一种基于深度相机和3D卷积神经网络的步态识别方法与流程
本发明是一种基于深度相机和3d卷积神经网络的步态识别方法,涉及图像处理、模式识别、深度传感器、深度学习等技术领域。
背景技术:
步态识别是一种生物特征识别技术,能够根据视频序列中行人走路的姿态识别行人身份;与传统的指纹、人脸、虹膜等生物识别技术相比,具有非接触识别、易于隐藏,采集方便等优势,尤其适用于远距离场景下的目标识别任务。深度相机是一种能够同时记录rgb图像和深度图像的传感器,与传统相机相比,能够为目标识别任务提供更丰富、更立体的图像信息。卷积神经网络是一种常用的深度学习框架,随着深度学习在图像处理和模式识别方面的应用,卷积神经网络的研究和应用也越来越受到人们的重视,传统的2d卷积神经网络是以图像为输入数据,提取图像数据的空间分布特征,3d卷积神经网络是以连续的图像序列或视频序列为输入,能够同时提取输入数据在时间和空间的分布特征。深度相机和3d卷积神经网络结合应用将会显著提高步态识别的准确率。
技术实现要素:
本发明的目的在于提供了一种基于深度相机和3d卷积神经网络的步态识别方法,其特征在于,包括步骤:a)利用深度相机采集行人步态的rgb-d图像序列;b)获取每帧图像的步态剪影以及剪影对应的深度图像剪影;c)将每帧剪影图像和深度图像剪影组成双通道的步态图像;d)归一化步态图像序列;e)将步态图像序列输入3d卷积神经网络,前向传播并输出识别结果。
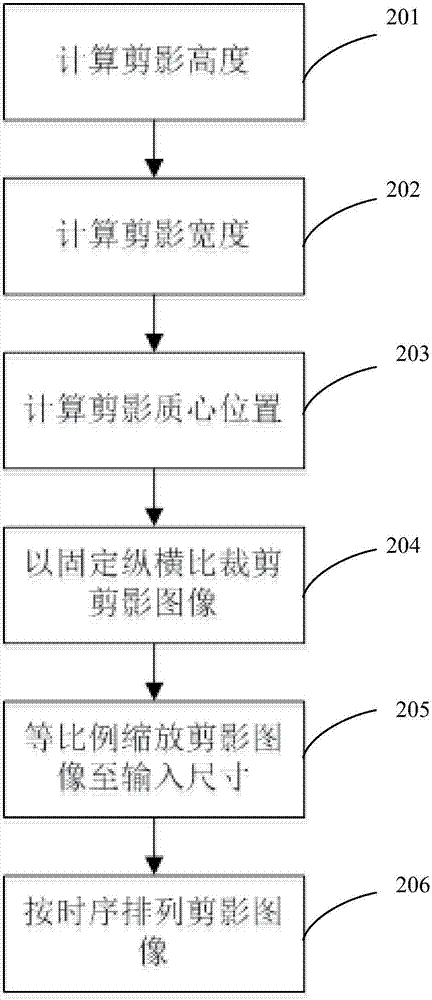
优选地,所述步骤d的具体步骤为:
d1)定位步态剪影的最上和最下像素点,从而计算步态剪影的高度h0;
d2)定位步态剪影的最左和最右像素点,从而计算步态剪影的宽度w0;
d3)根据步态剪影的高度和宽度,计算剪影的质心位置;
d4)给定一个纵横比r,以质心为中心,用w0×h0的矩形裁剪步态图像,其中w0=h0*r;
d5)将已裁剪的步态图像等比例缩放到3d卷积神经网络的输入尺寸;
d6)根据时间顺序将步态图像重组成步态序列i1,其维度为wi×hi×ci×m,w1,h1,c1,m1分别为i1的宽度,高度,通道数和序列帧数。
优选地,所述步骤e中3d卷积神经网络前向传播的步骤为:
e1)第一组3d卷积层,对步骤d)所得的图像序列进行3d卷积操作,卷积核大小为kw1×kh1×km1,步长为ks1,卷积核个数为kn1;其卷积输出为
其中v1j(x,y,s)表示第j个卷积核的第s个特征图在位置(x,y)处的值,b1j为第j个卷积偏移量,ω1j为第j个卷积权重,ω1j(α,β,γ)和i1(x,y,s)均为c1维向量;将每个卷积核对应的特征图归为一组,则该层共有kn1组特征图,每组(m1-km1)/ks1+1个特征图,每个特征图的尺寸为:
((w1-kw1)/ks1+1)×((h1-kh1)/ks1+1);
其输出维度为:
((w1-kw1)/ks1+1)×((h1-kh1)/ks1+1)×((m1-km1)/ks1+1)×kn1;
e2)第一组relu激活函数层,对步骤e1)的输出使用relu激活函数,其输出为:
e3)第一组3d池化层,对步骤e2)的输出进行最大值池化,核大小为2×2×2,步长为2,按照步骤e1)中的分组规则,池化层对每组特征图分别进行池化操作,其输出为:
p1j(x,y,s)=max{y1j(x+α,y+β,s+γ)|α,β,γ=0,1}
池化层的输出维度为:
((w1-kw1)/ks1+1)/2×((h1-kh1)/ks1+1)/2×((m1-km1)/ks1+1)/2×kn1
e4)第一组时序重构层,对步骤e3)的输出进行时序重构;按照步骤e1)所述,3d卷积层输入的图像序列是按照时序排列的,输出的特征图序列在每个分组内的特征图仍然是按照时序排列,不同分组之间的特征图不满足时序关系,而不同分组中相同位置的特征图处于同一时间节点;按照e3)所述,3d池化层的输出同样满足上述时序规则;为了使后续数据依然满足时序要求,将不同分组中同一位置的特征图组合在一起看作一幅多通道图像,并将这些图像按照时序排列;令该时序重构层的输出为i2,其维度为w2×h2×c2×m2,则:
i2(x,y,s,j)表示i2第s组第j个特征图在位置(x,y)处的值;
e5)第二组3d卷积层,对步骤e4)的输出进行3d卷积操作,卷积核大小为kw2×kh2×km2,步长为ks2,卷积核个数为kn2;其卷积输出为
其中v2j(x,y,s)表示第j个卷积核的第s个特征图在位置(x,y)处的值,b2j为第j个卷积偏移量,ω2j为第j个卷积权重,ω2j(α,β,γ)和i2(x,y,s)均为c2维向量;其输出维度为
((w2-kw2)/ks2+1)×((h2-kh2)/ks2+1)×((m2-km2)/ks2+1)×kn2;
e6)第二组relu激活函数层,对步骤e5)的输出使用relu激活函数,其输出为:
e7)第二组3d池化层,对步骤e6)的输出进行最大值池化,核大小为2×2×2,步长为2,其输出为:
p2j(x,y,s)=max{y2j(x+α,y+β,s+γ)|α,β,γ=0,1}
输出维度((w2-kw2)/ks2+1)/2×((h2-kh2)/ks2+1)/2×((m2-km2)/ks2+1)/2×kn2;
e8)第二组时序重构层,对步骤e7)的输出进行时序重构;令该时序重构层的输出为i3,其维度为w3×h3×c3×m3,则:
i3(x,y,s,j)表示i3第s组第j个特征图在位置(x,y)处的值;
e9)2d卷积网络,对步骤e8)的输出进行2d卷积和分类识别,采用裁剪的vgg16网络,具体方案为:删除conv1_1~pool2的网络结构,i3作为conv3_1的输入,fc8的维度与类别数目一致。应当理解,前述大体的描述和后续详尽的描述均为示例性说明和解释,并不应当用作对本发明所要求保护内容的限制。
附图说明
参考随附的附图,本发明更多的目的、功能和优点将通过本发明实施方式的如下描述得以阐明,其中:
图1示出了根据本发明的一种基于深度相机和3d卷积神经网络的步态识别方法的流程图;
图2示出了根据本发明的一种基于深度相机和3d卷积神经网络的步态识别方法中归一化步态图像序列的流程图;
图3示出了根据本发明的一种基于深度相机和3d卷积神经网络的步态识别方法中3d卷积神经网络的结构图。
具体实施方式
通过参考示范性实施例,本发明的目的和功能以及用于实现这些目的和功能的方法将得以阐明。然而,本发明并不受限于以下所公开的示范性实施例;可以通过不同形式来对其加以实现。说明书的实质仅仅是帮助相关领域技术人员综合理解本发明的具体细节。
在下文中,将参考附图描述本发明的实施例。在附图中,相同的附图标记代表相同或类似的部件,或者相同或类似的步骤。
为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细描述。
如图1所示,一种基于深度相机和3d卷积神经网络的步态识别方法的步骤为:
步骤101:利用深度相机采集行人步态的rgb-d图像序列;
步骤102:获取每帧图像的步态剪影以及剪影对应的深度图像剪影;
步骤103:将每帧剪影图像和深度图像剪影组成双通道的步态图像;
步骤104:归一化步态图像序列;
根据本发明的一个实施例,所述步骤104的具体步骤为:
步骤201:定位步态剪影的最上和最下像素点,从而计算步态剪影的高度h0;
步骤202:定位步态剪影的最左和最右像素点,从而计算步态剪影的宽度w0;
步骤203:根据步态剪影的高度和宽度,计算剪影的质心位置;
步骤204:给定一个纵横比r,以质心为中心,用w0×h0的矩形裁剪步态图像,其中w0=h0*r;
步骤205:将已裁剪的步态图像等比例缩放到3d卷积神经网络的输入尺寸;
步骤206:根据时间顺序将步态图像重组成步态序列i1,其维度为wi×hi×ci×mi,w1,h1,c1,m1分别为i1的宽度,高度,通道数和序列帧数。
步骤105:将步态图像序列输入3d卷积神经网络,前向传播并输出识别结果。
根据本发明的一个实施例,所述步骤105的3d卷积神经网络前向传播的步骤为:
步骤301:3dconv_1,第一组3d卷积层,对步骤104所得的图像序列进行3d卷积操作,卷积核大小为kw1×kh1×km1,步长为ks1,卷积核个数为kn1;其卷积输出为
