一种渲染方法及装置与流程
本申请的实施例涉及图像处理技术领域,尤其涉及一种渲染方法及装置。
背景技术:
在三维图形处理领域,通常对图形的处理需要经过复杂的渲染计算过程。一般来说,渲染分实时渲染和非实时渲染,实时渲染需要在i秒内产出若干张图片,主要用于三维游戏、三维模型动态实时展示;非实时渲染一般耗时较长,旨在产出物理真实的效果图,主要用于影视动漫、广告策划、室内设计、工业设计等领域。
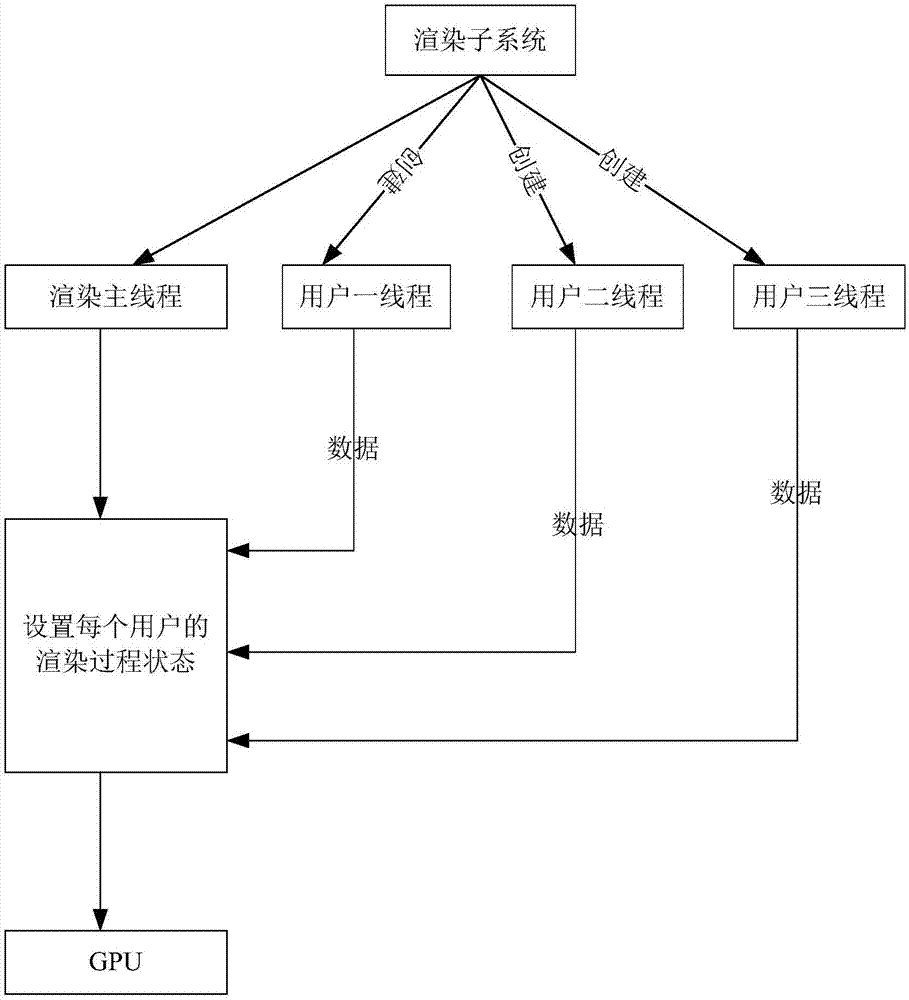
一般在进行实时渲染过程中,数据先由cpu(centralprocessingunit,中央处理器)处理再传输到gpu(graphicsprocessingunit,图形处理器)处理,最后生成最终的已渲染的画面。如图1所示,在cpu中,渲染子系统开启主线程、并创建针对三个用户的用户线程(用户线程1、用户线程2、用户线程3),对于每个用户通过各自提交的渲染任务数据,均需要通过主线程设置渲染过程状态后再传输到gpu处理。为提高实时渲染的速度,当数据传输延时可以忽略时,一种方案是可以将数据传输至后台的云端服务器进行实时渲染的相关计算。如图1所示,现阶段三维图形渲染在进行渲染之前,需要通过cpu设定对于当前场景的渲染过程状态,在渲染过程状态设置中一般需要设定各种参数,在云端服务器上进行实时渲染时,虽然cpu的运算能力强于普通pc(personalcomputer,个人电脑),但是在基于c/s(client/server,客户机和服务器)架构的云端服务器上实现时,每时每刻都有成千上万的用户终端接入,当用户终端接入增多时,对于每一个用户,均存在渲染过程状态的设定,而现有技术中渲染过程状态的设定都被图形api限制于一个线程/进程之中,受限于主线程缓存fifo(first-infirst-out,先入先出)的处理方式,如图2所示,每一个用户的图像帧的渲染过程可能需要在主线程中依次处理;而针对每一个用户的一个渲染过程均需包含如图3所示的一个渲染过程状态设置流程:绑定顶点(通常为通过bindvertex函数申请内存)>设置视图(通常为通过setviewport函数实现)>绑定渲染管道(通常通过bindpipeline函数实现)>绘制(通常为通过draw函数实现),最终按照上述的设置对用户提交的一个图像帧进行绘制。而上述过程中bindvertex、以及bindpipelin通常是通过在一个openglcontex(opengraphicslibrarycontex,开放图形库上下文中进行修改),而现有渲染api(applicationprogramminginterface,应用程序编程接口)限制只能在主线程的一个openglcontex对每个用户的渲染过程状态进行修改,因此渲染过程状态设定操作所花费的计算时间就不能被简单的忽略了,而cpu多核多进程根本对此不能起到作用。
这样,当接入的用户终端量上升时,渲染任务量增大,云端服务器单个cpu负载率过高,其他cpu无法分担渲染工作,同时由于cpu端处理延迟增大,造成gpu与cpu间的带宽并不能有效利用,gpu并不能发挥最大效用。
技术实现要素:
本申请的实施例提供一种渲染方法及装置,能够降低cpu负载率,提高gpu与cpu间的带宽利用率。
第一方面、一种渲染方法,包括:
在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态;
将至少一个在用户线程中为所述渲染任务数据配置渲染过程状态后的缓存数据发送至渲染主线程;
通过所述渲染主线程将所述缓存数据发送至图形处理器gpu进行图形渲染。
第二方面,提供一种渲染装置,包括:
配置单元,用于在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态;
