访问日志的查询方法和装置与流程
本申请涉及数据处理领域,具体而言,涉及一种访问日志的查询方法和装置。
背景技术:
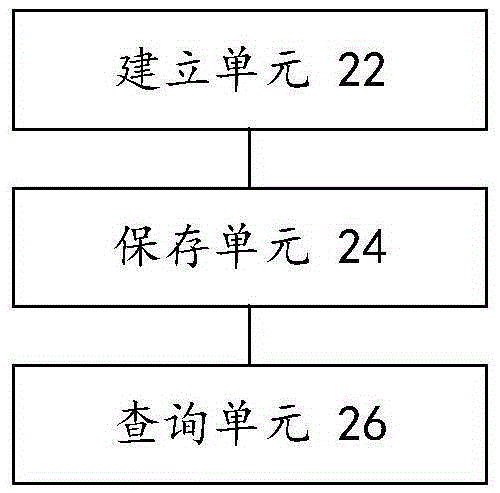
:Tomcat是一个免费的开源的Web应用服务器,在中小型系统和并发访问用户下被普遍使用。用户访问Tomcat的访问日志是十分有价值的,需要对用户的访问日志进行保存。由于访问日志的数据量比较大,在服务器本地保存访问日志就会消耗磁盘的资源,影响服务器的性能,将数据保存至分布式数据库是十分可行的方法。HBase是一个可靠性高、性能好、面向列、可伸缩分布式存储系统,可以在HBase中同时保存多个Tomcat的访问日志。在HBase中保存Tomcat的访问日志,需要在HBase中建立一张表,用于存放Tomcat的访问日志。当需要对Tomcat中的访问日志进行查询时,在这张表中进行查询。由于这张表中同时保存多个Tomcat的访问日志,数据量是十分大的,查询某一个或某几个特定服务器的访问日志耗时较长,查询效率低。针对上述的问题,目前尚未提出有效的解决方案。技术实现要素:本申请实施例提供了一种访问日志的查询方法和装置,以至少解决现有技术中在HBase中查询某一个或某几个服务器的访问日志耗时较长,查询效率低的技术问题。根据本申请实施例的一个方面,提供了一种访问日志的查询方法,包括:在分布式数据库中建立表,其中,所述表的行键包括服务器的标识,所述表包括多个行;将接收到的多个服务器的访问日志对应保存至所述表的目标行,其中,与目标服务器对应的所述目标行为行键包括所述目标服务器的标识的行,所述目标服务器为所述多个服务器中的任一服务器,与任一所述服务器对应的所述目标行为多个;根据所述行键,在所述表中查询待查询服务器的访问日志。进一步地,所述表的行键还包括预设时间,将接收到的多个服务器的访问日志对应保存至所述表的目标行包括:获取所述多个服务器中服务器i的访问日志Li的访问时间ti,其中,i依次取1至m,m为所述多个服务器中服务器的数量;查找所述目标 行中行键包括标识Zi和预设时间Ti的目标行Hi,其中,所述标识Zi为所述服务器i的标识,所述预设时间Ti为所述访问时间ti所属的预设时间;以及将所述服务器i的访问日志保存至所述目标行Hi,根据所述行键,在所述表中查询待查询服务器的访问日志包括:根据所述待查询服务器的标识,在所述表中查询所述待查询服务器的访问日志;或根据所述待查询服务器的标识和待查询时间,在所述表中查询所述待查询服务器的访问日志,其中,所述待查询时间为所述表的行键中的任一预设时间。进一步地,所述服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为所述多条访问数据中访问数据的数量,获取所述多个服务器中服务器i的访问日志Li的访问时间ti包括:获取访问数据Lij的访问时间tij,其中,j依次取1至ni,查找所述目标行中行键包括标识Zi和预设时间Ti的目标行Hi包括:查找所述目标行中行键包括所述标识Zi和预设时间Tij的目标行Hij,其中,所述预设时间Tij为所述访问时间tij所属的预设时间,将所述服务器i的访问日志保存至所述目标行Hi包括:将所述服务器i的所述访问数据Lij保存至所述目标行Hij。进一步地,所述表的行键还包括预设时间和日志标识,将接收到的多个服务器的访问日志对应保存至所述表的目标行还包括:获取所述多个服务器中服务器i的访问日志Li的访问时间ti和所述访问日志Li的日志标识Ri,其中,i依次取1至m,m为所述多个服务器中服务器的数量;查找所述目标行中行键包括标识Zi、预设时间Ti和所述日志标识Ri的目标行Hi,其中,所述标识Zi为所述服务器i的标识,所述预设时间Ti为所述访问时间ti所属的预设时间;以及将所述服务器i的访问日志保存至所述目标行Hi,根据所述行键,在所述表中查询待查询服务器的访问日志还包括:根据所述待查询服务器的标识,在所述表中查询所述待查询服务器的访问日志;或根据所述待查询服务器的标识和待查询时间,在所述表中查询所述待查询服务器的访问日志,其中,所述待查询时间为所述表的行键中的任一预设时间。进一步地,所述服务器i的访问日志包括由访问数据Li1至访问数据组成的多 条访问数据,其中,ni为所述多条访问数据中访问数据的数量,获取所述多个服务器中服务器i的访问日志Li的访问时间ti和所述访问日志Li的日志标识Ri包括:获取访问数据Lij的访问时间tij和所述访问数据Lij的通用识别唯一码Uij,其中,j依次取1至ni,所述日志标识为所述通用识别唯一码Uij,查找所述目标行中行键包括标识Zi、预设时间Ti和所述日志标识Ri的目标行Hi包括:查找所述目标行中行键包括所述标识Zi、预设时间Tij和所述通用识别唯一码Uij的目标行Hij,其中,所述预设时间Tij为所述访问时间tij所属的预设时间,将所述服务器i的访问日志保存至所述目标行Hi包括:将所述服务器i的所述访问数据Lij保存至所述目标行Hij。