其中v1j(x,y,s)表示第j个卷积核的第s个特征图在位置(x,y)处的值,b1j为第j个卷积偏移量,ω1j为第j个卷积权重,ω1j(α,β,γ)和i1(x,y,s)均为c1维向量;将每个卷积核对应的特征图归为一组,则该层共有kn1组特征图,每组(m1-km1)/ks1+1个特征图,每个特征图的尺寸为:
((w1-kw1)/ks1+1)×((h1-kh1)/ks1+1);
其输出维度为:
((w1-kw1)/ks1+1)×((h1-kh1)/ks1+1)×((m1-km1)/ks1+1)×kn1;
步骤302:relu_1,第一组relu激活函数层,对步骤301的输出使用relu激活函数,其输出为:
步骤303:3dpool_1,第一组3d池化层,对步骤302的输出进行最大值池化,核大小为2×2×2,步长为2,按照步骤301中的分组规则,池化层对每组特征图分别进行池化操作,其输出为:
p1j(x,y,s)=max{y1j(x+α,y+β,s+γ)|α,β,γ=0,1}
池化层的输出维度为:
((w1-kw1)/ks1+1)/2×((h1-kh1)/ks1+1)/2×((m1-km1)/ks1+1)/2×kn1
步骤304:restruct_1,第一组时序重构层,对步骤303的输出进行时序重构;按照步骤301所述,3d卷积层输入的图像序列是按照时序排列的,输出的特征图序列在每个分组内的特征图仍然是按照时序排列,不同分组之间的特征图不满足时序关系,而不同分组中相同位置的特征图处于同一时间节点;按照303所述,3d池化层的输出同样满足上述时序规则;为了使后续数据依然满足时序要求,将不同分组中同一位置的特征图组合在一起看作一幅多通道图像,并将这些图像按照时序排列;令该时序重构层的输出为i2,其维度为w2×h2×c2×m2,则:
i2(x,y,s,j)表示i2第s组第j个特征图在位置(x,y)处的值;
步骤305:3dconv_2,第二组3d卷积层,对步骤304的输出进行3d卷积操作,卷积核大小为kw2×kh2×km2,步长为ks2,卷积核个数为kn2;其卷积输出为
其中v2j(x,y,s)表示第j个卷积核的第s个特征图在位置(x,y)处的值,b2j为第j个卷积偏移量,ω2j为第j个卷积权重,ω2j(α,β,γ)和i2(x,y,s)均为c2维向量;其输出维度为
((w2-kw2)/ks2+1)×((h2-kh2)/ks2+1)×((m2-km2)/ks2+1)×kn2;
步骤306:relu_2,第二组relu激活函数层,对步骤305的输出使用relu激活函数,其输出为:
步骤307:3dpool_2,第二组3d池化层,对步骤306的输出进行最大值池化,核大小为2×2×2,步长为2,其输出为:
p2j(x,y,s)=max{y2j(x+α,y+β,s+γ)|α,β,γ=0,1}
输出维度((w2-kw2)/ks2+1)/2×((h2-kh2)/ks2+1)/2×((m2-km2)/ks2+1)/2×kn2;
步骤308:restruct_2,第二组时序重构层,对步骤307的输出进行时序重构;令该时序重构层的输出为i3,其维度为w3×h3×c3×m3,则:
i3(x,y,s,j)表示i3第s组第j个特征图在位置(x,y)处的值;
步骤309:vgg16_reduced,2d卷积网络,对步骤308的输出进行2d卷积和分类识别,采用裁剪的vgg16网络,具体方案为:删除conv1_1~pool2的网络结构,i3作为conv3_1的输入,fc8的维度与类别数目一致。
综上,本发明一种基于深度相机和3d卷积神经网络的步态识别方法,以深度相机作为采集装置,同时考虑步态图像的颜色信息和深度信息,采用3d池化和时序重构操作,提供了一种新颖的3d卷积神经网络结构,直接以步态图像序列为输入,能够同时提取步态序列的时间特征和空间特征,有效的提高了步态识别的准确率。
结合这里披露的本发明的说明和实践,本发明的其他实施例对于本领域技术人员都是易于想到和理解的。说明和实施例仅被认为是示例性的,本发明的真正范围和主旨均由权利要求所限定。
- 还没有人留言评论。精彩留言会获得点赞!