上下文人物推荐的制作方法
背景技术:
诸如电子邮件、文档共享和社交联网之类的广泛通信应用正在连接越来越多的人物。随着人物的联系人列表越来越大,确定用来接收消息或加入对话的最相关的人物变得更加困难。例如,当用户考虑召集人物的会议以参与新项目时,用户可能必须依靠他或她自己的记忆来生成适当的人员列表。因此,用户可能因此遗漏某些可能重要的人物,或无意中包括可能不相关的人物。其他类似的情景包括标识电子邮件的相关接收者、社交网络上的联系人、与之共享文档的各方等。
现有的自动人物推荐技术可以使用某些基本信号(诸如用户输入姓名的首字母,或者最频繁发电子邮件的联系人等等)来推荐接收者。将期望利用诸如消息或对话之类的通信项目的附加的深层上下文特征来提高人物推荐的质量和相关性。
技术实现要素:
提供本发明内容是为了简化的形式介绍对概念的选择,这在下面的具体实施方式中被进一步描述。本发明内容不旨在标识所要求保护的主题的关键特征或基本特征,也不旨在用于限制所要求保护的主题的范围。
简而言之,在此描述的主题的各个方面针对基于用户创建的通信项目的上下文信号来生成人物推荐的技术。在某些方面中,针对多个个人实体中的每个个人实体构建包含记分的关键短语的个人简档。用于每个关键短语的分数可以例如基于关键短语与其中个人实体是参与者的通信项目或会话的相关性被生成。
随后,当用户创建新的通信项目时,项目的上下文信号被提取并且提供给包括第一层(l1)排名块和第二层(l2)排名块的推荐块。在l1排名中,可以在提取的上下文信号和个人简档之间执行多维向量相互关联,以标识一组排名最高的l1候选简档。在l2处理中,使用深层上下文信号(例如,应用深层语义相似性模型(dssm)和其他算法)进一步对l1候选简档评分和排名。来自l2处理的排名最高的简档作为用于新通信项目的人物推荐被提供给用户。在一方面中,可以响应于显式用户查询而反应性地生成人物推荐,或者可以在用户正在创建通信项目时主动地生成它们。
从以下详细描述和附图,其他优点可以变得显而易见。
附图说明
图1图示了图示本公开的某些方面的用于电子邮件客户端软件的示例性用户界面。
图2图示了根据本公开的电子邮件接收者推荐系统的示例性实施例。
图3图示了图2的历史分析引擎的示例性实施例。
图4图示了关键短语提取的示例。
图5图示了对应于单个个人实体的个人简档的示例。
图6图示了根据本公开的用于将关键短语指派给个人简档的方法的示例性实施例。
图7图示了图2的推荐块的示例性实施例。
图8图示了图7的l1候选标识块的示例性实施例。
图9图示了图7的l2排名块的示例。
图10图示了图9中的用于第m个简档的分数计算块的示例性实施例。
图11图示了根据本公开的用于执行系统更新和反馈的方法的示例性实施例。
图12图示了根据本公开的方法的示例性实施例。
图13图示了根据本公开的装置的示例性实施例。
图14图示了根据本公开的装置的备选示例性实施例。
具体实施方式
在此描述的技术的各个方面通常针对用于使用用户创建的项目的上下文特征来生成人物推荐的技术。这些技术可以适用于推荐用于电子邮件的接收者、会议邀请、文本消息、社交联网或共享文档等。另外的应用包括但不限于即时消息接发、用于因特网呼叫的应用、用于标识业务关系的客户关系管理(crm)、其中希望标识要与之玩/共享内容的其他方的在线游戏应用,等等。将会认识到,其中用户选择与其他用户连接或通信的任何应用都可以利用本发明的技术。
以下结合附图阐述的详细描述旨在作为对“用作示例、实例或例示”的示例性手段的描述,并且不应被解释为比其他示例性方面优选或有利。详细描述包括为了提供对本发明的示例性方面的透彻理解的目的的具体细节。对本领域技术人员将显而易见的是,可以在没有这些具体细节的情况下实践本发明的示例性方面。在一些情况中,以框图形式示出了众所周知的结构和设备,以避免使在此呈现的示例性方面的新颖性模糊。注意,除非另有说明,否则如在此使用的术语“对话”通常可以表示任何用户创建的通信项目,该通信项目被与其他人共享或被发送给其他人或者随后将被与其他人共享或被发送给其他人。还注意到,如在此使用的术语“人物”并不意味着仅表示一个或多个个人,而是还可被理解为是指可以被系统推荐以用于包括在对话中的任何实体。因此,群组、组织、邮件列表、社交联网群组等也将被理解为落入可被系统推荐的“人物”的范围内。
在设计如上所述的用于使人物彼此连接的软件时,期望为这样的软件提供基于项目的上下文来智能地预测和推荐用于用户创建的通信项目的合适的接收者的能力。例如,当用户撰写与某一任务或项目有关的电子邮件时,电子邮件软件可以智能地预测与这样的任务或项目最相关的人物,并且将那些人物作为电子邮件接收者推荐给用户。备选地,当用户考虑召集一组人物从事新项目时,任务管理软件可以推荐最可能与新项目相关的人物的列表。
