基于卷积神经网络的显著信息检测方法及装置与流程
本发明涉及计算机处理技术领域,尤其涉及一种基于卷积神经网络的显著信息检测方法及装置。
背景技术:
社交媒介网络的快速发展,应用广泛且易于获取,一方面极大程度上方便了用户的生活,丰富了用户的体验,但同时,社交媒介网络上的不实信息传播也会扰乱人们的正常生活,误导舆情,危害公共安全和社会稳定。因此从海量的社交媒介网络信息中鉴别出不实信息的任务变得越来越重要和紧迫,不实信息的早起检测也变得更加实用和有效。
现有的不实信息鉴别的方法主要是一些特征工程的方法,所提取的手工特征可以源自以下几个方面,用户可信度,微博层次的内容,事件层次的内容以及从微博层次向事件层次的聚合。所提取的手工特征大致可以分为以下几类,微博中的冲突观点,微博转发数量随时间的变化特征,微博回复和包含怀疑态度等的信号微博。但是这些基于手工特征的方法都很难涉及到新出现的情形,而社交媒体是动态的,可变的,复杂的,会产生很多手工特征难以设计到的新情形。
CSID模型能够根据社交媒体上面用户生成内容和生成时间来检测一些显著的信息,包括但不限于谣言信息的鉴别和早期检测。一般地,微博事件会包含几千条相关的微博,而且微博的热度差异巨大。首先对于数据集上面的不实信息和真实信息,统计它们的时间特性,这里指微博随时间的幂律分布特点。然后模型将事件涉及到的微博根据对应的时间特性分组处理。对于不同组的微博文本,模型引入了表征学习方法(representation learning method),运用段落分布式表达学习算法(paragraph vector),学习每一组微博文本的表达。最后用深层卷积神经网络,建模各组微博之间的高阶交互,进行从低阶特征向高阶特征学习的过程,学习事件发生各个阶段的隐含表达(latent representation),并且提取重要的因素。基 于这些隐含表示,模型事件的最终表达并在不实信息的检测和早期检测上面做出了创新贡献。
技术实现要素:
鉴于传统基于人工特征的方法存在技术缺陷,为了更好检测信息可信度,本发明提供一种基于卷积神经网络的显著信息检测方法及装置。
根据本发明一方面,提供了一种基于卷积神经网络的显著信息检测方法,包括以下步骤:
步骤S1,对于所爬取的包括多个事件信息的的数据集,确定所述数据集中的事件信息对应的每个事件发展各个阶段的时间分布,并确定各个时间段对应的时间节点;所述数据集中的事件信息包括不实事件信息和真实时间信息,且所述事件信息对应多个事件,每个事件对应多个不实事件信息或多个真实事件信息;
步骤S2,对于每一个事件,根据所确定的时间节点将所述事件样本对应的所有的事件信息分成若干份,将每一个时间阶段内事件信息的文本内容拼接成一个段落,生成段落数据集;
步骤S3,根据段落的分布表达算法学习所述段落数据集中每个段落的无监督表达向量;
步骤S4,对于一个事件,将每个段落的无监督表达向量输入到深度卷积神经网络模型,利用多层卷积操作得到事件各个阶段的底层到高层的表达,通过k最大池化操作充分地提取事件各个阶段的关键特征,最后通过一个全连接层对输入的信息进行不实信息的分类;利用所有事件对所述深度卷积神经网络模型进行步骤S4的上述训练之后,得到显著信息检测模型;
步骤S5,利用所述显著信息检测模型对待检测信息进行分类检测。
步骤S1包括:
确定所述事件对应的所有事件信息的时间戳;
对于每一事件,按照时间先后顺序对所述时间戳进行排序;
将最早时间戳和最晚时间戳对应的时间等分成多个时间段;