转发单元,用于将所述配置单元通过至少一个在用户线程中为所述渲染任务数据配置渲染过程状态后缓存数据发送至渲染主线程;
发送单元,用于通过所述渲染主线程将所述缓存数据发送至图形处理器进行图形渲染。
第三方面,提供电子设备,包括:存储器、通信接口和处理器,所述存储器用于存储计算机执行代码,所述处理器用于执行所述计算机执行代码控制执行上述的渲染方法,所述通信接口用于所述渲染装置与外部设备的数据传输。
第四方面,提供一种计算机存储介质,用于储存为渲染装置所用的计算机软件指令,其包含执行上述的渲染方法所设计的程序代码。
第五方面,一种计算机程序,可直接加载到计算机的内部存储器中,并含有软件代码,所述计算机程序经由计算机载入并执行后能够实现上述述渲染方法。
在上述方案中,渲染装置可以在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态;将至少一个在用户线程中为所述渲染任务数据配置渲染过程状态后的缓存数据发送至渲染主线程;通过所述渲染主线程将所述缓存数据发送至图形处理器gpu进行图形渲染,由于渲染装置能够在用户对应的用户线程中为用户提交的渲染任务数据配置渲染过程状态,之后将配置渲染过程状态后的缓存数据发送至渲染主线程处理,相比于现有技术避免了由一个线程配置所有用户对应的渲染过程状态,这样很好地发挥了cpu多核多进程的优势,由于在各自的用户线程配置了用户提交的渲染任务数据的渲染过程状态,这样主线程只需要将渲染过程状态对应的缓存数据并行发送给gpu,因此能够降低cpu负载率,提高gpu与cpu间的带宽利用率。
附图说明
为了更清楚地说明本申请实施例的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为现有技术提供的实施例提供的一种渲染方法的逻辑结构图;
图2为现有技术提供的实施例提供的一种主线程中用户的图像帧处理顺序逻辑图;
图3为现有技术提供的实施例提供的一种主线程中渲染状态配置过程示意图;
图4为本申请的实施例提供的一种渲染方法的流程图;
图5为本申请的实施例提供的一种主线程中渲染状态配置过程示意图;
图6为本申请实施例提供的一种渲染方法的逻辑结构图;
图7为本申请的实施例提供的一种渲染装置的结构图;
图8a为本申请的另一实施例提供的一种渲染装置的结构图;
图8b为本申请的又一实施例提供的一种渲染装置的结构图。
具体实施方式
本申请实施例描述的系统架构以及业务场景是为了更加清楚的说明本申请实施例的技术方案,并不构成对于本申请实施例提供的技术方案的限定,本领域普通技术人员可知,随着系统架构的演变和新业务场景的出现,本申请实施例提供的技术方案对于类似的技术问题,
同样适用。
需要说明的是,本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
需要说明的是,本申请实施例中,“的(英文:of)”,“相应的(英文:corresponding,relevant)”和“对应的(英文:corresponding)”有时可以混用,应当指出的是,在不强调其区别时,其所要表达的含义是一致的。
本申请的实施例提供的用户终端可以为个人计算机((英文全称:personalcomputer,缩写:pc)、上网本、个人数字助理(英文:personaldigitalassistant,简称:pda)等,或者上述用户终端可以为安装有可执行本申请实施例提供的方法的软件客户端或软件系统或软件应用的pc等,具体的硬件实现环境可以通用计算机形式,或者是asic的方式,也可以是fpga,或者是一些可编程的扩展平台例如tensilica的xtensa平台等等。本申请的实施例提供的服务器包括本地域名服务器、本地代理服务器,网络服务器,本申请的实施例提供服务器用于响应服务请求提供计算服务。基本构成包括处理器、硬盘、内存、系统总线等,和通用的计算机架构类似。