本公开的技术有利地提供了一种人物推荐系统,其用于基于各种上下文指示符来预测和推荐要包括在通信项目中的相关人物或其他个人实体。推荐可以反应性地(例如,响应于用户对人物推荐系统的特定查询)或主动地(例如,在没有用户的具体查询时,基于用户当前正工作于的内容的上下文)被提供给用户。
图1示出了图示本公开的某些方面的用于电子邮件客户端软件的示例性用户界面。注意,图1仅为了例示性目的而被示出,并且不意味着将本公开的范围限制于电子邮件应用,或将其限制于任何特定类型的用户界面、电子邮件客户端。其他示例性实施例可以将本技术应用于例如用于会议邀请的人物推荐、文本消息、即时消息接发应用、包含帖子或推文的社交联网平台、其他共享应用,等等。在备选示例性实施例中,用户可以在社交网络上创建消息或加字幕的图像,并且例如基于诸如最活跃用户、社交网络上的先前动作、关键字、共同兴趣、标签、话题标签、因特网浏览历史等的上下文信号来将其与其他用户共享。这样的备选示例性实施例被预期在本公开的范围内。
在图1中,电子邮件消息100包括发送者字段110、接收者字段112、主题字段114、日期和时间字段116以及主体120。当用户撰写电子邮件100时,电子邮件客户端软件(在此也被表示为“内容创建应用”的示例)可以使用如在下文中被进一步描述的某些上下文信号来向用户推荐一个或多个接收者或“人物推荐”,例如以用于包括在接收者字段112中。
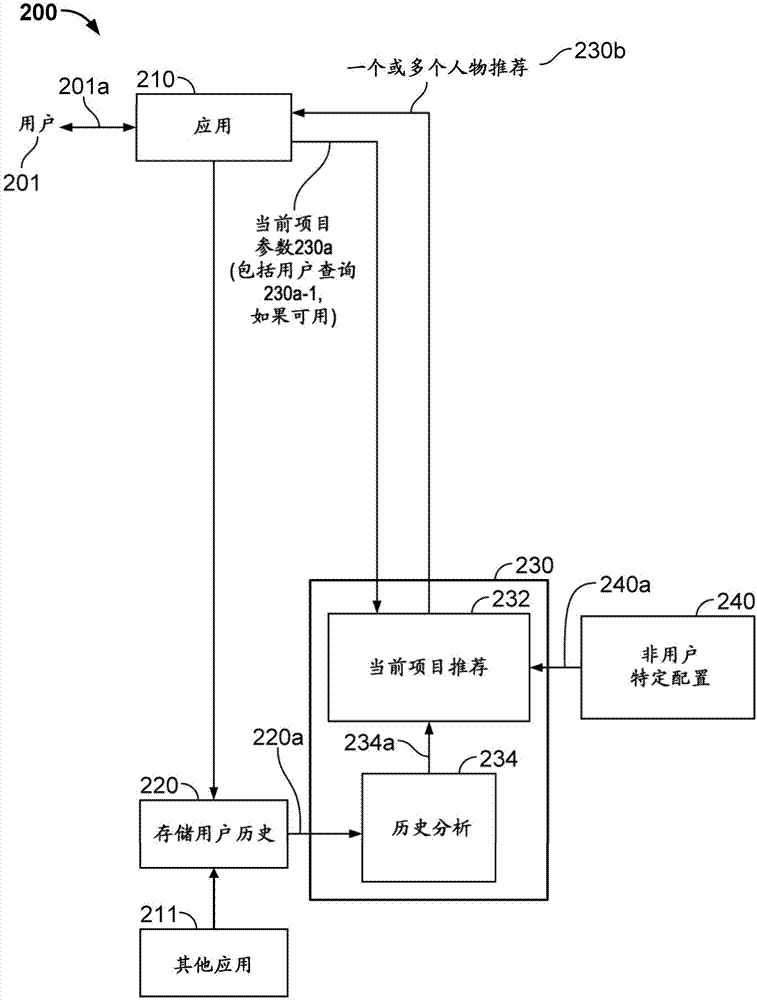
图2图示了根据本公开的人物推荐系统200的示例性实施例。在示例性实施例中,系统200可以生成用于电子邮件100的人物推荐。
在图2中,用户201通过内容创建应用210提供文本或其他输入201a(例如,“用户输入”)。在示例性实施例中,应用210可以对应于例如用于接收、撰写、编辑、发送电子邮件等的在线或离线(本地存储的)的电子邮件客户端软件应用。在备选示例性实施例中,应用210可以对应于用于接收用户输入201a以创建对话的任何应用,例如,用于创建本地或共享的文档的文字处理软件、社交联网网站用户界面、在线会议设置界面、文本消息或其他即时消息接发应用等,如在上文中例示性描述的。
在块220处,去往应用210以及先前通过应用210(例如,从其他人)接收到的任何通信项目的用户输入201a被累积地存储在用户历史220a中。在示例性实施例中,历史220a可以包括一个或多个数据文件,其包括由应用210或其他应用211累积地创建或处理的所有项目,例如,在用户与其他人之间被发送和接收的消息(诸如电子邮件)、文档(例如,有或没有发送者和/或接收者)、聊天对话(例如,聊天历史)、日历项目、会议请求、议程、社交消息接发应用上的帖子或更新、和/或与这样的项目相关联的元数据(例如,包括时间/日期指示符、位置指示符(如果可用)等)等
注意,历史220a通常可以包括来自不限于应用210的多个通信应用的通信项目。历史220a可被存储在本地硬盘驱动或远程服务器上。
在图2中,应用210还将来自用户输入201a的当前项目参数230a提供给推荐引擎230。当前项目参数230a可以包括例如用户201当前正在撰写的通信项目(例如,电子邮件项目、会议邀请、社交网络更新等)的内容。参数230a也可以(但不需要)包括显式用户查询230a-1,其对应于由用户201针对来自推荐引擎230的人物推荐而显式提交的查询。在示例性实施例中,参数230a还可以包括正在被撰写的项目的其他上下文信号和元数据,包括当日时间、当前用户位置等。
推荐引擎230分析参数230a和用户历史220a以生成用于当前项目的一个或多个人物推荐230b。特别地,一个或多个人物推荐230b可以对应于用户可能希望包括作为当前项目的一个或多个接收者的一个或多个附加的人物或其他实体。注意,在示例性实施例中,用户201可以例如通过点击应用210的用户界面中的“人物推荐”按钮或菜单项来具体地请求(例如,提交“显式查询”)引擎230提供一个或多个人物推荐230b。这样的显式查询的内容可以在此被指定为用户查询230a-1。备选地,引擎230在其接收参数230a时可以经由应用210自动地提供一个或多个推荐230b,例如,在用户201未显式地请求这样的推荐的情况下。这种备选示例性实施例被预期在本公开的范围内。
在所示出的示例性实施例中,推荐引擎230包括历史分析引擎234,其标识在用户历史220a中的某些上下文信号和潜在的人物推荐候选者之间的关系,如下文参照图3被进一步描述的。标识的关系被量化并以与要被推荐的可能的人物推荐候选者(在此也被称为“个人实体”)相关联的个人简档的形式被组织,并且个人简档被聚合以生成聚合个人简档234a。推荐引擎230还包括当前项目推荐块232,其基于参数230a和聚合个人简档234a来生成用于当前项目的一个或多个人物推荐230b。
