一种面向业务的数据计算方法及装置与流程
本发明涉及云计算技术领域,特别涉及一种面向业务的数据计算方法及装置。
背景技术:
对于游戏厂商来说,用户操作游戏系统的行为以及游戏运行时,在游戏厂商的服务器上产生大量的数据。在用户操作游戏系统时,因网络中断等其他因素导致系统无法正常的运行,游戏运营人员需要及时发现问题。另外,在推广新游戏时,基于游戏厂商的服务器上的数据进行玩家消费行为分析、玩家数量分析等多种类型的数据计算,则需要从游戏厂商服务器处请求适于进行不同数据分析任务的数据,会对游戏厂商服务器来说会造成很大的压力,甚至会有可能会影响游戏厂商服务器上游戏程序的运行。
在游戏业务领域,经常需要对大量的业务数据进行分析,由于待分析的数据量通常较大,所以如何使得数据分析的效率得到提高就成为重要的课题。
技术实现要素:
本发明实施例的主要目的在于提出一种面向业务的数据计算方法及装置,利用计算结果对业务服务器上的数据进行分析,提供工作效率,以克服上述问题。
为实现上述目的,本发明提供了一种面向业务的数据计算方法,包括:
收集用户数据和业务数据;
对用户数据和业务数据进行消重处理;
对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。
在一实施例中,用户数据通过异步传输方式传输至分布式面向列的存储系统。
在一实施例中,业务数据按照系统日志协议传输至分布式面向列的存储系统。
在一实施例中,对用户数据和业务数据采用布隆过滤器进行消重处理。
在一实施例中,实时计算的步骤具体为:
对消重处理后的数据按照storm框架进行实时计算,获得报表数据,报表数据存储至分布式文档存储数据库。
在一实施例中,离线计算的步骤具体为:
通过日志收集器将消重处理后的数据中无结构化数据以文件形式存储至Hadoop分布式文件系统,通过日志收集系统将消重处理后的数据中结构化数据和半结构化数据存储至分布式面向列的存储系统;
基于Hadoop平台提供的编程接口,对Hadoop分布式文件系统和分布式面向列的存储系统各自存储的数据进行加载、抽取、转换处理,获得面向业务的集成数据。
在一实施例中,面向业务的集成数据包括:业务维度统计汇总和渠道维度统计汇总。
在一实施例中,报表数据包括:用户行为跟踪数据和用户标签;其中,用户行为跟踪数据包括网页行为和游戏系统行为。
在一实施例中,本方法获得了报表数据和游戏业务的集成数据,其中,利用报表数据及时发现游戏系统中的问题,利用游戏业务的集成数据决策后续游戏运营策略。
对应地,为解决现有技术的问题,本发明还提出了一种面向业务的数据计算装置,包括:
收集数据单元,用于收集用户数据和业务数据;
消重单元,用于对用户数据和业务数据进行消重处理;
计算单元,用于对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得游戏业务的集成数据。
进一步地,收集数据单元将游戏用户数据通过异步传输方式传输至分布式面向列的存储系统。
进一步地,收集数据单元将业务数据按照系统日志协议传输至分布式面向列的存储系统。
进一步地,消重单元对游戏用户数据和业务数据采用布隆过滤器进行消重处理。
进一步地,计算单元包括实时计算模块;其中,实时计算模块,用于对消重处理后的数据按照storm框架进行实时计算,获得报表数据,报表数据存储至分布式文档存储数据库。
进一步地,计算单元包括离线计算模块,离线计算模块包括存储子模块和计算子模块;其中,
存储子模块,用于通过日志收集器将消重处理后的数据中无结构化数据以文件形式存储至Hadoop分布式文件系统,通过日志收集系统将消重处理后的数据中结构化数据和半 结构化数据存储至分布式面向列的存储系统;
计算子模块,用于基于Hadoop平台提供的编程接口,对Hadoop分布式文件系统和分布式面向列的存储系统各自存储的数据进行加载、抽取、转换处理,获得面向业务的集成数据。