本申请的基本原理为将渲染过程状态的设置过程从主线程剥离至每个用户对应的用户线程,很好地发挥了cpu多核多进程的优势,由于在各自的用户线程配置了用户提交的渲染任务数据的渲染过程状态,这样主线程只需要渲染过程状态的缓存数据初始化为gpu能够处理的数据降低cpu负载率,提高gpu与cpu间的带宽利用率。
本申请的实施例提供的渲染方法可以应用于用户终端,也可以应用于基于c/s架构的云端服务器。
参照图4所示,本申请的实施例提供一种渲染方法,包括如下步骤:
101、在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态。
在步骤101之前首选需要通过为每个用户创建一个用户线程。其中渲染任务数据至少包括如下状态参数:场景、场景中的元素、用户姿态;例如对于游戏场景,包含的元素有人、动物、植物、建筑、交通工具、武器等;元素的姿态可以为人或动物的姿态。步骤101具体为根据所述状态参数在用户对应的用户线程中,配置所述用户提交的渲染任务的渲染过程状态。示例性的,渲染过程状态通常设置为渲染任务数据的context(上下文),context包括当前渲染管线中的所有状态,如绑定的shader(着色器),rendertarget(渲染目标)等。在opengl(opengraphicslibrary,开放图形库)中context和单一线程是绑定的,所以所有需要作用于context的操作,例如改变渲染过程状态:绑定shader,调用drawcall(绘制调用),都只能在单一线程上进行。具体的,参照图5所示,步骤101包括如下步骤:
s1、在用户线程通过绑定顶点操作为用户提交的渲染任务数据申请内存。
s2、在用户线程为渲染任务数据设置视图。
s3、在用户线程为渲染任务数据绑定渲染管道。
其中步骤s1中绑定顶点操作通常通过bindvertex函数实现,在s2中设置视图操作通常通过setviewport函数实现,在步骤s3中绑定渲染管道通常通过bindpipeline函数实现。此外为了避免每一个用户渲染过程状态不停改变带来额外开销的影响,该方案还包括步骤s4在用户线程为渲染任务数据绑定描述符,其中描述符用于指示绑定渲染管道使用的资源。其中绑定描述符操作通过binddescriptor函数实现。由于descriptor描述bindpipeline阶段所需要的资源,当真正需要改变bindpipeline阶段的参数时只需要从资源相应的位置读入即可。
102、将至少一个在用户线程中为渲染任务数据配置渲染过程状态后的缓存数据发送至渲染主线程。
其中在步骤102中,当包含多个用户线程是,各个用户线程将各自配置的渲染过程状态对应的缓存数据(buffer)并行的发送给渲染主线程,其中,为了步骤102之后还包括:通过所述渲染主线程为所述至少一个用户线程对应的缓存数据建立缓存队列,这样在步骤103中渲染主线程直接将缓存队列里的缓存数据并行发送至gpu。
103、通过渲染主线程将缓存数据发送至图形处理器gpu进行渲染。
具体的参照图6所示,基于vulkan架构(一个跨平台的2d和3d绘图应用程序接口api),对本申请的实施例说明如下:渲染子系统运行一个渲染主线程,并通过创建三个用户线程,用户一线程、用户二线程以及用户三线程,每个用户线程针对各自用户提交的渲染任务数据设置渲染过程状态(renderprocessstate),该过程参照上述步骤101的描述不再赘述;之后各个用户配置渲染过程状态后的缓存数据并行发送至渲染主线程,这里缓存数据存储在缓存区域(通常为:commendbuffer),在渲染主线程维护一个缓存区域队列(例如commendbufferqueue)存储缓存数据,由于各个用户线程将各个用户渲染过程状态对应的缓存数据并行发送至渲染主线程的任务递交时间是不能忽略的。因此,这里通常在渲染主线程中设置initfence(初始化栅栏),当各个用户线程将各个用户渲染过程状态对应的缓存数据并行发送至渲染主线程全部完成后,通过触发fence释放,由渲染主线程将缓存区域队列中的数据递交至gpu。