在示例性实施例中,推荐块232还可以从非用户特定配置块240接收非用户特定配置240a,以帮助生成人物推荐。这样的非用户特定配置240a可以包括例如可能不能从用户历史220a被确定的某些关键短语之间的关系,然而这可能与生成一个或多个人物推荐230b有关。例如,用户历史220a可以显式地将诸如“营销活动”之类的关键短语与简档相关联,而不是诸如“广告活动”之类的短语,虽然这两个短语可能有关。然而,基于例如来自可公开获得的因特网使用记录等的非用户特定配置240a,当参数230a包含短语“广告活动”时,块232然而可能能够推荐与关键短语“营销活动”相关联的个人简档。在示例性实施例中,可以例如在第二层(l2)排名块730中使用非用户特定配置240a,如以下参照图7被进一步描述的。
图3图示了图2的历史分析引擎234的示例性实施例234.1。注意,引擎234.1仅为了例示目的而被示出,并且不意味着限制本公开的范围。引擎234.1包括关键短语提取块310、个人简档构建器320以及生成聚合个人简档234.1a的聚合个人简档块330。
特别地,块310接收用户历史220a作为输入,并且生成提取的关键短语310a。图4示出了关键短语提取的示例,其中从电子邮件400提取诸如关键短语410(“2015夏季营销活动”)和关键短语412(“营销活动”)之类的关键短语。提取的关键短语310a可以表示通常出现或被链接到历史220a中的通信项目的短语或其他语言实体,并且可以对应于例如名词短语、n元语法、语义符号等。
在示例性实施例中,关键短语提取可以使用自然语言处理(nlp)技术(例如,后跟浅解析器的断句器)被执行。用来提取关键短语的其他技术包括例如应用白名单和/或黑名单。特别地,可以定义列出一组短语的“白名单”,并且可以自动地将白名单中的短语在通信项目中的任何出现提取作为关键短语。类似地,“黑名单”可以定义通常不从通信项目提取的一组短语,并且可以包括例如敏感或保密短语,或者不太适合于关键短语提取的短语(例如,像“和”、“因为”等常用词)。
提取关键短语的另外技术可以例如包括例如使用如从深层语义相似性模型(dssm)得到的语义特征来将dssm或其他机器学习技术应用于历史220a中的个体项目或对话。特别地,应用dssm的神经网络可以接受来自历史220a中的项目的句子作为输入,并且生成某些关键短语候选作为输出。注意,dssm本身可以使用来自跨各种用户、来源等的项目被训练,并且无需限于一个用户。dssm可以得到将历史220a中的单词或短语映射到低维向量的嵌入(embedding)。
另外,关键短语可以通过利用诸如非语义特征(nsf)(例如,大写、出现频率、出现位置、停用词匹配、标点符号、接收者姓名和别名匹配等)之类的特征集被提取。
在示例性实施例中,关键短语提取块310可以使用块312来生成与提取的每个关键短语对应的提取分数312a。提取分数312a可以提供对例如提取的关键短语对某一项目有多重要的指示。例如,提取分数312a可以对应于从0至100的数字,其中可以例如基于关键短语在项目中的更高出现频率、在项目的开头附近放置关键短语等来指派更高的值。提取分数312a例如可被后续处理块作为在其中关键短语被用作变量的计算中对关键短语的重要性加权的软度量而被使用。
在关键短语提取310之后,块320针对多个个人实体中的每个个人实体构建个人简档。每个个人实体可以对应于在用户历史220a中被标识的个人、一组人、公司、团队,实体等。注意,术语“人”在此也可以被用于指个人实体,尽管这并不意味着暗示这样的“人”需要必须对应于仅一个个人。相反,这样的“人”可以被理解为指如从上下文将被理解的一组人或团队、组织等。
图5示出了对应于单个个人实体的个人简档500(“简档n”)的示例。每个个人简档包含与该个人实体相关联的多个属性。每个属性可以包含对应的值,以及对应的“属性分数”,该“属性分数”例如量化属性值与该简档的相关程度。特别地,与每个属性值相关联的属性分数通常可以量化给定个人实体与通信项目(诸如电子邮件)相关联的可能性,假定通信项目包括该属性值。
注意,图5中明确示出并在此描述的个人简档500的属性仅用于例示目的,并且不意味着将本公开的范围限制为包含或不包含所示出的任何特定属性或者所示出的任何特定的属性值、分数或评分范围的个人简档。
例如,简档500的属性510.1包括与个人实体相关联的个人的名字,该名字例如具有值“bob”以及对应的属性分数(例如,属性分数为90),该属性分数指示属性值“bob”与简档n的相关程度。在所示出的示例性实施例中,属性分数的范围可以对应于0-100,其中0对应于不相关并且100对应于最大相关,尽管可以容易地采用备选的标度范围。属性的其他示例包括定义姓氏的属性510.2以及列出个人的爱好等的属性510.3等,如从显式用户输入或其他方式确定的。
