基于GPU的腔内扫描光声系统及数据处理方法与流程
本发明涉及腔内图像处理领域,特别涉及一种用GPU实现实时成像的腔内扫描光声系统及数据处理方法。
背景技术:
光声成像技术(Photoacoustic Imaging)是一种新型的无损成像技术,由于其具有高分率、高穿透深度、高对比度、无损实时活体成像等优点,在最近20年里得到迅速发展;光声成像技术是指受短脉冲光(脉宽<微秒)辐照的光吸收介质在吸收光能量后快速升温膨胀,由于辐照时间远小于受照介质内部的热传导时间,产生瞬时热膨胀导致应激出超声信号(称为光声信号)。利用超声传感器接收应介质应激出的光声信号,并通过一定的演算算法进行图像重建,可以反演出组织内部光吸收的分布情况,它是一种基于光学吸收差异特性反演组织生理病变的功能成像技术。
由于光声成像的数据量很大,特别是进行光声、超声双模B模式成像时,光声成像的投影数据和超声成像的投影数据需要同时进行算法处理,再将处理得到的数据进行成像。如果采用CPU运算,由于CPU的串行数据处理方式将大大消耗CPU的资源,占用系统通讯,降低光声系统的成像速度。
如果采用DSP、FPGA等硬件处理系统,由于数据采集卡采到的数据为浮点数据,FPGA等硬件处理系统并不适合浮点计算,因此降低了硬件系统的数据处理速度,并且在硬件设计上也会很复杂。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于GPU的腔内扫描光声系统。
本发明的另一目的在于,提供一种基于GPU的腔内扫描光声系统的数据处理方法。
为了达到上述第一目的,本发明采用以下技术方案:
本发明基于GPU的腔内扫描光声系统,包括激光光源、信号触发器、光纤耦合器、延时器、超声发射接收器、腔内扫描头、数据采集卡、计算机、图像处理器GPU、以及图像显示器,所述信号触发器、延时器、超声发射接收器以及腔内扫描头顺序连接,所述信号触发器、激光光源、光纤耦合器以及腔内扫描头顺序连接,所述数据采集卡分别与信号触发器、超声发射接收器以及计算机连接,所述图像处理器GPU和图像显示器均与计算机连接;
所述的信号触发器发出同步触发信号触发激光光源,激光光源发出的脉冲激光经过光纤耦合器进入光纤,经过腔内扫描头旋转扫描后输出光声信号;
所述的信号触发器发出的同步触发信号经过延时器延时一段时间后触发超声发射接收器发射激励电压,激励电压驱动腔内扫描头发射超声信号,腔内扫描头返回超声信号;
所述的数据采集卡接收信号触发器发出的同步触发信号,触发采集卡采集上述的光声信号和超声信号,并将A/D转换后的光声和超声信号作为投影光声图像和超声图像的采样数据存储在计算机内存中;
所述的计算机通过PCIE总线接口将采样数据拷贝至GPU显存,图像处理器GPU进行并行数据处理,并将处理好的结果数据传回计算机,计算机将数据进行图像显示。
作为优选的技术方案,所述图像处理器GPU进行并行数据处理的方法为:
启动GPU的CUDA内核时,CPU将图像像素分配信息传输到GPU,GPU启动并行计算时,GPU的任务分配单元将图像像素分配信息分配到GPU芯片上,并分配相应的二维线程数,每一个线程在宏观上同时读取显存数据进行并行计算。
为了达到上述第二目的,本发明采用以下技术方案:
本发明基于GPU的腔内扫描光声系统的数据处理方法,首先规定一幅图像代表一次B-scan,一次B-scan由θ个采样深度为ρ的A-line组成;采样数据f1n(ρ,θ)是由数据采集卡进行A/D转换后的光声投影数据,f2n(ρ,θ)是由数据采集卡进行A/D转换后的超声投影数据,其中横坐标ρ为采样深度,纵坐标为采样角度θ,n为采样角度θ的采样次数;该方法的具体步骤为:
S1、将采样数据f1n(ρ,θ)、f2n(ρ,θ)存储在计算机内存中,为f1n(ρ,θ)、f2n(ρ,θ)分配内存,内存空间大小为n*ρ*θ;其中f1n(ρ,θ)表示第θ角度第n次采集到的深度为ρ的光声信号,f2n(ρ,θ)表示第θ角度第n次采集到的深度为ρ的超声信号;
S2、为f1n(ρ,θ)、f2n(ρ,θ)分配GPU端显存空间,分配显存空间大小为n*ρ*θ,将f1n(ρ,θ)、f2n(ρ,θ)从主机端内存拷贝到GPU端显存;
S3、为图像显示数组矩阵F1(x,y)、F2(x,y)分配显存空间,分配空间大小为x*y,其x为图像像素点横坐标,y为图像像素点纵坐标;
S4、并行将ρ个f1n(ρ,θ)、f2n(ρ,θ)分别进行去噪运算,得到f1’(ρ,θ)、f2’(ρ,θ);其中f1’(ρ,θ)表示第θ角度的采集到的n次光声信号经过运算得到的一个光声信号,f2’(ρ,θ)表示第θ角度的采集到的n次超声信号经过运算得到的一个超声信号;
S5、根据图像矩阵F1(x,y)和F2(x,y),CPU将图像矩阵像素分配信息传输到GPU,GPU启动并行计算时,GPU的任务分配单元将图像像素分配信息分配到GPU芯片上,每个线程的坐标为(x,y);
S6、线程(x,y)对图像F1(x,y),F2(x,y)进行并行坐标转换,得到对应的f1’(ρ,θ)、f2’(ρ,θ)上的数据点;将f1’(ρ,θ)、f2’(ρ,θ)上的对应点数据值赋值到图像矩阵F1(x,y),F2(x,y)上,对未在f1’(ρ,θ)、f2’(ρ,θ)上的数据点进行双线性内插后赋值到F1(x,y),F2(x,y)上;
S7、为图像显示数组矩阵F1(x,y)、F2(x,y)分配内存空间,将F1(x,y)、F2(x,y)矩阵从GPU端显存拷贝到主机端进行显示,释放所有未释放的内存和显存空间。
作为优选的技术方案,步骤S4中所述的去噪运算是指将每个θ采样到的n个A-Line数据进行中值滤波运算,对应位置的n个值进行取中间值运算,然后取中间值作为滤波后的该位置的数据值。
作为优选的技术方案,步骤S6中所述的坐标转换公式为:
所述的双线性内插法为:ρ′=ρ+Δρ,θ′=θ+Δθ,其中ρ、θ为整数部分;Δρ,Δθ为小数部分,则
F1(x,y)=(1-Δρ)(1-Δθ)f1’(ρ,θ)+(1-Δρ)Δθf1’(ρ,θ+1)+Δρ(1-Δθ)f1’(ρ+1,θ)+ΔρΔθf1’(ρ+1,θ+1);
F2(x,y)=(1-Δρ)(1-Δθ)f2’(ρ,θ)+(1-Δρ)Δθf2’(ρ,θ+1)+Δρ(1-Δθ)f2’(ρ+1,θ)+ΔρΔθf2’(ρ+1,θ+1)。本发明的技术原理如下:
本发明的基于GPU平台的腔内扫描光声系统及数据处理方法是基于CUDA(Compute Unified Device Architecture),CUDA是一种由NVIDIA公司推出的通用并行计算架构,在计算上已经超越了通用的CPU,该架构使GPU能够解决复杂的计算问题。在CUDA架构下,开发人员可以通过CUDA C语言(CUDA C语言是对标准C语言的一种简单扩展)对GPU编程运算。