进一步地,本发明提出的一种面向业务的数据计算装置还包括:第一应用单元;其中,第一应用单元,用于利用报表数据及时发现业务系统中的问题。
进一步地,本发明提出的一种面向业务的数据计算装置还包括:第二应用单元;其中,第二应用单元,用于利用面向业务的集成数据决策后续业务运营策略。
上述技术方案具有如下有益效果:
本技术方案收集用户数据和业务数据,不同的数据采用不同的传输方式,提高收集数据的效率,接着对收集的数据进行消重处理,将错误的、无效的、重复的数据滤除掉,为后续数据的计算打下基础。
对消重处理后的数据进行实时计算,获得报表数据;由于实时计算基于storm框架进行,能够获得精度很高的报表数据,及时发现问题,运营人员根据异常的实时数据,快速查找有问题的地方,使得问题及时解决,提高用户的体验度。
进一步地,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。利用集成数据进行运营决策,节省推广费用的基础上提高业务的推广效率。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示出了一种面向业务的数据计算方法流程图;
图2示出了一种面向业务的数据计算装置框图;
图3示出了计算装置中计算单元的功能方框图;
图4示出了本实施例的系统框架图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供了一种面向业务的数据计算方法及装置。以下结合附图对本发明进行详细说明。
本发明实施例提供了一种面向业务的数据计算方法,如图1所示。面向游戏业务的数据计算方法包括:
步骤S101:收集用户数据和业务数据;
步骤S102:对用户数据和业务数据进行消重处理;
步骤S103:对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。
在步骤S101中,用户数据通过异步传输方式传输至分布式面向列的存储系统。业务数据按照系统日志协议传输至分布式面向列的存储系统。提高收集数据的效率,接着对收集的数据进行消重处理,将错误的、无效的、重复的数据滤除掉,为后续数据的计算打下基础,从而能够获得精度很高的报表数据和面向业务的集成数据,利用报表数据,及时发现问题,运营人员根据异常的实时数据,快速查找有问题的地方,使得问题及时解决,提高用户的体验度。同时,利用集成数据进行运营决策,节省推广费用的基础上提高业务的推广效率。
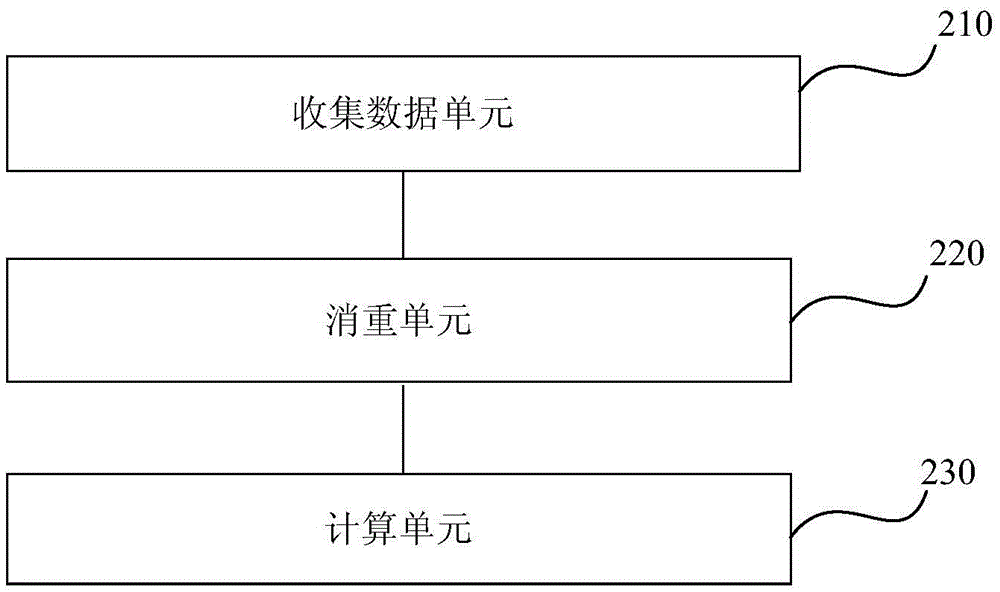
如图2所示,为本发明提出的一种面向业务的数据计算装置框图。该装置包括:
收集数据单元210,用于收集用户数据和业务数据;
对于收集数据单元210来说,用户数据通过异步传输方式传输至分布式面向列的存储系统。业务数据按照系统日志协议传输至分布式面向列的存储系统。
消重单元220,用于对用户数据和业务数据进行消重处理;
对于消重单元220来说,对分布式面向列的存储系统中缓存的数据进行消重处理。在本实施例中,对用户数据和业务数据采用布隆过滤器进行消重处理。布隆过滤器实际上是 一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法。为后面实时计算打下基础。
计算单元230,用于对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。
如图3所示,为本实施例计算装置中计算单元的功能方框图。其中,计算单元230包括实时计算模块231和离线计算模块232;其中,实时计算模块231用于对消重处理后的数据按照storm框架进行实时计算,获得报表数据,报表数据存储至分布式文档存储数据库。进一步地,离线计算模块232包括存储子模块和计算子模块;其中,存储子模块,用于通过日志收集器将消重处理后的数据中无结构化数据以文件形式存储至Hadoop分布式文件系统,通过日志收集系统将消重处理后的数据中结构化数据和半结构化数据存储至分布式面向列的存储系统;计算子模块,用于基于Hadoop平台提供的编程接口,对Hadoop分布式文件系统和分布式面向列的存储系统各自存储的数据进行加载、抽取、转换处理,获得面向业务的集成数据。