在示例性实施例中,简档500还可以包括属性510.4,其对应于与该个人实体相关联的关键短语(和/或语义符号,例如,如由dssm标识的)的列表512,每个相关联的关键短语具有对应的属性分数。在示例性实施例中,如果例如关键短语出现在发送到个人实体、从个人实体接收、或以其他方式与个人实体有关的通信项目中,则该关键短语可以与该个人实体相关联。在备选示例性实施例中,即使关键短语未显式地发生在发送到个人实体或从个人实体接收的通信项目中,该关键短语也可以与该个人实体相关联。
在示例性实施例中,属性分数分类器322(也被称为“属性评分模型”)可以向从用户历史220a提取的每个关键短语指派属性分数322a。分类器可以利用某些输入来生成对应于所提取的关键短语的属性分数322a,这些输入例如是用户历史220a中包含该关键短语的项目的重要性(例如,由用户或项目的其他接收者/发送者明确指定的)、该关键短语对项目的重要性(例如,基于提取分数312a)、利用首次或最后出现时间戳、上个月中的出现次数等而被应用于包含该关键短语的项目的时间衰减(例如,更新的项目被认为更重要并且因此被更加重地加权)。
用来生成属性分数的其他输入可以包括在用户和被包括在关键短语所出现于的项目中的人之间的电子邮件交互(例如,发送、接收或抄送的电子邮件)的数量、包含关键短语的文档共享交互的数量、关键短语在即时消息对话历史等中出现的次数、关键短语重要性特征(例如,提取分数、电子邮件重要性分数的统计)等。注意,属性评分模型可以根据这些特征的值的累积或组合函数来生成分数,例如,如由源于机器学习技术的神经网络实现的。
在示例性实施例中,可以使用用户特定历史220a和非用户特定语料库的组合来训练属性分数分类器322。例如,一组人类评估者可以被提供以通信项目的代表性(非用户特定)语料库(例如,电子邮件、会议邀请等),并且被要求例如通过指派属性值或对应于不良、公平、良好、优秀、完美的评级的评级来标记每个提取的关键短语与其所出现于的项目的相关性。例如,在图1的示例电子邮件中,短语“营销活动”可以被评估者标记为“完美”,这对应于短语与通信项目的最高相关性,而短语“时间”可以被标记为“不良。”
评估者提供的标签以及上文提及的其他输入(诸如电子邮件重要性等)可以用来训练用来实现属性分数分类器322的机器学习模型,以最佳地将属性分数指派给关键短语。在示例性实施例中,可以在“离线”模式下(例如,与推荐块232的实时运行分离)并且(不一定)使用在用户历史220a中找到的项目来执行训练。在示例性实施例中,可以采用来自不同用户集合的代表性通信项目的一般语料库。在示例性实施例中,机器学习模型可以采用增强的决策树技术、逻辑回归、神经网络等。
一旦底层机器学习模型被训练,属性分数分类器322然后就可以被用于在线模式,由此通过分类器322使用训练的算法来将属性分数指派给每个通信项目中的每个提取的关键短语。
在另一示例性实施例中,属性分数分类器322的底层算法可以在人物推荐系统200的实时操作期间被进一步训练。例如,从通信项目提取的关键短语(例如,通过块310对用户历史220a中的项目,或者通过块712对当前项目参数220a)可以作为“主题标签”候选者而被(即时地或周期性地)递送给用户,并且用户可被提示接受或拒绝(或提供甚至更精细的评级,诸如完美、优秀、良好等)主题标签作为与特定通信项目相关的关键短语。用户接受或拒绝然后可以用来标记主题标签候选者的相关性,并且所得到的数据然后可以用来重新训练属性分数分类器322的底层算法。这样的示例性实施例被预期在本发明的范围内。
例如,对于图1中所示出的例示性电子邮件100,用户“john”通常可以与接收者“bob”交换电子邮件或其他文档,并且这样的通信项目可以包含提取的关键短语“2015夏季”和“营销活动”。因此,“2015夏季”和“营销活动”可以是与bob的个人简档(例如,图5中的属性510.4)相关联的关键短语。另外,属性分数分类器322可以将属性分数95和80分别指派给“2015夏季”和“营销活动”。用户然后可以被呈现“营销活动”的主题标签,并且被请求接受或拒绝该主题标签与接收者bob的关联或该主题标签与电子邮件100的关联。
在示例性实施例中,还可以向每个个人简档指派对应于简档重要性分数的属性(未示出),从而指示该个人实体对用户有多重要。简档重要性分数可以由用户显式地输入,或者其可以由系统200基于例如基于用户历史220a的与该个人实体的用户交互的频率而被推断。简档重要性分数可以用于由推荐引擎230执行的进一步计算,例如下文所述的l1候选标识块720。
