提问应答系统的训练装置以及该训练装置用的计算机程序的制作方法
本发明涉及提问应答系统,特别是,涉及在提问应答系统中提高针对“为什么型提问”的回答的精度的技术。
背景技术:
:对人类而言,在产生某种疑问时寻找其回答是基本的活动之一。例如,针对“为什么会得癌?”这样的提问,为了找到其回答而进行了各种努力。另一方面,计算机得到发展,变得能够以高于人类的能力进行人类迄今为止所能进行的各种活动。例如,存储事物或高速检索所需要的信息的能力。可是,以往认为用计算机来检索针对上述那样的“为什么型提问”的回答是极为困难的任务。在此,所谓“为什么型提问”,是指像“为什么会得癌?”这样的提问那样追寻发生了某种现象的理由的提问,利用计算机来寻找针对其的回答称为“为什么型提问应答”。另一方面,由于计算机硬件和软件的发展,正在研究通过与人类寻找针对“为什么型提问”的回答的方法不同的方法来探索针对“为什么型提问”的回答的技术。作为
技术领域:
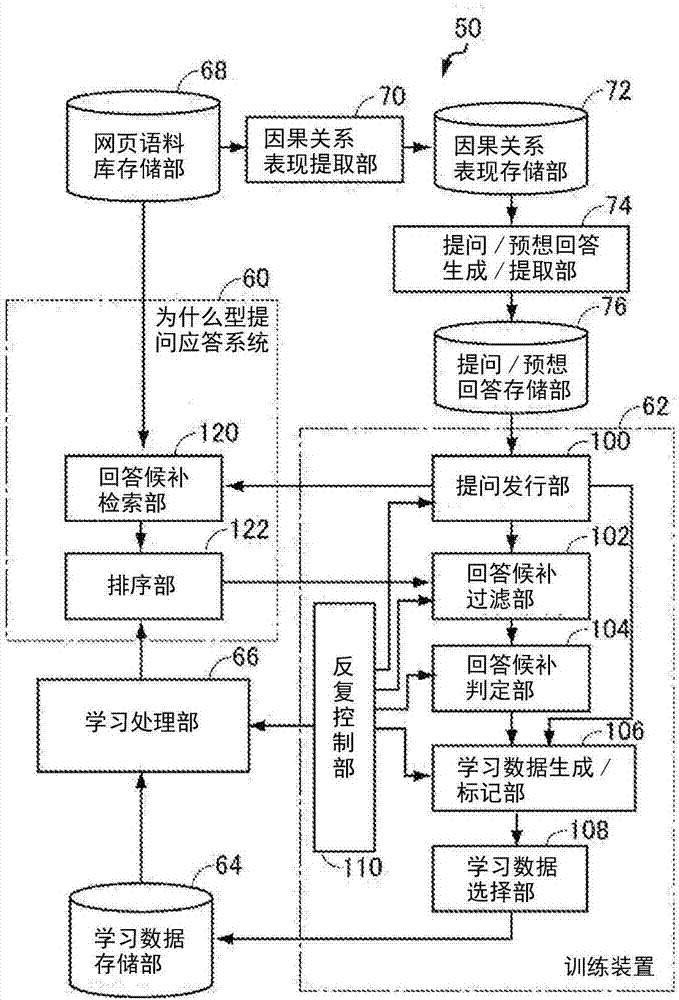
,是所谓的被称为人工智能、自然语言处理、网页挖掘、数据挖掘等的领域。关于这一点,作为提问应答系统的一个例子,有本申请的申请人在互联网上公开的提问应答服务。该提问应答系统作为其一个构成要件而安装了为什么型提问应答系统。该为什么型提问应答系统使用了后面说明的专利文献1所公开的技术。该为什么型提问应答系统预先从网页收集大量的文件,并着眼于表示因果关系的词汇等而从中取出大量的因果关系表现。在此所说的因果关系表现,是指表示原因的词组和表示结果的词组通过特定的词汇而结合那样的表现。当接受“为什么型提问”时,该系统从该大量的因果关系表现之中,将结果部分与提问句共同的因果关系表现汇集起来,并提取该表示原因的词组作为回答候补。因为可大量地得到这样的回答候补,所以在该系统中,使用用于从它们之中选择适当的回答候补作为针对提问的回答的分类器。该分类器通过使用了文本的词汇性的特征(单词串、词素串等)、构造特征(部分的文章结构树等)、意义性的特征(单词的意义、评价表现、因果关系等)的有教师的学习来进行学习。在先技术文献专利文献专利文献1:日本特开2015-011426号公报专利文献2:日本特开2013-175097号公报技术实现要素:发明要解决的课题上述的以往的为什么型提问应答系统虽然使用该分类器表现出了某种程度的性能,但是仍有改善的余地。为了改善性能,认为只要使用更多的、适当的学习数据来进行分类器的学习即可。但是,以往,学习数据通过人工作成,从而作成成本高,因此难以作成大量的学习数据。进而,并不清楚选择什么样的学习数据才能高效地进行分类器的学习。因此,期望更高效地进行分类器的学习而提高分类器的性能的技术。故此,本发明的目的在于,提供一种尽可能不经由人工而高效地作成分类器的学习数据来进行学习的为什么型提问应答系统的训练装置。用于解决课题的技术方案本发明的第一局面涉及的提问应答系统的训练装置与因果关系表现存储单元、提问及预想回答存储单元、以及提问应答系统一起使用,且用于提高进行该提问应答系统内的回答候补的得分附加的分类器的性能,其中,该因果关系表现存储单元存储多个因果关系表现,该提问及预想回答存储单元存储多个从存储在因果关系表现存储单元的、相同的因果关系表现提取出的提问与针对该提问的预想回答的组,该提问应答系统当接受提问时附带得分地输出针对该提问的多个回答候补。训练装置进一步与具备用于进行提问应答系统的分类器的学习的学习数据存储单元的学习装置一起使用。该训练装置包含:学习装置控制单元,对学习装置进行控制,以便使用存储在学习数据存储单元的学习数据进行分类器的学习;提问发行单元,发行存储在提问/预想回答存储单元的提问,并提供给提问应答系统;学习数据追加单元,从针对提问发行单元所发行的提问而从提问应答系统与得分一起输出的多个回答候补的每一个与该提问的配对生成提问应答系统的分类器的学习数据,并追加到学习数据存储单元;以及反复控制单元,对学习装置控制单元、提问发行单元、以及学习数据追加单元进行控制,以便直到给定的结束条件成立为止,反复执行多次基于学习装置控制单元的学习装置的控制、基于提问发行单元的提问的发行、以及基于学习数据追加单元的学习数据的追加。优选为,学习数据追加单元包含:回答候补选择单元,在针对提问发行单元所发行的提问而从提问应答系统与得分一起输出的多个回答候补之中,选择得分的绝对值小于正的第一阈值且该得分处于上位的给定个数的回答候补;学习数据候补生成单元,算出由回答候补选择单元选择出的给定个数的回答候补的每一个与对应于提问的预想回答之间的一致度,并按照该一致度是否大于第二阈值对该回答候补和该提问附加正例或反例的标记而生成学习数据候补;以及学习数据追加单元,将由学习数据候补生成单元生成的学习数据候补作为新的学习数据而追加到学习数据存储单元。更优选为,学习数据追加单元还包含:第一回答候补废弃单元,设置在回答候补选择单元的输出与学习数据候补生成单元的输入之间,将由回答候补选择单元选择出的回答候补之中、从得到了成为该回答候补之源的提问的因果关系表现得到的回答候补废弃。