在上述方案中,可以在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态;将至少一个在用户线程中所述渲染任务数据配置渲染过程状态后的缓存数据发送至渲染主线程;通过所述渲染主线程将所述缓存数据发送至图形处理器gpu进行图形渲染,由于能够在用户对应的用户线程中为用户提交的渲染任务数据配置渲染过程状态,之后将配置渲染过程状态后的缓存数据发送至渲染主线程处理,相比于现有技术避免了由一个线程配置所有用户对应的渲染过程状态,这样很好地发挥了cpu多核多进程的优势,由于在各自的用户线程配置了用户提交的渲染任务数据的渲染过程状态,这样主线程只需要将渲染过程状态对应的缓存数据并行发送给gpu,因此能够降低cpu负载率,提高gpu与cpu间的带宽利用率。
可以理解的是,通过其包含的硬件结构和/或软件模块实现上述实施例提供的功能。本领域技术人员应该很容易意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,本申请能够以硬件或硬件和计算机软件的结合形式来实现。某个功能究竟以硬件还是计算机软件驱动硬件的方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本申请实施例可以根据上述方法示例对渲染装置进行功能模块的划分,例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。需要说明的是,本申请实施例中对模块的划分是示意性的,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。
在采用对应各个功能划分各个功能模块的情况下,图7示出了上述实施例中所涉及的渲染装置的一种可能的结构示意图,渲染装置包括:配置单元71、转发单元72和发送单元73。配置单元71,用于在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态;转发单元72,用于将所述配置单元71通过至少一个在用户线程中为所述渲染任务数据配置渲染过程状态后缓存数据发送至渲染主线程;发送单元73用于通过所述渲染主线程将所述缓存数据发送至图形处理器进行图形渲染。可选的,还包括缓存单元74,用于通过所述渲染主线程为所述至少一个用户线程对应的所述缓存数据建立缓存队列;所述发送单元73具体用于将所述缓存数据建立缓存队列发送至图形处理器gpu进行图形渲染。其中,所述配置单元71具体用于在所述用户线程通过绑定顶点操作为用户提交的渲染任务数据申请内存;在所述用户线程为所述渲染任务数据设置视图;在所述用户线程为所述渲染任务数据绑定渲染管道。所述配置单元71还用于在所述用户线程为所述渲染任务数据绑定描述符,其中所述描述符用于指示绑定渲染管道使用的资源。可选的,渲染任务数据至少包括如下状态参数:场景、场景中的元素、元素的姿态;配置单元71具体用于根据所述状态参数在用户对应的用户线程中,配置所述用户提交的渲染任务数据的渲染过程状态。可选的还包括:线程控制单元75,用于为每一个用户创建一个用户线程。其中,上述方法实施例涉及的各步骤的所有相关内容均可以援引到对应功能模块的功能描述,在此不再赘述。