确定所述多个时间段对应的时间节点。
步骤S2包括:
对于每一事件,根据步骤S1中确定的多个时间段以及该事件对应的事件信息的时间戳,将该事件对应的事件信息划分到不同的时间段;
将每一个时间段内的事件信息的文本内容拼接成一个段落,得到多个时间段对应的多个段落,组成段落数据集。
步骤S3包括:
将所述段落数据集看成一个语料库,分别在词级别和段落级别上,运用无监督词和段落的分布式表达学习算法学习得到每个段落的无监督表达向量。
步骤S4包括:
对于每一个事件,将所有段落的无监督向量表达式拼接成一个矩阵;
将所述矩阵输入至深度卷积神经网络模型进行训练。
根据本发明第二方面,提供了一种基于卷积神经网络的显著信息检测装置,包括以下步骤:
时间节点确定模块,被配置为对于所爬取的包括多个事件信息的的数据集,确定所述数据集中的事件信息对应的每个事件发展各个阶段的时间分布,并确定各个时间段对应的时间节点;所述数据集中的事件信息包括不实事件信息和真实时间信息,且所述事件信息对应多个事件,每个事件对应多个不实事件信息或多个真实事件信息;
段落生成模块,被配置为对于每一个事件,根据所确定的时间节点将所述事件样本对应的所有的事件信息分成若干份,将每一个时间阶段内事件信息的文本内容拼接成一个段落,生成段落数据集;
向量生成模块,被配置为根据段落的分布表达算法学习所述段落数据集中每个段落的无监督表达向量;
模型训练模块,被配置为对于一个事件,将每个段落的无监督表达向量输入到深度卷积神经网络模型,利用多层卷积操作得到事件各个阶段的底层到高层的表达,通过k最大池化操作充分地提取事件各个阶段的关键特征,最后通过一个全连接层对输入的信息进行不实信息的分类;利用所有事件对所述深度卷积神经网络模型进行步骤S4的上述训练之后,得到显著信息检测模型;
检测模块,被配置为利用所述显著信息检测模型对待检测信息进行分类检测。
所述时间节点确定模块:
第一确定子模块,被配置为确定所述事件对应的所有事件信息的时间戳;
排序子模块,被配置为对于每一事件,按照时间先后顺序对所述时间戳进行排序;
等分子模块,被配置为将最早时间戳和最晚时间戳对应的时间等分成多个时间段;
第二确定子模块,被配置为确定所述多个时间段对应的时间节点。
所述段落生成模块包括:
时间段划分子模块,被配置为对于每一事件,根据确定的多个时间段以及该事件对应的事件信息的时间戳,将该事件对应的事件信息划分到不同的时间段;
段落生成子模块,被配置为将每一个时间段内的事件信息的文本内容拼接成一个段落,得到多个时间段对应的多个段落,组成段落数据集。
所述向量生成模块包括:
无监督学习子模块,被配置为将所述段落数据集看成一个语料库,分别在词级别和段落级别上,运用无监督词和段落的分布式表达学习算法学习得到每个段落的无监督表达向量。
所述模型训练模块包括:
拼接子模块,被配置为对于每一个事件,将所有段落的无监督向量表达式拼接成一个矩阵;
训练子模块,被配置为将所述矩阵输入至深度卷积神经网络模型进行训练。
附图说明
图1是本发明中基于卷积神经网络的显著信息检测模型CSID的的示意图;
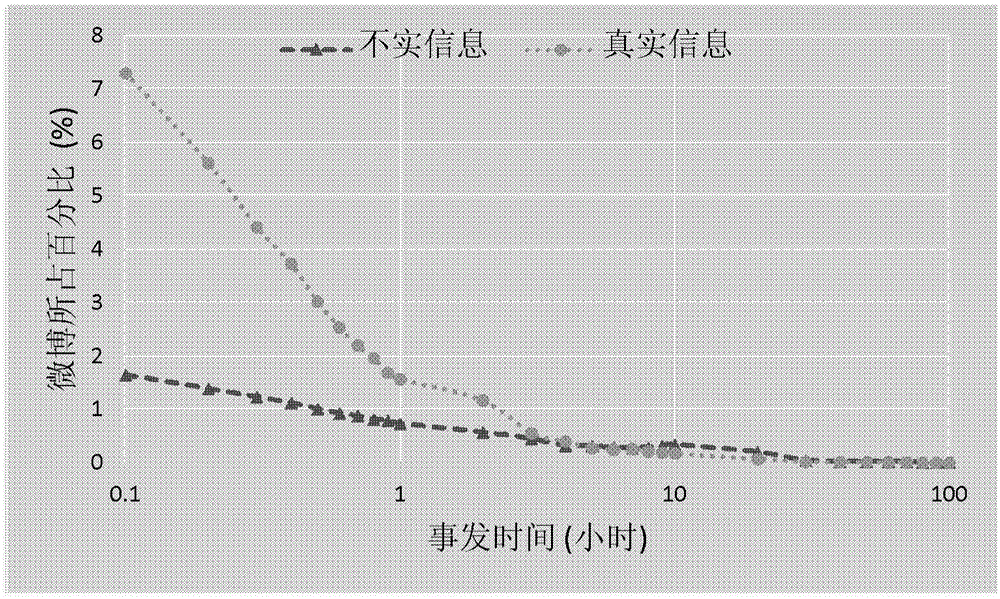
图2是本发明中微博数据集上不实信息和真实信息的幂律分布图示;
图3是不同的对比方法在微博数据集上早期检测效果对比示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