根据本申请实施例的另一方面,还提供了一种访问日志的查询装置,包括:建立单元,用于在分布式数据库中建立表,其中,所述表的行键包括服务器的标识,所述表包括多个行;保存单元,用于将接收到的多个服务器的访问日志对应保存至所述表的目标行,其中,与目标服务器对应的所述目标行为行键包括所述目标服务器的标识的行,所述目标服务器为所述多个服务器中的任一服务器,与任一所述服务器对应的所述目标行为多个;查询单元,用于根据所述行键,在所述表中查询待查询服务器的访问日志。进一步地,所述表的行键还包括预设时间,所述保存单元包括:第一获取子单元,用于获取所述多个服务器中服务器i的访问日志Li的访问时间ti,其中,i依次取1至m,m为所述多个服务器中服务器的数量;第一查找子单元,用于查找所述目标行中行键包括标识Zi和预设时间Ti的目标行Hi,其中,所述标识Zi为所述服务器i的标识,所述预设时间Ti为所述访问时间ti所属的预设时间;以及第一保存子单元,用于将所述服务器i的访问日志保存至所述目标行Hi,所述查询单元包括:第一查询子单元,用于根据所述待查询服务器的标识,在所述表中查询所述待查询服务器的访问日志;以及第二查询子单元,用于根据所述待查询服务器的标识和待查询时间,在所述表中查询所述待查询服务器的访问日志,其中,所述待查询时间为所述表的行键中的任一预设时间。进一步地,所述服务器i的访问日志包括由访问数据Li1至访问数据组成的多 条访问数据,其中,ni为所述多条访问数据中访问数据的数量,所述第一获取子单元包括:第一获取模块,用于获取访问数据Lij的访问时间tij,其中,j依次取1至ni,所述第一查找子单元包括:第一查找模块,用于查找所述目标行中行键包括所述标识Zi和预设时间Tij的目标行Hij,其中,所述预设时间Tij为所述访问时间tij所属的预设时间,所述第一保存子单元包括:第一保存模块,用于将所述服务器i的所述访问数据Lij保存至所述目标行Hij。进一步地,所述表的行键还包括预设时间和日志标识,所述保存单元还包括:第二获取子单元,用于获取所述多个服务器中服务器i的访问日志Li的访问时间ti和所述访问日志Li的日志标识Ri,其中,i依次取1至m,m为所述多个服务器中服务器的数量;第二查找子单元,用于查找所述目标行中行键包括标识Zi、预设时间Ti和所述日志标识Ri的目标行Hi,其中,所述标识Zi为所述服务器i的标识,所述预设时间Ti为所述访问时间ti所属的预设时间;以及第二保存子单元,用于将所述服务器i的访问日志保存至所述目标行Hi,所述查询单元还包括:第三查询子单元,用于根据所述待查询服务器的标识,在所述表中查询所述待查询服务器的访问日志;以及第四查询子单元,用于根据所述待查询服务器的标识和待查询时间,在所述表中查询所述待查询服务器的访问日志,其中,所述待查询时间为所述表的行键中的任一预设时间。进一步地,所述服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为所述多条访问数据中访问数据的数量,所述第二获取子单元包括:第二获取模块,用于获取访问数据Lij的访问时间tij和所述访问数据Lij的通用识别唯一码Uij,其中,j依次取1至ni,所述日志标识为所述通用识别唯一码Uij,所述第二查找子单元包括:第二查找模块,用于查找所述目标行中行键包括所述标识Zi、预设时间Tij和所述通用识别唯一码Uij的目标行Hij,其中,所述预设时间Tij为所述访问时间tij所属的预设时间,所述第二保存子单元包括:第二保存模块,用于将所述服 务器i的所述访问数据Lij保存至所述目标行Hij。在本申请实施例中,采用在分布式数据库中建立表,其中,表的行键包括服务器的标识,表包括多个行,将接收到的多个服务器的访问日志对应保存至表的目标行,其中,与目标服务器对应的目标行为行键包括目标服务器的标识的行,目标服务器为多个服务器中的任一服务器,与任一服务器对应的目标行为多个,根据行键,在表中查询待查询服务器的访问日志。通过在建立HBase的表时,使表的行键包括服务器的标识,将服务器的访问日志对应保存至行键包括该服务器的标识的行中,使得同一个服务器的访问日志的访问数据保存在表中相邻的位置,当需要查询某个服务器的访问日志时,按照表的行键进行查询,由于同一个服务器的访问日志的访问数据在表中所处的位置很集中,因此,查询时速度很快,从而实现了快速查询出待查询服务器的访问日志的技术效果,进而解决了现有技术中在HBase中查询某一个或某几个服务器的访问日志耗时较长,查询效率低的技术问题。附图说明此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:图1是根据本申请实施例的访问日志的查询方法的流程图;以及图2是根据本申请实施例的访问日志的查询装置的示意图。具体实施方式为了使本
技术领域:
的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方 法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。首先对本申请实施例所涉及的技术术语作如下解释:时间戳:时间戳(time-stamp)是一个经加密后形成的凭证文档,它包括三个部分:(1)需加时间戳的文件的摘要(digest);(2)DTS收到文件的日期和时间;(3)DTS的数字签名。时间戳主要分为两种:(1)自建时间戳:此类时间戳是通过时间接收设备(如GPS,CDMA,北斗卫星)来获取时间到时间戳服务器上,并通过时间戳服务器签发时间戳证书。此种时间戳可用来企业内部责任认定,在法庭认证时并不具备法律效力。因其在通过时间接收设备接收时间时存在被篡改的可能,故此不能做为法律依据。(2)具有法律的效力的时间戳:它是由我国中科院国家授时中心与北京联合信任技术服务有限公司负责建设的我国第三方可信时间戳认证服务。由国家授时中心负责时间的授时与守时监测。因其守时监测功能而保障时间戳证书中的时间的准确性和不被篡改。获取时间戳平台有“大众版权保护平台”,可与我国中科院国家授时中心时间同步。根据本申请实施例,提供了一种访问日志的查询方法的实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。图1是根据本申请实施例的访问日志的查询方法的流程图,如图1所示,该方法包括如下步骤:步骤S102,在分布式数据库中建立表,其中,表的行键包括服务器的标识,表包括多个行。步骤S104,将接收到的多个服务器的访问日志对应保存至表的目标行,其中,与目标服务器对应的目标行为行键包括目标服务器的标识的行,目标服务器为多个服务器中的任一服务器,与任一服务器对应的目标行为多个。步骤S106,根据行键,在表中查询待查询服务器的访问日志。分布式数据库可以为HBase数据库。当需要保存的数据的数据量非常巨大时,使用HBase数据库中的表保存数据是一个非常好的方法。HBase只能用行键rowkey来查找数据。所以rowkey的设计是至关重要的,关系到查询效率的高低。行键rowkey是以字典顺序排序的。例如,有三个行键,分别为rowkey1、rowkey2、rowkey3。rowkey1为aaa222,rowkey2为bbb111,rowkey3为abb111。首先将rowkey1、rowkey2和rowkey3的第一位进行比较,rowkey1和rowkey3的第一位是a,rowkey2的第一位是b,所以rowkey1和rowkey3排在rowkey2前面,再将rowkey1和rowkey3的第二位进行比较,rowkey1的第二位是a,rowkey3的第二位是b,所以rowkey1排在rowkey3前面,综上所述,rowkey1排在rowkey3前面,rowkey3排在rowkey2前面。HBase中用rowkey来查询表中的记录,支持以下三种查询方式:(1)通过单个rowkey访问:即按照某个rowkey键值进行get操作。(2)通过rowkey的范围进行扫描:即通过设置startRowKey(开始行键)和endRowKey(结束行键),在这个范围内进行扫描;(3)全表扫描:即直接扫描整张表中所有行记录。当需要将多个服务器的访问日志保存到HBase的表中时,设计表的行键rowkey为服务器的标识,这样当接收到来自某一个服务器的访问日志时,就可以将该服务器的访问日志保存至行的行键为该服务器的标识的行中。设置HBase的表的列包括:远程主机名(RemoteHosts)、时间戳(TimeStamp)、虚拟主机名(VirtualHost)、查询参数(Query)、用户代理浏览器(UserAgent)、方法名(Method)、单次请求Tomcat内存的变化值等。HBase数据库中的列的数量不用事先指定,可以根据需要随时添加。例如,一共需要在HBase的表T1中保存5个Tomcat的访问日志,这5个Tomcat的标识分别为字符串s1、字符串s2、字符串s3、字符串s4和字符串s5。设计HBase的表T1的行键分别包括字符串s1、字符串s2、字符串s3、字符串s4、字符串s5。假设一共接收到10条访问数据,表1示出了这10条访问数据中每条访问数据的编号和访问数据来自哪个服务器,则将访问数据D2保存至表T1中行键包括字符串s1的行中,将访问数据D6和访问数据D8保存至表T1中行键包括字符串s2的行中,将访问数据D1和访问数据D4保存至表T1中行键包括字符串s3的行中,将访问数据D5保存至表T1中行键包括字符串s4的行中,将访问数据D3、访问数据D7、访问数据D9和访问数据D10保存至表T1中行键包括字符串s5的行中。需要注意的是,由于篇幅所限,本例子给出的数据仅为10条,而在实际应用中,访问日志的访问数据的数量是非常巨大的。表1访问数据编号访问数据来源D1Tomcat3D2Tomcat1D3Tomcat5D4Tomcat3D5Tomcat4D6Tomcat2D7Tomcat5D8Tomcat2D9Tomcat5D10Tomcat5查询表T1中行键包括字符串s1的行,得到Tomcat1的全部访问日志;查询表T1中行键包括字符串s2的行,得到Tomcat2的全部访问日志;查询表T1中行键包括字符串s3的行,得到Tomcat3的全部访问日志。通过在建立HBase的表时,使表的行键包括服务器的标识,将服务器的访问日志对应保存至行键包括该服务器的标识的行中,使得同一个服务器的访问日志的访问数据保存在表中相邻的位置,当需要查询某个服务器的访问日志时,按照表的行键进行查询,由于同一个服务器的访问日志的访问数据在表中所处的位置很集中,因此,查询时速度很快,从而实现了快速查询出待查询服务器的访问日志的技术效果,进而解决了现有技术中在HBase中查询某一个或某几个服务器的访问日志耗时较长,查询效率低的技术问题。