图8a示出了本申请一个实施例中所涉及的电子设备的一种可能的结构示意图。电子设备包括:通信模块81和处理模块82。处理模块82用于对渲染动作进行控制管理,例如,处理模块82用于支持渲染装置执行配置单元71、转发单元72以及线程控制单元75执行的方法。通信模块81用于支持渲染装置与其他设备的数据传输,实施发送单元73执行的方法。电子设备还可以包括存储模块83,用于存储辅助显示装置的程序代码和数据,例如执行缓存单元74执行的方法。
其中,处理模块82可以是处理器或控制器,例如可以是中央处理器(centralprocessingunit,cpu),通用处理器,数字信号处理器(digitalsignalprocessor,dsp),专用集成电路(application-specificintegratedcircuit,asic),现场可编程门阵列(fieldprogrammablegatearray,fpga)或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本申请公开内容所描述的各种示例性的逻辑方框,模块和电路。所述处理器也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,dsp和微处理器的组合等等。通信模块81可以是收发器、收发电路或通信接口等。存储模块可以是存储器。
当处理模块82为处理器,通信模块81为通信接口,存储模块83为存储器时,本申请实施例所涉及的电子设备可以为图8b所示的电子设备。
参阅图8b所示,该电子设备包括:处理器91、通信接口92、存储器93以及总线94。其中,通信接口92以及存储器93通过总线94耦接处理器91;总线94可以是外设部件互连标准(peripheralcomponentinterconnect,pci)总线或扩展工业标准结构(extendedindustrystandardarchitecture,eisa)总线等。所述总线可以分为地址总线、数据总线、控制总线等。为便于表示,图8b中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
结合本申请公开内容所描述的方法或者算法的步骤可以硬件的方式来实现,也可以是由处理器执行软件指令的方式来实现。软件指令可以由相应的软件模块组成,软件模块可以被存放于随机存取存储器(randomaccessmemory,ram)、闪存、只读存储器(readonlymemory,rom)、可擦除可编程只读存储器(erasableprogrammablerom,eprom)、电可擦可编程只读存储器(electricallyeprom,eeprom)、寄存器、硬盘、移动硬盘、只读光盘(cd-rom)或者本领域熟知的任何其它形式的存储介质中。一种示例性的存储介质耦合至处理器,从而使处理器能够从该存储介质读取信息,且可向该存储介质写入信息。当然,存储介质也可以是处理器的组成部分。处理器和存储介质可以位于asic中。另外,该asic可以位于核心网接口设备中。当然,处理器和存储介质也可以作为分立组件存在于核心网接口设备中。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本申请所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。计算机可读介质包括计算机存储介质和通信介质,其中通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质。存储介质可以是通用或专用计算机能够存取的任何可用介质。
以上所述的具体实施方式,对本申请的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本申请的具体实施方式而已,并不用于限定本申请的保护范围,凡在本申请的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!