在块330处,跨所有个人实体收集由块320输出的每个实体的个人简档,以生成聚合个人简档234.1a。
图6图示了根据本公开的用于将关键短语指派给个人简档的方法600的示例性实施例。在块610,从图2中的历史220a中的每个项目提取一个或多个关键短语。在块620,一个或多个关键短语与一个或多个对应的个人简档相关联。例如,每个关键短语可以与历史220a中的对应项目的任何和所有接收者的简档相关联。在块625,例如针对每个项目并且跨历史220a中的所有项目来确定是否已经提取了所有关键短语。如果为“否”,则该方法经由块627进行,并且返回到块610以继续提取。如果为“是”,则该方法继续到块630。在块630,用属性分数对相关联的关键短语评分,并且在每个个人简档中对其排名。
图7图示了图2的推荐块232的示例性实施例232.1。在块710,从参数230a提取上下文信号710a。在示例性实施例中,块710可以包含用来以与图3的块310类似或相同的方式提取关键短语的关键短语提取块712,因此上下文信号710a可以包括由块712提取的关键短语的列表。块710可以进一步提取其他上下文信号714,诸如出现在消息或文档中的项目名称、消息主题和主体的文本、相关人物(例如,已经在项目的接收者字段或其他部分中被列出的人物)、消息或文档所生成于的应用(例如,对应于应用210的类型,诸如电子邮件客户端、文字处理软件等)及其使用场景、当前日期和时间、当前用户位置等。
一旦在块710处提取了信号710a,就将它们与参数230a一起提供给l1候选标识块720,以选择来自聚合个人简档234a的最可能与信号710a和参数230a有关的简档的候选子集720a(在此也被表示为“第一层候选者”或者“l1候选者”)。在示例性实施例中,候选子集720a对应于在首次搜索(例如,“第一层”处理)时被判断为与参数230a和信号710a最相关的候选简档。
图8图示了图7的l1候选标识块720的示例性实施例720.1。在块810,参数230a和上下文信号710a被与聚合个人简档234a中的每个个人简档相互关联,以生成每个个人简档810a的相关性分数。在示例性实施例中,相互关联可以沿着多个维度(例如,如由包含在每个个人简档中的属性的多维向量定义的)被执行。
特别地,l1候选标识可以计算以下各项之间的相关性:1)包含上下文信号710a和参数230a(诸如提取的关键短语或用户查询230a-1等)的一个或多个分量的第一向量,以及2)包含与每个个人简档相关联的多个属性的第二向量。
例如,如果用户查询230a-1可用(例如,用户已经向用于人物推荐的系统200发出特定查询),则第一向量(fv)可以包括对应于用户查询230a-1的单个分量:
第一向量(fv)=[用户查询230a-1](式1)。
结合用户查询230a-1,或者如果没有用户查询230a-1可用,则fv可被用其他信号(例如,来自参数230a的一个或多个提取的关键短语)填充。注意,第一向量也可以被写为例如fv=[n1;n2;...;nf],其中变量“nf”中的“f”表示第一向量的维度的总数,并且在上面的式1中f=1(即,仅一维)。
给定个人简档m的第二向量可以对应于例如:
个人简档m的第二向量(sv)=[简档m第一属性值;简档m第二属性值;...;简档m第s属性值](式2);
其中sv的每个维度对应于给定个人简档的属性值,并且s表示第二向量sv的维度的总数。例如,sv可以包含与图5中的简档500相关联的属性值的全部或任何子集。
对应于sv的第二分数向量(ssv)还可被如下定义,从而包含sv中列出的每个属性的属性分数:
个人简档m的第二分数向量(ssv)=[简档m第一属性分数;简档m第二属性分数;...;简档m第s属性分数](式3);
其中属性分数如上文早先参照图5中的简档n描述。
如下定义fv的分量fv[f]与sv的分量sv[s]之间的“匹配”:
匹配(fv[f],sv[s])=p用于fv[f]与sv[s]之间的完美匹配;
c用于fv[f]与sv[s]之间的完全匹配;
n用于fv[f]与sv[s]之间的不匹配;
其中f是从1到f的索引,s是从1到s的索引,并且其中p、c、n被指派数值(例如,例如,p=100,c=50,n=0),并且其中“完美匹配”可以表示两个文本字符串之间的整个字符串匹配,“完全匹配”可以表示两个文本字符串之间的完整的子字符串匹配等。注意,匹配定义仅为了例示性目的而在上文中被给出,并且不意味着将本公开的范围限制于所描述的任何特定类型的匹配定义。在备选示例性实施例中,可以指定除上文示出的三个(p,c,n)分级之外的“匹配”附加的分级。这样的备选示例性实施例被预期在本公开的范围内。
基于匹配定义,可以如下计算第一向量fv和第二向量sv之间的第一相关性分数correlation1:
correlation1(fv,sv)=∑f,smatch(fv[f],sv[s])(式4);
其中,将会理解,可以在两个向量fv和sv的所有维度(f,s)上迭代求和f,s的指数。
在备选示例性实施例中,可以如下计算第二相关性分数correlation2:
correlation2(fv,sv)=∑f,sssv[s]·match(fv[f],sv[s])(式5)。
特别地,correlation2按照对应的属性分数对每个第二向量分量匹配加权。
注意,上文给出的相关性分数仅用于例示性目的,并且不意味着将本公开的范围限制于用于得到两个向量之间的相关性分数的任何特定技术。在备选示例性实施例中,相关性分量还可以按照如上所述的简档重要性分数、参数230a中的第一向量分量的出现次数等被加权。另外,在备选示例性实施例中,式4和式5中表示的求和可以由其他操作(例如,l2范数或任何其他距离度量的计算)代替。或者,可以使用非线性技术来计算相关性。这样的备选示例性实施例被预期在本公开的范围内。
在块820,基于与每个简档的相关性结果相关联的前几个值来选择优选的候选子集720.1a。特别地,基于相关性分数(例如,要么是correlation1、correlation2,要么是可使用本文所述的技术得到的某一其他相关性分数),因此可以通过l1候选标识720来标识来自聚合个人简档234a的一组最相关简档(例如,具有最高相关性分数的那些简档)。
在示例性实施例中,可以使用特里结构或倒置树排名数据结构来执行对相关性分数的排名。特里和反向索引可用于提高算法的速度,以在给定大量候选者的情况下计算完美/完全/无匹配特征。
作为l1排名的例示性示例,假设用户201已经在电子邮件消息的接收者字段中键入字母“ph”,并且对应于电子邮件消息的参数230a被转发到系统200。参数230a因此可以包括包含字母“ph”的用户查询分量230a-1。块232作为响应可以计算每个简档的相关性分数,其指示字母“ph”与该简档有多相关。由框720标识的相关简档可以包括例如与姓名“philsmith”相关联的个人简档、与工作职能“医师”相关联的另一个人简档等。
在示例性实施例中,用户201可以显式地指定l1候选标识720如何标识相关l1候选的集合的“硬”规则。特别地,结合(或代替)如上所述对具有最大相关性分数的简档进行计算和排名,l1候选标识720可被配置为总是包括某些类型的简档作为l1候选者720a。例如,一个这样的用户指定的硬规则可以规定:每当用户查询230a-1包含与任何简档的“名字”或“姓氏”属性值的完美匹配(p),则该简档应当被包括在l1候选者720a中,而不管相关性分数排名的结果如何。将会认识到,针对人物推荐系统200的多个不同用户中的每个用户,这样的硬规则可以被个性化并存储在例如配置文件中。
返回到图7,在通过l1候选标识块720标识候选简档之后,可以将候选简档720a提供给l2排名块730,以生成对应于二次排名(例如,“第二层”处理)的结果的排名集合730a。个人简档的排名集合730a然后可被提供作为人物推荐230b。将会认识到,如下面进一步描述的,l2排名块730可以考虑到比l1候选标识720更复杂的因素和决定因素,并且因此在生成每个简档的相关性分数时可能消耗更多的时间和计算资源。
鉴于参照框232.1描述的架构,将会认识到,将人物推荐/排名任务分成用来快速标识相关简档的子集的第一(粗)l1排名并且随后对简档的子集执行第二(广泛)l2排名以完善人物排名,可以有利地提供在系统的性能和计算资源需求之间的最佳平衡。因此将会认识到,l1处理的目的是合理完成但是快速标识相关简档,而l2处理的目的确切的说是对l1候选简档排名。
图9图示了图7的l2排名块730的示例730.1。特别地,针对由l1候选标识块720标识的候选子集720a的每个简档执行分数计算910.1、...910.m、...910.m,其中m是表示由框720标识的简档的数量的数字。在分数计算之后,每个简档(例如,简档1至简档m)的分数910.1a、...910.ma、...910ma被提供给排名块920,其按照值对分数排名。块920的输出包括排名简档920a的列表,可以例如基于一个或多个最高分数从该列表生成一个或多个人物推荐230b。
图10图示了图9中针对第m个简档的分数计算块910.m的示例性实施例。将会认识到,可以使用类似的技术来实现任何任意个人简档的分数计算。
在图10中,块910.m包括排名分数生成器1020,其接收多个输入1001.1、1001.2、1001.3、1001.4、1001.5,以生成第m个简档的简档分数910.ma。