进一步优选为,学习数据追加单元还包含:第二回答候补废弃单元,设置在回答候补选择单元的输出与学习数据候补生成单元的输入之间,将由回答候补选择单元选择出的回答候补与提问的配对之中、与存储在学习数据存储单元的配对一致的配对删除。学习数据追加单元也可以包含:学习数据选择单元,仅选择作为由学习数据候补生成单元生成的学习数据候补的一部分的、包含于该学习数据候补的回答候补的得分处于上位的给定个数的学习数据候补,作为新的学习数据追加到学习数据存储单元。此外,提问应答系统也可以从由多个句子构成且包含至少一个在进行因果关系表现的提取时成为线索的词组的段落的集合提取回答候补。本发明的第二局面涉及的计算机程序使计算机作为提问应答系统的训练装置起作用,其中,该提问应答系统的训练装置与因果关系表现存储单元、提问及预想回答存储单元、以及提问应答系统一起使用,且用于提高该提问应答系统内的基于机器学习的分类器的性能,其中,该因果关系表现存储单元存储多个因果关系表现,该提问及预想回答存储单元存储多个从存储在因果关系表现存储单元的、相同的因果关系表现提取出的提问与针对该提问的预想回答的组,该提问应答系统当接受提问时附带得分地输出针对该提问的多个回答候补。训练装置进一步与具备用于进行提问应答系统的分类器的学习的学习数据存储单元的学习装置一起使用。形成组的提问和预想回答是从相同的因果关系表现生成的提问和预想回答。计算机程序使计算机作为构成上述任一个训练装置的各单元起作用。附图说明图1是示意性地示出本发明的实施方式涉及的为什么型提问应答系统的训练系统的概要的图。图2是示出图1所示的为什么型提问应答系统的训练装置的概略结构的框图。图3是示出从因果关系表现作成提问与预想回答的配对的过程的示意图。图4是从由存储了大量的文件的网页文件等提取出的大量的因果关系来生成如图3所示的提问与预想回答的配对的提问/预想回答生成/提取部的框图。图5是在图4所示的提问/预想回答生成/提取部中使用的、进行执行提问的过滤处理的第二过滤部的学习的第二过滤学习部的框图。图6是示出通过计算机硬件和计算机软件的协作来实现图2所示的反复控制部110时的计算机程序的控制构造的流程图。图7是示出实现图2所示的回答候补过滤部、回答候补判定部、以及学习数据生成/标记部的计算机程序的控制构造的流程图。图8是将通过本发明的实施方式涉及的训练系统进行了学习的分类器的性能与现有技术进行比较而示出的曲线图。图9是示出用计算机来实现本发明的实施方式时所需的计算机硬件的结构的框图。具体实施方式在以下的说明以及附图中,对于同一部件标注同一附图标记。因此,不再重复对它们的详细的说明。[概要]在图1示意性地示出本发明的实施方式涉及的为什么型提问应答系统的训练系统50的概要。参照图1,该训练系统50包含训练装置62,训练装置62自动识别上述的在先技术的为什么型提问应答系统60难以应付的提问,发现针对这样的提问的应答而自动作成强化分类器的性能那样的学习数据,并保存到学习数据存储部64。通过使用了存储在学习数据存储部64的学习数据的基于学习处理部66的学习,为什么型提问应答系统60的性能得到提高。[结构]在图2示出训练系统50的具体的结构。参照图2,训练系统50包含:网页语料库存储部68,对由从网页汇集的大量的文件构成的网页语料库进行存储;因果关系表现提取部70,从存储在网页语料库存储部68的大量的文件提取大量的因果关系表现;以及因果关系表现存储部72,对由因果关系表现提取部70提取出的因果关系表现进行存储。另外,关于因果关系的提取,除了在上述的专利文献1公开的技术以外,还能够使用在专利文献2记载的技术。训练系统50还包含:提问/预想回答生成/提取部74,从存储在因果关系表现存储部72的大量的因果关系表现之中,生成并输出适合于生成学习数据的提问及其预想回答;提问/预想回答存储部76,对由提问/预想回答生成/提取部74输出的提问和预想回答进行存储;前述的训练装置62,将存储在提问/预想回答存储部76的提问以及预想回答的组提供给为什么型提问应答系统60,使用该回答生成使为什么型提问应答系统60的性能提高那样的学习数据并保存在学习数据存储部64。在图3示出从因果关系表现130作成提问144及其预想回答146的过程。在因果关系表现中可以有各种表现,例如,在图3所示的因果关系表现130的情况下,表示原因的原因词组140和表示结果的结果词组142通过表示两者之间的因果关系的连词“因为~,所以”而连接。通过按照一定的变形规则对该结果词组142进行变形,从而可得到提问144。从原因词组140,也可通过一定的变形规则得到针对提问144的预想回答146。通过根据因果关系的形式而预先准备变形规则的组,从而能够从因果关系表现生成提问句及其预想回答的配对。再次参照图2,为什么型提问应答系统60包含:回答候补检索部120,从网页语料库存储部68之中检索针对所给出的提问的多个回答候补;以及排序部122,使用预先完成学习的分类器对由回答候补检索部120检索出的大量的回答候补附加评分,并进行排序而输出。