本发明公开一种基于卷积神经网络的显著信息检测模型(Convolutional Salient Information Detection,简称CSID)的训练方法,可用于社交媒介网络中的不实信息鉴别和早期检测任务中。模型可以学习包含不同数量级微博的事件整体表达。同时CSID还可以根据事件发展的时间特征建模事件发展各个阶段,从底层到高层的语义表达,并通过灵活地k最大池化操作选择关键的特征,输送到最后的全连接层进行社交媒介网络信息的分类学习。在模型中,每个事件包含的所有微博都根据事件发展的时间阶段分成若干组,每组微博学习一个表达后送到一个深度卷积神经网络,最后输出这个时间属于不实信息的概率。CSID模型建立:1)对于所爬取的大量的不实信息和真实信息的数据集,从整体上研究事件发展各个阶段的时间分布,依此确定各个时间段对应的时间节点;2)对于每一个事件样本,根据之前确定的时间节点将所有的微博分成若干份,将每一个时间阶段内微博的文本内容拼接成一个段落;3)将整体数据集生成段落根据段落的分布表达算法学习每个段落的无监督表达向量;4)对于一个事件样本,将每个阶段的表达向量输入到深度卷积神经网络模型,利用多层卷积操作得到事件各个阶段的底层到高层的表达,通过灵活地k最大池化操作充分地提取事件各个阶段的关键特征,最后通过一个全连接层对输入的信息进行不实信息的分类;5)在测试集上,通过梯度反传,对卷积核和梯度进行了可视化实验,对模型学习到的显著信息进行了深入的分析和论证。在新浪微博数据集和推特数据集的实验上,获得比其他现有模型更准确的预测效果。
如图1所示,本发明实施例提供了一种基于卷积神经网络的显著信息检测方法,该方法包括:
接收待分类信息;
将所述待分类信息输入至预先训练好的显著信息检测模型;
所述显著信息检测模型输出所述待分类信息为真实信息或不实信息的结果。
在一实施例中,所述显著信息监测模型先根据已有数据将模型训练好,获取了已经训练好的模型后,对于新出现的信息,也经过类似的操作将新信息输入到模型中去,然后模型会输出一个概率值,表示输入信息属于不实信息的概率,输出值越大,输入信息越有可能是不实信息。
以下结合附图详细说明本发明技术方案中所涉及的各个细节问题。应当指出的是,所描述的实施例仅旨在便于理解,对本发明不起任何限定作用。
为了更好地理解CSID模型在不实信息检测中作用,以及验证本发明的实施效果,接下来以实验为例进行说明,本示例采用新浪微博数据库。实验数据集分为60%训练集,30%测试集和10%验证集。
实验包含四个评价指标准确率(Accuracy),精确率(Precision),召回率(Recall)和F1-score。研究对象分别为不实信息和真实信息时分别计算了Precision和Recall来显示模型检测两种信息的能力。四种评价指标的值越大,模型的不实信息的检测性能越高。
如图1所示,在新浪微博数据集上具体实验步骤如下:
步骤S1,对于所爬取的大量的不实信息和真实信息的数据集,包含有多个事件E={ei},(对于一个事件,可以对应有多个信息来描述该事件,例如对于一件重大时间,会有很多条微博或新闻等信息来描述该事件),从整体上研究事件发展各个阶段的时间分布,首先收集所有事件对应的所有微博(此处以微博为例,也可以是其他信息)的时间戳(即该信息发布的时间点),按照时间先后顺序排列,然后将最早和最晚时间戳对应的时间段等分成M份(如M=20份),并依此确定各个时间段对应的时间节点,
Ti=[ti-1,ti),i=1,2,…,20.
