意图估计装置以及意图估计方法与流程
本发明涉及意图估计装置以及意图估计方法,它们用于对利用语音、键盘等输入的文本进行识别,估计使用者的意图,并执行使用者所期望的操作。
背景技术:
近年来,已知有对人的自由讲话进行识别并使用其识别结果来执行机械等的操作的技术。该技术被用作便携电话或导航装置等的语音界面,对输入语音的识别结果的意图进行估计,通过使用意图估计模型,能够应对使用者的各式各样的表达方式,其中,所述意图估计模型是根据各式各样的句子示例和对应的意图使用统计的方法进行训练而得到的。
这样的技术在讲话内容所包含的意图为一个的情况下是有效的。然而,在由讲话者输入复句那样的包含多个意图的讲话的情况下,难以正确地估计出多个意图。例如,在“東京タワーも寄りたいが、先にスカイツリーへ寄って。(想去东京塔,但请先去天空树)。”这样的讲话中,具有将作为设施的东京塔设定为经由地的意图以及将作为设施的天空树设定为经由地这两个意图,使用上述的意图估计模型难以估计出这两个意图。
针对这样的问题,例如,在专利文献1中,提出有如下的方法:对于包含多个意图的讲话,通过利用意图估计和复句分割概率来估计输入文本的恰当的分割点位置。
在先技术文献
专利文献
专利文献1:日本特开2000-200273号公报
技术实现要素:
发明要解决的课题
然而,在专利文献1的技术中,只是直接输出利用分割点估计多个意图而得到的结果,存在无法估计到与估计出的多个意图对应的机械命令的执行顺序从而无法准确地估计用户意图的课题。
本发明是为了解决上述课题而完成的,其目的在于提供能够正确地估计用户意图的意图估计装置以及意图估计方法。
用于解决课题的手段
本发明的意图估计装置的特征在于具有:词素解析部,其对包含多个意图的复句进行词素解析;语法解析部,其对由词素解析部进行了词素解析后的复句进行语法解析而分割为第1单句和第2单句;意图估计部,其对第1单句所包含的第1意图和第2单句所包含的第2意图进行估计;特征量提取部,其提取第1单句所包含的示出操作的执行顺序的词素作为第1特征量,并提取第2单句所包含的示出操作的执行顺序的词素作为第2特征量;以及执行顺序估计部,其根据由特征量提取部提取出的第1特征量和第2特征量来估计与第1意图对应的第1操作和与第2意图对应的第2操作的执行顺序。
此外,本发明的意图估计方法的特征在于包括:对包含多个意图的复句进行词素解析的步骤;对进行了词素解析后的复句进行语法解析而分割为多个单句的步骤;估计多个单句各自包含的意图的步骤;提取多个单句各自包含的、示出操作的执行顺序的词素作为特征量的步骤;以及根据多个单句各自包含的特征量来估计与多个单句各自包含的意图对应的各操作的执行顺序的步骤。
发明效果
根据本发明的意图估计装置以及意图估计方法,根据从单句中提取出的特征量来估计与意图对应的操作的执行顺序,因此,能够准确地估计用户的意图。
附图说明
图1是示出实施方式1的意图估计装置1的结构例的图。
图2是示出实施方式1的意图估计模型的一例的图。
图3是示出实施方式1的特征量提取规则的一例的图。
图4示出实施方式1的执行顺序的种类的一例。
图5是示出实施方式1的执行顺序估计模型的一例的图。
图6是示出实施方式1的意图估计装置1的硬件结构例的图。
图7是示出用于说明实施方式1的执行顺序估计模型的生成处理的意图估计装置1的结构例的图。
图8是示出实施方式1的训练用数据的示例的图。
图9是用于说明实施方式1的执行顺序估计模型的生成处理的流程图。
图10是示出实施方式1的对话例的图。
图11是用于说明实施方式1的意图估计处理的流程图。
图12是示出实施方式1的各执行顺序的各特征量的评分的图。
图13是示出实施方式1的求评分之积的计算式的图。
图14是示出实施方式1的对各执行顺序的最终评分的图。
图15是示出实施方式2的意图估计装置1b的结构例的图。
图16是示出实施方式2的执行顺序估计模型的一例的图。
图17是示出用于说明实施方式2的执行顺序估计模型的生成处理的意图估计装置1b的结构例的图。
图18是用于说明实施方式2的执行顺序估计模型的生成处理的流程图。
图19是示出实施方式2的对话例的图。
图20是用于说明实施方式2的意图估计处理的流程图。
图21是示出实施方式2的对各执行顺序的最终评分的图。
具体实施方式
实施方式1.