进行使用了存储在学习数据存储部64的学习数据的基于学习处理部66的学习的是该排序部122的分类器。排序部122以对各回答候补附加了得分的形式进行输出。该得分是附带了基于该分类器的分类的结果的、表示针对提问的回答的可能性的得分。回答候补检索部120所输出的回答候补是在保存在网页语料库存储部68的文件之中、提问句之间的tf-idf的值处于上位的一定数量(在本实施方式中,为1200组)的一系列的句子串(段落)。另外,在本实施方式中,为了使为什么型提问应答系统60能够从大量的文件高效地检索回答候补,进行了如下的设计。即,在存储在网页语料库存储部68的文件之中,提取由连续的7个句子构成且包含至少一个在oh等的论文(jong-hoonoh,kentarotorisawa,chikarahashimoto,motokisano,stijndesaeger,andkiyonoriohtake.2013.why-questionansweringusingintra-andinter-sententialcausalrelations.inproceedingsofthe51stannualmeetingoftheassociationforcomputationallinguistics,pages1733-1743.)中使用的、成为用于识别因果关系的线索的词组的段落,并限定了为什么型提问应答系统60的回答候补的检索范围,以便从这些段落的集合之中检索回答候补。另外,段落所包含的句子的数量并不限定于7,也可以从5至10左右的范围中选择。训练装置62包含:提问发行部100,从存储在提问/预想回答存储部76的许多的提问/预想回答的配对选择提问并发行针对回答候补检索部120的提问;以及回答候补过滤部102,从针对由提问发行部100发行的提问而由为什么型提问应答系统60发送来的、进行了排序的回答候补之中,仅留下俱备一定的条件的回答候补,而将其它过滤掉。关于回答候补过滤部102的功能,将在后面参照图7进行叙述。训练装置62还包含:回答候补判定部104,针对回答候补过滤部102所输出的回答候补中的每一个,与和提问发行部100所发行的提问成为组的预想回答进行比较,由此判定该回答候补是否正确,并输出判定结果;学习数据生成/标记部106,对提问及其回答候补的组附加回答候补判定部104针对该回答候补所输出的判定结果来作为标记,从而生成学习数据候补;学习数据选择部108,积累由学习数据生成/标记部106输出的学习数据候补,并在针对提问/预想回答生成/提取部74所包含的全部因果关系表现结束了学习数据候补的生成的时间点,在学习数据候补之中选择由排序部122附加的得分最高的给定个数(k个)来作为学习数据追加到学习数据存储部64;以及反复控制部110,对提问发行部100、回答候补过滤部102、回答候补判定部104、学习数据生成/标记部106以及学习数据选择部108进行控制,以便直到俱备给定的结束条件为止,反复进行基于它们的处理。在图4示出图2所示的提问/预想回答生成/提取部74的结构。参照图4,提问/预想回答生成/提取部74包含:补充处理部172,如果在存储在因果关系表现存储部72的因果关系表现的结果部分存在对于生成提问句来说不足的信息,则对它们进行补充;规则存储部170,对预先通过人工作成的、用于从因果关系的结果词组生成提问句的规则进行存储;以及提问句生成部174,对于存储在因果关系表现存储部72的因果关系表现的各个结果词组且是由补充处理部172进行了补充的结果词组,在存储在规则存储部170的规则之中选择并应用任一个合适的规则来生成提问句并进行输出。在此,对补充处理部172的处理进行说明。在因果关系表现的结果词组部分中,很多情况下存在向其它部分的呼应(其它部分的参照),或没有谓语所应取的自变量。其结果是,有时在结果部分不存在主语,或者缺少主题。如果从这些结果部分生成提问句,则不能得到适合作为学习数据的提问句。因此,补充处理部172从因果关系表现的其它部分补充这样的主语以及主题。提问/预想回答生成/提取部74还包含:第一过滤处理部176,在提问句生成部174所输出的提问句之中,过滤掉包含代词的提问句,并输出除此以外的提问句;第二过滤处理部178,在第一过滤处理部176所输出的提问句之中,如果存在缺少与谓语相关的自变量的提问句,则将它们过滤掉,并输出除此以外的提问句;规则存储部182,存储了用于从因果关系表现的原因部分生成预想回答的变形规则;以及预想回答生成部180,对得到了第二过滤处理部178所输出的提问的因果关系表现的原因部分,应用存储在规则存储部182的变形规则,生成针对该提问的预想回答,并与提问作为组而保存到提问/预想回答存储部76。基于图4所示的第二过滤处理部178的处理使用基于机器学习的判别器来进行。参照图5,该第二过滤处理部178用的学习由第二过滤学习部202进行。为了该学习,在正例学习数据存储部200作为正例而存储自身完整的“为什么型提问”的例子。