可选地,表的行键还包括预设时间,将接收到的多个服务器的访问日志对应保存至表的目标行包括:获取多个服务器中服务器i的访问日志Li的访问时间ti,其中,i依次取1至m,m为多个服务器中服务器的数量;查找目标行中行键包括标识Zi和预 设时间Ti的目标行Hi,其中,标识Zi为服务器i的标识,预设时间Ti为访问时间ti所属的预设时间;以及将服务器i的访问日志保存至目标行Hi,根据行键,在表中查询待查询服务器的访问日志包括:根据待查询服务器的标识,在表中查询待查询服务器的访问日志;或根据待查询服务器的标识和待查询时间,在表中查询待查询服务器的访问日志,其中,待查询时间为表的行键中的任一预设时间。可选地,服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为多条访问数据中访问数据的数量,获取多个服务器中服务器i的访问日志Li的访问时间ti包括:获取访问数据Lij的访问时间tij,其中,j依次取1至ni,查找目标行中行键包括标识Zi和预设时间Ti的目标行Hi包括:查找目标行中行键包括标识Zi和预设时间Tij的目标行Hij,其中,预设时间Tij为访问时间tij所属的预设时间,将服务器i的访问日志保存至目标行Hi包括:将服务器i的访问数据Lij保存至目标行Hij。每个服务器的访问日志都包括至少一条访问数据,在大多数情况下,每个服务器的访问日志都包括大量的访问数据。服务器1的访问日志包括n1条访问数据,分别为访问数据L11、访问数据L12、访问数据L13、……、访问数据服务器2的访问日志包括n2条访问数据,分别为访问数据L21、访问数据L22、访问数据L23、……、访问数据以此类推,服务器i的访问日志包括ni条访问数据,分别为访问数据Li1、访问数据Li2、访问数据Li3、……、访问数据访问数据Lij的访问时间为tij,tij精确到秒。预设时间Tij为访问时间tij所在的那一天,预设时间Tij精确到天。例如,当访问时间为2015年11月10日08:20:30,则访问时间所属的预设时间为2015年11月10日。再例如,当访问时间为2015年10月25日15:25:58,则访问时间所属的预设时间为2015年10月25日。例如,建立HBase的表T2,设置表T2的行键包括服务器的标识和日期,例如,假设一共有3个Tomcat服务器,这3个Tomcat服务器的标识分别为字符串s1、字符串s2、字符串s3,设置表T2的行键包括字符串s1和日期,或包括字符串s2和日期,或包括字符串s3和日期。假设HBase一共接收到1百万条访问数据,表2示出了这1百万条访问数据中每条访问数据的编号、访问数据来源于哪个服务器和访问数据产生的时间。将访问数据D1保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D2保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D3保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D4保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D5保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D6保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D7保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D8保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D9保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D10保存至表T2中行键包括字符串s1和字符串“20151015”的行中;……将访问数据D10000保存至表T2中行键包括字符串s2和字符串“20151016”的行中;将访问数据D10001保存至表T2中行键包括字符串s1和字符串“20151016”的行中;将访问数据D10002保存至表T2中行键包括字符串s3和字符串“20151016”的行中;……将访问数据D1000000保存至表T2中行键包括字符串s1和字符串“20151020”的行中。再例如,设置rowkey为:Tomcat标识-日期,如果想查询Tomcat1在2015年10 月15日这一天的访问日志,则查询时设置startKEY为Tomcat1-20151015,endKey为Tomcat1-20151016。如果想查询Tomcat2在2015年11月20日这一天的访问日志,则查询时设置startKEY为Tomcat2-20151120,endKey为Tomcat2-20151121。