下面,利用附图对本发明的实施方式1进行说明。
图1是示出实施方式1的意图估计装置1的结构例的图。意图估计装置1具有语音输入部101、语音识别部102、词素解析部103、语法(syntactic)解析部104、意图估计模型存储部105、意图估计部106、特征量提取规则存储部(特征量提取条件存储部)107、特征量提取部108、执行顺序估计模型存储部(执行顺序估计信息存储部)109、执行顺序估计部(执行顺序决定部)110、命令执行部(操作执行部)111、应答生成部112以及通知部113。
语音输入部101受理语音的输入。
语音识别部102针对与输入语音输入部101的语音输入对应的语音数据进行语音识别,在此基础上将其转换为文本数据,并输出给词素解析部103。在以下的说明中,设文本数据为包含多个意图的复句。复句由多个单句构成,一个单句中包含一个意图。
词素解析部103针对由语音识别部102转换得到的文本数据进行词素解析,并将该词素解析的结果输出给语法解析部104。这里,词素解析是指,将文本划分成词素(语言中具有含义的最小单位)、并利用辞典来识别词类的自然语言处理技术。例如,对于“東京タワーへ行く(去东京塔)”这样的单句,划分成“東京タワー(东京塔)/专有名词、へ/格助词、行く(去)/动词”这样的词素。另外,词素也可以表述为独立词(independentword)、属性。
语法解析部104针对由词素解析部103进行词素解析后的文本数据,根据语法规则对文章的结构以句子或短语为单位进行解析(语法解析)。在与文本数据对应的文本是包含多个意图的复句的情况下,语法解析部103将其分割为多个单句,并将各单句的词素解析结果输出给意图估计部106和特征量提取部108。作为语法解析方法,例如可以使用cyk(cocke–younger–kasami,cyk算法)法等。
另外,在这里的说明中,设文本(复句)包含单句1和单句2这两个单句进行说明,但不限于此,也可以由三个以上的单句构成。另外,语法解析部103无需将与分割得到的全部单句对应的数据输出给意图估计部106和特征量提取部108,例如,即使在所输入的文本(复句)中包含有单句1、单句2及单句3的情况下,也可以仅将单句1和单句2作为输出对象。
意图估计模型存储部105存储用于进行以词素作为特征进行意图估计的意图估计模型。意图可以用“<主意图>[<插槽(slot)名>=<插槽值>、…]”这样的形式来表述。这里,主意图表示意图的分类或功能。在导航装置的示例中,主意图与用户最初操作的上位层的机械命令(目的地设定、听音乐等)对应。插槽名和插槽值表示为了执行主意图所需的信息。例如,“目的地を東京タワーに設定する(将目的地设定为东京塔)”这一单句所包含的意图可以表示为“<目的地设定>[<设施>=<东京塔>]”,“目的地を設定したい(想设定目的地)”这一单句所包含的意图可以表述为“<目的地设定>[<设施>=<null(空)>]”。在该情况下,虽然要设定目的地,但还未确定具体的设施名称。
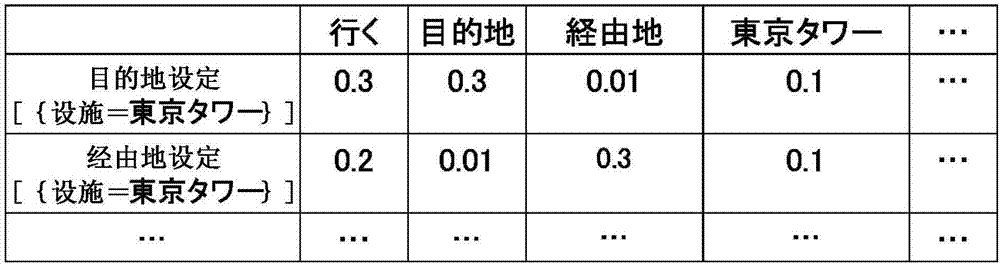
图2是示出实施方式1的意图估计模型的一例的图。如图2所示,意图估计模型表示对“目的地设定[{设施=東京タワー(东京塔)}]”、“经由地设定[{设施=東京タワー(东京塔)}]”等意图的各词素的评分。如图2所示,对于词素“行く”(去)和“目的地”,期望进行目的地设定的可能性较大,因此,意图“目的地设定[{设施=東京タワー(东京塔)}]”的评分变高。另一方面,对于词素“経由地(经由地)”,期望进行经由地设定的可能性较大,因此,意图“经由地设定[{设施=東京タワー(东京塔)}]”的评分变高。
意图估计部106根据从语法解析部104输入的多个单句的词素解析结果,使用意图估计模型分别估计多个单句中包含的意图,并将估计结果输出给命令执行部111。这里,作为意图估计方式,例如可以采用最大熵法。即,意图估计部106利用统计方法,从大量收集到的词素和意图的组中估计与所输入的词素对应的意图是怎样程度地相似。
特征量提取规则存储部107存储如下的特征量提取规则(特征量提取条件):该特征量提取规则是用于估计执行顺序,用于将存在于单句中的词素作为特征量进行提取的规则。
图3是示出实施方式1的特征量提取规则的一例的图。如图3所示,特征量提取规则与出现位置条件和词类条件相对应。出现位置条件意味着词素在单句中的出现位置(句子开头、句子结尾等),词类条件意味着存在于该出现位置的词素的词类。在图3中,如果单句中的句子开头出现的词素的词类是时间名词和格助词,则将该词素作为特征量进行提取。此外,如果单句中的句子结尾出现的词素的词类是接续助词,则将该词素作为特征量进行提取。