在本实施方式中,通过人工准备了9500个“为什么型提问”。第二过滤处理部178使用了在svm-light(t.joachims.1999.makinglarge-scalesvmlearningpractical.inb.schoelkopf,c.burges,anda.smola,editors,advancesinkernelmethods-supportvectorlearning,chapter11,pages169-184.mitpress,cambridge,ma.)中安装的子集树内核(subsettreekernel)。使用以下的树以及矢量的组合进行了该子集树内核的学习。·词组构造树的子集树·用对应的单词类置换名词后得到的子集树·用词素以及pos标签-n元模型表示的矢量第二过滤学习部202包含:反例学习数据生成部220,在存储在正例学习数据存储部200的正例学习数据的各提问句中,通过删除主语或宾语、或这两者,从而自动地生成反例的学习数据;反例学习数据存储部222,对由反例学习数据生成部220生成的反例学习数据进行存储;学习数据生成部224,将存储在正例学习数据存储部200的正例以及存储在反例学习数据存储部222的反例合并,并从各提问句提取给定的特征量而附加正例/反例的标记,由此生成学习数据集;学习数据存储部226,对存储在学习数据生成部224的学习数据进行存储;以及学习处理部228,使用存储在学习数据存储部226的学习数据进行第二过滤处理部178的学习。在本实施方式中,从9500个正例学习数据生成了16094个反例的学习数据。因此,学习数据成为合计25594个。基于学习数据生成部224的学习数据的生成以如下方式进行,即,通过日本语修饰关系分析工具(j.depp)进行各提问句的依赖构造分析,并将得到的依赖构造树变换为词组构造树。在该变换中,使用了如下这样的简单的规则。在依赖构造树中,作为依赖构造树的各短语的父节点,如果各短语的核心词为名词,则追加np(名词性短语),如果是动词或形容词,则追加vp,除此以外,追加op,由此变换为词组构造树。从该词组构造树提取了上述子集树的特性。再次参照图2,对图2所示的反复控制部110的功能进行说明。反复控制部110具有如下功能,即,直到俱备给定的结束条件为止,反复执行基于图2的提问发行部100、回答候补过滤部102、回答候补判定部104、学习数据生成/标记部106、以及学习数据选择部108的处理。反复控制部110能够由计算机硬件和计算机软件来实现。参照图6,实现反复控制部110的程序包含:步骤250,在启动后,进行存储器区域的确保、客体的生成等准备处理;步骤252,将0代入到反复控制变量i;以及步骤254,直到与变量i相关的结束条件成立为止(具体地,直到变量i达到预先确定的上限数为止),反复执行以下的处理256。另外,在以下的说明中,为了表示是反复的第i次的数据,在各记号的右上角附上小写的i。另外,在以下的说明中,将从提问发行部100对为什么型提问应答系统60提供的提问设为q,将针对该提问q的预想回答设为e,设针对该提问q从为什么型提问应答系统60返回的回答候补有多个(具体地,20个),并将它们设为回答候补pj(j=1~20)。对各回答候补附加了基于排序部122的排序的得分s。排序部122在本实施方式中由svm实现。因此,得分s的绝对值q表示从svm的识别边界到回答候补的距离。该距离越小,回答的可信度越低,该距离越大,可信度越高。在由提问q和回答候补pj构成的配对之中,将得分s最大的配对用(q′,p′)来表示。此外,反复的第i个学习数据用li来表示,并用ci来表示利用该学习数据li进行了学习的排序部122的分类器。将尚未附加正例、反例的标记这样的配对称为无标记配对。处理256包含:步骤270,学习处理部66用存储在图2所示的学习数据存储部64的学习数据li进行图2所示的排序部122的分类器ci的学习。处理256还包含:步骤272,在步骤270之后,将保存在提问/预想回答存储部76的各提问句提供给回答候补检索部120,其结果,根据从排序部122发送过来的应答,对由提问和回答候补构成的无标记配对之中适合于作为学习数据的一部分配对附加正例/反例的标记。关于步骤272的处理内容,将在后面参照图7进行叙述。对于一个提问q,多个(在本实施方式中,为20个)回答候补从排序部122发送到回答候补过滤部102。当将除提问q以及预想回答e以外还由来自排序部122的回答候补pj(j=1~20)构成的三元组(q,e,pj)用u表示,并将针对一个提问q通过步骤272的处理得到的数据的集合设为lui时,可表示为lui=label(ci,u)。在步骤272中,对存储在提问/预想回答存储部76的全部的提问/预想回答配对执行该处理。处理256还包含:步骤274,在针对全部提问通过步骤272得到的全部的标记后的配对lui之中,将其得分处于上位的k个配对追加到学习数据li而生成新的学习数据li+1;以及步骤276,对变量i的值加1并结束处理256。