特别地,输入1001.1可以对应于来自系统的针对人物推荐的显式用户请求(如果可用),例如,如上面参照图2被描述的用户查询230a-1。注意,在某些情况下,如果没有显式用户请求被做出,例如当引擎230在没有显式用户查询的情况下自动(主动地)向用户提供一个或多个人物推荐时,则输入1001.1可以为空。
输入1001.2可以对应于参数230a(例如,包括上下文信号710a)与聚合个人简档234a中的每个个人简档之间的相互关联的结果,如上文参照图8被描述的。例如,输入1001.2可以包括多维向量,其表示沿着多个不同维度的这种相互关联的结果。
输入1001.3可以对应于例如在图7中的块710处已经被提取的上下文信号710a。上下文信号710a可以包括(但不限于)以下信号:用于撰写对话的设备的身份和类型(例如,工作计算机通常可以对应于工作上下文,而智能电话可以对应于个人/私人上下文)、电子邮件发送和接收时间(例如,作为工作时间相对于停工时间的指示符)、响应能力(例如,定义为从接收电子邮件到向发件人回复的平均、最小、最大或中间时间)、有或没有按照时间衰减加权、以时间衰减发自、发往或抄送(cc)给用户的电子邮件计数特征、如从会议邀请得到的响应能力特征(主持人、共同出席、被接受等)。
包括在上下文信号710a中的其他信号可以包括例如如从电子邮件服务器、日历或联系人管理器等获得的网络浏览器数据、接收者缓存信号和/或反馈回路。上下文信号710a还可以包括用来创建对话或通信项目的内容创建应用的身份,以及该内容创建应用中的特定应用任务。特别地,上下文信号710a可以允许在当用户使用内容创建应用来执行一个任务时和使用同一内容创建应用来执行另一个任务(也由内容创建应用支持)之间区分。例如,当使用支持包括语音呼叫、视频会议和文本消息接发的多个任务的与skype对应的内容创建应用时,根据skype被用来进行语音呼叫还是文本消息接发会话,可以由系统200向用户提供不同的人物推荐。
在示例性实施例中,用户先前完成的应用任务也可被包括在上下文信号710a中。例如,用户刚刚完成与特定个人实体skype语音呼叫的事实在某些情况下可能影响(例如,增加)在短时间内接下来是对该个人实体的电子邮件的可能性。这样的备选示例性实施例被预期在本公开的范围内。
输入1001.4可以对应于与第m个简档(例如,如由图3中的个人简档构建器320构造的)相关联的多个属性。上面参照图5描述了示例简档500,从而示出了可能与个人简档相关联的多个属性(例如,名字、姓氏、爱好、关键字等)。
输入1001.5可以对应于深层神经网络1010的输出,其通常对简档m的属性(包括关键短语)和从参数230a生成的上下文信号710a之间的相似性分类。深层神经网络1010可以利用从由适当大量数据训练的深层神经网络(诸如dssm)学习的嵌入,或者使用图2中的非用户特定配置240。注意,深层神经网络1010可以备选地或进一步接受在图10中指示的任何信号(例如,1001.1、1001.2、1001.3等),并且这样的备选示例性实施例被预期在本公开的范围内。
返回到图9,在根据排名简档920a生成一个或多个人物推荐230b之后,可以按照多种方式中的任何方式将人物推荐230b呈现给用户。例如,使用上文公开的技术,系统200可以基于用户对接收者姓名或地址的部分输入来建议接收者的全名或电子邮件地址。或者,除了用户已经输入的接收者的列表之外,系统200可以推荐一个或多个接收者。或者,在给定由系统200确定的上下文信号的情况下,如果确定用户输入的接收者不太可能被包括为接收者,则系统200可以提示用户进行确认。
在示例性实施例中,可以结合本文公开的技术来提供反馈,以训练在系统200中存在的功能关系。例如,如果在基于当前参数230a从系统200接收到推荐230b之后,用户201选择不继续执行推荐230b,而是手动选择另一(未推荐)人(p*),则这样的数据可被系统200收集并且用作反馈以改进所实现的算法。例如,在排名分数生成器1020中使用的机器学习模型可被更新,例如,使用用户指示的数据来训练。或者,对应于个人实体p*的个人简档可以被更新为将当前参数230a(例如,键入的用户内容)的分量包括在现有(例如,关键短语)或新的属性字段中。另外,如果用户201选择继续执行推荐230b,那么这样的信息也可以被系统200用于实时或离线的训练。
图11图示了根据本公开的用于执行系统更新和反馈的方法的示例性实施例1100。
在图11中,在块1110,系统200向用户201呈现人物推荐230b。
在块1120,确定用户201是否接受推荐230b。如果是,则方法1100前进到块1130。如果否,则方法1100前进到块1140。
在块1130,由于推荐230b被用户201接受,所以用户历史220a被更新,并且下一人物推荐的新参数230a可以被接收。