特征量提取部108根据从语法解析部104输入的多个单句的词素解析结果,使用特征量提取规则,将各单句中包含的示出操作的执行顺序的词素作为特征量进行提取。即,特征量提取部108根据多个单句中的词素的位置和词素的词类,提取各个特征量。例如,对于“先に東京タワーへ行く(先去东京塔)”这样的单句,由词素解析部103如“先に(先)/时间名词+格助词、東京タワー(东京塔)/专有名词、へ/格助词、行く(去)/动词”这样进行词素解析。其中,“先に”这一词素由时间名词和格助词构成,因此,特征量提取部108依照图3所示的特征量提取规则,将作为词素的“先に”作为特征量进行提取。然后,特征量提取部108将提取出的特征量输出给执行顺序估计部110。
执行顺序估计模型存储部109存储如下的执行顺序估计模型(执行顺序估计信息),该执行顺序估计模型用于估计文本中包含的多个单句的执行顺序。
图4示出实施方式1的执行顺序的种类的一例。如图4所示,多个单句的执行顺序意味着,以哪个顺序来执行与各单句的意图对应的操作。例如,在文本中包含有单句1和单句2的情况下,执行顺序的种类(类别)被分为:是先执行单句1(单句1优先:编号1)、还是先执行单句2(单句2优先:编号2)、还是同时执行单句1和单句2(同时执行:编号3)、还是仅执行单句1(仅执行单句1:编号4)、还是仅执行单句2(仅执行单句2:编号5)。
图5是示出实施方式1的执行顺序估计模型的一例的图。如图5所示,执行顺序估计模型表示将与多个单句各自的意图对应的操作的执行顺序的类别与多个单句中分别包含的特征量的评分对应起来得到的信息(执行顺序信息)。例如,当单句1中存在特征量“ので(由于)”时,“单句1优先”的评分为0.07,“单句2优先”的评分为0.25,同时执行的评分为0.03,仅执行单句1的评分为0.05,仅执行单句2的评分为0.6。关于给出该评分的方法,可以由软件根据特征量的内容计算出,也可以由用户来任意设定。如上述示例那样,当单句1中存在特征量“ので”时,执行与单句1连接的单句2所包含的意图的可能性较大,根据这样的情况,仅执行单句2的评分第一高,单句2优先的评分第二高。此外,当单句2中存在特征量“て”时,“单句1优先”的评分为0.2,单句2优先的评分为0.2,同时执行的评分为0.2,仅执行单句1的评分为0.2,仅执行单句2的评分为0.2。关于图5所示的其它特征量“先に(先)”、“だけど(但是)”、“やっぱり((尽管)……还是)”、“まず(首先)”也同样地给出评分。
执行顺序估计部110根据由特征量提取部108提取出的各单句中的特征量来估计与多个单句所包含的各意图对应的操作的执行顺序,并将估计的结果输出给命令执行部111。例如,“東京タワーも寄りたいが、先にスカイツリーへ寄って。(也想去东京塔,但请先去天空树。)”这样的文本被输入时,通过使用单句1“東京タワーも寄りたいが(也想去东京塔)”的特征量和单句2“先にスカイツリーへ寄って(请先去天空树)”的特征量,估计出单句2优先的执行顺序。对执行顺序的估计算法的详细情况,在后面进行叙述。
命令执行部111根据由意图估计部106估计出的多个单句中包含的各个意图和由执行顺序估计部110估计出的操作的执行顺序,执行与多个单句中分别包含的意图对应的机械命令(操作)。例如,在“東京タワーも寄りたいが、先にスカイツリーへ寄って。(也想去东京塔,但请先去天空树。)”这样的文本被输入时,从意图估计部106输入“<经由地设定>[<设施>=<東京タワー(东京塔)>]”作为单句1的意图,并输入“<经由地设定>[<设施>=<スカイツリー(天空树)>]”作为单句2的意图。此外,从执行顺序估计部110输入单句2优先的执行顺序。然后,命令执行部111执行与单句2的意图对应的机械命令(天空树的经由地设定操作)之后,再执行与单句1的意图对应的机械命令(东京塔的经由地设定操作)。
应答生成部112生成与由命令执行部111执行的机械命令对应的应答。关于应答,可以以文本数据的形式生成,也可以生成合成语音作为语音数据。在生成语音数据的情况下,例如可以是“スカイツリーを経由地に設定します。東京タワーを経由地に設定します。(将天空树设定为经由地。将东京塔设定为经由地。)”这样的合成语音。
通知部113将由应答生成部112生成的应答通知给驾驶员等使用者。即,通知部113将已由命令执行部111执行了多个机械命令的情况通知给用户。另外,关于通知的方式,只要是通过显示进行的通知、通过语音进行的通知或通过振动进行的通知等能够使使用者认识到通知的方式即可,可以是任意的方式。
接下来,对意图估计装置1的硬件结构进行说明。
图6是示出实施方式1的意图估计装置1的硬件结构例的图。意图估计装置1构成为由cpu(centralprocessingunit,中央处理器)等处理装置(processor,处理器)150、rom(readonlymemory,只读存储器)、硬盘装置等存储装置(memory,存储器)160、键盘、麦克风等输入装置170以及扬声器、显示器等输出装置180进行总线连接而成的结构。另外,cpu也可以自身具备存储器。