参照图7,实现图6所示的步骤272的程序包含:步骤300,在由从提问发行部100对为什么型提问应答系统60提供的提问q和针对该提问q从为什么型提问应答系统60发送来的20个回答候补pj中的每一个构成的无标记配对(q,pj)之中,选择得分s最大的配对(q′,p′);以及步骤302,判定在步骤300中选择出的配对(q′,p′)的得分s的绝对值是否小于给定的阈值α(>0),若判定为否定,则不作任何操作而结束该例行程序的执行。像这样,在本实施方式中,针对应答候补中的得分s最大且其值小于阈值α的应答候补,判断为基于为什么型提问应答系统60的应答不可信,并追加针对该例子的学习数据。该程序还包含:步骤304,在步骤302的判定为肯定时,判定回答候补p′是否包含得到了提问q′的原来的因果关系表现,若判定为肯定,则结束该例行程序的执行;以及步骤306,在步骤304的判定为否定时,判定配对(q′,p′)是否存在于当前的学习数据中,若判定为肯定,则结束该例行程序的执行。步骤304的判定是为了使得不会对得到了因果关系表现的段落施加过大的偏倚。步骤306的判定是为了使得不会将相同的例子加入到学习数据中。该程序还包含:步骤308,在步骤306的判定为否定时,算出回答候补p′与针对提问q′的预想回答e′之间的重复词汇量w1、以及回答候补p′与提问q′之间的重复词汇量w2;步骤310,判定在步骤308中算出的重复词汇量w1以及w2是否均大于给定的阈值a,并根据判定结果使控制的流程分支;步骤312,在步骤310的判定为肯定时,对配对(q′,p′)附加表示正例的标记并作为追加学习数据而进行输出,结束该例行程序的执行;步骤311,在步骤310的判定为否定时,判定重复词汇量w1以及w2是否均小于给定的阈值b(b<a),并根据判定结果使控制的流程分支;以及步骤314,在步骤311的判定为肯定时,对配对(q′,p′)附加表示反例的标记并作为追加学习数据而进行输出,结束该例行程序的执行。在步骤311的判定为否定时,不进行任何操作,该例行程序结束。预想回答e′是从得到了提问q′的因果关系表现的原因部分得到的。因此,认为预想回答e′作为提问q′的回答是相称的。假设在预想回答e′与回答候补p′的重复词汇量大的情况下,认为回答候补p′作为针对提问q′的回答是相称的。一般来说,预想回答e与回答候补p之间的重复词汇量tm(e,p)可通过以下的式子算出。[数学式1]在此,t(x)是由句子x所包含的内容词语(名词、动词、形容词)构成的集合,s(p)是由构成回答候补p的段落之中的连续的两个句子构成的集合。另外,虽然在以上的例子中,在步骤310中,针对重复词汇量w1以及w2,与相同的阈值a进行了比较,但是本发明并不限定于那样的实施方式。针对重复词汇量w1和w2,也可以与相互不同的阈值进行比较。在步骤311中,针对与重复词汇量w1以及w2进行比较的阈值b也是同样的,也可以相互将重复词汇量w1以及w2与相互不同的阈值进行比较。此外,虽然在步骤310以及步骤311中,在两个条件均成立时判定为作为整体俱备条件,但是也可以是只要两个条件中的任一个成立,就判定为作为整体俱备条件。[动作]该训练系统50像以下那样动作。参照图2,预先在网页语料库存储部68收集许多的文件。回答候补检索部120将作为被认为与所提供的各提问相称的回答候补的段落从网页语料库存储部68根据tf-idf进行排序,并提取tf-idf处于上位的给定个数(在本实施方式s中,为1200个)而提供给排序部122。在学习数据存储部64中准备了初始的学习数据。因果关系表现提取部70从网页语料库存储部68提取许多的因果关系表现,并保存到因果关系表现存储部72。提问/预想回答生成/提取部74从存储在因果关系表现存储部72的许多的因果关系表现提取提问与针对该提问的预想回答的组,并保存到提问/预想回答存储部76。参照图4,此时,提问/预想回答生成/提取部74像以下那样动作。首先,图4所示的补充处理部172针对存储在因果关系表现存储部72的因果关系表现的每一个检测呼应关系、省略等,并对这些呼应关系、省略语等进行增补,从而对因果关系表现的、特别是结果部分中不足的部分(主语、主题等)进行补充。提问句生成部174参照规则存储部170针对因果关系表现的结果部分应用适当的变形规则来生成为什么型提问句。第一过滤处理部176将由提问句生成部174生成的提问句之中包含代词的提问句过滤掉,将除此以外的提问句输出到第二过滤处理部178。第二过滤处理部178将谓语的自变量之中必需的自变量所不存在的提问过滤掉,并将除此以外的提问提供给预想回答生成部180。预想回答生成部180对得到了第二过滤处理部178所输出的提问的因果关系表现的原因部分应用存储在规则存储部182的变形规则,生成针对该提问的预想回答,并与提问作为组而保存在提问/预想回答存储部76。另外,在此之前,需要由图5所示的第二过滤学习部202进行第二过滤处理部178的学习。参照图5,反例学习数据生成部220在存储在正例学习数据存储部200的正例学习数据的各提问句中,删除主语或宾语、或这两者,由此自动地生成反例的学习数据。