通过设置rowkey包括服务器标识和日期,在HBase的表中保存访问日志时会将同一个服务器的同一天的访问日志保存在相邻的位置,在该表中查询访问日志时,可以快速查询出某一个服务器在某个日期的访问日志,大大提高了查询效率。表2访问数据编号访问数据来源访问数据产生的时间(访问时间)D1Tomcat22015年10月15日12:00:00D2Tomcat22015年10月15日12:00:00D3Tomcat32015年10月15日12:00:03D4Tomcat12015年10月15日12:00:03D5Tomcat12015年10月15日12:00:03D6Tomcat12015年10月15日12:00:03D7Tomcat32015年10月15日12:00:05D8Tomcat32015年10月15日12:00:05D9Tomcat22015年10月15日12:00:06D10Tomcat12015年10月15日12:00:10………………D10000Tomcat22015年10月16日09:00:15D10001Tomcat12015年10月16日09:00:15D10002Tomcat32015年10月16日09:00:17………………D1000000Tomcat12015年10月20日18:00:17可选地,表的行键还包括预设时间和日志标识,将接收到的多个服务器的访问日志对应保存至表的目标行还包括:获取多个服务器中服务器i的访问日志Li的访问时间ti和访问日志Li的日志标识Ri,其中,i依次取1至m,m为多个服务器中服务器的数量;查找目标行中行键包括标识Zi、预设时间Ti和日志标识Ri的目标行Hi,其中,标识Zi为服务器i的标识,预设时间Ti为访问时间ti所属的预设时间;以及将服务器i的访问日志保存至目标行Hi,根据行键,在表中查询待查询服务器的访问日志还包括:根据待查询服务器的标识,在表中查询待查询服务器的访问日志;或根据待查询服务器的标识和待查询时间,在表中查询待查询服务器的访问日志,其中,待查询时间为表的行键中的任一预设时间。可选地,服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为多条访问数据中访问数据的数量,获取多个服务器中服务器i的访问日志Li的访问时间ti和访问日志Li的日志标识Ri包括:获取访问数据Lij的访问时间tij和访问数据Lij的通用识别唯一码Uij,其中,j依次取1至ni,日志标识为通用识别唯一码Uij,查找目标行中行键包括标识Zi、预设时间Ti和日志标识Ri的目标行Hi包括:查找目标行中行键包括标识Zi、预设时间Tij和通用识别唯一码Uij的目标行Hij,其中,预设时间Tij为访问时间tij所属的预设时间,将服务器i的访问日志保存至目标行Hi包括:将服务器i的访问数据Lij保存至目标行Hij。通用识别唯一码(UniversallyUniqueIdentifier,简称UUID)是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。使用UUID的目的,是让分布式系统中的所有元素,都能有唯一的辨识资讯,而不需要透过中央控制端来做辨识资讯的指定。UUID由以下几部分的组合:(1)当前日期和时间,UUID的第一个部分与时间有关,如果在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。(2)时钟序列。(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。UUID生成的结果串会比较长。关于UUID这个标准使用最普遍的是微软的 GUID(GlobalsUniqueIdentifiers)。在ColdFusion中可以用CreateUUID()函数很简单地生成UUID,其格式为:xxxxxxxx-xxxx-xxxx-xxxxxxxxxxxxxxxx(8-4-4-16),其中每个x是0-9或a-f范围内的一个十六进制的数字。而标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx(8-4-4-4-12),可以从cflib下载CreateGUID()UDF进行转换。使用UUID的好处在分布式的软件系统中(比如:DCE/RPC,COM+,CORBA)就能体现出来,它能保证每个节点所生成的标识都不会重复,并且随着WEB服务等整合技术的发展,UUID的优势将更加明显。根据使用的特定机制,UUID不仅需要保证是彼此不相同的,或者最少也是与公元3400年之前其他任何生成的通用唯一标识符有非常大的区别。访问日志的每条访问数据在生成时,都产生了唯一的UUID,此UUID能够唯一地标识一条访问数据。设置行键包括服务器标识、日期和UUID,在保存访问日志时,能够把每条访问数据都保存到行键包含该访问数据的UUID的行中,在需要查询访问日志时,通过合理地设置startKEY和endKey,既可以快速查询出每个服务器的所有的访问日志,又可以快速查询出每个服务器在指点日期的访问日志,还可以快速查询出每个服务器的指定的某一条访问数据,大大提高了在HBase的表中查询服务器的访问日志的效率。