图1所示的语音输入部101通过输入装置170来实现,通知部113通过输出装置180来实现。
存储于意图估计模型存储部105、特征量提取规则存储部107、执行顺序估计模型存储部109、后述的训练用数据存储部114中的数据等分别被存储在存储装置160中。此外,语音识别部102、词素解析部103、语法解析部104、意图估计部106、特征量提取部108、执行顺序估计部110、命令执行部111、应答生成部112以及后述的执行顺序估计模型生成部115等“~部”也作为程序存储在存储装置160中。
通过由处理装置150适当读出并执行存储在存储装置160中的程序来实现上述“~部”的功能。即,通过将处理装置150即硬件和上述程序即软件进行组合来实现上述“~部”的功能。此外,在图6的示例中,构成为由一个处理装置150来实现功能的结构,但是,例如也可以通过由位于外部的服务器内的处理装置来承担一部分功能等方式,使用多个处理装置来实现功能。因此,作为处理装置150的“处理器”不仅仅是一个处理装置,还包含多个处理装置的概念。另外,这些“~部”的功能不限于硬件和软件的组合,也可以是,使处理装置150履行上述程序,如所谓的系统lsi那样,由硬件单体来实现。作为包含这样的硬件和软件的组合以及硬件单体双方在内的上位概念,也可以表述为处理电路(processingcircuitry)。
对实施方式1的意图估计装置1的动作进行说明。首先,对与执行顺序估计模型的生成处理相关的动作进行说明。
图7是示出用于说明实施方式1的执行顺序估计模型的生成处理的意图估计装置1的结构例的图。
图7中,训练用数据存储部114存储通过对多个句子示例给出执行顺序而得到的训练用数据。
图8是示出实施方式1的训练用数据的示例的图。如图8所示,训练用数据是通过对多个句子示例(编号1、编号2、编号3、···)给出执行顺序而得到的数据。例如,关于句子示例编号为1的“時間が厳しいので、高速道路で行って(因为时间紧,所以请走高速)”,分成单句1“時間が厳しいので(因为时间紧)”和单句2“高速道路で行って(请走高速)”,作为执行顺序,给出了“仅执行单句2”。该执行顺序由训练数据制作者预先给出。
返回图7,执行顺序估计模型生成部115利用统计的方法训练存储于训练用数据存储部114中的执行顺序的对应关系。执行顺序估计模型生成部115使用由特征量提取部108提取出的特征量和存储于训练用数据存储部114中的执行顺序,生成执行顺序估计模型。
图9是用于说明实施方式1的执行顺序估计模型的生成处理的流程图。首先,词素解析部103对存储于训练用数据存储部114的训练用数据的各句子示例中的单句1和单句2进行词素解析(步骤st1)。例如,对于编号为1的句子示例来说,词素解析部103对单句1“時間が厳しいので(因为时间紧)”和单句2“高速道路で行って(请走高速)”进行词素解析。词素解析部103经由语法解析部104将进行词素解析得到的结果输出给特征量提取部108。
特征量提取部108根据存储于特征量提取规则存储部107中的特征量提取规则,对进行词素解析后的单句1和单句2进行特征量提取处理(步骤st2)。例如,对于编号为1的句子示例来说,特征量提取部108提取特征量“ので”和“て”。此外,特征量提取部108将各个单句位置信息分别追加给提取出的特征量(步骤st3)。例如,特征量提取部108将单句位置信息“单句1”追加给从单句1中提取出的特征量“ので”,成为“单句1_ので”。此外,特征量提取部108将单句位置信息“单句2”追加给从单句2中提取出的特征量“て”,成为“单句2_て”。这里,也可以像带单句位置信息的特征量那样去表述追加单句位置信息后的特征量。特征量提取部108将与提取出的特征量相关的信息输出给执行顺序估计模型生成部115。
执行顺序估计模型生成部115根据特征量和训练用数据中包含的执行顺序,生成执行顺序估计模型(步骤st4)。例如,在特征量“单句1_ので”和“单句2_て”的情况下,如图8所示,训练用数据中包含的执行顺序为“仅执行单句2”,因此,执行顺序估计模型生成部115判断为:特征量“单句2_て”的评分高于特征量“单句1_ので”的评分。执行顺序估计模型生成部115对训练用数据中包含的全部句子示例进行与上述同样的处理,最终生成图5所示那样的执行顺序估计模型。
接下来,对与使用了执行顺序估计模型的意图估计处理相关的动作进行说明。
图10是示出实施方式1的对话例的图。图11是用于说明实施方式1的意图估计处理的流程图。