所生成的反例的学习数据保存到反例学习数据存储部222。学习数据生成部224将存储在正例学习数据存储部200的正例和存储在反例学习数据存储部222的反例合并,生成第二过滤处理部178用的学习数据。学习数据存储到学习数据存储部226。学习处理部228使用该学习数据进行第二过滤处理部178的学习。以下,通过以下的反复来进行为什么型提问应答系统60的排序部122的训练。参照图2,最初,通过反复控制部110的控制,学习处理部66使用存储在学习数据存储部64的初始的学习数据进行排序部122的学习。接着,反复控制部110对提问发行部100进行控制,依次选择保存在提问/预想回答存储部76的提问q,并提供给回答候补检索部120。回答候补检索部120将作为被认为与所提供的各提问相称的回答候补的段落从网页语料库存储部68根据tf-idf进行排序,并提取tf-idf处于上位的给定个数(在本实施方式中,为1200个)而提供给排序部122。排序部122从各段落提取给定的特征量,并通过进行了基于学习处理部66的学习的分类器进行打分,选择上位20个来附加得分并发送到回答候补过滤部102。回答候补过滤部102当接受回答候补时,从提问/回答候补的配对(q,pj)(j=1~20)选择包含得分s处于最上位的回答候补p′的配对(q′,p′)(图7,步骤300),如果该得分不小于阈值α(在步骤302中“否”),则废弃该配对,并转移到针对下一个提问的处理。如果得分小于阈值α(在步骤302中,“是”),则接着判定回答候补p′是否包含得到了提问q′的因果关系表现(步骤304)。若判定为肯定(在步骤304中“是”),则结束针对该提问的处理,并转移到下一个提问的处理。若判定为否定(在步骤304中“否”),则在步骤306中判定配对(q′,p′)是否存在于当前的学习数据中。若判定为肯定(在步骤306中“是”),则结束针对该提问的处理并转移到针对下一个提问的处理。若判定为否定(在步骤306中“否”),则在步骤308中通过式(1)分别算出回答候补p′与预想回答e之间的重复词汇量w1、回答候补p′与提问q′之间的重复词汇量w2。接下来,在步骤310中,判定重复词汇量w1以及w2是否均大于给定的阈值a。若判定为肯定,则对配对(q′,p′)附加表示正例的标记并作为追加学习数据而进行输出。若判定为否定,则控制推进到步骤311。在步骤311中,判定重复词汇量w1以及w2是否均小于给定的阈值b(b<a)。若判定为肯定,则对配对(q′,p′)附加表示反例的标记并作为追加学习数据而进行输出。若判定为否定,则不进行任何操作而结束该处理。这样,当针对存储在图2的提问/预想回答存储部76的提问/预想回答的处理结束时,由训练装置62选择出的新的学习数据与正例/反例的标记一同存储到学习数据选择部108中。学习数据选择部108在这些新的学习数据之中选择得分处于上位的k个并追加到学习数据存储部64。反复控制部110对反复变量i加1(图6的步骤276),并判定是否俱备结束条件。如果不俱备结束条件,则再次使用存储在学习数据存储部64的更新后的学习数据,通过反复控制部110的控制由学习处理部66执行排序部122的学习。由此,排序部122的分类器通过基于使用存储在因果关系表现存储部72的因果关系表现而得到的学习数据的学习被强化。通过俱备反复的结束条件,从而以上的反复结束,得到由使用存储在因果关系表现存储部72的因果关系而得到的学习数据进行了强化的排序部122,其结果是,基于为什么型提问应答系统60的应答的精度提高。[实验]为了确认上述实施方式的效果,准备了由850个日本语的为什么型提问和针对这些提问从6亿日本语网页提取出的前20的回答候补段落构成的实验集。该实验集是通过由murata等(masakimurata,sachiyotsukawaki,toshiyukikanamaru,qingma,andhitoshiisahara.2007.asystemforansweringnon-factoidjapanesequestionsbyusingpassageretrievalweightedbasedontypeofanswer.inproceedingsofntcir-6.)提出的提问应答系统得到的。针对它们中的每一个,通过人工确认了是否为正确的提问-回答配对。在实验中,将该实验集分割为学习集、开发集、以及测试数据集。学习集由15000个提问-回答配对构成。剩余的2000个实验数据由100个提问和针对它们的回答(各20个)构成,二等分为开发集和测试集。将上述的学习数据用作初始学习数据而进行了排序部122的反复学习。开发集为了决定阈值α、重复词汇量的阈值β而使用,进而,为了决定每次反复时追加到学习数据的新的数据数k而使用。针对满足α∈{0.2,0.3,0.4}、β∈{0.6,0.7,0.8}、以及k∈{150,300,450}的α、β以及k的组合,用开发数据进行了实验,其结果是,在α=0.3、β=0.7、k=150的组合下得到了最好的结果。