如图4所示,为本实施例的系统框架图。在本实施例中,业务类型为游戏。需要注意的是,上述业务类型仅是为了便于理解本发明的精神和原理而示出,本发明的实施方式在此方面不受任何限制。相反,本发明的实施方式可以应用于适用的任何业务。数据目标为:用户行为数据、用户标签数据、游戏维度统计汇总和渠道维度统计汇总。其中,用户行为数据包括网页行为和系统行为。
从系统框架图中可知,数据源包括游戏厂商数据源和游戏公司网页数据源。其中,游戏厂商数据源以系统日志协议的形式生成syslog数据。通过日志收集系统fluentd传送至缓存区。游戏公司网页数据源包括用户的网页点击行为数据和网页特效数据。这些数据以分布式消息队列qbus传送至缓存区。该缓存区为分布式面向列的存储系统。
对分布式面向列的存储系统中的数据检查,本实施例采用布隆过滤器进行消重处理。该技术方案的优点是空间效率和查询时间都远远超过一般的算法。
在实时计算方面,对消重处理后的数据按照storm框架进行实时计算,获得报表数据,报表数据存储至分布式文档存储数据库(mongoDB)。在storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。这个拓扑将会被提交给集群,由集群中的主控节点(master node)分发代码,将任务分配给工作节点(worker node)执行。一个拓 扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。由spout发射出的tuple是不可变数组,对应着固定的键值对。storm框架适用于分布式实时计算,具有实时性比较高的特点。且该框架的容错性比较好,能够获得精确性比较高的报表数据,报表数据包括:用户行为跟踪数据和用户标签;其中,用户行为跟踪数据包括网页行为和游戏系统行为。利用报表数据能够及时发现游戏系统中的问题。比如:在付款购买游戏币时,支付操作完毕,后台服务器也获得了支付操作指令,准备反馈支付成功信息时,网络中断,导致用户获得的反馈信息为“操作失败”。实际上,用户已经支付成功。这种情况下,本技术方案就很快发现异常的实时数据,就能够快速查找有问题的游戏区服,第一时间联系厂商。
在离线计算方面,日志收集器(scribe)从分布式面向列的存储系统中获得无结构化数据,以文件形式存储至Hadoop分布式文件系统(Hdfs)。日志收集系统(fluentd)从分布式面向列的存储系统中获得结构化和半结构化数据,将这些数据存储至一个高可靠性、高性能、面向列、可伸缩的分布式存储系统(Hbase)。以数据仓Hive提供编程接口,从Hadoop分布式文件系统(Hdfs)和分布式存储系统(Hbase)中获得的数据经过抽取(extract)、转换(transform)、加载(load)处理,获得游戏业务的集成数据,集成数据为游戏业务的历史数据的统计,包括游戏维度统计汇总和渠道维度统计汇总。通过游戏业务的集成数据,能够获得游戏的运营情况,根据运营情况,决定后续游戏运营策略。比如:在渠道维度统计汇总中,渠道人员实时获知渠道导量数据,利用该数据,渠道人员定时定向导量,节省推广费用。
由上述实施例可知,本技术方案将来可作为大数据实时游戏监控统计平台和精准营销推广平台使用。
本发明的实施例公开了:
A1、一种面向业务的数据计算方法,其特征在于,包括:
收集用户数据和业务数据;
对所述用户数据和业务数据进行消重处理;
对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。
A2、如权利要求A1所述的方法,其特征在于,所述用户数据通过异步传输方式传输至分布式面向列的存储系统。