首先,如图10所示,语音识别装置1说出“ピッと鳴ったらお話ください(噼——声响后请讲话)”(s1)。对此,用户说出“××へ行きたい。(想去××)。”(u1)。另外,这里,来自语音识别装置1的讲话被表示为“s”,来自用户的讲话被表示为“u”。以下也同样。
图11中,如由u1所示那样,当用户讲话时,语音识别部102对用户输入进行语音识别处理(步骤st01),将该用户输入转换为文本数据。词素解析部103对转换得到的文本数据进行词素解析处理(步骤st02)。语法解析部104对进行词素解析后的文本数据实施语法解析处理(步骤st03),当该文本数据是复句时,将该复句分割为多个单句。当文本数据不是复句时(步骤st04,“否”),转至步骤st05以后的处理,当文本数据是复句时(步骤st04,“是”),转至步骤st07以后的处理。
u1的输入例是单句,因此,这里,转至步骤st05。因此,语法解析部104将进行词素解析后的单句的文本数据输出给意图估计部106。意图估计部106利用意图估计模型,对所输入的单句执行意图估计处理(步骤st05)。这里,如“<目的地设定>[<设施>=<××>]”这样来估计意图。
命令执行部111执行与意图估计部106的意图估计结果对应的机械命令(步骤st06)。例如,命令执行部111执行将设施××设定为目的地这样的操作。然后,应答生成部112生成与由命令执行部111执行的机械命令对应的合成语音。作为合成语音,例如为“××を目的地にしました。(已将××设定为目的地。)”。通知部113利用扬声器等将由应答生成部112生成的合成语音通知给用户。其结果是,如图10的“s2”所示那样,对用户进行“××を目的地にしました。(已将××设为目的地。)”这样的通知。
接下来,对图10中“u2”所示那样用户讲话“先に○○へ寄りたいのだけど、やっぱりまず△△へ寄る。(虽然想先去○○,但还是首先去△△。)”的情况进行说明。
图11中,当用户如“u2”所示那样讲话时,语音识别部102对用户输入进行语音识别处理而将该用户输入转换为文本数据,词素解析部103对文本数据进行词素解析处理(步骤st01、st02)。接下来,语法解析部104对文本数据进行语法解析处理(步骤st03)。在此,像单句1(第1单句)“先に○○へ寄りたいのだけど(虽然想先去○○)”和单句2(第2单句)“やっぱりまず△△へ寄る(但还是首先去△△)”那样,将与用户输入相关的文本数据分割为多个单句。因此,语法解析部104将进行词素解析后的各单句的文本数据输出给意图估计部106和特征量提取部108,进行步骤st07之后的处理。
意图估计部106利用意图估计模型,对单句1和单句2分别实施意图估计处理(步骤st07)。在这里的示例中,意图估计部106针对单句1估计出“<经由地设定>[<设施>=<○○>]”的意图,针对单句2估计出“<经由地设定>[<设施>=<△△>]”的意图。
特征量提取部108使用特征量提取规则,对单句1和单句2分别实施特征量提取处理(步骤st08)。在这里的示例中,特征量提取部108提取出针对单句1的第1特征量、即特征量“单句1_先に”、“单句1_だけど”,并提取出针对单句2的第2特征量、即特征量“单句2_やっぱり”、“单句2_まず”。另外,这里,对特征量还赋予了单句位置信息。特征量提取部108将与针对各单句提取出的特征量相关的信息输出给执行顺序估计部110。
执行顺序估计部110根据与从特征量提取部108输出的特征量相关的信息和存储于执行顺序估计模型存储部109中的执行顺序估计模型,估计各单句的执行顺序(步骤st09)。以下,对执行顺序估计的详细情况进行说明。
首先,执行顺序估计部110将从特征量提取部108输出的特征量与执行顺序估计模型进行对照,求出针对各执行顺序的各特征量的评分。
图12是示出实施方式1的针对各执行顺序的各特征量的评分的图。如图12所示,针对执行顺序“单句1优先”,特征量“单句1_先に”的评分为0.45,特征量“单句1_だけど”的评分为0.2,特征量“单句2_やっぱり”的评分为0.1,特征量“单句2_まず”的评分为0.2。关于其它执行顺序,也同样地求出各特征量的评分。
接下来,执行顺序估计部110求各执行顺序下的各特征量的评分之积。
图13是示出实施方式1的求评分之积的计算式的图。在图13中,si是针对作为估计对象的执行顺序的、第i个特征量的评分。s是表示针对作为估计对象的执行顺序的、si之积的最终评分。
图14是示出实施方式1的针对各执行顺序的最终评分的图。执行顺序估计部110使用图13所示的计算式,计算出图14所示的最终评分。在这里的示例中,关于执行顺序“单句1优先”,特征量“单句1_先に”的评分为0.45,特征量“单句1_だけど”的评分为0.2,特征量“单句2_やっぱり”的评分为0.1,特征量“单句2_まず”的评分为0.2,因此,计算出上述评分之积即最终评分s为1.8e-3。同样,关于其它执行顺序,也分别计算出最终评分。