在CUDA的架构中,一个系统分为两个部份:Host端和Device端。Host端是指在CPU上执行的系统部份,而Device端则是在显示芯片(GPU)上执行的系统部份。在同一个系统中可以有一个Host和多个Device。CPU主要负责进行逻辑事件的处理和串行计算,GPU负责执行高度线程化的并行数据处理任务。在CUDA程序中,将允许在GPU上的可以被并行执行的步骤称为Kernel(内核函数)。通过GPU并行计算,极大的提高了光声成像速度。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明的基于GPU平台的腔内扫描光声系统及数据处理方法,利用计算机通用显卡GPU,并将基于GPU的统一技术设备构架(CUDA)首次引入到光声系统成像中数据处理和投影,借助GPU多线程并行数据处理能力和浮点计算能力,将光声成像系统的成像速度较基于CPU平台处理的成像速度提高了数十倍,达到了临床2D实时成像的要求。
2、本发明由于采用CUDA并行数据处理方法,光声成像的数据处理速度远远大于CPU方式的数据处理速度,因此可以使用更加复杂的光声成像投影算法,在得到更加精确的光声图像的同时达到临床2D的实时成像要求。
3、本发明由于采用基于CUDA的GPU并行数据处理方法,省去了专用的图像处理系统,因此降低了系统的成本。
附图说明
图1是本发明的系统构成示意图;
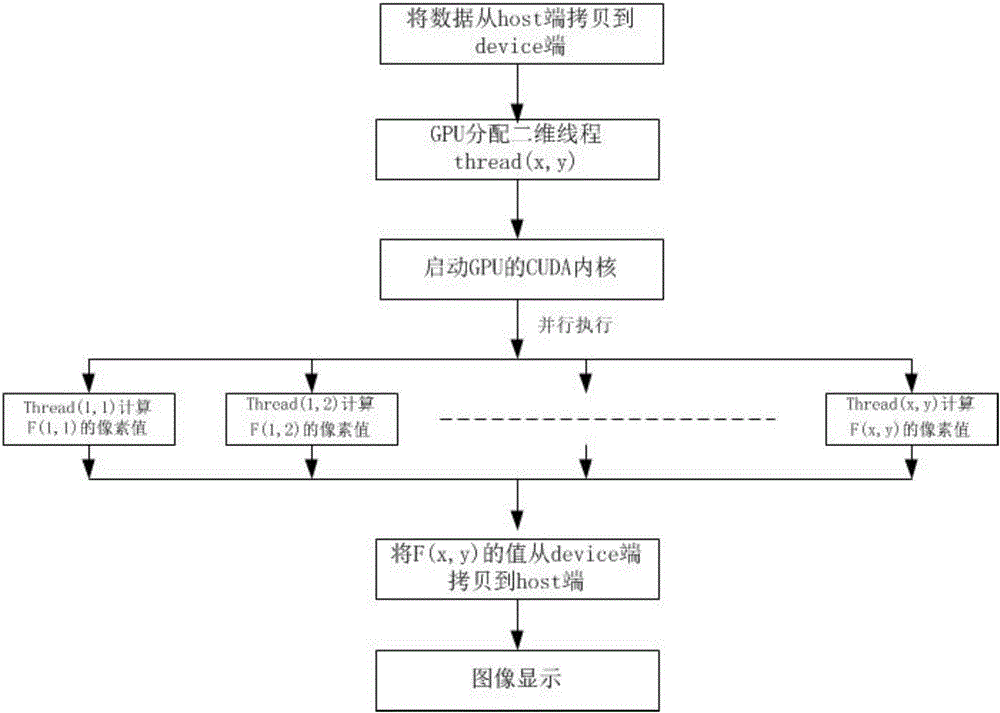
图2是本发明的数据处理方法流程图;
图3是模拟样品B扫描成像效果图;其中:图a为投影算法在CPU模式下系统成像图像;图b为投影算法在GPU模式下系统成像图像;
附图标号说明:
1:激光光源;2:信号触发器;
3:光纤耦合器;4:延时器;
5:超声发射接收器;6:腔内扫描头;
7:数据采集卡;8:计算机;
9:图像处理器GPU;10:图像显示。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示,本实施例基于GPU的腔内扫描光声系统,包括激光光源1、信号触发器2、光纤耦合器3、延时器4、超声发射接收器5、腔内扫描头6、数据采集卡7、计算机8、图像处理器GPU 9、以及图像显示器10,所述信号触发器2、延时器4、超声发射接收器5以及腔内扫描头6顺序连接,所述信号触发器2、激光光源1、光纤耦合器3以及腔内扫描头6顺序连接,所述数据采集4卡分别与信号触发器2、超声发射接收器5以及计算机8连接,所述图像处理器GPU 9和图像显示器10均与计算机8连接。
工作时,信号触发器2发出同步触发信号触发激光光源1,激光光源1发出的脉冲激光经过光纤耦合器3进入光纤,并通过光纤进入腔内扫描头6,腔内扫描头6经过360°旋转扫描后返回光声信号;信号触发器2发出的同步触发信号经过延时器4延时一段时间后触发超声发射接收器5发射激励电压,激励电压驱动腔内扫描头6发射超声,腔内扫描头6返回超声信号;信号触发器2发出的同步触发信号触发数据采集卡7采集光声信号和超声信号,并将A/D转换后的光声和超声信号作为投影光声图像和超声图像的采样数据存储在计算机8内存中;计算机通过PCIE总线接口将采样数据拷贝至GPU显存,图像处理器GPU9进行并行数据处理,并将处理好的结果数据传回计算机8,计算机将数据进行图像显示10。