根据本申请实施例,还提供了一种访问日志的查询装置。该访问日志的查询装置可以执行上述访问日志的查询方法,上述访问日志的查询方法也可以通过该访问日志的查询装置实施。图2是根据本申请实施例的访问日志的查询装置的示意图。如图2所示,该装置包括:建立单元22、保存单元24和查询单元26。建立单元22用于在分布式数据库中建立表,其中,表的行键包括服务器的标识,表包括多个行。保存单元24用于将接收到的多个服务器的访问日志对应保存至表的目标行,其中,与目标服务器对应的目标行为行键包括目标服务器的标识的行,目标服务器为多个服务器中的任一服务器,与任一服务器对应的目标行为多个。查询单元26用于根据行键,在表中查询待查询服务器的访问日志。分布式数据库可以为HBase数据库。当需要保存的数据的数据量非常巨大时,使用HBase数据库中的表保存数据是一个非常好的方法。HBase只能用行键rowkey来查找数据。所以rowkey的设计是至关重要的,关系到查询效率的高低。行键rowkey是以字典顺序排序的。例如,有三个行键,分别为rowkey1、rowkey2、rowkey3。rowkey1为aaa222,rowkey2为bbb111,rowkey3为abb111。首先将rowkey1、rowkey2和rowkey3的第一位进行比较,rowkey1和rowkey3的第一位是a,rowkey2的第一位是b,所以rowkey1和rowkey3排在rowkey2前面,再将rowkey1和rowkey3的第二位进行比较,rowkey1的第二位是a,rowkey3的第二位是b,所以rowkey1排在rowkey3前面,综上所述,rowkey1排在rowkey3前面,rowkey3排在rowkey2前面。HBase中用rowkey来查询表中的记录,支持以下三种查询方式:(1)通过单个rowkey访问:即按照某个rowkey键值进行get操作。(2)通过rowkey的范围进行扫描:即通过设置startRowKey(开始行键)和endRowKey(结束行键),在这个范围内进行扫描;(3)全表扫描:即直接扫描整张表中所有行记录。当需要将多个服务器的访问日志保存到HBase的表中时,设计表的行键rowkey为服务器的标识,这样当接收到来自某一个服务器的访问日志时,就可以将该服务器的访问日志保存至行的行键为该服务器的标识的行中。设置HBase的表的列包括:远程主机名(RemoteHosts)、时间戳(TimeStamp)、虚拟主机名(VirtualHost)、查询参数(Query)、用户代理浏览器(UserAgent)、方法名(Method)、单次请求Tomcat内存的变化值等。HBase数据库中的列的数量不用事先指定,可以根据需要随时添加。例如,一共需要在HBase的表T1中保存5个Tomcat的访问日志,这5个Tomcat的标识分别为字符串s1、字符串s2、字符串s3、字符串s4和字符串s5。设计HBase的表T1的行键分别包括字符串s1、字符串s2、字符串s3、字符串s4、字符串s5。假设一共接收到10条访问数据,表1示出了这10条访问数据中每条访问数据的编号和访问数据来自哪个服务器,则将访问数据D2保存至表T1中行键包括字符串s1的行中,将访问数据D6和访问数据D8保存至表T1中行键包括字符串s2的行中,将访问数据D1和访问数据D4保存至表T1中行键包括字符串s3的行中,将访问数据D5保存至表T1中行键包括字符串s4的行中,将访问数据D3、访问数据D7、访问数据D9和访问数据D10保存至表T1中行键包括字符串s5的行中。需要注意的是,由于篇幅所限,本例子给出的数据仅为10条,而在实际应用中,访问日志的访问数据的数量是非常巨大的。查询表T1中行键包括字符串s1的行,得到Tomcat1的全部访问日志;查询表T1中行键包括字符串s2的行,得到Tomcat2的全部访问日志;查询表T1中行键包括字符串s3的行,得到Tomcat3的全部访问日志。通过在建立HBase的表时,使表的行键包括服务器的标识,将服务器的访问日志对应保存至行键包括该服务器的标识的行中,使得同一个服务器的访问日志的访问数据保存在表中相邻的位置,当需要查询某个服务器的访问日志时,按照表的行键进行查询,由于同一个服务器的访问日志的访问数据在表中所处的位置很集中,因此,查询时速度很快,从而实现了快速查询出待查询服务器的访问日志的技术效果,进而解决了现有技术中在HBase中查询某一个或某几个服务器的访问日志耗时较长,查询效率低的技术问题。可选地,表的行键还包括预设时间,保存单元24包括第一获取子单元、第一查找子单元和第一保存子单元。第一获取子单元用于获取多个服务器中服务器i的访问日志Li的访问时间ti,其中,i依次取1至m,m为多个服务器中服务器的数量。第一查找子单元用于查找目标行中行键包括标识Zi和预设时间Ti的目标行Hi,其中,标识Zi为服务器i的标识,预设时间Ti为访问时间ti所属的预设时间。第一保存子单元用于将服务器i的访问日志保存至目标行Hi。查询单元26包括第一查询子单元和第二查询子单元。第一查询子单元用于根据待查询服务器的标识,在表中查询待查询服务器的访问日志。