执行顺序估计部110将计算出的作为估计对象的各执行顺序的最终评分中评分最高的执行顺序“单句2优先”估计为恰当的执行顺序。即,执行顺序估计部110根据执行顺序估计模型所包含的多个特征量的评分来估计各操作的执行顺序,进一步说,是基于根据多个特征量的评分之积得到的最终评分来估计各操作的执行顺序。
返回图11,命令执行部111根据由意图估计部106估计出的多个单句中包含的各个意图和由执行顺序估计部110估计出的多个单句的执行顺序来执行与多个单句各自包含的意图对应的机械命令(步骤st10)。
在这里的示例中,由意图估计部106针对单句1估计出“<经由地设定>[<设施>=<○○>]”的意图,针对单句2估计出“<经由地设定>[<设施>=<△△>]”的意图。此外,由执行顺序估计部110将执行顺序“单句2优先”估计为恰当的执行顺序。因此,命令执行部111首先执行与单句2的意图“<经由地设定>[<设施>=<△△>]”对应的机械命令(△△的经由地设定操作),然后执行与单句1的意图“<经由地设定>[<设施>=<○○>]”对应的机械命令(○○的经由地设定操作)。与第1意图对应的操作也可以被表述为第1操作,与第2意图对应的操作也可以被表述为第2操作。
如图10的s3所示,应答生成部112生成与由命令执行部111执行的机械命令对应的合成语音“△△を経由地に設定します。○○を経由地に設定します。(将△△设定为经由地。将○○设定为经由地。)”,并由通知部113对用户通知该合成语音(步骤st11)。
根据以上内容,根据实施方式1,语法解析部104将所输入的复句分割为多个单句,特征量提取部108提取多个单句各自包含的特征量,执行顺序决定部110根据提取出的特征量来确定与多个单句各自包含的意图对应的处理的执行顺序,因此,能够考虑到意图的执行顺序进行意图估计,能够准确地估计用户的意图。
此外,命令执行部111根据由执行顺序估计部110估计出的多个单句的执行顺序来执行与多个单句各自包含的意图对应的机械命令,因此能够减轻用户的操作负担。
实施方式2.
以下,使用附图对本发明的实施方式2进行说明。在实施方式2中,执行顺序估计部110除了使用从特征量提取部108得到的特征量之外,还使用从意图估计部106得到的主意图的特征量(主意图特征量)来估计执行顺序。关于主意图特征量的说明,在后面进行叙述。
图15是示出实施方式2的意图估计装置1b的结构例的图。实施方式2的意图估计装置1b与意图估计装置1的不同之处在于,替代实施方式1的执行顺序估计模型存储部109和执行顺序估计部110而具有执行顺序估计模型存储部109b和执行顺序估计部110b。其它结构与实施方式1相同,因此,标注与图1相同的标号,并省略其说明。
执行顺序估计模型存储部109b存储如下的执行顺序估计模型(执行顺序估计信息),该执行顺序估计模型用于估计文本所包含的多个单句的执行顺序。
图16是示出实施方式2的执行顺序估计模型的一例的图。如图16所示,执行顺序估计模型是如下这样的信息:该信息是将各执行顺序的类别与多个单句各自包含的特征量的评分对应起来而得到的,此外,进一步是将各执行顺序的类别与多个单句各自包含的主意图特征量的评分对应起来而得到的。
图16中,特征量“单句1_ので”、特征量“单句2_て”、特征量“单句1_先に”、特征量“单句1_だけど”、特征量“单句2_やっぱり”、特征量“单句2_まず”的评分与实施方式1相同,因此,省略说明。
图16中,“单句1_経由地追加(经由地追加)”、“单句2_目的地設定(目的地设定)”是主意图特征量。主意图特征量表示通过对从意图估计部106的意图估计结果提取出的主意图赋予单句位置信息而得到的特征量。例如,如果是“单句1_経由地追加”,则表示单句1所包含的意图是“经由地追加”。如果是“单句2_目的地設定”,则表示单句2所包含的意图是“目的地设定”。
在图16的示例中,关于主意图特征量“单句1_経由地追加”,执行顺序“单句1优先”下的评分为0.2,执行顺序“单句2优先”下的评分为0.25,执行顺序“同时执行”下的评分为0.2,执行顺序“仅执行单句1”下的评分为0.25,执行顺序“仅执行单句1”下的评分为0.1。此外,关于主意图特征量“单句2_目的地設定”,执行顺序“单句1优先”下的评分为0.1,执行顺序“单句2优先”下的评分为0.45,执行顺序“同时执行”下的评分为0.05,执行顺序“仅执行单句1”下的评分为0.1,执行顺序“仅执行单句1”下的评分为0.3。在导航装置中,通常在设定目的地和经由地时,进行先设定目的地之后再设定经由地的操作。因此,关于主意图特征量“单句2_目的地設定”,执行顺序“单句2优先”的评分提高。