在以下所述的实验中,使用了该α、β以及k的值的组合。反复次数设定为40。这是因为,相对于开发集的、基于上述α、β以及k的组合的学习数据在该反复次数的附近收敛。评价使用测试集来进行。在实验中,以从存储了20亿个文件的网页语料库自动地提取出的6亿5600万个因果关系表现为基础,选择出相当于其60分之一的1100万个因果关系表现。从它们之中选择了自身完整型的提问及其预想回答的组合。该数量为56775个。将这些提问输入到为什么型提问应答系统60,并针对各提问接受20个上位回答候补,使用它们生成了无标记的提问-回答候补配对(无标记配对)。为了比较,最初从上述的1100万个因果关系表现随机地提取了10万个因果关系表现。从它们的全部生成提问,并全部生成无标记配对而进行使用。将这两个类型称为usc(仅从自身完整型的提问生成的无标记配对)以及uall(从还包含自身完整型以外的提问生成的无标记配对)而相互进行区分。|usc|=514674,|uall|=1548998,|usc∩uall|=17844。将比较结果示于下表。[表1]p@1mapoh4246.5atonce4245.4ours(uai)3441.7ours(usc)5048.9upperbound6666oh是进行了基于初始学习数据的学习的结果。atonce表示将在实施方式的第一次的反复中得到的全部的附带标记的数据追加到学习数据时的性能。通过对该结果和后述的ours(usc)进行比较,从而反复的效果变得明确。ours(uall)是上述实施方式的变形例,是将以上所述的uall用作无标记配对的结果。通过与ours(usc)进行比较,可知在本实施方式中仅使用自身完整型的提问所带来的效率的良好程度。ours(usc)是基于上述实施方式的结果。upperbound是如下的系统,即,只要对全部的提问在测试集之中存在n个正确的回答,就在前n个的回答候补之中必然可得到正确的回答。该结果示出本实验的性能的上限。在除upperbound以外的全部的系统中,为了进行分类器的学习,使用了线性内核的tinysvm。使用最前的回答(p@1)以及平均精度均值(map)来进行评价。p@1表示在基于系统的最前的回答之中可得到何种程度的数量的正解。平均精度均值表示前20的整体的品质。表1示出该评价的结果。根据表1,atonce和ours(uall)均未能示出超过oh的结果。在本发明的实施方式涉及的结果(ours(usc))中,在p@1中和map中均稳定地示出了优于oh的结果。该结果表示:上述实施方式中的反复的结果对于性能提高是重要的;以及仅使用自身完整型的提问句对于性能提高是重要的。进而,若将ours(usc)的p@1的结果与upperbound进行比较,则可知示出75.7%这样的值。由此可认为,只要存在从网页取出至少一个正确的回答的回答检索模块,就可通过上述实施方式以高精度对为什么型提问找到正确的回答。在图8,在反复次数=0至50的范围示出ours(uall)和ours(usc)的、反复次数与精度的关系。在本申请实施方式涉及的ours(usc)中,在50次的反复学习之后,在p@1(曲线图350)和map(曲线图360)中,精度分别达到了50%和49.2%。在p@1的情况下,在38次收敛。ours(uall)(p@1用曲线图362表示,map用曲线图364表示。)在最初的阶段的几次反复中示出了比ours(usc)高的性能,但是随着反复增多,相对地,性能变低。认为这大概是自身完整型的提问以外的提问作为噪声对性能带来了不良影响。[表2]p@1p@3p@5oh43.065.071.0ours(usc)50.068.075.0进而,进行用上述本发明的实施方式涉及的装置进行了学习的提问应答系统(ours(usc))和仅使用初始学习数据进行了学习的提问应答系统(oh)的性能比较。学习的对象在任一情况下均为提问应答系统的排序部122的分类器。在实验中,使得针对开发集的100个提问的每一个得到前5的回答段落。3位评价员对这些提问-回答的配对进行检查,并通过多数表决判定了其正误。评价以p@1、p@3、以及p@5进行。在此,所谓p@n,是指在前n个回答候补之中存在正确的回答的比率。在表2示出其结果。根据表2的结果可知,根据本发明的实施方式,在p@1、p@3、以及p@5中的任一个中都示出比通过oh得到的结果更好的结果。[实施方式的效果]如上所述,根据本实施方式,从存储在网页语料库存储部68的大量的文件提取许多的因果关系表现。从该因果关系表现选择许多的提问q与预想回答e的配对。将选择出的配对之中的提问q提供给为什么型提问应答系统60,并从为什么型提问应答系统60接受多个(p1~p20)针对提问的回答候补p。对于各回答候补pj,附加由作为本系统的训练对象的排序部122的分类器给出的得分s。选择得分s最高的回答候补与提问的配对(q′,p′),并仅在该配对满足以下的条件时,采用该回答候补。(1)回答候补p′的得分s小于阈值α(>0)。(2)该回答候补p′不包含得到了提问q′的因果关系表现。