其中Ti表示第i个时间阶段,ti-1和ti分别表示第i个时间阶段起始时间戳和终止时间戳。此外,还需要对各个时间节点进行归一化操作,将所得到的时间节点对应的时间戳归一化到0-1区间。
步骤S2,对于每一个包含有多条微博的事件样本首先将这个事件包含的所有微博的时间戳tj归一化到0-1区间,再根据S1确 定的时间节点将所有的微博分成若干份,将每一个时间阶段内微博的文本内容拼接成一个段落,即把微博的时间戳在第i个时间阶段Ti里的所有微博的内容都拼接成一个段落。
步骤S3,将S2中所有的微博内容文本数据集看做一个语料库,分别在词级别和段落级别上,运用无监督词和段落的分布式表达学习算法word2vec和para2vec,学习得到每个词和每个段落的表达向量,分别组成矩阵W,D。矩阵W和D中的每一列分别对应一个词和段落的表达向量。
其中N表示段落中的词数,上下文的窗宽为2k,即选择当前词前后各k个词作为上下文,算法主要是通过上下文的词语和段落表达向量中的记忆信息来最大化段落中所有词的联合条件分布概率p,概率p通过softmax计算得出。yi表示第i个词的输出响应,可由下式得出,
y=b+UTh(pj,wn-k,…wn+k;D,W)
其中pj为一个段落的向量表达,wn表示段落中的第n个词的向量表达,pj和wn分别是矩阵D和W中的某一列。b和U为softmax的参数,h为求平均值或者拼接操作。
步骤S4,对于一个事件样本,将S3中的段落表达向量pj拼接成一个矩阵其中d和n表示矩阵P的维度,输入到深度卷积神经网络模型,利用多层卷积操作得到事件各个阶段的底层到高层的表达,深度神经网络模型中的某一层的输出结果中称为一个特征图,神经网络的低层的输出结果称为低阶特征图,神经网络的高层的输出结果称为高阶特征图,特征图的某一个元素可以通过如下卷积操作得到,
f[i]=tanh(<P[:,i:i+ω-1],C>F)
其中P[:,i:i+w-1]表示矩阵E的第i到第(i+ω-1)列,ω表示卷积核的宽度,C表示卷积权重矩阵。求矩阵乘积后的迹的操作可以表示为Frobenius内积操作,如下:
<X,Y>F=Tr(XYT)
通过灵活地k最大池化操作充分地提取事件各个阶段的关键特征,即提取特征图中k个最大的元素作为新的特征图。最后通过一个全连接层对输入的信息进行不实信息的分类。
深度卷积神经网络模型可以先随机初始化,再经过S4不断训练,更新模型的参数。
步骤S5,在测试集上,通过梯度反传,得到输出标签对于输入的梯度矩阵,对于输入矩阵做显著性分析得到对应输入中起到显著作用的微博内容。另外对第一个卷积层的卷积核进行了深入的可视化分析,得到事件中显著的微博内容的分布特点。
图2是本发明中微博数据集上不实信息和真实信息的幂律分布图示;如图2所示的数据集中,对于真实信息和不实信息,不同阶段微博数所占的比例随时间的变化情况,反应了微博数随时间的幂律分布情况。图3表示了不实信息的早期检测的实验结果。
表1 表示了Twitter和Weibo数据集中的属性统计信息
表2:不实信息鉴别(M:不实信息,T:真实信息)
表2表示了所提出的CSID方法与现有的其他方法的实验结果比较
本发明提出的上述模型揭示了社交媒介网络中事件包含的微博数量随时间的幂律分布规律,并且依据此规律采用整体等分确立事件各个阶段的时间节点,然后根据这些时间阶段对每一个事件进行切分,这样不仅保证每一个时间间隔内有大致相同数目的微博数目,而且能够从整体上保证所有事件共用一个时间尺度。模型能够学会事件更加真实的表达,而且能够充分挖掘和利用信息分布的时间规律。利用多层卷积操作得到事件各个阶段的底层到高层的表达,能够充分建模事件各个阶段的高阶交互和深层语义表达;通过灵活地k最大池化操作充分地提取事件各个阶段的关键特征,使模型更能够适应于动态复杂的社交媒介场景。
本发明涉及基于卷积神经网络的显著信息检测任务,,特别针对信息数量规模大,时间跨度差异明显,语义场景复杂,用户行为动态多变等真实的社交媒介场合,显著信息检测能获得更准确的检测效果。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!