第二查询子单元用于根据待查询服务器的标识和待查询时间,在表中查询待查询服务器的访问日志,其中,待查询时间为表的行键中的任一预设时间。可选地,服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为多条访问数据中访问数据的数量,第一获取子单元包括第一获取模块。第一获取模块用于获取访问数据Lij的访问时间tij,其中,j依次取1至ni。第一查找子单元包括第一查找模块。第一查找模块,用于查找目标行中行键包括标识Zi和预设时间Tij的目标行Hij,其中,预设时间Tij为访问时间tij所属的预设时间。第一保存子单元包括第一保存模块。第一保存模块,用于将服务器i的访问数据Lij保存至目标行Hij。每个服务器的访问日志都包括至少一条访问数据,在大多数情况下,每个服务器的访问日志都包括大量的访问数据。服务器1的访问日志包括n1条访问数据,分别为访问数据L11、访问数据L12、访问数据L13、……、访问数据服务器2的访问日志包括n2条访问数据,分别为访问数据L21、访问数据L22、访问数据L23、……、访问数据以此类推,服务器i的访问日志包括ni条访问数据,分别为访问数据Li1、访问数据Li2、访问数据Li3、……、访问数据访问数据Lij的访问时间为tij,tij精确到秒。预设时间Tij为访问时间tij所在的那一天,预设时间Tij精确到天。例如,当访问时间为2015年11月10日08:20:30,则访问时间所属的预设时间为2015年11月10日。再例如,当访问时间为2015年10月25日15:25:58,则访问时间所属的预设时间为2015年10月25日。例如,建立HBase的表T2,设置表T2的行键包括服务器的标识和日期,例如,假设一共有3个Tomcat服务器,这3个Tomcat服务器的标识分别为字符串s1、字符串s2、字符串s3,设置表T2的行键包括字符串s1和日期,或包括字符串s2和日期,或包括字符串s3和日期。假设HBase一共接收到1百万条访问数据,表2示出了这1百万条访问数据中每条访问数据的编号、访问数据来源于哪个服务器和访问数据产生的时间。将访问数据D1保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D2保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D3保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D4保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D5保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D6保存至表T2中行键包括字符串s1和字符串“20151015”的行中;将访问数据D7保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D8保存至表T2中行键包括字符串s3和字符串“20151015”的行中;将访问数据D9保存至表T2中行键包括字符串s2和字符串“20151015”的行中;将访问数据D10保存至表T2中行键包括字符串s1和字符串“20151015”的行中;……将访问数据D10000保存至表T2中行键包括字符串s2和字符串“20151016”的行中;将访问数据D10001保存至表T2中行键包括字符串s1和字符串“20151016”的行中;将访问数据D10002保存至表T2中行键包括字符串s3和字符串“20151016”的行中;……将访问数据D1000000保存至表T2中行键包括字符串s1和字符串“20151020”的行中。再例如,设置rowkey为:Tomcat标识-日期,如果想查询Tomcat1在2015年10月15日这一天的访问日志,则查询时设置startKEY为Tomcat1-20151015,endKey为Tomcat1-20151016。如果想查询Tomcat2在2015年11月20日这一天的访问日志,则查询时设置startKEY为Tomcat2-20151120,endKey为Tomcat2-20151121。通过设置rowkey包括服务器标识和日期,在HBase的表中保存访问日志时会将同一个服务器的同一天的访问日志保存在相邻的位置,在该表中查询访问日志时,可以快速查询出某一个服务器在某个日期的访问日志,大大提高了查询效率。可选地,表的行键还包括预设时间和日志标识,保存单元24还包括第二获取子单元、第二查找子单元和第二保存子单元。第二获取子单元用于获取多个服务器中服务器i的访问日志Li的访问时间ti和访问日志Li的日志标识Ri,其中,i依次取1至m,m为多个服务器中服务器的数量。第二查找子单元用于查找目标行中行键包括标识Zi、预设时间Ti和日志标识Ri的目标行Hi,其中,标识Zi为服务器i的标识,预设时间Ti为访问时间ti所属的预设时间。第二保存子单元用于将服务器i的访问日志保存至目标行Hi。查询单元26还包括第三查询子单元和第四查询子单元。第三查询子单元用于根据待查询服务器的标识,在表中查询待查询服务器的访问日志。