对实施方式2的意图估计装置1b的动作进行说明。首先,对与执行顺序估计模型的生成处理相关的动作进行说明。
图17是示出用于说明实施方式2的执行顺序估计模型的生成处理的意图估计装置1b的结构例的图。图18是用于说明实施方式2的执行顺序估计模型的生成处理的流程图。
首先,词素解析部103对图8所示的训练用数据的各句子示例中的单句1和单句2进行词素解析(步骤st001)。例如,以编号为1的句子示例来说,词素解析部103对单句1“時間が厳しいので(因为时间紧)”和单句2“高速道路で行って(请走高速)”进行词素解析。词素解析部103经由语法解析部104将进行词素解析得到的结果输出给特征量提取部108和意图估计部106。
特征量提取部108根据存储于特征量提取规则存储部107中的特征量提取规则,对进行词素解析后的单句1和单句2进行特征量提取处理(步骤st002)。例如,以编号为1的句子示例来说,特征量提取部108提取特征量“ので”和“て”。此外,特征量提取部108将单句位置信息分别追加给提取出的特征量(步骤st003)。例如,特征量提取部108将单句位置信息“单句1”追加给从单句1中提取出的特征量“ので”,成为“单句1_ので”。此外,特征量提取部108将单句位置信息“单句2”追加给从单句2中提取出的特征量“て”,成为“单句2_て”。特征量提取部108将与提取出的特征量相关的信息输出给执行顺序估计模型生成部115b。
接下来,意图估计部106估计进行词素解析后的单句1和单句2所包含的意图,作为主意图特征量进行提取(步骤st004)。例如,以编号为4的句子示例来说,意图估计部106从单句1中提取主意图特征量“経由地設定(经由地设定)”,并从单句2中提取主意图特征量“目的地設定(目的地设定)”。此外,意图估计部106将单句位置信息“单句1”追加给从单句1中提取出的主意图特征量,成为“单句1_経由地設定”。此外,意图估计部106将单句位置信息追加给提取出的主意图特征量(步骤st005)。例如,意图估计部106将单句位置信息“单句1”追加给从单句1中提取出的主意图特征量,成为“单句1_経由地設定”。此外,意图估计部106将单句位置信息“单句2”追加给从单句2中提取出的主意图特征量,成为“单句2_目的地設定”。意图估计部106将与提取出的特征量相关的信息输出给执行顺序估计模型生成部115b。
执行顺序估计模型生成部115b根据特征量、主意图特征量及训练用数据中包含的执行顺序,生成执行顺序估计模型(步骤st006)。执行顺序估计模型生成部115b对训练用数据中包含的全部句子示例进行与上述同样的处理,最终生成图16所示那样的执行顺序估计模型。
接下来,对与使用执行顺序估计模型的意图估计处理相关的动作进行说明。
图19是示出实施方式2的对话例的图。图20是用于说明实施方式2的意图估计处理的流程图。
如图19所示,语音识别装置1说出“ピッと鳴ったらお話ください(噼——声响后请讲话)”(s11)。对此,用户说出“先に○○へ寄って、△△へ行く。(先去○○,再去△△。)”(u22)。
首先,语音识别部102对用户输入进行语音识别处理而将该用户输入转换为文本数据,词素解析部103对文本数据进行词素解析处理(步骤st0001、st0002)。接下来,语法解析部104对文本数据进行语法解析处理(步骤st0003)。在此,像单句1(第1单句)“先に○○へ寄って(先去○○)”和单句2(第2单句)“△△へ行く(再去△△)”那样,将与用户输入相关的文本数据分割为多个单句。语法解析部104将进行词素解析后的各单句的文本数据输出给意图估计部106和特征量提取部108,进行步骤st07以后的处理。由于步骤st0005和步骤st0006的处理与实施方式1中的图11的说明相同,因此省略。
意图估计部106利用意图估计模型,对单句1和单句2分别实施意图估计处理(步骤st0007)。在这里的示例中,意图估计部106针对单句1估计出“<经由地设定>[<设施>=<○○>]”的意图,针对单句2估计出“<目的地设定>[<设施>=<△△>]”的意图。
特征量提取部108使用特征量提取规则,对单句1和单句2分别实施特征量提取处理(步骤st0008)。在这里的示例中,特征量提取部108针对单句1提取特征量“单句1_先に”和“单句1_て”。另外,针对单句2没有提取出的特征量。特征量也被赋予了单句位置信息。特征量提取部108将与针对各单句提取出的特征量相关的信息输出给执行顺序估计部110b。
执行顺序估计部110b根据由意图估计部106估计出的各单句的意图提取主意图特征量(步骤st0009)。例如,执行顺序估计部110b根据单句1的意图“<经由地设定>[<设施>=<○○>]”提取主意图特征量“单句1_経由地設定”,根据单句2的意图“<目的地设定>[<设施>=<△△>]”提取主意图特征量“单句2_目的地設定”。主意图特征量也被赋予了单句位置信息。另外,这里,设为由执行顺序估计部110b进行主意图特征量的提取处理进行了说明,但不限于此。例如,也可以是,在意图估计部106中进行主意图特征量的提取处理,并将提取出的信息输出给执行顺序估计部110b。