A3、如权利要求A1所述的方法,其特征在于,所述业务数据按照系统日志协议传输至分布式面向列的存储系统。
A4、如权利要求A1所述的方法,其特征在于,对所述用户数据和业务数据采用布隆过滤器进行消重处理。
A5、如权利要求A1所述的方法,其特征在于,所述实时计算的步骤具体为:
对消重处理后的数据按照storm框架进行实时计算,获得报表数据,所述报表数据存储至分布式文档存储数据库。
A6、如权利要求A1所述的方法,其特征在于,所述离线计算的步骤具体为:
通过日志收集器将消重处理后的数据中无结构化数据以文件形式存储至Hadoop分布式文件系统,通过日志收集系统将消重处理后的数据中结构化数据和半结构化数据存储至分布式面向列的存储系统;
基于Hadoop平台提供的编程接口,对Hadoop分布式文件系统和分布式面向列的存储系统各自存储的数据进行加载、抽取、转换处理,获得面向业务的集成数据。
A7、如权利要求A1~A6任一权利要求所述的方法,其特征在于,所述面向业务的集成数据包括:业务维度统计汇总和渠道维度统计汇总。
A8、如权利要求A1~A6任一权利要求所述的方法,其特征在于,所述报表数据包括:用户行为跟踪数据和用户标签;其中,所述用户行为跟踪数据包括网页行为和业务系统行为。
A9、如权利要求A1~A6任一权利要求所述的方法,其特征在于,还包括:
利用所述报表数据及时发现业务系统中的问题。
A10、如权利要求A1~A6任一权利要求所述的方法,其特征在于,还包括:
利用所述面向业务的集成数据决策后续业务运营策略。
B11、一种面向业务的数据计算装置,其特征在于,包括:
收集数据单元,用于收集用户数据和业务数据;
消重单元,用于对所述用户数据和业务数据进行消重处理;
计算单元,用于对消重处理后的数据进行实时计算,获得报表数据;同时,对消重处理后的数据进行存储,达到规定数据量后,对存储的数据进行离线计算,获得面向业务的集成数据。
B12、如权利要求B11所述的装置,其特征在于,所述收集数据单元将所述用户数据通过异步传输方式传输至分布式面向列的存储系统。
B13、如权利要求B11所述的装置,其特征在于,所述收集数据单元将所述业务数据按照系统日志协议传输至分布式面向列的存储系统。
B14、如权利要求B11所述的装置,其特征在于,所述消重单元对所述用户数据和业务数据采用布隆过滤器进行消重处理。
B15、如权利要求B11所述的装置,其特征在于,所述计算单元包括实时计算模块;其中,所述实时计算模块,用于对消重处理后的数据按照storm框架进行实时计算,获得报表数据,所述报表数据存储至分布式文档存储数据库。
B16、如权利要求B11所述的装置,其特征在于,所述计算单元包括离线计算模块,所述离线计算模块包括存储子模块和计算子模块;其中,
所述存储子模块,用于通过日志收集器将消重处理后的数据中无结构化数据以文件形式存储至Hadoop分布式文件系统,通过日志收集系统将消重处理后的数据中结构化数据和半结构化数据存储至分布式面向列的存储系统;
所述计算子模块,用于基于Hadoop平台提供的编程接口,对Hadoop分布式文件系统和分布式面向列的存储系统各自存储的数据进行加载、抽取、转换处理,获得面向业务的集成数据。
B17、如权利要求B11~B16任一权利要求所述的装置,其特征在于,还包括:第一应用单元;其中,
所述第一应用单元,用于利用所述报表数据及时发现业务系统中的问题。
B18、如权利要求B11~B16任一权利要求所述的装置,其特征在于,还包括:第二应用单元;其中,
所述第二应用单元,用于利用所述面向业务的集成数据决策后续业务运营策略。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读取存储介质中,比如ROM/RAM、磁碟、光盘等。
以上具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!