第四查询子单元 用于根据待查询服务器的标识和待查询时间,在表中查询待查询服务器的访问日志,其中,待查询时间为表的行键中的任一预设时间。可选地,服务器i的访问日志包括由访问数据Li1至访问数据组成的多条访问数据,其中,ni为多条访问数据中访问数据的数量。第二获取子单元包括第二获取模块。第二获取模块用于获取访问数据Lij的访问时间tij和访问数据Lij的通用识别唯一码Uij,其中,j依次取1至ni,日志标识为通用识别唯一码Uij。第二查找子单元包括第二查找模块。第二查找模块用于查找目标行中行键包括标识Zi、预设时间Tij和通用识别唯一码Uij的目标行Hij,其中,预设时间Tij为访问时间tij所属的预设时间。第二保存子单元包括第二保存模块。第二保存模块用于将服务器i的访问数据Lij保存至目标行Hij。通用识别唯一码(UniversallyUniqueIdentifier,简称UUID)是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。使用UUID的目的,是让分布式系统中的所有元素,都能有唯一的辨识资讯,而不需要透过中央控制端来做辨识资讯的指定。UUID由以下几部分的组合:(1)当前日期和时间,UUID的第一个部分与时间有关,如果在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。(2)时钟序列。(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。UUID生成的结果串会比较长。关于UUID这个标准使用最普遍的是微软的GUID(GlobalsUniqueIdentifiers)。在ColdFusion中可以用CreateUUID()函数很简单地生成UUID,其格式为:xxxxxxxx-xxxx-xxxx-xxxxxxxxxxxxxxxx(8-4-4-16),其中每个x是0-9或a-f范围内的一个十六进制的数字。而标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx(8-4-4-4-12),可以从cflib下载CreateGUID()UDF进行转换。使用UUID的好处在分布式的软件系统中(比如:DCE/RPC,COM+,CORBA)就能体现出来,它能保证每个节点所生成的标识都不会重复,并且随着WEB服务等整合技术的发展,UUID的优势将更加明显。根据使用的特定机制,UUID不仅需要保证是彼此不 相同的,或者最少也是与公元3400年之前其他任何生成的通用唯一标识符有非常大的区别。访问日志的每条访问数据在生成时,都产生了唯一的UUID,此UUID能够唯一地标识一条访问数据。设置行键包括服务器标识、日期和UUID,在保存访问日志时,能够把每条访问数据都保存到行键包含该访问数据的UUID的行中,在需要查询访问日志时,通过合理地设置startKEY和endKey,既可以快速查询出每个服务器的所有的访问日志,又可以快速查询出每个服务器在指点日期的访问日志,还可以快速查询出每个服务器的指定的某一条访问数据,大大提高了在HBase的表中查询服务器的访问日志的效率。所述访问日志的查询装置包括处理器和存储器,上述建立单元22、保存单元24和查询单元26等均作为程序单元存储在存储器中,由处理器执行存储在存储器中的上述程序单元来实现相应的功能。处理器中包含内核,由内核去存储器中调取相应的程序单元。内核可以设置一个或以上,通过调整内核参数来快速高效地在HBase的表中查询服务器的访问日志。存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(RAM)和/或非易失性内存等形式,如只读存储器(ROM)或闪存(flashRAM),存储器包括至少一个存储芯片。本申请还提供了一种计算机程序产品,当在数据处理设备上执行时,适于执行初始化有如下方法步骤的程序代码:在分布式数据库中建立表,其中,表的行键包括服务器的标识,表包括多个行,将接收到的多个服务器的访问日志对应保存至表的目标行,其中,与目标服务器对应的目标行为行键包括目标服务器的标识的行,目标服务器为多个服务器中的任一服务器,与任一服务器对应的目标行为多个,根据行键,在表中查询待查询服务器的访问日志。上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。在本申请的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模 块的间接耦合或通信连接,可以是电性或其它的形式。所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、只读存储器(ROM,Read-OnlyMemory)、随机存取存储器(RAM,RandomAccessMemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。以上所述仅是本申请的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1