执行顺序估计部110b根据与从特征量提取部108输出的特征量相关的信息和与提取出的主意图特征量相关的信息,估计与各单句的意图对应的操作的执行顺序(步骤st0010)。执行顺序估计部110b与实施方式1同样,将特征量和主意图特征量与执行顺序估计模型进行对照,求出针对各执行顺序的特征量和主意图特征量的评分。然后,执行顺序估计部110b使用图13所示的计算式,求出各执行顺序下的特征量和主意图特征量的评分之积。即,执行顺序估计部110b根据各单句所包含的多个特征量的评分和根据主意图特征量的评分之积得到的最终评分来估计操作的执行顺序。
图21是示出实施方式2的对各执行顺序的最终评分的图。在这里的示例中,关于执行顺序“单句1优先”,特征量“单句1_先に”的评分为0.45,特征量“单句1_て”的评分为0.2,主意图特征量“单句1_経由地設定”的评分为0.2,主意图特征量“单句2_目的地設定”的评分为0.1,因此,计算出上述评分之积即最终评分s为1.8e-3。同样,关于其它执行顺序,也分别计算出最终评分。
执行顺序估计部110将计算出的作为估计对象的各执行顺序的最终评分中评分最高的执行顺序“单句2优先”估计为适当的执行顺序。
返回图20,命令执行部111根据由意图估计部106估计出的多个单句中包含的各个意图和由执行顺序估计部110估计出的多个单句的执行顺序来执行与多个单句各自包含的意图对应的机械命令(步骤st0011)。
在这里的示例中,由意图估计部106针对单句1估计出“<经由地设定>[<设施>=<○○>]”的意图,针对单句2估计出“<目的地设定>[<设施>=<△△>]”的意图。此外,由执行顺序估计部110将执行顺序“单句2优先”估计为适当的执行顺序。因此,命令执行部111首先执行与单句2的意图“<目的地设定>[<设施>=<△△>]”对应的机械命令(△△的目的地设定操作),然后执行与单句1的意图“<经由地设定>[<设施>=<○○>]”对应的机械命令(○○的经由地设定操作)。
如图19的s02所示,应答生成部112生成与命令执行部111执行的机械命令对应的合成语音“△△を目的地に設定します。○○を経由地に設定します。(将△△设定为目的地。将○○设定为经由地。)”,并由通知部113对用户通知该合成语音(步骤st0012)。
根据以上内容,根据实施方式2,执行顺序估计部110b除了使用由特征量提取部108提取出的特征量之外,还使用从意图估计部106得到的主意图特征量来估计与多个单句各自包含的意图对应的操作的执行顺序,因此,与实施方式1相比较,能够更准确地估计用户的意图。
例如,在进行上述那样的“先に○○へ寄って、△△へ行く。(先去○○,再去△△。)”的讲话时,如实施方式1那样,执行顺序估计部110如果在执行顺序的确定中不使用主意图特征量,则在图21中,特征量只有“单句1_先に”、“单句1_て”,因此,“单句1优先”的最终评分成为最高的值。于是,要执行与单句1的意图“<经由地设定>[<设施>=<○○>]”对应的机械命令(○○的经由地设定操作),然后执行与单句2的意图“<目的地设定>[<设施>=<△△>]”对应的机械命令(△△的目的地设定操作)。
然而,通常在导航装置中,只有在进行目的地设定操作之后才能进行经由地设定操作,因此,在实施方式1中,对于“先に○○へ寄って、△△へ行く。(先去○○,再去△△。)”这一讲话无法适当地执行机械命令,结果导致无法准确地估计用户的意图。
另一方面,在执行顺序的估计中使用特征量和主意图特征量的实施方式2中,如上所述,执行顺序估计部110b考虑主意图特征量而将执行顺序确定为“单句2优先”,因此,能够恰当地执行机械命令,能够准确地估计用户的意图。
另外,也可以是,通过其它装置来执行到此为止说明的意图估计装置1、1b的功能的一部分。例如,也可以是,由设置于外部的服务器等来执行一部分的功能。
标号说明:
1、1b:意图估计装置;101:语音输入部;102:语音识别部;103:词素解析部;104:语法解析部;105:意图估计模型存储部;106:意图估计部;107:特征量提取规则存储部;108:特征量提取部;109、109b:执行顺序估计模型存储部;110、110b:执行顺序估计部;111:命令执行部;112:应答生成部;113:通知部;114:训练用数据存储部;115、115b:执行顺序估计模型生成部;150:处理装置;160:存储装置;170:输入装置;180:输出装置。
- 还没有人留言评论。精彩留言会获得点赞!