S314和S310也可以进行调整,即在返回的搜索引擎对应的搜索结果中,将全部或者部分的链接对应的站点均作为目标站点,分别获得章回实体在目标站点中的对应主页,并分别识别主页中被各用户最近访问的章节编号的下一章节的对应链接,获取所述章节编号的下一章节对应的页面内容进行缓存后,根据用户的触发对缓存的页面内容进行加载。也即,可以在获取到目标站点中章节编号的下一章节对应的页面内容后,对所述页面内容进行缓存;然后,当根据用户的操作确定用户需要浏览所述页面内容时,从缓存中加载所述页面内容并进行展示。本实施例提供了一种优化的浏览同步方案,当用户输入的查询词中包含有章回实体时,搜索引擎将该章回实体和用户对应的用户标识发送至后台服务器,由后台服务器获得该用户历史行为和涉及该章回实体的最近访问的章节,触发对应的目标站点时,将最近访问的章节的“下一期”内容链接返回给搜索引擎进行融合,然后展现给用户。通过本实施例,针对章回体实体(小说、漫画、综艺等)进行结构分析,分析章回体实体的目录结构,根据用户的历史阅读日志将对应的“下一章节”推送给用户,实现了全网阅读的同步,从而避免了热门连续性信息常伴随许多作弊页面,其中不含有效信息,或者夹杂过多广告,但从摘要角度看很具有欺骗性的现象,以及搜索引擎对不同用户展现相同搜索结果,需要用户自己根据当前进度选择的现象,提高了信息筛选的效率。本实施例的网页浏览同步方案中,页面解析后按实体进行规整,整合到一条结果中,信息简单明了;按CTR、站点分级和广告数选出最优质站点,避免了用户筛选;引擎通过用户行为生成个性化内容,省去用户自己甄别和查找,进一步,提高了信息筛选的效率。实施例四参照图4,示出了本实施例四的一种浏览同步装置的结构框图。本实施例的网页搜索中的浏览同步装置包括:第一获取模块402,用于从输入的查询信息中获取用户标识和章回实体名称;第二获取模块404,用于根据用户标识、章回实体名称,从用户个性化信息库中获取用户最近访问的章回实体的章节编号;其中,用户个性化信息库包括各用户的用户标识、每个用户访问过的各章回实体的名称和每部章回实体分别被各用户最近访问的章节编号;第一展示模块406,用于根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析,获取目标站点中所述章节编号的下一章节对应的页面内容。优选地,本实施例的网页搜索中的浏览同步装置还包括:第二展示模块,用于使搜索引擎通过以下方式返回搜索结果:根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体分别在全网的各网站中对应的链接;其中,实体信息库中包括全网中各章回实体的名称、各章回实体分别在全网的各网站中对应的链接;根据章回实体分别在全网的各网站中对应的链接向用户返回包含章回实体名称的搜索结果。优选地,第二展示模块在根据章回实体分别在全网的各网站中对应的链接向用户返回包含章回实体名称的搜索结果时:根据章回实体分别在全网的各网站中对应的链接中各个网站链接的质量参数,确定向用户返回包含章回实体名称的搜索结果;其中,质量参数包括以下至少之一:网站的网页级别、网站的访问速度、网站的访问量、网站的广告因数。优选地,本实施例的网页搜索中的浏览同步装置还包括:第一生成模块,用于在第一获取模块从输入的查询信息中获取用户标识和章回实体名称之前,分别获取全网中各站点中的章回实体,根据各站点包含的章回实体对应网页进行解析,识别网页中的章回实体对应的目录页;从目录页中分别提取章回实体的名称和章回实体的网站链接;根据各个网站链接对应的质量参数,确定网站链接的等级;对章回实体的名称、章回实体的分别在全网的各网站中对应的链接和链接的等级进行结构化存储,生成实体信息库。优选地,本实施例的网页搜索中的浏览同步装置还包括:更新模块,用于在第一生成模块生成实体信息库之后,每隔设定的时间间隔,重新获取各个网站链接的质量参数,并重新确定各个网站链接的等级;根据重新确定的网站链接的等级,对实体信息库中的网站链接的等级进行更新。优选地,实体信息库中还存储有各个章回实体对应的标识;第二展示模块在根据章回实体名称,从实体信息库中获取包含有章回实体名称指示的章回实体对应的链接时:根据存储的章回实体的标识和章回实体名称之间的对应关系,确定与从用户输入的查询信息中获取的章回实体名称相对应的章回实体的标识;根据章回实体的标识,从实体信息库中获取与章回实体的标识相对应的、且满足设定标准的至少一个网站的链接。优选地,用户个性化信息库还包括,每个用户访问过的各章回实体分别在全网的各网站中对应的链接;第一展示模块406在根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析时:根据被调用的目标站点在用户个性化信息库中进行搜索,得到章回实体在目标站点中的对应链接;根据章回实体在目标站点中的对应链接的页面进行页面分析,获得章回实体在目标站点中的目录区域;根据章节编号在目录区域中进行查找,得到章节编号的下一章节对应的链接。优选地,第一展示模块406在根据章节编号对搜索引擎返回的搜索结果中被调用的目标站点进行分析时:根据章回实体的名称在目标站点中进行搜索,获得章回实体在目标站点中的对应主页;根据章节编号在主页的目录区域中进行查找,得到章节编号的下一章节对应的链接;或者,根据章节编号直接在目标站点对应的搜索结果中进行搜索,获得章节编号对应的页面内容;根据章节编号对应的页面内容中的提示链接获得章节编号的下一章节对应的链接。优选地,第一展示模块406在获取目标站点中章节编号的下一章节对应的页面内容时:在主页的目录区域中获取章节编号的下一章节对应的链接,并以副标题或子链接的形式进行提示;接收用户触发副标题或子链接的操作,获取目标站点中章节编号的下一章节对应的页面内容。优选地,第一展示模块406,还用于在获取目标站点中章节编号的下一章节对应的页面内容之后,缓存章节编号的下一章节对应的页面内容;当根据用户的操作确定用户需要浏览页面内容时,从缓存中加载页面内容并进行展示。优选地,本实施例的网页搜索中的浏览同步装置还包括:第二生成模块,用于在第一获取模块402从输入的查询信息中获取用户标识和章回实体名称之前,获取全网用户的网络访问日志;对网络访问日志进行解析,提取各用户的用户标识、每个用户访问过的各章回实体的名称、和每部章回实体分别被各用户最近访问的章节编号之间的对应关系,结构化存储生成用户个性化信息库。优选地,更新模块还用于在生成用户个性化信息库后,每隔设定的时间间隔,重新获取全网用户的网络访问日志,并根据重新获取的网络访问日志对用户个性化信息库进行更新。本实施例的网页搜索中的浏览同步装置用于实现前述多个方法实施例中相应的网页浏览同步方法,并且具有相应的方法实施的有益效果,在此不再赘述。本发明提供了一种网页搜索中的浏览同步方案,该方案可广泛用于所有包含章回实体的场合,如连续剧、综艺节目、书籍等。本发明的网页搜索中的浏览同步方案通过对全网索引库中的页面进行分析,按实体对各站点中的章回体内容进行聚合;根据聚合形成的关联关系和各站点中记录的用户行为,分别确定每个用户对应实体的待加载章节或位置,使用户在任何站点调用对应实体时,均可加载对应的待加载章节或位置,实现了不同站点的书签同步。本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。以上对本发明所提供的一种网页搜索中的浏览同步方法和装置进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1