本实施例基于GPU的腔内扫描光声系统的数据处理方法,如图2所示,包括下述步骤:
(a)将采样数据f1n(ρ,θ)、f2n(ρ,θ)存储在计算机内存中,为f1n(ρ,θ)、f2n(ρ,θ)分配内存,内存空间大小为n*ρ*θ;
(b)为f1n(ρ,θ)、f2n(ρ,θ)分配GPU端显存空间,分配显存空间大小为n*ρ*θ,将f1n(ρ,θ)、f2n(ρ,θ)从主机端内存拷贝到GPU端显存;
(c)为图像显示数组矩阵F1(x,y)、F2(x,y)分配显存空间,分配空间大小为x*y,其x为图像像素点横坐标,y为图像像素点纵坐标;
(d)并行将ρ个f1n(ρ,θ)、f2n(ρ,θ)分别进行去噪运算,得到f1’(ρ,θ)、f2’(ρ,θ);
(e)为图像矩阵F1(x,y),F2(x,y)分配x*y个并行线程,每个线程的坐标为(x,y);
(f)线程(x,y)对图像F1(x,y),F2(x,y)进行并行坐标转换,得到对应的f1’(ρ,θ)、f2’(ρ,θ)上的数据点;将f1’(ρ,θ)、f2’(ρ,θ)上的对应点数据值赋值到图像矩阵F1(x,y),F2(x,y)上,对未在f1’(ρ,θ)、f2’(ρ,θ)上的数据点进行双线性内插后赋值到F1(x,y),F2(x,y)上;
(g)为图像显示数组矩阵F1(x,y)、F2(x,y)分别内存空间,将F1(x,y)、F2(x,y)矩阵从GPU端显存拷贝到主机端进行显示,释放所有未释放的内存和显存空间。
步骤d中所述的去噪运算是指将每个θ采样到的n个A-Line数据进行中值滤波运算,对应位置的n个值进行取中间值运算,然后取中间值作为滤波后的该位置的数据值。
步骤f中所述的坐标转换公式为:
所述的双线性内插法为:ρ′=ρ+Δρ,θ′=θ+Δθ,其中ρ、θ为整数部分;Δρ,Δθ为小数部分。则
F1(x,y)=(1-Δρ)(1-Δθ)f1’(ρ,θ)+(1-Δρ)Δθf1’(ρ,θ+1)+Δρ(1-Δθ)f1’(ρ+1,θ)+ΔρΔθf1’(ρ+1,θ+1)。
F2(x,y)=(1-Δρ)(1-Δθ)f2’(ρ,θ)+(1-Δρ)Δθf2’(ρ,θ+1)+Δρ(1-Δθ)f2’(ρ+1,θ)+ΔρΔθf2’(ρ+1,θ+1)。
例如:计算100帧B-scan图像,像素大小为768*768。分别采用CPU端和GPU端计算图像投影算法,并用CUDA提供的计时函数进行计时,实验得到结果为CPU端执行100帧B-scan需要约121秒,GPU端需要3秒,基于GPU的投影速度提高了40倍。如图3(a)、图3(b)所示,图3(a)为采用双线性内插算法在CPU模式下的系统成像图,图3(b)为采用双线性内插算法在GPU模式下的系统成像图。
本发明提供的基于GPU的腔内扫描光声系统及数据处理方法,通过GPU并行计算,极大的提高了光声成像速度,同时也提供了一种低成本,高性能的光声成像系统。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!