(3)在当前的学习数据中没有配对(q′,p′)。仅将俱备这样的条件的配对(q′,p′)之中、重复词汇量的得分处于上位的k个配对追加到学习数据。此时,基于针对提问q′的预想回答e′和回答候补p′的重复词汇量,判定该配对是否为正例,并根据其结果,对学习数据附加表示正例或反例的记号。因此,在学习数据中,重点追加原来的基于排序部122的判定的可信度低的数据。通过针对所得到的全部因果关系表现反复进行给定次数的这样的学习,从而能够扩充与可信度低的部分相关的学习数据。而且,虽然提问应答系统的分类器的初始学习数据需要通过人工进行准备,但是无需通过人工来准备应追加的学习数据,能够以低成本高效地作成大量的学习数据。其结果是,能够在尽可能不经由人工的情况下提高利用该学习数据进行了学习的排序部122的分类器的精度。另外,在上述的实施方式中,在提问/预想回答存储部76中存储有从由存储在网页语料库存储部68的大量的文件提取出的因果关系自动地作成的提问和预想回答的配对。但是,本发明并不限定于那样的实施方式。存储在提问/预想回答存储部76的提问与预想回答的配对的来源可以是任意的。此外,不仅是自动地生成的配对,还可以与自动地收集了通过人工作成的提问和预想回答后得到的配对一起存储在提问/预想回答存储部76。此外,在上述实施方式中,使基于回答候补检索部120的反复在反复数达到上限数时结束。但是,本发明并不限定于那样的实施方式。例如,也可以在没有了要追加到学习数据存储部64的新的学习数据的时间点结束反复。进而,在上述实施方式中,在图7的步骤300中,选择一个得分最大的配对。但是,本发明并不限定于那样的实施方式。也可以选择两个以上的给定个数的得分最大的得分。在该情况下,只要对各配对分别进行步骤302至步骤314的处理即可。[基于计算机的实现]上述实施方式涉及的训练装置62能够由计算机硬件和在该计算机硬件上执行的计算机程序实现。图9示出计算机系统930的内部结构。参照图9,该计算机系统930包含:具有存储器端口952以及dvd(digitalversatiledisc)驱动器950的计算机940、键盘946、鼠标94、以及监视器942。计算机940除了存储器端口952以及dvd驱动器950以外,还包含:cpu(中央处理装置)956;与cpu956、存储器端口952以及dvd驱动器950连接的总线966;对引导程序等进行存储的读出专用存储器(rom)958;以及与总线966连接并对程序命令、系统程序、以及工作数据等进行存储的随机存取存储器(ram)960。计算机系统930还包含提供对使得能够进行与其它终端(例如,图2所示的为什么型提问应答系统60、实现学习数据存储部64以及66的计算机、实现提问/预想回答存储部76的计算机等)的通信的网络的连接的网络接口(i/f)944。网络i/f944也可以与互联网970连接。用于使计算机系统930作为构成上述的实施方式的训练装置62的各功能部起作用的计算机程序存储在安装于dvd驱动器950或存储器端口952的dvd962或移动式存储器964,进而转发到硬盘954。或者,程序也可以通过网络i/f944发送到计算机940并存储到硬盘954。程序在执行时载入到ram960。也可以从dvd962、从移动式存储器964、或者经由网络i/f944直接将程序载入到ram960。该程序包含用于使计算机940作为上述实施方式涉及的训练装置62的各功能部起作用的多个命令。进行该动作所需的基本的功能中的几个功能由在计算机940上动作的操作系统(os)或者第三方的程序、或安装在计算机940的各种编程工具集的模块来提供。因此,该程序未必一定要包含实现该实施方式涉及的训练装置62所需的全部功能。该程序只要仅包含命令之中的如下命令即可:即,通过以控制为可得到所希望的结果的做法调用适当的功能或编程工具集内的适当的程序工具,从而实现作为上述系统的功能的命令。计算机系统930的动作是众所周知的。因此,在此不再重复。此次公开的实施方式仅是例示,本发明并不仅限制于上述的实施方式。本发明的范围在参考发明的详细的说明的记载的基础上由权利要求书的各权利要求示出,包含与在权利要求书中记载的语句等同的意思以及范围内的所有的变更。产业上的可利用性本发明能够应用于对提问应答服务的提供,该提问应答服务通过提供针对为什么型提问的回答,从而对参与研究、学习、教育、兴趣、生产、政治、经济等的企业以及个人做出贡献。附图标记说明50:训练系统;60:为什么型提问应答系统;62:训练装置;64:学习数据存储部;66:学习处理部;68:网页语料库存储部;70:因果关系表现提取部;72:因果关系表现存储部;74:提问/预想回答生成/提取部;76:提问/预想回答存储部;100:提问发行部;102:回答候补过滤部;104:回答候补判定部;106:学习数据生成/标记部;108:学习数据选择部;110:反复控制部;120:回答候补检索部;122:排序部。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1