或者,在块1140,由于建议230b未被用户201接受,所以系统200将从应用210接收关于针对当前内容参数230a要包括的正确人物(p*)的信息,例如,如用户直接指示的。例如,在某些情况下,系统200可以针对用户201正在撰写的电子邮件(230a)推荐候选接收者(230b),并且用户201可以拒绝该候选接收者。用户201可以作为替代地选择备选的接收者(p*)作为正确的接收者。
在块1160,基于如用户201指示的对正确接收者(p*)的指示,系统200可以使用由p*和当前参数230a定义的数据集来执行对系统参数的实时更新或训练。
在示例性实施例中,从当前参数230a(例如,通过图7中的块710)提取的一个或多个关键短语可以被与适当生成的属性分数一起添加到与p*对应的个人简档的关键短语属性字段(例如,图5中的简档500的属性510.4)。
在备选示例性实施例中,图10中的排名分数生成器1020可以按照实时“训练模式”被临时配置,并且生成器1020中的算法权重/功能可以使用正确的(用户指示的)人p*和当前参数230a及对应的提取的上下文信号710a的组合来更新。
图12图示了根据本公开的方法1200的示例性实施例。注意,图12仅为了例示性目的而被示出,并且不意味着将本公开的范围限制到所示出的任何特定方法。
在图12中,在块1210,从多个通信项目中的每个通信项目提取至少一个关键短语,所述项目中的每个项目与至少一个个人实体相关联。
在块1220,每个关键短语与至少一个个人实体相关联。
在块1230,针对与每个个人实体相关联的每个关键短语生成属性分数。
在块1240,从内容创建应用接收用于当前通信项目的参数。
在块1250,将每个个人身份的每个关键短语与接收到的参数相互关联,以生成用于每个个人身份的相关性分数。
在块1260,基于相关性分数来针对所述当前通信项目生成人物推荐。
图13图示了根据本公开的装置的示例性实施例1300。注意,图13仅为了例示性目的而被示出,并且不意味着将本公开的范围限制于所示出的任何特定装置。
在图13中,装置1300包括被配置为从多个通信项目1310a提取多个关键短语的关键短语提取块1310。装置1300还包括个人简档构建器1320,其被配置为:针对多个个人实体中的每个个人实体生成1322个人简档;将提取的所述多个关键短语中的每个关键短语与所述个人简档中的至少一个个人简档相关联1324;以及将关联的提取的所述关键短语中的每个关键短语与属性分数相关联1326。装置1300还包括推荐块1330,其被配置为将当前通信项目1332a的至少一个参数与所述个人简档中的每个个人简档相互关联,以得到用于所述个人简档中的每个个人简档的相关性分数。推荐块1330还被配置为基于得到的相关性分数来生成用于当前通信项目1332a的人物推荐1334a。
在示例性实施例中,关键短语提取块1310和个人简档构建器1320可以利用上文参照图3被描述的技术,并且推荐块1330可以利用上文参照第一层(l1)排名(例如,图8)被描述的技术。
图14图示了根据本公开的装置的备选示例性实施例1400。在图14中,装置1400包括用于从多个通信项目中的每个项目提取至少一个关键短语的装置1410,所述项目中的每个项目与至少一个个人实体相关联;用于将每个关键短语与至少一个个人实体相关联的装置1420;用于针对与每个个人实体相关联的每个关键短语生成属性分数的装置1430;用于从内容创建应用接收用于当前通信项目的参数的装置1440;用于将每个个人身份的每个关键短语与接收到的参数相互关联以生成用于每个个人身份的相关性分数的装置1450;以及用于基于相关性分数来针对所述当前通信项目生成人物推荐的装置1460。
在本说明书和权利要求书中,将会理解,当元件被称为被“连接到”或“耦合到”另一元件时,其可以被直接连接或耦合到另一元件或者中间元件可能存在。相比之下,当元件被称为被“直接连接到”或“直接耦合到”另一元件时,不存在中间元件。另外,当元件被称为被“电耦合”到另一元件时,其表示在这样的元件之间存在低电阻的路径,而当元件被称为只是被“耦合”到另一元件时,在这样的元件之间可能存在或者可能不存在低电阻的路径。
可以至少部分地由一个或多个硬件和/或软件逻辑组件来执行本文所描述的功能。例如但不限于,可以使用的例示性类型的硬件逻辑组件包括现场可编程门阵列(fpga)、程序专用集成电路(asic)、程序专用标准产品(assp)、片上系统级系统(soc)、复杂可编程逻辑器件(cpld)等
尽管本发明易于被进行各种修改和替代构造,但是其某些例示的实施例在附图中被示出并且已经在上面得到详细描述。然而,应当理解,并非旨在于将本发明限制于所公开的具体形式,相反,意图是覆盖落入本发明的精神和范围内的所有修改、替代构造和等同物。
- 还没有人留言评论。精彩留言会获得点赞!